概述
这篇题为"NAS-Bench-101: Towards Reproducible Neural Architecture Search"的论文由Chris Ying等人合作完成,旨在解决神经网络架构搜索(NAS)领域面临的重大挑战:计算资源需求高和实验难以复现的问题。
论文提出了NAS-Bench-101,这是第一个公开的NAS研究架构数据集。通过精心构建一个紧凑但表达力强的搜索空间,并利用图同构识别423k个独特的卷积架构,作者训练并评估了这些架构在CIFAR-10上的表现,最终编译成一个包含超过500万训练模型结果的大型数据集。
贡献
-
NAS-Bench-101数据集:首个大规模开源的NAS架构数据集,使研究人员能够在毫秒级别评估各种模型的质量,而无需实际训练模型。
-
搜索空间分析:首次全面分析NAS搜索空间的特性,揭示了可能指导NAS算法设计的见解。
-
算法基准测试:展示了如何使用该数据集对各种开源NAS优化算法进行快速基准测试。
架构设计
- 采用细胞(cell)结构,每个细胞由最多7个节点组成的有向无环图(DAG)
- 使用三种基本操作:3×3卷积、1×1卷积和3×3最大池化
- 限制最大边数为9
- 通过图同构识别出423k个独特架构
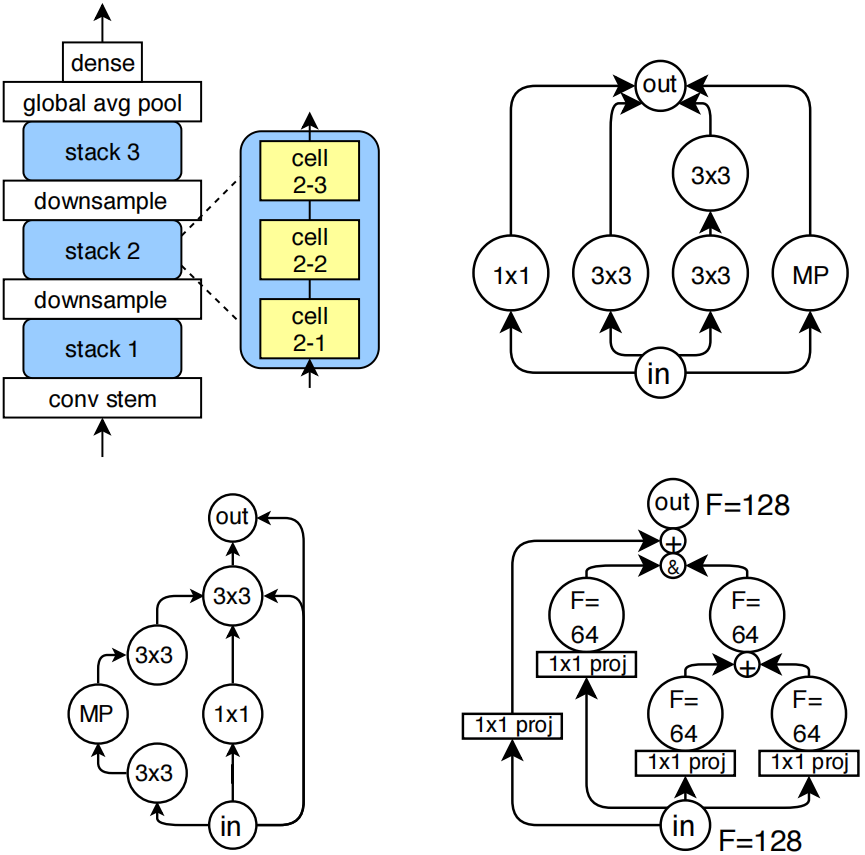
图1:(左上)各模型的外部架构示意图。(右上)一个类似Inception的卷积单元,其原始5x5卷积结构通过两个3x3卷积进行近似处理(省略了拼接和投影操作)。(左下)测试误差均值最低的卷积单元(省略了投影层)。(右下)展示通道计数自动确定方式的典型单元示例("+"表示加法运算,"&"表示拼接;使用1×1投影来缩放通道计数)。
(右上和左下都是左上这个架构图内部的cell的结构,右上是inception cell,左下是最佳cell,右下是每个cell的更细节展示,包括了他们的输入输出的连接方式。根据后面论文的描述,每个cell最多有7个节点、9条边,输入都是&操作,输出都是&操作。)
训练过程
- 所有模型在CIFAR-10上训练和评估
- 使用固定超参数集,通过RMSProp优化器训练
- 每个架构重复训练3次以获得方差测量
- 采用四种不同的epoch预算(4,12,36,108)来支持多保真度优化方法
数据集指标
数据集映射每个架构到以下指标:
- 训练准确率
- 验证准确率
- 测试准确率
- 训练时间(秒)
- 可训练模型参数数量
数据集分析发现
性能分布
- 大多数架构能达到100%的训练准确率
- 验证和测试准确率多数超过90%
- 最佳架构平均测试准确率达到94.32%
- ResNet-like和Inception-like细胞分别达到93.12%和92.95%
架构设计影响
- 用1×1卷积或3×3最大池化替换3×3卷积通常会导致绝对最终验证准确率下降
- 深度为3时平均验证准确率最优
- 宽度增加似乎会提高验证准确率,最高达到5(数据集中的最大宽度)
局部性特征
- 搜索空间表现出局部性,即"相近"架构往往具有相似性能
- 随机游走自相关(RWA)显示低距离时相关性高
- 全局最大值周围的邻域也显示出局部性
算法基准测试结果
论文比较了多种NAS和超参数优化算法:
- 随机搜索(RS)
- 正则化进化(RE)
- SMAC
- TPE
- Hyperband(HB)
- BOHB
- 强化学习(RL)
主要发现:
- RE、BOHB和SMAC表现最佳,在约50000 TPU秒后开始优于RS
- SMAC作为贝叶斯优化方法表现良好,尽管存在无效架构问题
- TPE表现不佳,性能回落到随机搜索水平
- 多保真度优化算法HB和BOHB未显示出常见加速效果
- RL虽然最终优于RS,但收敛到全局最优的速度慢得多
论文的第二节详细介绍了nas的架构。
2. The NASBench Dataset
NAS-Bench-101数据集是一张将神经网络架构与训练评估指标对应起来的表格。目前大多数神经架构搜索方法都选择在CIFAR-10分类数据集上训练模型,因为该数据集的小尺寸图像能让神经网络快速完成训练。此外,那些在CIFAR-10上表现优异的模型,在扩展到更难的基准测试(如ImageNet,克里热夫斯基等人,2012年)时通常也能取得好成绩(佐普等人,2018年)。基于这些原因,我们也将CIFAR-10作为CNN训练的基础,构建了NAS-Bench-101数据集。
2.1. Architectures
与其它神经架构搜索方法类似,我们把神经网络拓扑结构的探索范围search space 限定在小型前馈结构small feedforward structures (通常称为单元cells )的空间内,具体描述如下。每个单元堆叠三次后接一个下采样层a downsampling layer ,通过最大池化操作将图像的高度和宽度各减半,同时通道数翻倍。这种模式重复三次后接全局平均池化层global average pooling ,最终连接一个密集型softmax层a final dense softmax layer 。模型的初始层是一个包含一个3×3卷积核、输出128个通道的干层conv stem 。图1左上角展示了整个网络结构示意图。值得注意的是,干层后接单元堆叠的布局模式,在人工设计的图像分类器(何等人,2016;黄等人,2017;胡等人,2018)以及图像分类的神经架构搜索空间中都十分常见。因此,架构差异主要源于单元本身cell的创新设计。
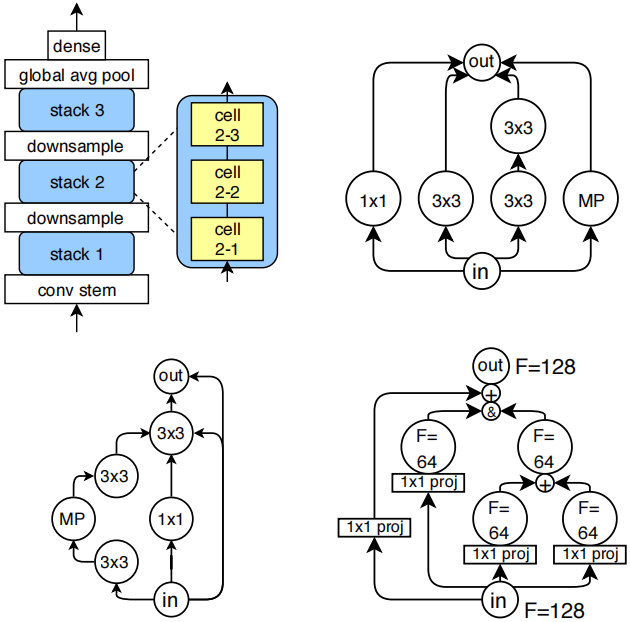
细胞cell架构空间由所有可能的有向无环图directed acyclic graphs 构成,这些图包含V个节点 ,每个节点都带有L种标签 之一,分别代表对应的操作operation 。其中两个顶点被特别标记为输入和输出操作,分别表示细胞的输入张量 和输出张量input** and **output tensors。然而,这种带标签的有向无环图空间在节点数V和标签数L上都呈指数级增长。为了限制该空间的规模以实现穷举枚举,我们施加了以下约束条件:
•我们设定L = 3,仅使用以下操作:(这里的操作可以理解节点上的标签,3种操作=3个标签)
-- 3×3卷积
-- 1×1卷积
-- 3×3最大池化
•将V限制在7以内。
•将边的最大数量限制为9条。
所有卷积层convolutions 均采用批量归一化batch normalization 后接ReLU激活函数ReLU 。这种设计选择旨在确保搜索空间仍包含ResNet式和Inception式单元(何等人,2016;塞格迪等人,2016)。图1右上角展示了Inception式单元的典型示例。我们特意选用卷积层convolutions 而**非可分离卷积层separable convolutions**来复现ResNet和Inception的原始架构设计,尽管这会导致参数量比AmoebaNet(瑞尔等人,2018)等最新前沿架构更为庞大。
2.2. Cell encoding
对细胞进行编码存在多种方式,不同的编码方式可能通过调整搜索空间来优化特定算法的性能。在多数实验中,我们选择采用一种通用编码方案:即使用7×7上三角二进制矩阵 表示的7顶点有向无环图,以及包含5个标签的列表(每个中间顶点对应一个标签,需注意输入输出顶点是固定的)。由于矩阵中存在2¹¹种可能的边连接方式,每个标签对应3种操作模式,因此该编码方案总共可生成2²¹∗3⁵≈5¹⁰M个独特模型。补充材料S3中我们还讨论替代编码。
然而,该空间中存在大量无效模型(即输入顶点之间不存在路径,或总边数超过9条)。此外,不同图在该编码方式下可能不具备计算唯一性。我们用于识别和枚举唯一图的方法详见补充材料S1。经过去重处理后,搜索空间中共有约42.3万个唯一图。
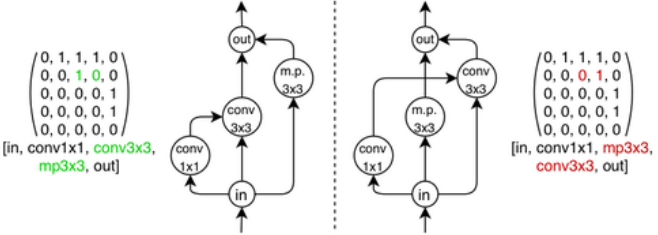
在NAS-Bench-101模型搜索空间中,存在具有不同邻接矩阵或标签但计算等效的模型(如图1所示)。我们将这类单元称为同构单元。此外,不在输入节点到输出节点路径上的顶点不会对单元计算产生贡献。对于包含此类顶点的单元,可以通过剪枝操作将其缩减为更小的单元,而不会改变该单元在网络中的有效行为。由于搜索空间规模庞大,若不考虑同构性而逐一评估所有可能的图表示方式,将会导致计算复杂度过高且效率低下。
图1:两个单元,根据它们的邻接矩阵和标签的不同而表示不同,但编码相同的计算。
2.3. Combine semantics
将图结构转换为对应的神经网络架构相对简单,但存在一个例外情况:当多条边指向同一节点时,需要对传入的张量进行合并处理。此时采用加法+或拼接\&操作都是常规做法。为兼容ResNet和Inception类网络单元,同时保持计算空间的可扩展性,我们制定了固定规则:输出节点的张量采用拼接方式处理,而其他节点的输入则进行求和运算。输入节点的输出张量会按顺序投影projected in order,以匹配后续操作所需的输入通道数量。该机制如图1右下角所示。
2.4. Training
训练流程是架构搜索基准测试中的关键环节,因为不同的训练方法会导致性能出现显著差异。为解决这一问题并确保NAS算法在公平条件下进行对比,我们为数据集中的所有模型设计并开源了一个通用训练流程。
超参数选择方面**Choice of hyperparameters.**,我们为NAS-Bench-101的所有模型采用统一固定超参数集。该参数集通过粗网格搜索优化了从空间中随机抽取的50个架构的平均准确率,从而确保其在不同架构间的鲁棒性。这种做法与文献中的标准做法(Zoph等人,2018;Liu等人,2018a;Real等人,2018)相似,并在第5.1节的实验分析中得到了进一步验证。
