前文讲解了机器学习的算法、数据预处理、特征工程、交叉验证和网格搜索等,本章主要介绍对前文所介绍知识的应用,如利用Pipeline类建立管道模型,将机器学习的流程打包到一起;对文本数据进行进一步处理;对真实数据集进行处理等。
9.1管道模型
机器学习的构建步骤包括对数据集进行训练、进行预处理、进行特征选取和利用算法建立模型评估等。上面4个步骤构成一个流水式的流程,而管道模型则实现了对全部步骤的流式化封装和管理。
那么不使用管道不行吗?有些时候确实不行。假设利用make_blobs数据集生成标准差为5的数据集,然后进行处理。

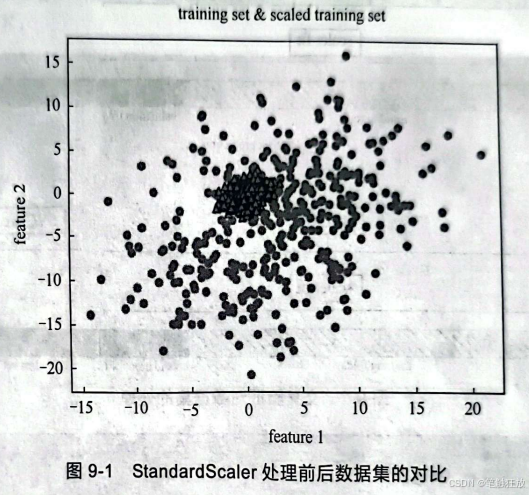
对数据进行预处理是为了算法能够更好地建立模型,下面加入SVM算法。代码如下:

经过网格搜索得到的精度达到了约95%,但其实上述步骤中出现了错误。在进行数据预处理的时候,用StandardScaler拟合了训练集scaler,再用这个拟合后的scaler去分别转换了X_train、X_test,这一步没有错。
但在进行网格搜索的时候,用GridSearchCV来拟合训练集在进行交叉验证的时候,对train_scaled进行了拆分,这时的 train_scaled基于训练集用StandardScaler拟合后再对自身进行转换,相当于用StandardScaler拟合了交叉验证中生成的旁试集后,再用scaler转换这个测试集,如图9-2所示。
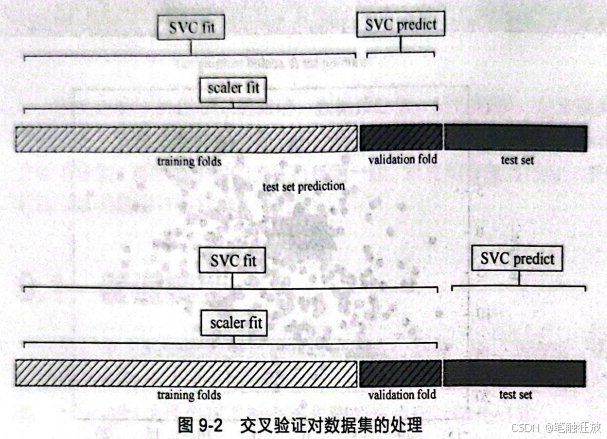

从图9-2中可以看到,这样的做法是错误的,交叉验证的得分是不准确的。为了解决这个问题,在交叉验证的过程中,应该在进行任何预处理之前完成数据集的划分。那怎么在预处理之前完成数据集的划分呢,显然一次次划分太麻烦,因此就需要用到管道模型。那么如何建立管道模型呢,在sklearn库中存在Pipeline库,导入之后就能使用了。代码如下:

建立管道模型还有一个简单的方法,就是利用make_pipelineO函数:


