RMT:当Retentive遇见ViT------一个具有显式空间先验的强大视觉骨干
论文信息
论文题目:RMT: Retentive Networks Meet Vision Transformers(RMT:Retentive网络与视觉变压器相遇)
会议:CVPR2024
摘要:视觉变压器(Vision Transformer, ViT)近年来在计算机视觉界受到越来越多的关注。然而,ViT的核心成分自注意缺乏明确的空间先验,且计算复杂度为二次,制约了ViT的适用性。为了缓解这些问题,我们从NLP领域最近的RetNet (retention Network)中获得灵感,提出了RMT,一种具有明确空间先验的通用强视觉主干。具体而言,我们将RetNet的时间衰减机制扩展到空间域,并提出了一个基于曼哈顿距离的空间衰减矩阵,以引入显式空间优先于自我注意。此外,提出了一种适应显式空间先验的注意力分解形式,目的是在不破坏空间衰减矩阵的情况下减少建模全局信息的计算负担。基于空间衰减矩阵和注意分解形式,可以将显式空间先验灵活地集成到具有线性复杂度的视觉主干中。大量的实验表明,RMT在各种视觉任务中表现出优异的性能。具体来说,在没有额外训练数据的情况下,RMT在ImageNet-1k上分别以27M/4.5GFLOPs和96M/18.2GFLOPs分别达到了84.8%和86.1%的top-1 acc。对于下游任务,RMT在COCO检测任务上实现了54.5盒AP和47.2掩码AP,在ADE20K语义分割任务上实现了52.8 mIoU。
引言
Vision Transformer (ViT) 自诞生以来在计算机视觉领域引起了广泛关注,但其核心组件Self-Attention存在两个关键问题:缺乏显式的空间先验 和二次计算复杂度。这些问题限制了ViT在实际应用中的效果和效率。
核心创新:从时间衰减到空间衰减
RetNet的启发
RetNet在NLP领域取得成功的关键在于其距离相关的时间衰减矩阵,为一维单向文本数据提供了显式的时间先验。具体来说,RetNet使用以下形式:
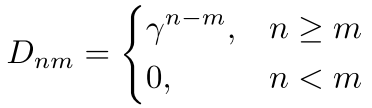
其中γ是衰减参数,n-m表示token间的时间距离。
空间衰减矩阵的设计

RMT的核心创新是将RetNet的时间衰减扩展到二维双向空间衰减 。研究团队设计了基于曼哈顿距离的空间衰减矩阵:

这里:
(x_n, y_n)和(x_m, y_m)分别是第n个和第m个token的二维坐标|x_n-x_m|+|y_n-y_m|是两个token间的曼哈顿距离- γ是衰减参数,控制距离衰减的强度
