今天学习了KNN算法的一个小项目手写数字识别,下面来对这部分项目代码进行详细分析下。
识别的数据是一张图片

这张图片的像素是2000*1000的,如果大家下载这个可能不是的,但应该可以转化。
下面是整体代码:
import numpy as np
import cv2
tp=cv2.imread('2e97f45f638a45aefac9f7599dcacaa.png')
# print(tp.shape)
gray=cv2.cvtColor(tp,cv2.COLOR_BGR2GRAY)
# print(gray.shape)
cell=[np.hsplit(i,100) for i in np.vsplit(gray,50)]
# print(cell[0][0].shape)
data=np.array(cell)
# print(data.shape)
trainx=data[:,:50,:]
testx=data[:,50:,:]
train_x=trainx.reshape(-1,400).astype(np.float32)
test_x=testx.reshape(-1,400).astype(np.float32)
k=np.arange(0,10)
# print(k)
train_y=np.reshape(np.repeat(k,250),(-1,1))
test_y=np.reshape(np.repeat(k,250),(-1,1))
# print(train_y.shape)
from sklearn.neighbors import KNeighborsClassifier
model=KNeighborsClassifier(n_neighbors=8)
model.fit(train_x,train_y)
result1=model.score(test_x,test_y)
print(result1)
new=cv2.imread('test1.png')
newgray=cv2.cvtColor(new,cv2.COLOR_BGR2GRAY)
# print(newgray.shape)
new1=np.reshape(newgray,(-1,400))
# print(new1.shape)
result2=model.predict(new1)
print('识别结果:',result2)下面我对这段代码,进行详细解析:
1 数据导入
tp=cv2.imread('2e97f45f638a45aefac9f7599dcacaa.png')我们通过cv2中的imread方法进行对图片数据的读取,他的读取结果就是3个矩阵,虽然我们图片看着是黑白的,但图片类型是RGB的所有读取下来就还是三个。
关于读取结果,我们图片是由许多像素点构成的,然后imread将每个像素点的黑白程度分为0-255,其中纯黑就是0,纯白就是255,然后根据这个一张图片就被读取为一个矩阵了,下面我们开看下这个的读取结果。
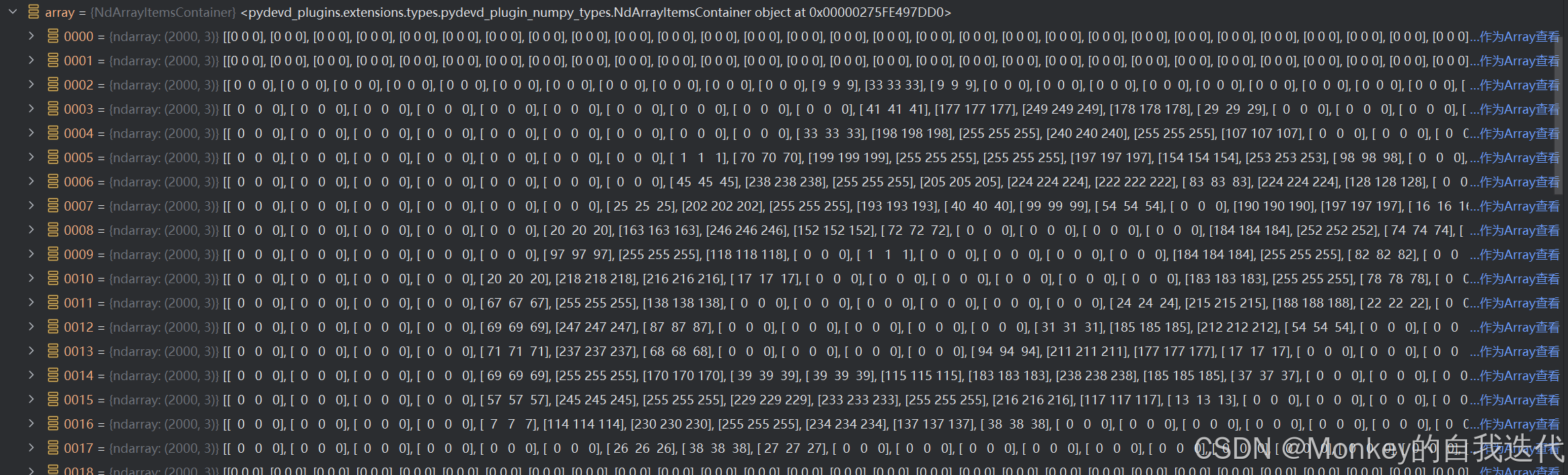
我们可以隐约看到,255连成的区域好像一个0,刚好对应这我们开头的第一个手写0。
他的维度是(1000, 2000, 3),与我们刚开始说的像素点也符合。
2 灰度图处理
gray=cv2.cvtColor(tp,cv2.COLOR_BGR2GRAY)这一步是将RGB图转化为黑白的了。这个可能不明显,在矩阵上面可以看到矩阵由0,0,0->0
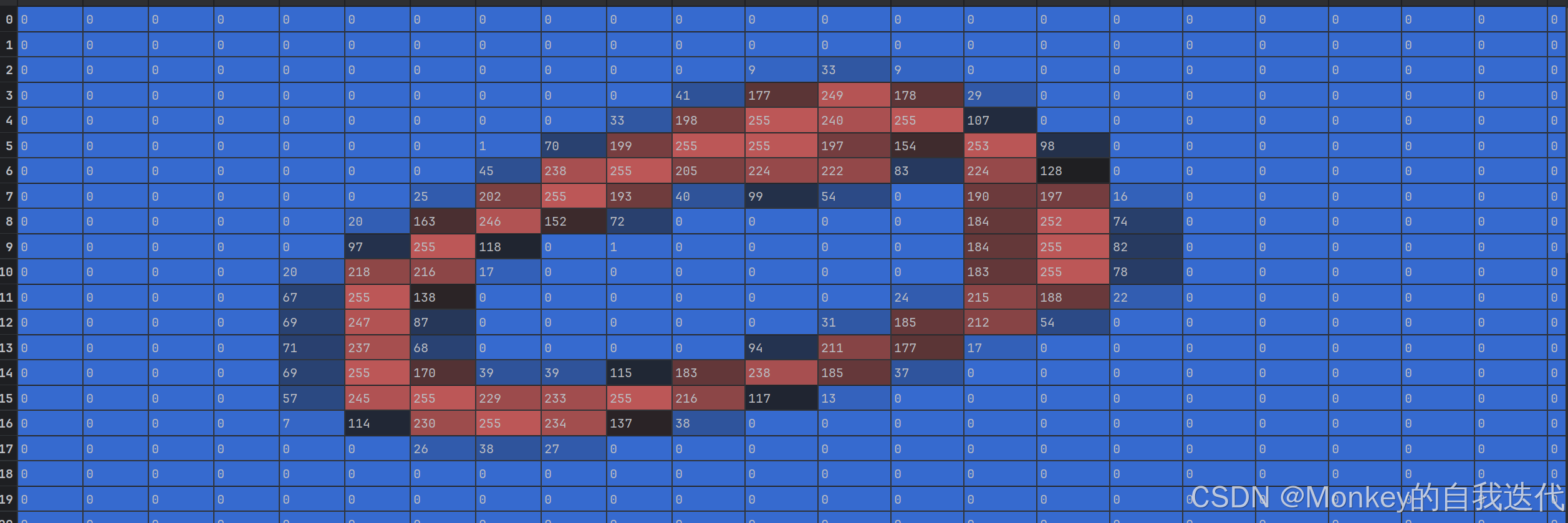 这样是不是就非常明显了。维度从(1000, 2000, 3)变成了(1000, 2000, 1)
这样是不是就非常明显了。维度从(1000, 2000, 3)变成了(1000, 2000, 1)
3 矩阵切割
