目录
[1. 序列到序列模型](#1. 序列到序列模型)
[2. Transformer的整体架构](#2. Transformer的整体架构)
[1. 编码器核心组件](#1. 编码器核心组件)
[2. 残差连接与层归一化](#2. 残差连接与层归一化)
[1. 自回归解码器](#1. 自回归解码器)
[2. 掩码自注意力机制](#2. 掩码自注意力机制)
[3. 非自回归解码器](#3. 非自回归解码器)
[1. Cross Attention的工作原理](#1. Cross Attention的工作原理)
[1. 训练目标与损失函数](#1. 训练目标与损失函数)
[2. 注意力引导技术(Guide Attention)](#2. 注意力引导技术(Guide Attention))
[3. 训练策略](#3. 训练策略)
[4. 解码策略](#4. 解码策略)
一、Transformer概述
1. 序列到序列模型
Transformer属于序列到序列(Seq2Seq) 模型,这类模型的特点是输出长度由机器自行决定,而不是预先固定。
Seq2Seq的应用场景:
-
机器翻译:输入中文句子,输出英文句子
-
文本摘要:输入长文本,输出简洁摘要
-
语音识别:输入音频特征,输出文字转录
与传统分类的区别:
-
多类别分类(Multi-class):每个样本只属于一个类别
-
多标签分类(Multi-label):每个样本可以属于多个类别
-
序列到序列 :输出是变长序列,长度由内容决定
2. Transformer的整体架构
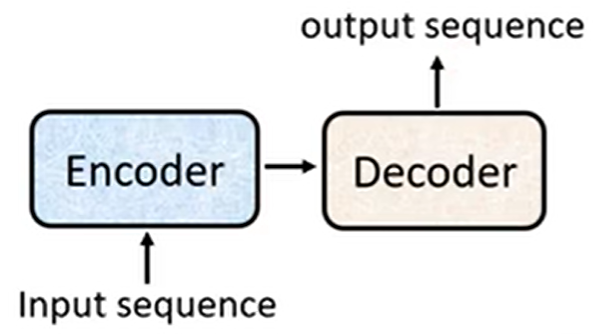
Transformer采用经典的编码器-解码器架构:
编码器(Encoder) :负责理解和编码输入序列的语义信息
解码器(Decoder):基于编码器的理解和已生成内容,逐步产生输出序列
二、Encoder编码器详解
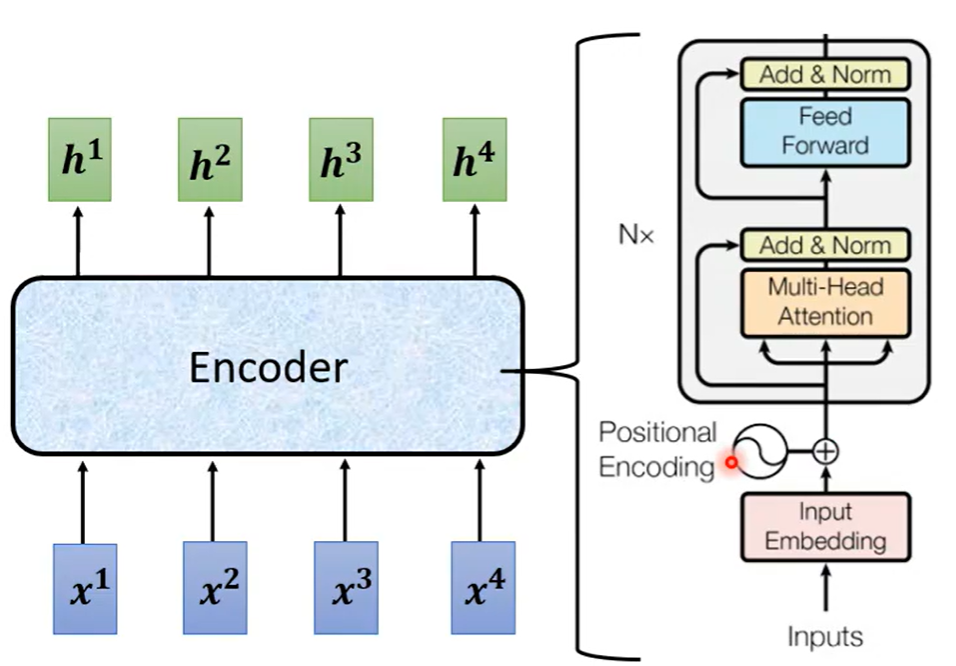
1. 编码器核心组件
编码器由多个相同的层堆叠而成,每层包含两个核心子层:
自注意力子层:
-
使用多头自注意力机制
-
让每个位置都能关注输入序列的所有位置
-
捕获丰富的上下文依赖关系
前馈神经网络子层(全连接层):
-
位置独立的全连接前馈网络
-
在每个位置上独立进行非线性变换
-
进一步增强表示能力
2. 残差连接与层归一化
