Redis集群(Redis Cluster)是 Redis 官方提供的分布式解决方案,通过数据分片(Sharding)和高可用(High Availability)机制,实现水平扩展和故障自动转移。
一、 Redis集群架构
Redis集群由多个主节点(Master)和对应的从节点(Replica)组成,每个节点负责存储部分数据(分片)。采用去中心化的分布式架构,通过分片(Sharding)实现数据的分布式存储。
(一) 特性
1、去中心化架构: 无中心节点,所有3节点通过Gossip协议通信。
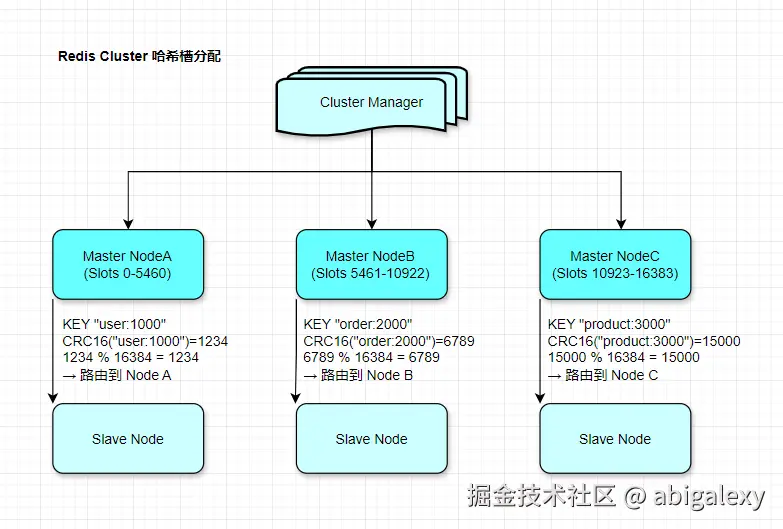
2、16384个哈希槽(Hash Slots): 数据通过 CRC16 算法映射到哈希槽,再分配到节点。
3、客户端直接路由 : 客户端可缓存槽位映射,直接访问正确节点(遇重定向时需处理MOVED/ASK错误)。
4、自动故障转移: 通过哨兵(Sentinel)类似的机制检测故障并选举新主节点。
| 角色 | 职责 |
|---|---|
| 主节点(Master) | 处理读写请求,负责分配的哈希槽范围内的数据 |
| 从节点(Slave) | 复制主节点数据,主节点故障时,由 Replica 选举为新 Master(故障转移) |
(二)数据分片(Sharding)
Redis 集群将整个数据空间划分为16384个哈希槽(编号 0~16383),每个槽对应一个数据分片。
1、哈希槽
分配算法
slot = CRC16(key) % 16384
定位节点
1)客户端计算键的哈希槽
2)查找槽所在节点
3)直接连接对应节点操作数据
集群维护一个槽到节点的映射表(CLUSTER SLOTS 命令可查看),客户端根据槽号找到对应节点。
2、动态扩缩容
添加节点:新节点加入时,会从现有节点迁移部分哈希槽(如从 Node A 迁移 1000 个槽到 Node C)。
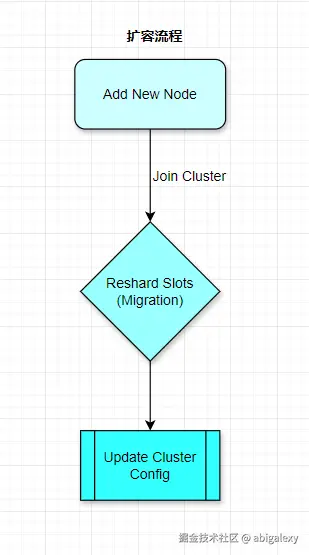
删除节点:将待删除节点的哈希槽重新分配到其他节点。
(三)集群通信
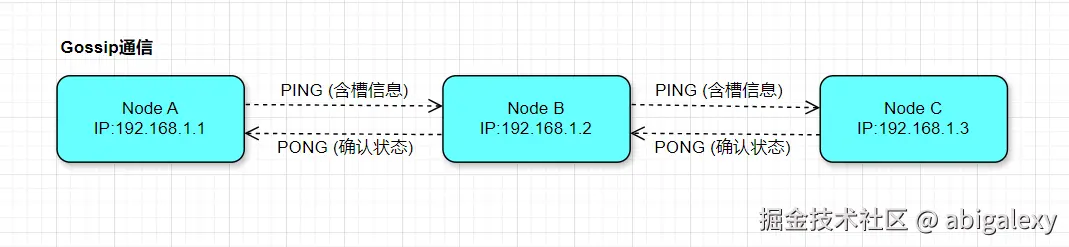
1、Gossip协议
Redis集群使用Gossip协议传播节点状态信息(如新增节点、故障检测、槽迁移等)
1)每秒随机选择5个节点中最久未通信的节点进行PING
2)携带自身和其他节点的状态信息
3)收到PING后回复PONG消息
消息类型
| 类型 | 说明 |
|---|---|
| MEET | 手动触发新节点加入集群 |
| PING | 检测节点健康状态,节点定期交换元数据(如槽分配、IP 地址、端口) |
| PONG | 对PING/MEET的响应,节点定期交换元数据(如槽分配、IP 地址、端口) |
| FAIL | 广播故障节点信息,通知其他节点某节点已下线,触发故障转移 |
| PUBLISH | 发布订阅消息 |
2、集群总线(Cluster Bus)
