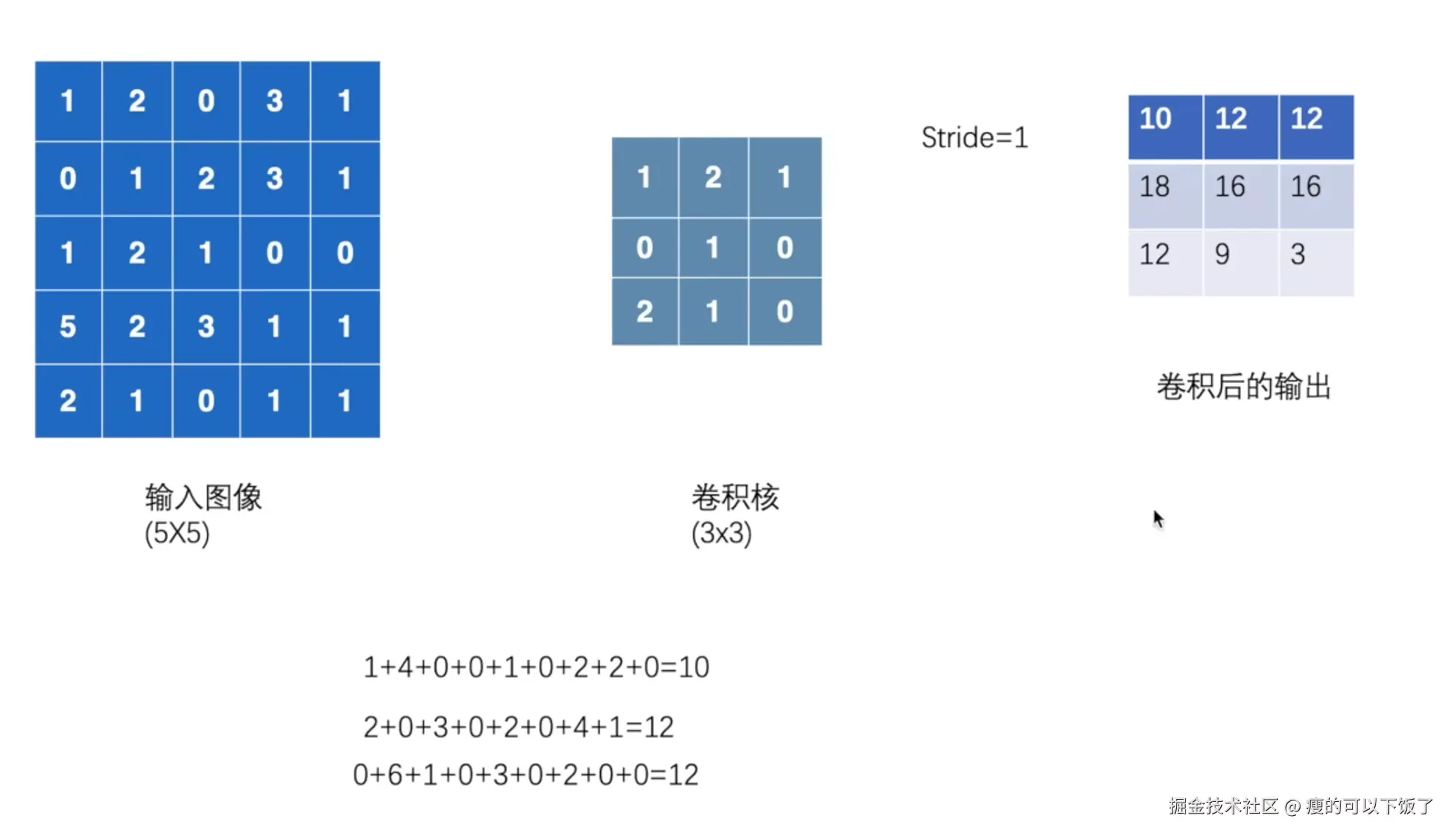
一、卷积操作
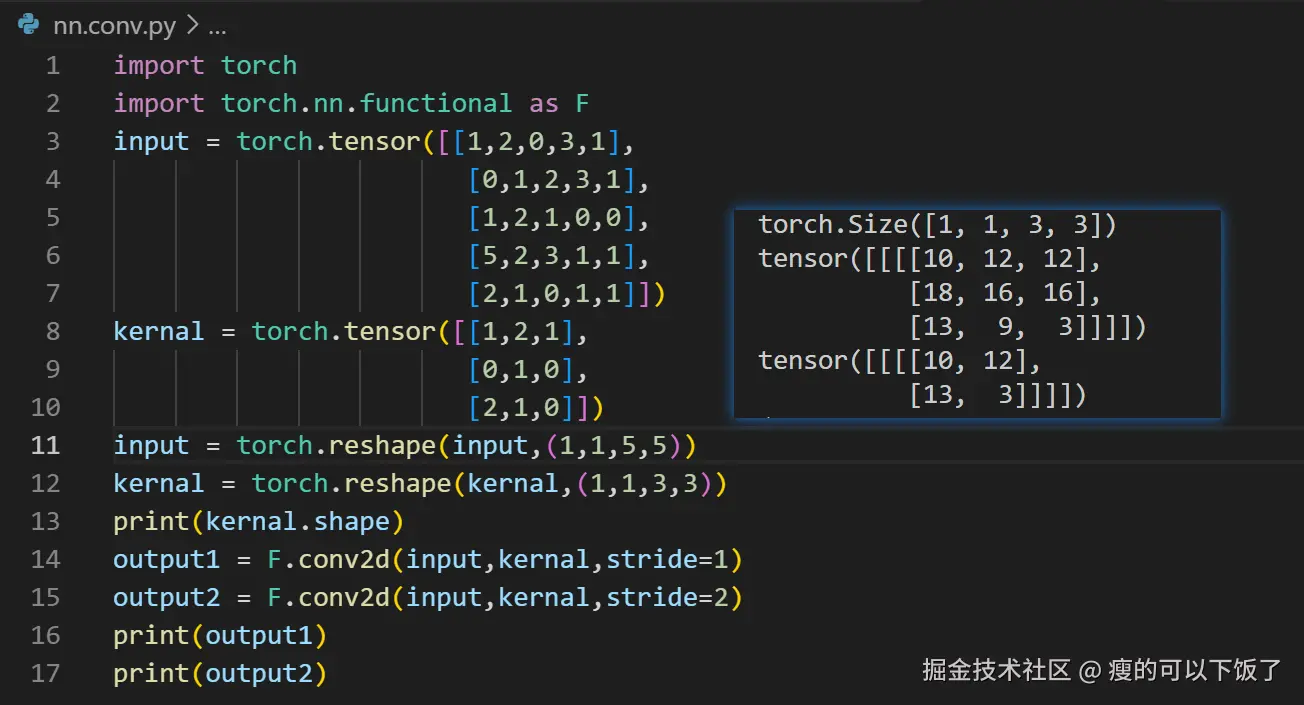
代码实现
Conv2d 参数解析
-
输入参数
input:- 输入张量的形状为
(minibatch, in_channels, iH, iW),其中minibatch是批次大小,in_channels是输入图像的通道数,iH和iW是图像的高度和宽度。
- 输入张量的形状为
-
权重参数
weight:- 卷积核/滤波器的形状为
(out_channels, in_channels/groups, kH, kW),out_channels是输出特征图通道数量,kH和kW是卷积核的高度和宽度,groups用于控制输入与输出的连接方式。
- 卷积核/滤波器的形状为
-
偏置参数
bias:- 是一个可选的张量,形状为
(out_channels),表示为输出特征图每一通道的偏置,默认值为None。
- 是一个可选的张量,形状为
-
步幅
stride:- 定义卷积核在输入上进行滑动步长,参数可以是单个数字或二元元组
(sH, sW),默认值为1,即每次移动一步。
- 定义卷积核在输入上进行滑动步长,参数可以是单个数字或二元元组
-
填充
padding:- 表示在输入的两边添加的像素数,参数可以是单个数字或二元元组
(padH, padW),默认值为0。填充有助于在进行卷积操作时保留输入的空间维度。
- 表示在输入的两边添加的像素数,参数可以是单个数字或二元元组
-
扩展
dilation:- 卷积核中元素的间隔,参数可以是单个数字或二元元组
(dH, dV),默认值为1。扩展卷积有助于增加感受野而不增加参数量。