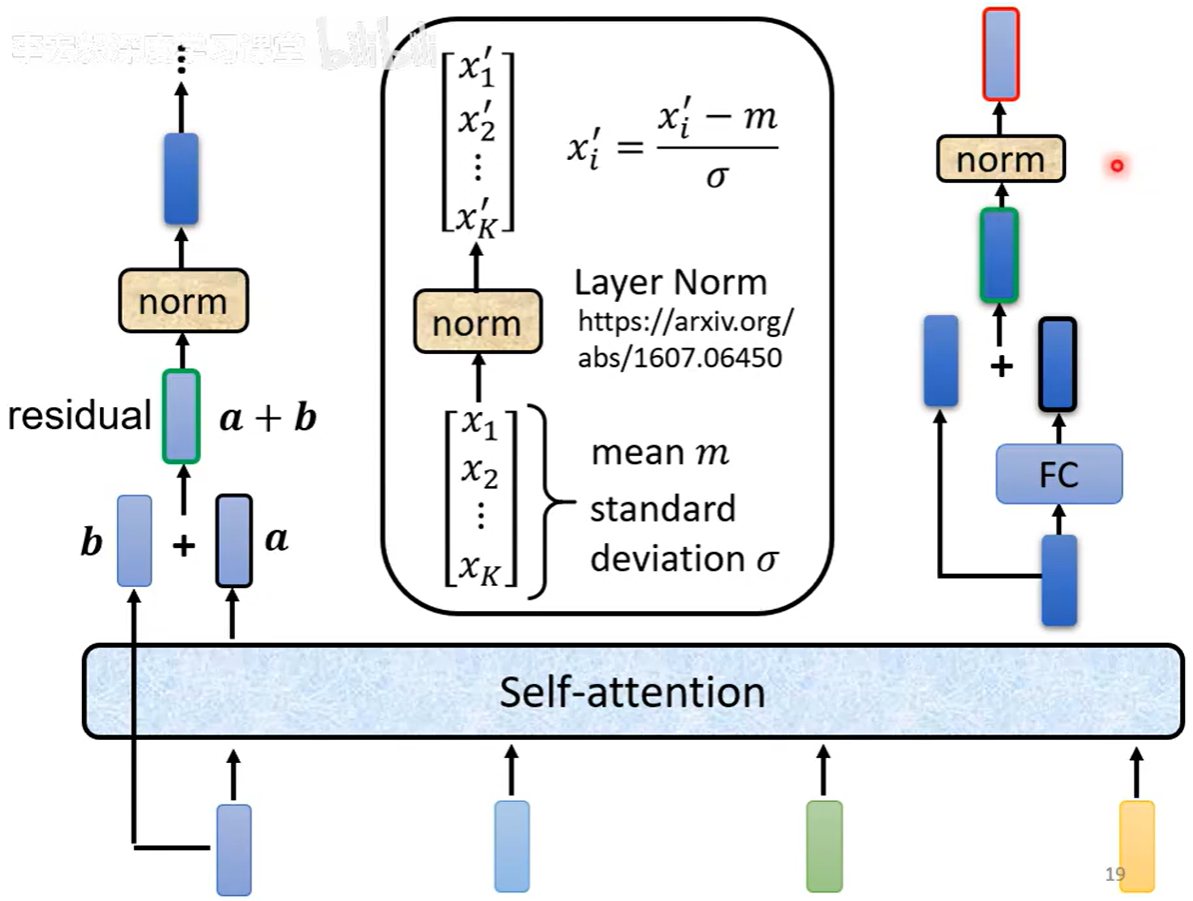
残差连接(Residual Connection):
-
在每个子层后,将输入向量与输出向量相加
-
数学表达:输出 = LayerNorm(x + Sublayer(x))
-
作用:缓解梯度消失,支持深层网络训练
层归一化(Layer Normalization):
-
对同一个样本的所有特征维度进行归一化
-
与批归一化(Batch Normalization)的区别:
| 归一化类型 | 计算方式 | 适用场景 |
|---|---|---|
| 层归一化 | 同一特征的不同维度 | 序列模型、RNN |
| 批归一化 | 不同特征的同一维度 | CNN、批量训练 |
层归一化的优势:
-
对批量大小不敏感
-
适合变长序列处理
-
训练和推理时行为一致
三、Decoder解码器详解
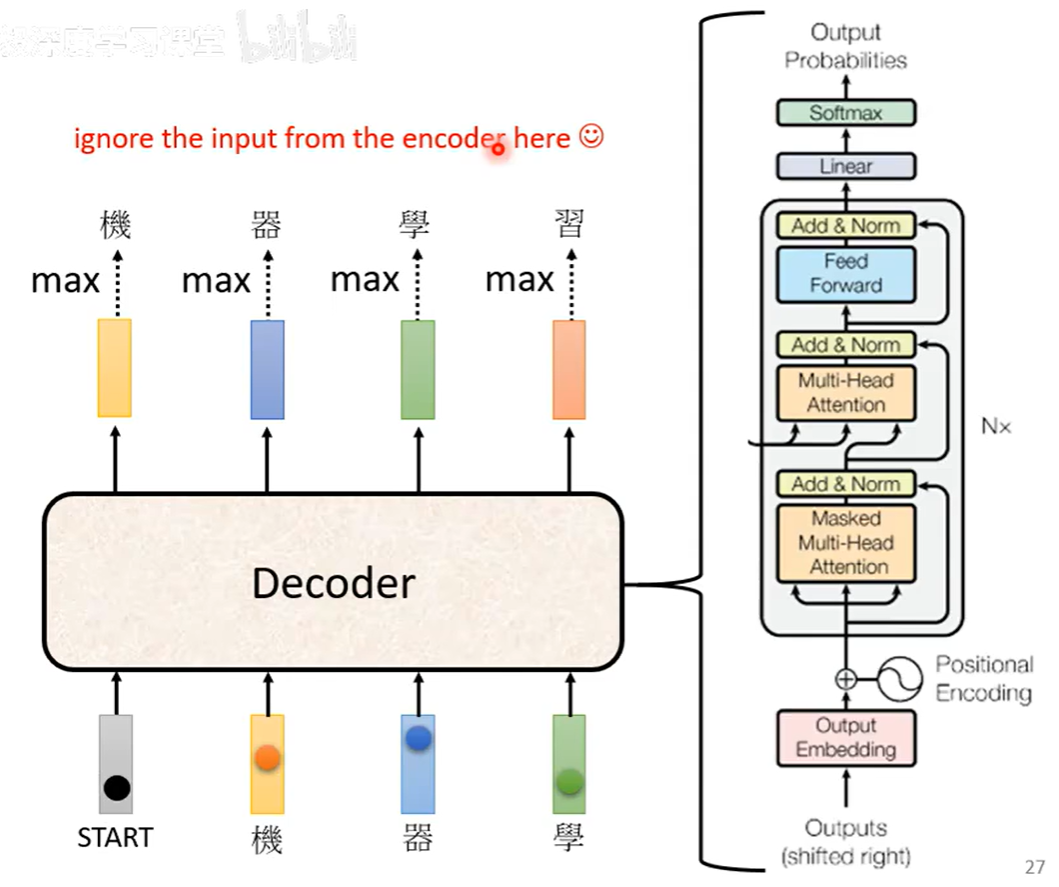
1. 自回归解码器
自回归解码器以逐步生成的方式工作:
生成过程:
-
输入特殊开始标记(如**
[begin of sentence,独热码]**) 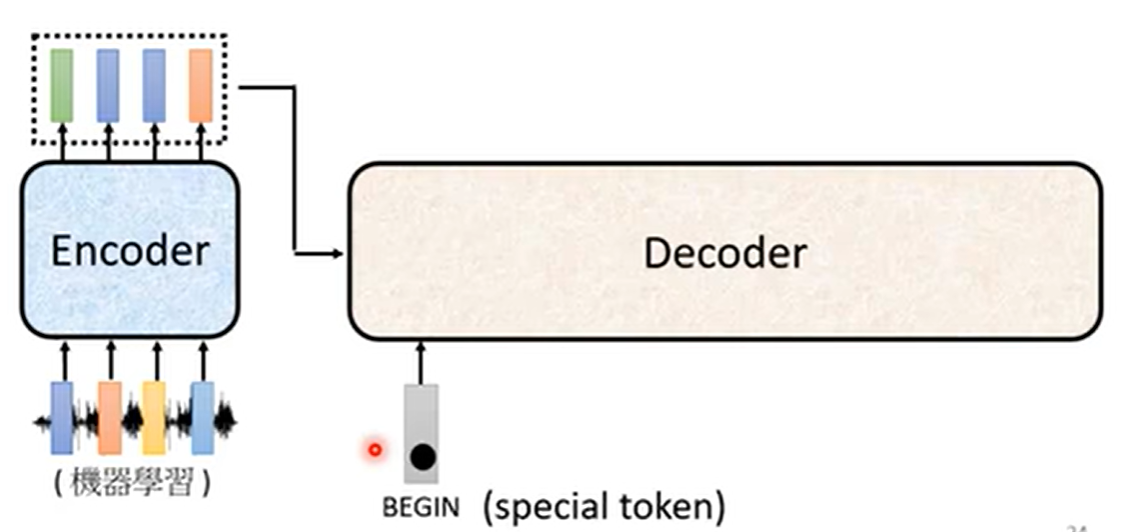
