| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文名称 | 3D-GENERALIST |
| 2 | 发表时间/位置 | 2025 |
| 3 | Code | 3D-Generalist |
| 4 | 创新点 | 1:核心范式转变 (The Core Paradigm Shift)从"生成"到"决策": 传统方法: 端到端生成(一次性输出模型或图像)。 本文: 将 3D 场景构建重构为 序列决策问题 (Sequential Decision-Making)。 把 VLM(如 GPT-4o)当作智能体(Agent/Policy),让它像人类设计师一样,"观察(Observation) -> 思考 -> 行动(Action/Code) -> 再观察",通过多轮迭代来完善场景。 2:模块创新 (Architectural Innovations) (1)全景环境生成 (Panoramic Environment Generation):解决了直接预测房间坐标不准的问题。 "先画图,后建模"。利用全景扩散模型生成 360° 图像,再通过逆图形学(Inverse Graphics)反推墙壁、门窗的 3D 结构。 (2)场景级策略 (Scene-Level Policy) :通过VLM 编写代码(Action Code)来控制场景。 设计了一套 DSL (领域特定语言),允许模型通过代码精确控制物体位置、材质和光照。 利用 VLM 的多模态能力,根据渲染图的视觉反馈进行自我修正(Self-Correction)。 (3)资产级策略 (Asset-Level Policy):解决了小物体(如桌上的书)放置的物理合理性和嵌套关系。 递归堆叠 (Recursive Stacking): 引入"容器对象"概念,支持在物体上放物体。 双模型协作: 大局观用 GPT-4o,精准定位用专门的像素级 VLM (Pixel-grounding VLM),实现指哪打哪。 