模型训练与评估细节**Implementation details.**。所有模型均在CIFAR-10数据集(包含4万训练样本、1万验证样本和1万测试样本)上进行训练与评估,采用标准数据增强技术(He等人,2016)。通过余弦衰减算法(Loshchilov & Hutter,2017)将学习率逐步降至零,以降低多次独立训练产生的方差波动。训练过程使用RMSProp优化器(Tieleman & Hinton,2012)配合交叉熵损失函数,并采用L2正则化。所有模型均在TPU v2加速器上完成训练。基于TensorFlow开发的代码及相关超参数配置已公开发布于https: //github.com/google-research/nasbench。
我们设置了3次重复实验和4个训练轮次预算**3 repeats and 4 epoch budgets.**。所有架构均进行三次重复训练与评估以获取方差度量。为评估多保真优化方法(如Hyperband算法,Li等人,2018),我们采用四个递增训练轮次预算进行训练:Estop∈{Emax/3 3,Emax/3 2,Emax/3,Emax} = {4,12,36,108}轮次。每次训练时,学习率在Estop轮次达到最大值后逐步衰减至零。因此,针对每个Estop参数值,我们分别训练了3×423k∼1.27M个模型,总计获得4×1.27M∼5M个模型。
2.5.Metrics
我们对每个架构A进行了三次不同随机初始化的训练测试,针对上述四个预算参数Estop逐一进行。最终数据集包含以下维度:
•训练准确率;
•验证准确率;
•测试准确率;
•训练耗时(秒);
•可训练模型参数数量。
在单一NAS算法中,仅需使用训练集和验证集的指标来搜索模型,测试准确率仅用于离线评估。训练耗时指标既可用于基准测试算法在时间限制下的精度优化(见第4节),也可评估多目标优化方法。其他无需重新训练的指标可通过公开代码计算得出。
2.6. Benchmarking methods
该数据集的核心目标之一是为NAS算法提供基准测试支持。本节将详细阐述使用NAS-Bench-101的推荐最佳实践方案,这些方案在后续分析中均被采用;若需获取完整的基准测试操作指南,请参阅补充材料S6。
NAS算法的目标是在Emax轮次时找到具有高测试准确率的架构。为此,我们会在(A,Estop)配对点上反复查询数据集,其中A是搜索空间中的一个架构,Estop表示允许的轮次数(Emstop∈{4,12,36,108})。每次查询都会通过随机试验索引进行查找,该索引是均匀分布的从{1,2,3}中随机选取,以模拟SGD训练的随机性。
在搜索过程中,我们会记录算法在每次函数评估后找到的最佳架构Aˆi,并根据其验证准确率进行排序。为了更好地模拟现实世界的计算约束,当总"训练时间"超过固定限制时,我们会终止搜索运行。每次完整搜索结束后,我们会查询该模型对应的平均测试准确率f(Aˆi)(测试准确率本身不应作为搜索的指导依据)。随后计算即时测试遗憾值:r(Aˆi)=f(Aˆi)−f(A∗),其中A∗表示整个数据集中平均测试准确率最高的模型。该遗憾值即为本次搜索运行的得分。为了评估不同搜索算法的鲁棒性,需要进行大量独立的搜索运行测试。
3. NASBench as a Dataset
在本节中,我们将对NAS-Bench-101数据集进行全面分析,以深入理解神经网络操作和细胞拓扑结构对卷积神经网络性能的影响。通过这一研究,我们希望揭示NAS算法所经历的损失函数变化轨迹。