建立管道模型后,对比之前数据预处理以及算法建模过程,所需的代码量大大减少,接下来就需要避免在预处理过程中使用不当的方式对训练集和验证集进行错误的预处理。通过使用管道模型,可以在网格搜索每次拆分训练集与验证集之前,重新对训练集和验证集进行预处理操作,从而避免模型过拟合的情况。管道配合网格搜索使用,定义一个需要搜索的参数网格,并利用管道和参数网格构建GridSearchCV,然后需要为每个参数指定它在管道中所需的工作步骤。代码如下:
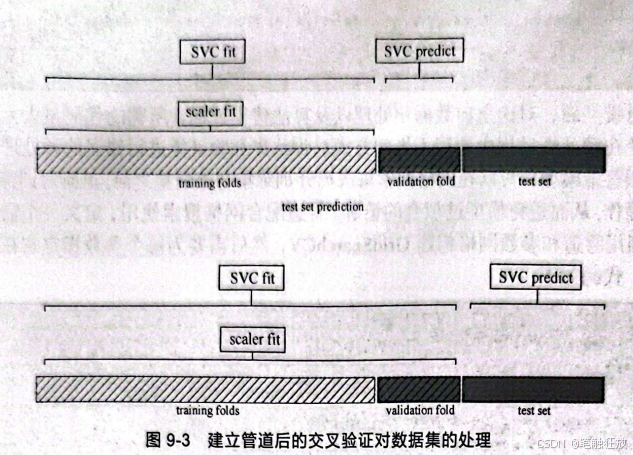
通过在网格搜索中使用管道,解决了进行任何预处理之前完成数据集划分的问题。此时的交叉验证对数据集的处理如图9-3所示。代码如下:

Pipeline类不但可用于预处理和网格搜索,实际上还可用于将任意数量的估计器连接在起,也可用于构建一个包含特征提取、特征选择、缩放和分类的管道。代码如下:
这里在管道中进行了两次预处理,两次预处理属于同一阶段,可以看到管道的工作步骤。根据需要可以将任意数量的估计器都构建到一个管道里。
利用管道还可以创建多分类器的管道。在前文的线性回归内容中,我们知道利用其构建的模型容易产生过拟合,所以需要正则化。接下来利用管道来对两种正则化方式进行选择以及进行参数的调优。代码如下

9.2 文本数据处理
本节是对文本特征提取的补充与扩展。文本数据处理,简而言之就是自然语言处理,是人工智能重要的分支之一。本节将从sklearn和NLTK两个不同的方面对文本数据处理进行讲解。
9.2.1 扩展与深化一不同方式的文本数据处理
前文利用sklearn库简单地介绍了一些关于文本数据处理的知识,例如CountVectorizer、N-Grams、TF-IDF等。下面将对其进行详细介绍。
在拿到文本数据并对其进行处理之前,首先要做的就是将其转换成机器能够看懂的机器语言。文字只是表达我们所说内容的载体,其所适用的对象仅限于人类。例如,拿着一段中文文本让一个从未见过或者听过中文的外国人看懂,这是强人所难的。
那如何才能将文本数据翻译成机器语言呢?第一步是对文本进行分词,把一段话或者一句话中所要表达的主要意思提取出来。例如,"今天是星期一,我要去上学"这句话,完成分词操作后将会变成"今天""是""星期---""我""要去""上学"。将一段话或者一句话,拆分成基本单元,这就是分词操作。
对于英文文本,可以借助正则化进行分词,而对于中文文本,多用jieba进行分词。对于英文文本,虽然可以通过正则化对文本进行分词,但如何删去冗余的停止词,是令我们头疼的操作。
1.利用sklearn对英文文本进行分词 例如,有下面这样一段英文文本。 Life is a chess-board The chess-board is the world: the pieces are the phenomena of the universe; the rules of the game are what we call the laws of nature. The player on the other side is hidden from us. We know that his play is always fair, just and patient. But also we know, to our cost, that he never overlooks a mistake, or makes the smallest allowance for ignorance.
对这段文本使用正则化分词:


这里要注意,由于作者是直接在编译器中进行输入的,需要将一整段文本中的字符串分开,因此才会使用正则化。如果用openO直接打开文本,就不需要使用正则化。
- 利用jieba对中文文本进行分词 上面两种方法是sklearm对英文文本的分词方法,可以明显感受到,使用sklearn自带的CountVectorizer来进行分词是优于使用正则化进行分词的。但是sklearn有一个弊端就是不能对中文文本进行分词,需要加载额外的库jieba来对其进行分词。下面来看如何使用jieba对中文文本进行分词。
jieba作为Python的第三方库,本身可以用Python自带的pip进行下载和安装。按<Win+R>组合键打开命令提示符窗口,输入如下代码:

用jieba进行分词,主要利用了jieba的cutO函数。cutO主要有3种模式,包括精确模式、全模式和搜索引擎模式。下面分别对其进行介绍。
(1)精确模式
精确模式在不影响文本大意的前提下,尽可能地将句子精确切开,此时cutO的参数cut_all应为 False.