物理验证: 引入碰撞检测,防止穿模。 3:训练策略 通用 VLM 不懂专业的 3D 布局设计。本文采用自我改进微调 (Self-Improvement Fine-tuning) 的方法。让模型"左右互搏"。1 针对一个 Prompt 生成多个方案。2 用 CLIP Score 作为裁判,选出图文最匹配的方案。 3 把高分方案作为"教材"反向微调模型。 In-context Library(上下文库,一个参考案例库里面存了很多高质量的成对数据): 建立优质代码库作为"作弊小抄",提升生成的起步质量。 |
| 5 | 引用量 | 生成3D场景,解决之前在3D数据上的短板。本文提出了 3D-GENERALIST 框架,通过将 3D 场景构建重塑为由 VLM(视觉语言模型)驱动的"观察-决策-修正"序列过程,实现了大规模、可物理模拟的 3D 环境自动生成,并证明了使用这些合成数据训练出的视觉模型,性能超越了使用人工合成数据训练的模型。 |

一:提出问题
**虽然现在的模型(如GPT-4V)能看懂图、能写代码,但在理解三维空间(空间推理)方面还很弱。**因此导致他们缺乏对3D世界的感知的空间感。而3D数据获取较为困难,成本很高。
提出了一个名为 3D-GENERALIST 的框架:
-
像玩游戏一样造世界(Sequential Decision-Making): 作者没有让模型直接生成一个3D文件,而是把"造世界"看作一系列的决策步骤。
-
VLM作为大脑(Policy): 使用一个视觉-语言模型作为"工头"。它不仅看(Vision)和读(Language),还能做动作(Action)。
-
具体操作: 这个模型会一步步发出指令(Action),比如:"在这里放一张桌子"、"把材质改成木头"、"把灯光调暗"。它控制3D引擎来生成布局、材质、光照和资产。
-