-
模型输出第一个词的概率分布向量,每个大小为所有词总和
-
选择概率最高的词作为输出
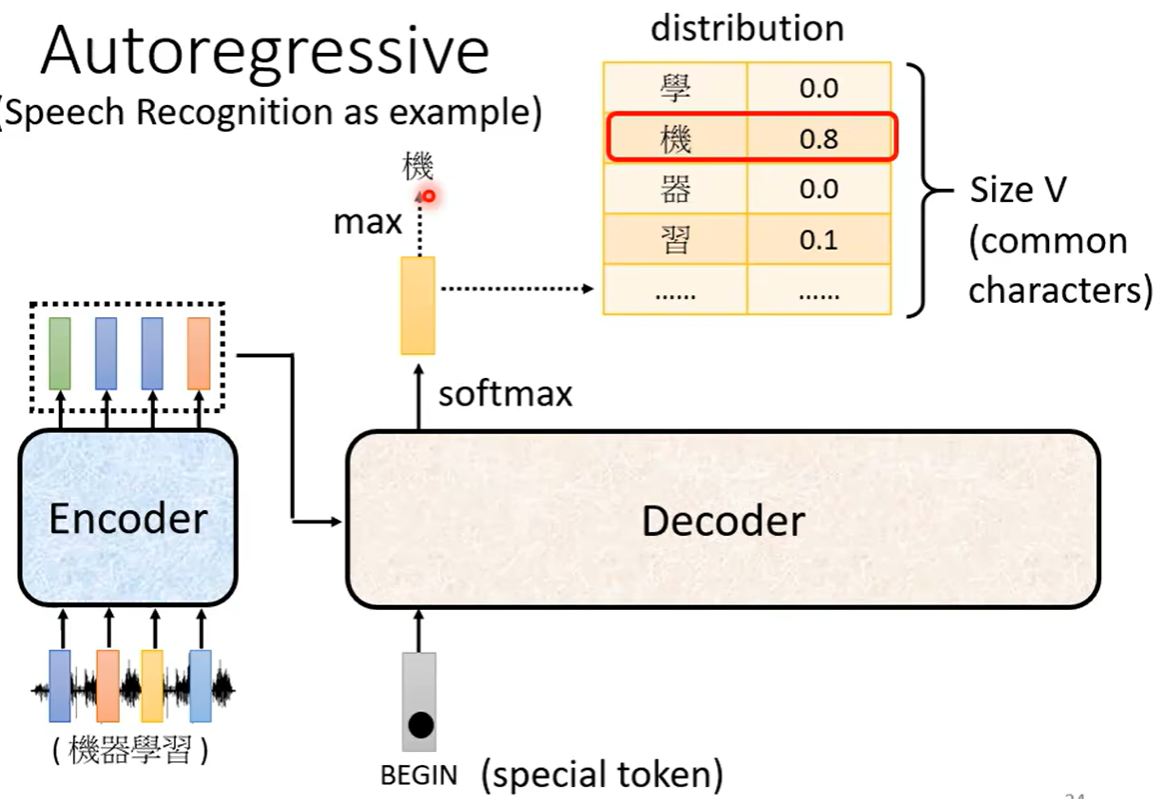
-
将已生成的词作为输入,继续生成下一个词
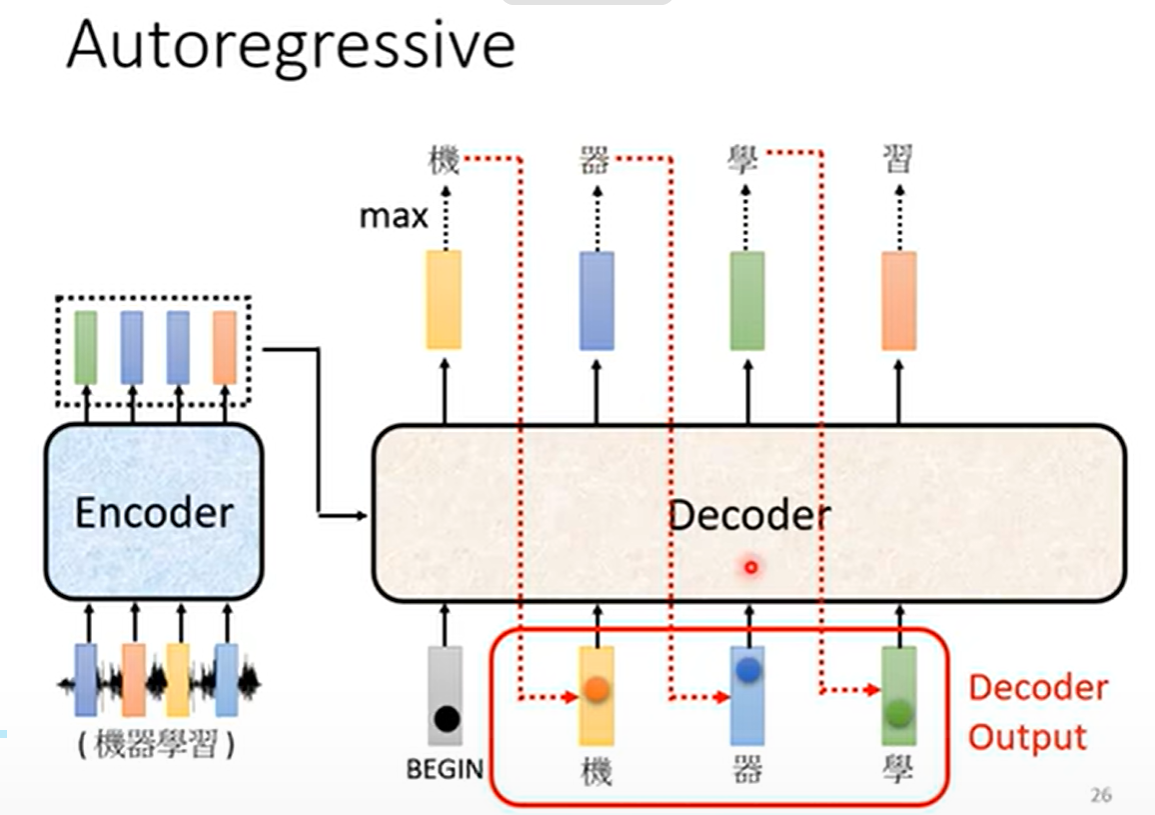
-
重复直到遇到结束标记(如
<EOS>)
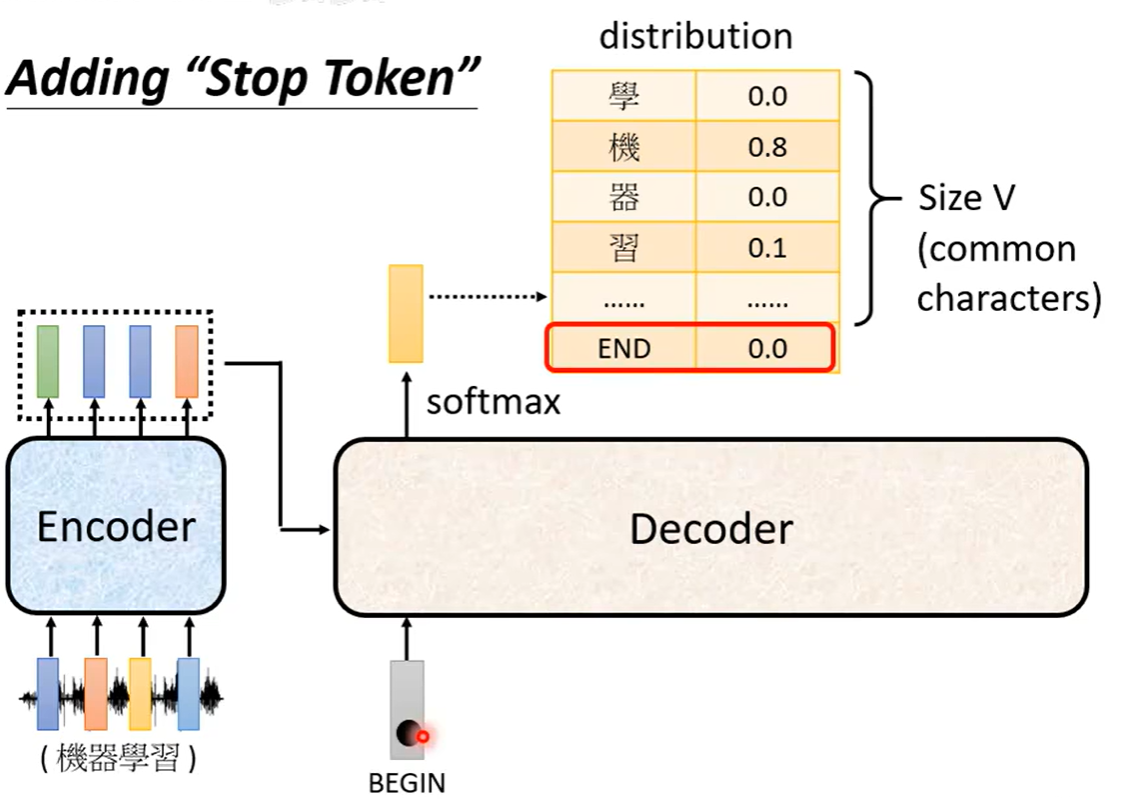
数学表达:
P(y_t | y_1, y_2, ..., y_{t-1}, X)其中X是编码器的输出,y_1到y_{t-1}是已生成的词。
自回归的挑战:
-
误差累积:一步出错可能导致后续全部错误
-
生成速度慢:必须顺序生成,无法并行
-
曝光偏差:训练时使用真实标签,推理时使用模型预测
2. 掩码自注意力机制
为了确保解码器在生成时只能看到左侧的上下文,Transformer引入了掩码自注意力:
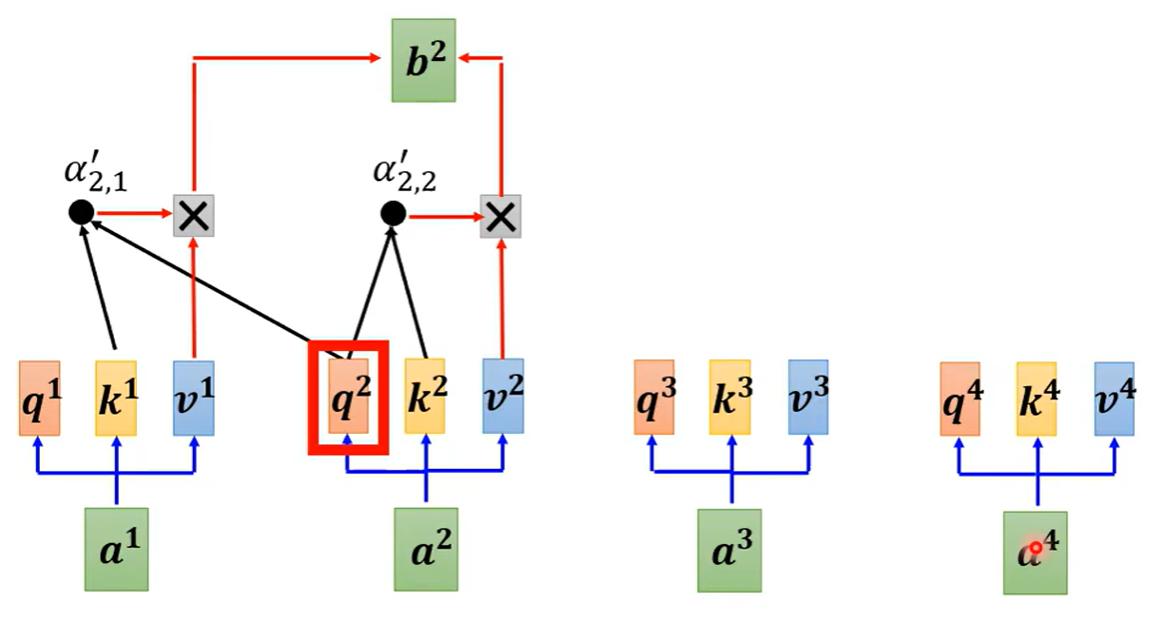
上图为a2的输出b2,自注意力机制只考虑他自身和他之前的a1
掩码的实现:
-
在计算注意力分数时,将未来位置的分数设为负无穷
-
