在StarRocks中,用户提交的SQL查询文本在FE需要经过一系列处理,最终生成分布式执行计划并分发到各个Backend(BE)节点进行计算。核心流程包括以下五个步骤:
-
Parser解析:将SQL文本解析为抽象语法树AST,表示其语法结构。
-
Analyze分析:对AST进行语义分析,验证表、列是否存在,检查语法合法性等。
-
Logical Plan生成:将AST转换为逻辑执行计划Logical Plan,即用Operator描述,描述查询的逻辑操作。
-
规则重写:基于一系列优化规则(如谓词下推、列裁剪)重写Logical Plan,提升执行效率。
-
Optimizer优化:通过代价模型选择最优的物理执行计划Physical Plan,并分发到BE节点执行。
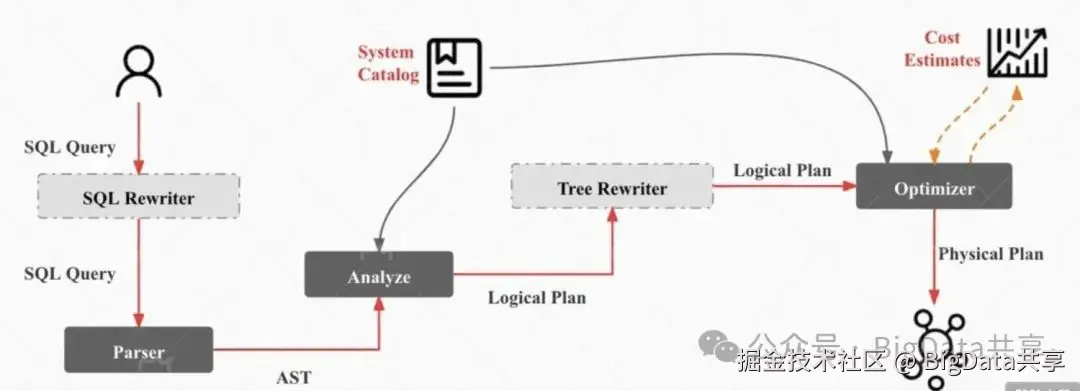
本文聚焦于Parser解析阶段,以一个简单SQL语句为例,结合ANTLR4解析器,详细分析SQL文本如何转化为AST,并简要介绍StarRocks的实现方式。
SQL语句是一种结构化查询语言,其文本形式在计算机中通常通过 AST(抽象语法树)表示。AST是一种树形数据结构,能有效表达SQL的词法、语法及嵌套层次结构。例如,以下SQL语句
css
SELECT a, sum(b) FROM tablex GROUP BY a ORDER BY a LIMIT 3;通过解析工具可生成对应的解析树(可使用ANTLR Preview插件查看)
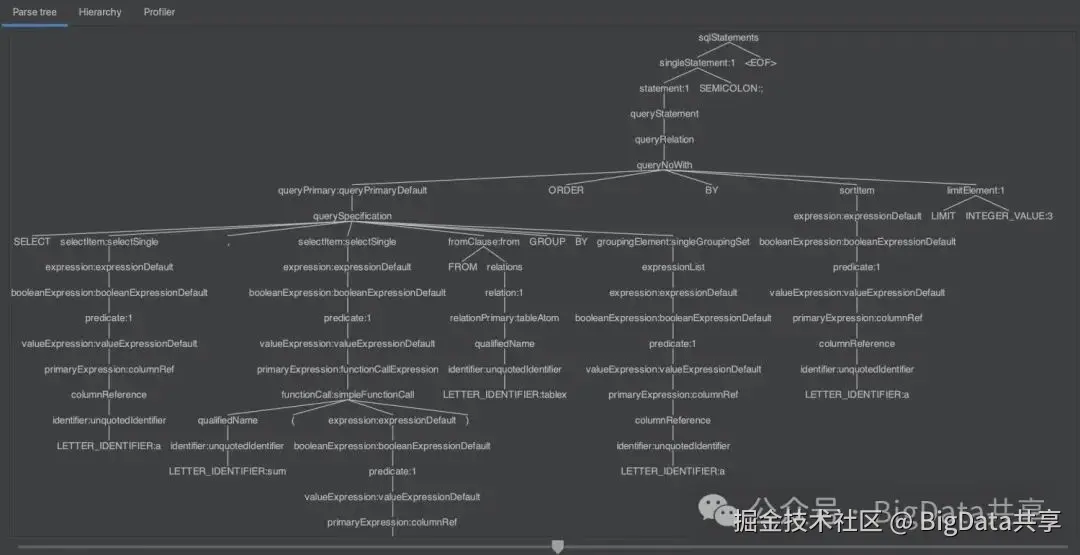
简单SELECT语句案例:ANTLR4与SQL解析
以下通过一个简单SQL语句, 展示ANTLR4解析流程。
sql
SELECT xx FROM table_xx;1.创建一个maven工程,增加以下依赖
xml
<dependency> <groupId>org.antlr</groupId> <artifactId>antlr4</artifactId> <version>4.11.1</version> </dependency>2.创建一个 SimpleSQL.g4 规则文件
css
grammar SimpleSQL;
// 语法规则singleStatement : selectStatement EOF ;
selectStatement : SELECT selectList FROM tableName #select ;
selectList : '*' #allColumns | identifier (',' identifier)* #columnList ;
tableName : identifier ;
identifier : ID ;
// 词法规则SELECT : 'SELECT' | 'select';FROM : 'FROM' | 'from';ID : [a-zA-Z_][a-zA-Z0-9_]*;WS : [ \t\r\n]+ -> skip;3.IDEA 安装 ANTLR 插件,然后就可以使用该文件自动生成代码
4.创建 Java 类表示 AST 节点,SelectStmt 用来描述 select 语句,用于存储解析后的 select SQL
arduino
import java.util.ArrayList;import java.util.List;
abstract class ParseNode {}
class SelectStmt extends ParseNode { private final SelectList selectList; private final String tableName;
public SelectStmt(SelectList selectList, String tableName) { this.selectList = selectList; this.tableName = tableName; }
@Override public String toString() { return "SELECT " + selectList + " FROM " + tableName; }}
class SelectList extends ParseNode { private final boolean isAllColumns; private final List<String> columns;
public SelectList(boolean isAllColumns, List<String> columns) { this.isAllColumns = isAllColumns; this.columns = columns != null ? columns : new ArrayList<>(); }
@Override public String toString() { return isAllColumns ? "*" : String.join(", ", columns); }}5.创建 ASTBuilder 类,继承 ANTLR4 的 SimpleSQLBaseVisitor,将解析树转换为 AST,实现对应的visitXXX 方法,转成对应的 ParseNode
typescript
import com.sql.parser.SimpleSQLBaseVisitor;import com.sql.parser.SimpleSQLParser;
import java.util.ArrayList;import java.util.List;
public class ASTBuilder extends SimpleSQLBaseVisitor<ParseNode> { @Override public ParseNode visitSingleStatement(SimpleSQLParser.SingleStatementContext ctx) { return visit(ctx.selectStatement()); }
@Override public ParseNode visitSelect(SimpleSQLParser.SelectContext ctx) { SelectList selectList = (SelectList) visit(ctx.selectList()); String tableName = ctx.tableName().identifier().ID().getText(); return new SelectStmt(selectList, tableName); }
@Override public ParseNode visitAllColumns(SimpleSQLParser.AllColumnsContext ctx) { return new SelectList(true, null); }
@Override public ParseNode visitColumnList(SimpleSQLParser.ColumnListContext ctx) { List<String> columns = new ArrayList<>(); for (SimpleSQLParser.IdentifierContext idCtx : ctx.identifier()) { columns.add(idCtx.ID().getText()); } return new SelectList(false, columns); }}6.实现自定义的 SqlParser 类,作为解析入口,调用 ANTLR4 的 Lexer 和 Parser,并使用 ASTBuilder 生成 AST
java
import com.sql.parser.SimpleSQLLexer;import com.sql.parser.SimpleSQLParser;import org.antlr.v4.runtime.*;import org.antlr.v4.runtime.tree.ParseTree;
public class SqlParser { public static ParseNode parse(String sql) throws Exception { CharStream input = CharStreams.fromString(sql); SimpleSQLLexer lexer = new SimpleSQLLexer(input);
lexer.removeErrorListeners(); lexer.addErrorListener(new BaseErrorListener() { @Override public void syntaxError(Recognizer<?, ?> recognizer, Object offendingSymbol, int line, int charPositionInLine, String msg, RecognitionException e) { throw new RuntimeException("Syntax error at line " + line + ":" + charPositionInLine + " " + msg); } });
CommonTokenStream tokens = new CommonTokenStream(lexer); SimpleSQLParser parser = new SimpleSQLParser(tokens);
parser.removeErrorListeners(); parser.addErrorListener(new BaseErrorListener() { @Override public void syntaxError(Recognizer<?, ?> recognizer, Object offendingSymbol, int line, int charPositionInLine, String msg, RecognitionException e) { throw new RuntimeException("Syntax error at line " + line + ":" + charPositionInLine + " " + msg); } });
ParseTree tree = parser.singleStatement();
// 使用 ASTBuilder 转换为 AST ASTBuilder builder = new ASTBuilder(); return builder.visit(tree); }}7.写个简单的测试用例
typescript
public class SqlTest { public static void main(String[] args) { String[] sqls = { "SELECT * FROM table_x", "SELECT a, b FROM table_x", "SELECT a, b FROM " };
for (String sql : sqls) { try { ParseNode ast = SqlParser.parse(sql); System.out.println("AST: " + ast); } catch (Exception e) { System.out.println("Error: " + e.getMessage()); } } }}输出结果如下,第三条sql解析语法错误
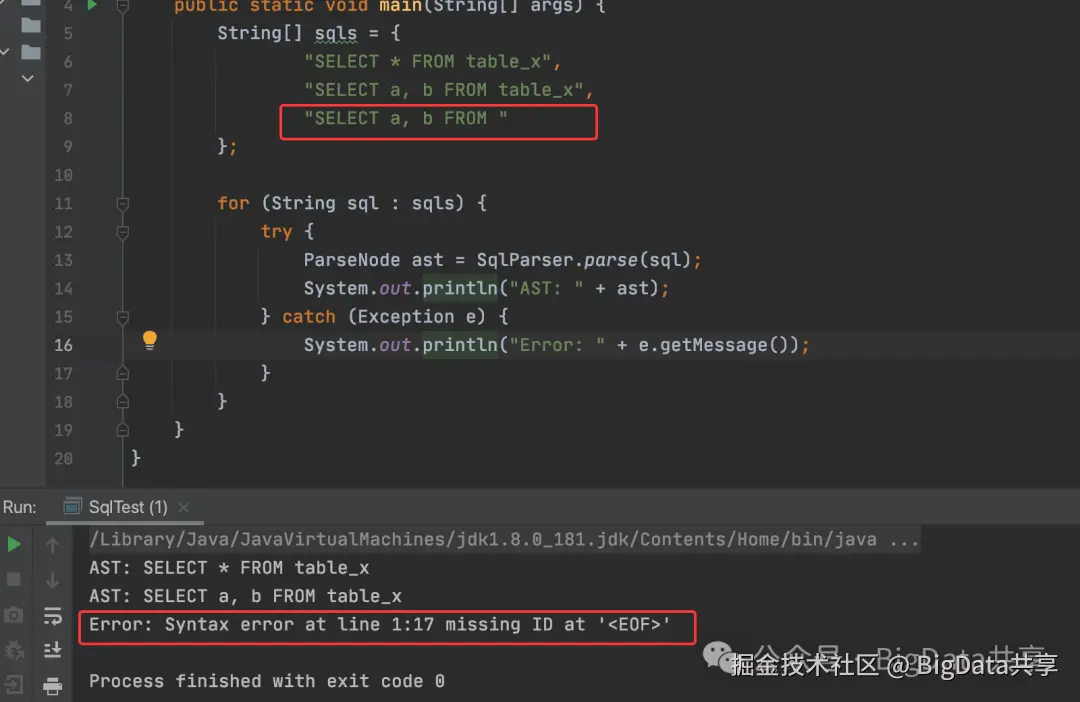
StarRocks中的SQL解析
StarRocks基于ANTLR4对词法语法进行解析的逻辑也是一样,其核心组件包括:
-
StarRocks.g4 和 StarRocksLex.g4:定义词法和语法规则。
-
ParseNode:接口类,所有AST节点都要实现该接口。
-
SqlParser:解析入口,调用ANTLR4的Lexer和Parser。
-
AstBuilder:将解析树转换为AST。
ParseNode, 是一个接口,所有具体的 AST 节点都继承或实现它
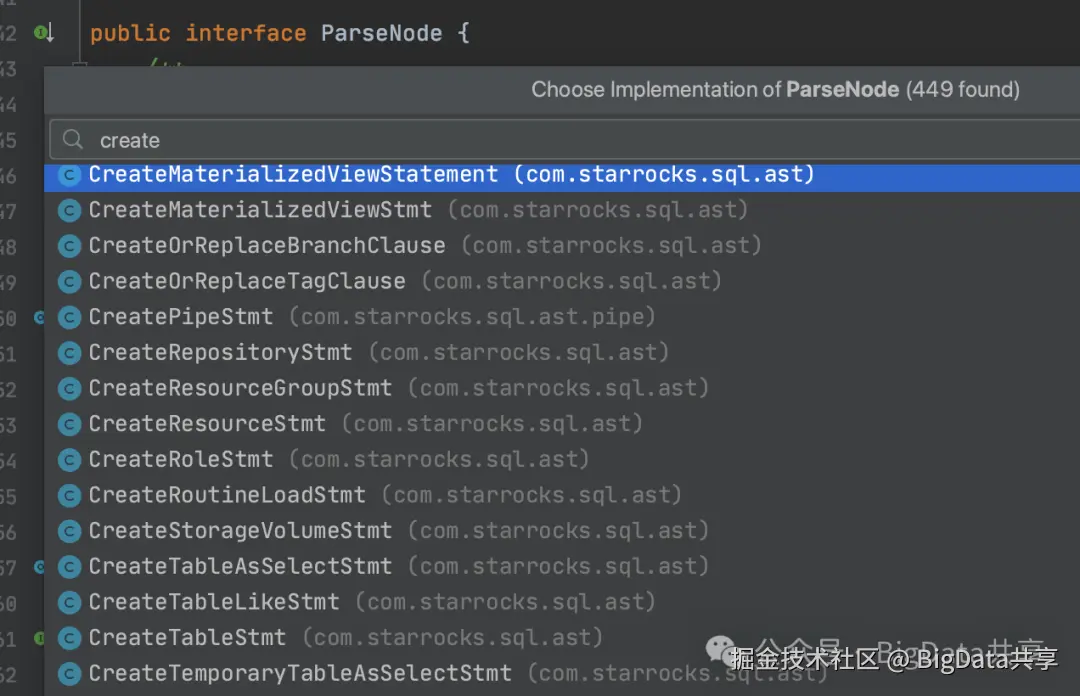
SqlParser
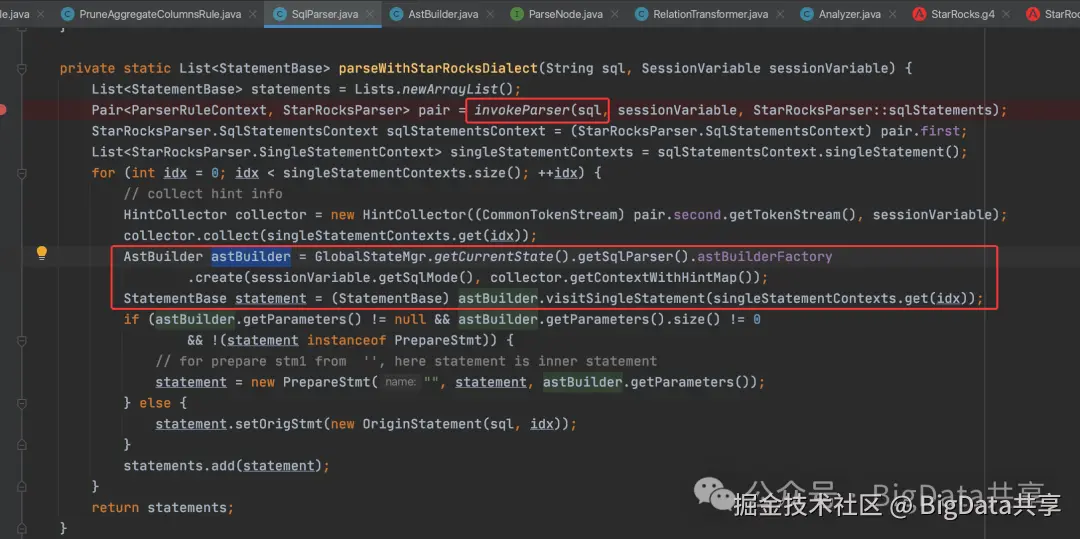 调用 StarRocksLexer,StarRocksParser进行词法,语法解析
调用 StarRocksLexer,StarRocksParser进行词法,语法解析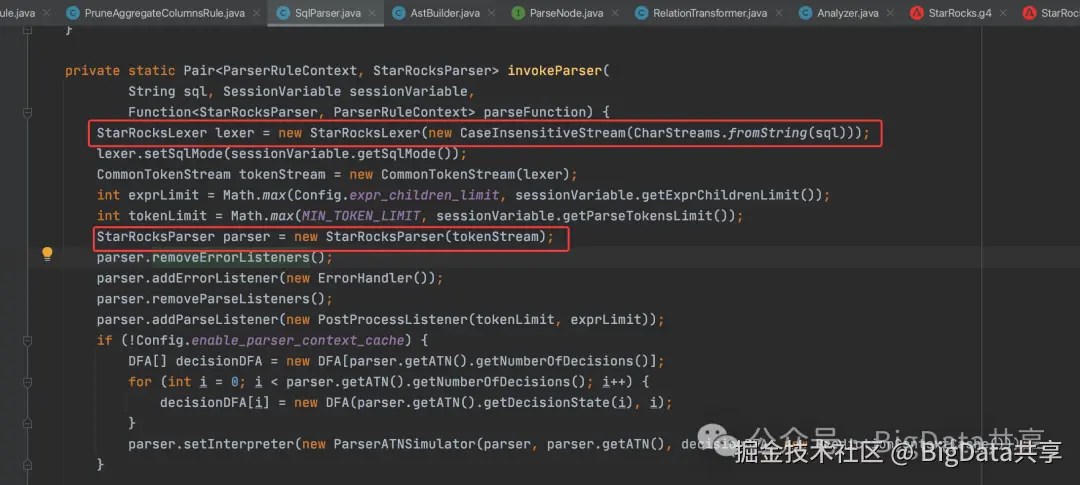
AstBuilder 处理单个 SQL 语句,递归访问子节点。AstBuilder 继承自AbstractParseTreeVisitor,通过重写 visit 方法(如 visitCreateDbStatement、visitCreateTableStatement)遍历解析树,生成对应的 ParseNode 节点,通过 visitChildren 遍历子节点;
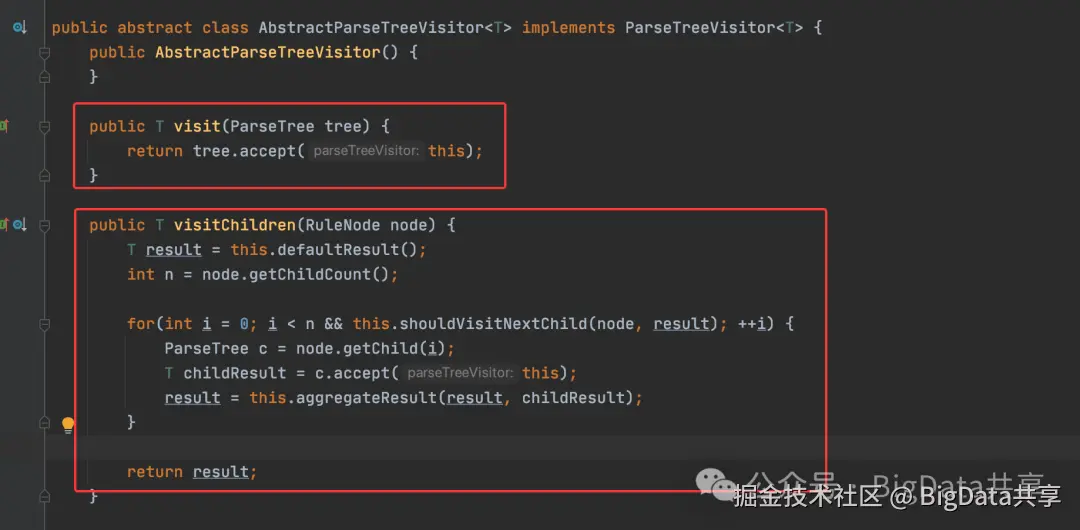 最终构建一棵树,返回 ParseNode 的具体实现类实例。至此 Parser 解析阶段完成。 更多大数据干货,欢迎关注我的微信公众号---BigData共享
最终构建一棵树,返回 ParseNode 的具体实现类实例。至此 Parser 解析阶段完成。 更多大数据干货,欢迎关注我的微信公众号---BigData共享