Antlr4入门学习及实用案例(二)
ANTLR4 (ANother Tool for Language Recognition) 是一个功能强大的解析器生成器,可以用来读取、处理、执行或格式化结构化文本或二进制文件。它被广泛用于构建语言、工具和框架。
常用的一些语法
上一篇文章中我们了解了 ANTLR4 基础使用,ANTLR4 提供了许多非常实用的语法特性,这能帮助开发者写出更简洁、更强大、更易于维护的 .g4 语法文件。
这里作一个简要地总结,以帮助初学者了解一些常用的语法规则及格式。
元素标签 (Element Labels)
在 ANTLR 的语法规则中,可以为匹配的元素(无论是一个expr规则还是一个Token词法单元)起一个别名。
这个语法格式是:labelName(别名)= element ,将匹配到的 element 实例进行命名。
规则标签 (#label)
允许开发者为语法规则中的分支添加标签,可在 Visitor/Listener 中为每个标签生成更精确的独立访问方法。
java
expr:
left=expr op=('*'|'/') right=expr # MulDivExpr
| INT
;词法命令 (Lexer Commands)
这些命令写在词法规则的末尾,使用 -> 符号,用来控制词法分析器的行为。
语法: LEXER_RULE : ... -> command,比如:WS : [ \t]+ -> skip; 跳过处理空格和制表符。
EBNF 风格的量词
ANTLR 支持类似扩展巴科斯范式 (EBNF) 的量词,可以方便地表示"零次或多次"、"一次或多次"以及"可选"。
-
*(星号):零次或多次。例:rule: ID (',' ID)*;匹配一个 ID,后面跟着零个或多个由逗号分隔的 ID (a,a,b,a,b,c) -
+(加号):一次或多次。例:rule: INT+;匹配一个或多个连续的整数 (1,1 2 3) -
?(问号):零次或一次 (可选)。例:rule: 'public'? 'class' ID;public 关键字是可选的 (class A,public class A)
片段规则 (Fragment Rules)
fragment 定义可复用的词法片段,但它本身不生成Token, 适当使用可提高词法规则的复用性和可读性。
语法: fragment NAME: ...;,比如:fragment DIGIT: [0-9]; 定义一个数字片段被其他词法规则引用或组合。
练手的实用案例
支持"代数表达式"的计算器
实现一个支持代数表达式的计算器,使用 ANTLR4 进行语法解析。该计算器将能够处理基本的四则运算、变量赋值、括号优先级以及小数运算。通过构建语法分析树,实现 Visitor 模式来遍历和计算表达式的值。
定义计算器语法
定义该计算器的语法规则,主要流程为处理运算优先级以及执行变量存储等步骤,语法关键流程如下所示:
java
grammar Calculator;
prog: stat+;
stat: expr NEWLINE # Expression
| ID '=' expr NEWLINE # Assign
| NEWLINE # Empty
;
expr: expr op=('*' | '/') expr # MulDiv
| expr op=('+' | '-') expr # AddSub
| number # num
| ID # id
| '(' expr ')' # parens
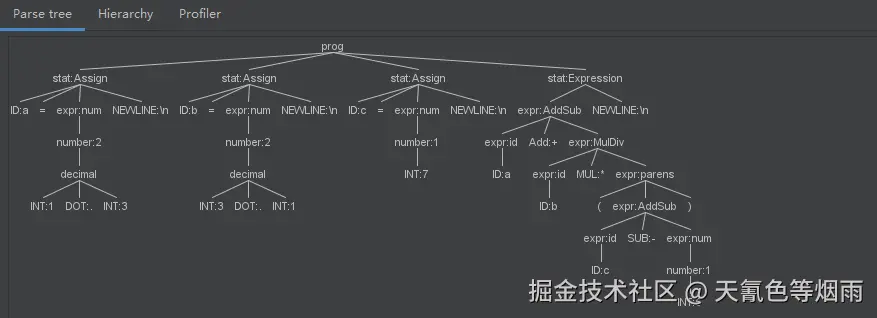
;通过 IDEA 的 ANTLR4 插件,输入如下表达式:
java
a=1.3
b=3.1
c=7
a+b*(c-5)查看 ANTLR 创建的解析语法树,可清晰地查看递归的每一步解析流程,解析结果也是准确的:
实现计算逻辑
语法树遍历时需要处理算术表达式的运算、变量的赋值,主要的实现方法如下:
java
private final Map<String, Number> memory = new HashMap<>();
// # Assign 标签:获取赋值表达式的值,并存入变量
@Override
public Number visitAssign(CalculatorParser.AssignContext ctx) {
String id = ctx.ID().getText();
Number value = visit(ctx.expr());
memory.put(id, value);
return value;
}
// # id 标签:遍历id节点,进行读取变量值
@Override
public Number visitId(CalculatorParser.IdContext ctx) {
String id = ctx.ID().getText();
if (memory.containsKey(id)) {
return memory.get(id);
}
return 0;
}
// # MulDiv 标签:执行乘法或除法的计算逻辑
@Override
public Number visitMulDiv(CalculatorParser.MulDivContext ctx) {
Number left = visit(ctx.expr(0));
Number right = visit(ctx.expr(1));
if (ctx.op.getType() == CalculatorParser.MUL) {
return mathTool.mul(left, right);
}
return mathTool.div(left, right);
}测试运算结果
编写上述表达式的测试用例,执行该计算器的运算,正确完成计算并返回结果值:
java
@Test
public void testAlgebraicCalculate(){
final String expr = "a=1.3\n" +
"b=3.1\n" +
"c=7\n" +
"a+b*(c-5)\n";
Number result = calculate(expr);
assertEquals(7.5, result);
}
private Number calculate(String expr) {
CalculatorLexer lexer = new CalculatorLexer(CharStreams.fromString(expr));
CommonTokenStream tokenStream = new CommonTokenStream(lexer);
CalculatorParser parser = new CalculatorParser(tokenStream);
CalculatorParser.ProgContext tree = parser.prog();
CalculatorEvalVisitor eval = new CalculatorEvalVisitor();
return eval.visit(tree);
}基于Map的内存数据库
解析 SQL 语法是 ANTLR 这类解析器工具的一个重要实现方式,在 Java 生态中,ANTLR4 和 JavaCC 是两种主流的 SQL 解析工具。其中,JavaCC 因被 Apache Calcite 采用而被广泛使用,诸多基于 Calcite 的大数据处理框架(如 Apache Hive、Flink SQL、Spark SQL等)均间接依赖 JavaCC 实现 SQL 解析。
定义 SQL Parser
使用 ANTLR4 定义一个 SimpleSql.g4 语法文件,实现简单的 SQL CRUD 操作,主要语法流程如下:
sql
grammar SimpleSql;
statement: (insertStatement | selectStatement | updateStatement | deleteStatement) ';'? ;
insertStatement:
INSERT INTO tableName=ID '(' columns=idList ')' VALUES '(' values=valueList ')'
;
selectStatement:
SELECT columns=selectList FROM tableName=ID (WHERE whereClause)?
;
updateStatement:
UPDATE tableName=ID SET assignments (WHERE whereClause)?
;
deleteStatement:
DELETE FROM tableName=ID (WHERE whereClause)?
;说明:
- 定义
insertStatement,selectStatement等四个增删改查规则。 whereClause只作简单条件语句的实现,只支持列名 >= 值这种的条件形式。- 词法规则定义关键字(如
INSERT)、标识符(ID)、字面量(STRING,NUMBER)等。
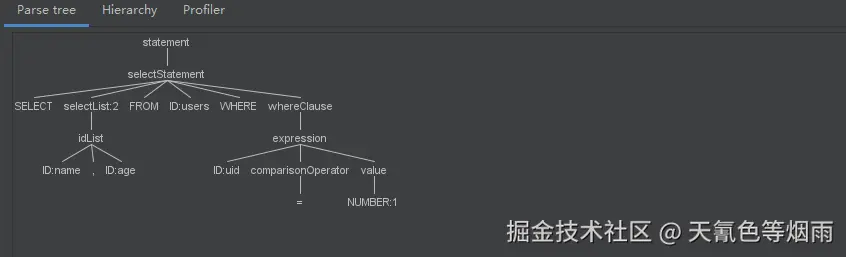
通过 IDEA 的 ANTLR4 插件,输入SQL的查询语句 select name, age from users where uid = 1,查看 ANTLR 创建的解析语法树及SQL解析流程:
实现 SQL CRUD 操作
依然使用 Visitor 模式来遍历语法树,实现对 Map 数据结构的内存数据库进行操作。
模拟数据库结构,使用一个嵌套的 Map 结构表达:
java
// 数据库: Map<表名, 表>
final Map<String, List<Map<String, Object>>> database;实现 Insert 操作,主要逻辑如下:
java
@Override
public Object visitInsertStatement(SimpleSqlParser.InsertStatementContext ctx) {
// 获取表名,如果表不存在则自动创建
String tableName = ctx.tableName.getText();
database.putIfAbsent(tableName, new ArrayList<>());
List<Map<String, Object>> table = database.get(tableName);
// 获取列名字段
List<String> columns = ctx.columns.ID().stream()
.map(ParseTree::getText)
.collect(Collectors.toList());
// 获取VALUES值
List<Object> values = ctx.values.value().stream()
.map(this::visitValue) // 使用 visitValue 方法转换值
.collect(Collectors.toList());
if (columns.size() != values.size()) {
throw new RuntimeException("列的数量和值的数量不匹配!");
}
// 创建新行
Map<String, Object> newRow = new HashMap<>();
for (int i = 0; i < columns.size(); i++) {
newRow.put(columns.get(i), values.get(i));
}
// 插入新行
table.add(newRow);
log.info("表 {} 成功插入1行", tableName);
return 1;
}同理实现 Select 操作:
java
@Override
public Object visitSelectStatement(SimpleSqlParser.SelectStatementContext ctx) {
String tableName = ctx.tableName.getText();
List<Map<String, Object>> table = database.get(tableName);
if (table == null) {
log.info("表 {} 不存在", tableName);
return new ArrayList<>();
}
// 构建WHERE条件的过滤器
Predicate<Map<String, Object>> whereFilter = row -> true; // 默认不过滤
if (ctx.whereClause() != null) {
whereFilter = createPredicate(ctx.whereClause().expression());
}
// 构建行数据的结果集
List<Map<String, Object>> results = new ArrayList<>();
for (Map<String, Object> row : table) {
if (whereFilter.test(row)) {
Map<String, Object> resultRow = new HashMap<>();
if (ctx.columns.getText().equals("*")) {
resultRow.putAll(row);
} else {
SimpleSqlParser.IdListContext idCtx = ctx.columns.idList();
for (org.antlr.v4.runtime.tree.TerminalNode idNode : idCtx.ID()) {
String colName = idNode.getText();
resultRow.put(colName, row.get(colName));
}
}
results.add(resultRow);
}
}
return results;
}其余的 Update、Delete 操作等详细的代码展示在文章末尾的项目仓库链接中,可点击查看具体的实现流程。
测试 SQL 语句
编写 SQL Parser 的测试用例,执行 CRUD 操作,验证 SQL 执行的结果准确性:
java
private final Map<String, List<Map<String, Object>>> database = new HashMap<String, List<Map<String, Object>>>();
@BeforeEach
public void setupTest() {
execute("INSERT INTO users (id, name, age) VALUES (1, 'Alice', 30);");
execute("INSERT INTO users (id, name, age) VALUES (2, 'Bob', 25);");
execute("INSERT INTO users (id, name, age) VALUES (3, 'Charlie', 35);");
}
@Test
public void testSimpleSqlInsert() {
for (Map<String, Object> user : database.get("users")) {
Integer id = (Integer) user.get("id");
if (id == 1) {
assertEquals("Alice", user.get("name"));
assertEquals(30, user.get("age"));
} else if (id == 2) {
assertEquals("Bob", user.get("name"));
assertEquals(25, user.get("age"));
} else if (id == 3) {
assertEquals("Charlie", user.get("name"));
assertEquals(35, user.get("age"));
} else {
fail("Invalid id");
}
}
printResults(database.get("users"));
}
@Test
public void testSimpleSqlSelect() {
String expr = "select * from users where id = 1";
List<Map<String, Object>> users = (List<Map<String, Object>>) execute(expr);
assertEquals(1, users.size());
assertEquals(1, users.get(0).get("id"));
assertEquals("Alice", users.get(0).get("name"));
assertEquals(30, users.get(0).get("age"));
printResults(users);
}
@Test
public void testSimpleSqlSelect2() {
String expr = "select name, age from users where id = 1";
List<Map<String, Object>> users = (List<Map<String, Object>>) execute(expr);
assertEquals(1, users.size());
assertNull(users.get(0).get("id"));
assertEquals("Alice", users.get(0).get("name"));
assertEquals(30, users.get(0).get("age"));
printResults(users);
}
@Test
public void testSimpleSqlUpdate() {
String expr = "update users set name = 'Dylan' where id = 1";
Object result = execute(expr);
assertEquals(1, result);
assertEquals("Dylan", database.get("users").get(0).get("name"));
printResults(database.get("users"));
}
@Test
public void testSimpleSqlDelete() {
String expr = "delete from users where id = 1";
Object result = execute(expr);
assertEquals(1, result);
assertEquals(2, database.get("users").size());
assertEquals(2, database.get("users").get(0).get("id"));
printResults(database.get("users"));
}
private Object execute(String expr) {
SimpleSqlLexer lexer = new SimpleSqlLexer(CharStreams.fromString(expr));
CommonTokenStream tokenStream = new CommonTokenStream(lexer);
SimpleSqlParser parser = new SimpleSqlParser(tokenStream);
SimpleSqlParser.StatementContext tree = parser.statement();
SimpleSqlEvalVisitor eval = new SimpleSqlEvalVisitor(database);
return eval.visit(tree);
}运行测试类,方法成功执行通过,可看到如下输出,清晰地展示了 HashMap 如何根据 SQL 语句被执行增、删、改、查操作:

小总结
在本篇文章中,我们使用 ANTLR4 实现了两个小案例。ANTLR 十分强大,我们可以自定义各种语法规则来实现复杂的业务逻辑,通过学习 ANTLR4 ,可以帮助我们更好理解各类开源组件库的源代码逻辑,也可以帮助我们构建符合业务流程的动态规则引擎的实现。
希望本文能够激发你对 ANTLR4 的兴趣,并在探索技术的旅程中提供有价值的参考。
简介 - ANTLR 4 简明教程 - 开发文档 - 文江博客
antlr4/doc/parser-rules.md at master · antlr/antlr4 · GitHub
文章案例项目代码:antlr4-simple-demo