天池AFAC赛道四-智能体赋能的金融多模态报告自动化生成part2
- [0 赛题](#0 赛题)
- [1 整体框架](#1 整体框架)
- [2 任务拆解模块](#2 任务拆解模块)
- [3 RAG模块](#3 RAG模块)
- 4.子任务回答模块
- [5 子任务回答归入章节](#5 子任务回答归入章节)
- [6 章节润色](#6 章节润色)
- [7 markdown报告输出](#7 markdown报告输出)
- [8 docx文件生成](#8 docx文件生成)
- [9 一些好的参考资料](#9 一些好的参考资料)
0 赛题
本任务需要参赛团队研发一个能够自动撰写三大类季度/年度跟踪型金融研报(宏观经济/策略研报、行业/子行业研报、公司/个股研报)的智能Agent系统,需实现生成研报质量及构建使用技术两部分的目标。
生成研报应满足:
- 多模态呈现:包含图表(如股票/指数走势图、关键金融、宏观或行业指标对比图、财务报表表格等)与文字说明,图文一致;
- 专业性和深度:行业术语规范、分析方法应用合理,掌握基本财务常识,避免常识性错误,分析具备一定原创性,避免机械摘录原始资料;
- 数据融合与事实溯源:整合实时权威数据源(如国家统计局、证券交易所、主流新闻),为所有数据与事实提供明确的来源引用。此外,报告内容应仅限于上市公司,数据来源应仅限于网络免费公开可获取数据和信息,不可直接接入付费第三方整理好的数据API;
- 格式与逻辑:满足中国证券业协会《发布证券研究报告暂行规定》排版与披露要求,论点-论据链完整,章节衔接流畅
具体任务要求:
- 生成公司/个股研报 应能够自动抽取三大会计报表与股权结构,输出主营业务、核心竞争力与行业地位;支持财务比率计算与行业对比分析(如ROE分解、毛利率、现金流匹配度),结合同行企业进行横向竞争分析;构建估值与预测模型,模拟关键变量变化对财务结果的影响(如原材料成本、汇率变动);结合公开数据与管理层信息,评估公司治理结构与发展战略,提出投资建议与风险提醒
- 行业/子行业研报 应能够聚合行业发展相关数据(协会年报、企业财报等),输出行业生命周期与结构解读(如集中度、产业链上下游分析);融合趋势分析与外部变量预测能力(如政策影响、技术演进),支持3年以上的行业情景模拟;提供行业进入与退出策略建议,支持关键变量(如上游原材料价格)敏感性分析;自动生成图表辅助说明行业规模变动、竞争格局等核心要素
- 宏观经济/策略研报 应能够自动抽取与呈现宏观经济核心指标(GDP、CPI、利率、汇率等),对政策报告与关键口径进行解读;构建政策联动与区域对比分析模型,解释宏观变量间的交互影响(如降准对出口与CPI的传导路径);支持全球视野的模拟建模(如美联储利率变动对全球资本流动的影响);提供对潜在"灰犀牛"事件的风险预警机制与指标设计。
Agent系统技术应满足:
1.多Agent协同:通过多Agent分工与链式推理完成端到端流程,自动拆解任务并分阶段调用功能模块(如信息检索、图表生成、内容撰写与审查),包含自检与反馈循环;
2.任务泛化能力:对不同行业、公司、宏观环境具备稳健性;
3.落地潜力:在实际业务场景下有落地可能性,具备可接受的生成效率及部署复杂度;
4.创新性:鼓励前沿相关技术(如MCP、A2A、工具调用、RAG)的使用。
5.开源限制:只能使用开源的模型及其API,不能使用闭源模型以及AI搜索接口
初赛赛题
公司:商汤科技(00020.HK)
行业:智能风控&大数据征信服务
宏观:生成式AI基建与算力投资趋势(2023-2026)
复赛赛题
公司:4Paradigm(06682.HK)
行业:中国智能服务机器人产业
宏观:国家级"人工智能+"政策效果评估 (2023-2025)
官方baseline
DataWhale的baseline:https://www.datawhale.cn/learn/summary/174
1 整体框架
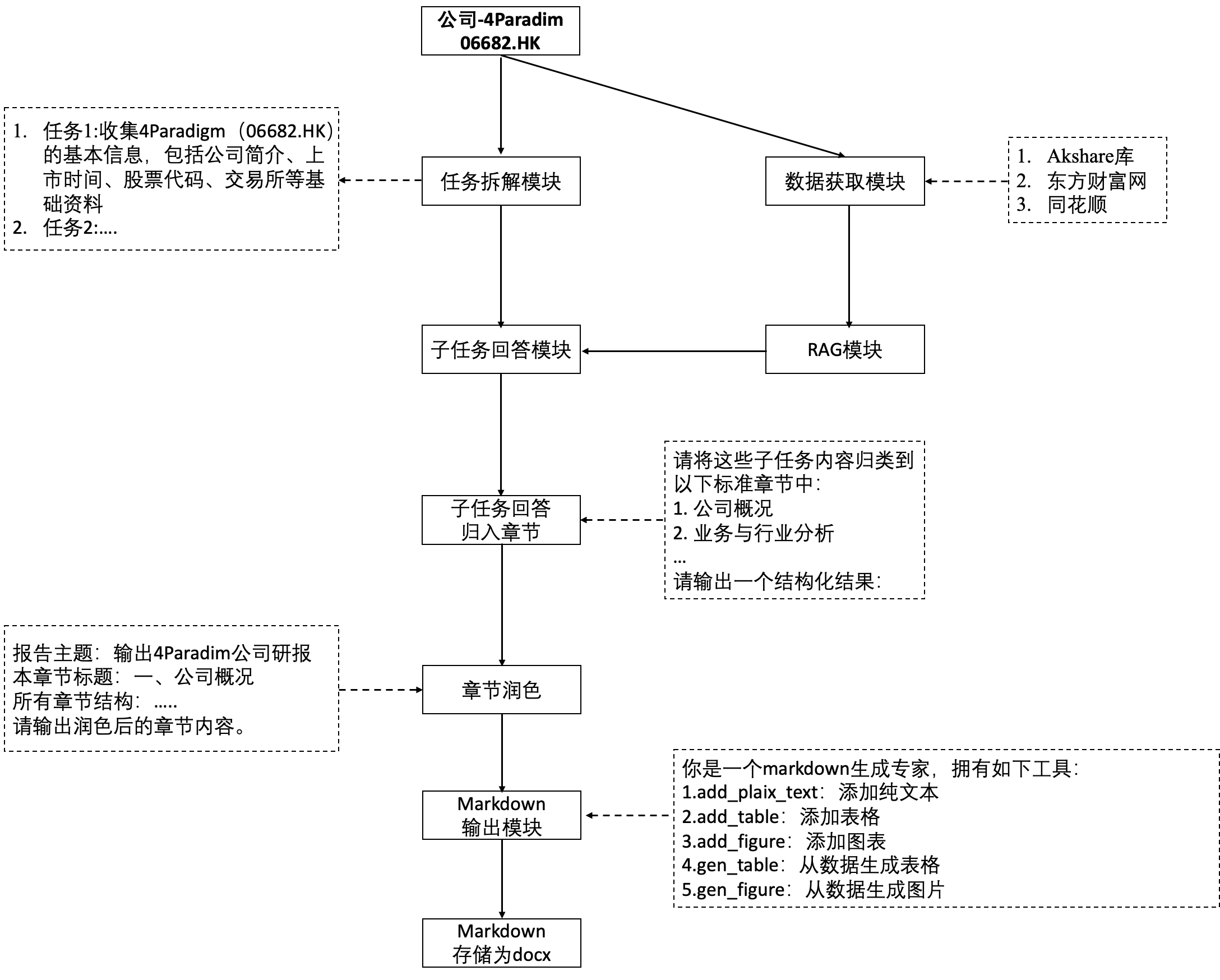
数据获取部分在part1:天池AFAC赛道四-智能体赋能的金融多模态报告自动化生成part1-数据获取
2 任务拆解模块
- ❌一开始尝试过更复杂的方式,任务拆解助手、数据获取助手、写文档助手、判断完成率和完成质量助手进行合作,耗费了1kw的token产出的结果也比较差很多时候会一直卡在一个循环里面,数据获取助手和写文档助手都很执着觉得当前step的任务没有完成,任务拆解助手判断的下一次执行的任务也一直在重复❌
- 简化这个问题,直接数据存储+任务拆分+RAG的方式会简单很多,以生成公司研报为例
python
# 任务拆解,把研究任务拆解成多个子任务,每个子任务可以独立完成,按照顺序进行标号,不超过10个子任务
sub_task_plan_template = """
你是一个专业的金融研究员,需要撰写一篇关于 {stock_info} 的金融研究报告。当前的研究任务如下:
任务说明:
------------
{query}
------------
请你根据这个研究任务,按照逻辑顺序拆解为多个子任务。每个子任务应具备以下特征:
- 可以独立完成
- 按照写作或研究的先后顺序排列
- 数量不超过 10 个子任务
输出格式要求如下:
- 使用如下格式:
#1# 子任务说明
#2# 子任务说明
...
- 不使用任何 Markdown 格式
- 不添加任何解释性内容
请开始输出子任务计划。
"""
sub_task_plan_prompt = sub_task_plan_template.format(
stock_info=input_stock_code, # 输入的股票代码
query=task1 # 当前的研究任务
)
sub_task_response = deepseek_v3.invoke(sub_task_plan_prompt)
import re
def generate_subtasks(llm_response):
# 提取子任务
subtasks = re.findall(r'#(\d+)#\s*(.+)', llm_response.strip())
# 按顺序排序并去重
subtasks = sorted(subtasks, key=lambda x: int(x[0]))
unique_tasks = {}
for idx, task in subtasks:
if task not in unique_tasks:
unique_tasks[task] = None
# 返回任务列表
return list(unique_tasks.keys())
task_list = generate_subtasks(sub_task_response.content)
