Towards Transparent AI:
A Survey on Explainable Large Language Models

Abstract
大型语言模型(Large Language Models, LLMs)在推进人工智能(AI)发展中扮演了关键角色 。然而,尽管取得了诸多成就,LLMs 常常难以解释其决策过程,使其成为一个"黑箱(black box)",并对可解释性构成了重大挑战。这种透明度的缺乏对 LLMs 在高风险领域(high-stakes domain) 应用中的采纳构成了显著障碍,在这些领域,可解释性(interpretability)尤为重要。
为克服这些限制,研究人员开发了各种可解释人工智能(Explainable Artificial Intelligence, XAI)方法,为 LLMs 提供人类可理解的解释。然而,对这些方法的系统性理解仍然有限。
为填补这一空白,本综述通过基于 LLMs 底层 Transformer 架构 对 XAI 方法进行分类,提供了一项全面的回顾:仅编码器(encoder-only) 、仅解码器(decoder-only) 和 编码器-解码器(encoder-decoder)模型。
接着,从评估可解释性 的角度审视这些技术,并进一步探讨这些解释如何在实际应用(practical applications)中被利用。
最后,讨论了可用资源、持续的研究挑战和未来方向,旨在引导持续努力发展透明和负责任的 LLMs。
1. Introduction
在快速发展的自然语言处理( NLP)领域,像 BERT , T5 , GPT-4 , 和 LLaMA-2 这样的大型语言模型(LLMs)已在机器翻译(machine translation)、代码生成(code generation)、医疗诊断(medical diagnosis)和个性化教育(personalized education)等多个领域展现出惊人的能力。然而,由于其庞大的参数和广泛的训练数据 ,它们的"黑箱"特性掩盖了内部机制和决策过程,使得可解释性变得复杂。这种透明度的缺乏可能导致诸如模型幻觉(model hallucinations)和有害内容等意外问题 ,在健康、金融和法律等高风险领域 构成重大挑战,在这些领域,可解释性对于避免严重错误至关重要 。若无法洞察决策过程,用户信任将受到侵蚀,伦理担忧也会升级。
研究人员开发了各种可解释人工智能(XAI) 方法来应对关于 LLMs 的担忧,旨在揭示其内部过程和决策机制,并提供清晰、人类层面的解释(human-level explanations)。这对于建立用户信任、确保伦理的高风险决策以及识别模型幻觉和偏见 (例如,在翻译中将"医生"对应为男性代词、"护士"对应为女性代词的性别偏见)等问题至关重要。XAI 也有助于调试,通过突出显示注意力模式或上下文错误来改进模型性能和可靠性,以供实际使用。
然而,当前的 XAI 文献缺乏对 LLMs 的系统性关注 ,许多综述广泛覆盖传统模型,很少涉及基于 Transformer 架构 (具有独特注意力机制的编码器-解码器组件)的独特挑战。因此,需要一个系统性综述来标准化分类体系(standardize taxonomies)并为这些架构的具体问题定制解决方案(tailor solutions)。
本综述对大型语言模型(LLMs)中的可解释人工智能(XAI)方法进行了系统性回顾,重点介绍了近期进展、评估机制(evaluation mechanisms)、解释的应用(explanation applications)以及未来研究方向(future research directions)。