Softmax后这些位置的权重变为0
-
确保每个位置只能关注它之前的位置
掩码自注意力的作用:
-
防止模型在训练时"偷看"答案
-
模拟推理时的真实生成过程
-
保持自回归特性
3. 非自回归解码器
为了解决自回归解码器的速度问题,研究者提出了非自回归解码器:
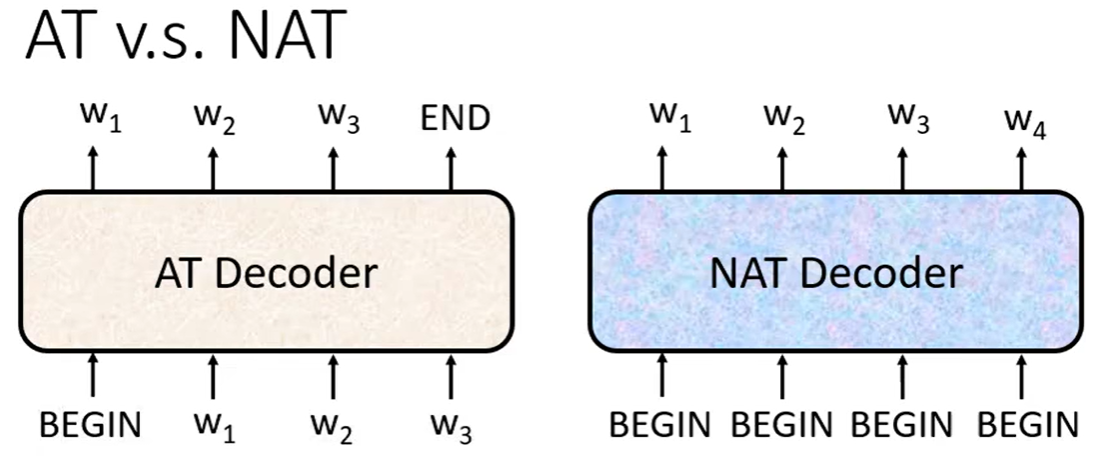
工作原理:
-
一次性生成整个输出序列
-
不需要逐步生成
-
并行计算,大幅提升速度
如何预测输出长度:
-
分类器方法:使用额外分类器预测输出长度
-
上限假设法:生成最大长度序列,遇到结束标记就停止
非自回归的优势与局限:
-
优势:生成速度快、输出长度可控
-
局限:通常生成质量不如自回归方法
-
应用:在速度要求高于质量的场景中使用
四、Encoder与Decoder的桥梁
1. Cross Attention的工作原理
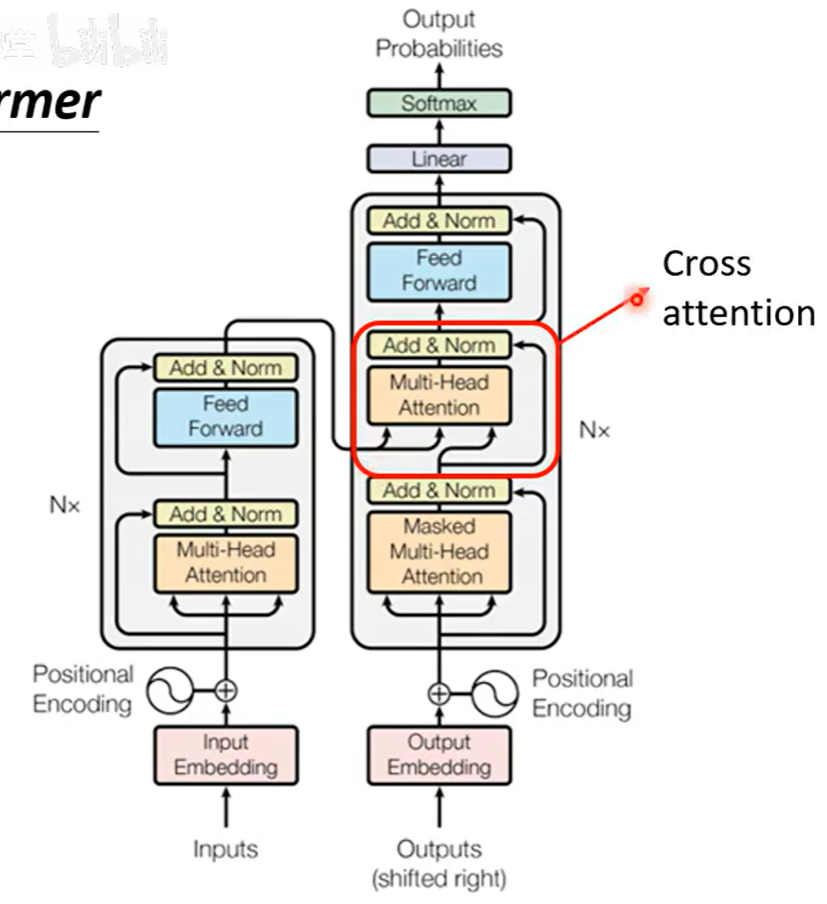
Cross Attention是连接编码器和解码器的关键桥梁,它在解码器的每一层中都存在:
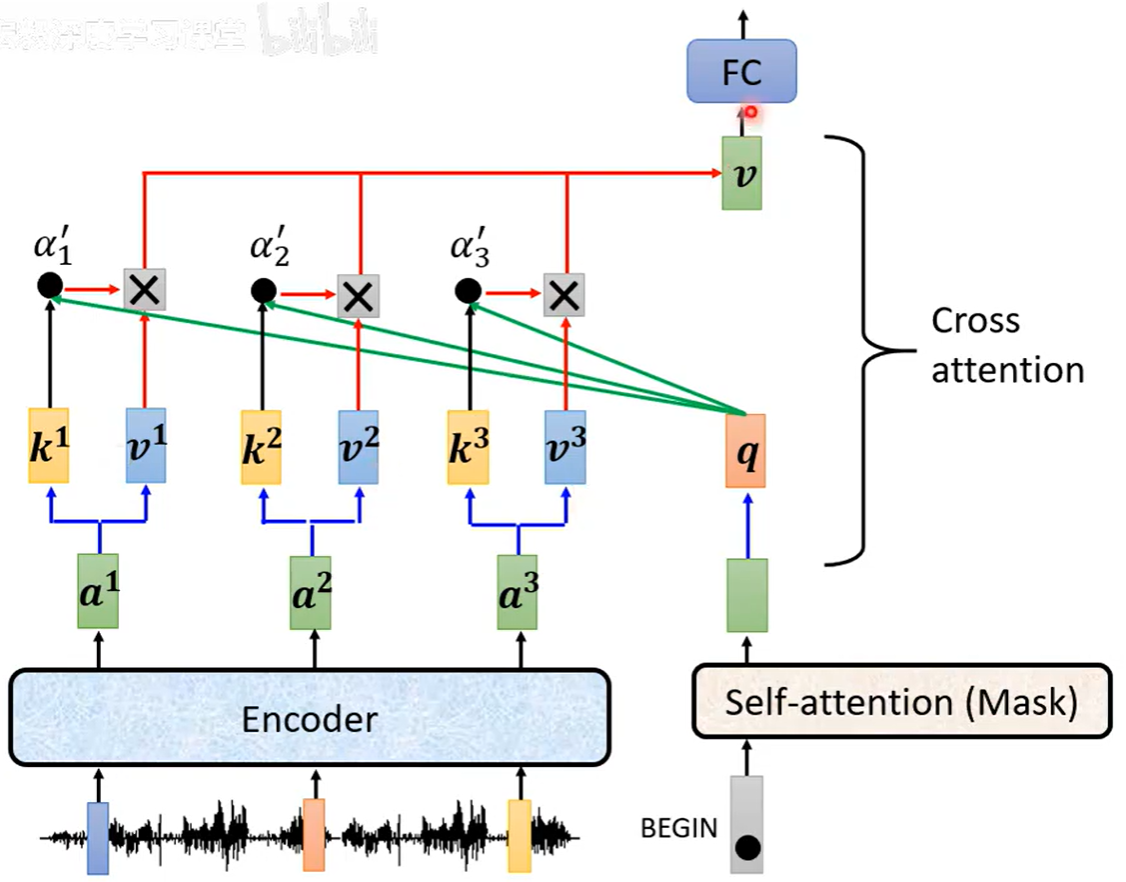
输入来源:
-
