服务降级是事件驱动系统中的常见问题,也是当系统过载时候的常见解决方案。本文将介绍基于 TCP 拥塞控制算法对负载进行优先级排序,从而解决基于优先级的服务降级问题。原文:Enhancing Distributed System Load Shedding with TCP Congestion Control Algorithm
简介
我们团队负责向所有 Zalando 平台上的客户发送消息 ------ 比如确认已下的订单、告知喜爱品牌的最新动态或促销活动等。在准备这些消息以及通过不同服务提供商发送消息的过程中,我们面临着资源限制,无法以最快速度处理所有消息请求,从而有时会导致请求积压。
但并非所有的通信都同等重要。业务相关方要求我们确保按照既定的服务水平目标(SLO)来处理对关键业务运营起支持作用的通信内容。
这促使我们对负载削减(load shedding)解决方案进行研究。负载削减的问题已经在 Skipper 中有所涉及。但我们的系统是基于事件驱动的,处理的所有请求都通过 Nakadi 以事件形式传递,Skipper 的功能在这方面并无帮助。那为何不采用同样的基本理念呢?
我们知道,如果系统运行在正常范围内,就能满足 SLO 的要求。如果我们能控制系统接收消息请求的量,就能及时完成任务。此外,还需要将这种对接收量的控制与对那些支持关键业务操作的请求的优先级处理相结合。
系统概述
首先介绍下当前的系统。

Nakadi 是一个分布式事件总线,在类似 Kafka 的队列上提供 RESTful API。该组件为不同团队发布的数千种事件类型提供服务,用于不同目的,其中超过 1000 种不同的事件类型需要触发客户通信。
流消费者(Stream Consumer)作为整个平台事件入口的微服务,负责从 Nakadi 消费事件,进行一些处理操作,然后将事件推送到 RabbitMQ 代理中。每个 Nakadi 事件类型都由一个事件监听器实例进行处理。
