效果演示
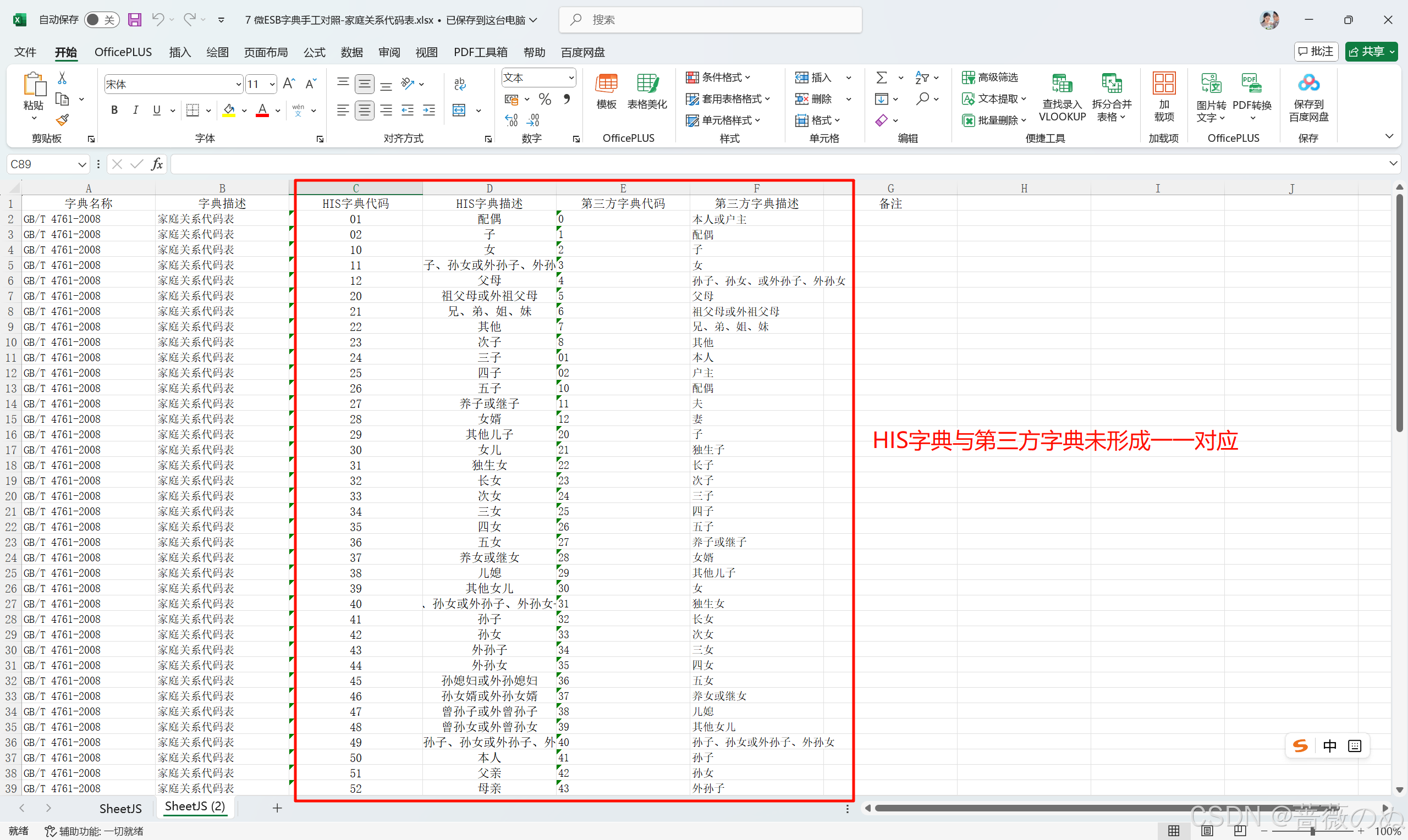
对照前(紊乱数据)
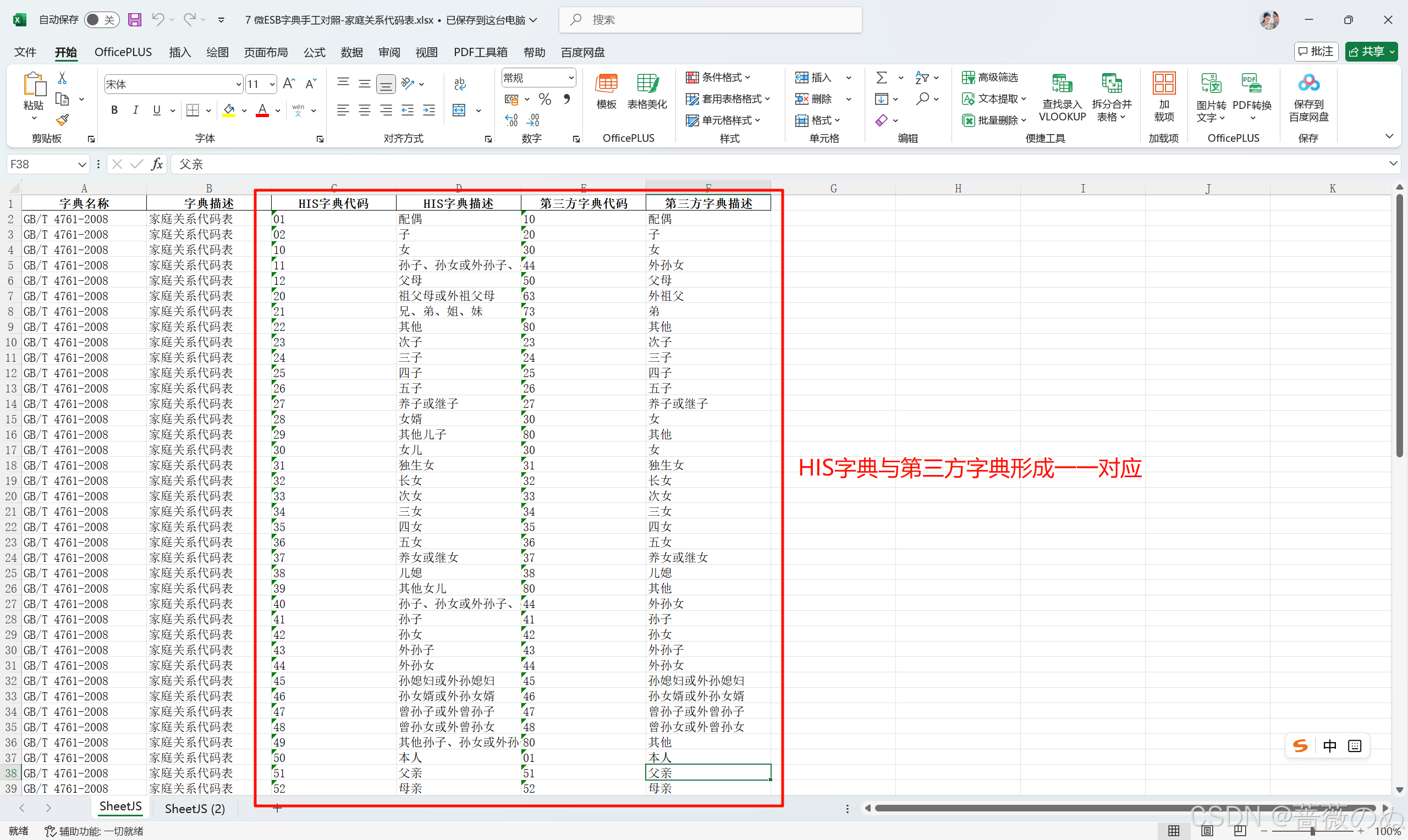
对照后(一一对应)
Python代码示例
python
# !/usr/bin/env python
# -*- coding:utf-8 -*-
"""
Creator: wcw
Date: 2025/7/29
Description: 字典对照自动化处理
"""
import os
import pandas as pd
class PDExcel(object):
def __init__(self):
pass
@classmethod
def compa_excel(cls, dir_path, file_name, fillna_code="", fillna_name=""):
"""
将未对照的Excel数据进行对照处理,将结果输出到新的sheet中
:param file_name:Excel文件名
:param fillna_code:空值编码默认值
:param fillna_name:空值名称默认值
:return:
"""
# 读取Excel表数据
print("开始读取Excel文件...")
file_path = os.path.join(dir_path, file_name)
sheet_data = pd.read_excel(
io=file_path,
sheet_name="SheetJS (2)",
header=0,
skiprows=0,
dtype=str
)
print("读取Excel文件完成.")
# 分别提取HIS字典和第三方字典内容
his_data = sheet_data.loc[:, ["字典名称", "字典描述", "HIS字典代码", "HIS字典描述"]]
vender_data = sheet_data.loc[:, ["第三方字典代码", "第三方字典描述"]]
# print(his_data.at[0, "HIS字典代码"])
# print(vender_data.get("第三方字典代码"))
# 初始化对照前的字典数据
columns = ["字典名称", "字典描述", "HIS字典代码", "HIS字典描述", "第三方字典代码", "第三方字典描述"]
new_df = pd.DataFrame(data=None, columns=columns, dtype=str)
new_df = pd.concat([new_df, his_data])
# print(new_df)
# 检索判断、对照处理
print("处理对照中,请耐心等待...")
for new_row in new_df.itertuples():
