elk快速部署、集成、调优
1.部署
1.1 docker部署
参考:https://blog.csdn.net/taotao_guiwang/article/details/135508643

1.2 elk部署
-
资源见,百度网盘:https://pan.baidu.com/s/1qlabJ7m8BDm77GbDuHmbNQ?pwd=41ac
-
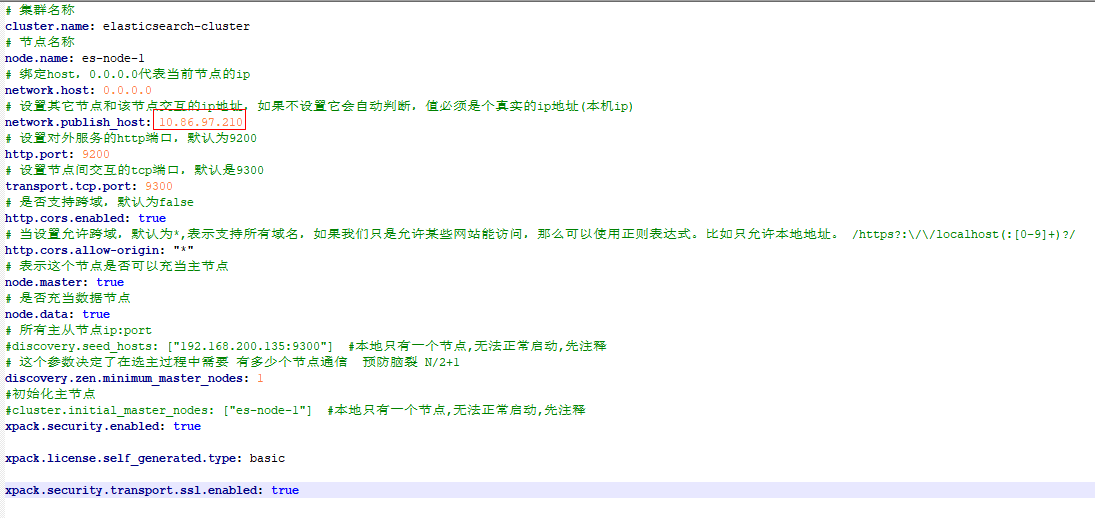
修改elasticsearch.yml,将IP修改为实际IP:
-
执行elk_install.sh,开始部署:
powershell
# 赋权,在elk_install目录,执行:
chmod -R 777 .
# 执行
./elk_install.sh.sh- 安装分词器
powershell
# 默认安装在/home/install/elk
docker cp /home/install/elk/elasticsearch-analysis-ik-7.17.3.zip elasticsearch:/
# 进入容器,执行以下命令,然后重启容器
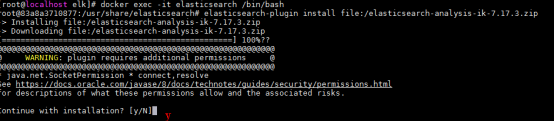
docker exec -it elasticsearch bash
elasticsearch-plugin install file:/elasticsearch-analysis-ik-7.17.3.zip出现如图所示页面输入 y
powershell
# 在容器内执行
bin/elasticsearch-setup-passwords interactive
# 设置密码为:test@123456(PS:不建议修改为其他密码,因为配置文件里配的都是这个密码)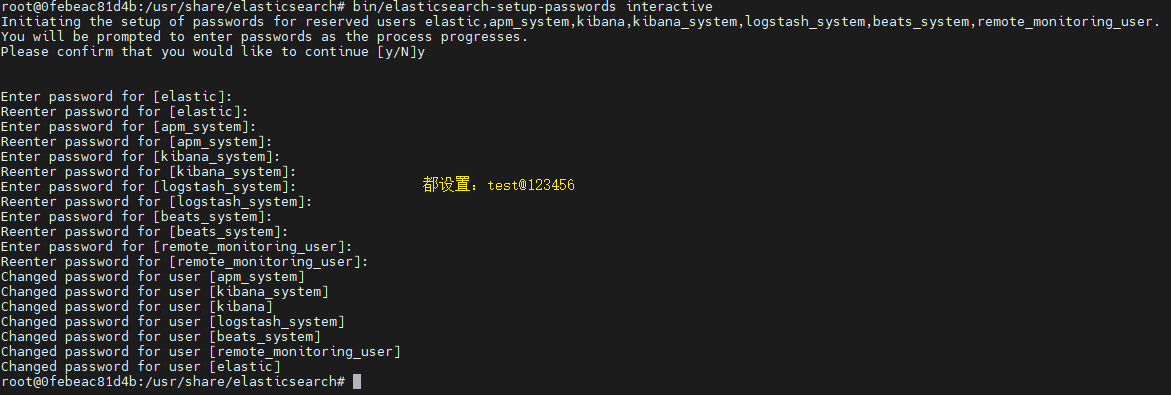
powershell
# 退出容器:
exit
# 重启容器:
docker restart elasticsearch logstash kibanaelastic访问地址:
账号:elastic
密码:test@123456
kibana访问地址:
账号:elastic
密码:test@123456
2. spring boot集成
2.1 创建索引
- 转到,kibana:Management->开发工具:
- 执行:
java
PUT blog
{
"mappings": {
"properties": {
"id":{
"type":"long"
},
"title": {
"type": "text"
},
"content": {
"type": "text"
},
"author":{
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"category":{
"type": "keyword"
},
"createTime": {
"type": "date",
"format":"yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"updateTime": {
"type": "date",
"format":"yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd'T'HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss||epoch_millis"
