前言
我们公司最近也开始搞 AI 落地了------下半年的技术规划里,AI 的接入和落地已经被正式列为重点方向。说真的,这股趋势谁也挡不住,现在不论是大厂小厂,几乎都在"卷 AI"。不搞点 AI 相关的项目,都不好意思说自己还在做研发。
拿我们公司举个例子,开发流程已经 AI 化了不少:代码合并前要走一遍大模型审查,写代码也基本都离不开 DeepSeek 或 GPT 的辅助。遇到啥奇奇怪怪的问题,第一反应不是百度,而是"问 AI 一下试试看"。
甚至连我朋友最近面试都开始被问:"你在工作中有用过 AI 吗?都用在哪些场景用到过?"这种问题现在已经从加分项变成了基本门槛。
大模型风口下,AI 应该怎么"真正用起来"?
不过话说回来,光靠 AI 帮忙写点代码、找找 bug,那我们这样算不算"真正用了 AI"呢?
如果我们除了用它写业务代码、调接口、查报错之外,还能让它去理解业务逻辑、解答内部问题,甚至代替客服处理咨询,那不就更厉害了吗?
其实现在不少公司已经开始往这个方向走了,尤其是一些对安全要求高、资料量大的企业,都会选择把大模型私有化部署 到内部系统里。
这样一来,既能用 AI 的能力,又能把数据掌握在自己手里,避免信息泄露的风险。
比如,有些公司内部有成千上万份技术文档、操作规范、历史方案,如果靠人培训一个新人,可能得好几周;但要是让 AI 来读懂这些内容,用户问一句"某某功能的配置流程怎么写",直接回答,效率不就上来了?
也有的企业客服要处理大量重复性问题,内容基本固定,但更新频率高,光靠人力维护 FAQ 成本太高。这时候用 AI 来做一个"能看懂我们内部资料的客服",就特别香。
那问题来了------
难不成我要自己整一个 DeepSeek?或者撸个自己的 MCP?
说实话,要是真能自己做出个 DeepSeek,那我都不打工了,直接融资去就完咯!
至于 MCP,我最近在掘金天天看,但是我是真没实际落地成功过 主要是感觉总是接触了一点皮毛就。MVP搞过但是意义不大。
那怎么办?我们公司也没给我这种平台,更不会给我几个月专门搞这个的时间。
那我总得自己搞点 AI 落地的"经验"出来吧?
不然以后面试又被问:"你工作中怎么用 AI 的?"
我堂堂十年开发,说一句"我会让 GPT 写 SQL"就完了?那不得被挂在白板上......
所以就算公司现在没这个需求,我们在摸鱼的时候也得自己先动手搞搞 多研究研究,不管能不能用上,起码咱玩过,以后也知道除了 ChatGPT 和 DeepSeek,还有 Ollama,还有 FastGPT,还有Dify 甚至咱还搭过一整套系统......
这不就不一样了吗?
以后聊起来也能自信的说:"俺们自己也搞过本地私有化部署,用过向量模型,搞过知识库问答系统。"
这逼格不就来了?
这算不算也是跟着 AI 大潮刷了一波存在感,谁说搞技术的不能主动点?
从小做起:先搭一个内部 AI 问答系统试试
既然没有公司级的平台,也没法腾出时间去研发一个完整的 MCP,那我们就从一个能落地的小项目开始,先做出个能跑、能用、能展示的东西再说。
我们的目标也不复杂:让 AI 能看懂我们自己的资料,还能回答我们团队的问题。最好满足以下几个条件:
- 支持本地部署,数据不出公司,安全合规;
- 能基于文档做语义检索,问一句就能理解我想找什么;
- 搭建成本不要太高,普通服务器或者一台本地机器能跑就行;
- 最好还能接入大语言模型,支持自然语言对话,体验接近聊天。
那我们就可以有两个非常合适的工具组合:
- Ollama:可以在本地运行各种开源大模型,部署非常简单,一条命令就能跑;
- FastGPT:一个开源问答系统,自带文档上传、向量检索、模型调用,前后端一体,界面也挺简洁好用。
用这套方案,我们可以来搭了一个内部 AI 问答系统:不用联网就能使用,还能接入我们自己的文档数据,实际效果比预期的要好很多。
啥是Ollama ?
Ollama 这玩意儿最近在技术圈挺火的,有些大佬已经玩得飞起了,但也有不少人一脸问号:这是个啥?能吃吗?
一句话介绍它------Ollama 是一个让我们在本地用一条命令就能跑大模型的神器。
没听错,真的就一条命令:
bash
ollama run qwen:7b然后它就会帮我们搞定模型下载、加载、推理服务启动,甚至还顺手给我们开个本地 API 接口,方便我们接前端、搞对话系统、做插件什么的,简直是"懒人福音"。
对比那些要手动拉 GGUF、编译 llama.cpp、调一堆推理参数的做法,Ollama 就像是我们开发路上的外卖小哥------我们来下单,它送达,模型直接热腾腾地跑起来。
重点是:本地部署、离线运行、隐私数据全掌控,谁用谁知道。
这里我就不展开详细介绍了,不了解的同学可以去官网看看:ollama.com/ ,或者直接去掘金搜 "Ollama" 相关的文章,有些大佬讲得非常细,适合入门 + 深挖。
FastGPT 是什么?是不是 ChatGPT 的极速版?
说实话,在我第一次接触FastGPT之前,我对 FastGPT 的第一印象是:"这是不是 ChatGPT 的魔改版?还是啥极速套壳客户端?"
毕竟名字太容易让人联想到 ChatGPT,结果一看------完全不是那么回事。
FastGPT 是一个开源的企业级 AI 知识库问答系统,本质上是帮我们把"ChatGPT 式的对话能力"接入我们自己的数据和文档里。
它做了几件很实用的事:
- 自带前后端界面,部署完就能用,不需要我们再写页面;
- 内置向量检索 + 文档管理系统,上传 PDF、Word、txt 都能自动分段索引;
- 可以配置多个模型源,比如我们用 OpenAI 的 GPT-4,也可以接 Ollama 本地模型;
- 支持多轮对话、消息记录、上下文管理,还能做聊天机器人、API 对接;
- 甚至还能配置知识库同步、文件定时刷新,对接企业场景非常友好。
和它比较像的还有一个项目叫 Dify ,很多人也在用。Dify 更偏向"AI 应用开发平台",提供工作流、角色设定、插件扩展等能力,适合做更复杂的 AI Copilot 系统。而 FastGPT 就是那种"我们只想搭个问答系统,那就直接给我们一个能跑的成品" ,上手更快、思路更聚焦。
对我这种想先搞个 Demo 的人来说,FastGPT 简直就是"RAG(检索增强生成)场景的低门槛快车道"。
不过这里我也不展开细讲了,想了解更多的可以去看看 FastGPT 的 GitHub(doc.fastgpt.io/docs/introd...),或者去掘金搜一搜,有很多实战分享文章。
环境准备:安装 Ollama(以 Mac 为例)
在开始搭建之前,我们先把大模型运行平台------Ollama 安装好。
Ollama 支持 macOS、Windows 以及部分 Linux 发行版的本地运行,安装过程也非常简单。下面以 macOS 为例,提供几种常用的安装方式:
方式一:通过 Homebrew 安装(比较推荐)
如果我们本地已经安装了 Homebrew,可以直接执行以下命令即可完成安装:
bash
brew install ollama安装完成后,我们可以前往 Ollama 官网,点击右上角的 "Models" 页面,查看目前支持的开源大模型列表,比如 Qwen(千问)、LLaMA3、Mistral、Gemma 等。