Manhattan Self-Attention (MaSA)
基于空间衰减矩阵,研究团队提出了Manhattan Self-Attention:
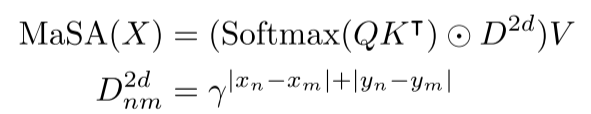
其中⊙表示元素级乘法。这种设计使得:
- 距离越远的token,注意力权重衰减越大
- 模型能感知全局信息,同时对不同距离的token给予不同程度的关注
- 显式引入了丰富的空间先验
解决计算复杂度:注意力分解
虽然MaSA引入了有效的空间先验,但在早期阶段处理大量token时仍面临计算复杂度问题。现有的稀疏注意力机制会破坏空间衰减矩阵,不适合MaSA。
研究团队提出了一种巧妙的分解方法,将Self-Attention沿图像的两个轴进行分解:
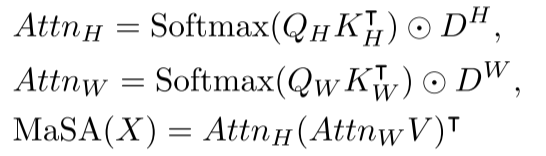
这种分解具有以下优势:
- 线性复杂度:将全局建模的复杂度从二次降低到线性
- 保持感受野形状:分解后的感受野与原始MaSA完全相同
- 无信息损失:完全保留了空间先验信息
RMT架构设计
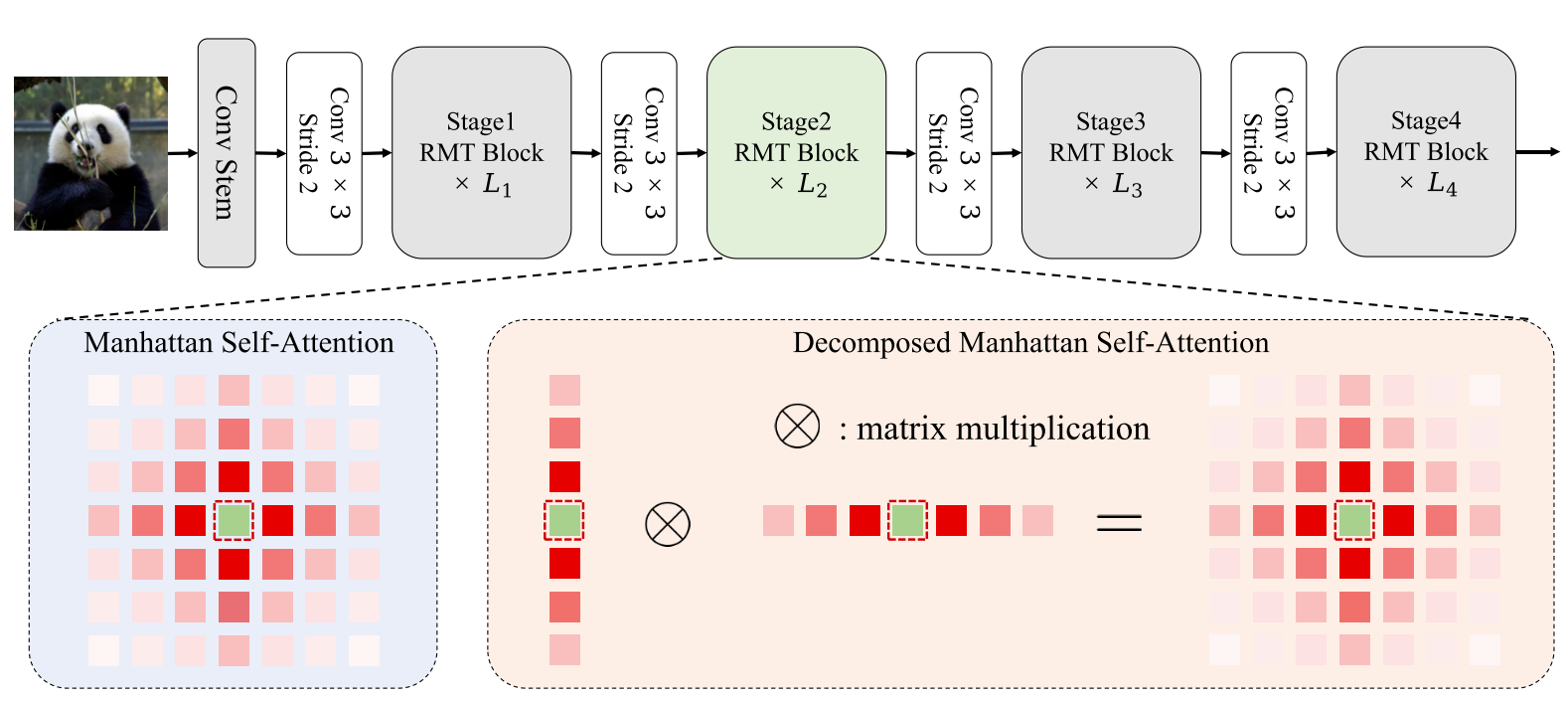
RMT采用了四阶段的层次化架构:
- 前三个阶段:使用分解的MaSA以降低计算成本
- 最后一个阶段:使用原始MaSA以充分利用空间先验
- 增强模块:引入Local Context Enhancement (LCE)模块增强局部表达能力
实验验证
图像分类性能(ImageNet-1K)
RMT在图像分类任务上取得了优异的性能:
| 模型 | 参数量 | FLOPs | Top-1准确率 |
|---|---|---|---|
| RMT-S | 27M | 4.5G | 84.1% |
| RMT-S* | 27M | 4.5G | 84.8% |
| RMT-B | 54M | 9.7G | 85.0% |
| RMT-L | 95M | 18.2G | 85.5% |
| RMT-L* | 96M | 18.2G | 86.1% |
(*表示使用token labeling训练)
目标检测与实例分割(COCO)
在COCO数据集上,RMT表现出色:
- Mask R-CNN框架:RMT-L达到51.6 box AP和45.9 mask AP
- Cascade Mask R-CNN:RMT-B达到54.5 box AP和47.2 mask AP
语义分割(ADE20K)
在ADE20K数据集上:
- UperNet框架:RMT-L达到52.8 mIoU