(3)搜索引擎模式 搜索引擎模式在精确模式的基础上,对比较长的词语进行划分,以提高分词的召回率,这也是在搜索引擎上常用的一种方法。

当然jieba是没有内置的停止词库的,如果需要删除停止词还需要读者自行构建或者导入停止词库。
- 利用NLTK 对文本进行分词 NLTK是自然语言处理工具包,在自然语言处理领域中是常使用的Python库之一。这里以英文文本为例,对NLTK库的使用进行讲解。如何对中文文本进行分词作为扩展的内容,有需要的读者可以自行学习和了解。
按<Win+R>组合键打开命令提示符窗口,输入"pip install nltk"进行安装,安装完成后,打开 PyCharm输入如下代码:

然后下载所需的组件进行安装。
NLTK 较 sklearn 的分词方式有两大优势:一是 NLTK 支持整段文本句子化,可利用sent_tokenize(来对整段文本进行分句;二是NLTK支持段落直接分词,而不是先将其分成句子,然后分词。
利用 sent_tokenize)进行分句:


有读者可能会问,为什么分完词之后那些标点符号以及一些无用的词语没有被去掉呢?这就涉及下面要讲的NLTK停止词的使用(关于分词操作,使用sent tokenizeO将文章分为句子后也可以进行分词操作,这里不再进行讨论)。
- NLTK停止词的使用
第7章已经对停止词做了详细的介绍,读者可以到第7章自行查看。下面介绍关于NLTK停止词的使用。
由于NLTK内置了停止词库,可以在nltk.corpus里找到它并查看其组成。

共计153个停止词,如果有特殊需要的话,读者也可以自行添加停止词。然后从文本中删除停止词。



9.2.2 文本数据的优化处理
本小节主要是关于如何利用NLTK对文本数据进行优化处理的。由于前文已经讲过sklearn对文本数据优化处理的相关内容,因此此处不再过多叙述。
- 利用NLTK 对文本数据进行优化处理
前文利用NLTK进行了分词操作,将一整篇文章分成若干个独立的基本单元,但是这种简单的分词方式,也会出现一些问题,读者是否想到了呢?来看下面一串代码。
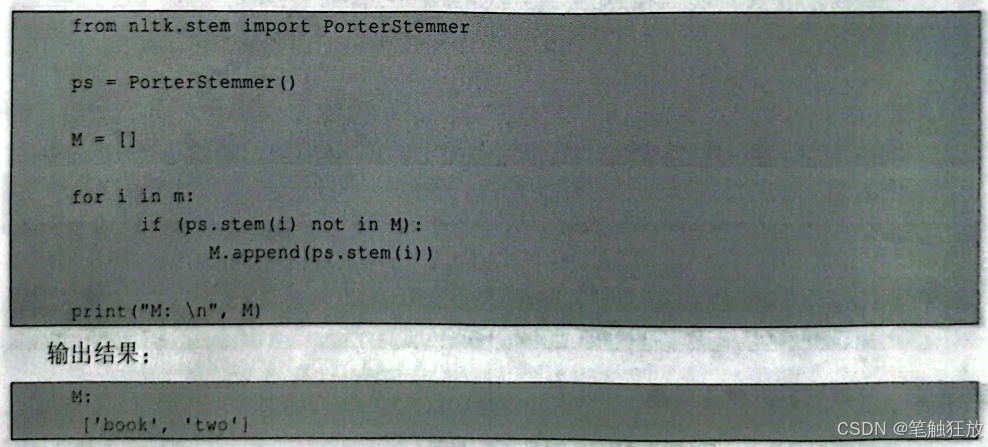
输入"I have a book, but he has two books.",代码如下


看到这里读者是不是明白了呢?,"has""have"和"books""book"这两组单词其实是个单词的不同形式,"has"是"have"的第三人称形式,"books"是"book"的复数形式。这里NLTK的分词默认它们是不同的单词,所以会出现上述的结果。针对这种情况,可以对已经分完词的列表m进行词干提取操作。什么是词干提取呢?顾名思义就是,将一个英文单词的词干提取出来,例如"having"提取词干之后会变成"have","imaging"提取词干之后会变成"image可以利用ntlk.stem中的PorterStemmerO提取词干。
在这里,由于"have"和"has"是停止词,在分词的时候会被过滤掉,因此不必考虑"have和"has"的关系。
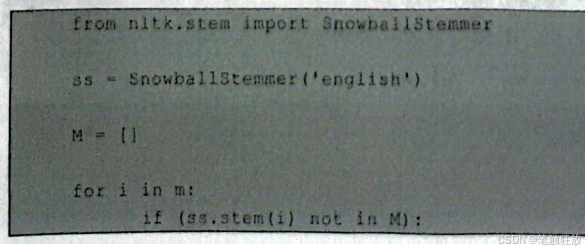
当然,nltk.stem中的 SnowballStemmer(也可以提取词干:

2.利用NLTK进行词性标注
前面已经介绍了如何用NLTK进行分词、筛选停止词和词干提取等,接下来将介绍如何利用NLTK进行词性标注。词性标注就是给已经分完词的单词一个标签,这个标签代表着这个单词的词性。例如"cat",可以给它名词的标签(NN),标记"cat"是一个名词。词性标注的实现主要使用NLTK中的pos_tagO。


这里,关于NLTK各个标签的含义,读者可以在编译器中,输入下面这行代码来进行查看,也可以去NLTK的官网查看。NLTK的标签、含义和示例如表9-1所示。
- 利用NLTK 进行词形还原
有时候,仅利用词干提取来还原单词是不够的,而且词干提取经常会创造一些字典上并不存在的"新单词",这也是词干提取和词形还原的最大差别。所谓词形还原,就是在实际的单词基础上进行的还原,而不会凭空创造出新单词。词形还原所用到的是 nltk.stem 中的WordNetLemmatizer,下面会将其和词干提取一起进行演示。代码如下:


通过对比可以发现,进行词性标注的词形还原比没有进行词性标注的词干提取的效果好了不知多少。从词干提取输出的"mistak"这个错误中,能够明显看出没有进行词性标注而直接贸然提取词干,会产生很多不存在的单词及一些不想要的单词,从而引发错误。
9.3 泰坦尼克号数据分析
本节将进入实战项目,对泰坦尼克号数据进行建模,并对测试集测试乘客是否生存。泰坦尼克号数据集是Kaggle算法平台提供的经典数据集,可以从官方网站中下载该数据集。
Kaggle算法平台提供了大量形状、大小、格式各异的真实数据集,每个数据集都有对应的一个社区,可以供学习者们相互交流。
如图9-4所示,进入官方网站后找到搜索索引。

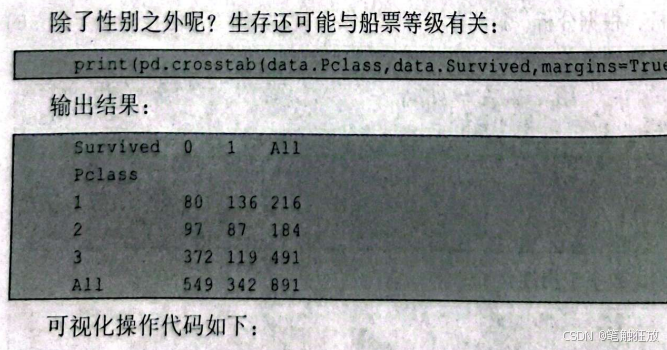
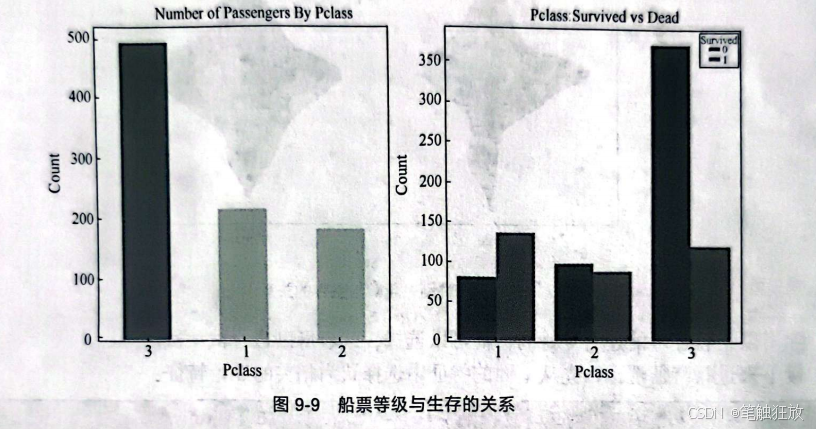
然后下载泰坦尼克号数据集,从图9-6所示页面还能看到数据集的Detail(详情入Compact(参数数组)、Column(柱状图),可以观察数据集的详细信息。表9-2所示为泰坦尼克号数据集中的所有字段以及描述。