},
"status":{
"type":"integer"
},
"serialNum": {
"type": "keyword"
}
}
}
}-
执行效果:
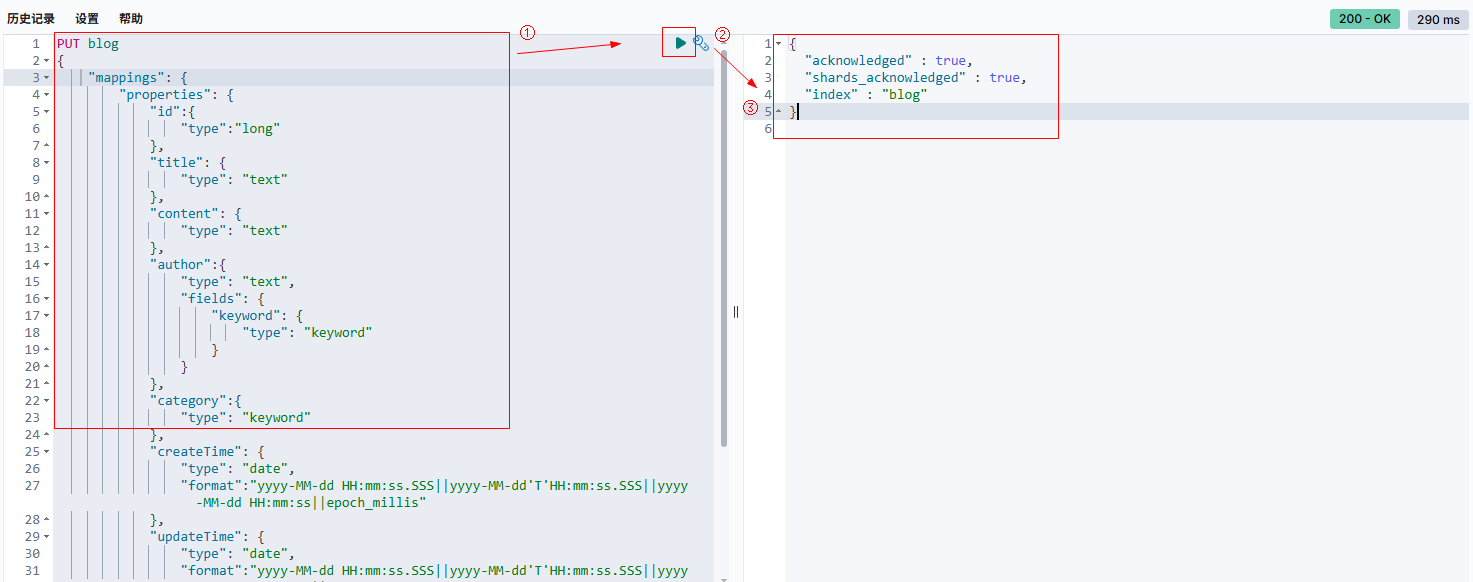
-
查看blog信息:
powershell
GET /blog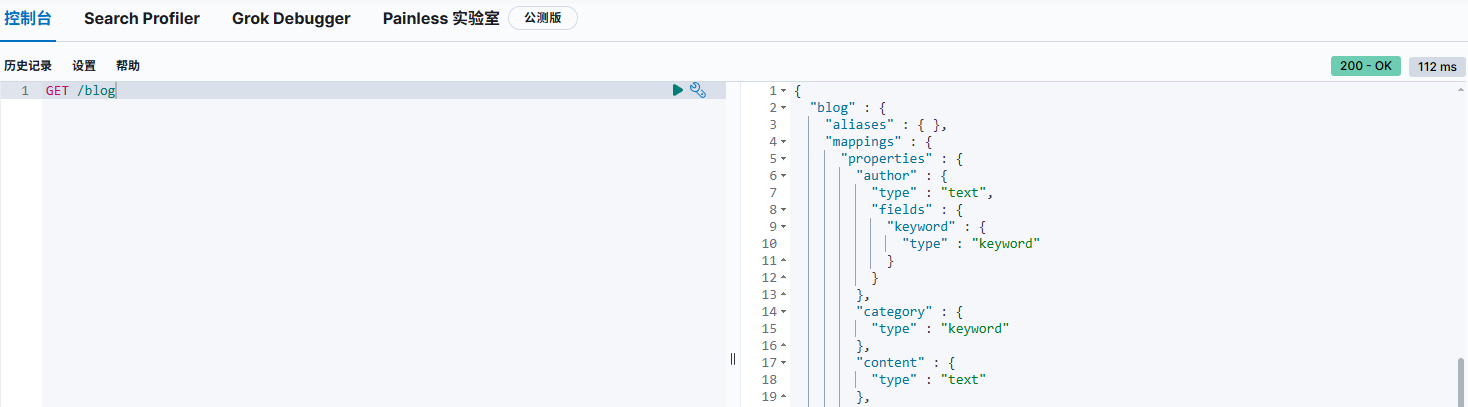
2.2 构造数据
- 数据,每个文档必须独占一行,不能换行:
java
{"index":{"_index":"blog","_id":1}}
{"blogId":1,"title":"Spring Data ElasticSearch学习教程1","content":"这是批量添加的文档1","author":"Iron Man","category":"ElasticSearch","status":1,"serialNum":"1","createTime":"2021-10-10 11:52:01.249","updateTime":null}
{"index":{"_index":"blog","_id":2}}
{"blogId":2,"title":"Spring Data ElasticSearch学习教程2","content":"这是批量添加的文档2","author":"Iron Man","category":"ElasticSearch","status":1,"serialNum":"2","createTime":"2021-10-10 11:52:02.249","updateTime":null}
{"index":{"_index":"blog","_id":3}}
{"blogId":3,"title":"Spring Data ElasticSearch学习教程3","content":"这是批量添加的文档3","author":"Captain America","category":"ElasticSearch","status":1,"serialNum":"3","createTime":"2021-10-10 11:52:03.249","updateTime":null}
{"index":{"_index":"blog","_id":4}}
{"blogId":4,"title":"Spring Data ElasticSearch学习教程4","content":"这是批量添加的文档4","author":"Captain America","category":"ElasticSearch","status":1,"serialNum":"4","createTime":"2021-10-10 11:52:04.249","updateTime":null}
{"index":{"_index":"blog","_id":5}}
{"blogId":5,"title":"Spring Data ElasticSearch学习教程5","content":"这是批量添加的文档5","author":"Spider Man","category":"ElasticSearch","status":1,"serialNum":"5","createTime":"2021-10-10 11:52:05.249","updateTime":null}
