导读
工业异常检测(IAD)从数据准备到模型训练,每一步都需要大量人工介入。现有的通用 Agent 框架(如 openHands、openManus)虽然能写代码,但缺乏工业视觉的领域知识,直接用于 IAD 任务时存在严重幻觉、Agent 间协调差、长流程执行不稳定等问题。
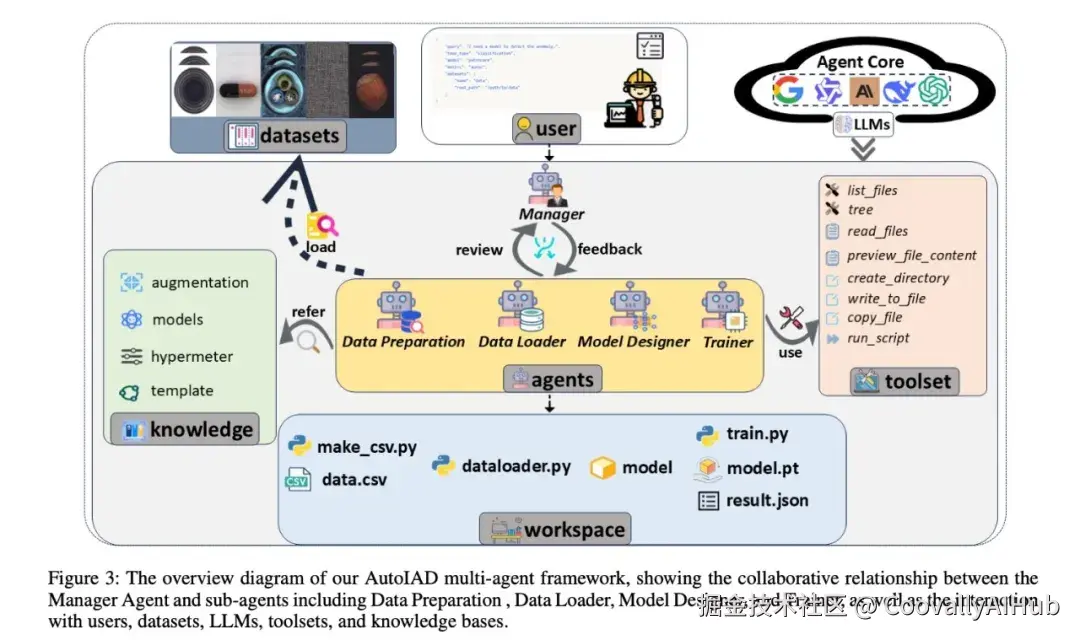
AutoIAD 提出了一种 Manager 驱动的多 Agent 协作框架,专门针对工业异常检测设计:一个 Manager Agent 统筹全局,调度数据准备、数据加载、模型设计、训练四个专业子 Agent,并集成领域知识库提供数据增强策略、模型模板和训练脚本。
在 MVTec AD 数据集的 15 个建模任务上,AutoIAD 以 88.3% 的任务成功率 和 63.69% 的平均 AUROC显著超越 openHands(73.3%、53.88%)和 openManus(50.0%、48.09%),通用 AutoML 框架(MLAgent-Bench、AutoML-Agent)则完全失败(0%)。消融实验表明,去掉 Manager Agent 后 AUROC 从 63.69% 骤降至 35.01%,去掉领域知识库后成功率从 88.3% 降至 60.0% 且 AUROC 归零。本文将拆解 AutoIAD 的架构设计、实验结果与关键发现。
论文标题:AutoIAD: Manager-Driven Multi-Agent Collaboration for Automated Industrial Anomaly Detection
作者:Dongwei Ji, Bingzhang Hu, Yi Zhou 机构:东南大学(教育部新一代人工智能技术及其跨学科应用重点实验室)、合肥中科迪宏自动化有限公司 发表:arXiv:2508.05503 代码:github.com/ji2814/Auto...
一、通用 Agent 做工业视觉任务,为什么不行?
工业异常检测的完整流程包括:数据探索与预处理、数据增强与加载、模型选择与设计、训练与调参评估。这条流水线环节多、领域知识密集------需要知道哪些数据增强策略适合工业图像,哪些模型架构(重建型、特征嵌入型、归一化流)适合不同缺陷类型。
现有通用 Agent 框架的问题在于:
- 严重幻觉:不了解 IAD 领域的模型和数据规范,容易生成无法运行的代码
- Agent 间协调差:多步骤之间缺乏有效的质量控制和输出验证
- 长流程执行脆弱:没有领域约束的长序列任务容易偏离目标
实验数据直接证明了这一点:MLAgent-Bench 和 AutoML-Agent 在 15 个 MVTec AD 任务上的成功率为 0%------完全无法完成工业异常检测的端到端流程。
二、Manager + 四个子 Agent:怎么分工协作?
