文章目录
- FlowRAM:用区域感知与流匹配加速高精度机器人操作策略学习
-
- 一、问题出在哪里?
- [方法部分:从结构到机制,详解 FlowRAM 的内部设计逻辑](#方法部分:从结构到机制,详解 FlowRAM 的内部设计逻辑)
-
- [1. 动态半径调度器:自适应注意力机制在 3D 感知中的实现](#1. 动态半径调度器:自适应注意力机制在 3D 感知中的实现)
- [2. 多模态编码器与序列融合模块(Mamba)](#2. 多模态编码器与序列融合模块(Mamba))
- [3. 条件流匹配策略生成器:一步式动作生成如何实现?](#3. 条件流匹配策略生成器:一步式动作生成如何实现?)
- [4. 推理流程:从噪声动作到最终执行动作](#4. 推理流程:从噪声动作到最终执行动作)
- [5. 总结方法特点与优势](#5. 总结方法特点与优势)
- [三、实验验证:任务泛化 + 高精度执行双优](#三、实验验证:任务泛化 + 高精度执行双优)
- 四、真实机器人实验
- 五、总结与展望

FlowRAM:用区域感知与流匹配加速高精度机器人操作策略学习
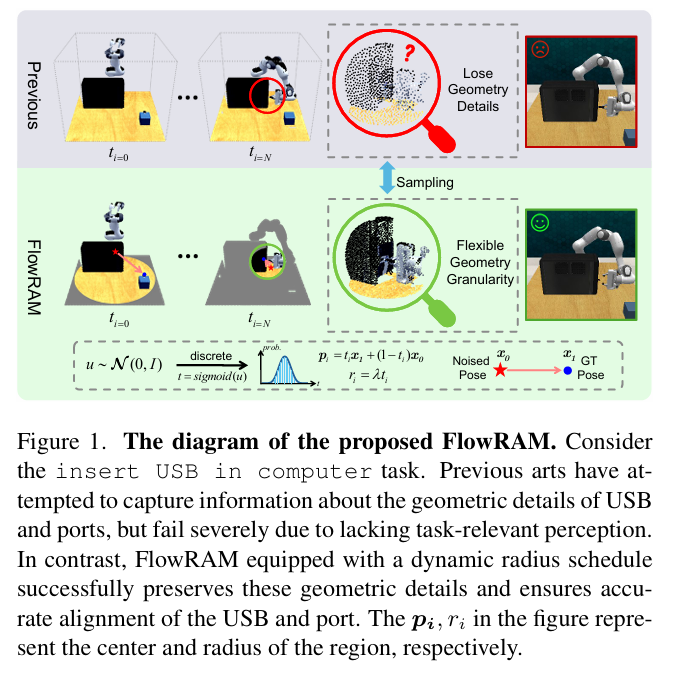
在机器人操作任务中,"又快又准"一直是关键挑战,尤其是在需要亚毫米级精度的插拔、拧螺丝等场景中。然而,当下流行的策略学习范式(如扩散模型)虽然在生成多模态动作方面表现优秀,却面临计算效率低、任务感知不精确等痛点。
我们在最近的研究中提出了一个全新的框架 FlowRAM(Flow-based Region-Aware Mamba) ,融合了条件流匹配(Conditional Flow Matching, CFM)和区域感知机制,打破扩散式方法低效、粗感知的壁垒,在 RLBench 多任务和高精度任务上均取得了SOTA 性能。本博客将系统介绍 FlowRAM 的设计思路、关键模块与实验表现。
一、问题出在哪里?