- Semantic FPN:RMT-L达到51.4 mIoU
消融实验与分析
为什么MaSA有效?
研究团队通过逐步改进实验发现:
- 分解形式的全局感知:用分解的Self-Attention替换Swin的窗口注意力,性能提升来自全局感知能力
- 衰减矩阵引入局部偏置:通过适当的衰减率引入局部偏置是有益的
- 多尺度衰减率:为每个注意力头分配不同的衰减率,引入多尺度局部偏置,进一步提升性能
关键组件分析
| 组件 | 作用 | 性能提升 |
|---|---|---|
| MaSA | 核心空间先验机制 | +0.8% |
| LCE | 局部上下文增强 | +0.3% |
| CPE | 条件位置编码 | 提供灵活的位置信息 |
| 卷积stem | 提供更好的局部信息 | 增强各任务性能 |
推理速度对比
RMT在准确率和推理速度之间实现了最佳平衡:
| 模型 | 参数量 | FLOPs | 吞吐量(imgs/s) | Top-1准确率 |
|---|---|---|---|---|
| RMT-T | 14M | 2.5G | 1650 | 82.4% |
| RMT-S | 27M | 4.5G | 876 | 84.1% |
| RMT-B | 54M | 9.7G | 457 | 85.0% |
技术优势总结
1. 显式空间先验
- 基于曼哈顿距离的空间衰减矩阵
- 为不同距离的token提供不同的注意力权重
- 比其他Self-Attention机制引入更丰富的空间先验
2. 线性复杂度
- 巧妙的注意力分解方法
- 在不破坏空间先验的前提下实现线性复杂度
- 保持与原始MaSA相同的感受野形状
3. 通用性强
- 可嵌入任意现有的视觉Transformer架构
- 在分类、检测、分割等多个任务上都表现优异
- 提供了良好的准确率-效率权衡
总结与意义
RMT通过将NLP领域的时间衰减机制创新性地扩展到视觉领域,提出了基于曼哈顿距离的空间衰减矩阵,成功为视觉Transformer引入了显式的空间先验。同时,通过巧妙的注意力分解设计,在保持空间先验信息的同时实现了线性计算复杂度。
这项工作的意义在于:
- 理论贡献:开创性地将RetNet的思想引入计算机视觉,为视觉Transformer的设计提供了新思路
- 实用价值:在多个视觉任务上都取得了SOTA性能,证明了方法的有效性
- 跨领域创新:展示了NLP和CV领域技术融合的巨大潜力
RMT为视觉Transformer的进一步发展开辟了新的道路,其显式空间先验的设计思想值得后续研究深入探索。