据本文所知,这是首个全面综述 ,提供了基于 Transformer 架构 的标准分类法(standard taxonomy),解决了每种架构中的特定挑战,并探讨了这些解释的评估和应用。通过从架构感知视角(architecture-aware perspectives) 比较各种 XAI 方法,它提供了对技术及其用例的整体视图(holistic view)。关键贡献包括:
- 对 XAI 方法的详细回顾,采用新颖的分类法,比较不同 LLM 架构下的技术和用例;
- 分析评估机制和 XAI 解释的实际应用;
- 识别可用资源、研究挑战和未来方向 ,以发展透明、符合伦理的模型。
2. Background
2.1. Large Language Models
大型语言模型(LLMs) 已成为现代自然语言处理的基础,推动了机器翻译(machine translation)、对话生成(dialogue generation)、问答(question answering)和代码合成(code synthesis)等应用的进步。这些模型主要建立在 Transformer 架构 之上,该架构使用自注意力机制 来编码标记之间的上下文关系。通过在海量文本语料库(massive text corpora) 上进行训练,LLMs 学习捕捉语言中的统计和语义模式,使其能够泛化到各种任务中。随着这些模型规模的增长(参数数量和训练数据多样性),它们开始展现出涌现行为(emergent behaviors) ,如上下文学习(in-context learning) 、多任务泛化(multi-task generalization)以及遵循自然语言指令的能力。
尽管其能力惊人,LLMs 在很大程度上仍然是不透明的(largely opaque) 。它们的内部决策过程编码在高维且深度分层的表征 中,使用户难以理解特定预测是如何做出的。这种可解释性的缺乏 在医疗保健、法律和教育等安全关键领域 带来风险,其中不正确或有偏见的输出可能产生严重后果。因此,提高 LLMs 的透明度和问责制已成为当务之急,推动了针对其独特架构和行为定制的可解释性方法的发展。
2.2. Explainability in LLMs
可解释性(Explainability) 指的是使模型的内部逻辑(internal logic)和输出能够被人类理解的能力。这一特性对于确保透明度、检测故障模式以及实现负责任的人工智能部署 。在大型语言模型的背景下,可解释性尤其具有挑战性,因为它们的黑箱特性 。这些模型依赖于深度堆叠的 Transformer 层 ,并将知识编码在高维隐藏状态中,这使得追踪特定输出如何生成本质上很困难。
为应对这些挑战,研究人员提出了各种旨在提高 LLMs 可解释性的策略。一些方法侧重于基于显著性的归因(saliency-based attribution) ,突出输入标记对模型输出的贡献,而另一些方法则使用探测技术(probing techniques) 来检查不同层的内部表征。更新的技术,如思维链(Chain-of-Thought, CoT)提示,已证明提示格式可以塑造中间推理步骤的表达方式。
尽管取得了这些进展,许多现有方法的适用范围有限 ,无法跨任务或模型架构泛化。重要的是,不同的 LLM 在架构上差异显著,每种类型都带来了独特的可解释性挑战。
3. Taxonomy
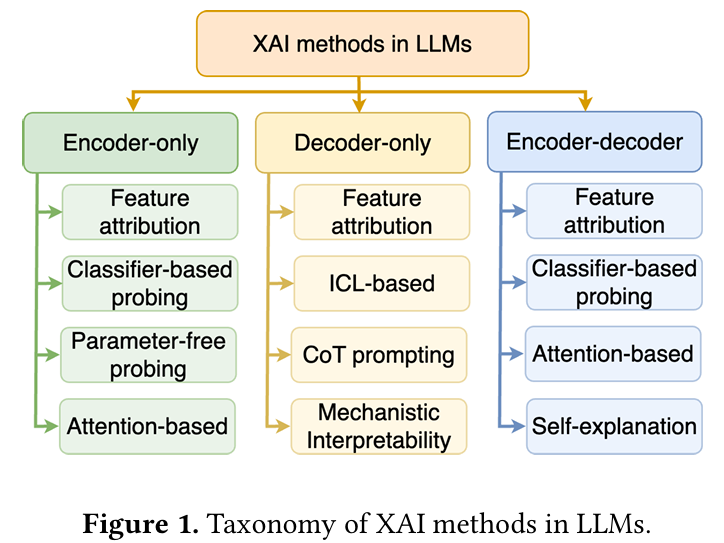
本文提出了一种新颖的分类法(taxonomy),用于根据 LLMs 的底层 Transformer 架构对 XAI 方法进行分类。如图 1 所示,该分类将 XAI 方法组织成三个基本组:
- 仅编码器 LLM 中的 XAI 方法 :旨在解释上下文嵌入 ,利用模型的双向结构(bidirectional structure)有效分析内部表征。
