基于 Flask 和 MySQL 的期货数据分析系统
代码详见:https://github.com/xiaozhou-alt/Futures_Analysis.git
ps:项目中使用的数据集信息仅供学习使用,请勿商用盈利,违者必究!
文章目录
一、项目介绍
项目包括前端网站和后端数据库管理两个部分组成,使用特定的(时间为 2025-04-01到2025-04-29)包含HTML、PDF两种格式文件的数据集(7183个文件)(后续可推广到更多数据或是实时更新),经过格式转化、数据清洗和文本数据特征提取后,存入后端 MySQL数据库;建立前端网站,能够手动选择日期和期货类型,观察期货在过去一个月的涨跌情况和涨跌原因
功能特点
- 期货市场涨跌情况统计图表
- 每日市场观点分析
- PDF报告生成与查看
- 数据筛选功能
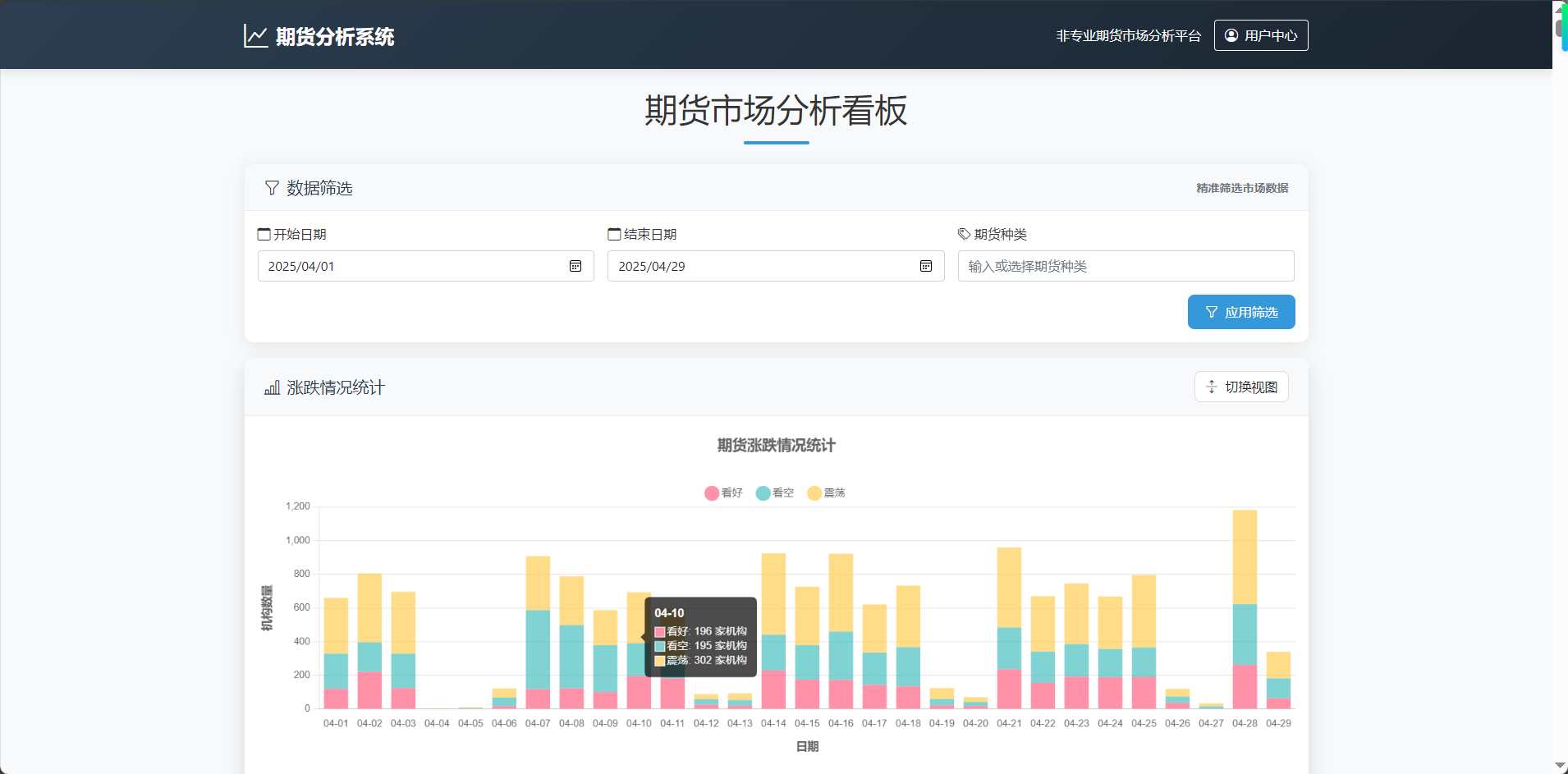
浅放一张前端展示图,吸引读者阅读兴趣,感兴趣的小伙伴请继续阅读 ↓
二、文件夹结构
1.数据集文件夹结构
c
Futures_Analysis/
├── data/ # 原始数据集目录
├── 20250401/ # 第一个日期文件夹
├── 宝城期货_323209.PDF # PDF文件示例
├── ...