每个模型下方都会列出对应的安装命令,直接复制粘贴到终端就能使用,非常方便。
在模型选择上,Ollama 支持的开源模型非常多,以我们这次用的 Qwen 系列为例,版本从轻量的 0.5b 到巨型的 72b、110b,甚至还有一个"看起来就不适合打工人"的 235b。不同版本在体积、性能、响应速度上的差异非常明显。
完整的模型列表可以在 Ollama 官网的 Qwen3 模型页面 查看,像下面这样:
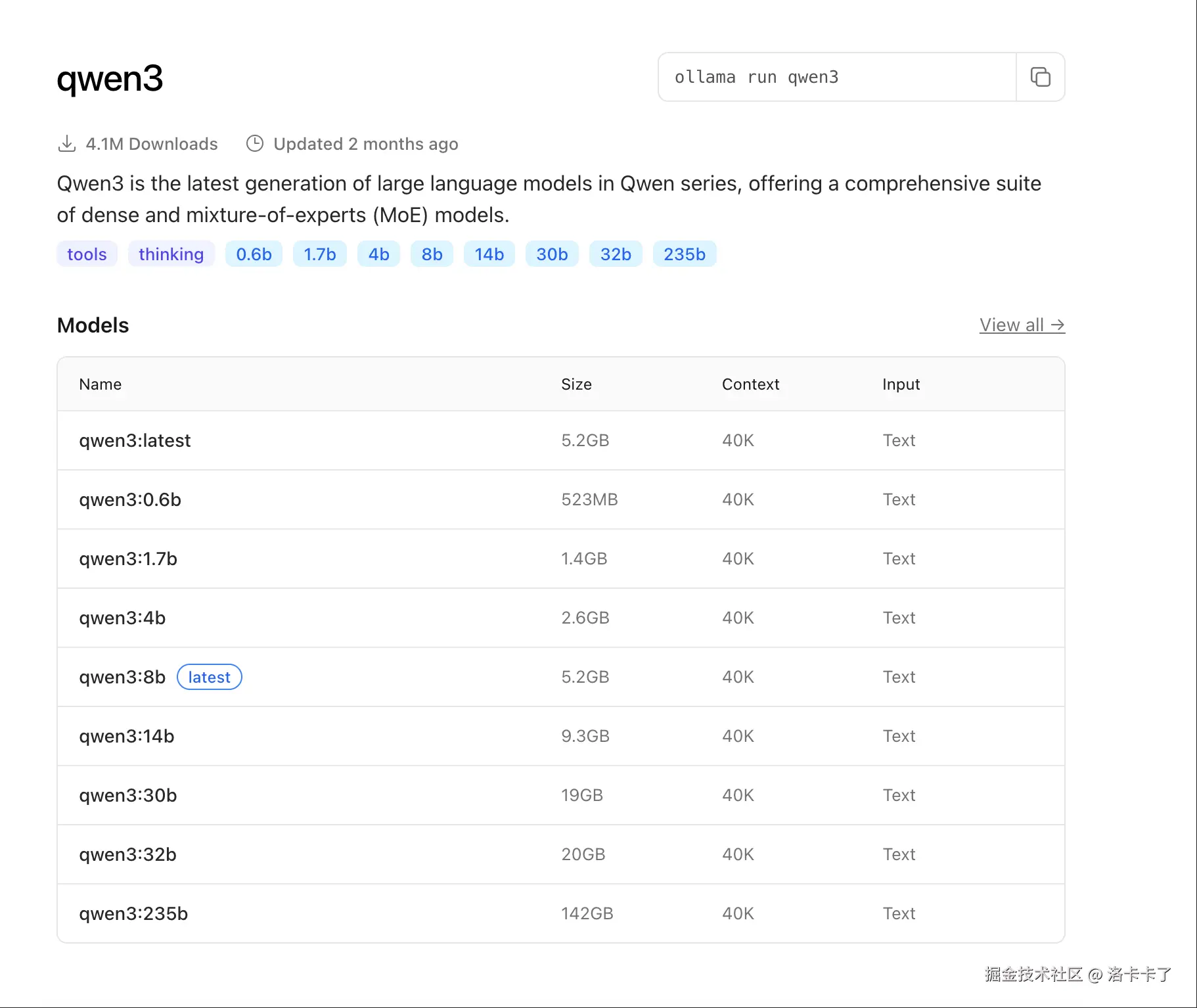
我们这次选择的是:
bash
ollama run qwen3:1.7b原因也比较简单:
- 模型够轻量,只有 1.4GB,下载和加载速度都很快;
- 上下文窗口 40K,不管是问答还是处理长文档都足够用了;
- 本地 MacBook 就能顺畅跑,不需要额外配置 GPU 环境;
- 响应速度快,结合 FastGPT 做问答体验非常流畅。
如果我们只是想先验证功能或者做原型测试,不建议一上来就用 14b、30b、235b 这些大家伙,光模型体积就几十个 G,部署和运行门槛也更高。而 1.7b 就是个比较理想的"起步选手",体验好、资源占用低、开发友好。
不过如果我们想让 AI 不只是"能说会道",还要"读得懂自己的文档",那光有一个主模型还不够。我们还需要再加一个模型,专门用来做文档的向量化处理------也就是所谓的嵌入模型。
简单来说,它的作用就是:把我们上传的 PDF、Word、Markdown 这些文档切成一段一段的,然后转换成"向量"(也就是一堆模型能理解的数字),这样后续在问问题时,系统就能用语义相似度匹配到我们说的那段内容。
我这次用的是:
bash
ollama run nomic-embed-text这是一个比较常见的开源嵌入模型,支持中英文混合,速度快、资源占用小,社区使用率也比较高。FastGPT 默认也推荐使用它来做文档向量化,接起来基本零障碍。
一句话总结它的作用就是:不负责说话,专门负责"读资料"并建索引。
完整的嵌入模型列表可以在 Ollama 官网的 nomic-embed-text 模型页面 查看,其中会列出模型简介、用途说明以及对应的运行命令,像这样:
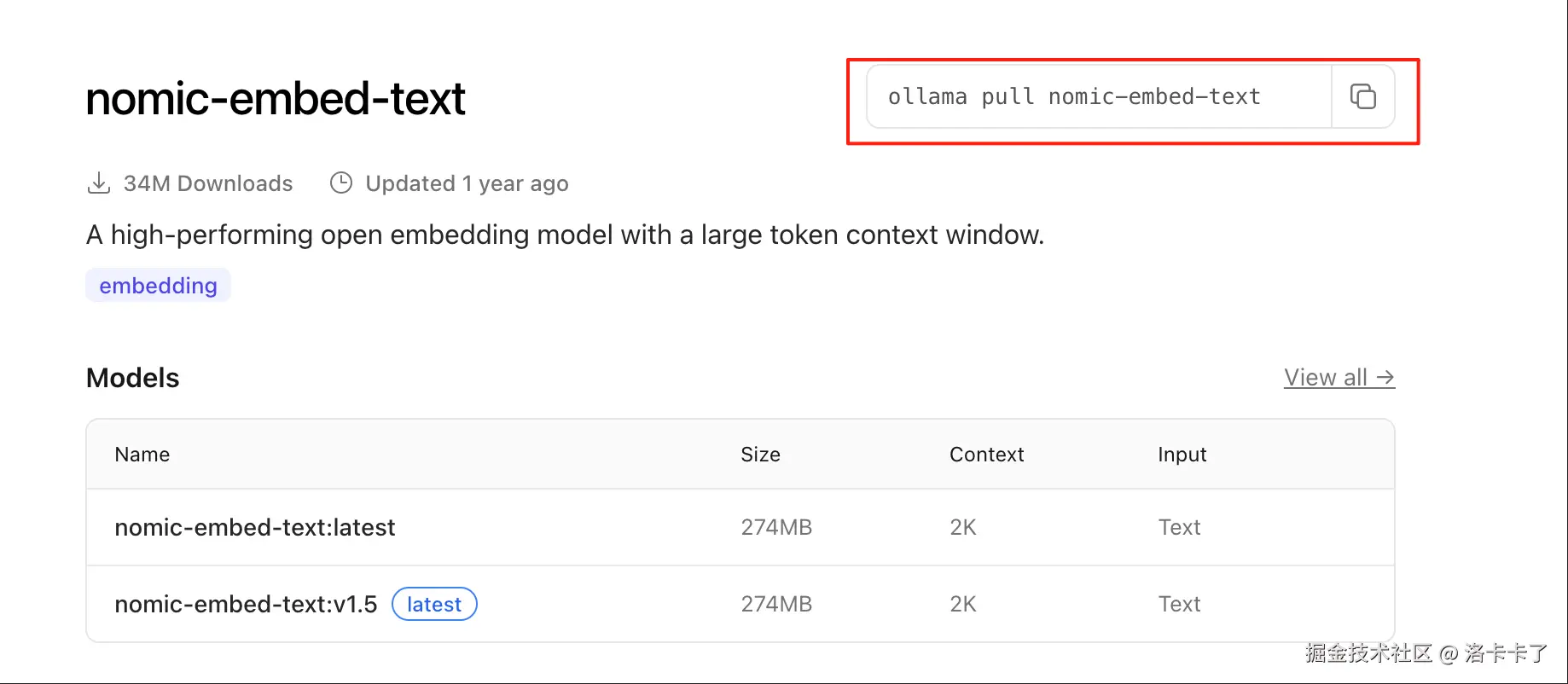
两者配合,才构成了一个完整的"知识库问答系统"。
方式二:从官网下载安装包
如果我们不使用 Homebrew,也可以直接前往 Ollama 官方网站下载安装程序:
官网会自动识别我们的操作系统并提供对应版本的安装包。安装完成后,同样可以通过终端运行上面的命令进行测试。
方式三:使用 Docker 安装(适合服务器或容器环境)
如果我们希望将 Ollama 跑在服务器上,或者已经习惯用 Docker 来部署服务,也可以通过官方提供的 Docker 镜像进行安装:
bash
docker run -d -p 11434:11434 ollama/ollama然后我们就可以像本地一样使用:
bash
curl http://localhost:11434/api/tags或者通过 FastGPT 这样的系统接入 Ollama 的本地推理服务。
注意:如果我们希望在 Docker 里使用模型,比如
qwen3:1.7b或nomic-embed-text,可以先进入容器内部执行ollama run xxx,模型数据会保存在容器中,也可以用挂载方式做持久化。
无论哪种方式,只要我们能成功运行 ollama run xxx 并看到模型加载输出日志,就说明 Ollama 环境已准备就绪,接下来就可以接入我们的问答系统了。
快速启动 Ollama 并加载模型(以 qwen3:1.7b 为例)
下面我们通过几步就可以跑通 Ollama,并进入大模型对话模式。
步骤 1:运行命令
在终端中执行以下命令:
bash
ollama run qwen3:1.7b第一次运行时会自动做几件事:
- 从 Ollama 官方仓库拉取
qwen3:1.7b模型文件(约 1.4GB) - 下载完成后自动加载模型并进入对话模式