- 仅解码器 LLM 中的 XAI 方法 :依赖于提示工程(prompt engineering) 和上下文学习(in-context learning) 策略,以揭示这些通常因其大规模 和自回归特性而不透明的模型的内部推理过程。
- 编码器-解码器 LLM 中的 XAI 方法 :可以在编码和解码阶段 提供见解,利用其双重架构(dual architecture) ,通过交叉注意力机制解释信息流。
这种标准化的分类法 提供了针对不同架构量身定制的 XAI 技术的全面回顾,使得能够对其底层结构和特性进行有意义的比较。它也解决了在每种架构类型中实现可解释性的独特挑战 ,并强调了这些方法如何用于实际应用。
4. Overview
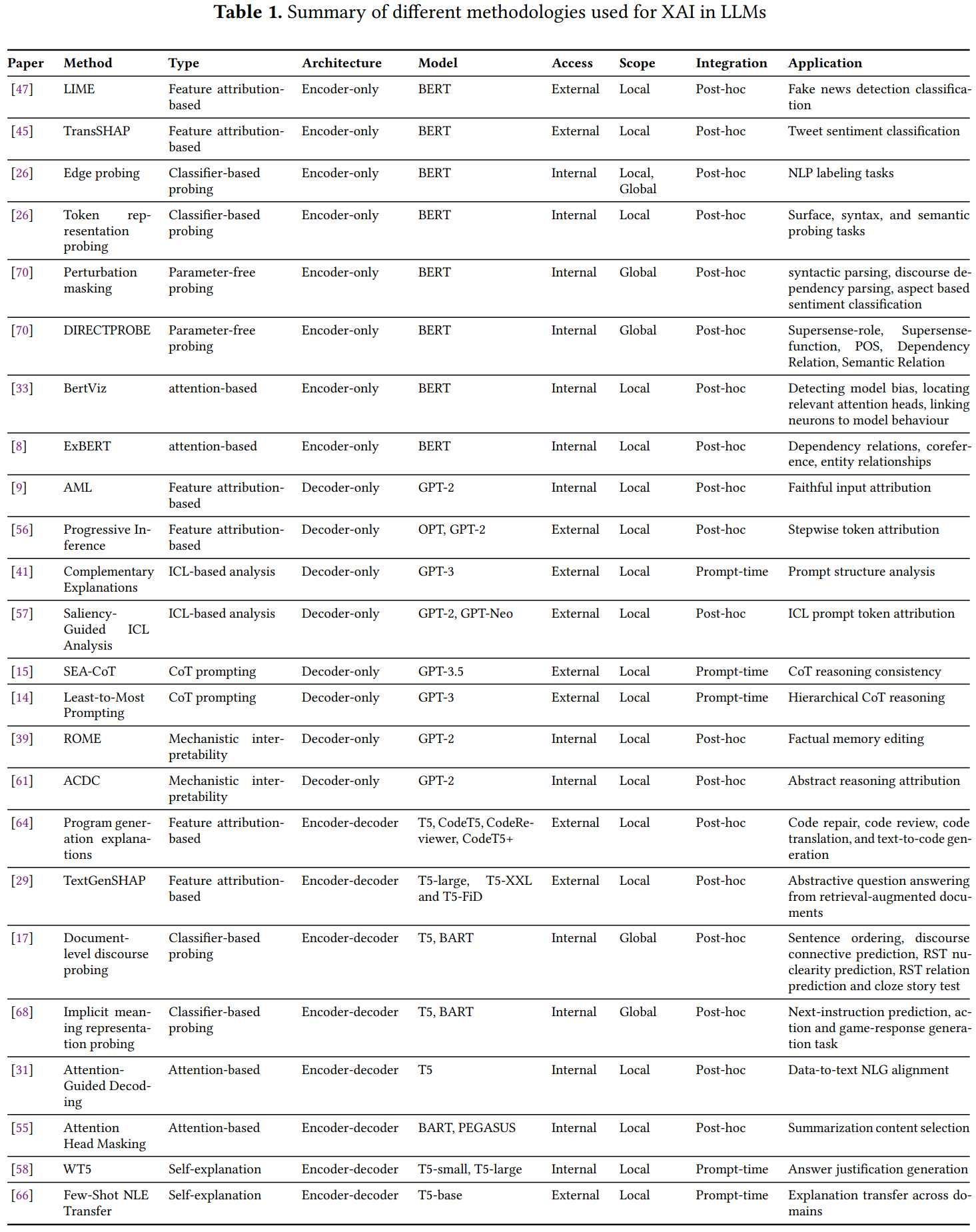
基于提出的分类法,本节概述了针对大型语言模型 的可解释人工智能(XAI) 方法学,详见表 1。研究在八个维度上进行分类:论文 、方法 、类型 、架构 、模型 、访问权限 、范围 和集成方式 ,其中应用 突出了实际用例。方法 (例如,基于特征归因的、基于分类器探测的)、基于注意力的)和类型 定义了可解释性方法,而架构 (仅编码器、仅解码器、编码器-解码器)和模型 (例如,BERT、GPT-2、T5)则标识了目标 LLM 框架。访问权限 (内部或外部)和范围 (局部或全局)反映了数据依赖性和可解释性范围,集成方式(Integration) (事后(post-hoc)、提示时(prompt-time))表明了实施阶段。应用 涵盖了多样化任务,如虚假新闻检测、情感分类、代码修复和抽象问答,展示了这些方法解决跨 LLM 架构的特定可解释性挑战的能力。
5. XAI methods in LLMs
本节详细概述了 XAI 方法 ,根据三种主要模型架构 进行了分类,每种架构都呈现出独特的可解释性挑战 并推动了不同的方法论进展 。第一类,仅编码器模型 ,侧重于解释其双向结构产生的稳定上下文嵌入 。第二类,仅解码器模型 ,针对自回归生成 ,通常使用提示工程 来评估行为。第三类,编码器-解码器模型 ,强调编码器和解码器组件之间的交互 ,并聚焦于交叉注意力机制 。这种分类揭示了共享的方法论基础 和影响当前及未来 XAI 研究的架构特定考量。
5.1. XAI methods in encoder-only LLMs
针对仅编码器模型 的 XAI 方法旨在解释其双向注意力机制(bidirectional attention mechanism) 产生的上下文表征 ,生成稳定的、语义丰富的嵌入,并通过诸如基于特征归因(feature attribution) 和基于分类器探测(classifier-based probing) 等技术进行分析。掩码语言建模(Masked language modeling, MLM) 训练简化了解释过程,它允许 XAI 追踪输入标记对内部状态或预测的影响 ,避免了生成式解码或编码器-解码器交互的复杂性。关键方法包括基于特征归因的方法、基于分类器探测的方法、无参数探测方法和基于注意力的方法。
5.1.1. 基于特征归因的方法
基于特征归因的方法(Feature attribution-based methods) 评估特征(例如,单词、短语)与模型预测的相关性,为每个特征对输出的贡献分配分数 。这些技术适用于仅编码器模型 ,这些模型使用掩码语言建模(MLM) 进行预训练,该任务整合了双向左右上下文 ,产生稳定、上下文丰富的嵌入 ,便于分析特征对预测的影响。
一种广泛使用的基于特征归因的 XAI 方法是 LIME(Local Interpretable Model-agnostic Explanations) ,它通过使用一个可解释模型在局部近似模型预测来忠实地解释模型预测 。Szczepański 等人 将 LIME 应用于基于 BERT 的、针对虚假新闻检测进行微调的模型,突出显示单词及其权重 以展示它们对预测概率的影响------权重越高,句子被分类为虚假的可能性越大 ,反之亦然。然而,LIME 存在局限性 ,它不满足可加性归因特性,如局部准确性、一致性和缺失性。