# 输出结果
# ['收集4Paradigm(06682.HK)的基本信息,包括公司简介、上市时间、股票代码、交易所等基础资料 ',
# '提取并整理4Paradigm的三大会计报表(资产负债表、利润表、现金流量表)数据 ',
# '分析公司主营业务、核心竞争力与行业地位,包括市场份额、技术优势、客户群体等 ',
# '计算关键财务比率(如ROE、毛利率、现金流匹配度等),并与行业同行进行对比分析 ',
# '选取可比公司进行横向竞争分析,包括财务表现、市场定位、技术能力等 ',
# '构建估值模型(如DCF、PE等),并对关键变量(如原材料成本、汇率变动)进行敏感性分析 ',
# '评估公司治理结构与管理层信息,包括董事会构成、管理层背景、股权结构等 ',
# '分析公司发展战略与未来规划,包括市场扩张、研发投入、合作项目等 ',
# '提出投资建议,包括目标价、投资评级(买入、持有、卖出等)及依据 ',
# '总结潜在风险因素,包括市场风险、经营风险、政策风险等,并给出风险提示']3 RAG模块
- 这里因为数据本身比较少,还用不到RAG,不存在粗排召回->精排的流程,直接可以精排,让大模型从数据描述里面判断哪些数据块对于回答当前子任务是最相关的
python
# 数据块构建
# RAG的思路
collected_data_value.keys()
# 注意数据里面的对应股票代码,指的是要完成的金融报告的指定公司的股票代码,除了行业价值表现数据和财务经营数据外,其他的数据里面只有要完成的金融报告的指定公司的信息。
collected_data_desc['财务摘要'] = '包含对应股票代码的财务信息的数据摘要分析'
collected_data_desc['股票近期价格和交易信息'] = '包含对应股票的日期、开盘价、收盘价、最高价、最低价、成交量、成交额、振幅、涨跌幅、涨跌额和换手率等信息'
all_data_chunks = []
def construct_collected_data_chunks(collected_data_value,collected_data_desc):
"""
构造数据块字符串,包含collected_data_value和collected_data_desc的内容
:param collected_data_value: 收集到的数据字典
:param collected_data_desc: 收集到的数据描述字典
:return: 数据块字符串
"""
global all_data_chunks
data_chunks_disc_list = []
idx = 1
for key, value in collected_data_value.items():
desc = collected_data_desc.get(key, "无描述")
discription = f"数据块{idx}: {key} - {desc}\n"
data_chunks_disc_list.append(discription)
# 如果是DataFrame类型的数据,转换为字符串
if isinstance(value, pd.DataFrame):
table_intro = f'{key} - {desc}'
table_str = value.to_csv(sep='|', index=False, header=True)
result_str = f"{table_intro}\n{table_str}"
else:
# 如果是其他类型的数据,直接转换为字符串
result_str = f"{key} - {desc}\n{str(value)}"
all_data_chunks.append(result_str) # 添加数据块内容
idx += 1
return "\n".join(data_chunks_disc_list)
data_chunks_disc = construct_collected_data_chunks(collected_data_value, collected_data_desc)
# 获取最相关的数据chunk块
find_most_relavent_chunks_template = """
你是一个专业的金融研究员,需要对关于 {stock_info} 的问题给出非常专业精准的回答,因此你需要先从候选的数据池中选择出最相关的数据块以提供参考信息。
该问题为:
-----
{task}
-----
为了回答该问题,你需要从以下数据池中选择最相关的数据块,获取信息作为参考:
-----
{data_chunks}
-----
请你筛选出回答该问题最有可能用到的数据块编号,最多选择6个数据块,最少选择1个数据块,每个数据块的编号之间用逗号分隔,直接输出编号,不要添加任何其他内容,例如 0,1
不要解释、分析或者输出任何其他内容,只需要输出数据块标号,你判断需要使用的数据块标号是:
"""4.子任务回答模块
python
# 用于生成报告正文内容的模板
subtask_solution_prompt_template = """
你是一个专业的金融研究员,正在撰写关于 {stock_info} 的公司研究报告。
当前章节需要涵盖的内容是:
-----
{task}
-----
你需要参考以下数据和信息:
-----
{used_data_chunk}
-----
请根据以上信息,撰写该章节的正式报告内容。要求如下:
1. 表述专业、逻辑清晰、内容翔实,适合用于正式研究报告;
2. 若涉及数据,应保证数据和参考信息里面一致,不能编造;
3. 若涉及表格,应使用Markdown格式输出表格,表格内容要清晰、易读,可以只呈现关键数据,例如按照年份进行采样或者汇总输出,但是表格内容要完整不能出现省略号;
4. 若涉及分析,应给出结论性判断(如趋势、对比、风险、机会等);
5. 不要写"我将如何分析",而是直接输出分析结论;
6. 不要写"步骤一、步骤二";
7. 使用中文,语句通顺,格式规范。
请直接以正式报告内容的形式输出该章节内容。
"""
task_solution_list = []
for i in range(len(task_list)): # 依次完成任务
task = task_list[i] # 当前任务
write_print_to_log(f"\n\n--------------------开始处理任务 {i+1}: {task} --------------------\n")
retry = 0
finish_flag = 0
while retry<3 and finish_flag<=0:
# 搜集和任务相关的信息,可以取出最相关的6个chunk
find_most_relavent_chunks_prompt = find_most_relavent_chunks_template.format(