cell=[np.hsplit(i,100) for i in np.vsplit(gray,50)]我们知道,训练的时候我们要对每一个数字进行训练,但现在那么多数字在一张图片上我们怎么训练呢,所有我们要先切割一下。由于我们这都是设计好的,每个数都是平均分配的像素,我们可以数一下 每行有100个数字,每列有50个数字,而且是平均分的,由此我们可以先对矩阵垂直平均分割(行分)为50行,然后再对每行水平分割(列分)为100列,就会把每个数组存在一个矩阵中了。
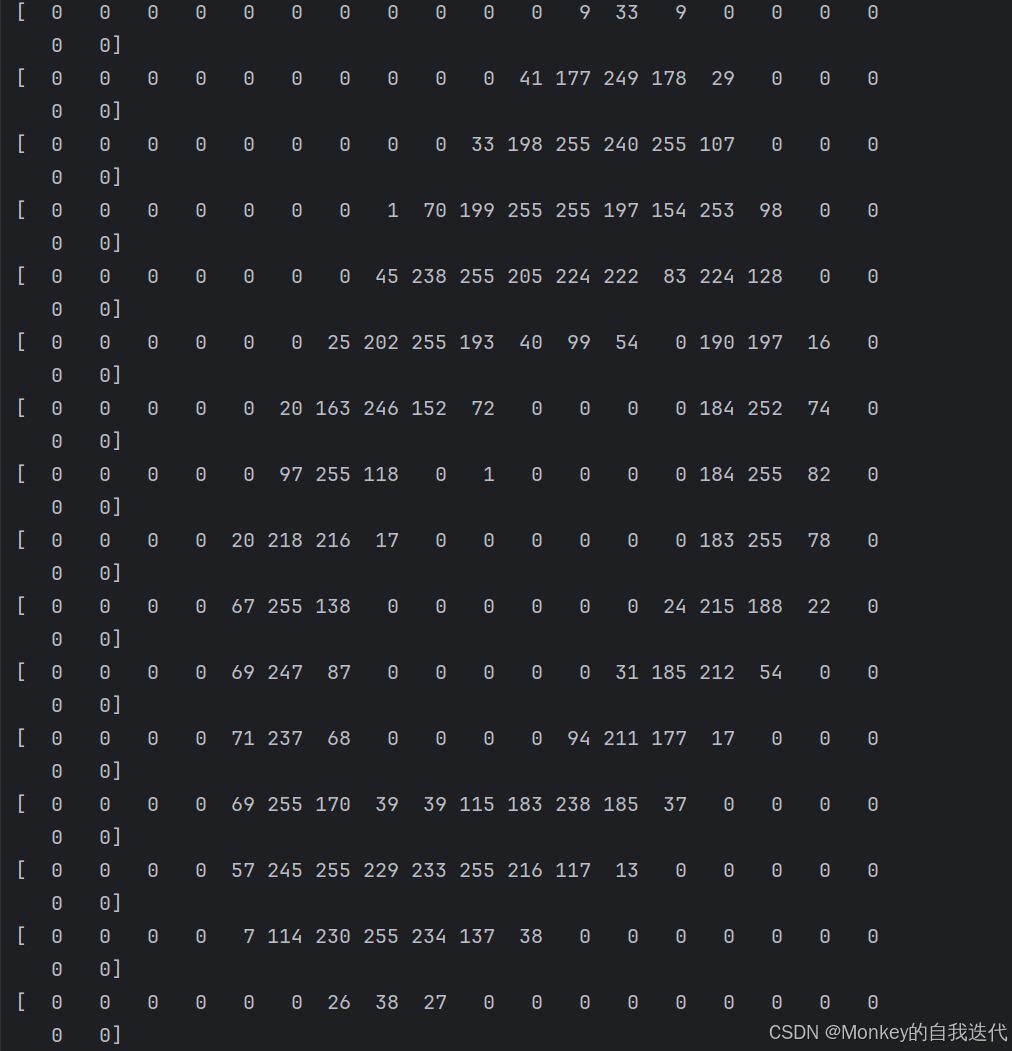
这里是第一张图片的读取结果。
4 转化为ndarry矩阵
data=np.array(cell)我们知道矩阵的计算比列表的计算快许多倍,所有我们把矩阵转化为列表再进行计算。
这下我们也可以清晰查看每个数字的具体矩阵
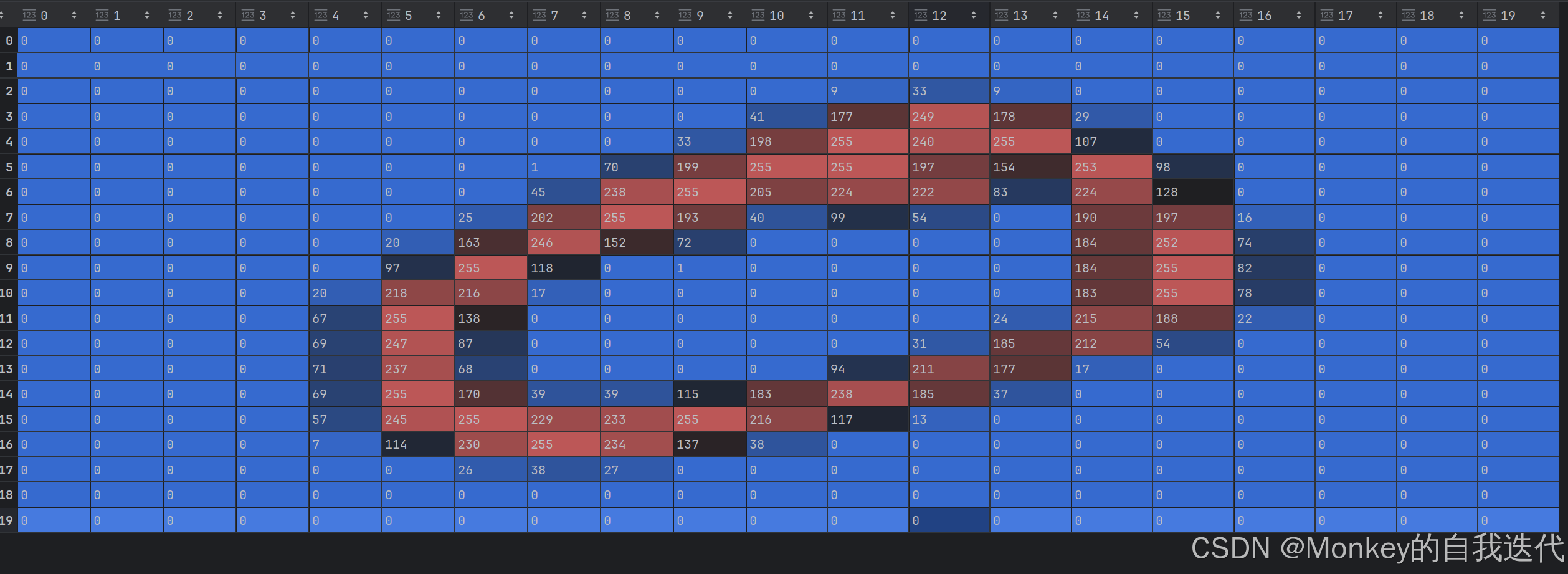
5 训练集和测试集划分
trainx=data[:,:50,:]
testx=data[:,50:,:]这里我们是对数据进行了55分,我们也可以进行其他比例的划分。
6 转化数据维度和类型
train_x=trainx.reshape(-1,400).astype(np.float32)
test_x=testx.reshape(-1,400).astype(np.float32)我们先把我们每张图片的维度转化为一维的并且将int型转化为浮点型,因为我们计算不能以以多维的矩阵进行计算,我们要以以为的矩阵来计算。然后转化为浮点数,是为了让后面距离计算的时候精度更细一点。
7 创建标签集
k=np.arange(0,10)
# print(k)
train_y=np.reshape(np.repeat(k,250),(-1,1))