{"index":{"_index":"blog","_id":6}}
{"blogId":6,"title":"Java学习教程6","content":"这是批量添加的文档6","author":"Spider Man","category":"ElasticSearch","status":1,"serialNum":"6","createTime":"2021-10-10 11:52:06.249","updateTime":null}
{"index":{"_index":"blog","_id":7}}
{"blogId":7,"title":"Java学习教程7","content":"这是批量添加的文档7","author":"Iron Man","category":"ElasticSearch","status":1,"serialNum":"7","createTime":"2021-10-10 11:52:07.249","updateTime":null}
{"index":{"_index":"blog","_id":8}}
{"blogId":8,"title":"Java学习教程8","content":"这是批量添加的文档8","author":"Iron Man","category":"ElasticSearch","status":1,"serialNum":"8","createTime":"2021-10-10 11:52:08.249","updateTime":null}
{"index":{"_index":"blog","_id":9}}
{"blogId":9,"title":"Java学习教程9","content":"这是批量添加的文档9","author":"Captain America","category":"ElasticSearch","status":1,"serialNum":"9","createTime":"2021-10-10 11:52:09.249","updateTime":null}
{"index":{"_index":"blog","_id":10}}
{"blogId":10,"title":"Java学习教程10","content":"这是批量添加的文档10","author":"God Of Thunder","category":"ElasticSearch","status":1,"serialNum":"10","createTime":"2021-10-10 11:52:10.249","updateTime":null}
- 执行效果:
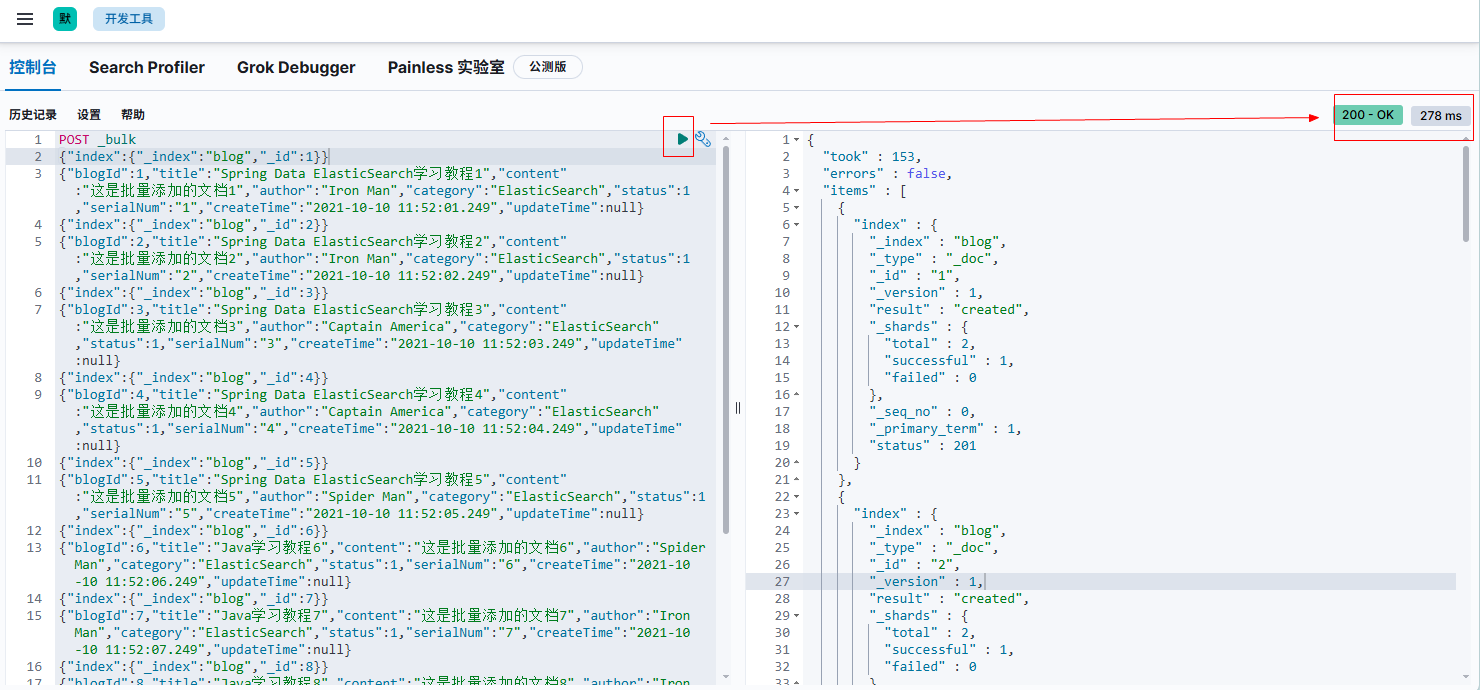
- 查询数据:
java
GET /blog/_search
{
"query": {
"match_all": {}
}
}2.3 核心代码
2.3.1 常见操作
包括:添加单个文档、添加多个文档、修改单个文档数据、修改单个文档部分数据、修改多个文档部分数据、查看单个文档、删除单个文档(根据id)、删除单个文档(根据条件)、删除所有文档。
java
package com.elk;
import com.elk.entity.Blog;
import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.document.Document;
