在2025年Data+AI Summit上,Databricks发布了一系列重大更新,标志着企业数据治理进入新阶段。其中,Unity Catalog的增强功能和对Apache Iceberg的全面支持尤为引人注目。这些更新不仅强化了跨平台数据管理能力,还推动了开放数据生态的发展。本文将从技术演进、行业实践和未来趋势三个维度,分析这些创新如何重塑企业数据架构。
一、Unity Catalog:构建智能化的数据治理体系
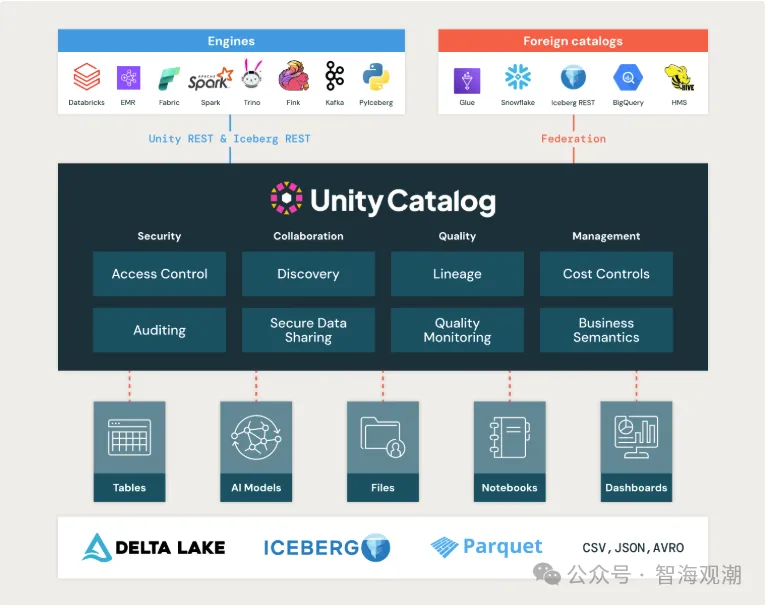
- 跨平台统一治理:打破数据孤岛
Databricks Unity Catalog的核心目标是实现跨云、跨平台的数据治理。2025年的升级重点包括:
第三方数据源集成:支持Snowflake、BigQuery、Redshift等系统的元数据同步,用户可在单一界面检索所有数据资产。
开放协议支持:通过OpenLineage实现与ETL、BI工具的血缘追踪,提升数据可观测性。
混合云适配:通过代理网关连接本地Hadoop集群,实现混合环境下的统一权限管理。
- AI与数据治理的深度融合
随着AI应用的普及,Unity Catalog新增了对机器学习模型和生成式AI的管理能力:
ML模型治理:记录模型训练数据来源、版本及部署状态,确保可追溯性。
生成式AI支持:提供提示词(Prompt)版本控制,避免LLM(如GPT-4o)的合规风险。
AI自动化分类:利用NLP技术自动识别敏感数据(如PII),提升分类效率。
- 性能优化与成本管理
智能分层存储:根据访问频率自动迁移冷数据至对象存储,提升查询性能。
统一计费看板:跨云成本监控与优化建议,帮助企业减少冗余开支。
二、Apache Iceberg支持:开放数据生态的关键一步
- 为什么选择Iceberg?
Apache Iceberg作为一种开放表格式,已成为数据湖仓的事实标准。Databricks的全面支持意味着:
读写兼容性:Iceberg可作为原生表格式,与Delta Lake并存,用户无需迁移即可使用。
性能优化:
向量化读取加速查询。
Z-Order聚类优化数据布局,TPC-DS基准测试性能提升20%。
跨引擎协作:支持Spark、Flink、Trino等计算引擎,避免厂商锁定。
- 企业落地价值
无缝迁移:提供Delta Lake到Iceberg的转换工具,降低迁移成本。
统一治理:Iceberg表可纳入Unity Catalog管理,继承其权限、审计和血缘追踪能力。
生态开放:企业可自由组合工具链(如Iceberg+Snowflake),提升灵活性。
- 对行业的影响
推动开放标准:减少对单一技术的依赖,促进数据生态多样化。
加速湖仓一体化:Iceberg的ACID特性使其成为湖仓架构的理想选择。
三、行业实践:数据治理的落地与未来趋势
- 行业核心洞察
实时数据治理:支持Kafka等流数据的元数据实时捕获,避免事后治理延迟。
行业模板:提供金融、医疗等领域的预置分类规则(如HIPAA、GDPR合规标签)。
未来方向:
Data Mesh支持:探索域(Domain)级别的联邦治理模式。
量子安全:研究抗量子加密算法保护元数据安全。
- 未来数据架构的三大趋势
统一化治理:Unity Catalog将成为跨平台数据管理的核心。
开放化生态:Iceberg等开放格式减少技术锁定,提升互操作性。
AI原生:从数据分类到模型管理,AI深度融入治理全流程。
Databricks 2025年的更新标志着数据治理进入新阶段:
技术层面:Unity Catalog与Apache Iceberg的结合,实现了"治理+开放"的双重优势。
业务层面:企业可更灵活地构建数据架构,同时满足合规与性能需求。
未来展望:随着Data Mesh、量子计算等技术的发展,数据治理将更加智能化、分布式化。
对于企业而言,现在正是重新评估数据治理策略的时机------拥抱开放生态,利用AI赋能,才能在数据驱动的未来保持竞争力。
参考资料:
https://www.databricks.com/blog/announcing-full-apache-iceberg-support-databricks
https://www.databricks.com/blog/whats-new-databricks-unity-catalog-data-ai-summit-2025