自我进化(Self-improvement): 模型通过一种自我改进的微调机制进行训练,确生成的环境能够精准地符合人类输入的提示词(Prompt)。
一个可用的3D场景的构建成本十分高昂,而现有的模型工具有的只管摆家具(Holodeck),有的只管画贴图(URDFormer)。它们是割裂的。作者希望建立一个系统,只要你给的算力越多(让他思考和修改的时间越长),它生成的质量就越高。
本文想让模型也能够实现把造世界看作一个**"序列决策过程"** (Sequential Decision-Making)。模型先做一个大概,然后"看一看"(Observation),再决定下一步怎么改(Action)。这赋予了模型**自我修正(Self-correct)**的能力。因此提出了一个3D-GENERALIST 框架:
**一次性决策(扔飞镖):**你瞄准,扔出去,动作结束。结果只有"中"或"不中"。这就像传统的 AI 画图:你给个提示词,它直接给你一张图,一步到位,好坏听天由命。
序列决策(下棋): 你不能一步就把对方"将死"。你必须第一步 走当头炮,看一眼 对方怎么应,第二步 再跳马,再看一眼 局势......经过几十步的博弈,最终赢得比赛。重点是: 现在的决定会影响未来的局势;未来的局势又决定了你下一步能做什么。
序列决策就是,别想一步到位。你得走一步、看一眼、想一下,再走下一步。而且你要为你的每一步选择负责,因为现在的选择,决定了你未来的路好不好走。
全景环境生成(搞基建): 先根据文字生成一张全景图,然后反推生成房间的墙壁、门窗位置(硬装)。
场景级策略(搞软装和氛围): 一个VLM(视觉语言模型)充当总指挥。它负责选家具、换材质、调灯光。它会不断地看当前场景,然后进行微调。
资产级策略(搞细节): 专门负责"套娃"式的摆放。比如在桌子上放个盘子,在盘子里放个苹果。这需要很强的物理常识(不能把苹果嵌到盘子里面去)。