这个问题由 SHAP(SHapley Additive exPlanations) 解决,这是一种有效的特征归因技术 ,它使用沙普利值(Shapley values) 来衡量独特的可加性特征重要性 。Kokalj 等人 通过 TransSHAP 扩展了 SHAP 以用于仅编码器模型,将其应用于 BERT 进行推文情感分类,可视化正面和负面情感的预测 。该工具比较每个单词的影响方向和幅度,在某些可视化方面优于 LIME,尽管在整体用户偏好方面 LIME 得分略高。SHAP 面临的挑战包括选择特征移除方法和管理估算沙普利值的计算复杂性。
5.1.2. 基于分类器的探测
基于分类器探测的方法 在仅编码器模型(如 BERT)之上训练轻量级分类器,首先冻结参数(freezing parameters) 并为输入单词、短语或句子生成表示。与评估输入特征对预测贡献的基于特征归因方法不同,这种方法使用探测分类器来识别语言属性或推理能力 。它适用于使用掩码语言建模(MLM) 预训练的仅编码器模型,为每个标记生成鲁棒的上下文化嵌入。
为了探索仅编码器模型(如 BERT)中的词级上下文化表示 ,Tenney 等人引入了边缘探测(edge probing) ,该方法检查模型如何跨句法、语义、局部和长距离现象编码句子结构,目标针对核心 NLP 任务,如词性标注(part-of-speech tagging) 、语义角色标注(semantic role labeling) 和共指消解(coreference resolution) 。他们的研究表明 BERT 优于非上下文模型 ,尤其是在句法任务上优于语义任务,表明其对句法特征(syntactic features)的编码能力更强 。然而,边缘探测缺乏对逐层行为和单个标记功能的洞察。
为了克服这一限制,Mohebbi 等人检查了 BERT 空间中的标记表示 ,以解释其在表面、句法和语义任务中的性能趋势,揭示较高层编码所需知识 ,其中大部分位置信息在层间减弱,而句子结束标记部分地传递了它。他们还发现 BERT 在这些标记中编码了动词时态和名词数(encodes verb tense and noun number) ,使用带有归因方法的诊断分类器(diagnostic classifier) 进行定性分析。然而,Hewitt 和 Liang 通过控制任务质疑了探测分类器的忠实性(probing classifier faithfulness) ,建议使用接下来讨论的无参数探测(parameter-free probing)作为解决方案。
5.1.3. 无参数探测
无参数探测技术(Parameter-free probing techniques) 绕过训练外部分类器或添加参数,直接分析输出(directly analyzing outputs) ,如激活模式、注意力权重或来自仅编码器模型的上下文化嵌入,以检测语言结构。这解决了基于分类器探测的一个关键缺陷,即探测可能学习下游任务的方面(the probe may learn downstream task aspects),并将其编码在自身参数中,而不是忠实地反映模型的固有知识。