import org.springframework.data.elasticsearch.core.mapping.IndexCoordinates;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.elasticsearch.core.query.UpdateQuery;
import org.springframework.data.elasticsearch.core.query.UpdateResponse;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
//增删改查(RestTemplate方式)
@RestController
@RequestMapping("crudViaRestTemplate")
public class CrudViaRestTemplateController {
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@PostMapping("addDocument")
public Blog addDocument() {
Long id = 1L;
Blog blog = new Blog();
blog.setBlogId(id);
blog.setTitle("Spring Data ElasticSearch学习教程" + id);
blog.setContent("这是添加单个文档的实例" + id);
blog.setAuthor("Tony");
blog.setCategory("ElasticSearch");
blog.setCreateTime(new Date());
blog.setStatus(1);
blog.setSerialNum(id.toString());
return elasticsearchRestTemplate.save(blog);
}
@PostMapping("addDocuments")
public Object addDocuments(Integer count) {
List<Blog> blogs = new ArrayList<>();
for (int i = 1; i <= count; i++) {
Long id = (long)i;
Blog blog = new Blog();
blog.setBlogId(id);
blog.setTitle("Spring Data ElasticSearch学习教程" + id);
blog.setContent("这是添加单个文档的实例" + id);
blog.setAuthor("Tony");
blog.setCategory("ElasticSearch");
blog.setCreateTime(new Date());
blog.setStatus(1);
blog.setSerialNum(id.toString());
blogs.add(blog);
}
return elasticsearchRestTemplate.save(blogs);
}
/**
* 跟新增是同一个方法。若id已存在,则修改。
* 无法只修改某个字段,只能覆盖所有字段。若某个字段没有值,则会写入null。
* @return 成功写入的数据
*/
@PostMapping("editDocument")