作者用这些生成的数据训练了一个新的模型,用这个系统生成的"假数据"训练出来的模型,比用人类精心制作的数据训练出来的模型还要强。这证明了该系统不仅能生成数据,还能生成高质量、有训练价值的数据。
二:解决方案
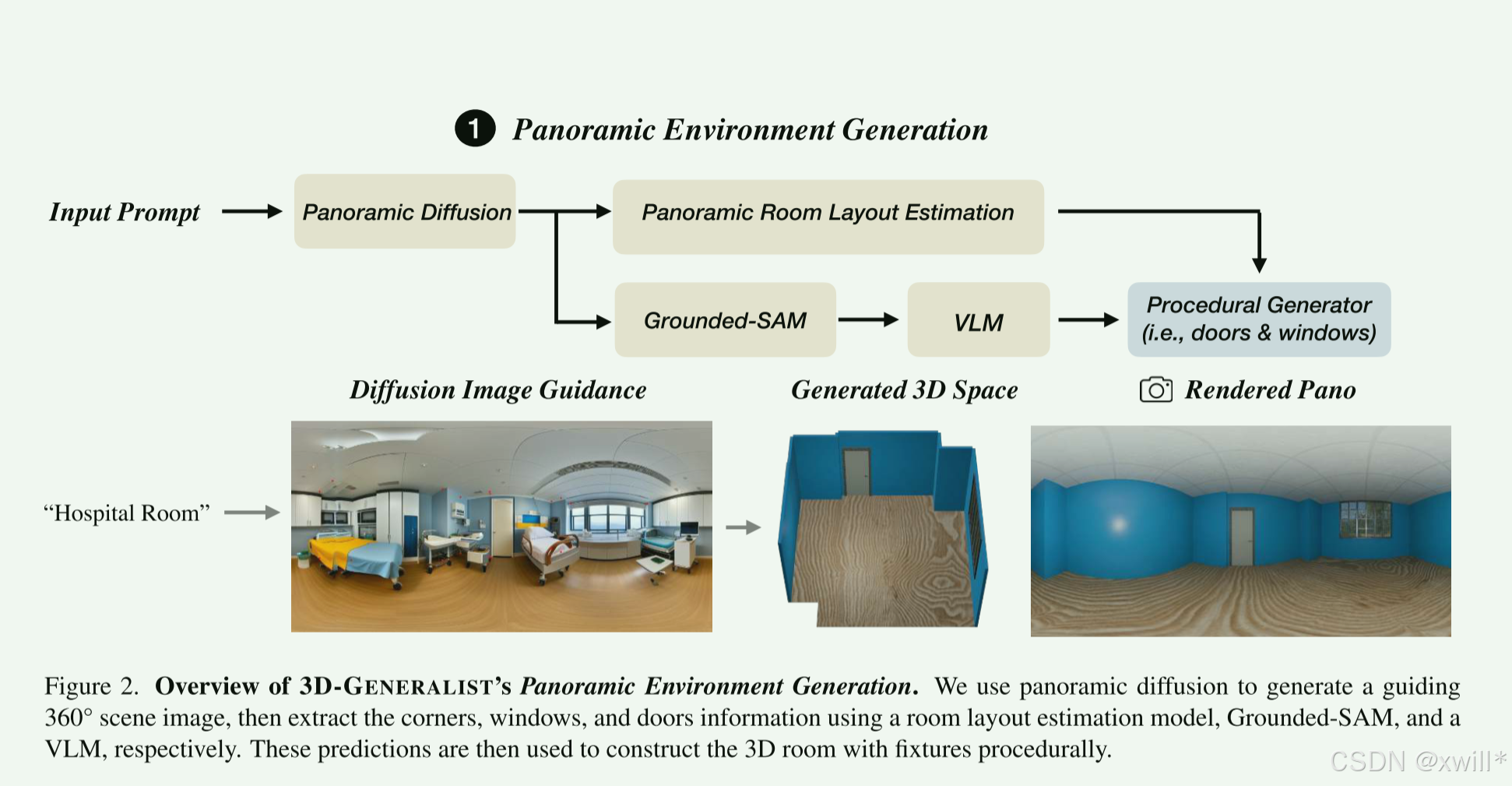
1 3D-GENERALIST
(1)全景环境生成 (The Skeleton),采用先画图,再建模的方法
-
**Step 1:**模型先把脑子里的房间画成一张"全景图"(就像你看房时的VR全景照片)。
-
Step 2: 用算法(HorizonNet)看这张图,识别哪里是墙角、哪里是天花板。
-
Step 3: 用分割算法(SAM)把门和窗户扣出来。
-
Step 4: 再让GPT-4o看一眼扣出来的门窗,决定是什么材质(木头还是金属?)。
-
Step 5: 最后在3D软件里生成模型。
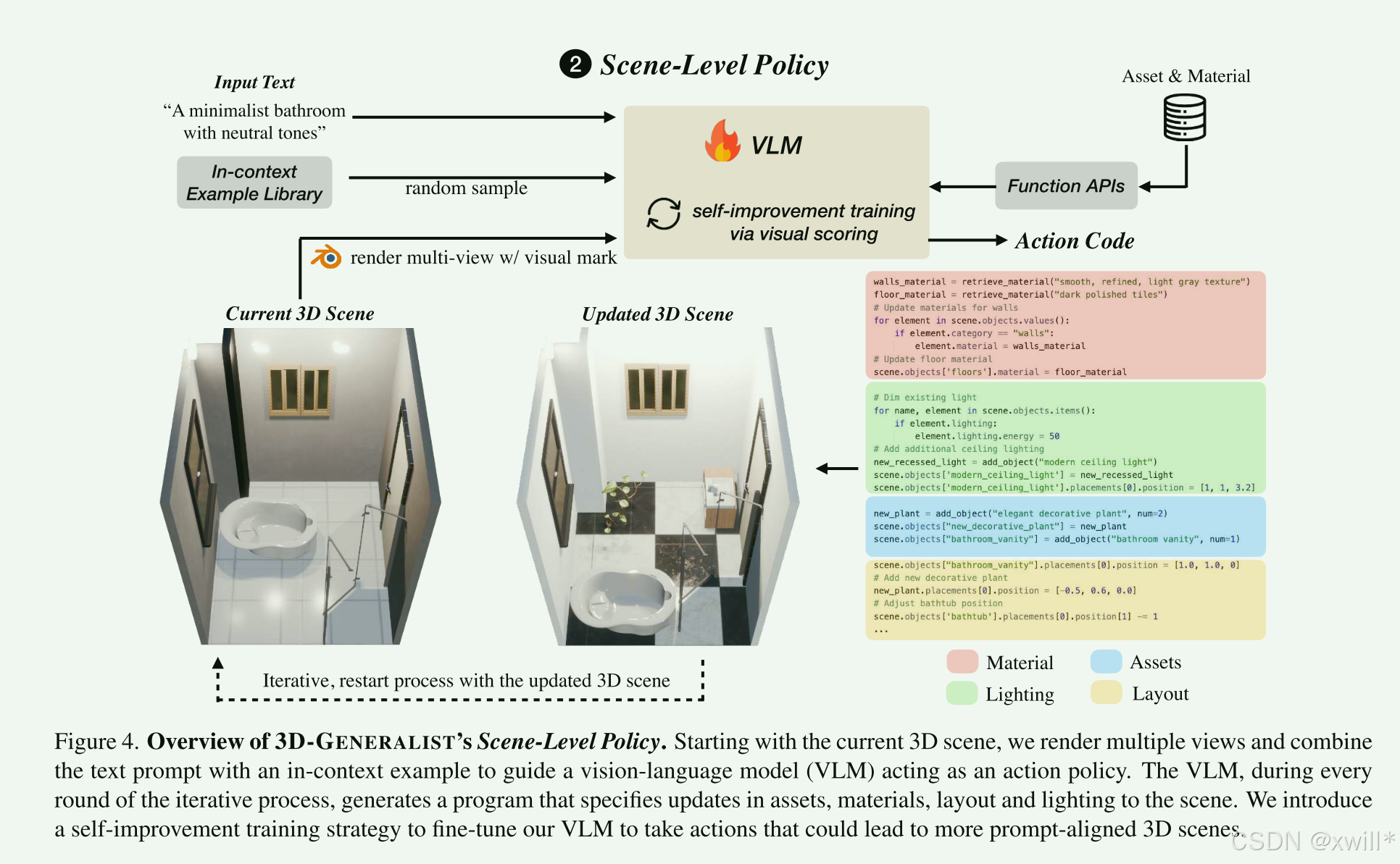
(2)场景级策略 (The Interior Designer),框架建好了之后,就需要进行细节的装饰。也就是放家具,贴壁纸,灯光等问题。由于现在的模型直接生成的3D物体经常有破损(伪影),或者不符合物理规律。因此不适合直接用模型生成。作者提出了检索+编程的方案:
-
作者有一个巨大的、高质量的3D模型库(桌子、椅子、灯)。
-
VLM(GPT-4o)充当设计师。它看着 现在的房间(输入图片),然后写代码(输出Action Code)来指挥系统。
-
比如代码写道:add_object(type="sofa", material="leather", pos=2,0,1)。系统就会去库里找个皮沙发放在那里。
这是一个不断调整的过程。放置 -> 拍照给模型看 -> 模型觉得"沙发歪了" -> 写代码调整 -> 再拍照给模型看 -> 满意为止 。 作者专门采用了一套简单的编程语言(DSL (领域特定语言)),让模型更容易操纵3D物体的位置、旋转和材质。
