基础可以先看看:深度学习入门(1)
深度学习入门(2)(计算机视觉)
自然语言和用向量表示单词:基于计数的方法
-
自然语言 natural language
平常说话写作使用的语言
-
自然语言处理 NLP
让计算机理解人类语言的技术
-
同义词词典
将具有相同含义或者相似含义的单词归类到同一个组中,在NLP中用的同义词词典有时会定义单词之间的粒度更细的关系(层级结构关系等),形成一个单词网络
example:
-
WordNet
使用WordNet,可以获得单词的近义词,计算单词之间的相似度
-
-
基于计数的方法
-
语料库:用于自然语言处理研究和应用的文本数据
-
语料库预处理:corpus单词ID列表 word_to_id单词到ID的字典 id_to_word ID到单词的字典
-
单词的分布式表示(类似所有的颜色都可用RGB来表示一样)
-
分布式假设:某个单词的含义由它周围的单词形成
-
基于计数/统计的方法:对某个单词的周围出现了多少次什么单词进行计数,然后再汇总
-
共现矩阵:汇总了所有单词的上下文其他单词出现的次数
-
如何测量单词的向量表示的相似度:余弦相似度
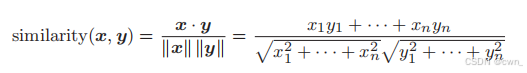
-
-
改进:
-
点互信息 PMI:PMI↑ 相关性↑
-
P(x): 单词x在语料库出现的概率
C(x): 单词x在语料库出现的次数
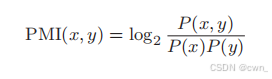
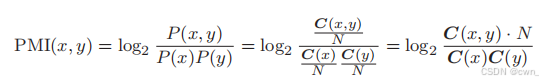
正的点互信息 PPMI:
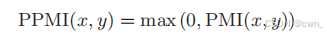
-
-
降维:尽量保留重要信息的基础上减少向量维度
-
奇异值分解 SVD
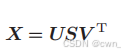
将共现矩阵转化为PPMI,并SVD降维:可以将大的稀疏向量转变为小的密集向量
-
-
word2vec和用向量表示单词:基于推理的方法
-
基于计数的方法弊端:一次性处理全部学习数据,不适用于大的语料库
-
基于推理的方法:选取mini_batch的数据,逐步学习
输入上下文,模型输出各个单词的出现频率
-
基于推理的方法 -神经网络学习
- 单词的处理:转换成one-hot独热编码
-
word2vec
word2vec中使用的两个神经网络模型:CBOW模型 & skip-gram模型
-
CBOW模型:根据上下文预测目标词
输入:上下文 -> one-hot
并行两个输入(表示上文 & 下文),经过1个隐藏层 两个全连接计算 到输出层
输出层后加上Softmax层和Cross Entropy Error交叉熵层 反向传播更新参数
-
skip-gram模型:根据给定单词预测上下文
输入:给定单词
经过一个隐藏层 两个全连接计算 输出层并行两个输出(表示上文 & 下文)
输出层后加上Softmax层和Cross Entropy Error交叉熵层 反向传播更新参数
-
-
GloVe(融合基于推理和基于计数)
将整个语料库的统计数据的信息纳入损失函数,进行mini_batch学习
Error交叉熵层 反向传播更新参数
-
GloVe(融合基于推理和基于计数)
将整个语料库的统计数据的信息纳入损失函数,进行mini_batch学习