- 卷积核中元素的间隔,参数可以是单个数字或二元元组
-
分组
groups:- 控制输入和输出之间的连接分组数,
in_channels应该被groups整除。默认值为1,表示全连接。更高的分组数可以减少每组之间的连接数,提高计算效率。
- 控制输入和输出之间的连接分组数,
重要性及使用
-
维度匹配:
- 为了保证卷积操作的正确执行,输入张量形状、卷积核形状、步幅、填充及输出特征图都需要在维度上适配。
-
灵活性:
- 通过调整
stride、padding和dilation可以自定义卷积层的感受野和输出尺寸,适应不同规模的输入数据。
- 通过调整
-
性能优化:
- 参数
groups可以用于实现深度可分离卷积(Depthwise Separable Convolutions),提高卷积操作的计算效率。
- 参数
二、 卷积层

Conv2d 类介绍
Conv2d 类通常用于深度学习框架(如 PyTorch 和 TensorFlow)以实现二维卷积层,其作用是对输入的二维数据应用卷积操作。
基本功能
-
卷积操作:
- Conv2d 实现了卷积神经网络(CNNs)中的基本卷积层,对输入的多通道特征图进行卷积运算。
-
特征提取:
- 通过卷积核(或称过滤器)扫描输入图像,可以提取出特定模式的特征,例如边缘、角点等。
常用参数
-
in_channels:
- 输入的通道数,例如,对于RGB图像,该值为3。
-
out_channels:
- 输出的通道数,即卷积核的数量。这个参数决定了输出特征图的深度。
-
kernel_size:
- 卷积核的大小,可以是单个整数或二元组。例如,
kernel_size=3表示使用 3x3 的卷积核。
- 卷积核的大小,可以是单个整数或二元组。例如,
-
stride:
- 步长,卷积核在每个方向上滑动的步幅大小。默认为1。
-
padding:
- 填充,决定了在输入特征图的边界补零的数量,用于控制输出的空间尺寸。
-
dilation:
- 空洞卷积的参数,用于控制卷积核元素之间的间距。
-
groups:
- 连接的卷积组数,允许对输入通道和输出通道进行分组卷积。
-
bias:
- 是否包含偏置项,默认为 True,表示每个卷积核的输出都加上一个偏置。
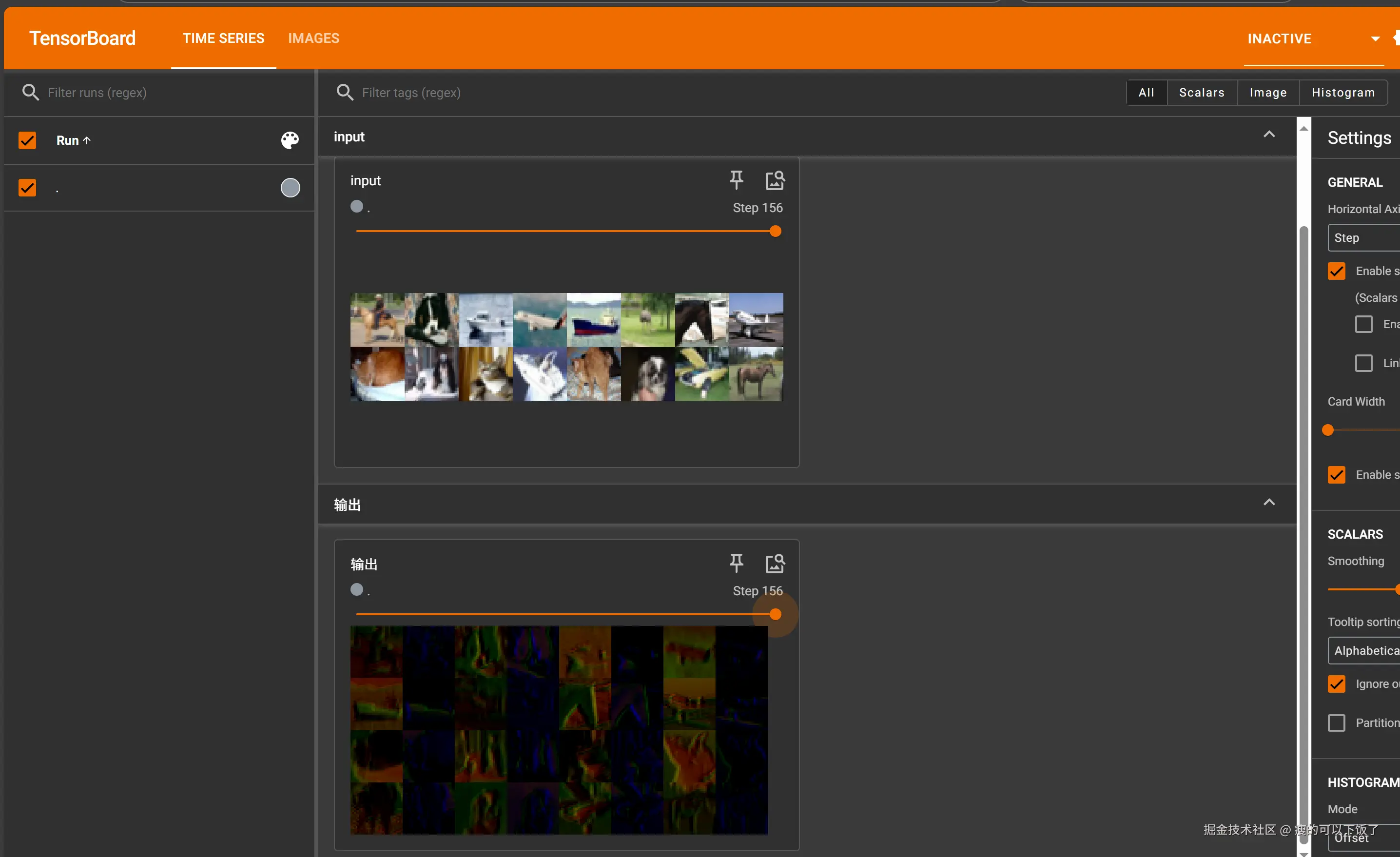
三、实操
python
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 下载CIFAR-10数据集并转换为Tensor格式,存储在指定路径中。
dataset = torchvision.datasets.CIFAR10("./cifar-10", train=False, transform=torchvision.transforms.ToTensor(), download=True)
# 创建DataLoader,用于批量加载数据。这里的批量大小为64。
dataloader = DataLoader(dataset, batch_size=64)
# 定义一个简单的卷积神经网络模型Xzx。
class Xzx(nn.Module):
def __init__(self):
super(Xzx, self).__init__()
# 添加一个二维卷积层,从输入的3个通道(RGB图像)变为输出的6个通道。
# 使用3x3的卷积核,步长为1,边界不填充(padding=0)。
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