public Blog editDocument() {
Long id = 1L;
Blog blog = new Blog();
blog.setBlogId(id);
blog.setTitle("Spring Data ElasticSearch学习教程" + id);
blog.setContent("这是修改单个文档的实例" + id);
return elasticsearchRestTemplate.save(blog);
}
@PostMapping("editDocumentPart")
public UpdateResponse editDocumentPart() {
long id = 1L;
Document document = Document.create();
document.put("title", "修改后的标题" + id);
document.put("content", "修改后的内容" + id);
UpdateQuery updateQuery = UpdateQuery.builder(Long.toString(id))
.withDocument(document)
.build();
UpdateResponse response = elasticsearchRestTemplate.update(updateQuery, IndexCoordinates.of("blog"));
return response;
}
@PostMapping("editDocumentsPart")
public void editDocumentsPart(int count) {
List<UpdateQuery> updateQueryList = new ArrayList<>();
for (int i = 1; i <= count; i++) {
long id = (long) i;
Document document = Document.create();
document.put("title", "修改后的标题" + id);
document.put("content", "修改后的内容" + id);
UpdateQuery updateQuery = UpdateQuery.builder(Long.toString(id))
.withDocument(document)
.build();
updateQueryList.add(updateQuery);
}
elasticsearchRestTemplate.bulkUpdate(updateQueryList, IndexCoordinates.of("blog"));
}
@GetMapping("findById")
public Blog findById(Long id) {
return elasticsearchRestTemplate.get(
id.toString(), Blog.class, IndexCoordinates.of("blog"));
}
@PostMapping("deleteDocumentById")
public String deleteDocumentById(Long id) {
return elasticsearchRestTemplate.delete(id.toString(), Blog.class);
}