RabbitMQ 是一个消息代理系统,被视为平台的核心组成部分,负责接收来自流消费者的消息,并将其提供给下游服务使用。
我们的平台包含众多服务,负责处理各类事件,其涵盖内容包括但不限于:
- 发送消息(包括推送通知和电子邮件)
- 检查客户许可、偏好和黑名单
- 检查客户资格
- 存储模板以及不同 Zalando 租户的配置
平台内部有许多相互作用的组件,这些组件之间的通信主要通过 RabbitMQ 进行。
每个服务都会向一个或多个交换器发布消息,并从一个或多个队列中接收消息,其他服务也是如此,因此服务之间有大量消息交互,而 RabbitMQ 则充当了这一切的中介角色。
概要设计
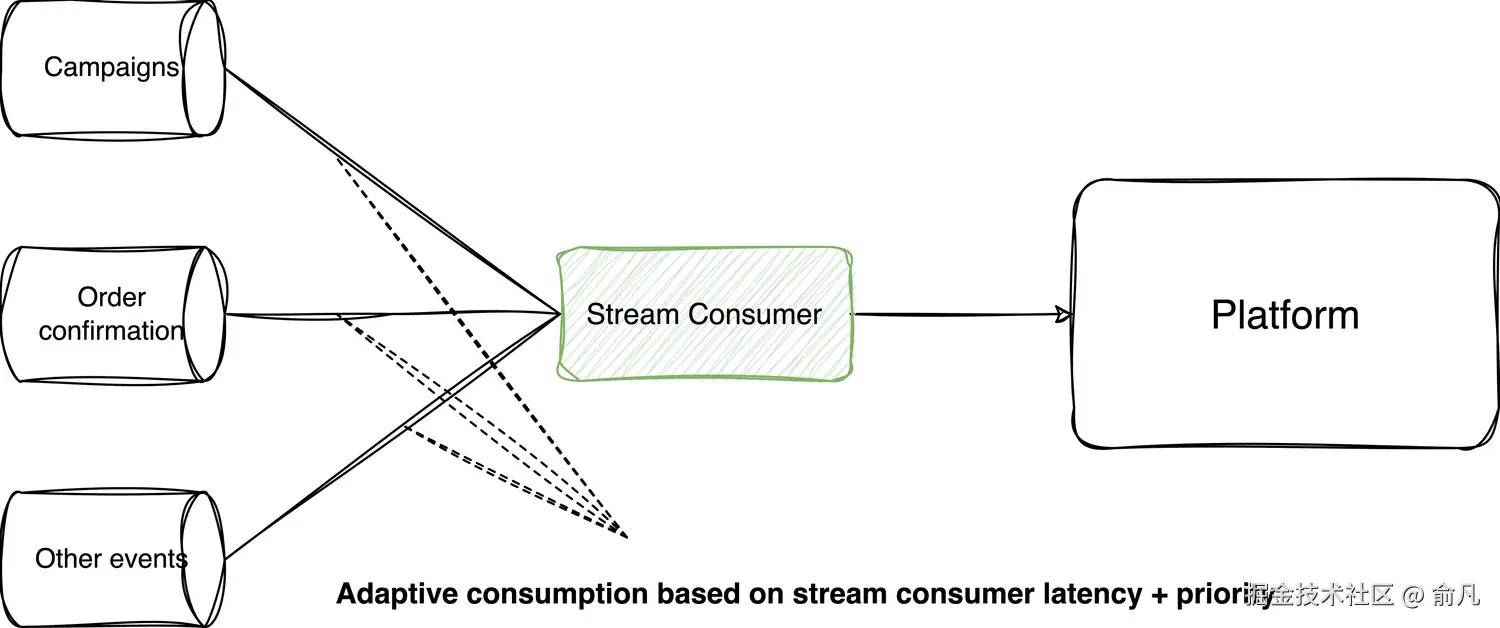
我们知道,为每个应用设置适当的冗余资源规模,能够确保其能够横向扩展并实现最佳吞吐量,从而满足 SLO。该系统具备根据需求动态获取资源的能力(通过基于 CPU/内存/端点调用/冗余资源的扩展机制来实现)。
我们将整个平台视为带接口的系统,并致力于在接口层面对其进行保护,即避免向该系统发送超出其处理能力的大量消息,以免造成系统过载。这意味着我们可以根据系统优先级和可用容量来控制数据的接收。
流消费者将采用 累加递增乘积递减(AIMD,Additive Increase Multiplicative Decrease) 算法来实现自适应并发管理。该算法会针对服务容量的降低做出反应,一旦检测到拥塞,请求速率就会乘以一个系数进行降低。
我们需要找到反映服务能力下降的恰当指标。流消费者会将消息发布到 RabbitMQ,所以我们一直在寻找可以从 RabbitMQ 中获取的指标。我们决定使用报错作为第一个指标。每当无法发布消息时,就应该降低消费速率。第二个指标则更为微妙。当检测到消费者响应缓慢且系统资源消耗过快时,RabbitMQ 能够施加回压。在这种情况下,RabbitMQ 会降低发布速率,而发布者则会感受到发布时间的延长。流消费者会监测这些指标,并调整消费速率。