现有方法面临以下两大瓶颈:
- 低效率的推理过程:扩散模型在推理阶段需进行几十到上百次去噪采样,推理速度慢,难以满足实时机器人控制需求;
- 感知不聚焦:很多方法使用全局感知机制(如 voxel grid、FPS),导致模型无法准确识别并关注于任务关键区域(如 USB 插口的位置或螺孔的细节),限制了高精度执行能力。
为解决这些问题,我们设计了 FlowRAM,一个结合"精细局部感知"与"流式一跳生成"的通用策略学习框架。
很好,下面我将进一步扩展博客中"方法部分"的内容,使其从介绍性的"三大模块概览"深化为具备工程/算法视角的逐层细化分析,适用于具备一定技术背景的读者或论文审阅者。该部分将拆解为五个子节,内容将涵盖架构设计逻辑、每个组件的技术实现、参数如何动态调度,以及为什么选择 CFM 和 Mamba 的理论与实践优势。
方法部分:从结构到机制,详解 FlowRAM 的内部设计逻辑
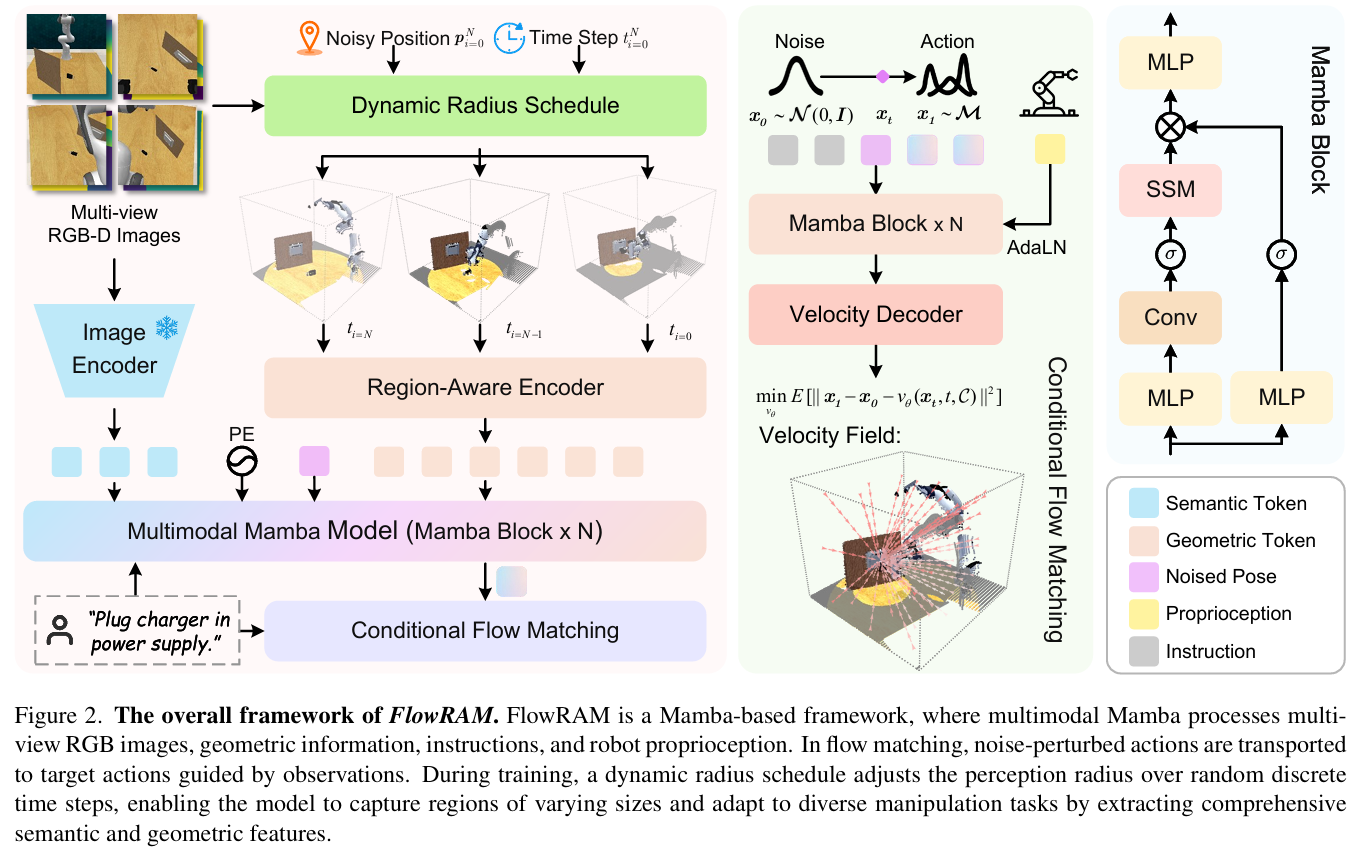
FlowRAM 是一个具备区域感知能力的生成式策略学习框架,融合了现代状态空间建模(Mamba)和条件流匹配(Conditional Flow Matching, CFM)两大技术范式,目标是在空间上对操作区域进行高精度建模,在时间上实现高效动作生成。
我们将从以下几个方面展开:
1. 动态半径调度器:自适应注意力机制在 3D 感知中的实现
在传统点云策略中,如 Act3D 使用的是全局 Farthest Point Sampling(FPS),每次采样的都是整个场景中的关键点,造成了以下问题:
- 感知资源被浪费在无关区域;
- 与操作目标相关的精细几何结构(如插口、盖子边缘)被稀释或错过;
- 在存在遮挡、局部物体形变等情况下缺乏鲁棒性。
为此,FlowRAM 提出了一种 Dynamic Radius Schedule (DRS) 感知调度机制,其基本思想是:
随着时间步的推进(即从粗到细的推理过程),感知区域的半径从大逐步收缩,使模型逐步聚焦于当前关键动作的目标区域。
公式化表示为:
r i = ( 1 − i / N ) ⋅ ( r 0 − r m i n ) + r m i n r_i = (1 - i/N) \cdot (r_0 - r_{min}) + r_{min} ri=(1−i/N)⋅(r0−rmin)+rmin