步骤 2:开始对话
当我们看到终端输出中出现类似:
python-repl
>>>就表示模型已经启动成功,现在我们可以直接和它对话,比如输入:
python-repl
>>> 你好,帮我解释一下什么是面向对象?模型会在 1~2 秒内返回结果,默认是中文交流,体验跟 ChatGPT 非常类似。

步骤 3:退出对话(可选)
如果我们要退出对话,可以按下 Ctrl + d,终止当前模型运行。
查看已安装模型
我们可以通过以下命令查看本地所有已下载的模型:
bash
ollama list
部署 FastGPT:从模型能力到可视化问答系统的关键一步
到这一步,我们已经成功在本地运行了 Ollama,并且可以直接在命令行里和大模型对话了。
虽然听起来已经挺"黑科技"的,但现实问题是------我们总不能让同事们每次提问都打开终端、敲命令吧?
想象一下产品经理问个"XX功能流程是啥",我们还得发个文档教他先装 Brew、跑 Ollama,然后敲 >>> 才能对话,这也太反人类了。
所以,我们需要一个更友好的方式,把大模型的能力用一个可视化页面封装起来,最好还能让它看懂公司自己的资料,变成一个"懂业务的 AI 客服"。
这个时候,就轮到我们今天的主角登场了------FastGPT。
我们已经有了 Ollama 提供的大模型能力,接下来就是把它"包一层壳"------也就是部署一个带前端界面的问答系统,让团队成员不需要敲命令行也能直接提问。
FastGPT 正好就是干这个的,它是一个开源的知识库问答系统,界面简单直观,支持上传文档、调用本地模型、构建私有知识库,非常适合企业内部部署使用。
部署方式选择:本地建议使用 Docker Compose
考虑到我们是本地开发或轻量测试环境,官方推荐使用 docker-compose-pgvector 版本进行快速部署。
这种方式最大的优点就是:
- 快速启动,所有服务一键拉起;
- 无需手动配置数据库或模型服务,适合个人或小团队验证;
- 对系统影响小,删除也干净。
环境准备:确保已安装 Docker 和 Docker Compose
在开始部署之前,建议我们环境确保本地已安装以下环境:
- Docker Desktop(或 Linux 下的 Docker CE)
- Docker Compose(版本建议 v2.17 及以上)
可以通过以下命令确认版本:
bash
docker --version
docker compose version如果有同学尚未安装,可以先前往 Docker 官网 下载并根据操作系统完成安装哈。
准备工作做完后我们就可以按如下步骤操作:
-
本地新建一个目录,例如:
bashmkdir fastgpt && cd fastgpt -
下载所需配置文件:
我们需要准备两个文件:
config.json:FastGPT 的默认配置docker-compose.yml:用于一键启动服务的容器编排文件
可以有两种方式获取它们:
方式一:手动下载
直接进入 GitHub 仓库,点击右上角的下载按钮或复制内容保存即可:
FastGPT config.json地址


方式二:命令行下载(推荐)
如果我们比较习惯终端操作,那我们就可以直接使用 curl 一键下载:
bash
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
# pgvector 版本(测试推荐,简单快捷)
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-pgvector.yml
# oceanbase 版本(需要将init.sql和docker-compose.yml放在同一个文件夹,方便挂载)
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-oceanbase/docker-compose.yml
# curl -o init.sql https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-oceanbase/init.sql
# milvus 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-milvus.yml
# zilliz 版本
# curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/deploy/docker/docker-compose-zilliz.yml修改配置文件:设置后端访问地址
在下载完 config.json 之后,我们还需要修改其中的一个关键字段:mcpServerProxyEndpoint。
这个字段用于指定 前端访问后端服务(MCP Server)的地址,默认情况下它指向的是一个公网接口地址。但如果我们是在本地部署 FastGPT,就需要手动把它改成我们本地能访问的地址。
打开 config.json 文件,找到这一行:
json
"mcpServerProxyEndpoint": "" // mcp server 代理地址,例如: http://localhost:3005将其修改为:
json
"mcpServerProxyEndpoint": "http://localhost:3005"这样配置后,FastGPT 前端界面就会通过 localhost:3005 来调用后端 API,而这个端口号正是我们在 docker-compose.yml 中默认映射出来的 MCP 服务端口。
如果我们是部署在远程服务器上,比如内网测试机或云服务器,那么就要把 localhost 改成对应的 IP 或域名(确保能从浏览器访问得到)。
启动 FastGPT 容器服务
完成配置后,就可以启动整个 FastGPT 系统了。
我们需要在 docker-compose.yml 所在目录下执行以下命令:
bash
docker compose up -d这条命令会后台启动所有服务,包括:
- Web 前端页面
- 后端 API 服务(MCP Server)
- 数据库(PostgreSQL + pgvector)
- 文档向量处理服务