Wu 等人引入了扰动掩码(perturbed masking) ,这是一种无参数探测技术,用于估计词间相关性(estimate inter-word correlations) 和提取全局句法信息(extract global syntactic information) 。该方法使用一个两阶段过程:首先,掩码一个目标词(masking a target word) ,然后观察当另一个词被掩码时其上下文化表示的偏移,量化第二个词的影响。从 BERT 输出中导出的影响矩阵(impact matrices) 捕获了这些相关性,反映了注意力机制的依赖结构,尽管这些矩阵是从输出而非中间表示计算得出的。算法从这些矩阵中提取句法树,表明 BERT 编码了丰富的句法属性,该方法还评估了其建模长文档序列的能力(ability to model long document sequences)。
同样,Zhou 等人 指出,训练分类器作为探测是不可靠的,因为不同的表示需要不同的分类器,这可能会歪曲对表示质量的估计 。为了解决这个问题,他们提出了 DIRECTPROBE ,一种无参数启发式方法(parameter-free heuristic method) ,它利用版本空间(version space) 来分析嵌入几何(embedding geometry) ,无需分类器即可确定任务适用性。
5.1.4. 基于注意力的方法
仅编码器模型 (如 BERT)依赖于 Transformer 架构 ,其核心是完全基于注意力的双向自注意力机制 。虽然先前的 XAI 方法(如基于特征归因或轻量级分类器探测)评估输入贡献,但基于注意力的方法通过可视化自注意力分布和标记权重分配,提供了模型推理的直接视图(offer a direct view into model reasoning) 。已经开发了各种工具来利用这一点,提供简洁的摘要并增强用户与 LLMs 的交互。
为了检查注意力机制,Vig 等人开发了 BertViz ,这是一个开源工具(open-source tool) ,可在多个尺度上可视化注意力,通过高层模型视图(high-level model view) (显示所有层和头)和低层神经元视图(low-level neuron view) (揭示注意力模式中的神经元交互)提供视角。应用于仅编码器的 BERT 模型时,它支持三个用例:检测偏见(detecting bias) 、识别关键注意力头 以及将神经元与行为联系起来 。然而,仅依赖注意力进行忠实解释可能会产生误导性结果。
为了解决这个问题,Hoover 等人引入了 ExBERT ,这是一个交互式工具,用于可视化 Transformer 模型中的注意力机制和内部表示 。它具有一个注意力视图 用于检查聚合模式,以及一个语料库视图 用于通过统计数据总结选定标记的隐藏表示。利用注意力可视化和最近邻搜索(nearest-neighbor search) ,ExBERT 揭示了捕获的信息和文本输入中的潜在偏见 ,尽管它仅限于局部分析,侧重于每个标记的少数邻居。
**5.2.**XAI methods in decoder-only LLMs
针对仅解码器模型 (decoder-only LLMs)的 XAI 方法旨在解决其自回归、左到右的生成特性 (autoregressive, left-to-right generation),呈现出独特的可解释性挑战和机遇 。与具有稳定、易于探测的上下文嵌入 (stable, easily probed contextual embeddings)的仅编码器模型不同,仅解码器模型需要专门为其单向特性 (unidirectional nature)量身定制的技术。关键方法 包括基于特征归因的方法 (feature attribution-based approaches)、基于上下文学习(ICL)的方法 、思维链(CoT)提示 (chain-of-thought prompting)和机械可解释性(mechanistic interpretability)。
5.2.1. 基于特征归因的方法