├── 倍特期货_323458_0.html # HTML文件示例
├── ...
...
├── 20250429/ # 最后一个日期文件夹
├── ...
├── data-example/ # 数据集示例文件夹
├── HTML-example/ # HTML示例
├── 倍特期货_323458_0.html # 原html
├── 倍特期货_323458_0.pdf # html->pdf
├── 倍特期货_323458_0.txt # md->txt
└── 倍特期货_323458_0/ # mineru转化后的包含md文件的文件夹
├── 86a9bf..._content_list.json # 内容列表文件
├── 86a9bf..._origin.pdf # 原始pdf
├── full.md # 转换后的md文件
├── images/ # pdf文件中包含的图片
└── layout.json # 布局配置文件
└── PDF-example/ # PDF示例
├── 宝城期货_323209.PDF # 原PDF
├── 宝城期货_323209.txt # md->txt
└── 宝城期货_323209/ # mineru转化后的包含md文件的文件夹
├── 1ff74f..._content_list.json
├── 1ff74f..._origin.pdf
├── full.md
├── images/
└── layout.json
├── output_pdf/ # pdf输出目录
├── ...
├── output_final/ # txt输出目录(最终mysql入库的文件格式)
├── ...
└── img/ # 项目相关图片2.代码文件夹结构
c
Futures_Analysis/
├── src/
├── app.py # 主应用入口文件,包含Flask/Django等web应用配置
├── deepseek.ipynb # 使用 DeepSeek 分析我的md文件得到txt文件
├── html-pdf.ipynb # HTML->PDF
├── mysql_pdf.py # MySQL数据库存储PDF
├── mysql_txt.py # MySQL数据库TXT
├── pdf-md-txt.ipynb # PDF->Markdown->TXT
└── pdf-md.ipynb # PDF->Markdown
├── templates/
└── index.html # 前端代码
├── demo.mp4 # 演示视频
├── company.txt # 公司映射文件
├── requirements.txt
└── README.md三、数据集介绍
原始数据下载:economy_origin (kaggle.com)
HTML -> PDF 后的数据(PDF 格式)下载:economy_pdf (kaggle.com)
PDF -> TXT 后的数据(TXT 格式)下载:economy_txt (kaggle.com)
重要说明:项目中使用的数据集信息仅供学习使用 ,请勿商用盈利 ,违者必究!
数据集包括多个期货公司 对于当日期货(日期为文件夹名称)的观点 和具体看法 ,总体格式包含 HTML 和 PDF 两种。
四、项目实现
1.后端代码
1)格式转化(HTML->PDF)
使用 wkhtmltopdf ,wkhtmltopdf 是一个开源的命令行工具,用于将 HTML 网页转换为 PDF 文件或图像(如 JPG、PNG 等)。它在后台启动一个无头(Headless)的 WebKit 渲染引擎,加载 HTML内容(包括 CSS、JavaScript 和图片等资源)完整渲染页面布局,再将渲染结果转换为 PDF 格式
- 流程:解析 HTML → 加载资源 → 执行 JavaScript → 渲染页面 → 输出 PDF。
- 优势:保留网页原始样式(如响应式布局、动态效果),实现 "所见即所得"。
遍历20250401到20250429的日期,为每个日期创建对应的输入输出文件夹,递归扫描输入文件夹中的所有 HTML 文件,使用 pdfkit 将它们转换为 PDF 并保持原始目录结构,同时显示详细的转换进度和错误信息。
python
import pdfkit
import os
from pathlib import Path
from tqdm import tqdm
# 配置wkhtmltopdf路径
path_wkhtmltopdf = r'C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf=path_wkhtmltopdf)
for i in range(20250401,20250430):
input_folder = f'../data/{i}/'
output_folder = f'../output/{i}/'
print(f"正在转换{i}。。。")
# 1. 递归收集所有HTML文件路径
html_files = []
for root, _, files in os.walk(input_folder):
...
