最近发现公司的订单查询越来越慢,明明给
order_date加了索引,可查询速度还是像蜗牛爬。盯着屏幕上的 SQL 语句和索引列表,百思不得其解------"索引明明存在,为什么数据库就是不用?" 一线的同志们,你们遇到过没?那有可能索引还真的是加了个寂寞!就像那首歌唱的:"哦!寂寞的夜里,一个人难受,伤心眼泪往下流!"那么我们一起分析分析呗,别让伤心继续下去!
一、索引失效的经典名场面(附代码验证)
场景 1:最左匹配原则
错误操作: 给 t_user 表建了联合索引 idx_name_age,但查询时跳过了 nick_name。
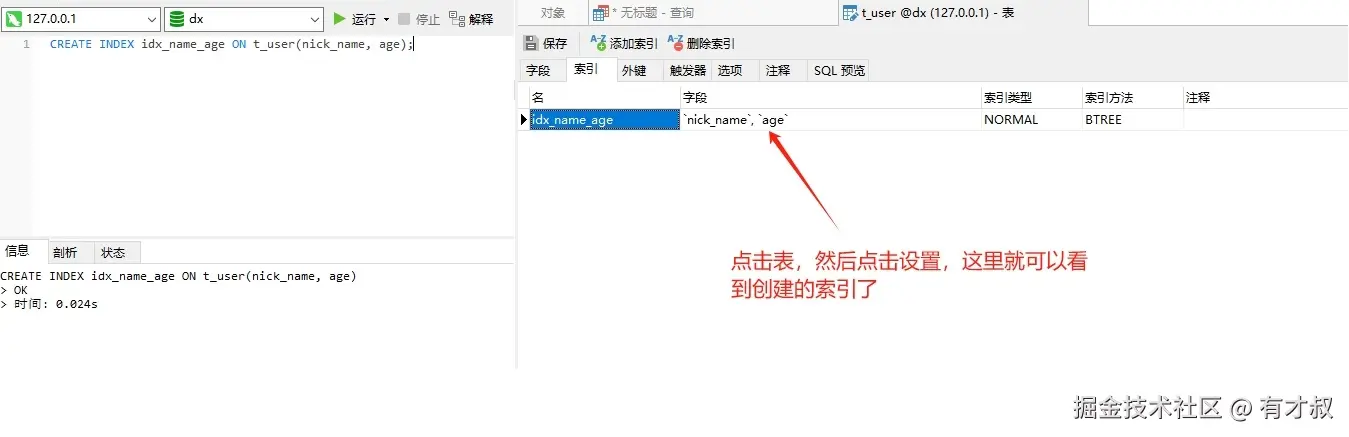
sql
-- 创建联合索引
CREATE INDEX idx_name_age ON t_user(nick_name, age);
-- 致命错误:跳过 name 直接查 age(索引失效!)
SELECT * FROM t_user WHERE age = 30; -- 全表扫描执行计划真相(MySQL 8.0):
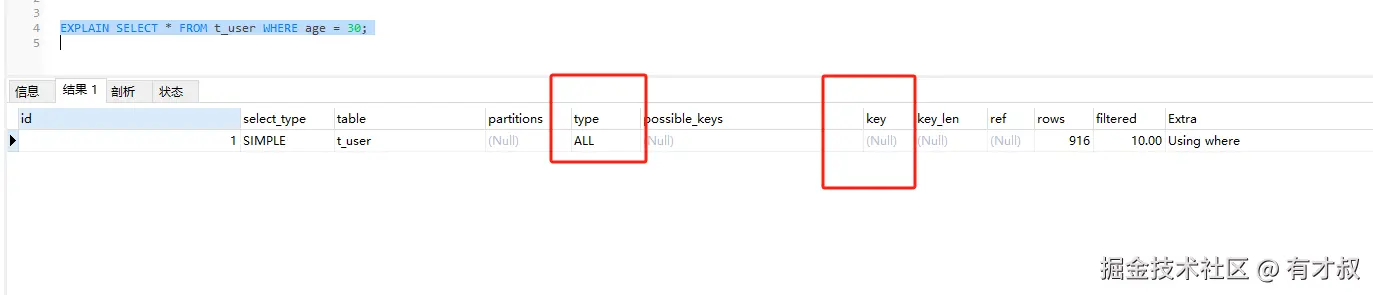
原理:联合索引就像电话簿的"姓+名",只查"名"时索引无法定位数据位置。
场景 2:隐式类型转换
错误操作: order_id 是字符串类型(VARCHAR),却用数字查询。
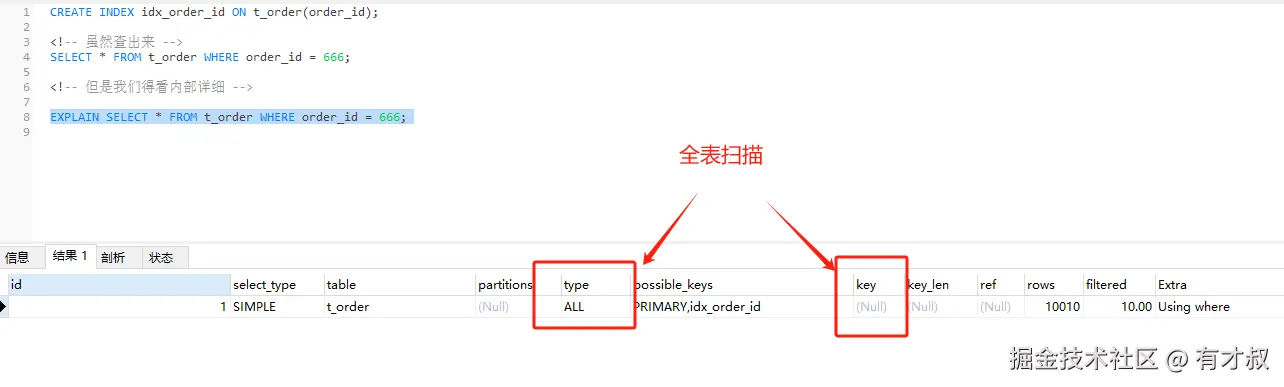
sql
-- order_id 是 VARCHAR(20)
CREATE INDEX idx_order_id ON t_order(order_id);
<!-- 致命错误:虽然查出来,(字符串当数字用(索引失效!) -->
SELECT * FROM t_order WHERE order_id = 666;执行计划真相:
sql
<!-- 但是我们得看内部详细 -->
EXPLAIN SELECT * FROM t_order WHERE order_id = 666;
-- 输出:type=ALL, key=NULL (全表扫描)原理 :数据库偷偷把
order_id转成数字再比较,相当于对索引列做了函数计算。
场景 3:索引列上做计算
错误操作: 在索引列 price 上做数学计算。

sql
CREATE INDEX idx_price ON t_user(balance);
-- 致命错误:索引列参与计算(索引失效!)
