文章目录
-
- 一、一个实验:亲眼见证地址的"骗局"
- 二、一个比喻:虚拟地址空间的本质
- 三、两张图:看懂地址空间的内部结构
- [四、三层解析:从虚拟到物理的 "翻译" 过程](#四、三层解析:从虚拟到物理的 “翻译” 过程)
-
- [4.1 第一层:CPU 发出虚拟地址](#4.1 第一层:CPU 发出虚拟地址)
- [4.2 第二层:MMU 查询页表](#4.2 第二层:MMU 查询页表)
- [4.3 第三层:访问物理内存或触发缺页中断](#4.3 第三层:访问物理内存或触发缺页中断)
- [写时拷贝 (Copy-on-Write) 的实现](#写时拷贝 (Copy-on-Write) 的实现)
- 五、为何需要虚拟地址空间?三大核心价值
- 六、系列总结:进程世界的宏伟蓝图
在上一篇文章中,我们探讨了父进程如何通过环境变量,将自己的"环境 DNA"传递给子进程,解决了进程间信息传递和环境初始化的问题。我们明白了进程如何获得其运行的"软件环境"。
但这引出了一个更深层次的问题:
- 进程运行所需的"硬件环境"------内存,又是如何分配和管理的?
- 为什么每个进程都似乎拥有自己独立的、从 0 开始的、互不干扰的内存空间?
fork后的父子进程,访问同一全局变量,为何地址相同,值却不同?
答案就隐藏在操作系统为每个进程精心构建的一个"独立内存王国"之中,而这个王国的基石,就是程序地址空间 (Program Address Space)。你所看到的地址,其实都是这个王国里的"虚拟门牌号"。
这篇文章将是本系列的终章,我们将彻底揭开"虚拟地址"的神秘面纱,通过一个实验、一个比喻、两张图、三层解析 ,让你不仅知其然,更知其所以然,为我们的 Linux 进程探索之旅画上一个圆满的句号。

一、一个实验:亲眼见证地址的"骗局"
让我们从一个经典的 fork 实验开始,直观地感受这个"独立王国"的存在。
实验代码:
c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_val = 0; // 全局变量,位于 .data 段
int main() {
pid_t pid = fork();
if (pid == 0) {
// 子进程:修改全局变量
g_val = 100;
printf("子进程:g_val = %d, 地址 = %p\n", g_val, &g_val);
} else {
// 父进程:等待子进程执行完,再读取
sleep(1);
printf("父进程:g_val = %d, 地址 = %p\n", g_val, &g_val);
}
return 0;
}运行结果 :

矛盾出现了 :同一个地址 0x601040,为何能读出两个完全不同的值?
唯一解释 :这个地址根本不是真实的物理内存地址。它是一个虚拟地址 。父、子进程各自生活在自己的"虚拟世界"里,它们的 0x601040 只是一个门牌号,背后通往的"真实房间"(物理内存)截然不同。这,就是进程独立性的体现。
二、一个比喻:虚拟地址空间的本质
虚拟地址空间究竟是什么?它不是内存,而是一套管理规则 和逻辑蓝图。
"富豪与继承人" 的故事:
- 操作系统 是一位深谋远虑的富豪,他拥有巨额的真实资产(物理内存)。
- 他有多个继承人(进程),他对每个继承人都承诺:"我名下所有的资产(例如 4GB 的空间)未来都是你的!"
