词向量 Word2vec
Word2Vec是Google于2013年开源推出的一个用于获取词向量(word vector)的工具包。它是语言模型中的一种,从大量文本预料中以无监督方式学习语义知识的模型,被广泛地应用于自然语言处理中。
自然语言处理相关任务中要将自然语言交给机器学习中的算法来处理,通常需要将语言数学化,因为计算机机器只认数学符号。向量是人把自然界的东西抽象出来交给机器处理的数学性质的东西,基本上可以说向量是人对机器输入的主要方式了。词向量是对词语的向量表示,这些向量能捕获词语的语义信息,如相似意义的单词具有类似的向量。
Word2Vec的主要作用是生成词向量,而词向量与语言模型有着密切的关系。Word2Vec的特点是能够将单词转化为向量来表示,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。Word2Vec模型在自然语言处理中有着广泛的应用,包括词语相似度计算、文本分类、词性标注、命名实体识别、机器翻译、文本生成等。其主要目的是将所有词语投影到K维的向量空间,每个词语都可以用一个K维向量表示。
Word2vec 原理
参考链接:https://zhuanlan.zhihu.com/p/371147732
https://www.cnblogs.com/Data-Science-Risk-Control/p/17705310.html
词向量就是用来将语言中的词进行数学化的一种方式,顾名思义,词向量就是把一个词表示成一个向量。 我们都知道词在送到神经网络训练之前需要将其编码成数值变量,常见的编码方式有两种:One-Hot Representation 和 Distributed Representation。
Word2Vec模型的核心思想是通过词语的上下文信息来学习词语的向量表示。具体来说,Word2Vec模型通过训练一个神经网络模型,使得给定一个词语的上下文时,能够预测该词语本身(CBOW模型),或者给定一个词语时,能够预测其上下文(Skip-gram模型)。Word2Vec的训练模型本质上是只具有一个隐含层的神经元网络。它的输入是采用One-Hot编码的词汇表向量,它的输出也是One-Hot编码的词汇表向量。使用所有的样本,训练这个神经元网络,等到收敛之后,从输入层到隐含层的那些权重,便是每一个词的采用Distributed Representation的词向量。
One-Hot Representation
一种最简单的词向量方式是One-Hot编码 ,就是用一个很长的向量来表示一个词,向量的长度为词典的大小,向量中只有一个 1 , 其他全为 0 ,1 的位置对应该词在词典中的位置。
举个例子:I like writing code,那么转换成独热编码就是:
词: One-Hot 编码
I: 1 0 0 0
like: 0 1 0 0
writing: 0 0 1 0
code: 0 0 0 1
这种One Hot编码如果采用稀疏方式存储,会是非常的简洁:也就是给每个 词分配一个数字 ID 。比如上面的例子中,code记为 1 ,like记为 4 。 如果要编程实现的话,用 Hash 表给每个词分配一个编号就可以了。这么简洁的表示方法配 合上最大熵、 SVM 、 CRF 等等算法已经能很好地完成 NLP 领域的各种主流任务。但这种词表示有两个缺点:
-
容易受维数灾难的困扰:当你的词汇量达到千万甚至上亿级别的时候,你会遇到一个更加严重的问题,维度爆炸了.这里举例使用的是4个词,你会发现,我们使用了四个维度,当词数量达到1千万的时候,词向量的大小变成了1千万维,不说别的,光内存你都受不了这么大的词向量,假设你使用一个bit来表示每一维,那么一个单词大概需要0.12GB的内存,但是注意这只是一个词,一共会有上千万的词,这样内存爆炸了
-
词汇鸿沟,不能很好地刻画词与词之间的相似性:任意两个词之间都是孤立的,从这两个向量中看不出两个词是否有关系。比如说,I、like之间的关系和like、writing之间的关系,通过0001和0010和0010和0100怎么表现,通过距离?通过1的位置?你会发现独热编码完全没法表现单词之间的任何关系。
-
强稀疏性:当维度过度增长的时候,你会发现0特别多,这样造成的后果就是整个向量中有用的信息特别少,几乎就没法做计算。
Distributed Representation