降低所有类型事件的消费量有助于使系统保持在合理范围内运行,但目前尚未对关键事件类型进行优先级排序。该组件应该能够选择性的从 Nakadi 消费事件的速度来调整流消费者的速度。因此,每个事件类型都将根据其优先级和系统负载分配相应的速度,确保每个读取器都能获得为其分配的专用容量。如果有更多可用容量,系统将进行相应调整,并为需求更高的事件(积压量)提供更高的速度。
因此,无需为单个服务确定临界吞吐量。AIMD 算法在系统扩容后能自动适应增加的容量。最重要的是,该算法仅需一个局部变量,避免了像共享数据库那样的中心化协调。
通过采用这种方法,我们:
- 通过将相关机制限定在单一组件内,避免对所有微服务做出变更。
- 通过服务消费级别实现优先级排序,避免在平台内部对消息进行优先级排序的需求。
- 获得具有无单点故障特性的可扩展解决方案。
- 通过 Nakadi 保留冗余资源,降低 RabbitMQ 超载风险。
我们需要优化用于减少接收消息的指标实际值(发布到 RabbitMQ 的延迟),该值应使系统有足够负载来触发服务扩容,并减少 RabbitMQ 中存储的消息数量。
详细设计
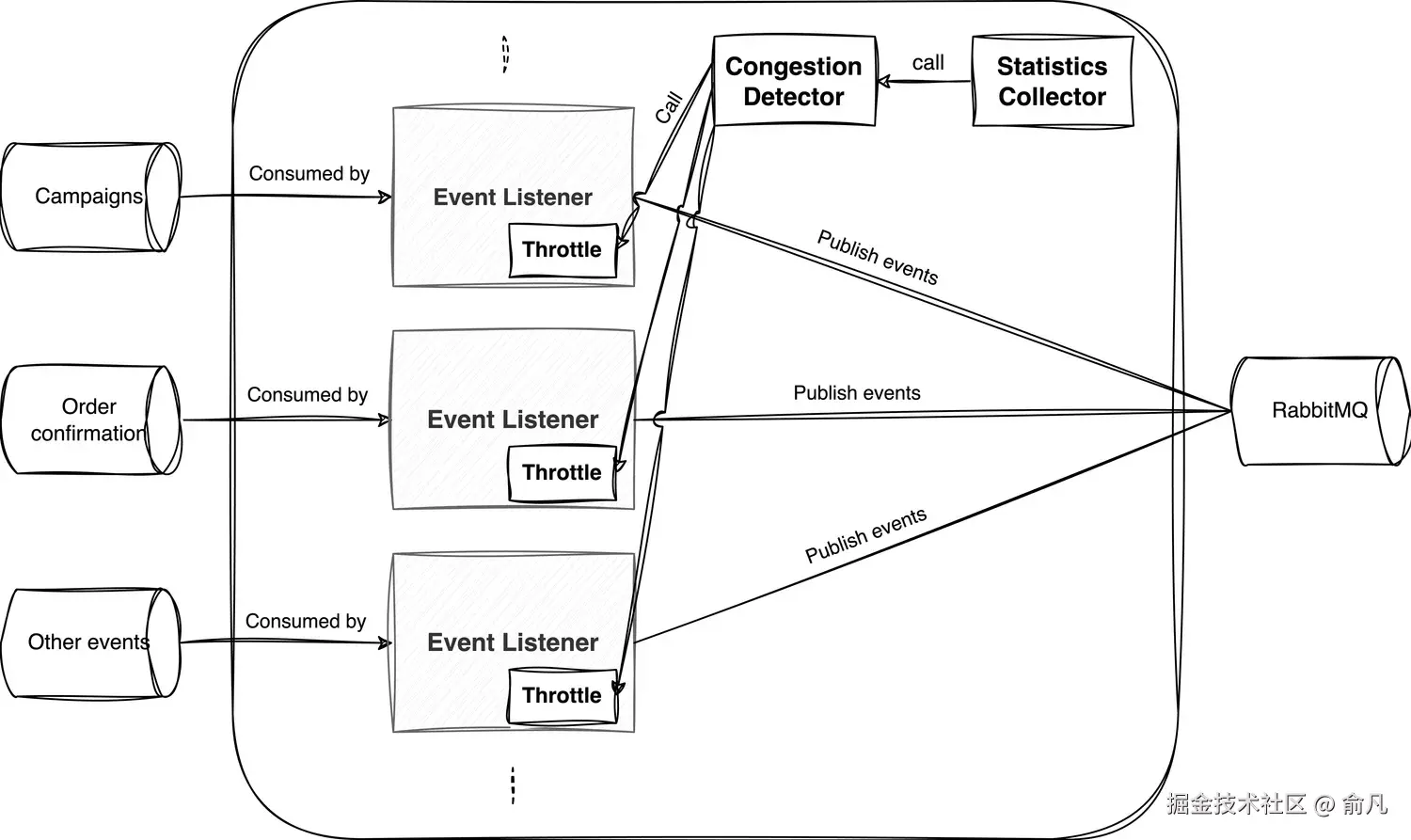
- 统计收集器(Statistics Collector)
收集有关延迟(例如 P50)的统计数据,并将其发布到 RabbitMQ,同时记录发布过程中出现的任何异常情况。
- **拥塞检测器(Congestion Detector)
根据从统计收集器接收到的数据以及与服务中配置的数值进行比较,判断系统是否存在拥塞现象(这取决于延迟是否可用或是否抛出了异常),其依据是从统计收集器接收到的数据。
- 限流器(Throttle)
每个消费者都有一个独立实例,是一个实现了 AIMD 算法的类,由消费者实例化,并向其提供该事件的优先级,该优先级将影响每秒可消费的事件数量。
设计是如何工作的?