test_y=np.reshape(np.repeat(k,250),(-1,1))现在我们有数据了,但是我们还没有标签,但是我们不能一个一个手敲出来标签吧,如果数据比较复杂没办法那就要手敲了,但现在我们注意到数据比较有规律。例如训练集的,前250个全部是0,然后下面250个全部是1,所以我们可以根据这个特点来创造,首先先创造出一个0-9的一维矩阵,然后repeat,这个函数功能是将矩阵中的每一个元素重复若干次。
这里后面还把我们矩阵转化为了一列n行的一个矩阵,刚开始我们1维n列的矩阵不好一一对应,转化为n行一列更好。
8 模型训练
from sklearn.neighbors import KNeighborsClassifier
model=KNeighborsClassifier(n_neighbors=8)
model.fit(train_x,train_y)这里我们创建了一个KNN分类器的一个模型你。然后导入了训练集进行训练
9 模型准确率
result1=model.score(test_x,test_y)
print(result1)我们这里导入了测试集对前面训练好的模型进行了一个评估。结果0.9152,说明准确率为91.52%感觉还是很高的。
10 应用模型
我们训练好了我们的模型下面我们该如何能实践用起来呢
new=cv2.imread('test1.png')
newgray=cv2.cvtColor(new,cv2.COLOR_BGR2GRAY)
# print(newgray.shape)
new1=np.reshape(newgray,(-1,400))
# print(new1.shape)
result2=model.predict(new1)
print('识别结果:',result2)我们先导入一张我们要测试的图片
然后像前面一样,imraed读取图片,灰度图处理,维度转换,用模型测试,然后最终结果就出现了。 识别结果: 1
至此我们的实战就结束了。(老外写的和我们写的数字可能不那么对应,所以对于我们自己的字体检查的可能不是那么准确)