文章目录
LLM
概念
大语言模型LLM( Large Language Model)是基于深度学习构建的自然语言处理工具,通过在海量的文本数据进行训练,能够理解和生成人类语言。
大语言模型的应用广泛,LLM可以用于文本生成,可以生成连贯的段落、文章、对话等,因此可应用于自动写作、机器翻译等实际任务,在问答场景中,它能够应对复杂问题的解答,甚至支持对话式交互,在语义处理领域,它可实现情感倾向分析、命名实体识别、文本类别划分等推理类任务。除此之外,智能助手交互、机器人对话系统、文本自动摘要、关键信息提取等场景,也能借助大语言模型提升效率。总之,大语言模型在自然语言处理及人工智能领域展现出巨大价值,有望为人机交互带来更智能、更贴近自然的体验。
调用过程
调用大语言模型是指通过API接口等途径,向模型发送处理请求并获取其生成的文本或运算结果,这一过程通常包含以下几部分:
- 准备输入:编写需要模型处理的文本信息或具体问题。
- 发起请求:通过 API 将输入内容传递给大语言模型。
- 获取结果:接收模型生成的文本回复或任务处理结果。
结果输出
输出分为流式输出以及非流式输出
流式输出
流式输出是指LLM在生成内容时,并非等全部内容完成后再返回,而是在生成过程中逐步输出部分结果。其主要特点包括:
- 用户能够实时查看模型生成的内容片段,从而缩短感知上的等待时长。
- 适用于需要生成较长文本或处理耗时较长的场景,能有效优化用户体验。
- 技术实现难度较高,一般需要依赖支持流式传输的应用程序接口或开发框架。
示例
python
model = ChatOpenAI(
model='glm-4-0520',
temperature=0.6,
api_key='自己的API_KEY',
base_url='https://open.bigmodel.cn/api/paas/v4/',
streaming=True, # 启用流式输出
callbacks=[StreamingStdOutCallbackHandler()] #流式回调处理器
)
messages = [
SystemMessage(content='你是一个真诚的助手'),
HumanMessage(content='你为什么要欺骗人类呢?')
]
print("答:", end="")
response = model.invoke(messages)
非流式输出
非流式输出是指LLM在完整处理完用户请求后,将生成的响应内容一次性返回,它的主要特点如下:
- 用户需等到模型彻底生成所有结果后,才能查看完整输出。
- 技术实现较为简单,适用于生成内容较短或模型响应速度较快的场景。
- 若需要生成的内容篇幅较长,用户可能会感受到较为明显的等待延迟。
示例
python
model = ChatOpenAI(
model='glm-4-0520',
temperature=0.6,
api_key='自己的API_KEY',
base_url='https://open.bigmodel.cn/api/paas/v4/',
streaming=False,
)
messages = [
SystemMessage(content='你是一个真诚的助手'),
HumanMessage(content='你会欺骗人类吗?')
]
print("答:", end="")
response = model.invoke(messages)
print(response.content)
LLM调用方式
使用OpenAI的API
实现代码如下
python
# 调用智谱GLM模型
from openai import OpenAI
# 初始化OpenAI客户端,指向智谱API
client = OpenAI(
api_key='自己的API_KEY',