Distributed Representation最早是Hinton于1986年提出的,可以克服One-Hot Representation的上述缺点。其基本想法是:通过训练将某种语言中的每一个词 映射成一个固定长度的短向量(当然这里的"短"是相对于One-Hot Representation的"长"而言的),所有这些向量构成一个词向量空间,而每一个向量则可视为 该空间中的一个点,在这个空间上引入"距离",就可以根据词之间的距离来判断它们之间的语法、语义上的相似性了。Word2Vec中采用的就是这种Distributed Representation 的词向量。
Word2Vec的网络结构
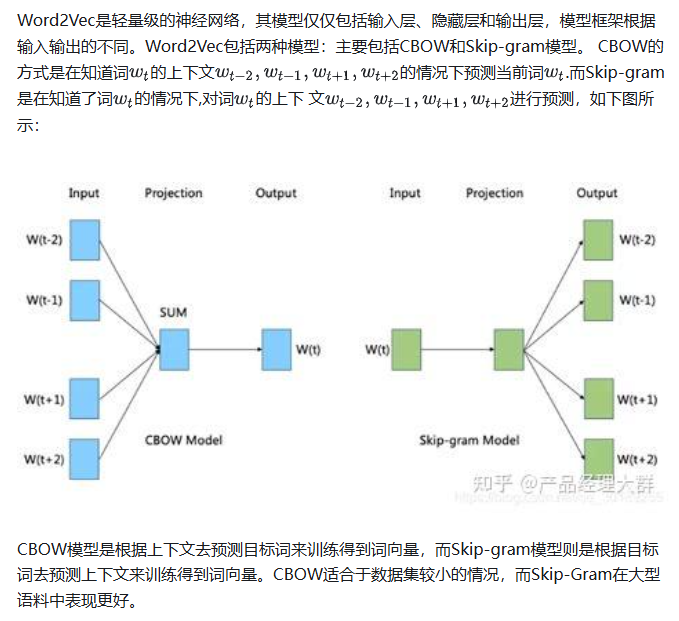
在CBOW模型(Continuous Bag of Words,连续词袋)中,给定上下文单词,目标是预测中心单词。例如,对于句子 "Thou shalt not make a machine in the likeness of a human mind",如果我们将上下文大小设置为1,那么对于中心单词 "machine",上下文单词可以是 "a", "in"。训练目标:最大化中心词出现时上下文词的概率。
在Skip-gram模型(跳字模型)中,目标是给定中心单词,预测其周围的上下文单词。训练目标:最大化上下文词出现时中心词的概率。
如上图所示,Skip-gram和CBOW模型的训练区别主要在输入层和隐层,Skip-gram输入层仅中心词的one-hot向量、隐藏层也就不需要再进行平均操作。过程如下:
① 输入层(Input layer):将中心单词用ont-hot编码表示,为[1 * V]大小的矩阵
② 中心词ont-hot向量乘以输入权重矩阵W得到大小为[1 * N]的隐藏层向量h,W是[V * N]大小的共享矩阵,N是指输出的词的向量维数;之后就和CBOW一致了
③ 将隐层向量h乘以输出权重矩阵W',W'是[N * V]大小的共享矩阵;
④相乘得到向量y,大小为[1 * V],然后利用softmax激活函数处理向量y,得到V-dim概率分布;
⑤由于输入的是ont-hot编码,即每个维度都代表着一个单词,那么V-dim概率分布中,概率最大的index所指代的那个单词为预测出的上下文单词。
⑥ 将结果与真实标签的ont-hot做比较,误差越小越好,这里的误差函数,即loss function一般选交叉熵代价函数。目的
word2vec的目的并不在于预测上下文的语言模型,而是在于训练得到中间结果输入层到隐藏层之间的权重矩阵W、即Embedding矩阵,即词向量矩阵。把每个词使用向量形式表示之后,在文本任务中就可以继续进行文本分类、文本相似度、推荐等等下游任务。
词向量的主要作用
词向量(Word Vectors)是自然语言处理(NLP)中的一个核心概念,它将词汇表中的每个单词映射到一个高维的连续向量空间中。这种表示方法相较于传统的离散表示(如one-hot编码),能够捕捉词语之间的语义和语法关系,从而极大地提升了NLP任务的性能。以下是词向量的几个主要作用:
-
语义相似性捕捉:
词向量能够将语义上相似的词语映射到向量空间中的相近位置。例如,"king"与"queen"、"cat"与"dog"等词语在向量空间中的距离较近,反映了它们之间的语义联系。
-
降维与稀疏性解决:
One-hot编码会导致维度灾难(即随着词汇表大小的增加,向量维度急剧增长),并且大多数元素为零,导致数据非常稀疏。而词向量通过将词语映射到低维稠密空间,有效解决了这一问题。
-
特征提取:
词向量作为特征输入到机器学习模型中,可以显著提升模型的性能。通过训练得到的词向量包含了丰富的语义信息,可以作为有效的特征用于文本分类、情感分析、命名实体识别等多种任务。
-
语言模型的基础:
现代的自然语言处理系统,特别是深度学习模型,如循环神经网络(RNN)、长短时记忆网络(LSTM)、Transformer等,都依赖于高质量的词向量作为输入。这些模型通过学习更复杂的上下文依赖关系来进一步优化词向量表示。
-
迁移学习与跨领域应用:
在大规模语料库上预训练的词向量可以被迁移到不同的NLP任务中,即使目标任务的数据量有限。这种迁移学习能力使得词向量成为跨领域应用的重要工具。
-
词语关系推理:
通过计算词向量之间的运算关系,可以发现一些有趣的词语关系模式。例如,通过"king - man + woman = queen"这样的操作,可以揭示出词语之间的类比关系。
-
提升模型泛化能力:
使用词向量表示的模型能够更好地处理未见过的词汇或短语,因为它们可以利用已学习到的语义结构进行推断。这提高了模型的泛化能力和鲁棒性。
使用 Tensorflow 实现 Word2Vec
在 TensorFlow 中实现 Word2Vec(通常指的是 Word2Vec 模型的两个变种:Skip-gram 和 CBOW)可以使用 TensorFlow 内置的 tf.keras API 来构建和训练模型。这里,我将向你展示如何使用 Skip-gram 模型来实现 Word2Vec。