stock_info=input_stock_code, # 输入的股票代码
task=task, # 当前的任务
data_chunks=data_chunks_disc # 数据块描述字符串
)
find_chunk_response = base_model.invoke(find_most_relavent_chunks_prompt,enable_thinking=False)
sleep(1)
most_relevant_chunks = find_chunk_response.content.strip() # 最相关的数据块编号
# 解析chunk编号
most_relevant_chunks_list = most_relevant_chunks.split(',') # 分割成列表
# 检查数据格式是否准确
most_relevant_chunks_list = [chunk.strip() for chunk in most_relevant_chunks_list if chunk.strip().isdigit()]
if len(most_relevant_chunks_list) == 0:
write_print_to_log(f"A没有找到相关的数据块,任务 {i+1} 无法完成")
most_relevant_chunks_list = [0]
write_print_to_log(f"最相关的数据块编号: {most_relevant_chunks_list}")
# trace_log输出
with open(trace_log, 'a', encoding='utf-8') as f:
f.write(f"Most relevant chunks: {most_relevant_chunks}\n")
finish_flag = 1 # 有数据了
# 构建数据块字符串
used_data_chunk = []
for k in range(len(most_relevant_chunks_list)):
chunk_index = int(most_relevant_chunks_list[k])
if chunk_index < len(all_data_chunks):
used_data_chunk.append(all_data_chunks[chunk_index])
used_data_chunk_str = '\n\n'.join(used_data_chunk)
# 生成任务解决方案
subtask_solution_prompt = subtask_solution_prompt_template.format(
stock_info=input_stock_code, # 输入的股票代码
task=task, # 当前的任务
used_data_chunk=used_data_chunk_str # 使用的数据块字符串
)
subtask_solution_response = deepseek_r1.invoke(subtask_solution_prompt)
sleep(1)
subtask_solution = subtask_solution_response.content
task_solution_list.append(subtask_solution) # 存储任务解决方案
# trace_log输出
with open(trace_log, 'a', encoding='utf-8') as f:
f.write(f"Subtask solution: {subtask_solution}\n")
write_print_to_log('\n\n--------------------子任务解决方案--------------------\n')
write_print_to_log(f"Subtask solution:\n {subtask_solution}")
# 数据保存,保存任务解决方案到pickle
import pickle
with open('task1_solution_list.pkl', 'wb') as f:
pickle.dump(task_solution_list, f)5 子任务回答归入章节
- 因为子任务和章节并不是一一对应的,10个子任务,5-7个章节,现在把子任务的内容归入到其中一个章节,以公司研报为例
python
# 把任务解决方案写入到报告中,形成一篇内容翔实的报告
auto_organize_sections_prompt_template = """
你是一个专业的金融研究报告编辑,需要将以下多个子话题的内容归类到标准的金融研究报告结构中。
每个子话题如下:
-----
{task_content_pairs}
-----
请将这些子任务内容归类到以下标准章节中:
1. 公司概况
2. 业务与行业分析
3. 财务分析
4. 财务建模与预测
5. 公司治理与战略分析
6. 投资价值分析与建议
请输出一个结构化结果,格式如下:
#1# 子任务标题
归类章节:公司概况
内容摘要:该部分内容主要介绍了公司基本信息和股权结构。
#2# 子任务标题
归类章节:财务分析
内容摘要:该部分内容主要分析了三大会计报表和财务比率。
...
要求:
- 不要遗漏任何子任务;
- 不要添加解释或说明;
- 严格按照输出格式;
- 章节名称必须从上面6个中选择;
- 内容摘要要简明扼要。
"""
# 生成子任务标题 + 内容的拼接字符串
task_content_pairs_str = ""
for idx, (task, content) in enumerate(zip(task_list, task_solution_list), 1):
task_content_pairs_str += f"#{idx}# {task}\n"
# 构建 Prompt
organize_prompt = auto_organize_sections_prompt_template.format(
task_content_pairs=task_content_pairs_str.strip()
)
# 调用模型
response = base_model.invoke(organize_prompt,enable_thinking=False)
sleep(1)
organize_result = response.content.strip()
# """
# 归入结果提取
from collections import defaultdict
import re
# 正则提取归类结果
pattern = r'#(\d+)# (.*?)\n归类章节:(.*?)\n内容摘要:(.*?)(?=\n#|\Z)'