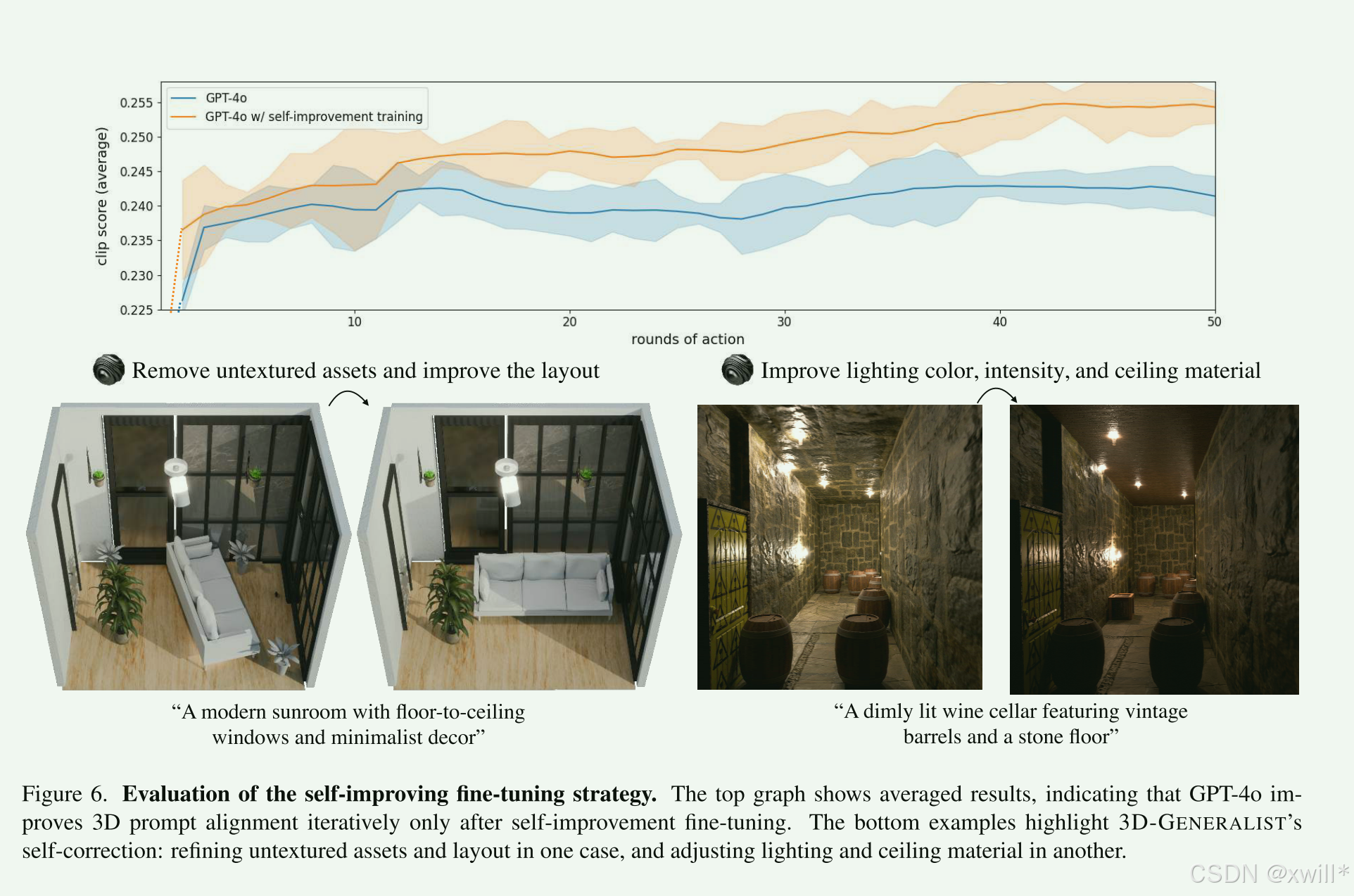
(3)自我改进微调 (The Tr模型ning Strategy),直接用GPT-4o,它可能写出的代码跑不通,或者摆放的位置很丑。因此采用让模型自己跟自己下棋(Self-Correction)的方式。
-
出题: 给模型一个提示词(如"一个温馨的卧室")。
-
尝试: 模型尝试生成好几种不同的摆放方案(动作序列)。
-
打分: 用 CLIP模型(一种能判断图片和文字是否相符的模型)来做裁判。看哪一种方案生成的图片最符合"温馨的卧室"。
-
学习: 把得分最高的那个方案当作"标准答案",拿回去训练模型。
-
进化: 训练完的模型(π(i+1)π(i+1))水平提高了,再让它去生成新的数据,周而复始。
作者在实验的过程中发现,如果预先给模型看一些高质量的代码范例(小抄),模型能生成出更多样化、更高分的结果。
(4)VLM as a Placement Policy
作者在这里把 3D 生成看作一个时间序列上的循环过程。
S0**(Initial State - 初始状态):**这是开始时的样子。也就是上一节提到的"全景环境生成"弄出来的那个只有墙壁、地板、门窗的空房间(毛坯房)。
St **(Current State - 当前状态):**这是第 t回合时,房间的样子。比如第1回合它是空的,第5回合可能已经放了一张床。
P **(Prompt - 任务目标):**这是指令,比如:"设计一个温馨的、有阳光的北欧风卧室"。这贯穿全程,是模型的终极目标。
It **(Observation - 观察):**模型看不见 St的 3D 数据(网格、顶点),它只能像人一样看"照片"。因此,系统把 St从不同角度拍成一组照片(多视角图像),这就是 It。模型通过看这些照片来理解现在的房间长什么样。
πθ **(Policy - 策略/大脑):**是 GPT-4o。θ 代表它的参数(它的知识)。输入是 It(现在的样子)和 P(目标)。输出是 at(下一步该干嘛)。
