目录
[编辑 导入计算准确率的库](#编辑 导入计算准确率的库)
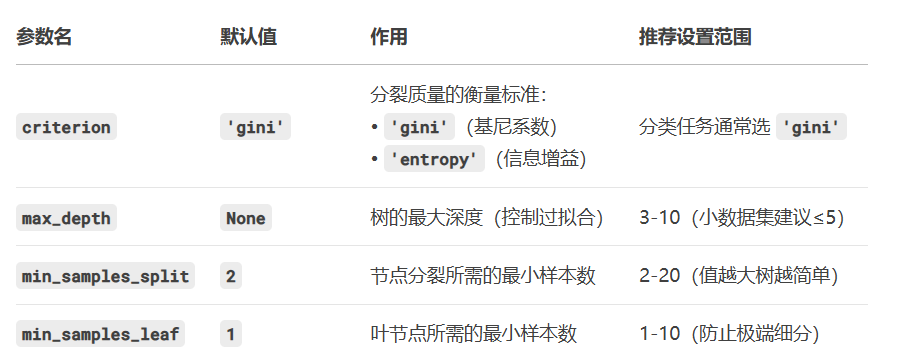
基本步骤
导入数据集
赋值x,y
划分数据集
导入模型
实例化模型
训练模型
使用模型进行预测
求准确率
决策树(分类)
导入鸢尾花数据集
赋值给x与y
python
#导入鸢尾花数据集,并赋值x,y
from sklearn.datasets import load_iris
data = load_iris()
python
x = data['data']
x
python
y = data['target']
y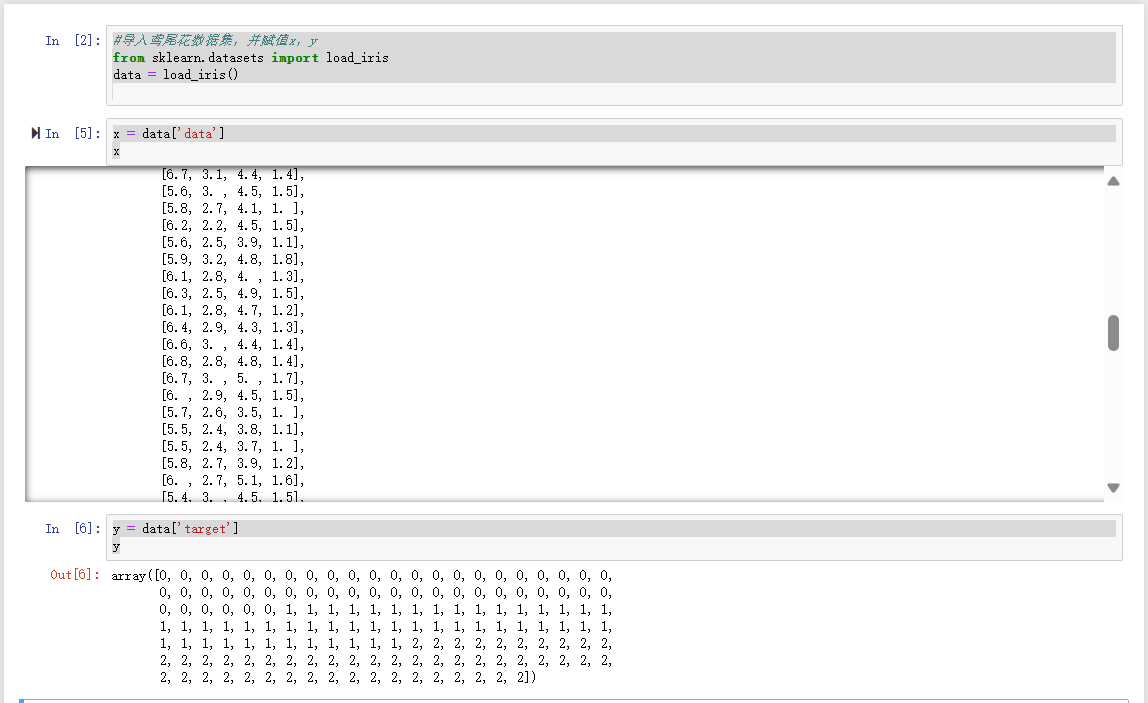
python
#先研究二分类问题,选择前一百的数据
x = x[:100]
y = y[:100]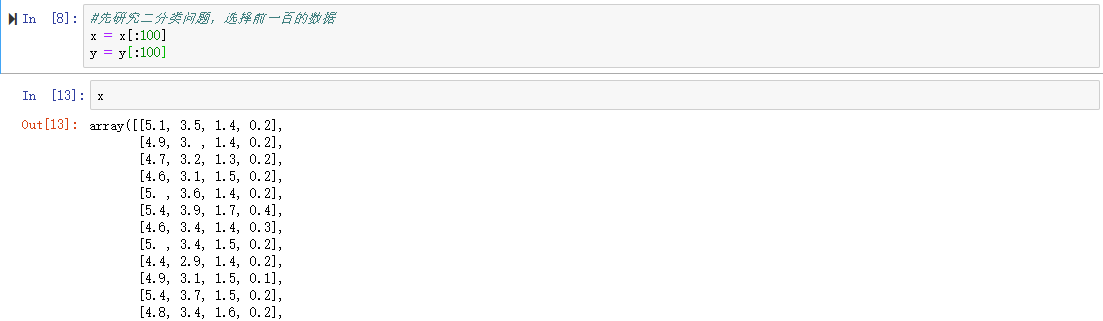

划分数据集

导入决策树模型
实例化
训练
python
#导入我们的决策树分类模型
from sklearn.tree import DecisionTreeClassifier
#实例化模型
#设置最长深度为3,太深容易过拟合
model = DecisionTreeClassifier(max_depth = 3)
#训练模型
model.fit(X_train,y_train)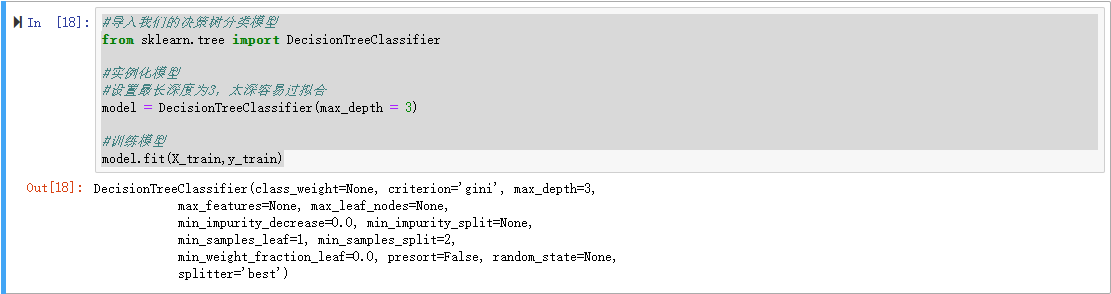
对训练集和测试集进行预测
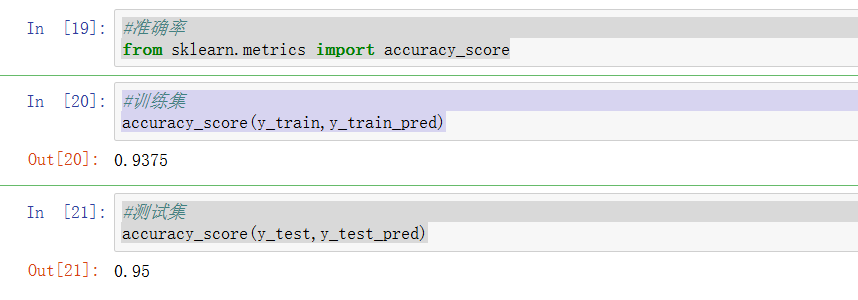
 导入计算准确率的库
导入计算准确率的库
计算准确率
python
#准确率的库
from sklearn.metrics import accuracy_score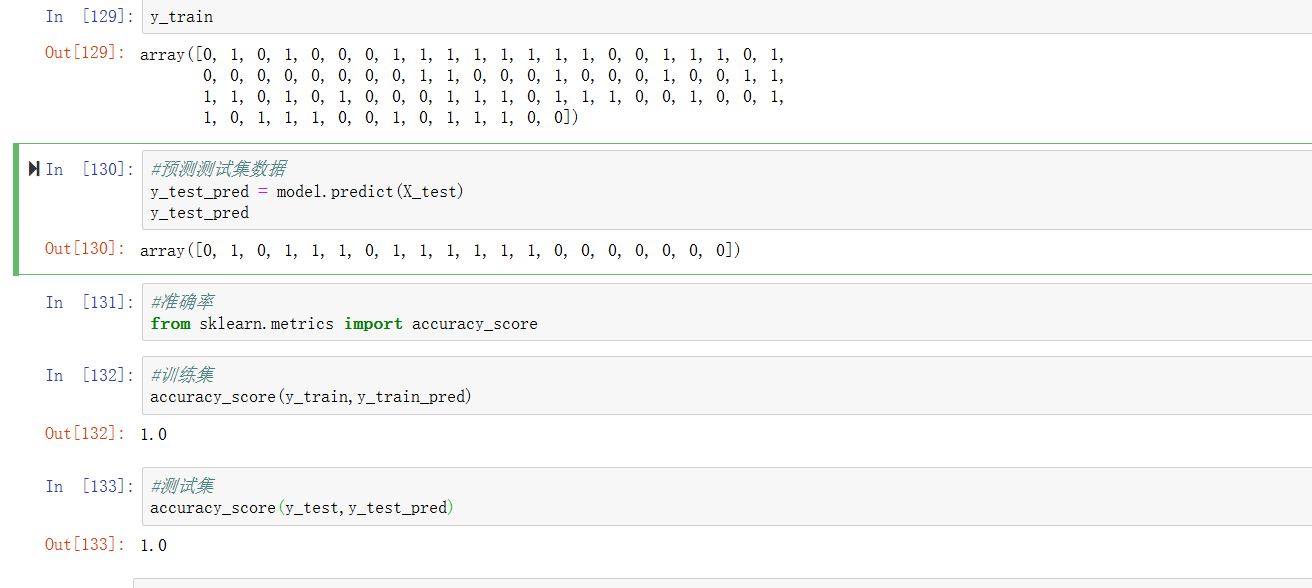
这么厉害?直接干到1了,难以置信,于是查了一下,发现是我没常识了,对不起
于是我们修改代码,选择的是后100数据

python
#先研究二分类问题,选择后一百的数据
x = x[50:]
y = y[50:]然后其他的不用改,从头 按 shift+enter 运行到最后
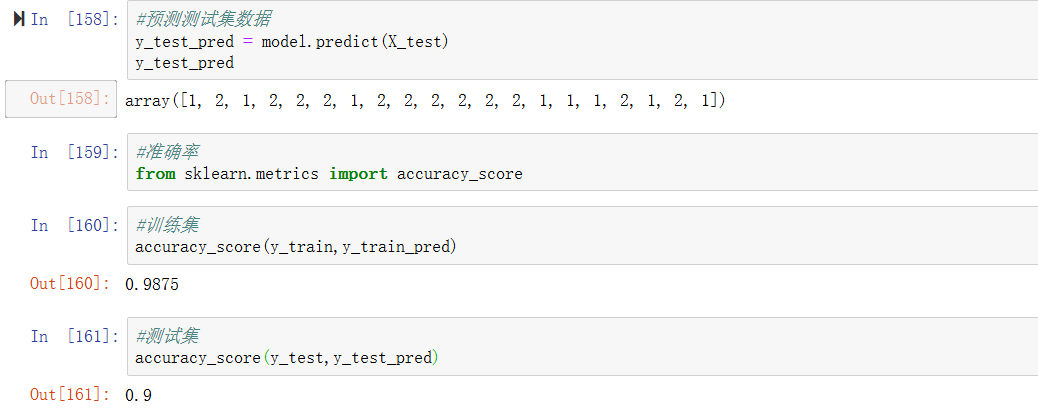
可以,这个结果才是比较正常的
也可以计算其他的指标比如MSE,R^2
python
from sklearn.metrics import mean_squared_error
mean_squared_error(真实值,预测值)
python
from sklearn.metrics import r2_score
r2_score(真实值,预测值)随机森林(分类)
导入鸢尾花的数据集,
赋值x,y
取后一百组
python
#导入鸢尾花的数据集,赋值x,y,取后一百组,与上面一样
from sklearn.datasets import load_iris
data = load_iris()
x = data['data']
y = data['target']
#先研究二分类问题,选择后一百的数据
x = x[50:]
y = y[50:]划分数据集
python
#划分数据集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=10)导入随机森林分类模型
实例化模型
训练模型
python
#导入我们的随机森林分类模型
from sklearn.ensemble import RandomForestClassifier
#实例化模型
model = RandomForestClassifier()
#训练模型
model.fit(X_train,y_train)预测训练集数据
python
#预测训练集数据
y_train_pred = model.predict(X_train)
y_train_pred预测测试集数据
python
#预测测试集数据
y_test_pred = model.predict(X_test)
y_test_pred 导入计算准确率的库
python
#准确率
from sklearn.metrics import accuracy_score对训练集和测试集求准确率
python
#训练集
accuracy_score(y_train,y_train_pred)
python
#测试集
accuracy_score(y_test,y_test_pred)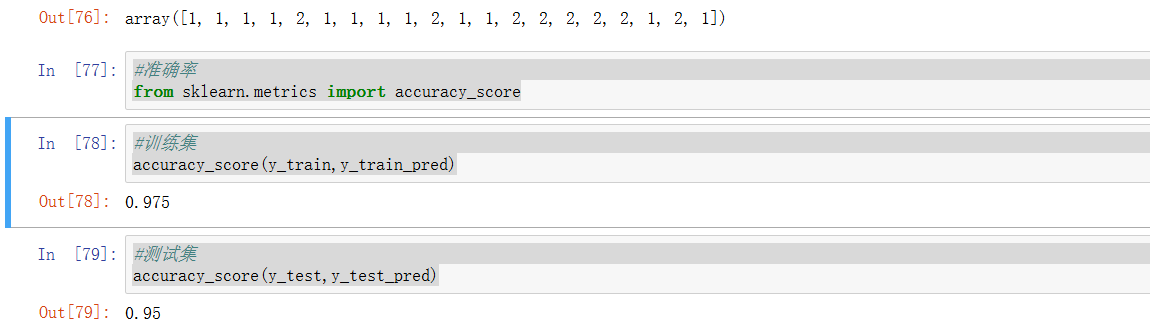
这个模型还是不错的
逻辑回归
导入数据
对x,y赋值
python
#导入鸢尾花的数据集,赋值x,y,取后一百组,与上面一样
from sklearn.datasets import load_iris
data = load_iris()
x = data['data']
y = data['target']
#先研究二分类问题,选择后一百的数据
x = x[50:]
y = y[50:]划分数据集
python
#划分数据集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=10)导入模型
实例化模型
训练
python
#导入我们的随机森林分类模型
from sklearn.ensemble import RandomForestClassifier
#实例化模型
model = RandomForestClassifier()
#训练模型
model.fit(X_train,y_train)
预测训练集和测试集
python
#预测训练集数据
y_train_pred = model.predict(X_train)
y_train_pred
python
#预测测试集数据
y_test_pred = model.predict(X_test)
y_test_pred 看准确率
python
#准确率
from sklearn.metrics import accuracy_score
python
#训练集
accuracy_score(y_train,y_train_pred)
python
#测试集
accuracy_score(y_test,y_test_pred)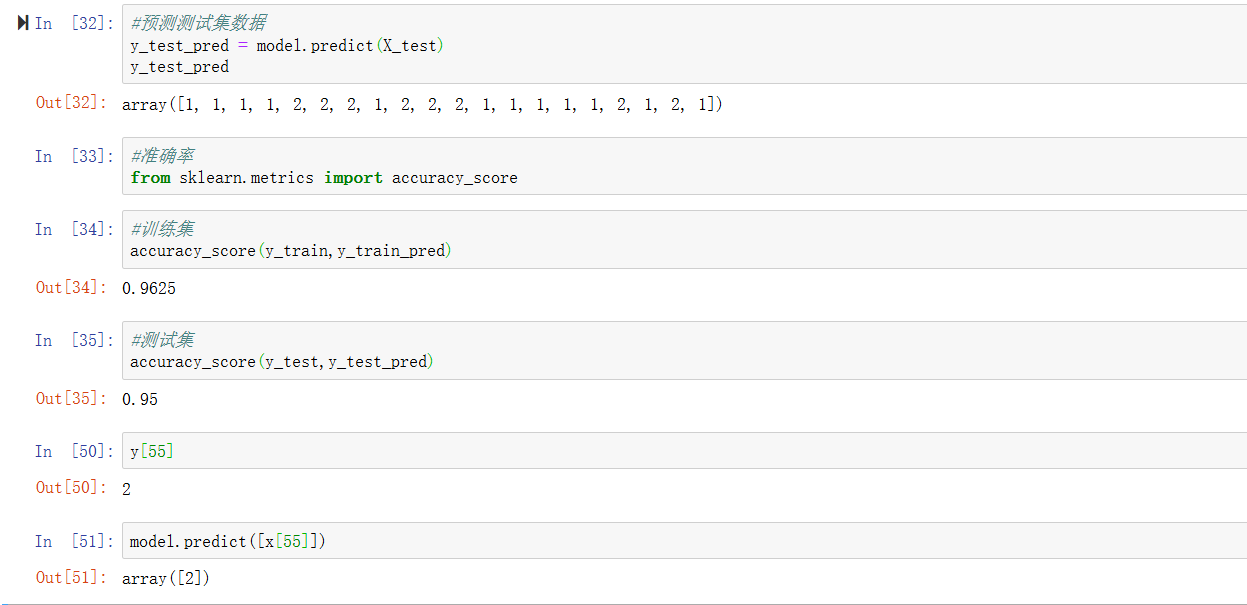
结果还是不错的
支持向量机
导库
赋值x,y
python
#导入鸢尾花的数据集,赋值x,y,取后一百组,与上面一样
from sklearn.datasets import load_iris
data = load_iris()
x = data['data']
y = data['target']
#先研究二分类问题,选择后一百的数据
x = x[50:]
y = y[50:]划分数据集
python
#划分数据集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=18)导SVC的库
python
#导库
from sklearn.svm import SVC
#实例化
#SVC有两个核线性核
实例化
训练
python
# 线性核
model_linear = SVC(kernel='linear', C=1.0)
model_linear.fit(X_train,y_train)
预测训练集,测试集
python
#预测训练集
#预测训练集数据
y_train_pred = model_linear.predict(X_train)
y_train_pred
python
#预测测试集数据
y_test_pred = model_linear.predict(X_test)
y_test_pred 求准确率
python
#准确率
from sklearn.metrics import accuracy_score
#训练集
print("model_linear训练集准确率:")
print(accuracy_score(y_train,y_train_pred))
#测试集
print("model_linear测试集准确率:")
print(accuracy_score(y_test,y_test_pred))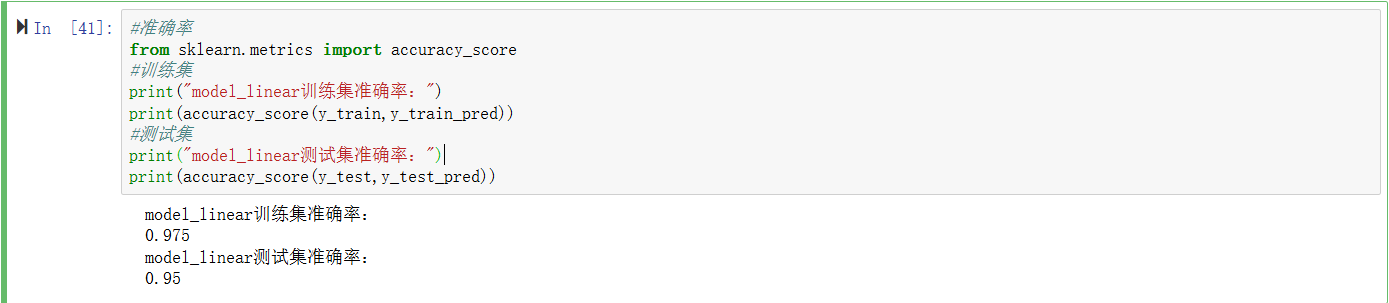 高斯核
高斯核
实例化
训练
python
# 高斯核(RBF)
model_rbf = SVC(kernel='rbf', gamma=0.1, C=1.0)
model_rbf.fit(X_train,y_train)
预测训练集,测试集
python
#预测训练集
#预测训练集数据
y_train_pred = model_rbf.predict(X_train)
y_train_pred
python
#预测测试集数据
y_test_pred = model_rbf.predict(X_test)
y_test_pred 求准确率
python
#准确率
from sklearn.metrics import accuracy_score
#训练集
print("model_rbfr训练集准确率:")
print(accuracy_score(y_train,y_train_pred))
#测试集
print("model_rbf测试集准确率:")
print(accuracy_score(y_test,y_test_pred))
KNN分类
导库
给x,y赋值
python
#导入鸢尾花的数据集,赋值x,y,取后一百组,与上面一样
from sklearn.datasets import load_iris
data = load_iris()
x = data['data']
y = data['target']
#先研究二分类问题,选择后一百的数据
x = x[50:]
y = y[50:]划分数据集
python
#划分数据集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=20)导库
实例化
训练
python
#导库
from sklearn.neighbors import KNeighborsClassifier
#实例化
model = KNeighborsClassifier(n_neighbors=3)
#训练
model.fit(X_train, y_train)
预测训练集与测试集
python
#预测训练集数据
y_train_pred = model.predict(X_train)
y_train_pred
python
#预测测试集数据
y_test_pred = model.predict(X_test)
y_test_pred 求准确率
python
#准确率
from sklearn.metrics import accuracy_score
python
#训练集
accuracy_score(y_train,y_train_pred)
python
#测试集
accuracy_score(y_test,y_test_pred)