基于特征归因的方法量化单个输入标记 (individual input tokens)对模型输出的贡献。如第 5.1.1 节所述,它们适用于具有双向上下文 (bidirectional context)的仅编码器模型。然而,将其应用于仅解码器大型语言模型具有挑战性,因其自回归、左到右的标记生成 (autoregressive token generation)使得传统双向方法无法捕捉因果结构(fail to capture causal structure)。因此,近期研究聚焦于开发专门针对自回归解码过程的归因技术。
归因掩码学习(AML) :通过基于梯度的方法识别最小且充分的输入标记子集 (minimal, sufficient token subset),利用掩码生成器最小化完整与掩码预测间的 KL 散度 (Kullback-Leibler divergence),提供忠实的因果解释(faithful, causally grounded explanations)。
依赖模型内部机制,无法用于闭源模型(如 GPT-4、Claude);在高组合性任务(如多跳推理)中因掩码响应不稳定而失效。
渐进推理 (Progressive Inference):采用无需参数、模型不可知 (parameter-free, model-agnostic)的方法,通过扩展输入序列跟踪输出概率演变,构建影响曲线(influence curve)。
忽略远距离标记依赖关系,在需全局语义理解的任务(如摘要)中解释力不足;以解释深度换取可访问性。
5.2.2. 基于上下文学习(ICL)的方法
上下文学习(ICL)使仅解码器模型(如 GPT 系列)能通过少量提示示例执行新任务,无需参数更新。其机制不透明性推动 ICL 可解释性方法聚焦于提示信息的提取与使用,强调结构、语义和标记级显著性(token-level saliency)。
Lampinen 等人的研究 :使用对比提示 (contrastive prompts)将语义替换为句法连贯但无意义的标记,揭示模型依赖句法结构与标记位置 (syntactic structures & token positions),而非深层语义理解,泛化能力源于统计模式匹配(statistical pattern matching)。
Li 等人的显著性引导方法 :利用输出损失梯度 (output loss gradients)生成显著性图 (saliency maps),发现注意力集中在最终标记 (final tokens,如答案标签),表明模型优先处理对比信号(contrastive signals)而非整体表征。需结合提示结构分析与显著性解释,以全面理解 ICL 机制。
5.2.3. 思维链(CoT)提示
思维链(Chain-of-thought, CoT)提示 通过添加中间推理步骤 (intermediate reasoning steps),将不透明的预测转化为可解释的推理依据 (interpretable rationales)。CoT 与自回归生成 (autoregressive generation)特性天然契合,允许实时跟踪推理路径 (reasoning paths),在数学或逻辑谜题等复杂任务中提升性能的同时,在输出中嵌入可解释性。与依赖提示结构引导任务行为的基于上下文学习(ICL) 方法不同,CoT 在响应中提供明确的推理洞察 (explicit reasoning insights),使其成为仅解码器模型的理想选择------其左到右的生成 (left-to-right generation)特性支持增量式、可解释的推理(incremental, interpretable reasoning)。
