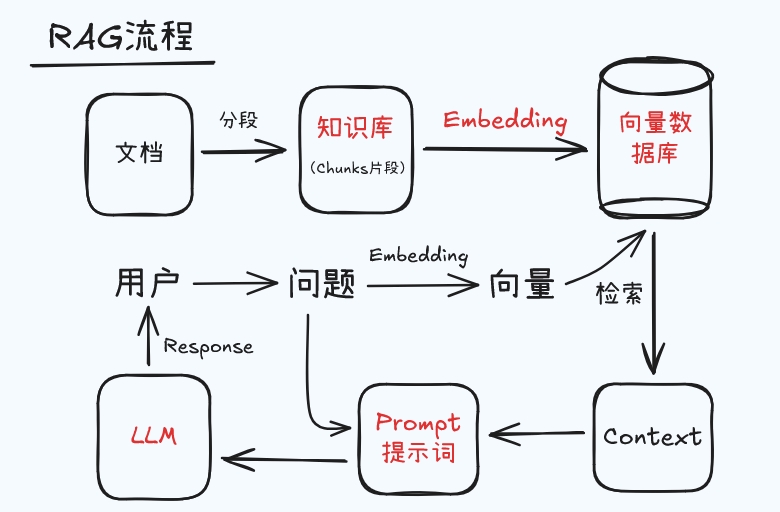
先通过信息 检索模块 从外部知识库(如数据库、文档、网页等)中获取相关的上下文信息,然后再将这些信息与原始输入一起传递给生成模型,生成更具上下文关联的回复。
作用:降低了大模型直接生成内容时容易出现 "幻觉"的问题。
一、关键阶段
RAG 的三个关键阶段:
1. 检索(Retrieval)
-
将用户问题转换为向量表示
-
在向量数据库中搜索相似内容
-
返回最相关的文档片段(top-n)
2. 增强(Augmentation)
-
将检索到的文档与原始问题组合
-
构建包含上下文的提示词(prompt)
3. 生成(Generation)
-
将增强后的提示输入生成模型
-
模型基于上下文生成最终回答
二、核心组成
1. 知识库(Knowledge Base)
-
作用:存储结构化/非结构化知识
-
形式:
-
文档数据库(PDF、Word、HTML等)
-
向量数据库(ChromaDB、FAISS、Milvus)
-
关系型数据库(MySQL、PostgreSQL)
-
图数据库(Neo4j)
-
知识库三种检索方式:
-
稀疏检索:基于关键词匹配(BM25、TF-IDF)
-
稠密检索:基于语义相似度(Embedding模型)
-
混合检索:结合稀疏和稠密方法
相似度计算:余弦相似度或欧氏距离
公式:similarity = cos(θ) = (A·B)/(||A||·||B||)
2. 嵌入模型(Embedding Model)
-
**作用:**将文本(问题、知识库片段)转换为向量表示,实现「语义层面的数值化」(向量距离越近,语义越相似)
-
**示例:**Sentence-BERT、bge-large-zh、text-embedding-ada-002 (OpenAI)
-
关键特性:
-
语义相似度计算,
-
支持长文本(可达8192 token)
-
3. 向量数据库(Vector Database)
-
**定义:**专门用于存储和检索 "向量" 的数据库,支持高效的 "相似性搜索"。
-
**作用:**提前将知识源中的文本(如文档段落)通过嵌入模型转换为向量,存储在向量数据库中(即 "构建知识库索引");当用户查询时,将查询转换为向量后,在数据库中快速找到与查询向量 "最相似" 的向量(即最相关的知识片段)。
-
示例:开源工具如 Chroma、Milvus、FAISS;云服务如 Pinecone、Weaviate 等。
4. 大语言模型(LLM)
- **作用:**基于"用户问题"和"检索到的知识",生成自然语言回答。
- 常用模型:GPT系列(GPT-3.5/4)、LLaMA、Claude、DeepSeek-R1、qwen、硅基流动
5. 提示词(Prompt)
由 用户问题 + 检索的上下文 组成
三、工作流程
1. 知识库构建
- 数据收集:收集领域内的结构化数据(如数据库表结构、Excel)、非结构化数据(如文档、PDF、网页、对话记录)等。
- 数据处理:对原始数据进行清洗、分割(如将长文档拆分为短片段,便于检索)、格式化(如提取关键词、生成向量)。
- 向量存储:将处理后的文本片段转换为向量(通过嵌入模型,如 bge-large-zh、text-embedding-ada-002、BERT、Sentence-BERT),存储到向量数据库(如 Chroma、Pinecone、Milvus)中,形成「可检索的知识库」。
2. 在线问答推理
- 问题解析:用户输入问题后,先将问题转换为向量(与知识库向量用同一嵌入模型)。
- 相似检索:通过向量数据库,计算问题向量与知识库中所有文本向量的相似度,检索出最相关的 top N 个文本片段(即「上下文信息」)。
- 增强生成:将「问题 + 检索到的上下文信息」一起作为提示词 输入大模型,让模型基于这些外部事实生成回答(而非仅依赖自身知识)。
四、关键技术
1. 检索优化技术
| 技术 | 说明 | 优势 |
|---|---|---|
| 查询扩展 | 使用LLM重写问题 | 提升召回率 |
| 多向量检索 | 对文档分段+摘要分别建索引 | 平衡精度与覆盖率 |
| 元数据过滤 | 按来源/日期/类型过滤 | 提升结果相关性 |
| 混合检索 | 结合关键词+语义搜索 | 兼顾精确匹配与语义理解 |
2. 提示工程技术
def build_rag_prompt(question, contexts) -> str:
"""
构建RAG提示模板
"""
prompt = """
你是一位银行业务专家,请严格根据提供的上下文信息回答问题。
上下文信息:
{contexts}
用户问题:
{question}
回答要求:
1. 基于上下文回答,不要编造信息
2. 如上下文未包含答案,请说明"根据现有资料未找到相关信息"
3. 使用专业、简洁的语言
4. 重要数据需标明来源
""".format(
contexts="\n\n".join([f"[来源:{c.metadata}] {c.content}" for c in contexts]),
question=question
)
return prompt五、RAG的局限和解决方案
| 挑战 | 解决方案 |
|---|---|
| 检索不相关 | 混合检索 + 重新排序 |
| 上下文长度限制 | 文本摘要 + 关键信息提取 |
| 多文档冲突信息 | 来源可信度评估 + 信息聚合 |
| 生成忽略上下文 | 提示工程强化约束 + 自我验证 |
| 实时性要求 | 流式知识更新 + 版本控制 |