base_url='https://open.bigmodel.cn/api/paas/v4/'
)
response = client.chat.completions.create(
model='glm-4-0520',
messages=[{'role': 'user', 'content': 'LLM的幻觉问题怎么解决?'}],
stream=True # 启用流式输出
)
print("\n流式输出:")
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end='', flush=True)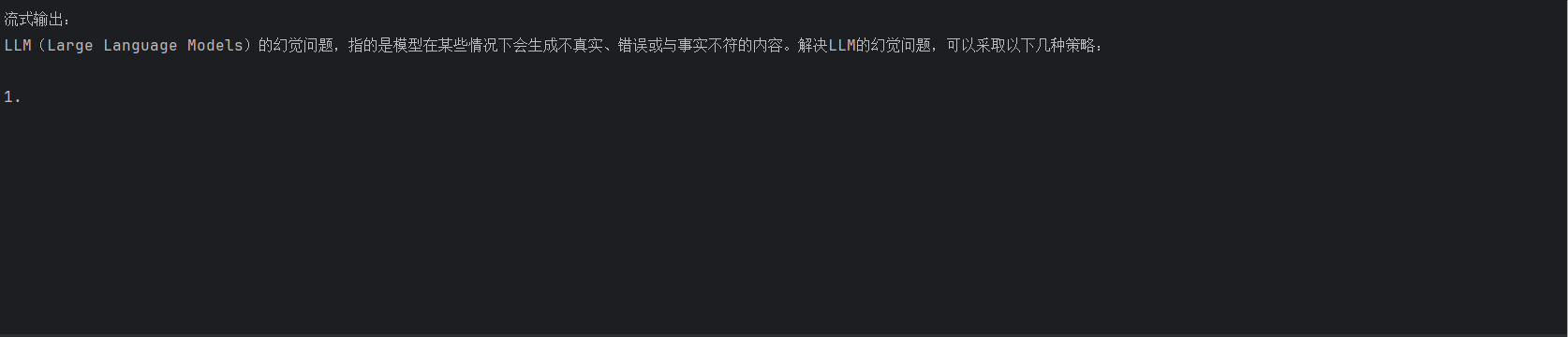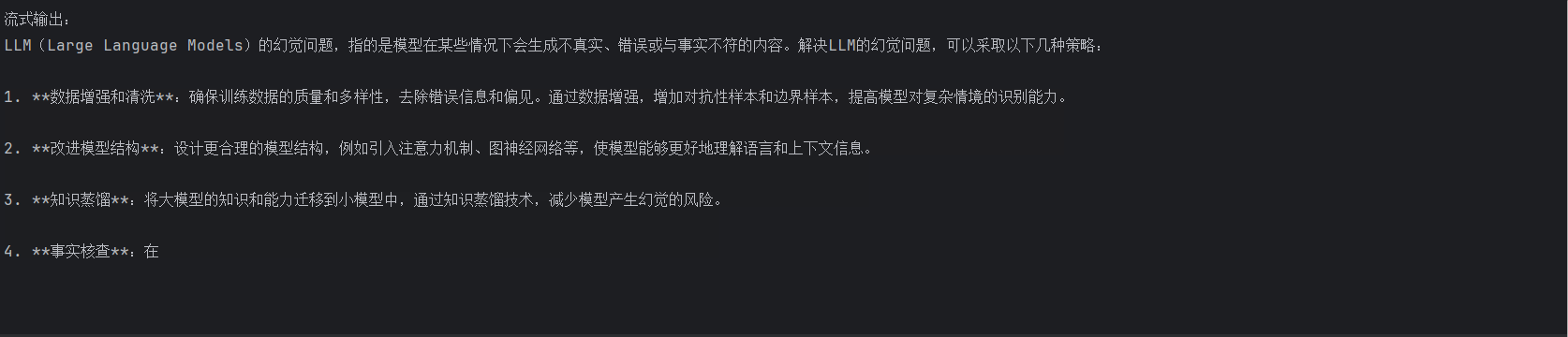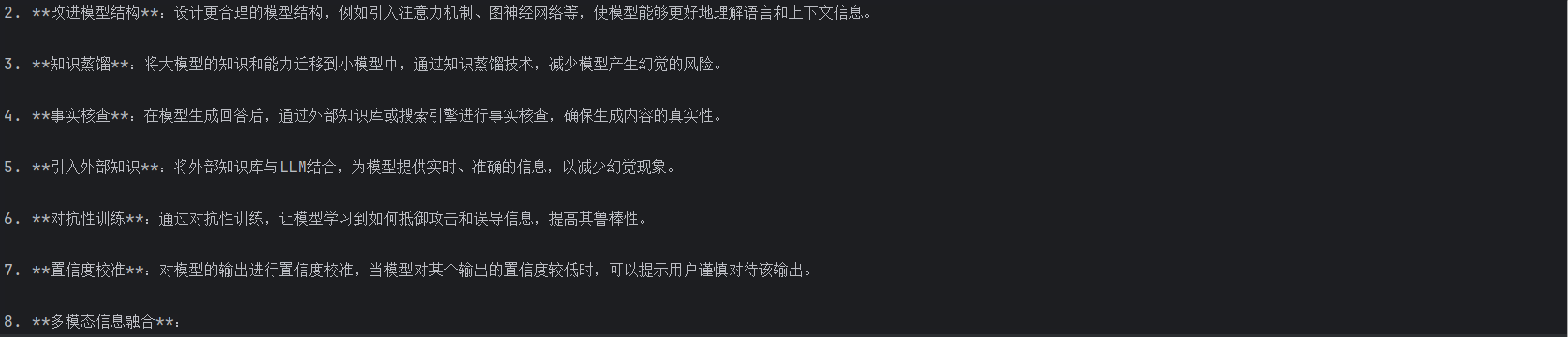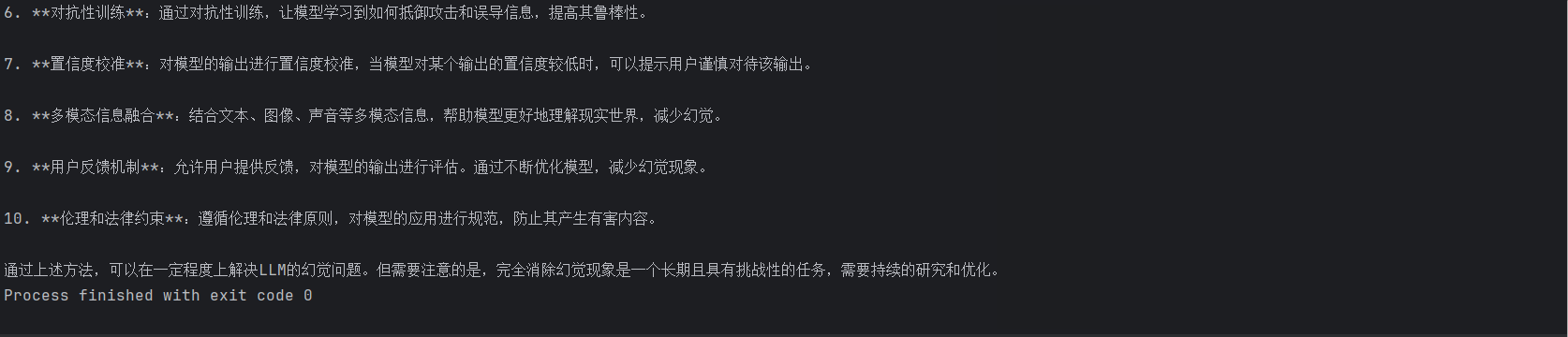
非流式输出版本
python
from openai import OpenAI
# 初始化OpenAI客户端,指向智谱API
client = OpenAI(
api_key='自己的API_KEY',
base_url='https://open.bigmodel.cn/api/paas/v4/'
)
# 非流式输出
response = client.chat.completions.create(
model='glm-4-0520', # 智谱模型名称
messages=[
{'role': 'user', 'content': 'LLM的幻觉问题怎么解决?'}
]
)
print("非流式输出结果:")
print(response.choices[0].message.content)
使用GLM的API
使用LLM之前需要在大模型的官网获取API_KEY和大模型的具体名称。
python
# 调用智谱GLM模型
from zhipuai import ZhipuAI
import os
api_key = os.getenv('API_KEY')
if not api_key:
api_key = '自己的API_KEY'
client = ZhipuAI(
api_key=api_key
responses = client.chat.completions.create(
model='glm-4-0520',
messages=[{'role': 'user', 'content': '介绍一下LLM以及应用'}],
stream=True
)
print("\n流式输出结果:")
for chunk in responses:
content = chunk.choices[0].delta.content
if content:
print(content, end='', flush=True) 
非流式输出
python
from zhipuai import ZhipuAI
import os
api_key = os.getenv('API_KEY')
if not api_key:
api_key = '自己的API_KEY'
client = ZhipuAI(
api_key=api_key
)
responses = client.chat.completions.create(
model='glm-4-0520', # 模型名称
messages=[
{'role': 'user', 'content': '介绍一下LLM以及应用'}
],
)
print("非流式输出结果:")
print(responses.choices[0].message.content)
LangChain调用GLM