Q :来自解码器的自注意力输出
-
K和V :来自编码器的最终输出
计算过程:
-
解码器的每个位置生成查询向量Q
-
查询向量Q与编码器所有位置的键向量K计算注意力分数
-
使用注意力权重对编码器的值向量V进行加权求和
-
得到融合了源序列信息的上下文向量
五、Transformer的训练与推理
1. 训练目标与损失函数
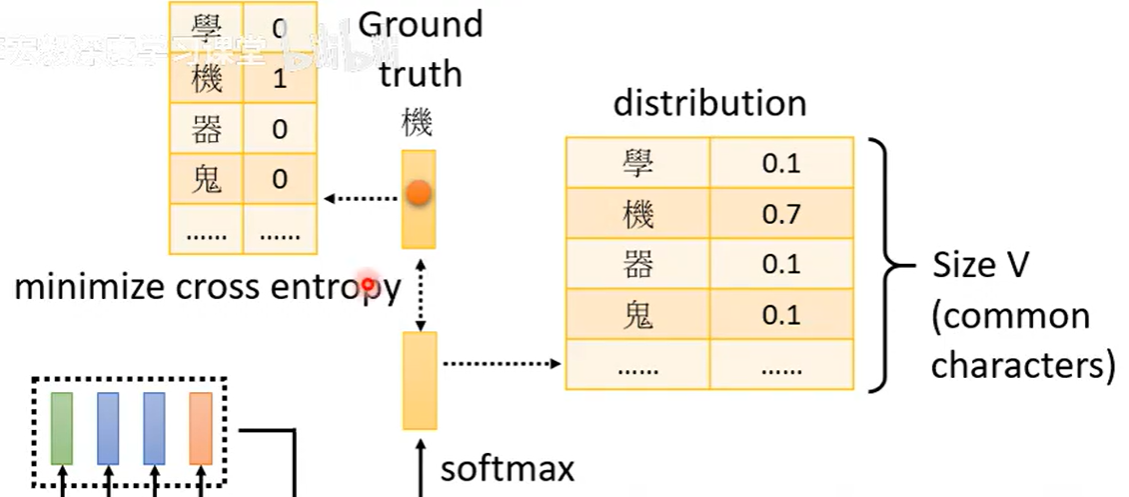
训练目标 :
最小化模型预测与真实标签之间的差异,通常使用交叉熵损失:
2. 注意力引导技术**(Guide Attention)**
在训练过程中显式引导模型关注特定的对齐关系,特别是在语音识别等任务中:
实现方法:
-
对齐损失:添加额外的损失项,惩罚注意力权重与理想对齐的差异
-
单调性约束:强制注意力权重沿对角线分布
-
覆盖度机制:防止模型重复关注相同位置
应用场景:
-
语音识别:强制音素与文本的单调对齐
-
机器翻译:保持源语言与目标语言的词序对应
-
文本到语音:确保文本与语音帧的时序对齐
3. 训练策略
Teacher Forcing :
在训练时,解码器每一步都使用真实的前缀作为输入:
-
优点:训练稳定,收敛快,避免误差累积