通信端口:每个节点使用主端口(如 6379)处理客户端请求,总线端口(主端口+10000,如 16379) 处理节点间通信。
消息格式:基于RESP协议扩展的二进制格式,包含节点ID、槽信息、状态标志等。
(四)故障恢复
1、故障检测
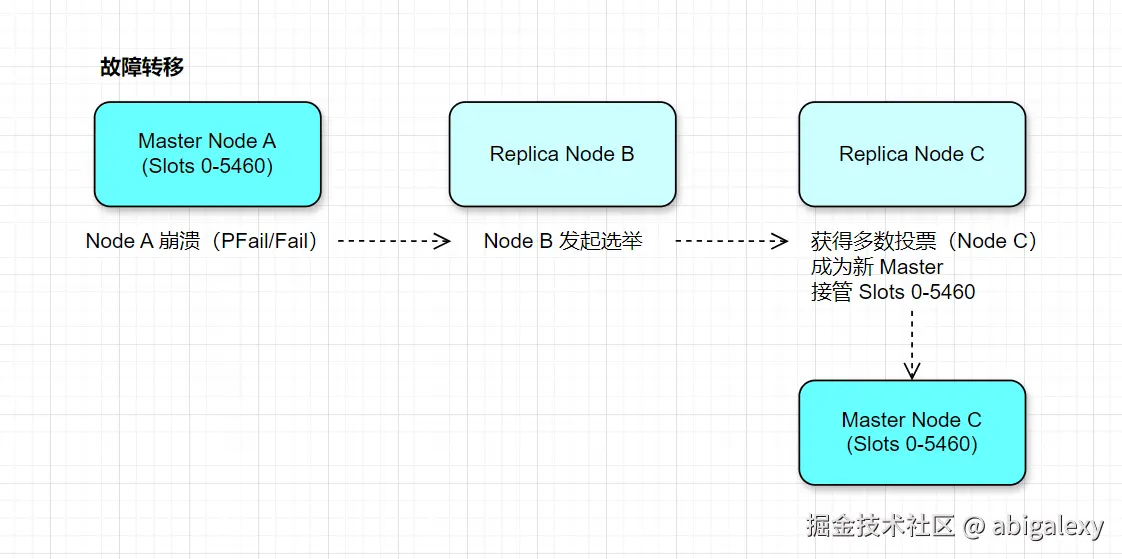
主观下线(PFail):节点A发现节点B超过cluster-node-timeout未响应,标记B为PFail。
客观下线(Fail):节点A通过Gossip协议将PFail广播给其他节点,若多数节点确认B不可达,则标记B为 Fail。
2、故障转移
1)故障检测:超过半数主节点确认某主节点下线
2)满足条件的Replica选举:
基于Raft算法的选举机制
优先选择复制偏移量最大的,数据最新从节点
3)配置更新:新主节点接管槽位并通知集群
3、槽重新分配
新Master接管原Master的哈希槽。
其他节点更新槽映射表。
(五)集群配置
| 配置项 | 说明 |
|---|---|
| cluster-enabled yes | 启用集群模式 |
| cluster-node-timeout | 节点超时时间(默认 15000ms),超时触发故障检测 |
| cluster-replica-validity-factor | Replica与Master断连超时阈值(防止脑裂) |
1、常用命令
sh
# 查看集群状态
redis-cli --cluster check <host:port>
redis-cli -c --cluster check 192.168.1.1:6379
# 添加新节点
redis-cli --cluster add-node 192.168.1.4:6379 192.168.1.1:6379
redis-cli --cluster add-node new_host:new_port existing_host:existing_port
# 手动故障转移
CLUSTER FAILOVER [FORCE|TAKEOVER]
# 重新分片(迁移槽)
redis-cli --cluster reshard <host:port>
redis-cli --cluster reshard 192.168.1.1:6379
# 删除节点
redis-cli --cluster del-node host:port node_id2、Redis集群 vs 哨兵模式
| 特性 | Redis Cluster | Redis Sentinel |
|---|---|---|
| 数据分片 | 支持(哈希槽) | 不支持(单主节点) |
| 故障转移 | Replica自动选举 | Sentinel自动投票 |
| 客户端路由 | 直接路由(需处理重定向) | 通过代理或客户端重定向 |
| 适用场景 | 大规模数据分布式存储 | 高可用但无需分片的场景 |
(六)Redis集群优化
1、集群架构优化
1)合理规划分片数量
分片数量:根据数据量和访问模式选择分片数(通常为16384的约数,如10、20、50等)。分片过多会增加管理开销,过少会导致数据倾斜。
哈希标签(Hash Tag):对需要共存于同一分片的数据使用{user:1000}.profile格式的键名,避免热点数据分散。
2)节点角色分配
主从比例:每个主节点建议配置1-2个从节点,平衡读写扩展与资源消耗。
避免单点瓶颈:确保高流量键均匀分布在多个主节点上,可通过监控工具(如redis-cli --stat)观察请求分布。
3)多数据中心部署
跨机房同步:使用Redis Enterprise或Proxy方案(如Twemproxy)实现跨机房集群,减少网络延迟对性能的影响。
异地容灾:通过CLUSTER REPLICATE命令配置跨机房从节点,确保故障时快速切换。
2、配置参数调优
1)内存管理
淘汰策略:根据业务需求选择volatile-lru(优先淘汰易变数据)或allkeys-lfu(全局使用频率淘汰)。
内存碎片整理:设置activedefrag yes并调整active-defrag-threshold-lower(默认10%)触发碎片整理。
2)网络优化
TCP参数:调整tcp-keepalive 60(保持长连接)和tcp-backlog 511(增加连接队列容量)。
集群总线:确保cluster-port(默认16379)与客户端端口分开,避免网络拥塞。
3)持久化策略
AOF+RDB混合:启用aof-use-rdb-preamble yes,结合RDB的快速恢复和AOF的增量安全。
异步写入:设置appendfsync everysec平衡性能与数据安全,禁用fsync always。
3、数据访问优化
1)批量操作
Pipeline:将多个命令打包发送(如MGET替代多次GET),减少网络往返时间(RTT)。
Lua脚本:使用EVAL执行原子性复杂操作(如计数器+条件判断),避免多次网络请求。
2)数据结构选择
Hash优化:对小对象使用HSET替代多个SET,减少键数量(例如用户属性存储)。
Sorted Set:对排行榜等场景使用ZADD/ZRANGE,避免全量扫描。
3)缓存策略
多级缓存:结合本地缓存(如Caffeine)和Redis,减少对集群的直接访问。
布隆过滤器:使用BF.RESERVE/BF.ADD过滤不存在的键查询,降低穿透风险。
4、监控与运维
1)实时监控
指标采集:通过INFO命令或Prometheus+Grafana监控instantaneous_ops_per_sec、used_memory等关键指标。
慢查询日志:设置slowlog-log-slower-than 10000(微秒)记录耗时操作,优化热点键。
2)自动化运维
动态扩容:使用CLUSTER ADDSLOTS和CLUSTER MEET在线添加节点,避免停机。
故障转移:配置cluster-node-timeout 2000(毫秒)调整故障检测灵敏度,防止误切换。
3)压力测试
基准测试:使用redis-benchmark -t set,get -n 1000000 -c 50模拟高并发场景,验证集群吞吐量。
混沌工程:随机杀死节点或模拟网络分区,测试集群容错能力。
示例优化配置(redis.conf)
sh
# 基础配置
# 守护进程模式(生产环境建议启用)
daemonize yes
# 进程文件(确保Redis用户有写入权限)
pidfile /var/run/redis/redis-cluster-6379.pid
# 工作目录(用于持久化文件存储)
dir /data/redis/cluster/6379
# 日志级别(生产环境用warning,调试用debug)
loglevel warning
logfile /var/log/redis/redis-cluster-6379.log
# 绑定监听地址(生产环境绑定内网IP或0.0.0.0)
bind 0.0.0.0
# 保护模式(集群模式下必须关闭)
protected-mode no
# 内存管理
# 最大内存限制(根据服务器内存设置,例如10GB)
maxmemory 10gb
# 内存淘汰策略(优先淘汰不常用数据)
maxmemory-policy allkeys-lfu
# 内存碎片整理(自动回收碎片内存)
activedefrag yes
# 碎片率>10%时启动
active-defrag-threshold-lower 10
# 碎片率>25%时全力回收
active-defrag-threshold-upper 25
# 最小回收周期(%)
active-defrag-cycle-min 1
# 最大回收周期(%)
active-defrag-cycle-max 25
# 网络优化
# 端口(集群节点间通信端口默认为客户端端口+10000)
port 6379
# TCP keepalive(防止连接断开)
tcp-keepalive 60
# TCP连接队列大小(高并发时调整)
tcp-backlog 511
# 客户端超时时间(0表示永不超时)
timeout 0
# 客户端连接数限制(根据业务需求调整)
maxclients 10000
# 持久化配置
# 开启AOF持久化(推荐混合模式)
appendonly yes
appendfilename "appendonly-6379.aof"
# AOF写入策略(每秒同步,平衡性能与安全)
appendfsync everysec
# AOF重写触发条件(文件增长百分比)
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# AOF使用RDB预加载(快速恢复)
aof-use-rdb-preamble yes
# 关闭RDB持久化(若仅用AOF可关闭,否则保留)
# save 900 1
# save 300 10
# save 60 10000
# rdbcompression yes
# rdbchecksum yes
# dbfilename dump-6379.rdb
# 集群配置
# 启用集群模式
cluster-enabled yes
# 集群配置文件名
cluster-config-file nodes-6379.conf
# 集群节点超时时间(毫秒,影响故障转移速度)
cluster-node-timeout 2000
# 集群要求全覆盖(若部分节点不可用,是否阻止客户端请求)
cluster-require-full-coverage no
# 集群迁移屏障(最少需要多少个从节点才能迁移槽位)
cluster-migration-barrier 1
# 安全控制
# 设置密码(所有节点需一致)
requirepass YourStrongPassword
# 集群节点认证密码(与requirepass相同)
masterauth YourStrongPassword
# 命令重命名(防止危险命令执行)
rename-command FLUSHALL ""
rename-command CONFIG ""
rename-command KEYS ""
# 高级优化
# 禁用THP(避免内存交换影响性能)
# echo never > /sys/kernel/mm/transparent_hugepage/enabled
# 慢查询日志(记录执行时间超过10ms的命令)
slowlog-log-slower-than 10000
slowlog-max-len 1000
# 监听通知(若不需要Keyspace通知可关闭)
notify-keyspace-events ""
# 哈希表动态调整(减少内存波动)
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
# 列表压缩优化
list-max-ziplist-size -2
list-compress-depth 0
# 有序集合优化
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
# 集合优化
set-max-intset-entries 512操作步骤
1、将上述配置保存为redis-cluster-6379.conf,并复制到所有节点。
启动Redis
redis-server /path/to/redis-cluster-6379.conf
2、组建集群,使用redis-cli连接任意节点,执行:
redis-cli --cluster create <node1_ip>:6379 <node2_ip>:6379 ... --cluster-replicas 1
3、验证集群状态
redis-cli -c -h <node_ip> -p 6379 -a YourStrongPassword CLUSTER NODES
二、Redis分布式缓存架构
(一)高可用集群架构
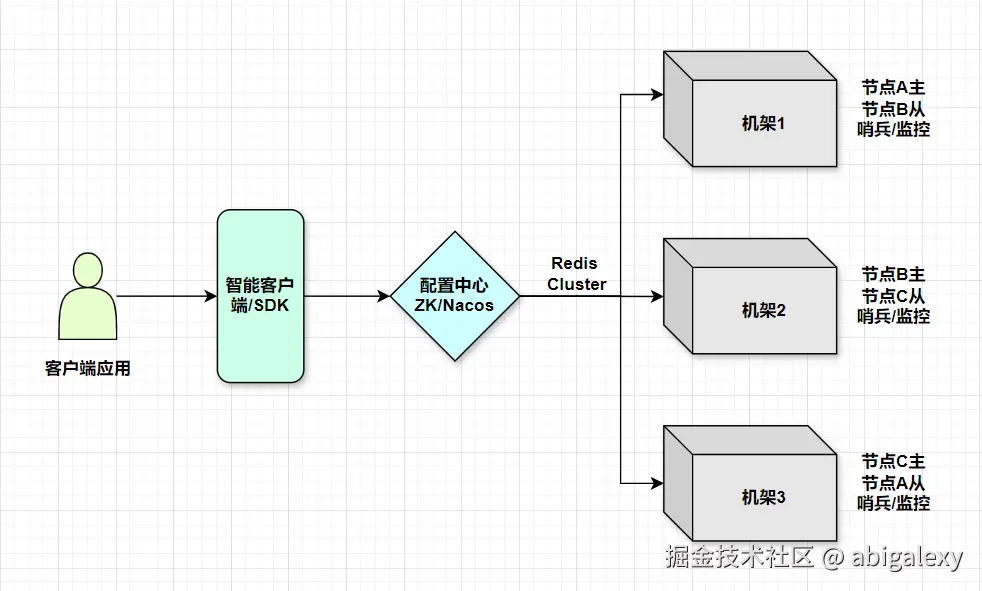
(二)多层缓存架构
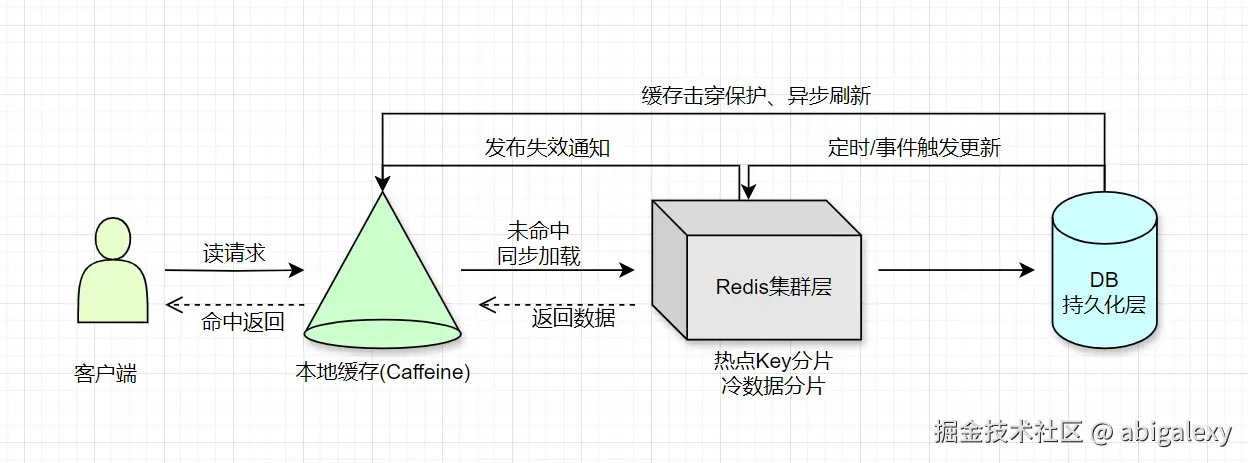
(三)数据安全方案
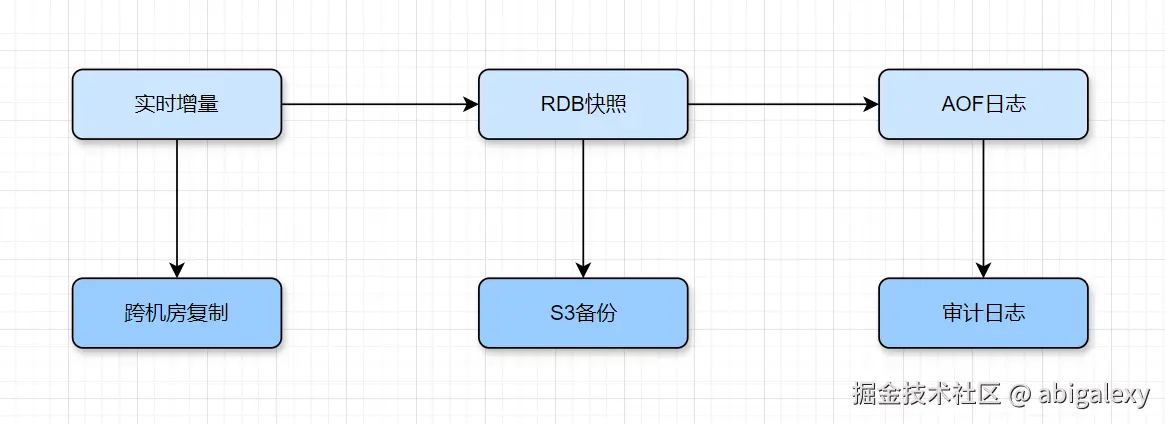
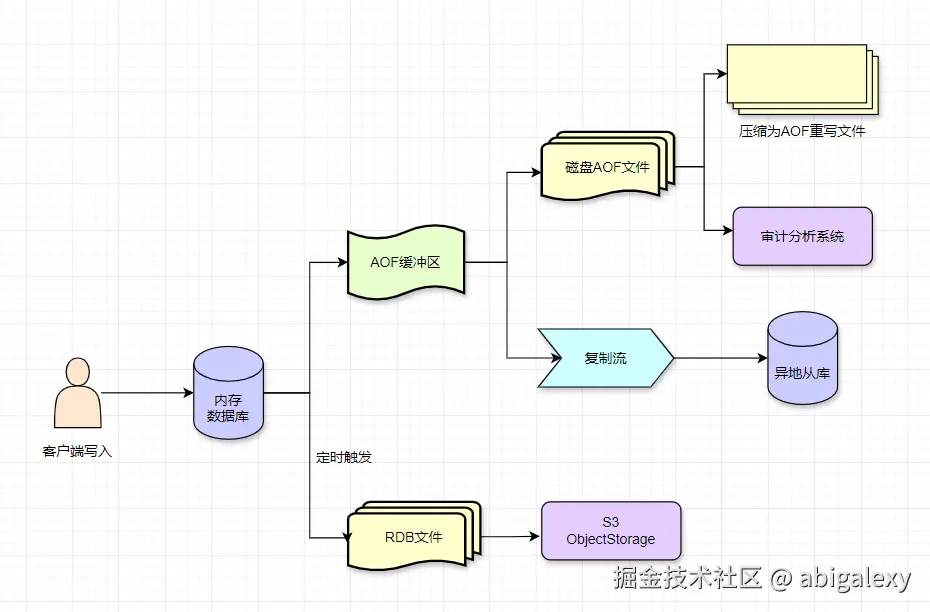
第一层:实时数据保护
| 组件 | 技术实现 | 特点 |
|---|---|---|
| 实时增量 | 基于主从复制的 repl-backlog-buffer |
秒级数据同步,内存级保护 |
| RDB快照 | SAVE/BGSAVE 生成二进制dump文件 |
全量备份,恢复快但可能丢数分钟数据 |
| AOF日志 | 配置 appendfsync everysec (折衷方案) |
增量持久化,最多丢1秒数据 |
协同关系
AOF记录每个写操作,RDB定期全量备份,两者通过 aof-use-rdb-preamble yes 可混合使用。
第二层:灾备方案
| 流向 | 实现方式 | 应用场景 |
|---|---|---|
| 跨机房复制 | 通过 REPLICAOF 建立异地容灾集群 |
机房级故障切换 (RTO<30秒) |
| S3备份 | 将RDB文件上传至AWS S3/OSS (需脚本自动化) | 防止物理损坏,保留历史版本 |
| 审计日志 | 开启 aclfile 或使用 redis-audit 工具 |
安全合规与操作追溯 |
1、生产部署建议
1)RDB配置
每天1次全量 + 每小时增量
cronjob: 0 * * * * redis-cli bgsave
2)跨机房同步
使用双向同步架构避免单点故障
网络延迟>50ms时建议启用 repl-disable-tcp-nodelay no
3)备份验证
定期测试备份有效性
redis-server --test-memory-load 80 &
redis-check-rdb /backup/dump.rdb
4)监控指标
persistence.rdb.last_bgsave_status
replication.backlog_histlen
2、异常处理方案
| 故障类型 | 恢复策略 |
|---|---|
| AOF损坏 | 使用 redis-check-aof --fix 修复 |
| RDB丢失 | 从S3拉取最近备份 + AOF重放 |
| 网络分区 | 通过 CLUSTER FAILOVER 手动切换 |
| 审计遗漏 | 结合Linux auditd 进行双重记录 |
(四)生产部署checklist
1、至少3主3从跨机架部署
2、监控指标全覆盖(CPU/内存/延迟/命中率)
3、备份策略验证(RDB+AOF)
4、故障转移演练
5、压测报告(单节点≥5万QPS)
6、安全组/密码认证配置
(五)典型问题处理方案
热点Key → 本地缓存+分片
BigKey → 拆分+扫描删除
倾斜 → 手动reshard
脑裂 → 合理配置超时
缓存雪崩 → 过期时间离散化