# 定义前向传播过程,输入x经过卷积层conv1。
x = self.conv1(x)
return x
# 实例化模型
xzx = Xzx()
# 创建TensorBoard的SummaryWriter,指定记录日志的目录为"logs"。
writer = SummaryWriter("logs")
# 初始化步骤计数器
step = 0
# 遍历DataLoader,处理每个批次的数据
for data in dataloader:
# 从DataLoader中获取批量数据,其中包含图像和对应的目标标签
imgs, targets = data
# 通过卷积神经网络前向传播获取输出
output = xzx(imgs)
# 打印输入和输出的形状以进行验证
print(imgs.shape) # torch.Size([64, 3, 32, 32])
print(output.shape) # torch.Size([64, 6, 30, 30])
# 将输入图像写入TensorBoard记录,标签为"input"
writer.add_images("input", imgs, step)
# 对卷积层的输出进行重新塑性以使得它能作为图像记录到TensorBoard。
# 这里将输出的形状变为(-1, 3, 30, 30),即重新调整为具有3个通道的图像。
output = torch.reshape(output, (-1, 3, 30, 30))
# 将重新塑性的输出图像写入TensorBoard记录,标签为"输出"
writer.add_images("输出", output, step)
# 增加步骤计数器
step = step + 1
# 关闭SummaryWriter以释放资源
writer.close()截图: