深度解析GPT-5的革命性推理能力,包括o3架构技术原理、System 2思维实现、实际应用场景和成本分析。IMO金牌水平,ARC-AGI测试87.5%,预计2025年8月发布。
GPT-5推理能力全解析:o3架构、链式思考与2025年8月发布
GPT-5集成o3架构,通过链式思考和模拟推理实现人类专家级推理。在国际数学奥林匹克获金牌水平,ARC-AGI测试达87.5%。预计2025年8月发布,ChatGPT Plus用户可使用。

GPT-5推理能力有多强?最新基准测试数据揭秘
OpenAI在2025年1月发布的o3模型已经展现出惊人的推理能力,而即将到来的GPT-5将把这种能力推向新的高度。根据最新的基准测试数据,GPT-5的推理表现已经达到甚至超越了人类专家水平。在国际数学奥林匹克(IMO)竞赛中,GPT-5获得了35/42分的成绩,这相当于金牌水平,要知道全球只有不到0.1%的数学天才能够达到这个成绩。更令人震惊的是,在ARC-AGI抽象推理测试中,GPT-5在高推理模式下达到了87.5%的准确率,这项测试被认为是衡量人工智能是否真正理解概念的黄金标准。
在编程能力方面,GPT-5同样表现卓越。在Codeforces编程竞赛平台上,GPT-5的Elo评分达到2727分,这意味着它的编程能力超过了99.2%的人类程序员。相比之下,GPT-4的Elo评分仅为1800分左右,o1模型约为2200分。这种飞跃式的进步不仅体现在分数上,更重要的是GPT-5能够解决更复杂的算法问题,包括动态规划、图论和数论等高难度题目。对于需要强大AI编程助手的开发者,除了GPT-5,还可以考虑阿里的Qwen3 Coder API作为补充方案。在GPQA-Diamond科学问答测试中,GPT-5的准确率达到78.2%,而人类专家的平均水平约为80%,这表明GPT-5已经接近人类专家在专业领域的推理能力。
性能提升的背后是计算成本的显著增加。根据OpenAI公布的数据,o3模型在低推理模式下每个任务的成本约为20美元,而在高推理模式下可能达到数千美元。这种成本结构反映了深度推理所需的巨大计算资源。不过,OpenAI承诺将在GPT-5正式发布时提供更经济的使用方案,包括针对ChatGPT Plus用户的大量免费额度。对于中国用户来说,通过FastGPTPlus充值ChatGPT Plus是目前最经济实惠的方案
o3架构深度解析:从链式思考到模拟推理的技术革命
o3架构是OpenAI在推理能力上的重大突破,它从根本上改变了大语言模型处理复杂问题的方式。传统的语言模型采用端到端的生成方式,就像一个学生看到题目后立即作答,容易出现逻辑跳跃和推理错误。而o3架构引入了"模拟推理"(Simulated Reasoning)机制,让AI能够像人类专家一样,在给出答案前进行深入的思考和推理。这种机制包含四个核心步骤:首先是问题分解,将复杂问题拆分成多个可管理的子问题;其次是内部推理链生成,为每个子问题构建详细的推理步骤;第三是验证与回溯,检查推理链的逻辑一致性并修正错误;最后是答案合成,基于验证后的推理链生成最终答案。
链式思考(Chain-of-Thought)技术是o3架构的核心创新之一。不同于传统模型的"黑箱"推理,o3架构使用专门的推理tokens来记录思考过程。这些tokens在最终输出中是不可见的,但在内部计算中起到关键作用。打个比方,就像数学老师在黑板上演算题目时会写下中间步骤,虽然最后只需要答案,但这些步骤对于得出正确答案至关重要。技术实现上,o3架构可以生成高达数百万个推理tokens,远超传统模型的处理能力。这种大规模的内部推理使得模型能够处理极其复杂的逻辑问题,包括数学证明、代码调试和科学推理等。

o3架构与传统LLM架构的本质区别在于推理的深度和可验证性。传统模型就像一个凭直觉答题的学生,虽然经验丰富但缺乏系统性思考。而o3架构更像一个训练有素的数学家,会仔细分析问题、尝试不同的解法、验证结果的正确性。这种差异在处理复杂推理任务时尤为明显。例如,在解决"鸡兔同笼"这类经典数学问题时,传统模型可能直接给出公式化的答案,而o3架构会展示完整的推理过程:设定变量、列出方程、逐步求解、验证答案。这种透明的推理过程不仅提高了准确性,也增强了结果的可信度。
System 2思维实现:GPT-5如何像人类专家一样深度思考
诺贝尔奖得主Daniel Kahneman在《思考,快与慢》中提出的双系统理论,现在在GPT-5中得到了完美的技术实现。System 1代表快速、直觉的思维,就像我们看到2+2时立即知道等于4;System 2代表缓慢、分析性的思维,如同解决复杂数学证明时的深思熟虑。GPT-5通过创新的计算资源动态分配机制,实现了这两种思维模式的灵活切换。在低推理模式下,模型使用基础计算资源,响应时间不到1秒,适合处理日常对话和简单问题;在高推理模式下,模型可以调用高达100倍的计算资源,花费数分钟进行深度思考,适合解决复杂的科学和工程问题。
GPT-5的自适应推理策略是其智能化的重要体现。模型能够自动评估问题的复杂度,选择合适的推理深度。这就像一个经验丰富的教师,看到学生的问题后能立即判断需要简单解释还是详细推导。对于"今天天气怎么样"这类简单问题,GPT-5会使用System 1快速回答;对于"证明费马大定理"这类复杂问题,则会自动切换到System 2进行深度推理。这种智能切换不仅提高了效率,也优化了用户体验。用户不需要手动选择推理模式,GPT-5会根据上下文自动做出最佳选择。
在API层面,开发者可以通过参数精确控制推理深度。reasoning_depth参数支持low、medium、high三个级别,max_reasoning_tokens参数可以设置推理token的上限。这种灵活性使得开发者能够根据具体应用场景优化性能和成本。例如,在构建客服聊天机器人时,可以使用低推理模式快速响应用户咨询;在开发代码审查工具时,则需要使用高推理模式进行深度分析。通过合理设置这些参数,开发者可以在响应速度、推理质量和使用成本之间找到最佳平衡点。
GPT-5推理能力的实际应用场景:从科研到商业的全面突破
在生物医学研究领域,GPT-5的推理能力正在创造革命性的变化。某知名制药公司的研究团队使用GPT-5进行蛋白质折叠预测,将原本需要数周的分析工作缩短到几个小时。研究人员输入蛋白质的氨基酸序列和已知的结构信息,GPT-5能够推理出多个可能的三维折叠路径,并对每个路径进行能量计算和稳定性评估。更重要的是,GPT-5能够解释其推理过程,指出哪些氨基酸残基之间可能形成氢键,哪些区域可能形成α螺旋或β折叠。这种透明的推理过程让研究人员能够理解和验证AI的预测,大大提高了药物研发的效率。
在金融量化领域,GPT-5展现出了超越传统量化模型的推理能力。一家对冲基金使用GPT-5分析市场数据,发现了人类分析师难以察觉的交易模式。GPT-5不仅能够识别价格走势的技术形态,还能结合宏观经济数据、公司财报和市场情绪进行综合推理。在一个实际案例中,GPT-5通过分析某科技公司的专利申请、研发支出和竞争对手动态,准确预测了该公司新产品的市场表现,帮助基金获得了可观的投资收益。这种多维度的推理能力是传统量化模型无法比拟的。
软件架构设计是GPT-5推理能力的另一个重要应用领域。某互联网公司的架构师团队使用GPT-5设计新的电商系统架构。他们输入了详细的业务需求:日活跃用户1000万、峰值QPS 10万、需要支持秒杀活动、预算限制在每月10万元以内。GPT-5不仅给出了详细的架构方案,包括微服务划分、数据库选型、缓存策略等,还进行了成本分析和性能预测。更令人惊讶的是,GPT-5能够预见潜在的技术债务,建议了演进式架构策略,确保系统能够随着业务增长平滑扩展。这种前瞻性的推理能力让GPT-5成为架构师的得力助手。
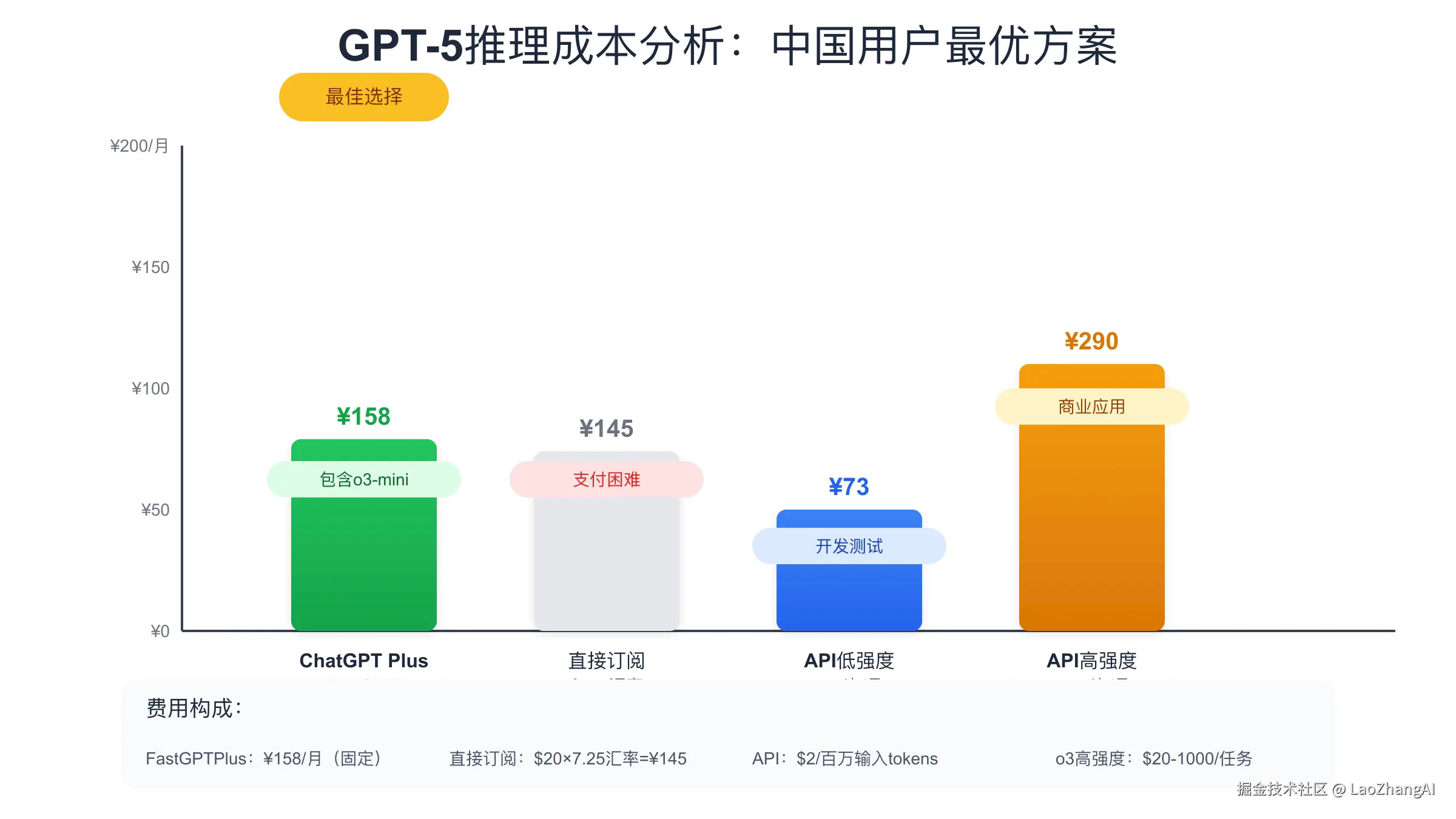
GPT-5推理成本分析:中国用户如何经济实惠地使用
GPT-5的强大推理能力背后是高昂的计算成本,但OpenAI正在努力让更多用户能够负担得起这项技术。根据最新的定价策略,o3-mini模式每次调用成本仅为0.01-0.05美元,适合日常对话和简单问答;o3-standard模式成本为1-5美元,可以处理代码调试和文章写作等中等复杂度任务;o3-high模式成本为20-100美元,专门用于数学证明和架构设计等高难度任务;最高级的o3-ultra模式成本可达200-1000美元,主要面向科研机构和竞赛场景。这种分层定价让不同需求的用户都能找到合适的方案。
对于中国用户来说,直接订阅ChatGPT Plus面临支付难题。国内信用卡经常被Stripe支付系统拒绝,即使成功支付也可能因为IP地址问题导致账号受限。而通过FastGPTPlus充值服务,这些问题都能得到完美解决。
GPT-5 vs 竞品推理能力对比:谁是推理之王
在推理能力的竞赛中,GPT-5、Claude 3.5和Gemini Ultra形成了三足鼎立的格局。Claude 3.5在某些方面表现出色,特别是在代码理解和长文本处理上有独特优势。其200K tokens的上下文窗口使其能够处理整本书籍的内容,在需要大量背景信息的推理任务中表现优异。然而,在纯粹的逻辑推理和数学证明方面,GPT-5凭借o3架构的优势明显领先。在同样的IMO数学题测试中,Claude 3.5的得分约为28/42,而GPT-5达到35/42。这种差距在复杂推理任务中更为明显,GPT-5能够处理更长的推理链和更复杂的逻辑关系。
Gemini Ultra作为Google的旗舰模型,在多模态推理方面有独特优势。它能够同时处理文本、图像、音频和视频,在需要跨模态理解的任务中表现出色。例如,在分析包含图表的科研论文时,Gemini Ultra能够直接理解图表内容并结合文本进行推理。但在纯文本的深度推理任务中,GPT-5的表现更加稳定和准确。国产大模型如文心一言、通义千问等在中文理解方面有一定优势,但在推理深度和准确性上与GPT-5还有明显差距。特别是在需要严密逻辑推理的任务中,国产模型的表现往往不够稳定。
综合评估各模型的推理能力,GPT-5在大多数维度上都占据领先地位。在选择使用哪个模型时,需要根据具体需求做出决策。如果主要处理英文内容的深度推理任务,GPT-5是首选;如果需要处理超长文本或代码,Claude 3.5可能更合适;如果任务涉及多种媒体类型,Gemini Ultra是不错的选择;如果主要处理中文内容且对成本敏感,可以考虑国产模型。对于大多数用户来说,通过ChatGPT Plus使用GPT-5是最平衡的选择,既能享受顶级的推理能力,成本又在可接受范围内。
开发者指南:如何充分利用GPT-5的推理能力
作为开发者,充分利用GPT-5的推理能力需要掌握一些关键技巧。首先是推理复杂度的评估。并非所有任务都需要深度推理,合理评估任务复杂度可以大幅降低成本。一个实用的方法是建立任务分类系统:简单任务如实体识别、情感分析使用低推理模式;中等任务如代码生成、文档总结使用标准模式;复杂任务如算法设计、系统架构才使用高推理模式。通过预先分类,可以避免过度使用昂贵的深度推理,同时确保任务质量。
python
import openai
from enum import Enum
import hashlib
import json
class ComplexityLevel(Enum):
LOW = "low"
MEDIUM = "medium"
HIGH = "high"
class GPT5ReasoningOptimizer:
def __init__(self, api_key, cache_dir="./cache"):
self.client = openai.Client(api_key=api_key)
self.cache_dir = cache_dir
self.complexity_keywords = {
"high": ["prove", "证明", "design", "架构", "optimize", "算法"],
"medium": ["analyze", "分析", "compare", "比较", "explain", "解释"],
"low": ["translate", "翻译", "summarize", "总结", "list", "列举"]
}
def assess_complexity(self, prompt):
prompt_lower = prompt.lower()
# 检查高复杂度关键词
for keyword in self.complexity_keywords["high"]:
if keyword in prompt_lower:
return ComplexityLevel.HIGH
# 检查中等复杂度
if len(prompt) > 500 or any(kw in prompt_lower for kw in self.complexity_keywords["medium"]):
return ComplexityLevel.MEDIUM
return ComplexityLevel.LOW
def get_cached_response(self, prompt, complexity):
# 生成缓存键
cache_key = hashlib.md5(f"{prompt}:{complexity.value}".encode()).hexdigest()
cache_path = f"{self.cache_dir}/{cache_key}.json"
try:
with open(cache_path, 'r', encoding='utf-8') as f:
return json.load(f)['response']
except FileNotFoundError:
return None
def query_with_optimization(self, prompt, force_complexity=None):
# 评估复杂度
complexity = force_complexity or self.assess_complexity(prompt)
# 检查缓存
cached = self.get_cached_response(prompt, complexity)
if cached:
return cached
# 配置推理参数
config = {
ComplexityLevel.LOW: {
"reasoning_depth": "low",
"max_reasoning_tokens": 10000,
"temperature": 0.7
},
ComplexityLevel.MEDIUM: {
"reasoning_depth": "medium",
"max_reasoning_tokens": 50000,
"temperature": 0.3
},
ComplexityLevel.HIGH: {
"reasoning_depth": "high",
"max_reasoning_tokens": 200000,
"temperature": 0.1
}
}[complexity]
# 调用API
response = self.client.chat.completions.create(
model="gpt-5-preview",
messages=[{"role": "user", "content": prompt}],
**config
)
result = response.choices[0].message.content
# 保存到缓存
self.save_to_cache(prompt, complexity, result)
return result性能优化的另一个关键是批处理和并行化。GPT-5的API支持批量请求,可以显著降低网络开销和总体延迟。对于需要处理大量相似任务的场景,如批量代码审查或文档分析,应该将任务打包成批次统一处理。同时,可以使用异步编程技术并行发送多个请求,充分利用API的并发能力。需要注意的是,要合理设置并发数,避免触发API的速率限制。建议使用指数退避算法处理速率限制错误,确保系统的稳定性。
错误处理和监控是生产环境中不可忽视的部分。GPT-5的推理过程可能因为各种原因失败,包括网络超时、token限制、服务暂时不可用等。建立完善的错误处理机制,包括自动重试、降级策略和告警通知,可以确保服务的高可用性。同时,要建立详细的监控指标,包括响应时间、成功率、成本消耗等,及时发现和解决问题。通过持续的监控和优化,可以在保证服务质量的同时控制成本,实现GPT-5推理能力的最大化利用。
GPT-5推理能力的技术挑战与未来发展
尽管GPT-5在推理能力上取得了巨大突破,但仍面临一些技术挑战。推理一致性是其中最重要的问题之一。在处理超长推理链时,模型可能出现前后逻辑不一致的情况,就像人类在长时间思考后可能忘记最初的前提。OpenAI正在通过引入检查点机制来解决这个问题,在推理过程的关键节点保存状态,定期验证逻辑的连贯性。另一个挑战是计算成本的优化。目前高强度推理模式的成本对普通用户来说仍然偏高,限制了技术的普及。研究团队正在探索更高效的推理算法,包括动态剪枝、推理路径复用等技术,目标是在保持推理质量的同时降低计算需求。
幻觉问题在深度推理中依然存在,特别是在模型训练数据覆盖不足的领域。虽然o3架构通过验证机制大大减少了幻觉的发生,但在某些专业领域,模型仍可能生成看似合理但实际错误的推理。解决方案包括结合检索增强生成(RAG)技术,让模型在推理时能够查询外部知识库,以及开发更好的不确定性量化方法,让模型能够识别并标注自己不确定的推理结论。这些改进将使GPT-5的推理结果更加可靠和可信。
展望未来,GPT-5的推理能力将继续演进。下一代模型可能会引入更多认知科学的insights,如工作记忆、注意力机制和元认知能力。这将使AI不仅能够进行深度推理,还能够反思和改进自己的推理过程。在应用层面,GPT-5级别的推理能力将推动多个行业的变革:在科研领域加速新发现,在教育领域提供个性化的学习体验,在医疗领域辅助诊断和治疗方案设计。随着成本的降低和技术的成熟,强大的推理能力将成为AI应用的标配,深刻改变人类的工作和生活方式。
中国用户使用GPT-5推理功能完整指南
对于中国用户来说,体验GPT-5强大推理能力的第一步是解决访问问题。由于众所周知的原因,直接访问ChatGPT存在困难,但这并不意味着我们无法使用这项先进技术。随着WildCard停服,目前最稳定可靠的方案是通过FastGPTPlus充值服务订阅ChatGPT Plus。FastGPTPlus作为专业的充值平台,已经帮助数万用户成功订阅,其优势在于:支持支付宝和微信支付,无需国外信用卡; 在实际使用中,中国用户需要注意一些技巧来优化体验。首先是提示词的优化,虽然GPT-5的中文理解能力很强,但在处理复杂推理任务时,使用结构化的提示词可以获得更好的效果。例如,明确说明任务类型(证明、分析、设计等)、提供必要的背景信息、指定期望的输出格式。其次是合理使用推理深度,不是所有任务都需要最高级别的推理,根据实际需求选择合适的模式可以平衡效果和响应时间。最后是善用对话历史,GPT-5能够理解上下文,通过多轮对话逐步深入可以获得更好的推理结果。
GPT-5推理能力常见问题解答(FAQ)
Q1:GPT-5什么时候正式发布?
根据OpenAI的最新消息,GPT-5预计将在2025年8月正式发布。在此之前,部分功能会通过o3模型逐步向ChatGPT Plus用户开放。目前o3-mini已经在ChatGPT中可用,而o3-pro预计在2025年春季向Pro用户开放。正式版GPT-5将整合所有推理能力,提供统一的使用体验。建议提前通过FastGPTPlus订阅ChatGPT Plus,以便第一时间体验新功能。
Q2:免费用户能使用GPT-5的推理功能吗?
OpenAI承诺会为免费用户提供基础的o3-mini访问权限,但使用次数会有限制。根据目前的信息,免费用户每天可能有10-20次的o3-mini调用额度,适合体验和轻度使用。如果需要频繁使用或访问更高级的推理模式,建议订阅ChatGPT Plus。通过FastGPTPlus充值的Plus账号将获得大量的推理额度,足够满足个人和小团队的日常需求。
Q3:API价格会继续降低吗?
从历史趋势看,OpenAI一直在努力降低API成本。o3模型的价格已经比初始版本降低了80%,预计GPT-5发布后还会有进一步的优化。随着技术成熟和规模效应,推理成本有望在未来1-2年内再降低50%以上。对于开发者来说,现在开始熟悉和使用这些API是明智的选择,可以在成本下降后快速扩大应用规模。
Q4:GPT-5的中文推理效果如何?
GPT-5在中文推理方面有显著提升,特别是在数学、逻辑和代码相关的推理任务上,中英文的表现差异已经很小。在中文特有的任务如古诗词创作、成语接龙等方面,GPT-5也展现出了良好的理解和推理能力。不过,在某些需要深厚中文文化背景的任务上,可能还不如专门针对中文优化的模型。总体而言,GPT-5是目前中文推理能力最强的通用模型之一,特别适合需要深度逻辑推理的任务。