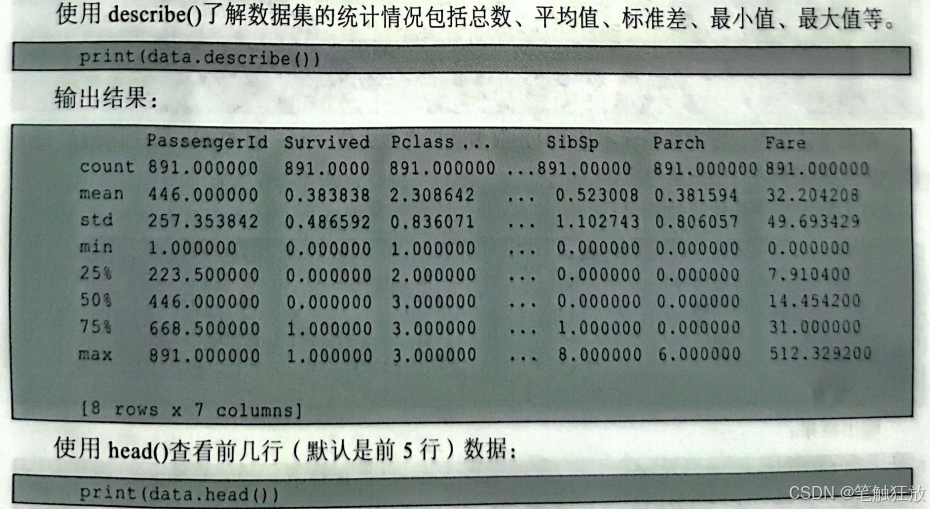
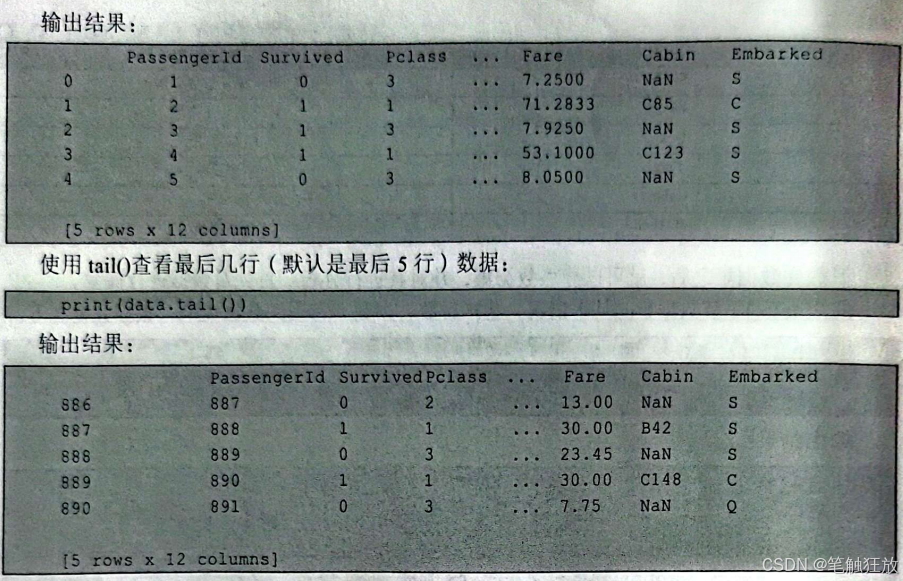