- 每个继承人(进程)都拿到了一份资产清单(虚拟地址空间),以为自己独享全部财富,可以随意规划使用(例如,这里放家具,那里建泳池)。
- 但实际上,只有当继承人真的要使用某笔钱(访问虚拟地址 )时,富豪的管家(MMU,内存管理单元 )才会将清单上的项目兑现为一笔真实的资产(映射到物理内存)。如果继承人想动的钱超出了承诺范围,管家会立刻阻止。
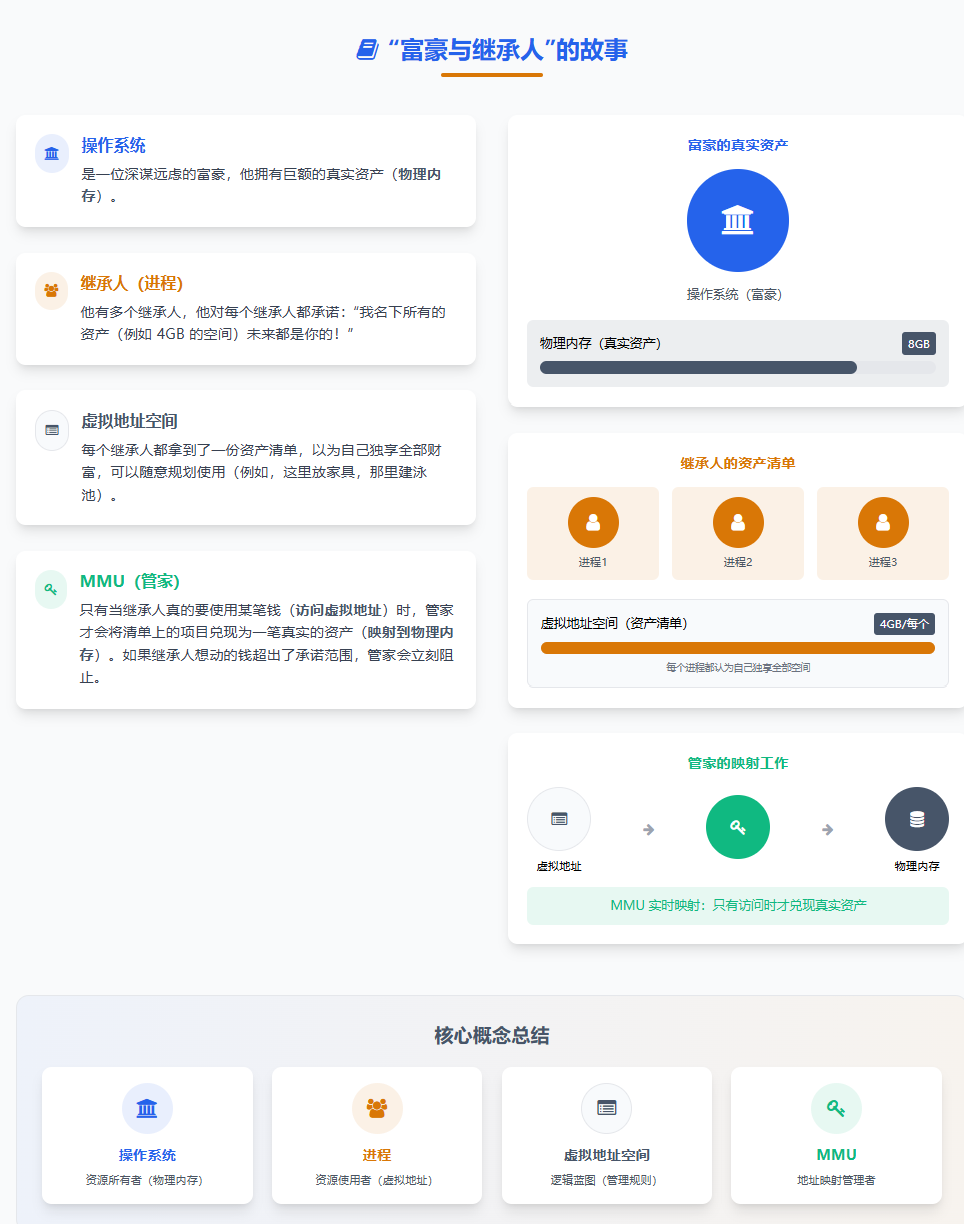
核心结论:
- 虚拟地址空间 :是内核为每个进程画的 "大饼",一个从 0 到 4G/256T 的线性地址范围。它是一个逻辑概念,一套数据结构 (
mm_struct)。 - 物理内存:是真正存在的硬件资源,是真正的 "饼"。
- 映射关系 :由页表来维护虚拟地址和物理地址之间的 "兑换关系"。
三、两张图:看懂地址空间的内部结构
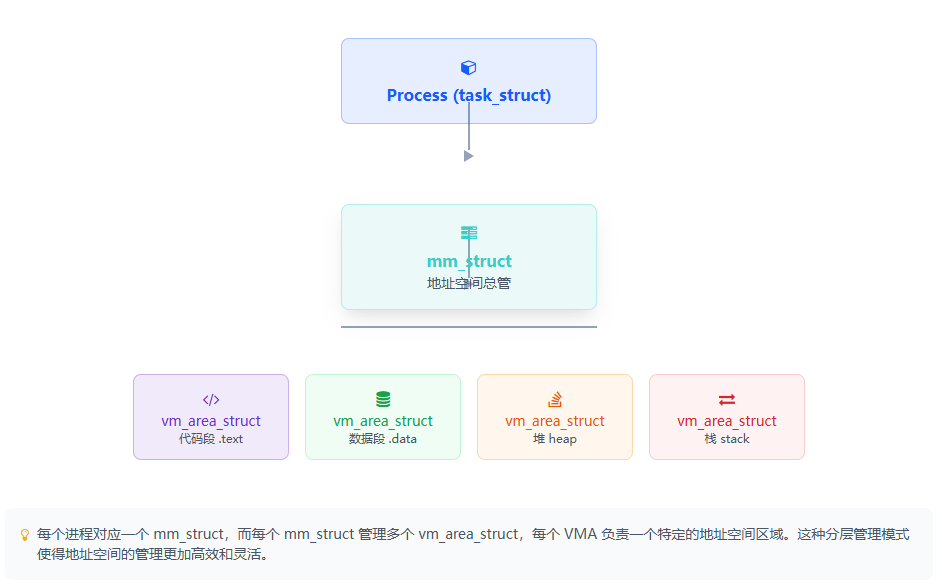
虚拟地址空间这张 "大饼" 不是随意画的,内部有精密的区域划分。这由两个关键的内核结构体 mm_struct 和 vm_area_struct 来管理。