- i 表示当前的时间步;
- N 为总步数;
- r_i 为第 i 步的感知半径;
- r_0 与 r_{min} 分别为起始与最小半径。
该机制本质上模拟了"空间注意力自焦点化"的过程,让模型逐渐从粗糙感知过渡到精确定位。
此外,我们为每个时间步定义了一个 mask 区域 M_i = {(p_i, r_i)},其中 p_i 为当前时间步的扰动位姿位置,作为圆心;最终的点云采样仅在这个动态球形区域中进行。
2. 多模态编码器与序列融合模块(Mamba)
FlowRAM 在感知编码阶段采用的是以下多模态输入:
- 点云输入:使用 PointMamba(基于 SSM 的 PointNet 变体)提取局部几何特征;
- RGB 图像输入:多视角图像经由 CLIP + FPN 编码器提取语义;
- 语言输入:任务指令经由 CLIP-Text 模块得到句向量;
- 机器人状态输入:包括夹爪状态、扰动初始动作 pose,线性投影后合并进入 token 序列。
所有特征统一嵌入至维度为 C 的向量空间,并拼接成:
F i n = concat ( F g e o , F r g b , F t e x t , F o p e n ) F_{in} = \text{concat}(F_{geo}, F_{rgb}, F_{text}, F_{open}) Fin=concat(Fgeo,Frgb,Ftext,Fopen)
接下来,FlowRAM 使用 多层 Mamba 块 对该多模态 token 序列进行时序建模,其形式如下:
math
H_1 = LN(F_{in})
H_2 = SSM(\text{SiLU}(Conv1D(Linear(H_1))))
F_{out} = Linear(H_2 \odot \text{SiLU}(Linear(H_1)))该模块实现了:
- 低复杂度(线性而非平方);
- 状态保持(不同模态 token 保留上下文记忆);
- 高效融合(融合语义与几何 token 时的注意力压缩);
最终,F_{out} 被送入动作生成模块作为条件特征。
3. 条件流匹配策略生成器:一步式动作生成如何实现?