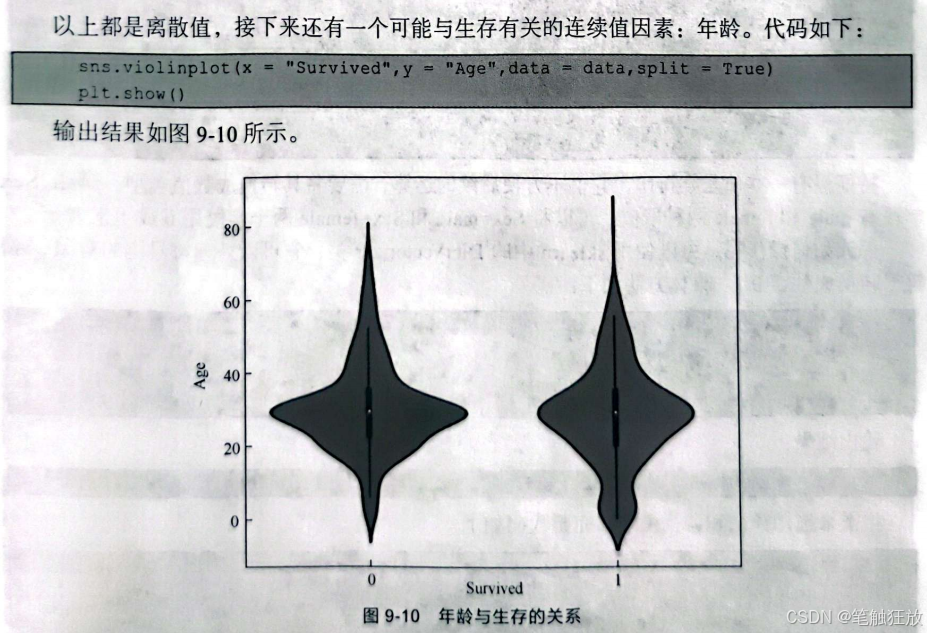
根据上述信息,发现数据大小是891,很多数据有缺失值,Age和Cabin缺失比较严重,接下来对数据集进行缺失值补全。对年龄采用平均值进行补全:
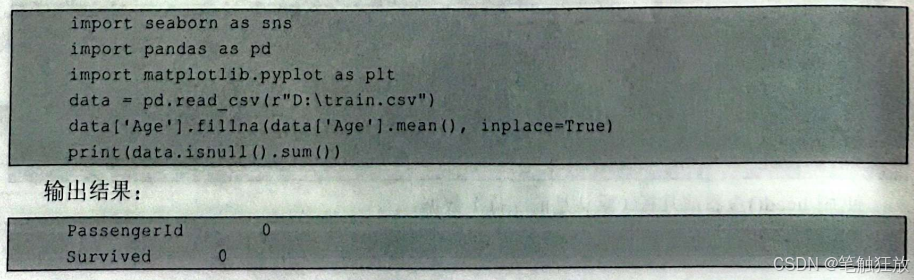

从输出结果中可以看到大部分值都是S,因此缺失值补全为S:

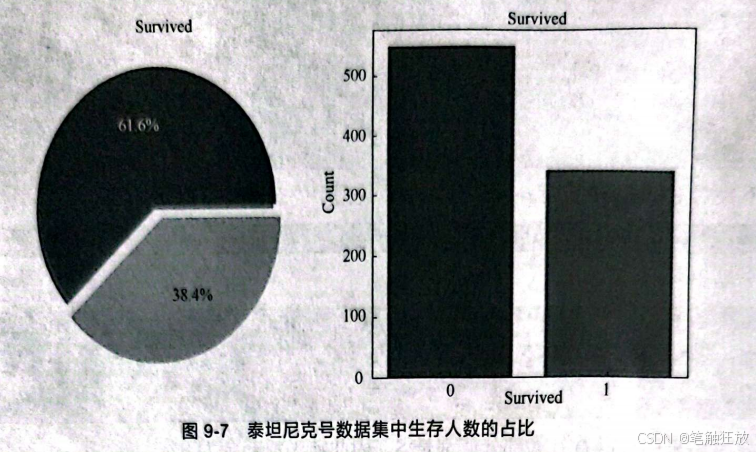
Cabin特征的值缺失太多,假设是否能够生存与船舱号无关,然后查看数据集中生存人数的占比:
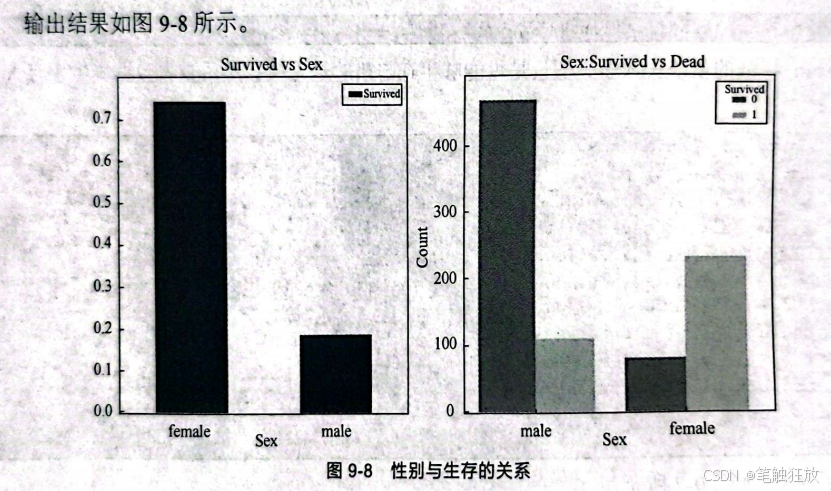
接下来对特征进行分析,根据分析,猜测存活可能与什么有关?因为可能存在女士优先的原则,所以猜测生存可能与性别有关。



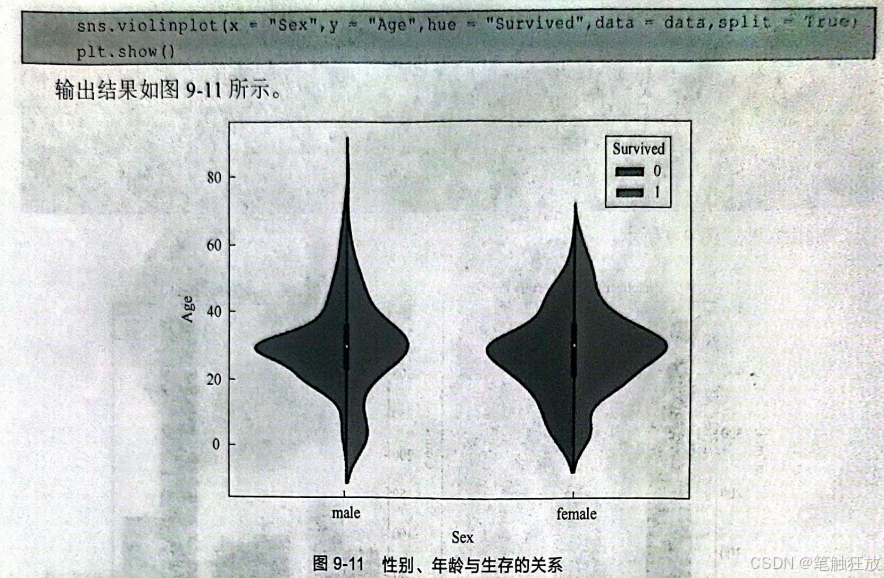
9.4 小结
本章首先介绍了管道模型的概念和管道模型的用途,并利用Pipeline类建立了管道。然后在网格搜索中使用了管道,还介绍了如何利用make_pipelineO函数更加简洁地建立管道。接下来介绍了如何在管道中创建多个估计器和分类器,以及利用网格搜索选择合适的参数。然后介绍了关于利用sklearn和NLTK进行文本数据处理的内容,没有列举一些很复杂的知识,只讲解了一些关于sklearn和NLTK的基本操作。如果读者还想了解更多的话,建议通过sklearm和NLTK的官网学习。最后介绍了关于泰坦尼克号数据集的实战。
习题 9
1.什么是管道模型?
2.利用管道将任意数量的估计器连接在一起并运用。
3.通过管道实现模型的选择与调优。
4.jieba库的cut(函数有几种模式?分别有什么作用?
5.利用其他算法对泰坦尼克号数据集建立模型。