需要注意:
- 建议使用 Docker Compose v2.17 及以上版本,旧版本在解析新版 YAML 或执行自动挂载等功能时可能会出现问题。
- 启动完成后,可以通过以下命令查看服务状态:
bash
docker compose ps如果所有服务都显示为 Up,说明环境已经成功启动。
启动后,默认访问地址为:
arduino
http://localhost:3000打开浏览器输入这个地址,能看到 FastGPT 的界面,那我们就可以开始创建我们的第一个知识库了!
开始使用 FastGPT:登录、配置模型与创建知识库
访问 FastGPT
FastGPT 默认监听在 3000 端口,启动成功后我们可以通过浏览器访问:
arduino
http://localhost:3000
如果我们部署在服务器上,请确保已开放防火墙端口,并使用 服务器 IP:3000 的形式访问。
如果我们希望通过域名访问,可自行配置 Nginx 做反向代理。
首次访问时,系统会自动初始化一个管理员账号:
- 用户名 :
root - 密码 :默认为
1234(由docker-compose.yml中的环境变量DEFAULT_ROOT_PSW设置)
我们也可以自行修改 DEFAULT_ROOT_PSW 来自定义初始密码。
第一次启动过程中,可能会在日志中看到一条类似报错:
pgsql
MongoServerError: Unable to read from a snapshot due to pending collection catalog changes;这条日志信息可以忽略,不影响正常使用。
配置模型
我们登录进去之后,系统会发现你啥都没配,然后会很贴心(其实是很严厉)地提醒你:没有配置语言模型和索引模型,系统没法正常用。
这两个模型是 FastGPT 跑起来的"核心引擎",一个用来回答问题(大语言模型),一个用来理解文档内容(嵌入模型)。缺任何一个,问答功能都别想跑通。
正常情况下,系统会自动跳转到模型配置页面,指导你一步步添加模型。
如果它没跳(比如我第一次用的时候它就"装死"了),也别慌,我们可以手动点进去配置:
点击左侧菜单【账号】,选择【模型提供商】,再点击【模型配置】,然后右上角点【新增模型】按钮,并选择"语言模型",如下图:

先添加语言模型(比如我们跑的 qwen3:1.7b),填好模型名称、模型 ID 和其他配置,模型 ID 就是我们用 ollama run 时候的名字
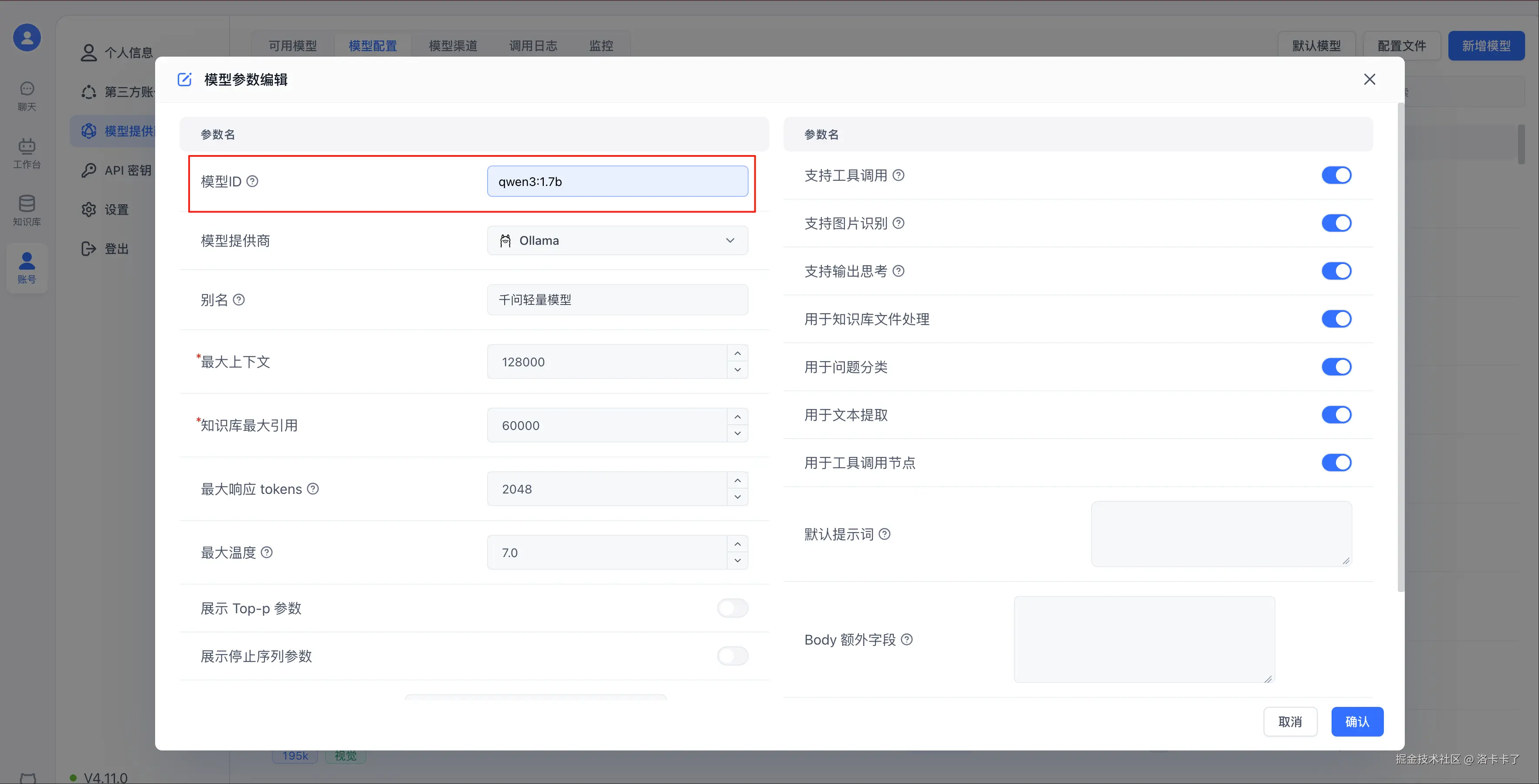
接着,再点一次右上角的【新增模型】,这次选择的是"索引模型"。配置方式跟刚才差不多,填上模型 ID、模型提供商等信息就行了。需要注意的是,模型 ID 要和我们在 Ollama 中安装的名称保持一致,否则连不上,如下图所示:

添加完这两种模型之后,我们可以回到模型列表中查看。把模型供应商切换为 Ollama,就能看到刚刚新增的两个模型(语言模型和索引模型)。确认它们都处于"启用"状态,后面知识库问答才能正常使用。