传统的 Diffusion Policy 在推理阶段必须通过 50-100 步的逐步去噪流程才能得到动作,而 FlowRAM 使用 Conditional Flow Matching (CFM) ,直接回归目标关键帧动作的矢量场导向路径,一次完成。
基本公式如下:
- 插值路径为:x_t = t x_1 + (1 - t) x_0
- 流速场为:u(x_t) = \\frac{d x_t}{dt} = x_1 - x_0
- 学习目标为最小化速度场残差:
L CFM = E x 0 , x 1 , t ∥ x 1 − x 0 − v θ ( x t , t , C ) ∥ 2 \mathcal{L}{\text{CFM}} = \mathbb{E}{x_0, x_1, t} \left\\\|x_1 - x_0 - v_\\theta(x_t, t, C)\\\|\^2\\right LCFM=Ex0,x1,t∥x1−x0−vθ(xt,t,C)∥2
其中 C 为条件信息(即 Mamba 编码的多模态特征)。
我们用一个带有 AdaLN 的 SSM 模型作为 v_\\theta,输入为 x_t, t, 和条件 C,输出为预测的矢量场速度。
此外,为了预测夹爪开闭状态,我们增加了一个 Binary Classifier,监督损失为交叉熵:
L open = − x log x ^ − ( 1 − x ) log ( 1 − x ^ ) \mathcal{L}_{\text{open}} = -x \log \hat{x} - (1 - x) \log (1 - \hat{x}) Lopen=−xlogx^−(1−x)log(1−x^)
最终训练目标为:
L total = λ 1 L CFM + λ 2 L open \mathcal{L}{\text{total}} = \lambda{1} \mathcal{L}{\text{CFM}} + \lambda{2} \mathcal{L}_{\text{open}} Ltotal=λ1LCFM+λ2Lopen
4. 推理流程:从噪声动作到最终执行动作
推理过程非常高效:
- 从高斯分布中采样初始动作 x_0;
- 通过 DRS 确定当前时间步的感知半径,提取关键区域点云;
- 使用 Mamba 提取融合特征 C;
- 用如下欧拉积分方式前向演化:
x t + Δ t = x t + v θ ( x t , t , C ) ⋅ Δ t x_{t + \Delta t} = x_t + v_\theta(x_t, t, C) \cdot \Delta t xt+Δt=xt+vθ(xt,t,C)⋅Δt
- 重复上步 2-4 次,便可得到目标关键帧动作 x_1,平均推理时间 < 92ms。
5. 总结方法特点与优势
| 维度 | FlowRAM 优势 |
|---|---|
| 感知方式 | 动态注意区域,多尺度几何采样 |
| 模态融合 | Mamba 结构替代 Transformer,复杂度线性 |
| 动作生成 | CFM 替代 Diffusion,速度更快,效果更稳定 |
| 通用性 | 可适配语言、RGB-D、点云、proprioception 多模态输入 |
| 可部署性 | 已在真实机器人 UR5 上部署成功 |
三、实验验证:任务泛化 + 高精度执行双优
我们在 RLBench 上进行了系统评估,包括:
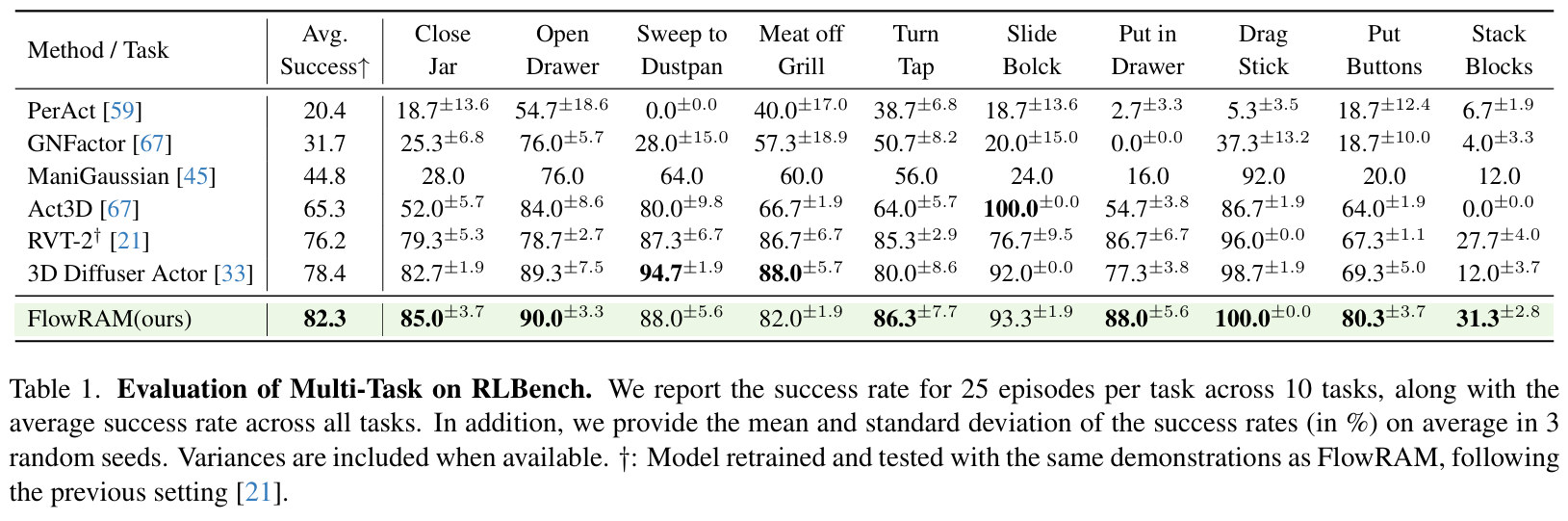
多任务泛化能力
在 10 个标准任务上,FlowRAM 平均成功率达到 82.3% ,比现有 SOTA 方法(如 RVT-2、3D Diffuser Actor)高出近 4%。在复杂任务(如 Stack Blocks)中更是超出对手近 19% 。
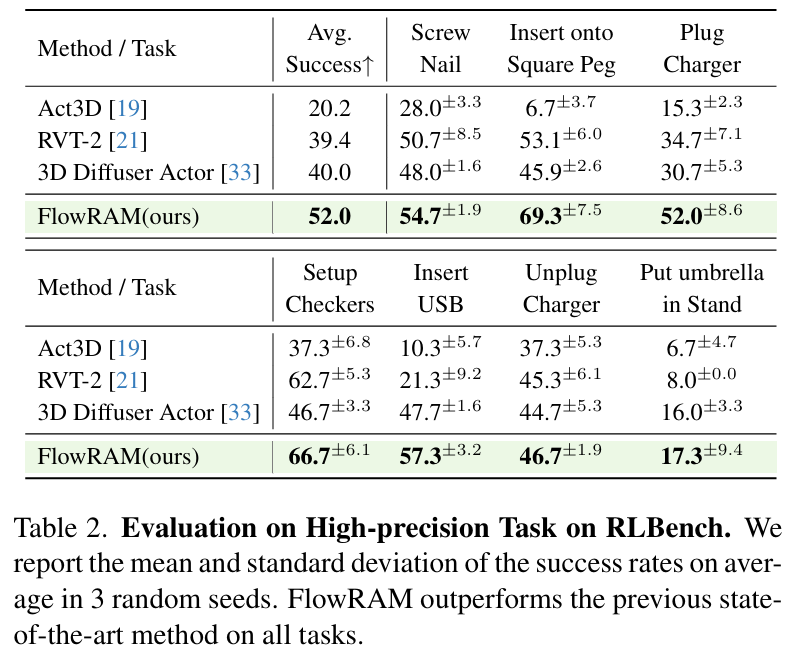
高精度任务性能
我们在 RLBench 中挑选了 7 个对几何精度极度敏感的任务,如插 USB、拧螺丝等。在这些任务中,FlowRAM 平均成功率高达 52.0%,相比基线模型大幅领先:
- Insert USB:FlowRAM 成功率 57.3%,RVT-2 仅 21.3%
- Screw Nail:FlowRAM 54.7%,其他方法均低于 50%
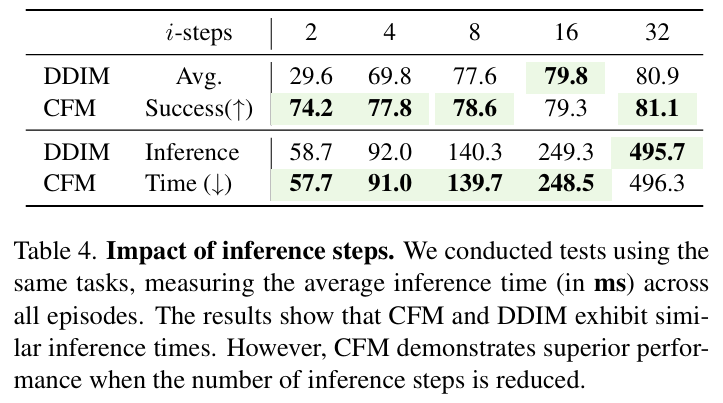
推理速度分析
在相同精度下,FlowRAM(CFM)仅需 2~4 步 即可生成动作,远优于 DDIM、DDPM 等扩散模型(需要 50~100 步)。如下图所示,速度与精度双优:
四、真实机器人实验
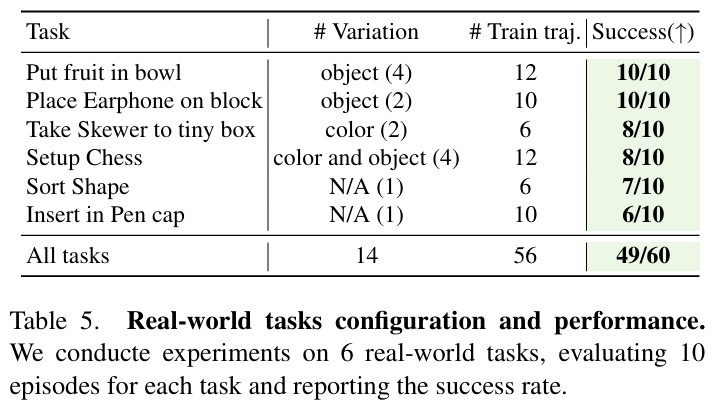
我们将 FlowRAM 部署于真实 UR5 机械臂,配合 Robotiq 夹爪与 Azure Kinect 相机,在 6 个语言条件下的真实任务中表现出色。平均成功率达 81.7%,验证了该方法在少量示范下的实用性和鲁棒性。
任务包括:
- 插入笔帽
- 果盘分类
- 耳机摆放
- 棋盘布置等
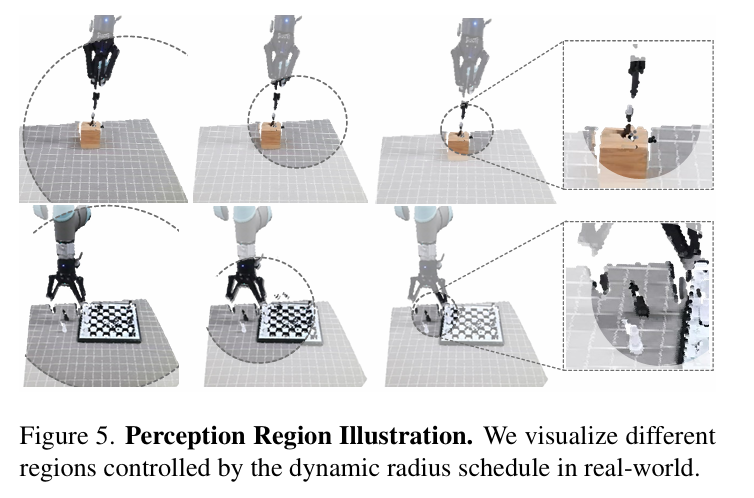
五、总结与展望
FlowRAM 提供了一种融合区域感知与高效生成的新范式,专为机器人操作中的高精度任务设计。其关键优势包括:
- 感知局部细节而非全局冗余
- 快速生成动作而非多轮迭代
- 高性能与低推理成本并存
未来,我们希望将 FlowRAM 推向更复杂的现实环境,如多机器人协作、非刚体操作以及开源多模态数据集适配。我们也欢迎社区同行一起探索流匹配范式下的策略生成与视觉感知新边界。
📌 如你感兴趣,欢迎阅读我们完整论文:FlowRAM: Grounding Flow Matching Policy with Region-Aware Mamba,或与我们团队联系交流合作。
📦 代码已开源:欢迎访问我们的 GitHub 仓库,如果对你有帮助,别忘了点个 star ⭐ 支持我们!