matches = re.findall(pattern, organize_result, re.DOTALL)
# 标准章节列表
standard_sections = [
"公司概况",
"业务与行业分析",
"财务分析",
"财务建模与预测",
"公司治理与战略分析",
"投资价值分析与建议"
]
# 构建结构化归类字典
section_content_map = defaultdict(list)
# matches 是你提供的模型输出结果
for idx, task_title, model_section, summary in matches:
# 清洗模型输出的章节名(去除前后空格/换行)
cleaned_section = model_section.strip()
# 初始化匹配章节为 None
matched_section = None
# 模糊匹配标准章节
for std_sec in standard_sections:
if std_sec in cleaned_section or cleaned_section in std_sec:
matched_section = std_sec
break
# 如果完全没匹配上,归类为 "其他分析"
if not matched_section:
matched_section = "其他分析"
# 清洗任务标题(去除前后空格)
cleaned_task_title = task_title.strip()
# 找到对应的完整内容
full_content = None
for task, content in zip(task_list, task_solution_list):
if cleaned_task_title in task or task in cleaned_task_title:
full_content = content.strip()
break
if full_content:
section_content_map[matched_section].append(idx)
section_content_map
"""
defaultdict(list,
{'公司概况': ['1'],
'财务分析': ['2', '4'],
'业务与行业分析': ['3', '5'],
'财务建模与预测': ['6'],
'公司治理与战略分析': ['7', '8'],
'投资价值分析与建议': ['9', '10']})
"""6 章节润色
- 因为归入章节后,每个章节内部内容可能重复,章节间可能也有重复内容,章节和子标题等也可能不准确,使用润色模块,以章节为单位对内容进行润色,以公司研报为例
python
# 对每个章节的内容进行润色,一方面是围绕主题来写,纠正幻觉
polish_section_prompt_template = """
你是一个专业的金融研究报告编辑,负责对本章节内容进行润色与整合,目标是输出一个**逻辑清晰、语言专业、无幻觉**的完整章节内容,以markdown文本格式输出。
【报告主题】
-----
{query}
-----
【完整报告目录结构】
-----
{report_structure}
-----
【当前章节标题】
-----
{section_title}
-----
【当前章节的原始内容】
-----
{section_content}
-----
【润色要求】
1. **围绕当前章节标题**组织内容,确保内容紧扣主题;
2. **整理好排版,输出内容应包含当前章节标题**
3. **去掉原始内容中多余的空格、换行符和格式混乱的部分**;
4. **对于原始内容中的表格**,如果有并且是完整的,请使用Markdown格式输出,确保表格内容清晰、易读;
5. **理清本章节在整体报告中的逻辑定位**,整合原始内容,删除冗余信息,合并重复内容,不遗漏重要信息和表述;
6. **确保语言正式、专业**,符合金融研究报告的写作规范;
7. **纠正可能存在的数据错误、逻辑矛盾或幻觉内容**;
8. **仅基于原始内容进行润色,不添加任何原始内容中没有的信息或数据**;
9. **输出格式为完整的markdown格式的研究报告章节**,不要包含解释性语句(如"我将如何整合");
特别的,对于当前章节的标题和子标题、列表等,你需要尤其注意格式:
1. 当前章节标题{section_title}为一级标题(#)格式,例如"# 一、"和"# 二、"
2. 其他的子标题不允许使用"# 一、"和"# 二、"这样的中文序号标题格式,可以使用"(一)"或者"(二)"这样的格式,或者使用"1."、"2."这样的数字序号格式等等
2. 对于原始内容进行排版,如果原始内容里面出现了某个子标题内容特别长,需要对其进行浓缩符合子标题风格
请直接输出润色后的章节内容:
"""
section_idx_title =[
"一、公司概况",
"二、业务与行业分析",
"三、财务分析",
"四、财务建模与预测",
"五、公司治理与战略分析",
"六、投资价值分析与建议"
]
polished_result_list = []
# 按照标准章节顺序拼接
for i in range(len(standard_sections)):
section_title = standard_sections[i] # 当前章节标题
print(f"正在润色章节:{section_idx_title[i]}")
idx = section_content_map.get(section_title)
# 获取对应章节的内容
contents = []
if idx:
for num in idx:
# 注意这里的i是字符串,需要转换为整数
task_index = int(num) - 1 # 索引从0开始
if task_index < len(task_solution_list):
content = task_solution_list[task_index].strip()
if content: # 如果内容不为空
contents.append(content)
if contents:
polish_section_prompt = polish_section_prompt_template.format(
query=task1, # 输入的研究任务
report_structure='\n'.join(section_idx_title), # 报告结构
section_title=section_idx_title[i], # 当前章节标题
section_content='\n\n'.join(contents) # 当前章节内容
)
# 调用模型进行润色
polish_response = deepseek_r1.invoke(polish_section_prompt)