AutoIAD 采用 "一个管理者 + 四个专家" 的架构:
 图片来源于原论文
图片来源于原论文
Manager Agent(中央调度)
Manager 是整个系统的大脑。它接收用户的高层任务描述(通过 TaskCard 定义:任务类型、模型名称、评估指标、数据集路径),将其分解为可执行的子任务,分配给对应的子 Agent,并对每个子 Agent 的输出进行质量验证。如果输出不达标,Manager 会启动迭代修正。
四个专业子 Agent
| 子 Agent | 职责 | 关键能力 |
|---|---|---|
| Data Preparation | 将原始数据集转换为标准 CSV 格式 | 探索目录结构、分析元数据 |
| Data Loader | 创建 PyTorch 兼容的数据加载器 | 随机拆分、数据增强策略 |
| Model Designer | 从领域模板中选择/设计 IAD 模型 | 迭代调试、确保架构可用 |
| Trainer | 管理超参调优、训练迭代、检查点保存 | AUROC 评估、性能优化 |
四个子 Agent 共享一个工作空间,各自完成任务后更新状态,Manager 持续监控直到系统达到终止条件。
 图片来源于原论文
图片来源于原论文
三、领域知识库:让 Agent 不再"瞎猜"
AutoIAD 的领域知识库包含三个核心组件:
1. 数据增强策略库
预定义了适合工业图像的增强方法:resize、水平翻转、高斯噪声等。
2. 结构化模型定义
提供三类 IAD 模型的标准化模板:
- 重建型模型(如 GANomaly)
- 特征嵌入型模型(如 PatchCore)
- 归一化流模型
子 Agent 不需要从零设计模型架构,而是基于模板进行适配。
3. 标准化训练脚本与超参指导
包含经过验证的训练流程和超参数优化策略,确保训练过程的稳定性。
消融实验证明了知识库的关键作用:去掉知识库后,即使任务能完成(60.0% 成功率),产出的模型 AUROC 为 0------流水线跑通了,但训练出来的模型完全无效。
四、消融实验与对比:通用框架、LLM 后端和核心组件的影响
与通用框架的对比
在 Gemini-2.5-Flash 作为后端的条件下,AutoIAD 与四个基线系统的对比:
| 系统 | 成功率 | AUROC (%) |
|---|---|---|
| MLAgent-Bench | 0% | --- |
| AutoML-Agent | 0% | --- |
| openManus | 50.0% | 48.09 |
| openHands | 73.3% | 53.88 |
| AutoIAD | 88.3% | 63.69 |
通用 AutoML 框架完全失败,通用代码 Agent 能部分完成但模型质量差,AutoIAD 在成功率和模型性能上都显著领先。
不同 LLM 后端的表现
| LLM 后端 | 成功率 | AUROC (%) |
|---|---|---|
| Gemini-2.5-Flash | 88.3% | 63.69 |
| Qwen-Max | 77.8% | 25.71 |
| Claude-3.7-Sonnet | 63.3% | --- |
| Qwen3-235B | 50.0% | 28.65 |
| GPT-4o-Mini | 43.3% | 25.00 |
| DeepSeek-v3 | 37.8% | 0.0 |
Gemini-2.5-Flash 在代码生成和工具编排能力上表现最优。不同 LLM 后端的表现差异很大,说明框架的实际效果高度依赖底层模型能力。
单品类结果(Gemini 后端)
| 品类 | 成功率 | AUROC (%) |
|---|---|---|
| Carpet | 4/4 | 98.15 |
| Tile | 4/4 | 89.91 |
| Metal Nut | 4/4 | 85.48 |
| Transistor | 4/4 | 79.30 |
| Hazelnut | 4/4 | 75.36 |
| Bottle | 4/4 | 0.0 |
部分品类(如 Carpet 98.15%)效果很好,但 Bottle 品类虽然任务完成却 AUROC 为 0,说明框架在某些缺陷类型上仍有失败模式。
消融实验
| 配置 | 成功率 | AUROC (%) |
|---|---|---|
| 完整 AutoIAD | 88.3% | 63.69 |
| 去掉 Manager Agent | 83.3% | 35.01 |
| 去掉领域知识库 | 60.0% | 0.0 |
- Manager Agent对成功率影响不大(-5%),但对模型质量至关重要(AUROC 近乎腰斩),说明 Manager 的核心价值在于输出验证和迭代修正,而非任务分解本身
- 领域知识库对成功率和模型质量都至关重要,没有领域知识的 Agent 即使跑通了流水线,也训练不出有效模型
五、总结与个人点评
AutoIAD 是专门为工业异常检测设计的多 Agent 自动化框架,核心贡献在于:
- Manager 驱动的多 Agent 架构:Manager 负责任务分解、子 Agent 调度和输出质量控制,四个子 Agent 各司其职覆盖数据→模型→训练全流程
- 领域知识库的关键作用:通用 Agent 在工业视觉上的失败,根本原因是缺乏领域知识。AutoIAD 通过知识库将增强策略、模型模板、训练脚本注入 Agent,解决了"通用但不专业"的问题
- LLM 后端选择至关重要:同一框架在不同 LLM 上的表现差异巨大(成功率从 37.8% 到 88.3%),工具编排和代码生成能力是瓶颈
值得注意的局限性:
-
63.69% 的平均 AUROC 仍有提升空间,且品类间差异大(Carpet 98.15% vs Bottle 0.0%),AutoIAD 目前更适合作为快速原型工具而非生产级方案
-
部分品类(Bottle)完全失败,说明框架对某些缺陷类型的泛化能力不足
-
Token 消耗量大(Gemini 后端平均超 150 万 completion tokens),运行成本较高