步骤 1:安装 TensorFlow
确保你已经安装了 TensorFlow。如果还没有安装,可以通过 pip 安装:
python
pip install tensorflow步骤 2:导入必要的库
python
import tensorflow as tf
from tensorflow.keras.layers import Embedding
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing.sequence import skipgrams
import numpy as np步骤 3:准备数据
为了使用 Skip-gram 模型,我们需要准备文本数据,并将其转换为适合训练的形式。这里我们使用 skipgrams 函数来生成跳元对。
python
# 示例文本数据
sentences = [
"apple banana", "banana apple", "apple orange", "orange banana", "banana apple banana"
]
# 将句子拆分为单词列表
words = [word for sentence in sentences for word in sentence.split()]
vocab = sorted(list(set(words))) # 词汇表
word_to_index = {word: i for i, word in enumerate(vocab)} # 单词到索引的映射
num_words = len(word_to_index) # 词汇表大小
# 生成跳元对
couples, labels = skipgrams(methods=["weighted"], vocabulary_size=num_words, sampling_table=None, window_size=2, negative_samples=1.0)步骤 4:构建 Skip-gram 模型
python
embedding_dim = 128 # 嵌入维度
# Embedding 层(输入层)
input_layer = tf.keras.layers.Input(shape=(1,))
embedding = tf.keras.layers.Embedding(input_dim=num_words, output_dim=embedding_dim)(input_layer)
reshaped_embedding = tf.keras.layers.Reshape((embedding_dim,))(embedding) # 重塑为 (batch_size, embedding_dim)
flat_embedding = tf.keras.layers.Flatten()(reshaped_embedding) # 展平为 (batch_size * embedding_dim)
# 输出层(使用 Dot product 来计算相似度)
output_layer = tf.keras.layers.Dot(axes=1)([flat_embedding, flat_embedding]) # 使用自身作为比较对象,计算相似度得分
model = Model(inputs=input_layer, outputs=output_layer)
model.compile(optimizer='adam', loss='mean_squared_error') # 使用 MSE 作为损失函数步骤 5:训练模型
python
model.fit(couples, labels, epochs=10, verbose=1) # 训练模型,注意这里的输入应为 (couples, labels) 对的列表形式,这里简化处理为直接传入。实际应用中可能需要额外的数据处理步骤。步骤 6:评估和使用模型
由于我们使用的是 Skip-gram 的简化版本,实际应用中你可能需要更复杂的输入处理和批量数据处理。你可以通过以下方式获取嵌入向量:
python
def get_embeddings(word):
word_index = np.array([word_to_index[word]], dtype=np.int32) # 将单词转换为索引数组
return model.predict(word_index).flatten() # 获取嵌入向量并展平为数组形式