sleep(2)
polished_content = polish_response.content.strip()
polished_result_list.append(polished_content) # 存储润色后的内容
# pickle保存润色后的内容
import pickle
with open('comany_polished_result_list.pkl', 'wb') as f:
pickle.dump(polished_result_list, f)7 markdown报告输出
- 之前的是纯文本格式的报告,为了最终的报告里面含有图表和表格等,内容更丰富、示意性更好,在生成最终的markdown文件时,使用function call的方式,配置上输出图和表的function
python
# 可以支持把llm生成结果保存为markdown的函数
import os
import pandas as pd
writer_data_value = {}
writer_data_desc = {}
class MarkdownReportBuilder:
def __init__(self, report_title="调研报告", output_path="comany_report.md", stream_out_path = "company_report_stream_output.md", image_dir="./company_img/"):
self.title = report_title
self.content = []
self.current_content = "" # 保存当前写了的临时的结果
self.image_counter = 0
self.table_couneter = 0
self.image_dir = image_dir
self.output_path = output_path
self.stream_out_path = stream_out_path
# 创建图片目录(如果不存在)
if not os.path.exists(self.image_dir):
os.makedirs(self.image_dir)
# 实时输出到文件
def stream_output(self, text):
"""实时输出到文件"""
with open(self.stream_out_path, "a", encoding="utf-8") as f:
f.write(text + "\n")
def add_paragraph(self, text):
"""添加一段文字"""
self.content.append(f"{text}\n")
self.current_content += f"{text}\n"
self.stream_output(f"{text}\n")
def add_table(self, df: pd.DataFrame, caption=None):
"""添加一个 DataFrame 表格"""
if caption:
self.content.append(f"**{caption}**\n")
self.current_content += f"**{caption}**\n"
self.stream_output(f"**{caption}**\n")
self.content.append(df.to_markdown(index=False) + "\n")
self.current_content += df.to_markdown(index=False) + "\n"
self.stream_output(df.to_markdown(index=False) + "\n")
self.table_couneter += 1
def add_image(self, image_path, caption=""):
"""添加一张图片(将原图复制到指定目录)"""
import shutil
new_image_name = f"image_{self.image_counter}{os.path.splitext(image_path)[-1]}"
new_image_path = os.path.join(self.image_dir, new_image_name)
shutil.copyfile(image_path, new_image_path)
self.content.append(f"\n")
self.current_content += f"\n"
self.stream_output(f"\n")
self.image_counter += 1
def save(self):
"""保存报告为 Markdown 文件"""
with open(self.output_path, "w", encoding="utf-8") as f:
f.write(f"---\ntitle: 公司研报-{company_name}\n---\n\n")
f.write("\n".join(self.content))
print(f"报告已保存至:{self.output_path}")
def clear_current_content(self):
"""清空当前内容"""
self.current_content = ""
def get_current_content(self):
"""获取当前内容"""
return self.current_content
@tool
def add_plain_text(content: str):
"""
添加一段文字内容到报告中,除了图片和表格,其他内容都必须调用这个函数才能添加到报告中。
"""
report_builder.add_paragraph(content)
return "已添加该段文字"
@tool
def add_table(df_key_name: str, caption: str = None):
"""把调用plain_text_dataframe_to_table函数生成的DataFrame添加到报告中
Args:
df_key_name (str): writer_data_value里面指向DataFrame的键名
caption (str): 表格的编号
"""
if df_key_name not in writer_data_value:
return f"没有找到键名为 '{df_key_name}' 的DataFrame,请先调用plain_text_dataframe_to_table函数生成表格数据。检查表格数据是否成功生成保存!"