mm_struct:地址空间总管。每个进程只有一个,描述了整个虚拟地址空间的布局,如代码段、数据段、堆、栈的起止位置。vm_area_struct(VMA):区域管理员 。每个mm_struct包含多个 VMA,每个 VMA 负责管理一小块连续的、属性(如读写权限)相同的虚拟地址区域。
图一:管理关系
图二:32 位 Linux 用户空间布局 (从低地址到高地址)
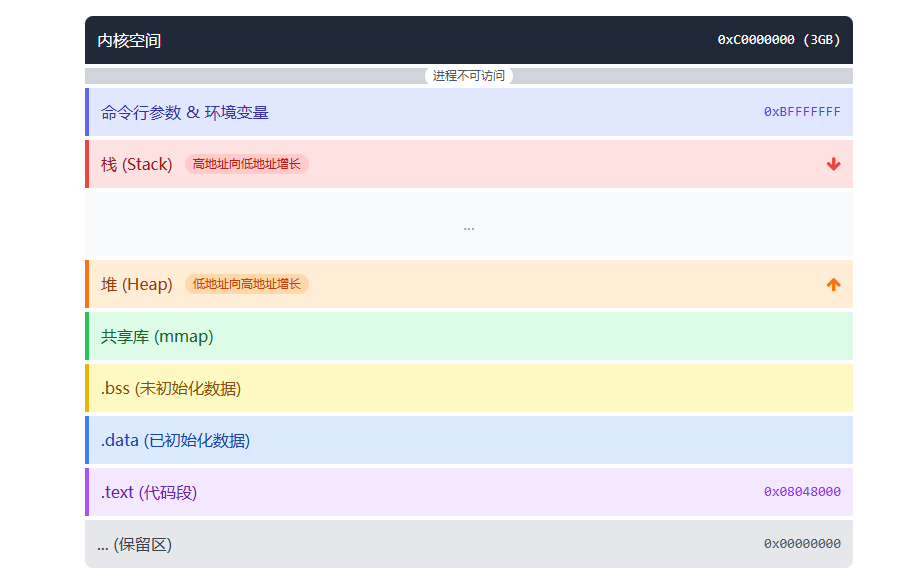
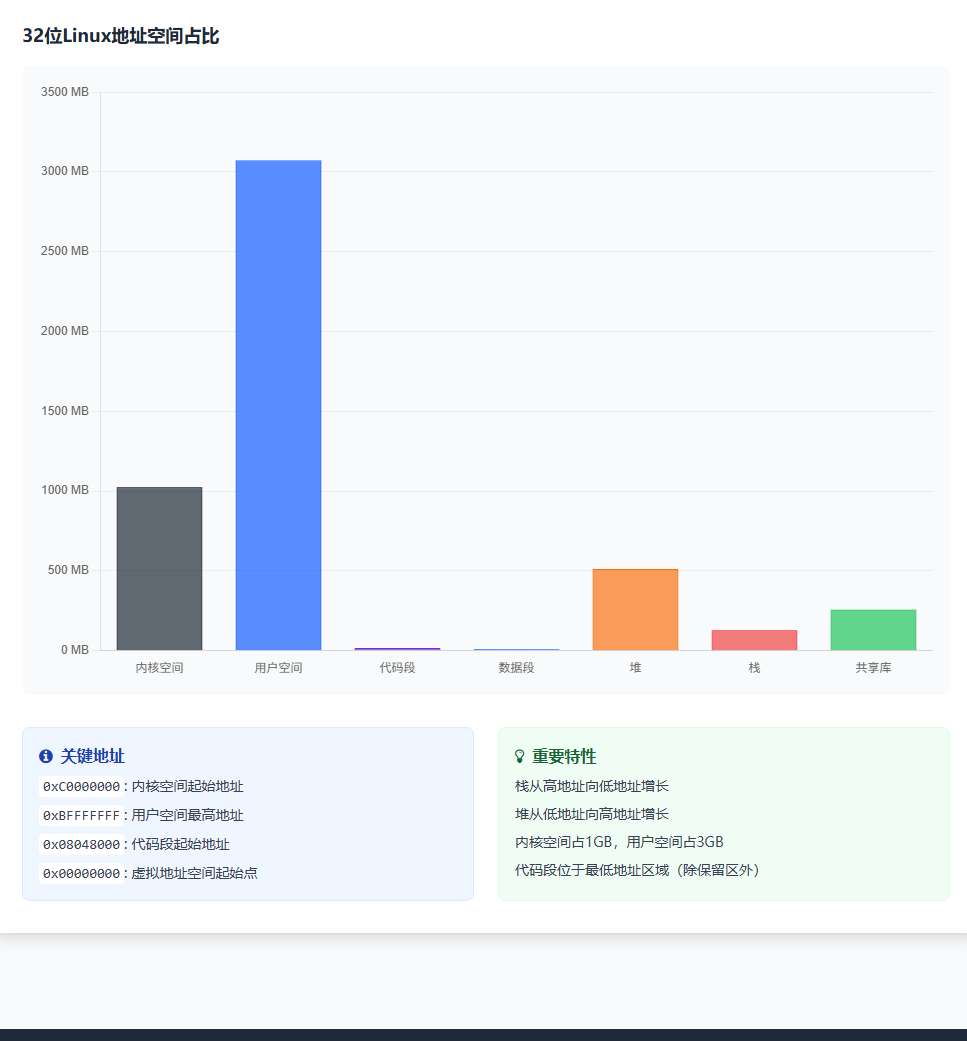
四、三层解析:从虚拟到物理的 "翻译" 过程
当进程执行 movl $100, 0x601040 这条指令时,背后发生了什么?
4.1 第一层:CPU 发出虚拟地址
CPU 执行指令,将虚拟地址 0x601040 发送给 MMU (内存管理单元)。
4.2 第二层:MMU 查询页表
MMU 是一个硬件单元,它负责 "翻译" 地址。它会自动查询由内核维护的页表。
- 页表:存储了虚拟页号到物理页号的映射关系。
- MMU 在页表中查找
0x601040所在的虚拟页对应的物理页。
4.3 第三层:访问物理内存或触发缺页中断
-
情况 A:映射有效