- 当流消费者启动时,所有事件监听器都会以初始消费批次大小开始工作,还会实例化一个节流器实例。
- 统计收集器定时任务启动,收集关于延迟(P50)和异常的统计数据,然后调用拥塞检测器以提供结果。
- 拥塞检测器检查接收到的数据,并通过将接收到的数据与配置中设置的限制进行比较来决定是否存在拥塞。拥塞检测器将其决策通过观察者模式传递给与每个事件监听器相关的节流器。
- 节流器根据拥塞检测器的决策以及消费者启动时为其分配的优先级,基于 AIMD 算法决定新的批次大小。(注意:不同的节流器之间没有协调!)
- 由于目前 Nakadi 本身不支持修改批次大小,应用将相应的减慢/加快消费速度。
优先级如何影响事件消耗的加速/减慢
假设系统中有三个优先级,从 P1 到 P3,其中 P1 是最高优先级,P3 是最低优先级。流消费者在配置中应该已经为每个优先级设定了加速/减速的特定数值。
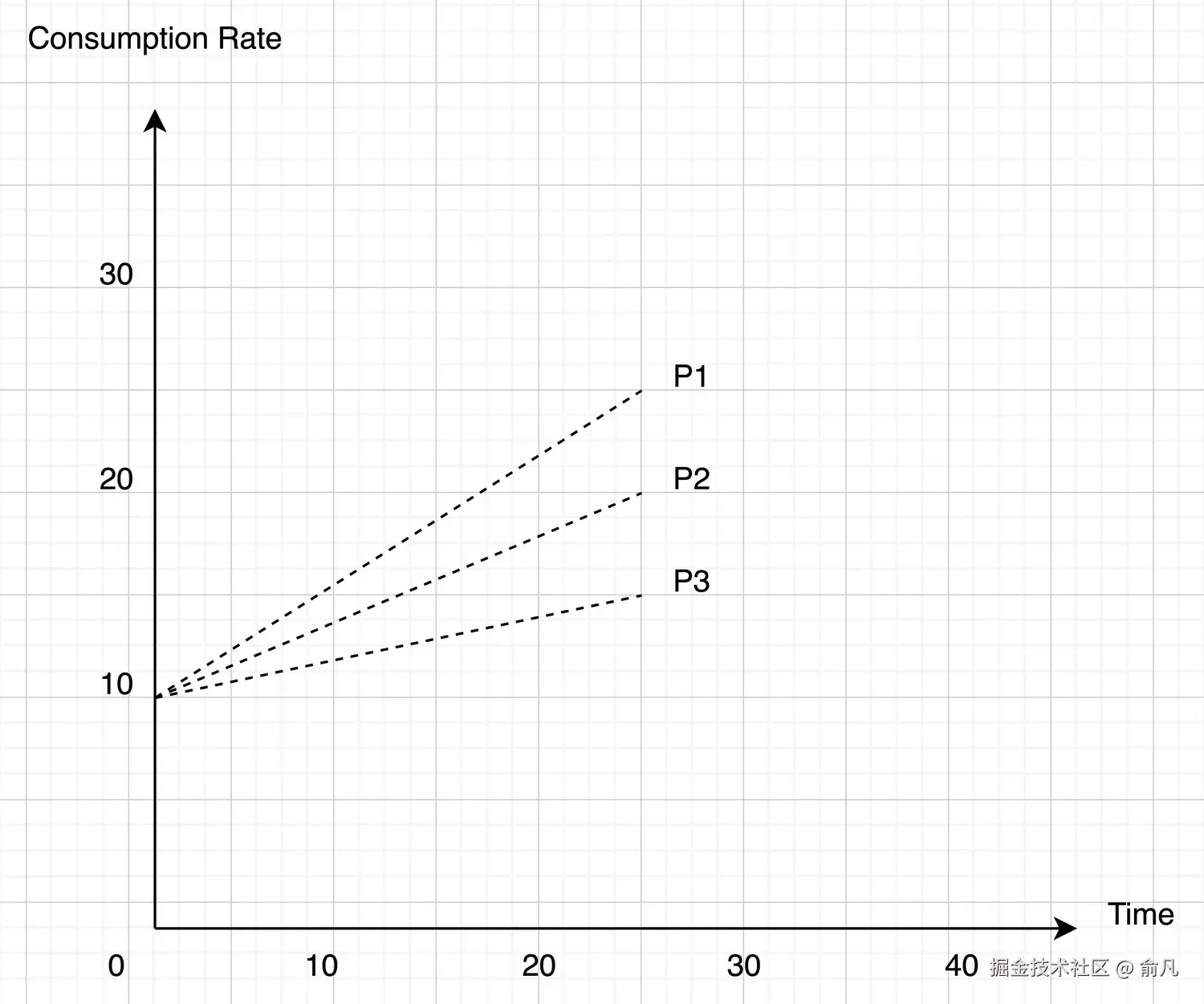
第一种情况:消费速度加快的信号(缓解了 RabbitMQ 集群的压力)
-
对于每个优先级,都会有一个明确的加快速度的数值,我们假设:
- P1:15
- P2:10
- P3:5
-
因此新的消耗率(批次大小)将会是:
- P1:之前的值 + 15
- P2:之前的值 + 10
- P3:之前的值 + 5
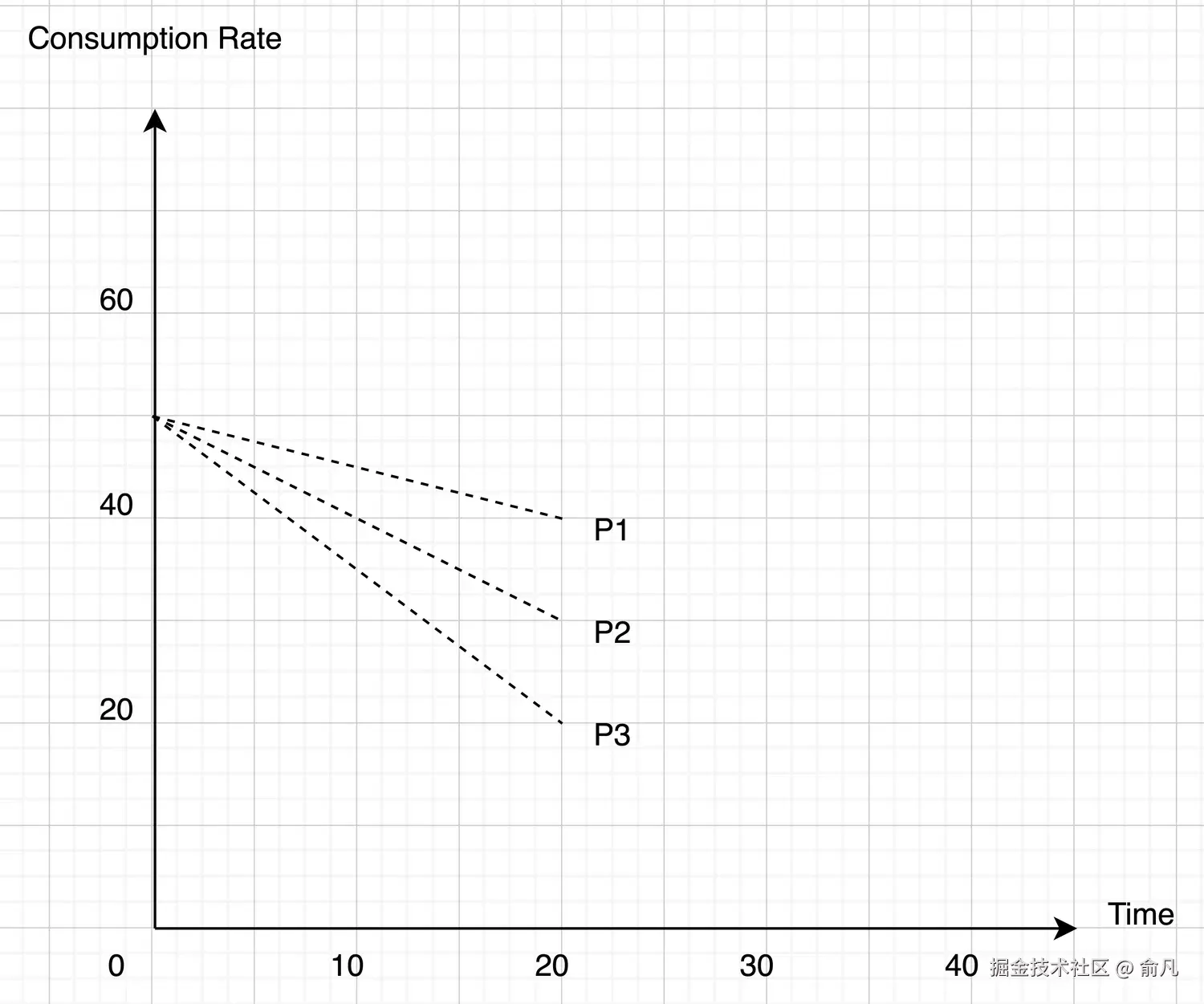
第二种情况:表明消费速度正在放缓(RabbitMQ 集群处于负载状态)。
- 同样地,根据优先级,还应设定不同的减速值,假设:
- P1:减少 20%
- P2:减少 40%
- P3:减少 60%
- 因此,新的消耗率将按以下百分比降低:
- P1:先前的值 * (20% (P1)) => 减少 20%
- P2:先前的值 * (40% (P2)) => 减少 40%
- P3:先前的值 * (60% (P3)) => 减少 60%
所以,经验法则是:
- 当 RabbitMQ 集群未处于负载状态时,提高所有消费者的消费速率,但会为优先级较高的事件类型提供更多的处理能力,其增加量要多于低优先级事件类型。
- 当 RabbitMQ 集群处于负载状态时,将所有消费者的消费速率降低一定比例,但优先级较高的消费者降低的比例要少于优先级较低的消费者。
结果
到目前为止,该解决方案已经在生产环境中运行了大约 6 个月,能够看到该平台有了许多改进,包括:
- 对 RabbitMQ 集群的压力较小,因为只有在有足够的处理能力来应对这些消息时,这些消息才会被推送到该集群。
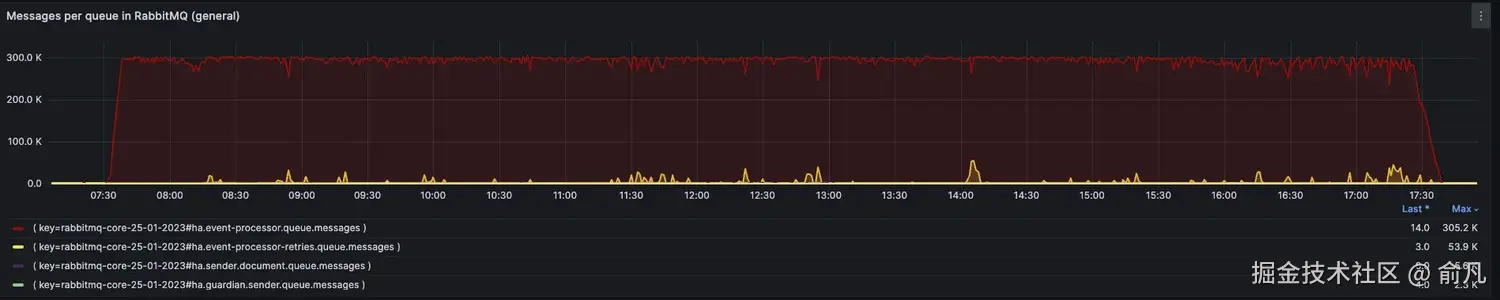
其中一个应用队列积压了大约 300,000 条消息,其他应用没有负载(从它们队列中消息数量很少可以明显看出这一点)。通过比较队列中的消息数量和 Nakadi 中积压的消息数量,也可以看出 RabbitMQ 集群的压力减轻了。
- 消息优先级,高优先级消息先发送,低优先级消息后发送。
