在机器学习中,Mutual Information(互信息) 是一种用于衡量两个变量之间相关性或依赖性 的统计量。它描述了一个变量中包含了多少关于另一个变量的信息 ,广泛用于特征选择、信息增益计算等任务。
一、互信息的定义
互信息(Mutual Information, MI)基于信息论,衡量随机变量 和
的信息共享程度:
其中:
:联合概率分布
:X的边缘分布
:Y的边缘分布
直观解释:
当 和
完全独立时,
,此时
当 能完全决定
时,互信息越大
二、直观理解
互信息衡量"减少不确定性" :知道 的值后,能减少多少对
的不确定性?
它可以看作是熵(Entropy)的差值:
其中:
:
的熵(不确定性):
:已知
后
的条件熵(剩余不确定性):
如果 对
提供了很多信息,则条件熵会降低,互信息值就大。通俗来讲的话:就是
发生的概率减去在已知
发生时
发生的概率。
利用韦恩图表示为:
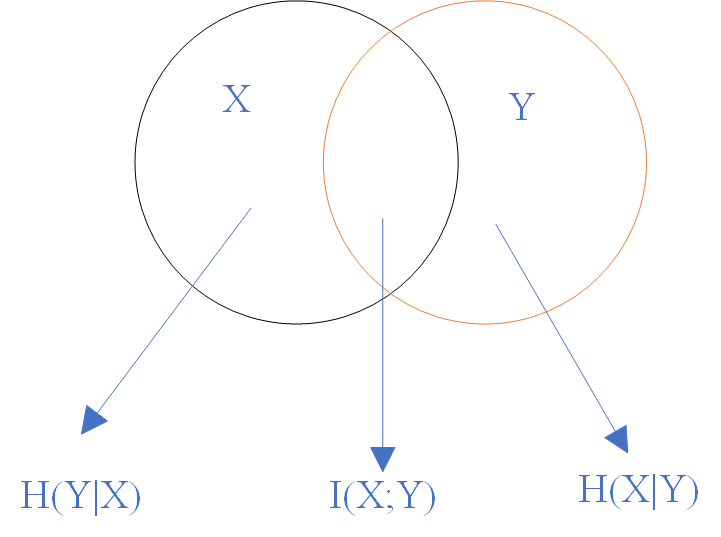
三、特征选择中的应用
在机器学习中,互信息常用于衡量特征与目标变量之间的关联度,尤其适合非线性关系。
示例:
假设要预测患者是否患病(: 0/1),并有以下特征:
-
年龄(
)
-
血压(
-
邮编(
我们可以计算:
如果 ,说明邮编与疾病无关,可以舍弃。
如果 和
较大,则应保留。
四、与相关系数的区别
相关系数 (如皮尔逊相关):只衡量线性关系。
互信息 :能捕捉任意关系(包括非线性),更通用。
例如:
的情况下,皮尔逊相关系数 ≈ 0(因为非线性),但互信息
(存在强关系)。
五、在Python中计算互信息
Scikit-learn 提供了互信息计算工具:
python
from sklearn.feature_selection import mutual_info_classif, mutual_info_regression
import pandas as pd
from sklearn.datasets import load_iris
# 以鸢尾花数据为例
data = load_iris()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
# 分类问题使用 mutual_info_classif
mi_scores = mutual_info_classif(X, y)
print("互信息分数:", mi_scores)输出的分数越高,说明该特征与目标变量关系越强。