MMU 找到了有效的物理页,计算出最终的物理地址,然后访问物理内存。整个过程对进程透明。
-
情况 B:映射无效 (缺页中断)
如果页表中没有该虚拟地址的映射,或者权限不足(例如,试图写入只读的代码段),MMU 会触发一个缺页中断 (Page Fault),将控制权交给内核。
内核接手后,会判断中断原因:
- 非法访问 :权限错误或地址越界。内核会发送
SIGSEGV信号,进程崩溃(Segmentation Fault)。 - 合法但未分配 :这块内存是合法的(例如,第一次写入堆区),但内核尚未为其分配物理内存。此时,内核会:
a. 分配一页物理内存。
b. 更新页表,建立映射关系。
c. 返回用户态,让 MMU 重新执行刚才失败的指令。
- 非法访问 :权限错误或地址越界。内核会发送
写时拷贝 (Copy-on-Write) 的实现
现在我们可以完美解释开头的实验了:
-
fork()时,内核为子进程创建独立的mm_struct和页表,但页表内容复制自父进程 。同时,内核将父子共享的页面标记为只读 。
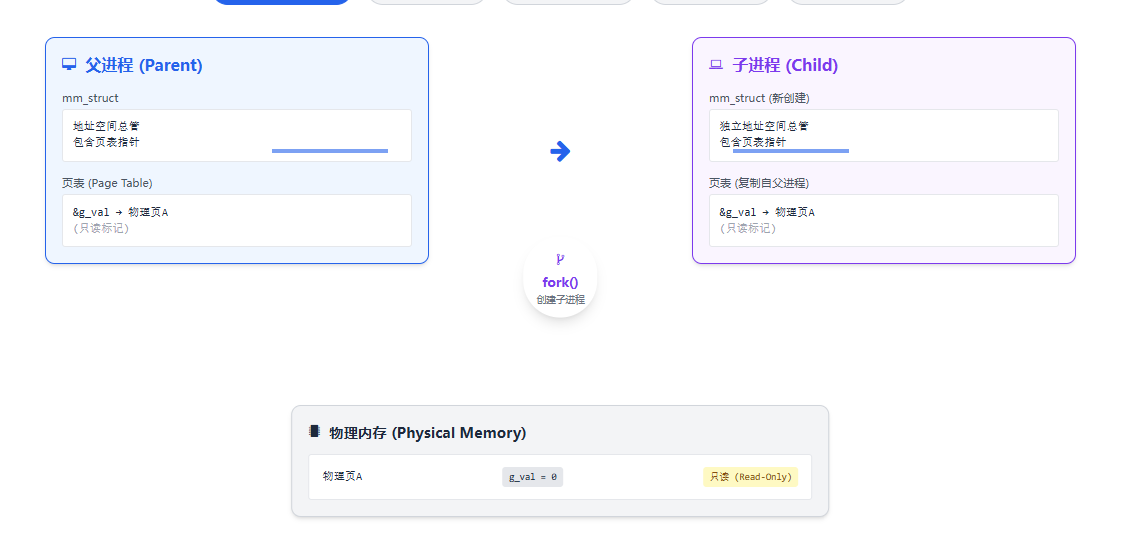
-
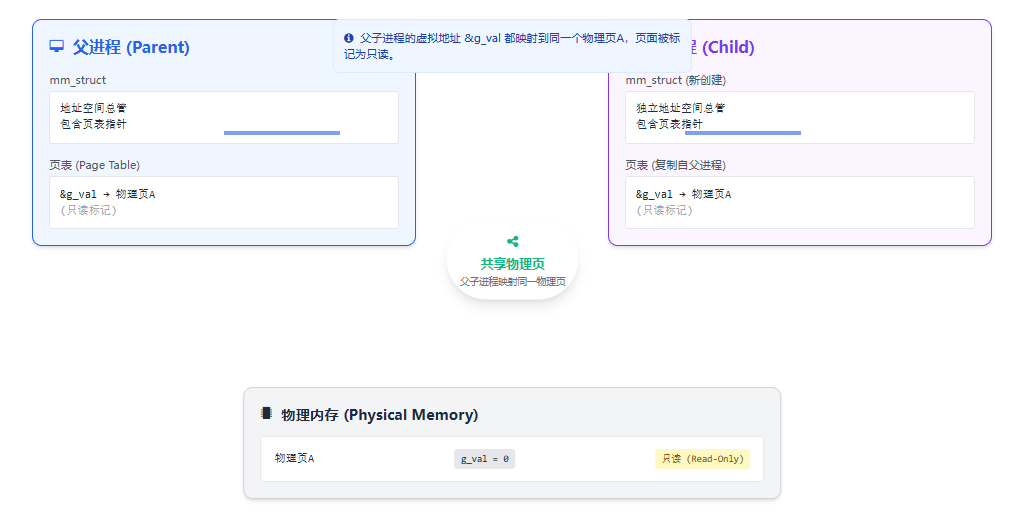
此时,父子进程的虚拟地址
&g_val都映射到同一个物理页 。
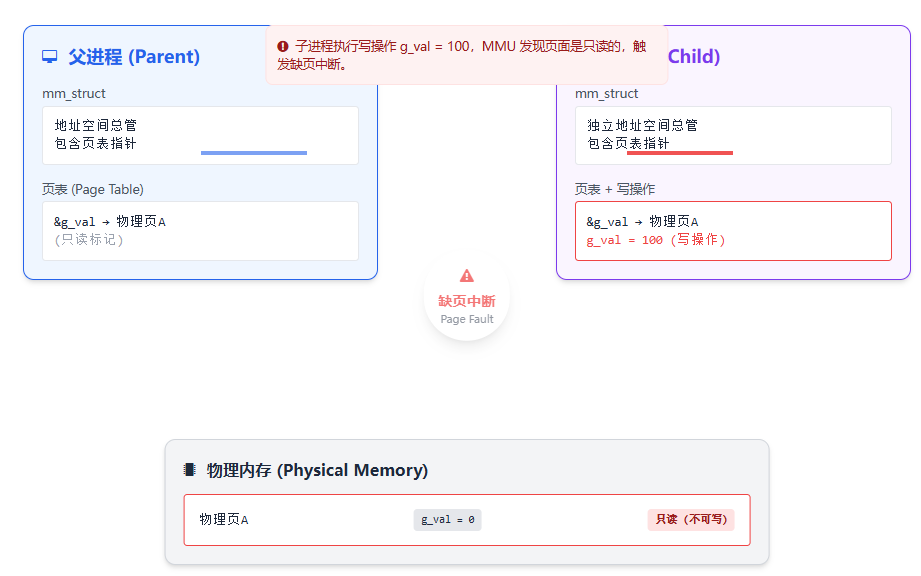
-
当子进程执行
g_val = 100(写操作)时,MMU 发现页面是只读的,触发缺页中断 。
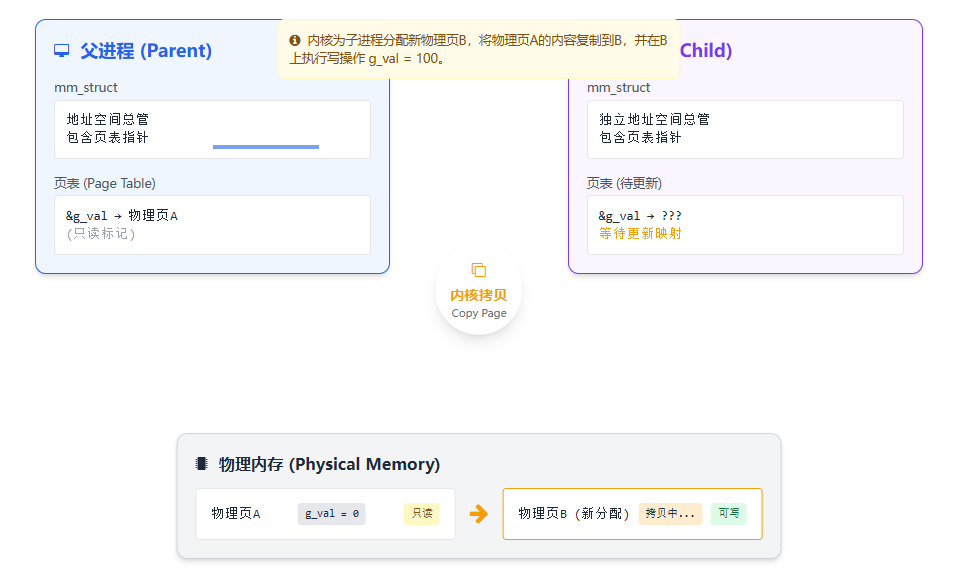
-
内核捕获中断,发现是合法的 "写时拷贝" 请求,于是:
a. 为子进程分配一个新的物理页。
b. 将旧物理页的内容复制到新页。
c. 在新页上执行写操作 (
g_val = 100)。d. 更新子进程的页表 ,将其
&g_val映射到这个新的物理页 ,并标记为可写。
-
父进程的页表不受任何影响 ,仍然指向旧的物理页。
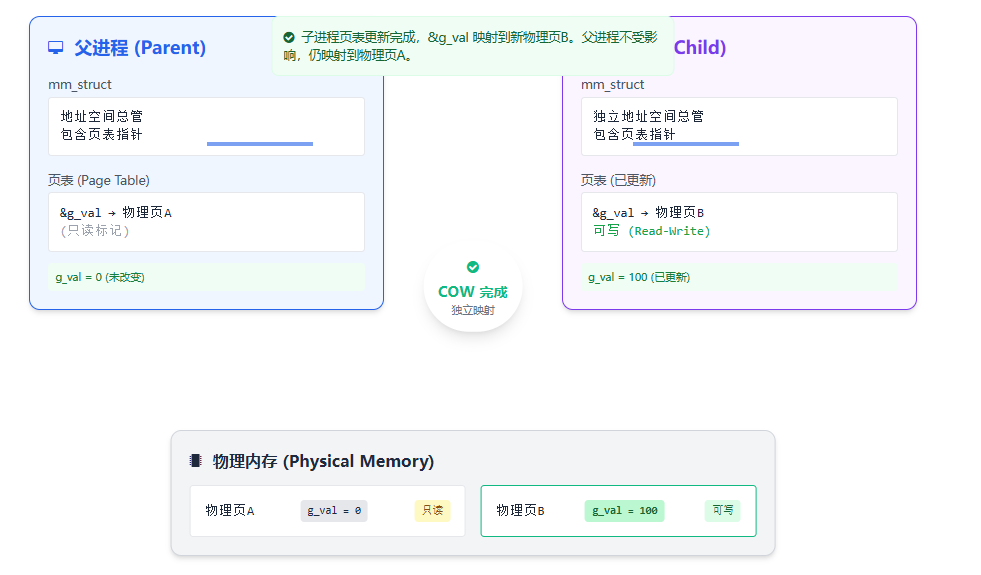
最终,父子进程的虚拟地址相同,但映射的物理地址不同,实现了数据的隔离。

五、为何需要虚拟地址空间?三大核心价值
直接操作物理内存简单粗暴,但会带来灾难。虚拟地址空间解决了三大核心问题:
-
安全与隔离 (Security)
每个进程都在自己的 "包间" 里活动,无法窥探或篡改其他进程的内存。页表和硬件权限检查(读/写/执行)构成了坚固的防火墙,任何越界访问都会被内核终结。
-
简化与抽象 (Simplicity)
它为程序员提供了一个连续、规整 的内存视图。
malloc申请一大块连续内存时,无需关心物理内存是否碎片化,内核会在后台处理好复杂的映射关系。这极大地降低了编程的复杂度。 -
灵活与高效 (Flexibility)
虚拟地址空间将 "程序如何使用内存" 与 "物理内存如何管理" 解耦。内核可以采用延迟分配(按需分配) 、内存共享(如共享库)等多种优化策略,以最高效的方式利用宝贵的物理内存。
六、系列总结:进程世界的宏伟蓝图
至此,我们的《Linux 进程深度解析》系列也迎来了尾声。让我们一同回顾这段探索之旅,将所有知识点串联成一幅宏伟的进程世界蓝图。
-
诞生与描述 (第一篇) :我们从
task_struct出发,理解了进程是"被管理和调度的基本单位"。我们学会了使用/proc和ps命令来窥探进程的内部状态,如同拥有了查看角色属性的"神之眼"。 -
状态与变迁 (第二篇) :我们厘清了进程从创建到消亡的完整生命周期(R、S、D、T、Z、X),并深入探讨了