配置模型渠道
模型虽然添加完了,但还没算真正接入系统,我们还得配置一个"模型渠道" ,也就是告诉 FastGPT:用哪个模型来处理回答、用哪个来做向量索引。
这个配置就像是把模型"接上线",不然系统不知道该调哪个。
我们还是一样的,点进去:
左侧菜单【账号】 → 【模型提供商】 → 点击上方"模型渠道" → 然后右上角点【新增渠道】按钮,如下图:
在弹出的"渠道配置"窗口中填写如下内容:
| 字段 | 示例值 | 说明 |
|---|---|---|
| 渠道名 | 本地测试渠道 | 自定义,怎么顺眼怎么来 |
| 协议类型 | Ollama | 选择我们当前用的模型服务类型 |
| 模型(2个) | qwen3:1.7b, nomic-embed-text | 分别对应主模型和嵌入模型 |
| 代理地址 | http://host.docker.internal:11434 |
重点!详解见下方说明 |
| API 密钥 | 随便填一个,比如 sk-xxxx |
目前 FastGPT 接 Ollama 不校验,可留空或伪造 |
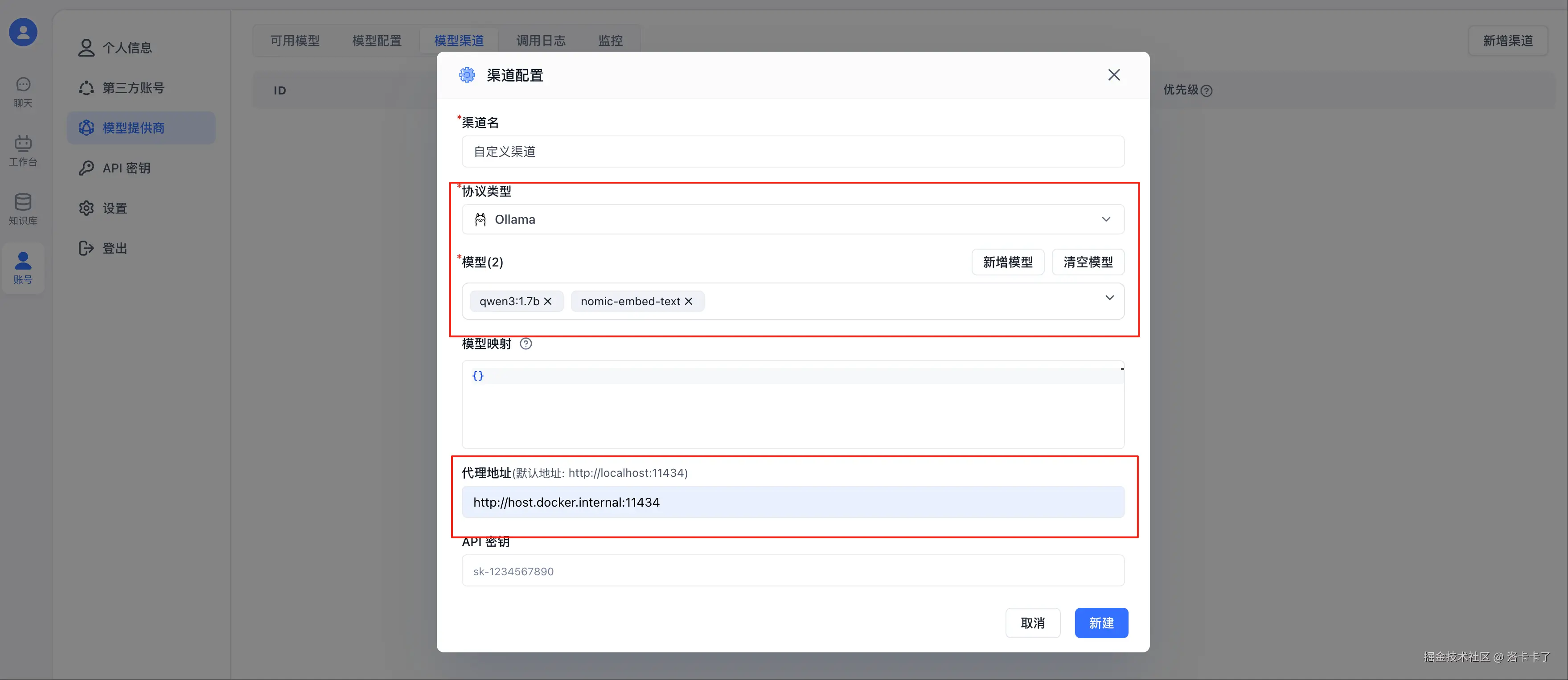
这里为什么不能填 localhost?
很多人第一反应会把代理地址写成:
arduino
http://localhost:11434结果模型死活调不通。为什么?
因为我们用的是 Docker 部署的 FastGPT,而容器里的 localhost 指的是容器自己,不是我们电脑。
所以如果我们填 localhost,FastGPT 会在它自己那个"密闭小房间"里找模型,自然找不到。
正确姿势是填:
arduino
http://host.docker.internal:11434这是 Docker 提供的一个"容器内访问宿主机"的别名,相当于在容器里说:"去我外面那台机子上找模型"。
如果我们是 Linux 系统,这个地址可能无法直接用,我们可以改成我们的本机 IP 地址,例如:
cpp
http://192.168.1.100:11434测试模型
添加好模型渠道之后,咱们还得验证一下模型能不能正常用。
点击顶部导航栏的【模型渠道】,你会看到我们刚才配置的"自定义渠道"已经在列表里了:
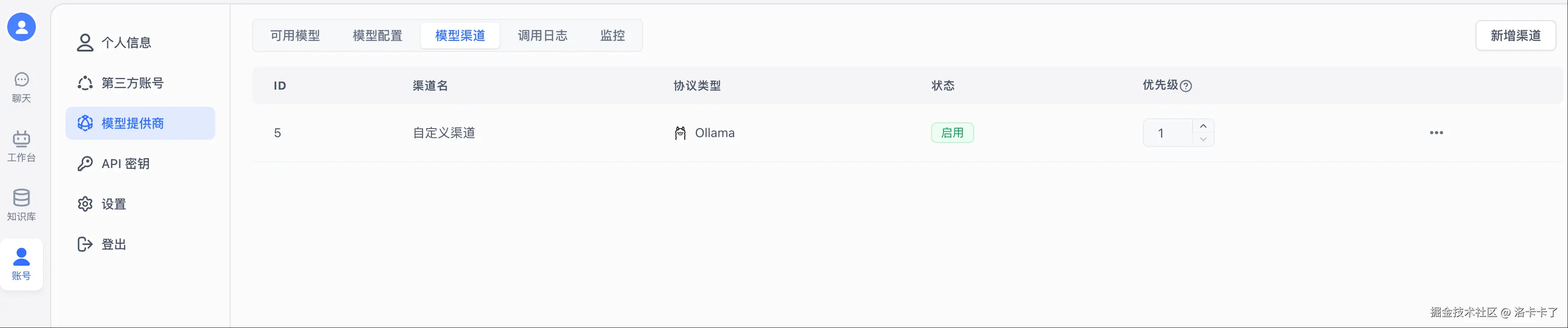
接着,点击右侧的 三个点 → 模型测试,就会进入如下页面:

在这里会列出我们配置的两个模型(语言模型 + 嵌入模型),此时状态是"等待测试"。
直接点击右下角的 "批量测试2个模型" 按钮,系统会自动对模型进行连通性检测。
如果一切正常,状态会从"等待测试"变为"测试通过" 如果失败了,建议检查代理地址是否填写正确(应该是
http://host.docker.internal:11434)或模型 ID 是否拼写一致。
测试通过之后,这一部分就算配置完成啦,后面就可以创建知识库了。

创建应用
进入 FastGPT 后台,点击左侧导航栏中的 【工作台】 → 【团队应用】 ,然后点击右上角的 【新建】 按钮。
这时候系统会弹出一个选项框,这里我们选择第一个------
简易应用:通过表单方式快速创建,适合新手,也足够满足我们当前"内部问答"场景。

如下图所示,选中【简易应用】即可开始配置:
这里我们随便输入一个应用名字并选择 【创建空白应用】
模型就选择我们之前添加的语言模型 ,然后右侧我们就可以输入我们需要提问的问题就可以了:

然后 我们可以点击右上角的保存并发布 接下来我们可以看下发布渠道这一栏的配置:
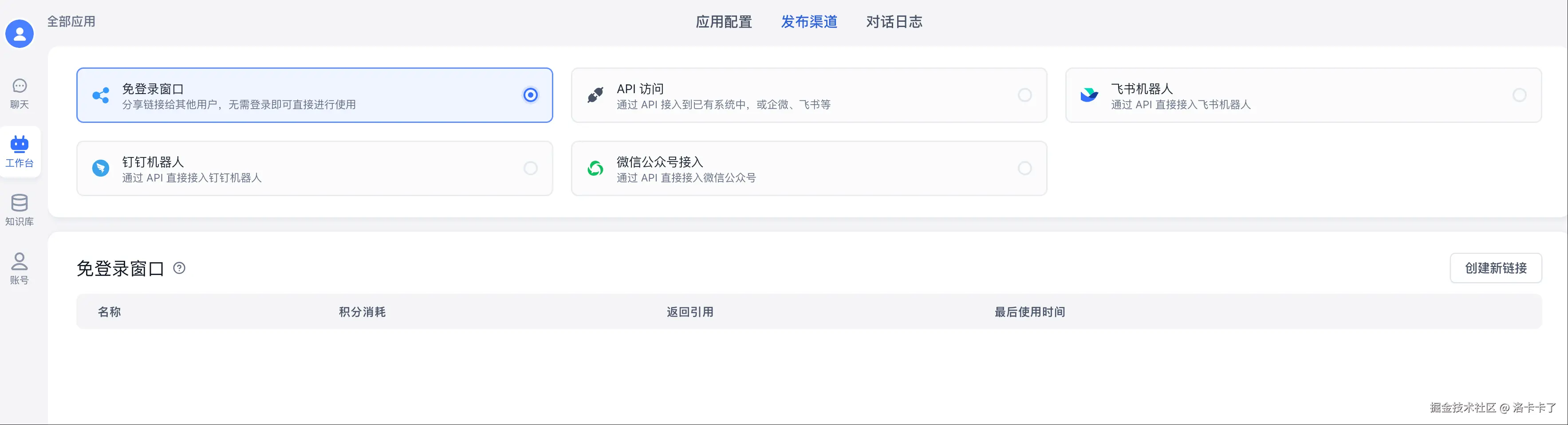
应用虽然建好了,但我们总不能自己一个人偷偷用吧。得把它"端出去",让别人也能访问、体验。
在 FastGPT 里,发布方式有好几种,看起来有点专业,但别怕,咱们一句话讲明白:
| 发布方式 | 是干嘛用的 |
|---|---|
| 免登录窗口(推荐) | 直接生成一个链接,发给别人就能用,不用登录账号,特别适合拉同事一起玩。 |
| API 接入 | 程序员用的,能把这个 AI 应用集成到你自己的系统里,比如后台管理、App 等。 |
| 钉钉 / 飞书机器人 | 适合企业用,在 IM 里就能问它话。 |
| 微信公众号接入 | 想给外部用户用,就可以用公众号这个入口。 |
这里我们测试可以选择 【免登陆窗口】 再点右边的【创建新链接】,就能生成一个访问地址啦!