-
缺点:导致曝光偏差(Exposure Bias),即训练与推理时输入分布不一致
计划采样(Scheduled Sampling) :
在训练过程中逐渐从Teacher Forcing过渡到使用模型自己的预测:
采样概率调度:
使用真实标签的概率 = max(ε, 1 - epoch / total_epochs)
- 其中ε是最小概率(如0.1),确保始终有一定比例的真实标签。
标签选择:
-
训练初期:主要使用真实标签(高概率),稳定训练
-
训练中期:真实标签与预测标签混合,逐步适应
-
训练后期:主要使用预测标签,减少曝光偏差
4. 解码策略
解码策略在推理阶段使用,用于生成输出序列:
贪心解码:
-
每一步选择概率最高的词
-
优点:简单高效,计算速度快
-
缺点:可能陷入局部最优,生成质量一般
束搜索(Beam Search):
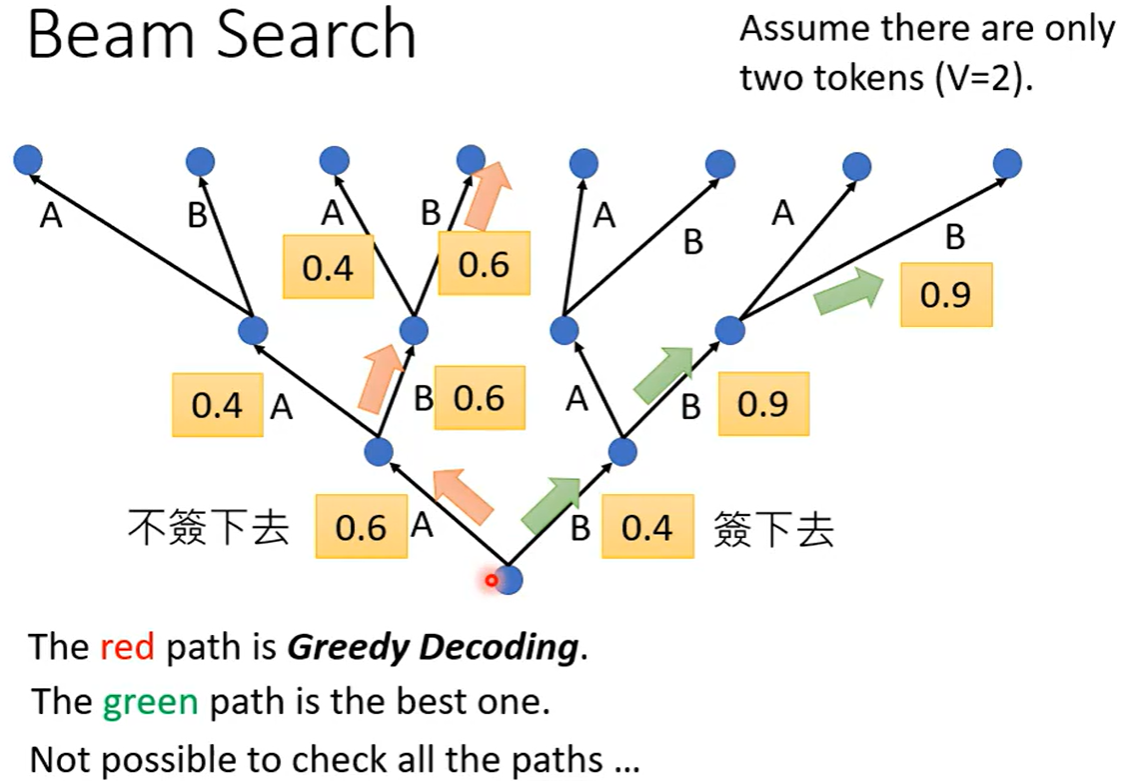
-
保留多个候选序列(束宽为k),每一步扩展所有候选序列
-
选择整体概率最高的序列作为最终输出
-
优点:生成质量较高,平衡质量与计算开销
-
缺点:计算开销大,束宽k是重要超参数
随机采样方法 :
在生成时从概率分布中随机采样,增加多样性:
温度采样(Temperature Sampling):
P'(w) = softmax(logits / temperature)
-
temperature > 1:分布更平缓,增加多样性
-
temperature < 1:分布更尖锐,减少随机性
-
典型值:0.5-1.0
Top-k采样 :
只从概率最高的k个词中采样:
-
避免选择低概率的无关词汇
-
k值影响生成质量和多样性(典型值:10-50)
Top-p采样(核采样) :
从累积概率达到p的最小词集合中采样:
-
动态调整候选词数量,适应不同概率分布
-
p值通常设为0.9-0.95
总结
Transformer是一种基于编码器-解码器架构的序列到序列模型,广泛应用于机器翻译、文本摘要等任务。其核心创新在于自注意力机制,使每个位置都能关注整个序列。编码器通过多头自注意力捕获上下文依赖,解码器则以自回归方式逐步生成输出。模型采用残差连接和层归一化来优化训练,并通过CrossAttention实现编解码器连接。训练中使用TeacherForcing、束搜索等技术提升性能。Transformer框架为序列建模提供了可扩展的解决方案,成为AI领域的重要突破。