# 2. 初始化tqdm进度条
with tqdm(total=len(html_files), desc="转换PDF", unit="file",
...
print(f"\n转换完成!PDF保存在: {os.path.abspath(output_folder)}")输出示例:
正在转换20250411。。。
转换PDF: 100%|██████████| 139/139 03:56\<00:00
转换完成!PDF保存在:Futures_Analysis\output\20250411
2)格式转化(PDF->Markdown)
MinerU 介绍:开源神器MinerU:一键提取PDF、网页、电子书的宝藏工具
MinerU 是由opendatalab开发的一站式开源数据提取工具,它包括两个主要组件:Magic-PDF和Magic-Doc。 Magic-PDF专注于PDF文档的提取,而Magic-Doc则能够处理网页和电子书。
MinerU 采用模块化设计,整合多个先进模型协同工作:
- 1.布局检测(Layout Detection)
- 模型:微调版 LayoutLMv3 或 DocLayout-YOLO
- 功能:精准定位标题、文本、表格、公式、图片等元素的边界框(Bounding Box)
- 创新点:通过多样化文档训练集提升复杂版式(如多论文、教材)的鲁棒性
- 2.公式处理
- 检测:基于 YOLOv8 的公式检测模型,区分行内公式与块公式
- 识别:自研 UniMERNet 模型将公式图像转为 LaTeX代码,支持手写和噪声公式
- 3.表格识别
- 双引擎并行:
- StructEqTable:端到端输出表格的 LaTeX/HTML/MD 结构
- TableMaster + PaddleOCR:联合重建表格内容与排版
- 4.OCR 引擎
- PaddleOCR:处理扫描版 PDF 的文本识别,支持 84 种语言
- 优化策略:仅对文本区域 OCR,避开公式/表格区域以提升效率
想了解更多的读者请自行前往 MinerU 官网网址 进行查看学习
将 PDF 文件转换为 Markdown 格式的工具,使用 MinerU 命令行工具进行转换,支持 CUDA 加速和并行处理。主要功能包括:递归扫描指定目录下的所有 PDF 文件,保持原始目录结构输出 Markdown 文件,自动清理非目标文件,并使用进度条显示转换进度,支持命令行参数指定输入输出目录,并对默认路径进行设置
python
import argparse
import os
import subprocess
from pathlib import Path
import shutil
from tqdm import tqdm
def convert_pdf_to_md(input_pdf, output_dir):
try:
cmd = [
"mineru",
"-p", str(input_pdf),
"-o", output_dir,
"--method", "auto",
"--device", "cuda",
"--ocr-mode", "fast", # 保留有效加速参数
"--dpi", "150", # 降低分辨率提速
"--parallel", "4" # 页面级并行
]
subprocess.run(cmd, check=True)
return True
except Exception as e:
print(f"❌ 转换失败: {input_pdf} - {str(e)}")
return False
def process_directory(input_dir, output_base_dir):
pdf_files = []
for root, _, files in os.walk(input_dir):
...
# ====================== 参数设置部分 ======================
def main(input_dir=None, output_dir=None):
...每一个 PDF 文件对应一个以 PDF 文件名命名的文件夹,文件夹内容如下:
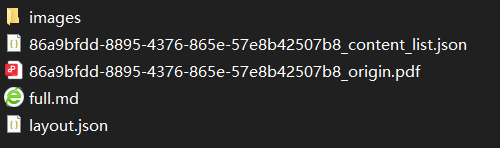
其中: images 保存从 PDF 文件中识别到的图片和表格;..._content_list.json 为 PDF 的内容列表;..._origin.pdf 为 PDF 源文件;full.md 为转化后的 Markdown 文件;layout.json 为 PDF 的布局
3)数据提取
使用 DeepSeek API (也可以使用其他大语言模型)处理期货分析报告,遍历指定日期范围内的期货报告文件夹,读取每个报告中的 Markdown 内容,通过 API 提取期货品种名称、涨跌情况和驱动因素(格式为'期货品种-涨跌情况-驱动因素'),将分析结果保存为 TXT 文件,并记录未包含期货信息的报告路径到 Excel 文件中
使用的 prompt 如下:
"content": f"请总结以下内容中出现的期货名称和对应的涨跌情况(震荡/看好/看空),格式为:期货品种-跌涨情况-核心驱动因素(如果有,没有就表示为 null),注意你只需要生成期货种类-跌涨情况-核心驱动因素(比如:玉米-震荡-购入者增加),如果我的文字中没有任何期货信息,那就不返回任何东西,以下为内容:{content}"}
python
import os
import requests
import json
import pandas as pd
from tqdm import tqdm
# 定义 API 相关信息
url = "your_api"
headers = {"Content-Type": "application/json"}
# 定义要处理的日期范围
date_range = [f"202504{str(i).zfill(2)}" for i in range(1, 30)]
output_md_folder = os.path.join(os.getcwd(), "../output_md")
for date_folder in date_range:
...