SELECT * FROM t_user WHERE balance * 0.9 > 100;
EXPLAIN SELECT * FROM t_user WHERE balance * 0.9 > 100;正确写法:
sql
SELECT * FROM t_user WHERE balance > 100 / 0.9; -- 计算移到右侧
EXPLAIN SELECT * FROM t_user WHERE balance > 100 / 0.9;
二、索引加了为何不用?
数据库选择索引不是看"有没有",而是看"值不值":
- 成本太高: 当需要回表查询大量数据时,直接全表扫描可能更快
- 数据倾斜: 如对"性别"字段建索引,因值重复度高(男/女),索引效率低下
- 统计信息过时: 数据库误判数据分布,以为全表扫描更优
三、这样加索引才有效!
策略 1:联合索引的黄金排列法则
口诀:高频查询字段在前,高区分度字段优先
sql
-- 正确姿势:name 区分度高且常被查询
CREATE INDEX idx_name_age_state ON t_user(nick_name, age, state);策略 2:拒绝隐式转换,类型严格一致
sql
-- 正确姿势:保持类型一致
SELECT * FROM t_order WHERE order_id = '666'; -- 用字符串查字符串
策略 3:利用覆盖索引减少回表
sql
-- 只查索引包含的列,避免回表
SELECT nick_name, age FROM t_user WHERE age > 25; -- 若索引是 (age,nick_name) 则高效四、实战检测:你的索引真的生效了吗?
用 EXPLAIN 看关键指标:
sql
EXPLAIN SELECT name FROM users WHERE age = 30 AND city='Beijing';有效索引信号:
type= ref/rangekey= 你的索引名Extra= Using index(覆盖索引)
危险信号:
type= ALLkey= NULLExtra= Using filesort/Using temporary
五、索引使用的三大铁律
- 最左匹配是底线: 联合索引查询必须从左连续使用
- 类型一致保平安: 避免隐式转换让索引失效
- 计算不在索引列: 将计算、函数移到查询条件右侧
🚨 提醒:写到最后,提醒各位喜欢使用索引的同志们,定期用
EXPLAIN检查执行计划,看看你的索引是否白加了。不要到最后时伤心的眼泪才往下流,到时盆儿都接不住了!!!