@PostMapping("deleteDocumentByQuery")
public void deleteDocumentByQuery(String title) {
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("title", title))
.build();
elasticsearchRestTemplate.delete(nativeSearchQuery, Blog.class, IndexCoordinates.of("blog"));
}
@PostMapping("deleteDocumentAll")
public void deleteDocumentAll() {
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchAllQuery())
.build();
elasticsearchRestTemplate.delete(nativeSearchQuery, Blog.class, IndexCoordinates.of("blog"));
}
}2.3.2 查询的方法
Query接口有3个抽象实现:
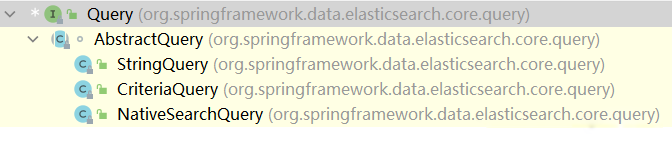
此处使用NativeSearchQuery。因为它更贴近ES,语法更偏向ES原来的命令。CriteriaQuery的语法跟JPA的差不多。
2.3.3构建Query
可通过new NativeSearchQueryBuilder()来构建NativeSearchQuery对象。NativeSearchQuery中有众多的方法来为我们实现复杂的查询与筛选等操作。其中build()返回NativeSearchQuery。

2.3.4 QueryBuilders构造复杂查询条件
NativeSearchQueryBuilder中接收QueryBuilder。
java
public NativeSearchQueryBuilder withQuery(QueryBuilder queryBuilder) {
this.queryBuilder = queryBuilder;
return this;
}可以用QueryBuilders构造QueryBuilder对象:
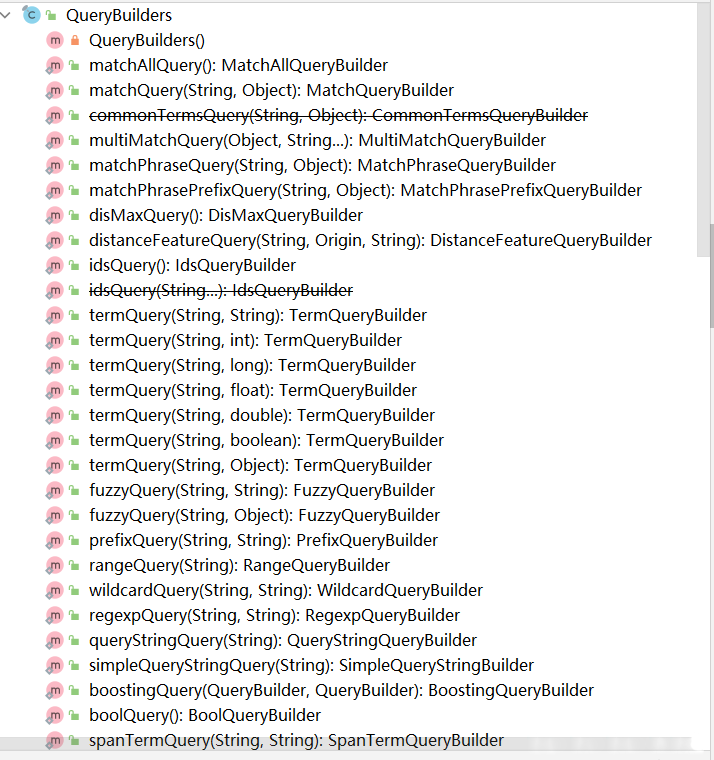
2.3.5 基本查询
通过标题和内容来查找博客:
java
package com.elk;
import com.elk.entity.Blog;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
// 动态查询
@RestController
@RequestMapping("dynamicQuery")
public class DynamicQueryController {
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
// 简单查询
@GetMapping("simple")
public List<Blog> simple(String title, String content) {
NativeSearchQueryBuilder query = new NativeSearchQueryBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