# 准备请求数据
data = {"content": f"请总结以下内容中出现的期货名称和对应的涨跌情况(震荡/看好/看空),格式为:期货品种-跌涨情况-核心驱动因素(如果有,没有就表示为 null),注意你只需要生成期货种类-跌涨情况-核心驱动因素(比如:玉米-震荡-购入者增加),如果我的文字中没有任何期货信息,那就不返回任何东西,以下为内容:{content}"}
try:
# 调用 API
...
if "-" in full_response:
# 生成 TXT 文件名
...
# 将无信息记录存入对应日期的 XLSX 文件
if no_info_records:
...部分输出展示:
正在处理日期文件夹: 20250422
处理 20250422 内部文件进度: 100%|██████████| 185/185 11:57\<00:00, 3.88s/it
20250422 无期货信息的文件夹路径已记录到 /output_md\20250422\20250422_no_futures_info.xlsx
4)数据清洗
递归扫描指定目录下的 TXT 文件,使用 正则表达式 提取 "期货名称-涨跌情况-涨跌原因" 格式的三元组信息,并统计每种涨跌情况的出现频率,会清理数据中的数字和格式标记,最终输出不同涨跌情况的统计结果
python
# 定义源文件夹路径
source_folder = os.path.join(os.getcwd(), "../output_final")
# 定义正则表达式模式来匹配三元组信息
pattern = re.compile(r'(.+?)-(.+?)-(.+)')
# 用于存储所有三元组的第二个元素及其出现次数
second_elements_count = {}
if os.path.exists(source_folder):
...
# 输出所有不同的第二个元素及其出现次数
print("所有三元组的第二个元素出现次数统计如下:")
...输出示例:
所有三元组的第二个元素出现次数统计如下:
%): 17
%、: 1
%): 5
-正套持有: 1
...
5)数据入库
之前没有使用过 mysql 数据库的读者,可以阅读: 2024 年 MySQL 8.0 安装 配置 教程 最简易(保姆级)进行安装
本次项目中使用 Navicat Premium 17 结合 MySQL 进行数据库的管理和查询
关于 Navicat Premium 17 的下载和安装可参考:【2025】Navicat 17最新保姆级安装教程(附安装包+永久使用方法)
创建数据库表结构(包含期货类型、涨跌趋势、原因、公司名称、日期等字段),递归扫描指定目录下的 TXT 文件,使用正则表达式提取"期货名称-涨跌情况-涨跌原因" 格式的三元组信息,并将这些数据连同公司名称、日期和源文件名一起存入 MySQL 数据库,同时避免重复插入相同数据
python
# 数据库连接配置
db_config = {
'host': 'localhost',
'user': 'xxx',
'password': 'your_password',
'database': 'xxx'
}
# 创建表结构
def create_table():
try:
connection = pymysql.connect(**db_config)
with connection.cursor() as cursor:
sql = """
CREATE TABLE IF NOT EXISTS data (
id INT AUTO_INCREMENT PRIMARY KEY,
type VARCHAR(255) NOT NULL,
trend VARCHAR(255) NOT NULL,
reason TEXT,
company VARCHAR(50) NOT NULL,
date DATE NOT NULL,
source VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)"""
cursor.execute(sql)
...
# 定义正则表达式匹配三元组
pattern = re.compile(r'(.+?)-(.+?)-(.+)')
# 数据库插入逻辑
if os.path.exists(source_folder):
print(f"找到源文件夹: {source_folder}")
file_count = 0
record_count = 0
for root, dirs, files in os.walk(source_folder):
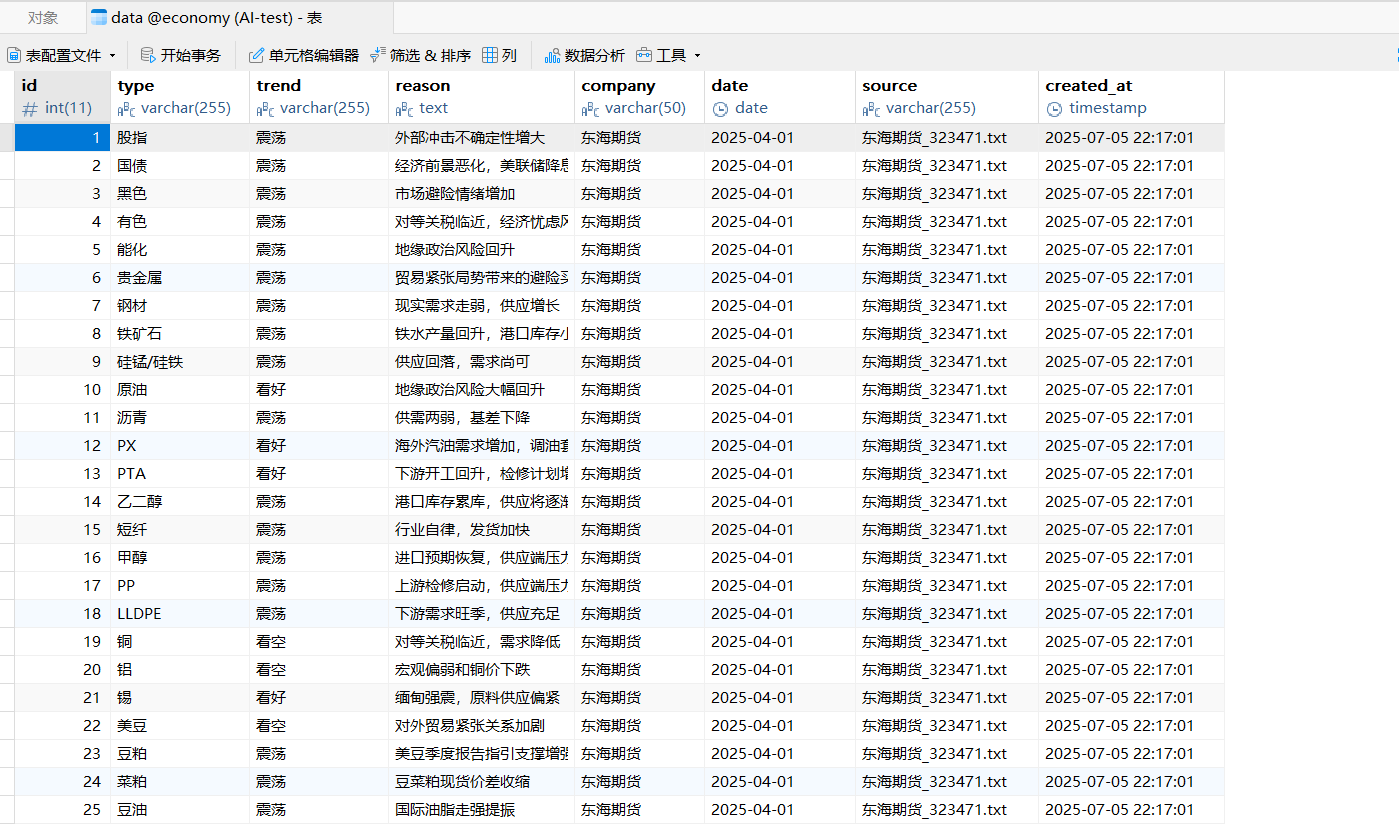
...输入完成后的表格在 Navicat Premium 17 软件中展示:
为了实现网页端能够直接下载我的数据库中保存的 PDF 源文件(对于需要明确知晓期货详细情况和市场分析的用户),我们还需要将 PDF 源文件入库。创建的步骤与处理期货数据基本类似,需要注意的是使用的 Cpyher 语句如下:
python
sql = """
CREATE TABLE pdf (
id INT AUTO_INCREMENT PRIMARY KEY,
file_name VARCHAR(255) NOT NULL,
file_content LONGBLOB NOT NULL,
company_name VARCHAR(100) NOT NULL,
file_date DATE NOT NULL,
file_size BIGINT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)"""其中 file_content 这个列属性为 LONGBLOB 可以将 PDF 文件保存为二进制文件便于之后的下载查看
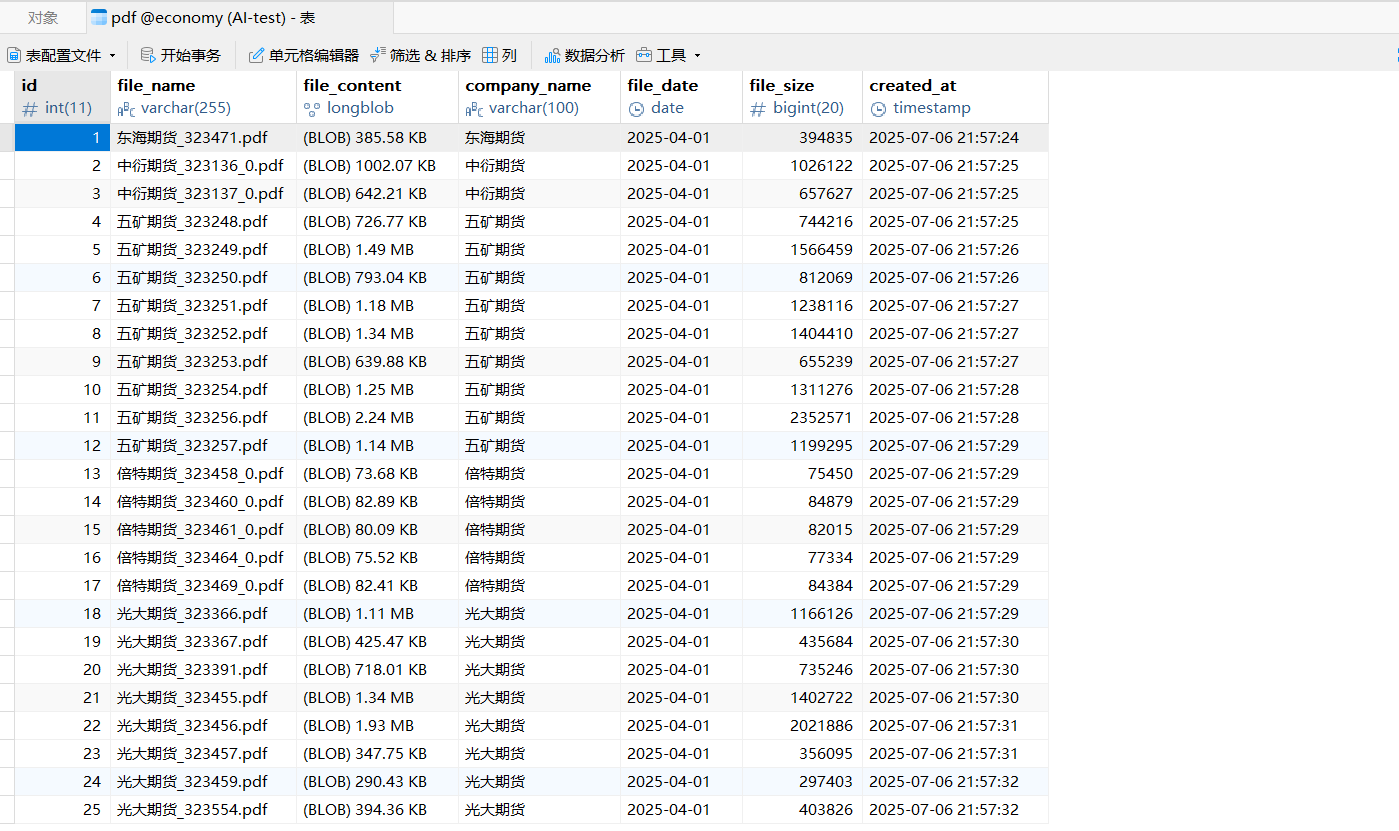
输入完成后在 Navicat Premium 17 软件中展示:
2.前端代码
1)主应用
基于 Flask 构建期货分析数据可视化平台,通过 MySQL 数据库存储和查询数据,提供多种API接口用于获取期货种类、筛选数据、生成图表数据以及下载 PDF 文件,支持按日期范围和期货类型筛选数据,自动统计各期货的观点分布并计算主流趋势,同时能够将原始分析报告的 PDF 文件提供给用户下载
python
app = Flask(__name__, template_folder=os.path.join(os.path.dirname(os.path.abspath(__file__)), '../templates'))
# 数据库配置
db_config = {
'host': 'localhost',
'user': 'xxx',
'password': 'your_password',
'database': 'xxx',
'charset': 'utf8mb4',
'cursorclass': pymysql.cursors.DictCursor
}
def get_db_connection():
return pymysql.connect(**db_config)
@app.route('/')
def index():
"""主页面"""
return render_template('index.html')
@app.route('/api/types')
def get_types():
"""获取所有期货种类"""
...
@app.route('/api/data', methods=['GET'])
def get_data():
"""获取筛选后的数据"""
...
@app.route('/api/chart_data', methods=['GET'])
def get_chart_data():
"""获取堆叠柱状图数据"""
...
@app.route('/api/download_pdf', methods=['GET'])
def download_pdf():
"""下载PDF文件"""
...2)网页界面
期货数据分析系统的前端页面,采用响应式设计,包含导航栏、数据筛选区域、涨跌统计图表、统计卡片和每日市场观点展示区。页面使用了 Bootstrap 框架和 Chart.js 图表库,定义了丰富的CSS样式来展示不同趋势(看好、看空、震荡)的视觉效果,并实现了数据加载动画、自定义下拉列表等交互功能
python
<!DOCTYPE html>
<html lang="zh-CN">
<!-- css,全局样式定义,响应设计 -->
<head>
...