# 获取嵌入向量示例
print(get_embeddings('apple')) # 查看 'apple' 的嵌入向量表示注意:实际应用中的数据处理和模型训练可能需要更多的优化和调整,比如使用更大的数据集、更复杂的负采样策略等。此外,实际应用中通常会将数据预处理、分批处理等操作封装到自定义的 tf.data 数据管道中,以提高效率和可扩展性。
Word2vec 优化技术
参考链接:https://blog.csdn.net/catfishH/article/details/118964326
Word2vec 是 Word Embedding 方式之一,将词转化为"可计算""结构化"的向量, 本质上是一种降维操作。
主要包含:CBOW(continuous bag-of-word)模型和 SG(skip-gram)模型,以及hierarchical softmax 和 negative sampling 两种参数优化技术。
1)Hierarchical Softmax
从隐藏层到输出的 softmax 层的计算量很大,因为要计算所有词的 softmax 概率,再去找概率最大的值。故而使用霍夫曼树来代替从隐藏层到输出 softmax 层的映射,沿着霍夫曼树从根节点一直走到我们的叶子节点的词w。由于是二叉树,计算量从 V 变成了 log2V;霍夫曼树高频的词靠近树根,高频词需要更少的时间被找到。
2)Negative Sampling
输出向量的维度很高时,反向传播计算量非常巨大,故而每次只修改了其中一小部分 weight,而不是全部。根据词出现概率来选 negative sample,更常出现的词,更容易被选为 negative sample,被选中的概率为:
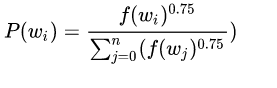
Skip-Gram 和 CBOW 的区别和选择
Word2Vec框架中的Skip-Gram和CBOW是两种核心的词嵌入模型,它们在训练目标、效率和适用场景上存在关键差异。
核心区别在于训练方式和效率: Skip-Gram和CBOW的核心差异体现在输入输出模式、训练效率和低频词处理上。具体来说:
- 训练方式:Skip-Gram通过中心词预测上下文词汇(输入为one-hot编码的中心词,输出为上下文词的概率分布),而CBOW则利用上下文词汇预测中心词(输入为上下文词向量的平均,输出为目标中心词的概率分布)。
- 训练效率:CBOW的训练速度通常更快,因为其通过上下文向量平均降低了计算复杂度(时间复杂度约为O(V),其中V为词典大小);Skip-Gram需对每个上下文词单独预测,计算开销更大(时间复杂度约为O(kV),k为窗口大小)。
- 低频词处理:Skip-Gram对低频词的表征能力更强,因为它直接以中心词为输入,每个词(包括罕见词)都会生成多个训练样本;CBOW在预测时倾向于选择高频词,可能导致低频词信息丢失。
- 精度与适用性:Skip-Gram在捕捉复杂语义关系(如一词多义)和小规模数据集上通常表现更优,而CBOW在大规模语料上能快速达到稳定性能,适合对效率要求高的场景。
选择模型时需权衡数据规模、计算资源和任务需求: 选择Skip-Gram或CBOW应基于以下因素:
- 数据规模:若语料库庞大(如数百万句子),优先选择CBOW以节省训练时间;若数据有限或需精细语义建模,Skip-Gram更合适。
- 计算资源:资源受限时(如内存或算力不足),CBOW的高效性更具优势;若追求更高精度且计算资源充足,可选Skip-Gram。
- 任务需求:对于低频词密集的任务(如专业术语识别),Skip-Gram能更好保留稀疏词信息;通用词向量任务中,CBOW的快速收敛性更实用。
- 实践建议:通常可先尝试CBOW获得基线性能,若效果不满足需求再切换至Skip-Gram;实际应用中还需结合负采样或层次Softmax等优化技术提升效率。
使用 Gensim 训练 Word2vec
使用Gensim库训练Word2vec模型是自然语言处理中的常见任务,尤其适用于中文文本。以下内容基于典型实践,涵盖从环境准备到模型训练的完整流程。
安装与依赖配置 :
首先安装Gensim库,可通过命令 pip install gensim 完成;需注意Gensim对numpy版本有特定要求,安装时可能自动升级numpy,若遇到兼容性问题,建议手动安装匹配版本的numpy(如从Christoph Gohlke的Windows预编译库下载)。此外,中文处理需安装jieba分词工具:pip install jieba。
中文文本预处理 :
中文文本需分词,推荐使用jieba库。预处理步骤包括:
- 分词与自定义词典:使用jieba.cut()进行分词,并通过jieba.suggest_freq()添加自定义词典(如人名)以提升准确性。
- 停用词处理:可选步骤,因Word2vec依赖上下文,停用词通常保留,但若需过滤,可加载停用词列表并移除。