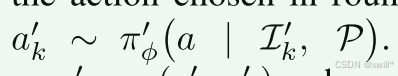
在当前看到了照片 It,并且心里想着目标 P的情况下,大脑 πθ 决定执行动作 at。
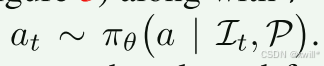
这里的 at不是一个简单的坐标数字,而是一段Python代码(此操作代码使用公开的工具和功能api(例如基于自然语言检索资产或材料的工具和功能api)执行)。
-
例如:scene.add_object(model="lamp", pos=1, 2, 0) 或 light.set_intensity(50)。
-
使用代码不仅能操作位置,还能操作逻辑(比如循环生成一排椅子)和属性(颜色、亮度),比单纯预测坐标要强大得多。
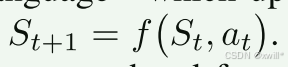
执行与更新 (Execution & Update):这是一个状态转移方程。f 是环境/渲染引擎(比如 Blender 或 Unity)。它接收当前的房间 St,运行模型写出来的代码 at。运行结果就是房间变样了,变成了新的状态 St+1
之后循环闭环(The Loop):房间变样后,系统再重新拍一组照片 It+1,交给 模型进行下一轮决策。
2 资产级策略 (Asset-Level Policy)
在"场景级策略"中使用的 VLM 策略通常会忽略较小的物体(例如书籍、盘子、餐具),而专注于更大且更能定义环境特征的资产 。相比之下,放置小资产需要不同的设计方法,以确保极强的物理合理性 (physical plausibility)。针对这个问题,作者引入了 资产级策略 ,它通过将小资产与"容器对象"(receptacle objects,例如架子、桌子、柜台)进行组合来细化环境,这紧密模仿了物理环境的构建过程。
为什么要单独搞一个"资产级策略"?