SEA-CoT :通过自然语言推理(NLI)模型 验证每一步推理与前序步骤的逻辑一致性,过滤不连贯的过渡 (incoherent transitions),提升忠实度 (faithfulness)和局部连贯性(local coherence)。
依赖外部 NLI 工具,且仅关注成对步骤关系(pairwise step relationships),忽略全局推理的有效性。
由易到难提示 (Least-to-Most Prompting):将复杂问题分解为有序子任务(如定义变量→建立方程→求解),构建增量式、清晰且可控的推理链。
需大量提示工程 (extensive prompt engineering),在开放域文本生成等非结构化任务(unstructured tasks)中表现不佳。
5.2.4. 机械可解释性
机械可解释性方法 (Mechanistic interpretability methods)通过揭示内部计算结构 (internal computational structures),追踪因果路径 (causal pathways)以识别神经元、注意力头或前馈层等组件的功能,提供结构化、细粒度的洞察 (structural, fine-grained insights)。其优势在于分离模块化组件 (modular components),尤其适用于具有深度堆叠 Transformer 块(deeply stacked transformer blocks)的自回归架构。
ROME(秩一模型编辑) :提供局部化编辑框架 (localized editing framework),通过修改前馈层神经元编辑事实性知识(如将"巴黎是法国首都"改为"佛罗里达"),证明知识存储于可编辑子网络(editable subnetworks)。
仅适用于事实召回,无法处理抽象或多跳推理(abstract or multi-hop reasoning),且假设固定的激活路径。
ACDC 与 Transformer 电路 :整合激活修补 (activation patching)、归因和剪枝,识别驱动认知任务(如数字比较)的最小子图 (minimal subgraphs),揭示可重用模块化组件(reusable modular components)。
需完全白盒访问(full white-box access)且计算密集,阻碍可扩展性。
5.3. XAI methods in encoder-decoder LLMs
编码器-解码器模型 (Encoder-decoder LLMs)采用一种双组件架构 (two-part architecture),包含一个交叉注意力机制 ,它集成了用于理解的编码器 和用于生成的解码器 ,从而能够在两个阶段实现可解释性。与仅编码器模型相比,它们增强了生成能力;与仅解码器模型相比,它们提供了更好的输入表征控制。关键的可解释性方法 包括基于特征归因的方法、基于分类器的方法、基于注意力的方法和自解释技术(self-explanation techniques)。
5.3.1. 基于特征归因的方法
如第 5.1.1 节和第 5.2.1 节所述,基于特征归因的方法为每个特征分配相关性分数。与在仅编码器和仅解码器模型中的应用不同,在编码器-解码器模型中,这些方法评估输入和输出序列中标记的相关性,反映了序列到序列的性质,考虑了来自前序输出标记以及输入标记的贡献。
为应用基于特征归因的 XAI 方法,Liu 等人对程序生成进行研究,使用基于梯度的 SHAP 解释决策过程。他们发现 CodeT5 、CodeReviewer 和 CodeT5+ 等模型优先考虑关键字和标识符而非运算符和分隔符 ,表明其对代码语法和结构有强识别能力。然而,移除微小标记会导致性能显著下降 ,揭示了鲁棒性问题。尽管 SHAP 实用,但其在处理大型模型和长序列时存在可扩展性挑战,常导致不切实际的延迟。