df = writer_data_value[df_key_name]
report_builder.add_table(df,caption)
table_idx = report_builder.table_couneter
return "已添加该表格,该表的编号为 表{}".format(table_idx)
@tool
def add_image(image_path: str, caption: str = None):
"""把调用draw_data_date_one_list_line_plot等画图函数生成的图片添加到报告中
Args:
image_path (str): 已经画好图的图片的存储路径
caption (str): 图片的标题或说明文字
"""
report_builder.add_image(image_path, caption)
img_idx = report_builder.image_counter
return "已添加该图片,该图片的编号为 图片{}".format(img_idx)
@tool
def save_report(output_path: str = "company_report.md"):
"""保存报告为markdown文件"""
report_builder.save()
return f"报告已保存至文件: {output_path}"
# 输入为dict的形式,变成一个dataframe,存在collected_data_value中,键名为df_key_name
# 例如{
# "H":['a','b','c,'d']
# "a":[1,2,3,4],
# "b":[5,6,7,8],}
@tool
def plain_text_dataframe_to_table(
df_key_name: str,
data_dict: dict
):
"""
将报告中文本格式的表格转化为dataframe,输入需要把表格的数据以字典形式传入,最后会把数据保存到writer_data_value中,保存的key为指定的参数df_key_name,供后续调用add_table函数插入到报告中。
Args:
df_key_name (str): 保存DataFrame的键名,不要和已有的键名冲突,可以取为插入文档中表格的名字
data_dict (dict): 包含数据的字典,键为列名,值为列数据列表
Returns:
str: 返回保存成功的信息
"""
global writer_data_value, writer_data_desc, report_builder
try:
df = pd.DataFrame(data_dict)
except Exception as e:
return f"数据转换为DataFrame失败: {str(e)},请注意数据格式是否正确"
writer_data_value[df_key_name] = df
writer_data_desc[df_key_name] = f"写作时需要使用的数据表,键名为{df_key_name}"
return f"DataFrame已保存到writer_data_value中,键名 '{df_key_name}' 中,稍后可以通过该键名调取插入表格函数add_table给报告中添加表格,该表格的编号为 表{report_builder.table_couneter + 1}。"
# # 画图函数
# 支持输入数据列表y_list,日期列表date_list,画出来,保存为图片,返回图片保存路径
@tool
def draw_data_date_one_list_line_plot(
y_list,
date_list,
title="数据变化趋势",
xlabel="日期",
ylabel="数值",
legend_label="数据",
image_path="data_trend.jpg") -> str:
"""
绘制一维简单数据变化趋势折线图,支持输入单个的数据列表和日期列表,要求数据列表和日期列表长度一致,按照日期顺序排序
Args:
y_list (List[float]): 数据列表
date_list (List[str]): 日期列表,格式为"YYYY-MM-DD"
title (str): 图表标题
xlabel (str): x轴标签
ylabel (str): y轴标签
legend_label (str): 图例标签
returns:
str: 图片保存路径
"""
from matplotlib import pyplot as plt
import os
# 检查输入数据长度是否一致
if len(y_list) != len(date_list):
return ("数据列表和日期列表长度不一致")
# 转换日期字符串为日期对象
try:
date_list = [datetime.strptime(date, "%Y-%m-%d") for date in date_list]
except ValueError:
return ("日期格式错误,请使用YYYY-MM-DD格式的日期字符串")
# 绘图
plt.figure(figsize=(10, 5))
plt.plot(date_list, y_list, marker='o', label=legend_label)
plt.title(title)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.xticks(rotation=45)
plt.legend()
# 保存图片
# image_path = "data_trend.jpg"
plt.tight_layout()
plt.savefig(image_path)
plt.close()
return "图片保存路径为: " + image_path + ",稍后可以通过调用add_image函数将图片插入到报告中"
# 绘制一维的数据占比图
@tool
def draw_data_one_list_pie_chart(y_list, labels, title="数据占比图", image_path="data_pie_chart.jpg") -> str:
"""
绘制一维数据占比饼图,支持输入单个的数据列表和标签列表,要求数据列表和标签列表长度一致
Args:
y_list (List[float]): 数据列表,饼图的每一块对应一个数据值,需要保证所有数据非负