LangChain是一个专为构建大型语言模型为核心的应用程序而设计的框架,它的核心目标是简化应用从开发阶段到生产部署整个生命周期的流程。
LangChain 能够整合 LLM 模型(例如对话模型、嵌入模型等)、向量数据库、交互层提示词(Prompt)、外部知识以及代理工具等,从而灵活构建 LLM 应用。LangChain 主要包含六个核心组件,具体如下:
-
模型输入 / 输出(Model I/O):作为与语言模型交互的接口,负责对输入和输出数据进行处理。
-
数据连接(Data Connection):用于与特定应用程序的数据进行交互的接口,保障数据流能够顺畅传输。
-
链(Chains):可将各个组件组合起来,实现端到端的应用,比如检索问答链,能够完成检索信息与回答问题的任务。
-
记忆(Memory):作用是在链的多次运行过程中,持久化保存应用程序的状态,保证上下文具有连贯性。
-
代理(Agents):扩展模型推理能力、执行复杂任务及流程的关键组件,代理可以整合外部信息源或 API,以此增强自身功能。
-
回调(Callbacks):用于扩展模型的推理能力,支持复杂应用的调用序列。
python
import os
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# 配置环境变量
os.environ['LANGCHAIN_TRACING_V3'] = "true"
os.environ["LANGCHAIN_API_KEY"] = '自己的API_KEY'
# 第一步:创建流式模型实例
model = ChatOpenAI(
model='glm-4-0520',
temperature=0.6,
api_key='自己的API_KEY',
base_url='https://open.bigmodel.cn/api/paas/v4/',
streaming=True, # 启用流式输出
callbacks=[StreamingStdOutCallbackHandler()] # 添加回调处理器
)
# 第二步:准备提示信息
messages = [
SystemMessage(content='你是一个真诚的助手'),
HumanMessage(content='我犯错了并且意识到错误了,你说怎么办?')
]
print("你是一个真诚的助手")
print("问:我犯错了并且意识到错误了,你说怎么办?")
# 第三步:直接调用模型
print("答:", end="")
response = model.invoke(messages)
非流式版本
python
import os
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
# 配置环境变量
os.environ['LANGCHAIN_TRACING_V3'] = "true"
os.environ["LANGCHAIN_API_KEY"] = '自己的API_KEY'
model = ChatOpenAI(
model='glm-4-0520',
temperature=0.6,
api_key='自己的API_KEY',
base_url='https://open.bigmodel.cn/api/paas/v4/'
)
messages = [
SystemMessage(content='你是一个真诚的助手'),
HumanMessage(content='我犯错并且知错了,可以原谅吗?')
]
print("你是一个真诚的助手")
print("问:我犯错并且知错了,可以原谅吗?")
print("答:", end="")
response = model.invoke(messages)
print(response.content)