</head>
<body>
<!-- 顶部导航栏 -->
<nav class="navbar navbar-expand-lg">
...
</nav>
<!-- 期货市场分析 -->
<div class="container py-4">
...
</div>
<!-- 页脚 -->
<footer class="footer">
...
</footer>
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.1.3/dist/js/bootstrap.bundle.min.js"></script>
<script>
// 全局变量
...
// 加载数据函数
function loadData() {
...}
// 渲染统计卡片
function renderStats(stats) {
...}
// 渲染堆叠柱状图
function renderChart(chartData) {
...}
// 更新图表视图(堆叠/分组)
function updateChartView() {
...}
// 渲染每日数据
function renderDailyData(data) {
...}
// 下载PDF文件
function downloadPDF(pdfFilename) {
...}
</script>
</body>
</html>前端效果展示:
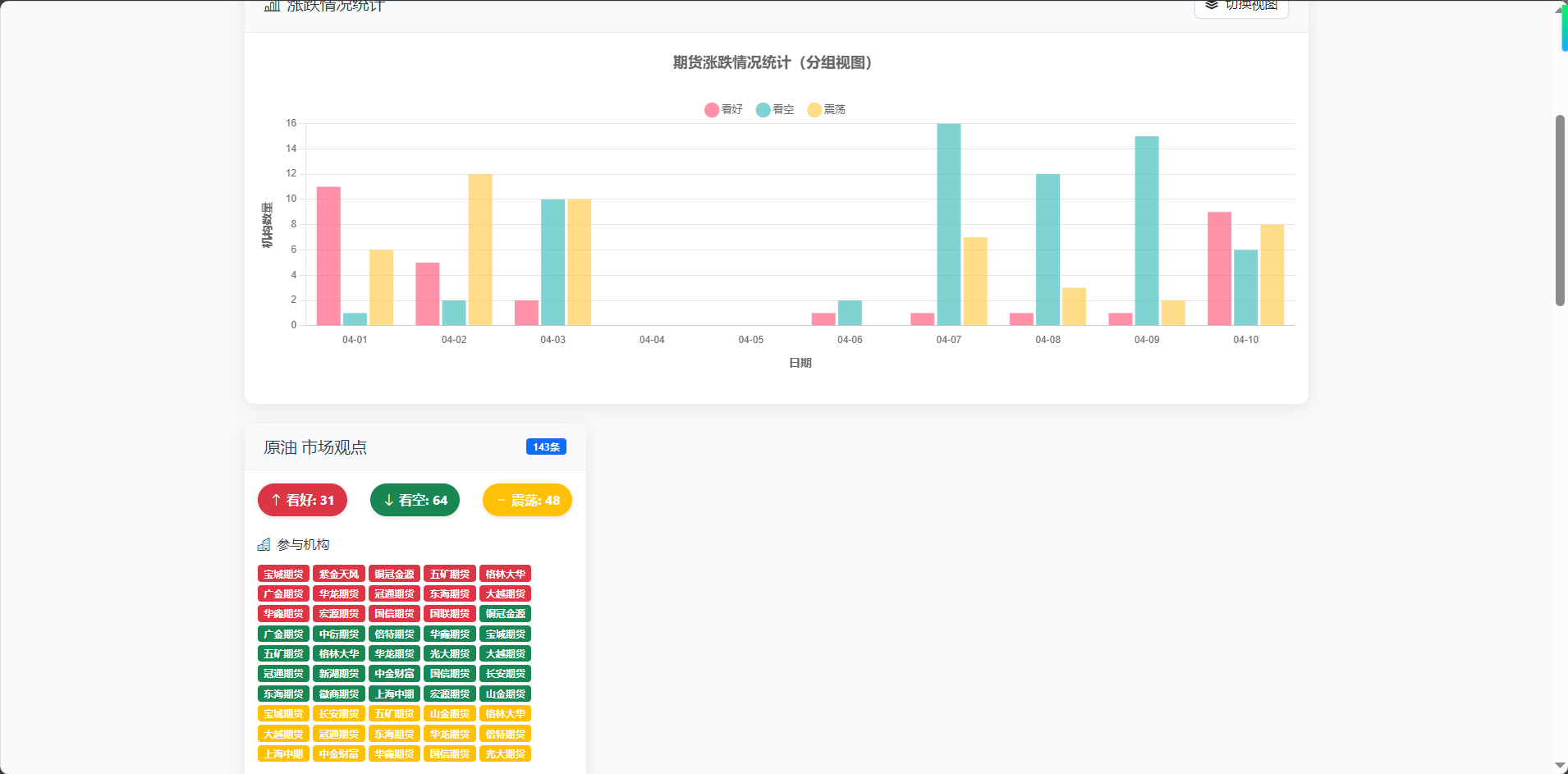
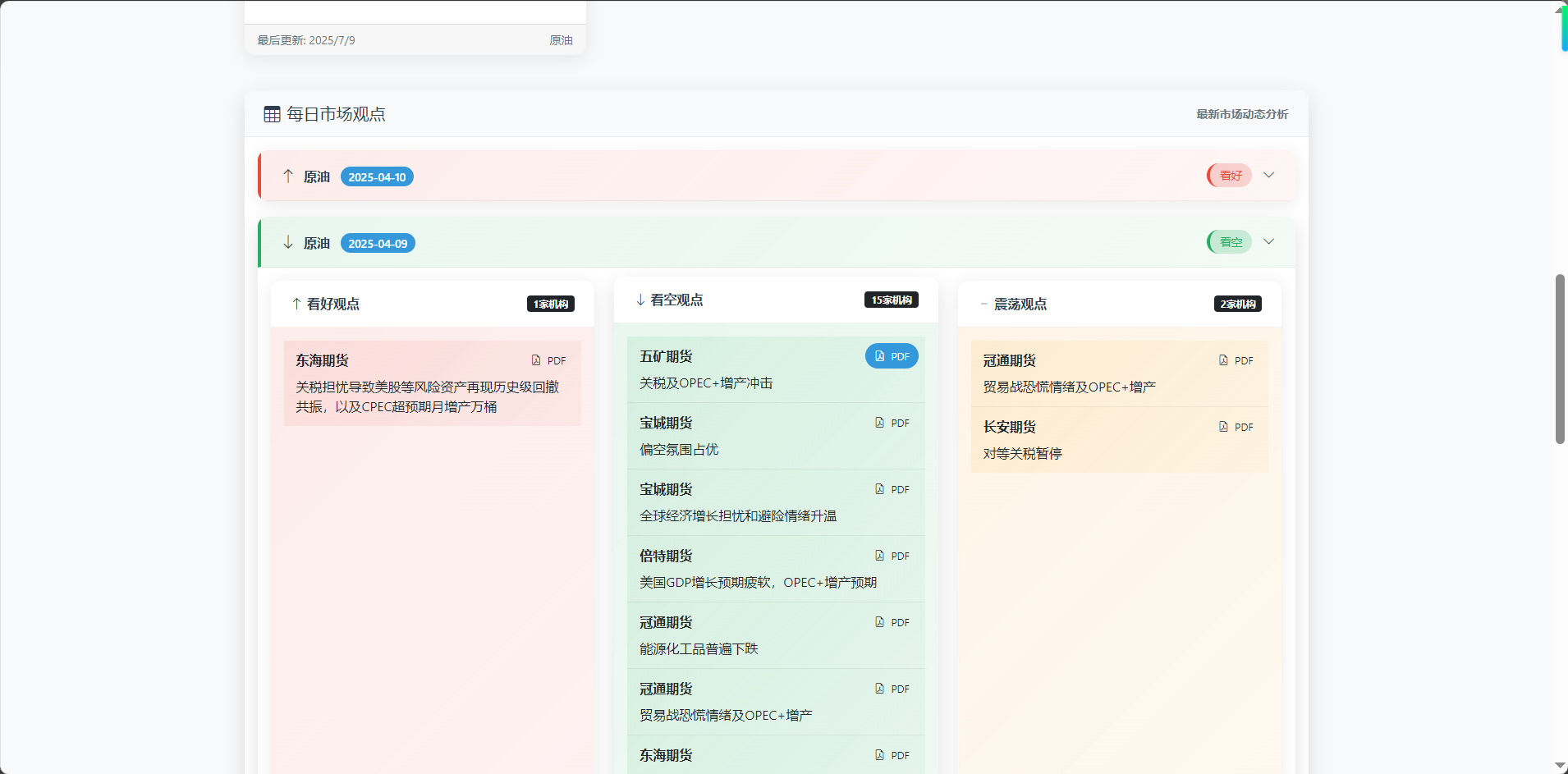
更多演示效果请看下方演示视频 ↓
五、结果展示
基于 Flask 和 MySQL 的期货数据分析系统
如果你喜欢我的文章,不妨给小周一个免费的点赞和关注吧!