大模型的弱点: GPT-4o 这种大模型虽然懂"这里应该有个桌子",但它很难精确控制"把杯子放在桌子右上角那个点上"。
物理合理性: 小物体乱放很容易穿模(比如书一半陷在桌子里)或者悬空。大件家具稍微偏一点没关系,但杯子悬空就很假。
嵌套关系(Stacking): 真实世界是"套娃"的------桌子上有盘子,盘子里有苹果。这种**递归(Recursive)**关系需要特殊的处理。
容器对象 (Receptacle Object)
首先,系统得知道哪些东西能放东西。
GPT-4o 先判断:桌子?是容器。床?是容器。台灯?不是容器。只有被认定为"容器"的物体,才会进入这个精细放置的流程。
2.1具体流程 (Step-by-Step)
第一步:找平地 (Surface Detection) 系统通过算法扫描3D模型,找到所有平整的、朝上的面。这保证了东西是放在面上的,而不是挂在墙上的。它不仅找桌面的平地,还找已经放上去的物体的平地。这意味着可以在书上放笔。
第二步:换个模型 (Switching Models)
-
场景级策略用的是 GPT-4o(擅长理解语义,比如"哪里该放沙发")。
-
资产级策略 用的是一个特定的预训练VLM 12(擅长像素定位 ,即"指哪里打哪里")。因为需要极高的精度,直接在图片上点出 (x,y)坐标,告诉系统东西放哪。
第三步:随机抓拍 (Random Camera Sampling) 系统会围着桌子转圈拍照。采用随机角度是为了看到不同的角落,防止死角,把桌子的每个地方都利用起来。
第四步:射线投射 (Ray Casting) 模型在图片上点了一个点(2D像素)。系统从相机位置发射一条射线(Ray),打到3D模型上,算出那个点在3D空间中的精确坐标 (x,y,z)。
第五步:物理安检 (Physics Verification) 在真正把东西放上去之前,先做检查:
-
会不会和别的物体撞车(Collision Check)?
-
是不是悬空了?
-
这个验证器是插件式的,以后还可以加更复杂的物理引擎(比如重力模拟)。
三:实验
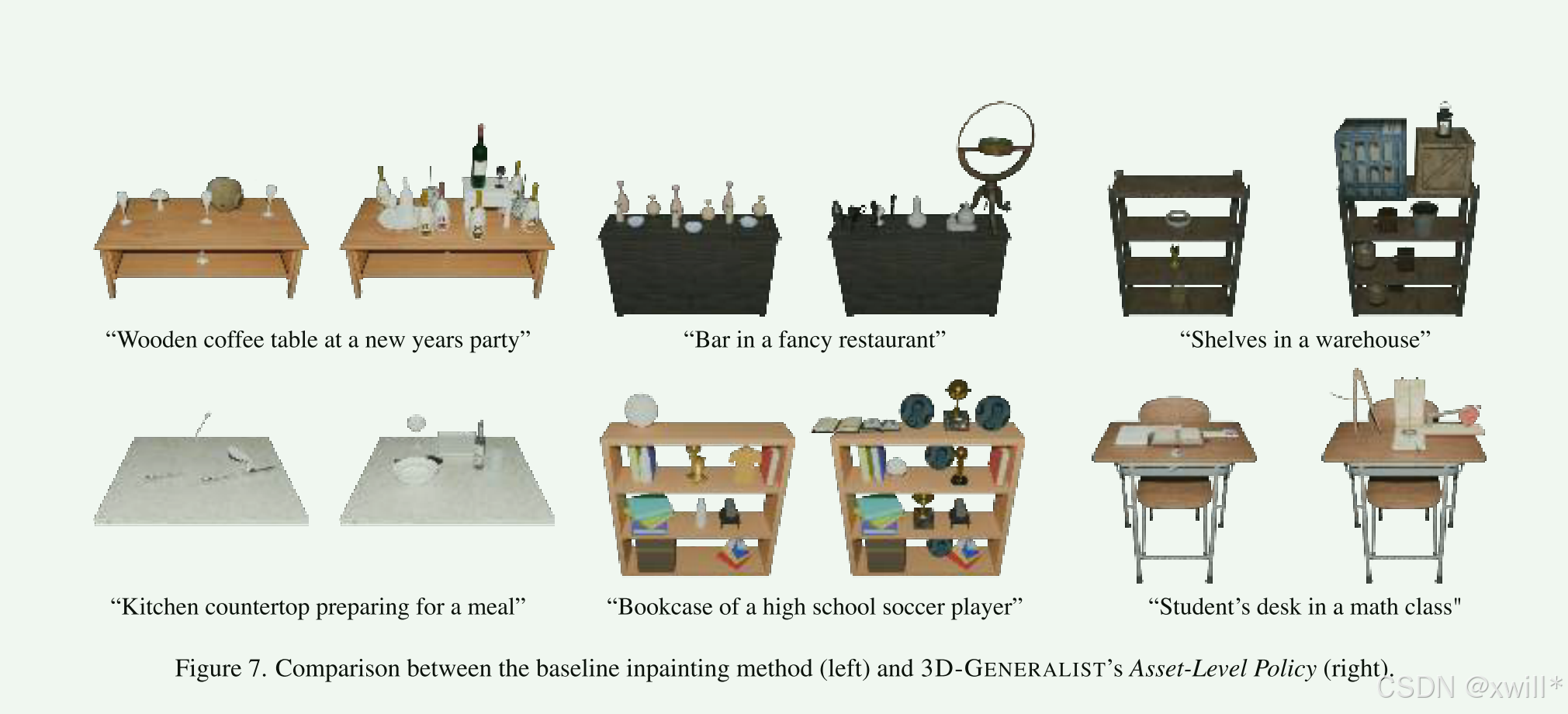
怎么看这张图感觉并不好呢,生成的哦电脑关系太多了,例如 数学课堂上的学生桌
我们要评估 3D-GENERALIST,其实验旨在回答以下问题:
(a) 与现有方法的对比: 在生成可用于模拟的(simulation-ready)3D 环境方面,3D-GENERALIST 与现有方法相比表现如何?