为解决问题,Enouen 等人引入 TextGenSHAP ,这是对沙普利值的高效增强,适用于 T5-large 、T5-XXL 和 T5-FiD 等模型。针对开放式文本生成 (open-ended text generation)(特别是带检索增强文档的抽象问答)的长提示,TextGenSHAP 提升了文档检索系统的召回率。尽管是重大进步,生成解释的计算成本仍是实际关注点。
5.3.2. 基于分类器的方法
基于分类器探测的方法通过在冻结表示上训练浅层分类器解释预测和行为。在编码器-解码器模型中,该方法独特地针对编码器和解码器组件,旨在解决其复杂交互带来的解释挑战。
Koto 等人引入文档级话语探测 (document-level discourse probing),评估 T5 和 BART 捕捉话语关系 (discourse relations)的能力。研究表明 BART 的编码器层在话语连接词 (discourse connective)、修辞结构理论核性 (RST nuclearity)和修辞结构理论关系(RST relation)任务中表现优异,但解码器更侧重生成而非理解。类似地,在 T5 中,话语知识在层间分布不均,受预训练目标和架构影响。
Li 等人将方法扩展至隐含意义 (implicit meaning)领域,探索 BART 和 T5 如何编码话语级信息状态 (discourse-level information states)。结果表明隐含意义可从实体提及中线性解码,捕捉状态变化和最终状态的语义细节。然而,仅约半数情况能恢复完整状态,且探测表示缺乏类人生成所需的表达能力。
5.3.3. 基于注意力的方法
基于注意力的方法利用注意力权重 ,特别是编码器-解码器模型中的交叉注意力 ,解释输入如何影响输出生成。交叉注意力层直接连接编码器输入与解码器输出,使注意力成为摘要或翻译等任务的关键工具,其中追踪源到目标序列(tracing source-to-target sequences)至关重要。
Juraska 等人引入注意力引导解码 (attention-guided decoding),通过分析解码过程中的交叉注意力激活识别影响目标标记的源标记。该方法通过跟踪注意力权重并重新评分束以实现语义一致性,揭示输入到输出的信息流。然而,其可靠性依赖良好校准的注意力图,冗长或嘈杂输入可能导致注意力扩散,削弱解释忠实度。
相比之下,注意力头掩蔽 (attention head masking)采用基于干预的方法,通过禁用特定注意力头评估其因果重要性,提供头部级别的归因和内部决策路径洞察。尽管能精确隔离功能角色,但组合复杂性导致可扩展性挑战,且可能忽略分布式模式。
5.3.4. 自解释方法
基于自解释的方法通过生成人类可读的推理依据(human-readable justifications)及任务预测来增强可解释性。该方法利用解码器的生成能力,在输出序列中嵌入解释,实现用户对齐的可解释性,无需事后分析。
WT5 是典型方法,训练模型同时输出答案和解释(如回答"巴黎是法国的首都吗?"时输出"是,因为巴黎是法国的首都")。这种格式将支持事实与结论关联,提升用户信任,并通过联合训练提高任务性能。然而,其依赖大量带解释标注的数据,且不确定解释是否反映因果推理或仅是标签模式。
Yordan 等人扩展该方法,提出少样本域外自然语言解释生成 (Few-Shot Out-of-Domain NLE generation),针对标注稀缺但标签丰富的任务。其方法在标注丰富的源域预训练模型,通过对齐表示空间和在有限示例上微调,适配目标域。相比 WT5,该方法增强跨领域可扩展性,但少样本方法在抽象推理(abstract reasoning)场景下面临解释质量泛化挑战。