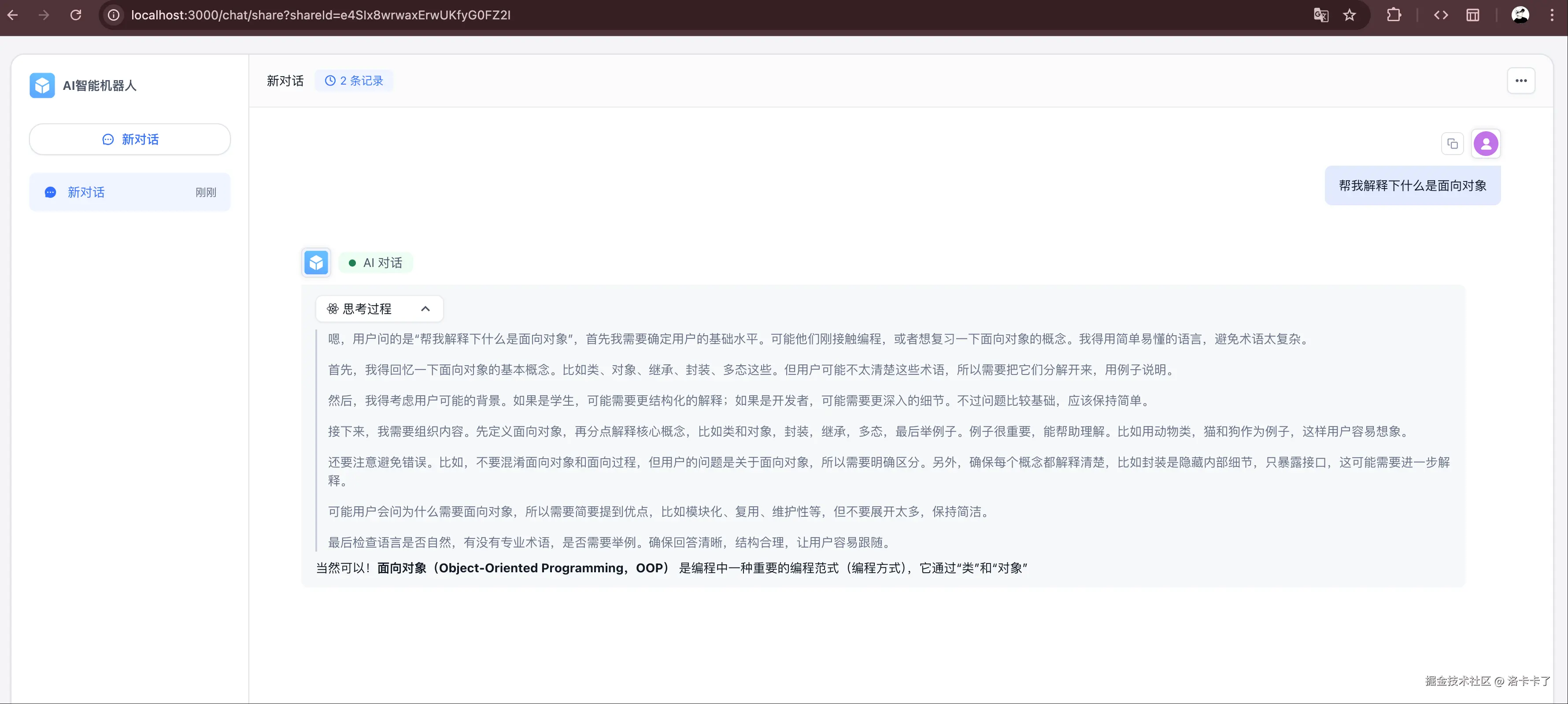
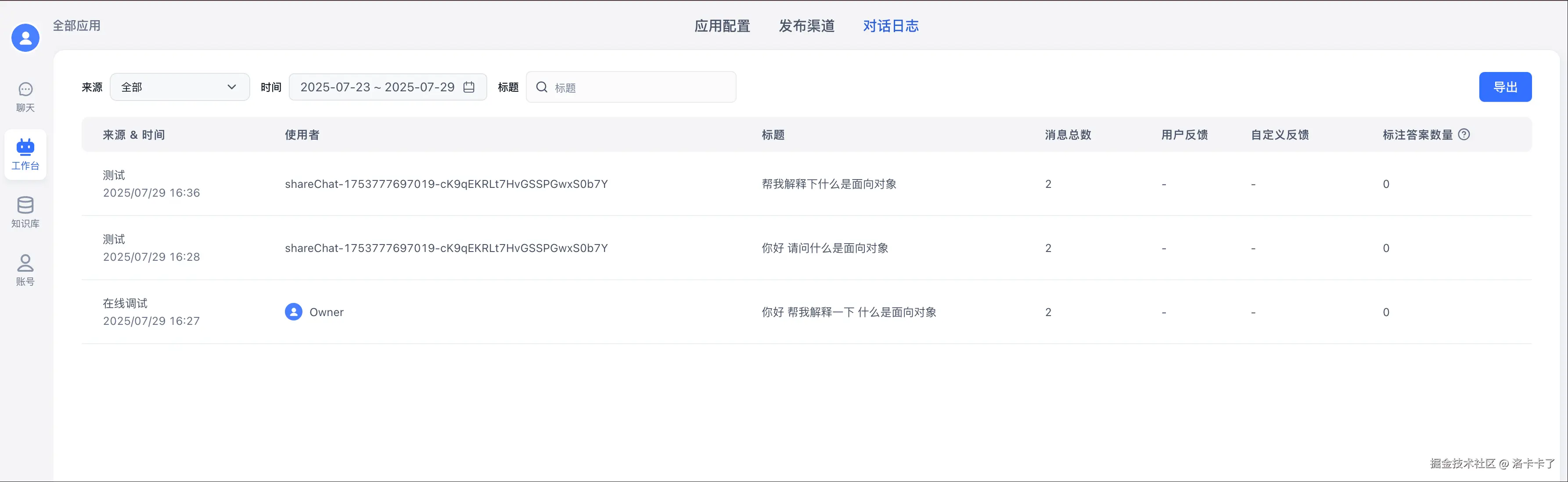
搞完发布之后,我们还可以点上方的 「对话日志」 标签页,来看看大家都和你的 AI 应用聊了些什么。
像上图这样,日志里会列出每一条对话的:
- 来源 & 时间:是谁问的,什么时候问的;
- 使用者 ID:比如通过分享链接进来的人;
- 问题内容:比如"什么是面向对象";
- 消息总数:用户跟 AI 聊了几轮;
- 反馈信息:有无点赞、踩或自定义反馈。
如果你是给公司或团队用的,这个功能特别实用------可以看看大家最常问的是什么、AI 有没有答偏、要不要优化下知识库。
右上角还可以点「导出」,把对话记录拉出来整理成表格或给老板看哈。
创建知识库
虽然我们前面已经成功创建了一个 AI 应用,但它现在其实就是个"空壳"------你问它啥,它可能一脸懵,啥也答不上来。
为什么?因为它还没接入任何知识内容,它哪知道我们公司的事、业务流程或者技术细节呀。
所以接下来我们要做的事情就是:
创建一个知识库,然后把这个知识库和我们刚刚的应用绑定起来。
这样用户在页面里提问时,系统就能去查这个知识库里的内容,再用大模型来帮你"组合语言",给出更准确的回答。
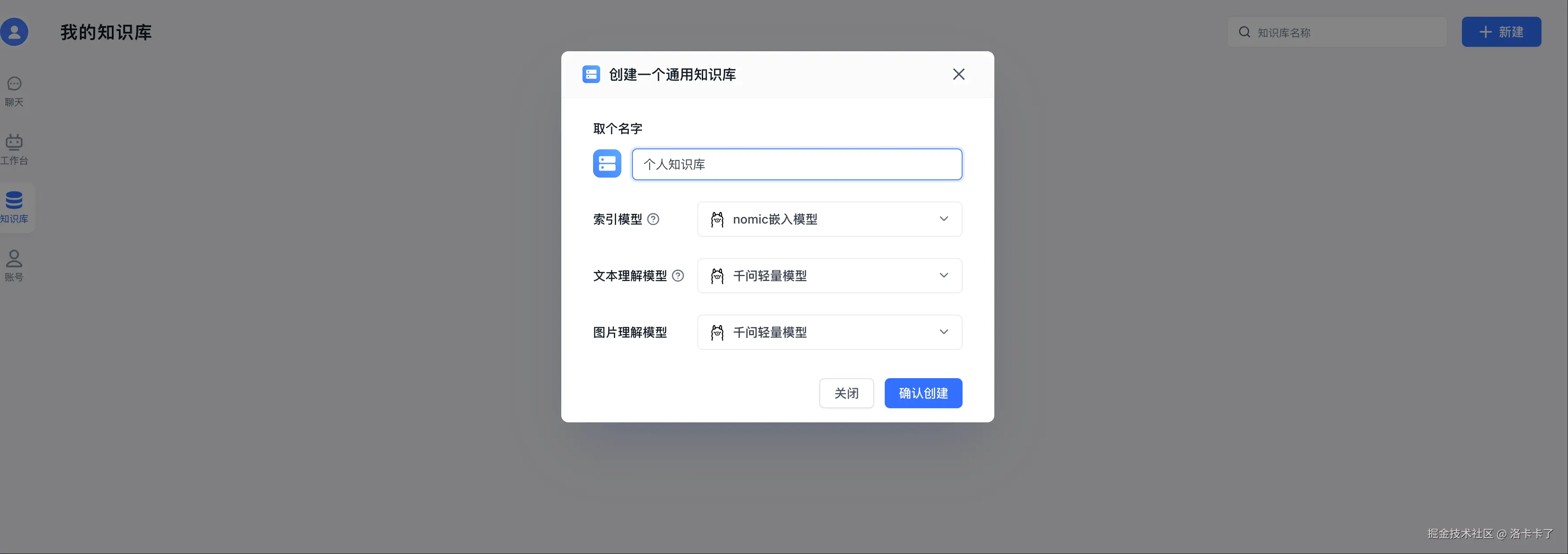
我们打开左边的菜单,点击「知识库」,然后点右上角的【新建】按钮,选择第一个「通用知识库」。

