本文参考视频:
DDP分布式训练理论基础
DDP具体细节可以参考我的另一篇专门讲DDP理论的博客:
DDP支持单机多卡和多机多卡
每个GPU上的模型都是完整的,一样的
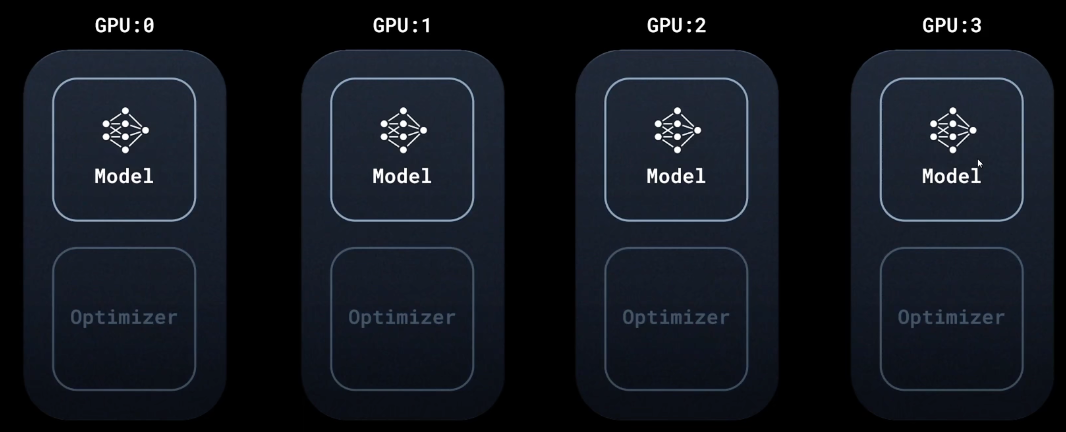
DDP将dataloader换成distributed sampler。把一个batch的内容分发给多个GPU
思想是数据并行

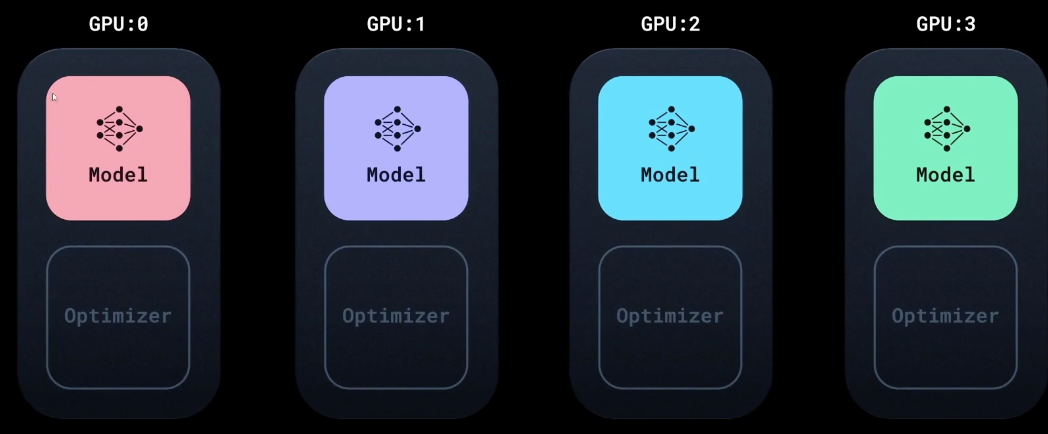
由于喂的数据不一样,所以每个机器的模型更新会不一样
DDP通过环形同步(All reduce)的方式将彼此的模型信息同步到一起,这些过程都封装到了反向传播的函数中,不用用户来考虑
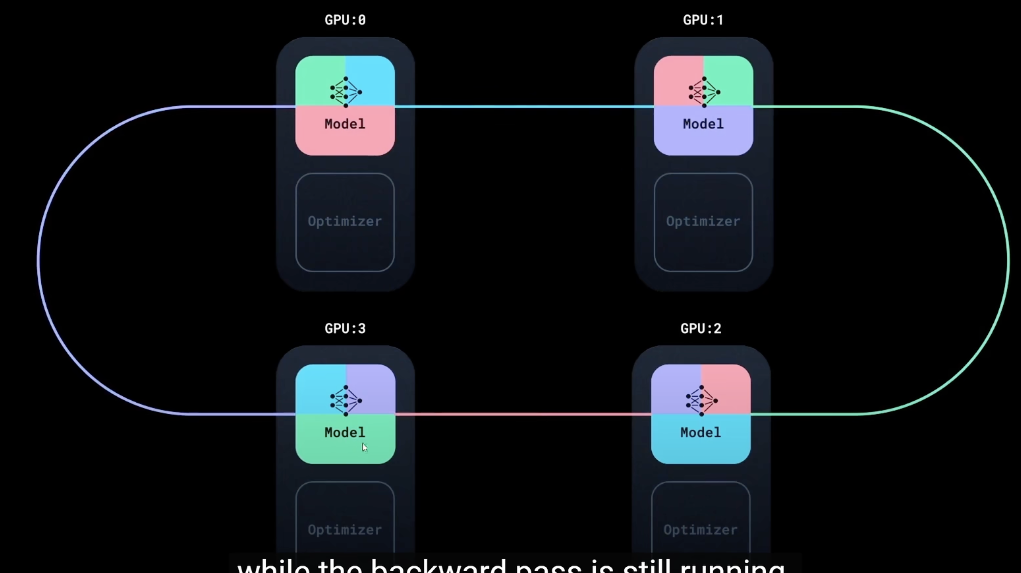
所有卡之间的梯度和损失都是同步对齐的
DDP代码实现
在代码实现上其实很简单,就是要注意几个点:
1,原有的代码前面加上trochrun
python
export CUDA_VISIBLE_DEVICES=4,5,6,7 && torchrun --nproc_per_node=4 dist_train.py目前仅考虑单机多卡的情况,nproc_per_node 的全称是 "number of processes per node" ,意思是 每个节点(机器)启动的进程数量, 在分布式训练中,这通常对应 每张 GPU 启动一个训练进程,保证每个 GPU 都被占用并参与梯度同步。
这个代码会在每个GPU上都运行dist_train.py这个脚本

2,让各个进程进入全局的通信组
由于DDP需要各个进程之间进行通信,因此需要在一开始的之后对每个进程进行通信的初始化。
DDP需要对原来的代码做以下几个地方的改动:
1,为每个GPU上的进程的模型显式的分配GPU
python
device = torch.device(f"cuda:{local_rank}")2,使用DistributedSampler把原始的dataset做切分
python
train_sampler = DistributedSampler(train_dataset)
train_loader = DataLoader(
train_dataset, batch_size=8, shuffle=(train_sampler is None), # 这里的batchsize是local的batchsize
sampler=train_sampler, collate_fn=dict_collate_fn
)3,把模型包装成DDP模型,用于DDP的模型同步通信(包括梯度和优化器的同步)
python
if is_ddp:
from torch.nn.parallel import DistributedDataParallel as DDP
model = DDP(model, device_ids=[local_rank], output_device=local_rank) # 作用:把你的模型包成 DDP 模型,让它支持分布式训练。4,在训练的循环中为了时数据同步要加上set_epoch和dist.barrier()等函数
python
if dist.is_initialized():
print(f"Rank: {dist.get_rank()}")
print("local batch size:", batch["pixel_values"].size(0)) # batch[0]:[B, 3, 128, 128]
# 多GPU时,确保所有进程都同步完成这个batch的计算
# dist.barrier() 等待所有进程初始化完毕5,训练完的最后要注销通信组
python
if is_ddp:
dist.destroy_process_group()
# 开始 DDP 时用了 init_process_group
# 结束 DDP 时要调用 destroy_process_group注意事项:
1,梯度同步:
python
grad_global = sum(grad_local_i for i in all_processes) / world_sizeDDP中dataloader的batchsize是local的batchsize,最后梯度更新的实际batchsize是global的batchsize
python
train_loader = DataLoader(
train_dataset, batch_size=8, shuffle=(train_sampler is None), # 这里的batchsize是local的batchsize
sampler=train_sampler, collate_fn=dict_collate_fn
)2,如果print()时没有判断rank时,所有的进程都会打印一次
因此在evaluate时,往往只需要rank0的机器eval,其他机器等待即可
涉及计算和打印loss时,如果不声明,每个进程都会打印一次,而且打印的是本地的local batch的loss。(但是在更新梯度时DDP会自动同步各个进程的local 梯度,最终是global的梯度)
如果想看到global batch上的loss,需要额外将所有进程的loss平均出来打印。
同样的,如果是保存文件这种操作,如果不判断rank时,所有的进程都会保存一次
完整代码:
python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, datasets
import os
from dataset import CatDogDataset
from dataloader import MyDataLoader, dict_collate_fn
from model import SimpleCNN
from tqdm import tqdm
from utils import train_one_epoch, evaluate
def main():
# -----------------------------
# ✅ 1. DDP 初始化(最小修改)
# -----------------------------
import torch.distributed as dist
import torch
import os
if "RANK" in os.environ and "WORLD_SIZE" in os.environ:
# nccl 这个跟显卡品牌有关系,是用于GPU之间的通信
dist.init_process_group(backend="nccl") # 让当前进程加入一个全局的通信组
# NCCL 是 NVIDIA Collective Communications Library 的缩写,是 NVIDIA 提供的一个高性能通信库,专门用于多 GPU 之间的通信和协作计算。
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(local_rank) # 当前进程之后所有的 CUDA 操作都在 local_rank 这张 GPU 上执行。
device = torch.device(f"cuda:{local_rank}")
is_ddp = True
print(f"Running in DDP mode on rank {dist.get_rank()} / {dist.get_world_size()}")
else:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
is_ddp = False
local_rank = 0
# -----------------------------
# ✅ 2. 原本你的代码(完全不动)
# -----------------------------
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor()
])
train_dataset = CatDogDataset("/data/czhang/datasets/cat_and_dog/train", transform=transform)
val_dataset = CatDogDataset("/data/czhang/datasets/cat_and_dog/train", transform=transform)
# ✅ sampler 替代 shuffle(DDP需要)
from torch.utils.data import DataLoader, DistributedSampler
if is_ddp: # 这个sampler是给dataloader用的
train_sampler = DistributedSampler(train_dataset) # DistributedSampler 会自动把数据集进行划分,保证每个进程看到不同的数据
val_sampler = DistributedSampler(val_dataset, shuffle=False)
else:
train_sampler = None
val_sampler = None
train_loader = DataLoader(
train_dataset, batch_size=8, shuffle=(train_sampler is None), # 这里的batchsize是local的batchsize
sampler=train_sampler, collate_fn=dict_collate_fn
)
val_loader = DataLoader(
val_dataset, batch_size=8, shuffle=False,
sampler=val_sampler, collate_fn=dict_collate_fn
)
model = SimpleCNN().to(device) # 每个进程单独加载完整的模型
# ✅ 如果是 DDP 模式则包一层
if is_ddp:
from torch.nn.parallel import DistributedDataParallel as DDP
model = DDP(model, device_ids=[local_rank], output_device=local_rank) # 作用:把你的模型包成 DDP 模型,让它支持分布式训练。
# dist.broadcast_parameters(model.state_dict(), src=0) # 从0号进程广播,使得初始参数完成对齐
# 在这个里面,rank 0的进程会将梯度广播到其他进程,从而保证所有进程的模型参数是一致的。
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4) # 优化器的部分就不用管了,会自动对齐
epochs = 5
for epoch in range(1, epochs + 1):
train_loss, train_acc = train_one_epoch(model, train_loader, optimizer, criterion, device, epoch)
if not is_ddp or dist.get_rank() == 0:
print(f"[Epoch {epoch}] Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.3f}")
if not is_ddp or dist.get_rank() == 0: # 如果是 DDP,只让 rank 0 执行 evaluate 打印和保存
val_loss, val_acc = evaluate(model, val_loader, criterion, device)
print(f"Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.3f}")
torch.save(model.state_dict(), "ckpts/model_final.pth")
if is_ddp:
dist.destroy_process_group()
# 开始 DDP 时用了 init_process_group
# 结束 DDP 时要调用 destroy_process_group
if __name__ == "__main__":
main()
# CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 /data/czhang/projects/mini_framework/dist_train.py