- 文件读写:分词后需将结果保存为文件,以便模型读取。例如,读取原始文本文件,分词后按行或整体写入新文件,注意编码格式(如UTF-8)。
模型训练与参数设置 :
使用Gensim的word2vec.Word2Vec类训练模型,关键参数包括:
- sentences:输入语料,可为文件路径或分词后的迭代器(如LineSentence或PathLineSentences)。
- size:词向量维度,默认100,小语料可保持默认,大语料建议增大。
- window:上下文窗口大小,默认5,一般取值5,10。
- min_count:忽略低频词的阈值,默认5,小语料可调低。
- sg:模型选择,0为CBOW,1为Skip-Gram,默认CBOW。
- workers:并行线程数,通常设为CPU核心数。
训练代码示例:
python
from gensim.models import word2vec
import multiprocessing
sentences = word2vec.LineSentence("segmented_text.txt") # 或 PathLineSentences 处理多文件
model = word2vec.Word2Vec(sentences, size=100, window=5, min_count=5, workers=multiprocessing.cpu_count())
model.save("word2vec_model.model") # 保存模型模型使用与评估 :
训练后可加载模型进行查询,如计算词相似度或找近义词:
- 加载模型:model = word2vec.Word2Vec.load("word2vec_model.model")。
- 相似度计算:model.wv.similarity("词A", "词B")返回0-1相似度值。
- 近义词查找:model.wv.most_similar("词", topn=10)获取最相似的10个词。
- 类比任务:model.wv.most_similar(positive="词A", "词B", negative="词C")。
评估时需注意,Word2vec基于统计,结果受语料质量影响,建议通过下游任务(如分类)验证效果。
词向量在企业中应用
1)词向量可视化探索
词向量可视化是探索自然语言处理模型内部语义结构的关键方法,它将高维词向量(通常数百维)投影到二维或三维空间,使词汇之间的语义关系变得直观可察。
词向量可视化的核心在于将高维数据降维到低维空间。 词向量通常具有高维度(如300维),无法直接观察,因此需要使用降维技术如多维缩放(MDS)或t-SNE,这些方法通过保持词向量间的相对距离或相似度,在低维空间中重构词汇的拓扑结构,从而揭示聚类和关联模式。
2)向量检索工具
向量检索工具是一种基于向量相似度计算来高效查找相关数据的技术,它将数据(如文本、图像)转换为向量表示,并通过计算向量间的距离或相似度分数快速定位最相关的条目,广泛应用于语义搜索、推荐系统和智能问答等场景。
-
使用 Annoy 加速搜索
Annoy(Approximate Nearest Neighbors Oh Yeah)是一个用C++编写的近似最近邻搜索库,通过树结构索引加速高维向量的相似性检索,特别适合处理大规模数据集的快速搜索需求。
安装与基本使用: 安装Annoy可通过pip命令完成,例如 pip install annoy;在Windows系统上可能遇到编译依赖问题,可考虑使用预编译的wheel包或Conda环境解决。基本使用流程包括创建索引、添加向量、构建索引和执行搜索
-
使用 Faiss 加速搜索
向量检索工具利用Facebook AI Similarity Search(Faiss)加速搜索,通过优化算法和数据结构实现大规模高维向量的快速相似性查询。
Faiss的核心加速技术包括量化算法和索引结构。 量化算法(如标准量化、乘积量化)将高维向量映射到低维码本,减少存储空间和计算量;索引结构(如倒排索引IVF)通过预筛机制降低搜索复杂度,避免全库扫描。
使用Faiss加速搜索的关键步骤包括数据准备、索引构建和查询优化。 首先将数据转换为向量格式(如浮点数数组),然后选择合适索引(如Flat索引用于精确搜索,IVF索引用于近似搜索),最后通过GPU加速和距离度量(如L2距离或余弦相似度)优化查询。
Faiss在实际场景中应用广泛,性能优势显著。 例如在图像搜索中,将图像编码为向量后使用Faiss快速匹配;在推荐系统中,通过词嵌入向量实现高效相似内容检索。实验表明,Faiss的检索速度比传统方法提升数倍,尤其适合实时应用。