fork的奥秘,以及僵尸进程与孤儿进程这对"难兄难弟"的成因与解决方案。 -
调度与回收 (第三篇) :我们揭开了 CFS 调度算法的公平性原则,学会了使用
nice、renice调整进程优先级。更重要的是,我们掌握了wait和waitpid,学会了如何作为一名合格的"父进程",优雅地为子进程"收尸",避免资源泄漏。 -
环境与继承 (第四篇) :我们明白了环境变量是进程的"环境 DNA",通过
export和写时复制机制,父进程得以将自己的"世界观"安全地传递给子进程,确保了环境的一致性与隔离性。 -
内存与隔离 (本篇) :今天,我们揭开了虚拟地址空间的终极秘密。它是一个精妙的"谎言",通过
mm_struct、页表和 MMU 的协同工作,为每个进程构建了一个独立、安全、简洁的内存王国,实现了三大核心价值:隔离、简化、高效。
从一个 fork 调用开始,到一个独立的虚拟内存空间结束,我们完整地走过了 Linux 进程从无到有、从生到死、从交互到隔离的全过程。希望这个系列能为你打下坚实的进程理论基础,让你在未来的开发与运维工作中,面对任何与进程相关的问题时,都能做到心中有数,游刃有余。
Linux 的世界博大精深,进程只是其中的一个篇章。愿你永葆好奇,继续探索!