labels (List[str]): 标签列表
title (str): 图表标题
image_path (str): 图片保存路径
"""
from matplotlib import pyplot as plt
# 检查输入数据长度是否一致
if len(y_list) != len(labels):
return ("数据列表和标签列表长度不一致")
# 检查数据是否为非负数
if any(value < 0 for value in y_list):
return ("数据列表中的值必须为非负数,请检查数据输入,该数据不适合用饼图展示,请尝试使用条形图draw_data_one_list_bar_chart或者折线图draw_data_date_one_list_line_plot")
# 绘图
plt.figure(figsize=(8, 8))
plt.pie(y_list, labels=labels, autopct='%1.1f%%', startangle=140)
plt.title(title)
# 保存图片
plt.tight_layout()
plt.savefig(image_path)
plt.close()
return "图片保存路径为: " + image_path + ",稍后可以通过调用add_image函数将图片插入到报告中"
# 绘制一维数据的条形图,例如用于展示行业地位,要求能支持将其中某一个柱子的颜色突出
@tool
def draw_data_one_list_bar_chart(y_list, labels, highlight_index=None, title="数据条形图", xlabel="类别", ylabel="数值", image_path="data_bar_chart.jpg") -> str:
"""
绘制一维数据条形图,支持输入单个的数据列表和标签列表,要求数据列表和标签列表长度一致
Args:
y_list (List[float]): 数据列表
labels (List[str]): 标签列表
highlight_index (Optional[int]): 突出显示的柱子索引,默认为None表示不突出显示
title (str): 图表标题
xlabel (str): x轴标签
ylabel (str): y轴标签
image_path (str): 图片保存路径
"""
from matplotlib import pyplot as plt
# 检查输入数据长度是否一致
if len(y_list) != len(labels):
raise ValueError("数据列表和标签列表长度不一致")
# 绘图
plt.figure(figsize=(10, 5))
bars = plt.bar(labels, y_list, color='blue')
# 突出显示指定柱子
if highlight_index is not None and 0 <= highlight_index < len(bars):
bars[highlight_index].set_color('red')
plt.title(title)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
# 保存图片
plt.tight_layout()
plt.savefig(image_path)
plt.close()
return "图片保存路径为: " + image_path + ",稍后可以通过调用add_image函数将图片插入到报告中"
markdown_tools = [
add_plain_text,
add_table,
add_image,
save_report,
plain_text_dataframe_to_table,
draw_data_date_one_list_line_plot,
draw_data_one_list_pie_chart,
draw_data_one_list_bar_chart
]
markdown_agent = tool_agent.bind_tools(markdown_tools)最后一章一章地把内容进行输出
python
# 全局报告对象(适用于单次任务)
report_builder = MarkdownReportBuilder(report_title="公司研报"+ " - " + input_stock_code, output_path="company_report.md", image_dir="./company_img/")
markdown_format_prompt_template = """
你是一个专业的金融研究报告编辑助手,负责将原始文稿内容结构化地写入 Markdown 格式的调研报告中。
你的任务是:
1. 分析【章节内容】,识别出需要结构化处理的内容(如表格、图表、普通文本等);
2. 按照以下规则调用工具函数,将内容写入报告;
3. 最终使用 `save_report` 保存报告。
【调用工具的规则】:
- **遇到表格内容**(如:`|列1|列2|\n|---|---|`)时:
1. 使用 `plain_text_dataframe_to_table` 将其转换为 DataFrame;
2. 使用 `add_table` 将表格插入报告;
3. 在输出内容中不再保留原始文本格式表格。
- **遇到图表描述**(如"收入趋势"、"行业占比"、"柱状图"等)时:
1. 使用对应的绘图工具(如 `draw_data_date_one_list_line_plot` 或 `draw_data_one_list_pie_chart`)生成图片;
2. 使用 `add_image` 将图片插入报告;
- **遇到普通文本内容**(非表格、非图表)时:
1. 使用 `add_plain_text` 添加内容,保证内容中没有转义字符或unicode值;
2. 保持段落结构清晰,不遗漏关键信息。
- **完成内容输出后**:
1. 使用 `save_report` 保存最终的 Markdown 报告。
【注意事项】:
- 你的下游就是研究报告,千万一定不要对中文进行转义,add_plain_text的参数不要出现转义字符或者unicode值;
- 你不能对原始内容进行任何润色、改写、缩写或扩展;
- 你不能添加任何你自己的解释、评价、分析、总结或者你的思维过程;
- 你不能修改原文稿中的任何数据、格式或语序,除非是识别到文本格式的表格需要调用表格处理函数输出,不保留原始的文本形式表格内容;
- 所有文本内容必须原样通过 `add_plain_text` 添加到报告中;
- 表格内容必须先调用 `plain_text_dataframe_to_table` 再调用 `add_table`添加;
- 要增加图表,必须先调用绘图函数生成图片,再调用 `add_image` 添加到报告中。
原始文稿的章节标题为:
-----
{section_title}
-----
原始文稿的章节内容为:
-----
{section_content}
-----
请开始调用工具,将内容结构化写入报告。
"""
# for polist list
for i in range(len(polished_result_list)):
polished_content = polished_result_list[i]
section_title = section_idx_title[i] # 当前章节标题
print(f"\n\n--------------------开始处理章节 {i+1}: {section_title} --------------------\n")
writer_history_message = []
while True:
# 构建章节写作提示
markdown_format_prompt = markdown_format_prompt_template.format(
section_title=section_title, # 当前章节标题
section_content=polished_content # 当前章节内容
)
# 调用markdown写作助手
writer_history_message.append(HumanMessage(
content=markdown_format_prompt # 当前章节内容
))
markdown_writer_output_response = markdown_agent.invoke(writer_history_message,enable_thinking=False) # 输出到markdown中
sleep(1) # 等待1秒,避免过快调用
writer_history_message.append(markdown_writer_output_response)
if markdown_writer_output_response.tool_calls is None or len(markdown_writer_output_response.tool_calls) == 0:
break
# 执行markdown输出工具
for tool_call in markdown_writer_output_response.tool_calls:
tool_name = tool_call['name']
tool_args = tool_call['args']
selected_tool = globals()[tool_call["name"]]
current_data = selected_tool.invoke(tool_args) # 正确调用方式
if tool_name == "save_report":
break
writer_history_message.append(ToolMessage(
content=str(current_data), # 转为字符串
name=tool_name, # 工具名称
tool_call_id=tool_call['id'] # 匹配对应的 tool_call ID
))
write_print_to_log(f"调用工具 {tool_name}, 参数: {tool_args}, 返回结果: {current_data}")
with open(trace_log, 'a', encoding='utf-8') as f:
f.write(f"调用工具 {tool_name}, 参数: {tool_args}, 返回结果: {current_data}\n")
if tool_name == "save_report":
break
# 手动调用save_report
report_builder.save()8 docx文件生成
- 使用pandoc来输出
python
import pypandoc
import os
def convert_markdown_to_docx(input_file, output_file):
"""
使用 Pandoc 将 Markdown 文件转换为 DOCX 格式
自动处理表格、格式和样式
"""
try:
# 检查文件是否存在
if not os.path.exists(input_file):
raise FileNotFoundError(f"输入文件 {input_file} 不存在")
# 使用 Pandoc 进行转换
output = pypandoc.convert_file(
input_file,
'docx',
outputfile=output_file,
extra_args=[
'--columns=80',
]
)
except Exception as e:
print(f"转换过程中发生错误:{str(e)}")
input_md = "company_report.md"
output_docx = "Company_Research_Report.docx"
# 执行转换
convert_markdown_to_docx(input_md, output_docx)效果展示:
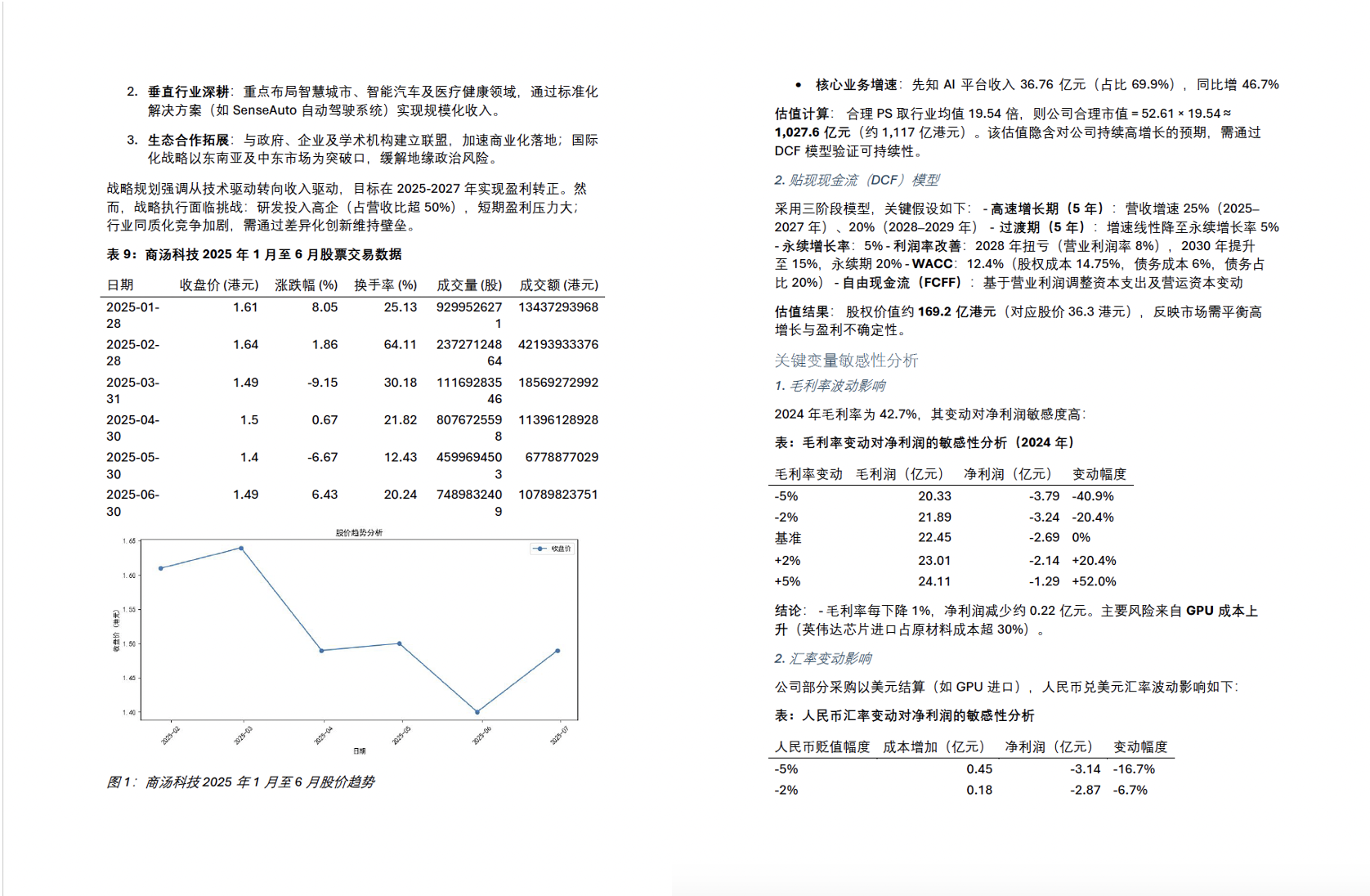
9 一些好的参考资料
现在的版本其实还有很多问题,比如幻觉的问题(没有数据的情况下,模型用自己的数据或者造了一些内容出来),可以引入llm as judge的方式检查润色,此外数据获取上可以更加智能,使用搜索引擎等,websailor看上去很厉害
- multimodal-deepresearcher:https://github.com/rickyang1114/multimodal-deepresearcher/
- 阿里的websailor:https://github.com/abusallam/Websailor