然后我们自定义一个知识库名字。索引模型和语言模型还是我们之前添加的那两个模型就可以:
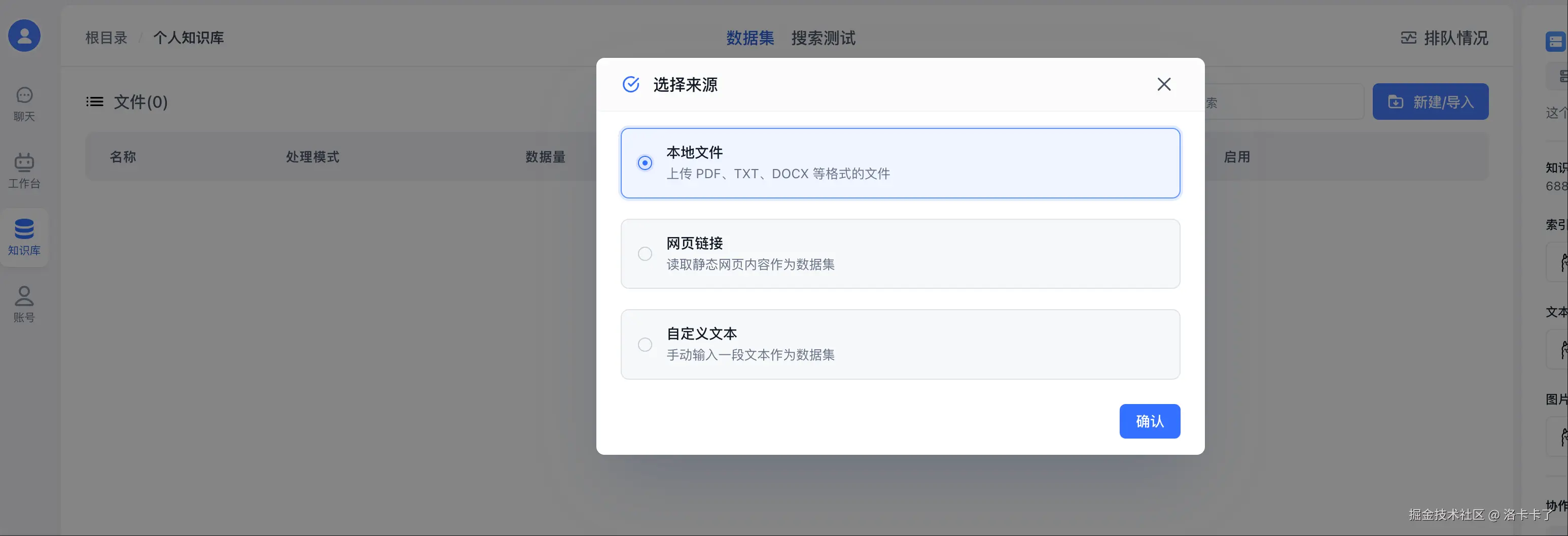
创建成功后 我们点击右上角 【新建/导入】 我们来上传文本数据集:

这里我选择一个我自己写的一个小说大纲文件:

这里选择合适的数据处理方式和参数。然后继续点击下一步:

点击左侧我们上传的文件,我们可以在右侧预览内容,然后继续点击下一步:

然后点击 开始上传

当状态显示为"已就绪"时,说明我们的知识库已经搭建成功了:


测试知识库
文档上传好了,那我们肯定得试试它到底有没有「记住」知识点。
这时候我们可以回到我们前面创建的 AI 应用(就那个"AI 智能机器人"),进行知识库关联:

选择我们刚才创建成功的知识库
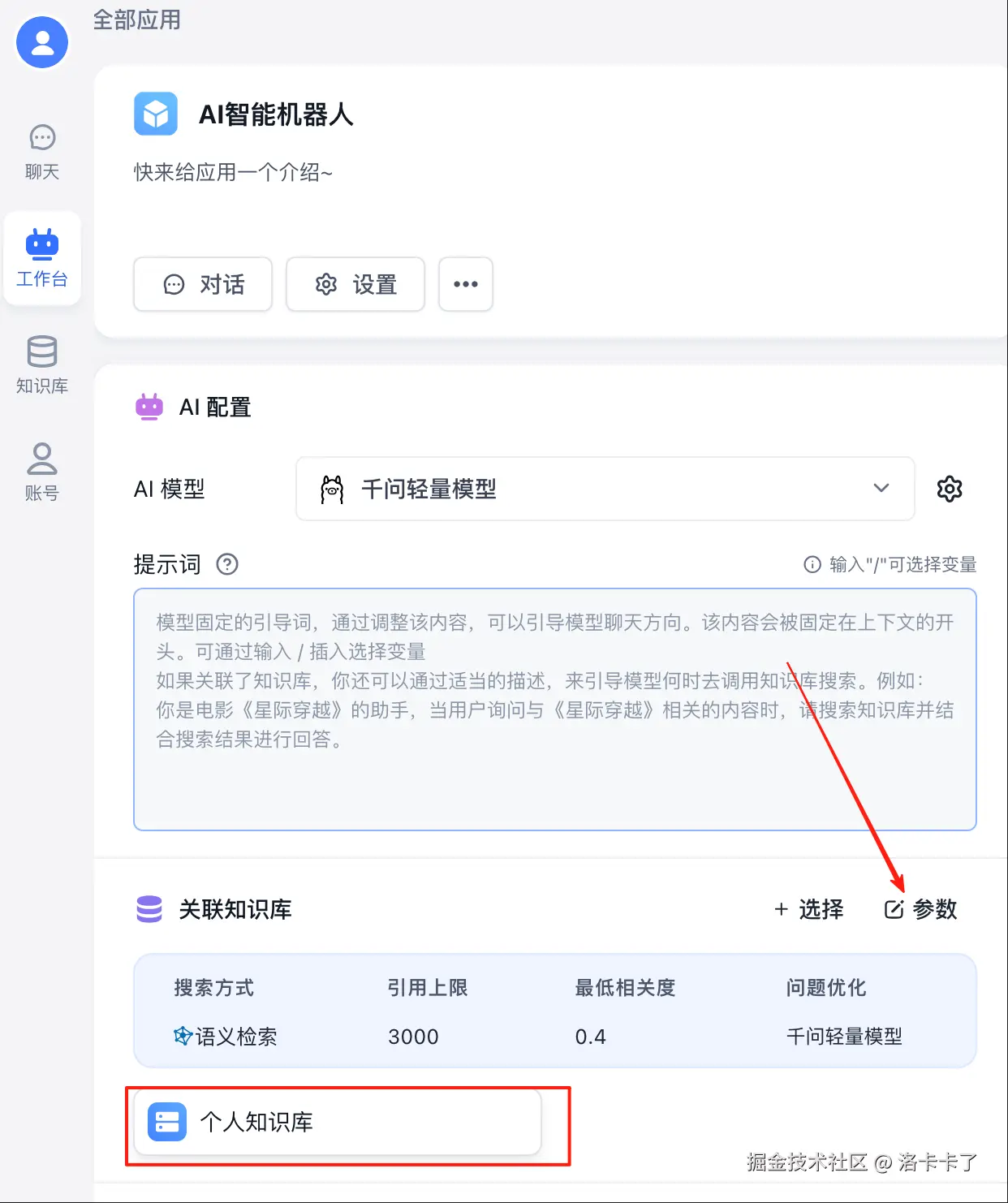
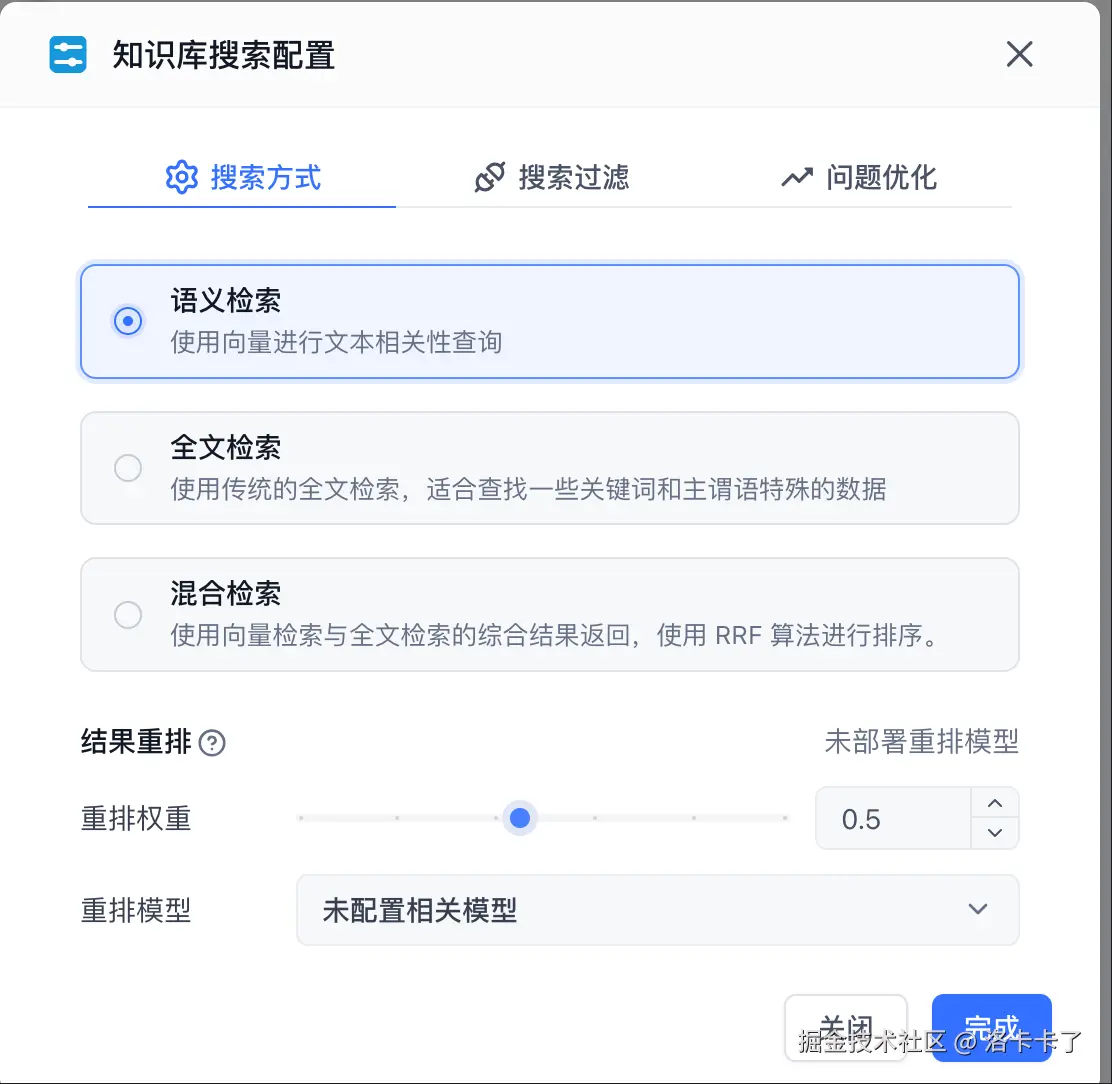
关联成功后 我们可以 进行以下参数配置:

然后接下来我们开始验证知识库是否应用到我们ai聊天中:比如我输入问题: "六煞图男二是谁?"

从上图我们可以看到,AI 在回答"六煞图男二是谁"这个问题时,给出了非常详细的思考过程 ,还标明了引用的知识库文档(六煞图大纲.docx) 。
同时,还展示了几个很实用的信息:
- 引用了 16 条内容
- 回答耗时 171 秒
- 提供了处理详情按钮,可以进一步查看知识命中情况
这就说明我们上传的 Word 文档确实被成功解析并纳入知识库中,AI 可以基于其中的内容进行回答------这一步就算打通啦!
最后
我们现在这样搞下来,其实就已经搭出来一个内部私有化部署 AI 的雏形了。
说白了,我们已经会自己搞一个"懂我们公司资料"的 AI 机器人了。
那以后如果公司真有这方面的需求,比如要做一个 AI 客服系统,或者一个智能问答系统,是不是就可以直接用这套方案来搭?
我们不但能做出来,而且还能做成我们公司自己的、私有化定制的版本。
而且这套还不局限于自己用,我们还能通过 API 接入飞书、企微、钉钉,甚至微信公众号,让公司内部的同事也能方便地使用,随时随地提问、查资料、自动回复......
这个体验,是不是立马就有"我们公司的专属 ChatGPT"那味了?
再说句实在话,这年头去面试,AI 几乎是必问项了。
要是面试官问你:"你平时工作中有用到 AI 吗?都用在哪些场景?"
我都可以直接回一句:
"我自己用 Ollama 和 FastGPT 搭过一套本地私有化的 AI 知识问答系统,能自动读公司文档,接入飞书做内部客服。"
卧槽。这不就直接拉满逼格了? 这不得立马录取!!!
你说这和"我平时让 ChatGPT 帮我写 SQL"听起来是不是完全不一个量级?
别的不说,能自己搭过一遍,起码面试的时候就不虚了嘎嘎😁。