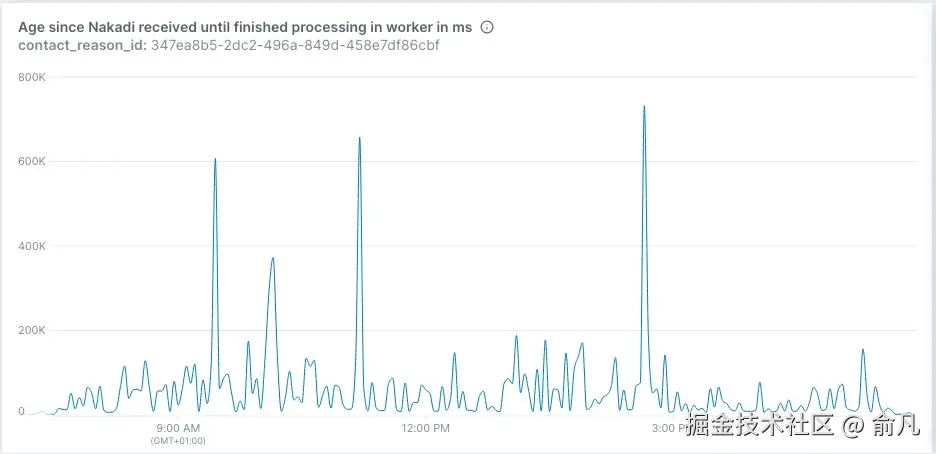
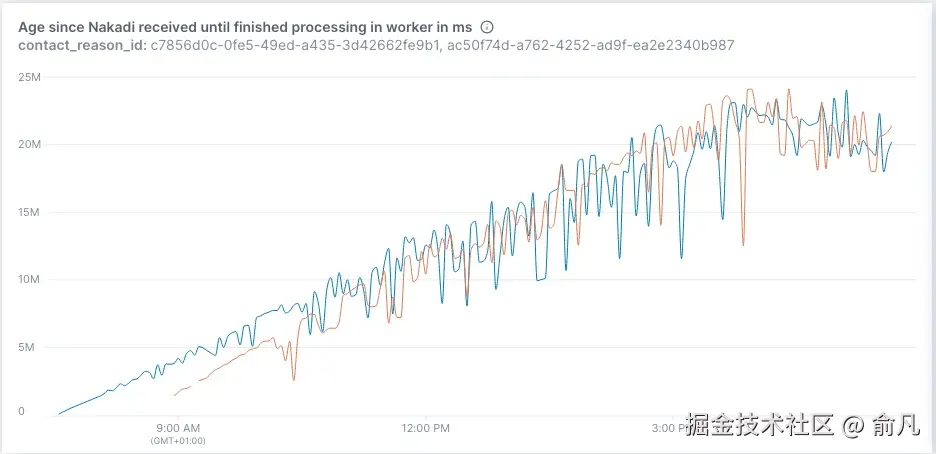
从上图可以看到订单确认的处理时间相对稳定。这很重要,因为这是一个高优先级用例。相比之下,商业消息的处理时间有所增加。这是可接受的,因为这是一个低优先级用例。
- 目前无法处理的事件仍在 Nakadi 中,因此可以稍后处理或在紧急情况下丢弃。
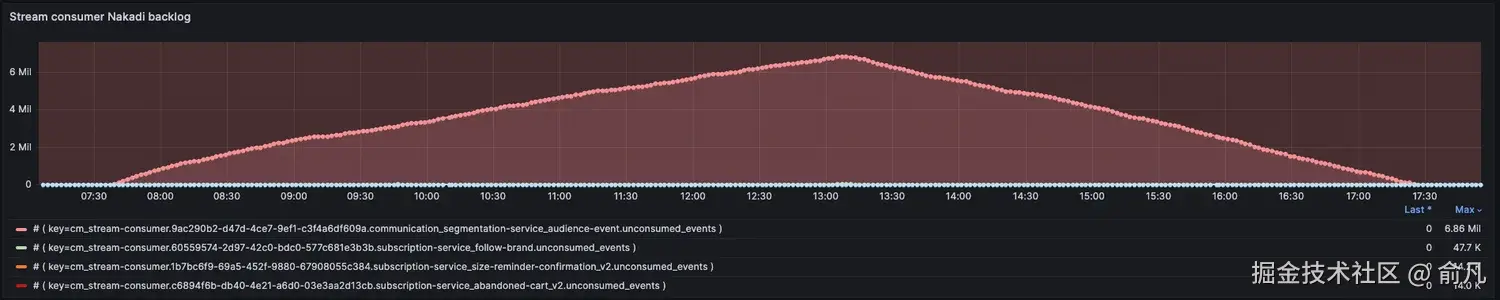
如图所示,积压消息正在被消耗,而不会给平台带来压力。在紧急情况下,可以丢弃低优先级消息。
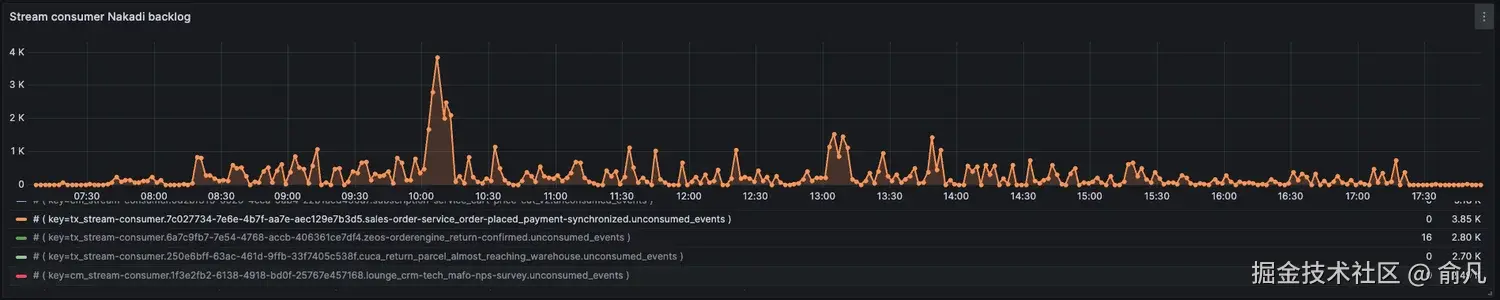
订单确认是 P1 优先级消息,会被优先处理(在同一时期,积压中增加的优先级消息较少)。
结论
在事件驱动型系统中,采用 TCP 拥塞控制算法来管理流量已被证明是有效的。总的来说,最好是从源头控制有多少流量被输入到系统中,而不是任由其大量涌入系统后再去处理。
就我们的情况而言,它帮助我们解决了消息的优先级排序问题。消息只有在符合其优先级且系统能够处理的情况下才能进入系统。它还帮助我们避免将 RabbitMQ 集群用作数百万条消息的存储库 ------ 在 RabbitMQ 中采用较小的队列规模符合最佳实践。紧急情况下,我们可以轻松丢弃消息,因为大多数消息仍会保留在源端。
参考资源
Stop Rate Limiting! Capacity Management Done Right | Strange Loop Conference | 2017
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。为了方便大家以后能第一时间看到文章,请朋友们关注公众号"DeepNoMind",并设个星标吧,如果能一键三连(转发、点赞、在看),则能给我带来更多的支持和动力,激励我持续写下去,和大家共同成长进步!