# print(new_row)
for vender_row in vender_data.itertuples():
# if new_row.HIS字典描述 == vender_row.第三方字典描述: # 精准匹配
if str(new_row.HIS字典描述).find(str(vender_row.第三方字典描述)) != -1: # 模糊匹配
new_df.at[new_row.Index, "第三方字典代码"] = vender_row.第三方字典代码
new_df.at[new_row.Index, "第三方字典描述"] = vender_row.第三方字典描述
if pd.isna(new_df.at[new_row.Index, "HIS字典代码"]):
new_df.drop(index=new_row.Index, inplace=True) # inplace=True,修改原数据
# 处理对照失败的默认值
new_df.fillna({"第三方字典代码": fillna_code, "第三方字典描述": fillna_name}, inplace=True)
# 得到对照后的字典数据
print(new_df)
print("处理对照完成.")
# 修改原Excel数据
print("开始输出到Excel...")
new_df = new_df.astype(str) # 指定数据类型,防止Excel自动转换
# 使用ExcelWriter,可以在原Excel中新增sheet表,if_sheet_exists若sheet表存在的处理方式(overlay:直接覆盖内容保留原格式,replace:直接替换同名工作表)
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a', if_sheet_exists="overlay") as writer:
new_df.to_excel(writer, sheet_name="SheetJS", columns=columns, index=False) # index 是否写入行索引
print("输出到Excel完成.")
if __name__ == '__main__':
# 运行方法
print("程序已启动...")
dir_path = r"D:\PythonDemo\字典手工对照"
file_name = "7 微ESB字典手工对照-家庭关系代码表.xlsx"
fillna_code = "99"
fillna_name = "非亲属"
PDExcel.compa_excel(dir_path, file_name, fillna_code, fillna_name)
print("程序结束.")此毕*。转载请注明出处。*