(b) 自我改进微调的有效性: 我们提出的自我改进微调策略(self-improvement fine-tuning strategy) 是否使**场景级策略(Scene-Level Policy)**能够迭代地细化 3D 环境,使其更符合提示词(prompt-aligned)?
(c) 资产级策略的有效性: 我们提出的**资产级策略(Asset-Level Policy)**能否以语义连贯的方式有效地放置小物体?
(d) 大规模数据生成的扩展性与应用: 我们的方法能否实现 3D 数据生成的有效扩展,从而训练出鲁棒的视觉特征提取器(visual feature extractors)?
鉴于 3D-GENERALIST 的迭代性质,以及我们在实验 (d) 中生成大规模数据集以渲染超过 1000 万张图像的目标,我们做出了特定的设计选择(见补充材料),以保持在可行的时间和计算预算之内。
四:总结
本文的主要贡献状态转移范式 ( St→at→St+1**)** 。这区别于传统的端到端(End-to-End)生成。正是这种序列化的特性,使得该框架具有极强的模块化能力,为下文提到的扩展性打下了基础。
- 框架的模块化与扩展性 (Modularity & Extensibility)
主要使用检索(Retrieval) 的方式来获取资产(即从数据库里找现成的模型)。目前的做法: VLM 决定"放一把椅子" →从数据库检索一个椅子模型。
未来的可能的方向: VLM 决定"放一把椅子" →调用一个 3D 生成模型(如 LRM 或 Meshy)现场生成一个独一无二的椅子。这将把系统从"组装(Assembly)"升级为"全生成(Fully Generative)",摆脱对预制资产库的依赖。
3. 显式表示的价值 (Value of Explicit Representations)
显式 3D 表示: 指网格(Mesh)、纹理、物理碰撞体等传统图形学格式。只有这种格式,机器人(RL Policy)才能在里面进行交互训练(比如练习开门、拿杯子)。如果是 NeRF,机器人是无法物理接触物体的。这强调了该框架在机器人学习领域的应用价值。
4. 局限性与未来方向 (Limitations & Future Work)
现在的模型可能更关注"视觉对齐"(看起来像个厨房),但可能缺乏"功能逻辑"。例如模型可能会把马桶放在厨房旁边,或者把门被柜子挡住。虽然视觉上都有这些东西,但在建筑学和使用逻辑上是不合理的。
未来的研究不仅要看 CLIP Score(图文匹配度),还要引入功能性指标 或常识推理,确保生成的空间在逻辑上是可居住、可使用的。
"状态转移范式"在这里就是指把"生成一个结果"变成了"玩一个回合制游戏"。模型是玩家,3D 环境是游戏棋盘,每一步操作都会改变棋盘的局势(状态)。