if (StringUtils.isNotBlank(title)) {
boolQueryBuilder.must(QueryBuilders.matchQuery("title", title));
}
if (StringUtils.isNotBlank(content)) {
boolQueryBuilder.must(QueryBuilders.matchQuery("content", content));
}
query.withQuery(boolQueryBuilder);
SearchHits<Blog> searchHits = elasticsearchRestTemplate.search(query.build(), Blog.class);
List<Blog> blogs = new ArrayList<>();
for (SearchHit<Blog> searchHit : searchHits) {
blogs.add(searchHit.getContent());
}
return blogs;
}
}postman调用:
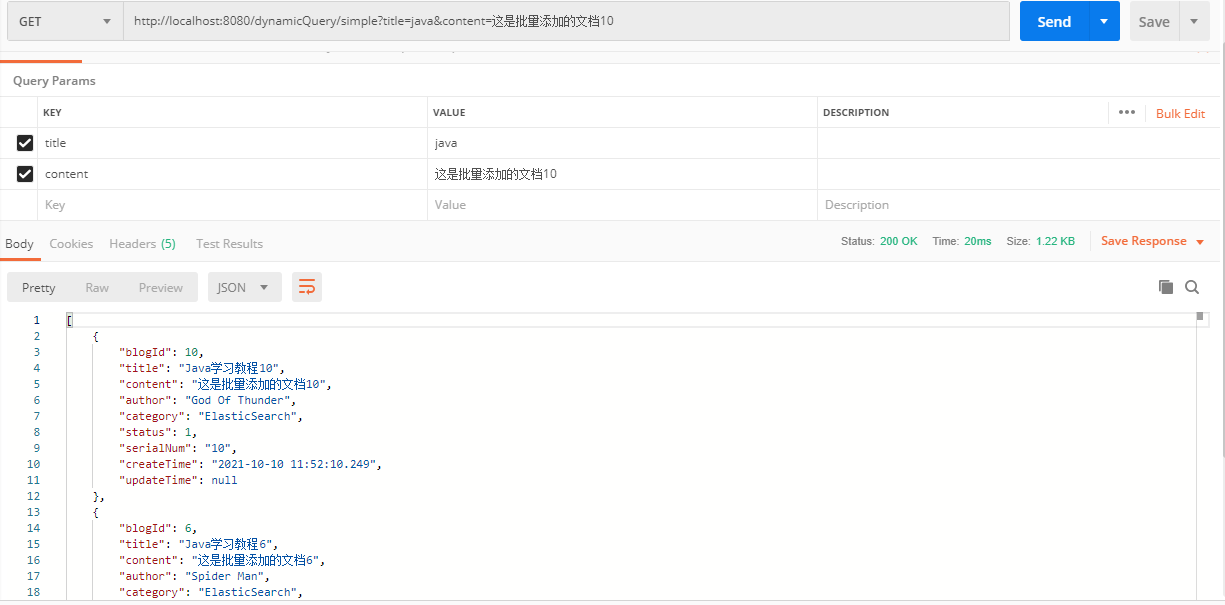
2.3.6 分页排序
通过标题和作者来查找博客,分页,并根据创建时间倒序排序。
java
// 分页排序
@GetMapping("pageAndSort")
public Page<Blog> pageAndSort(String title, String author) {
PageRequest pageRequest = PageRequest.of(0, 2);
NativeSearchQueryBuilder query = new NativeSearchQueryBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
if (StringUtils.isNotBlank(title)) {
boolQueryBuilder.must(QueryBuilders.matchQuery("title", title));
}
if (StringUtils.isNotBlank(author)) {
boolQueryBuilder.must(QueryBuilders.matchQuery("author", author));
}
query.withQuery(boolQueryBuilder);
query.withPageable(pageRequest);
query.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC));
SearchHits<Blog> searchHits = elasticsearchRestTemplate.search(query.build(), Blog.class);
List<Blog> blogs = new ArrayList<>();
for (SearchHit<Blog> searchHit : searchHits) {
blogs.add(searchHit.getContent());
}
return new PageImpl<Blog>(blogs, pageRequest, searchHits.getTotalHits());
}postman调用:
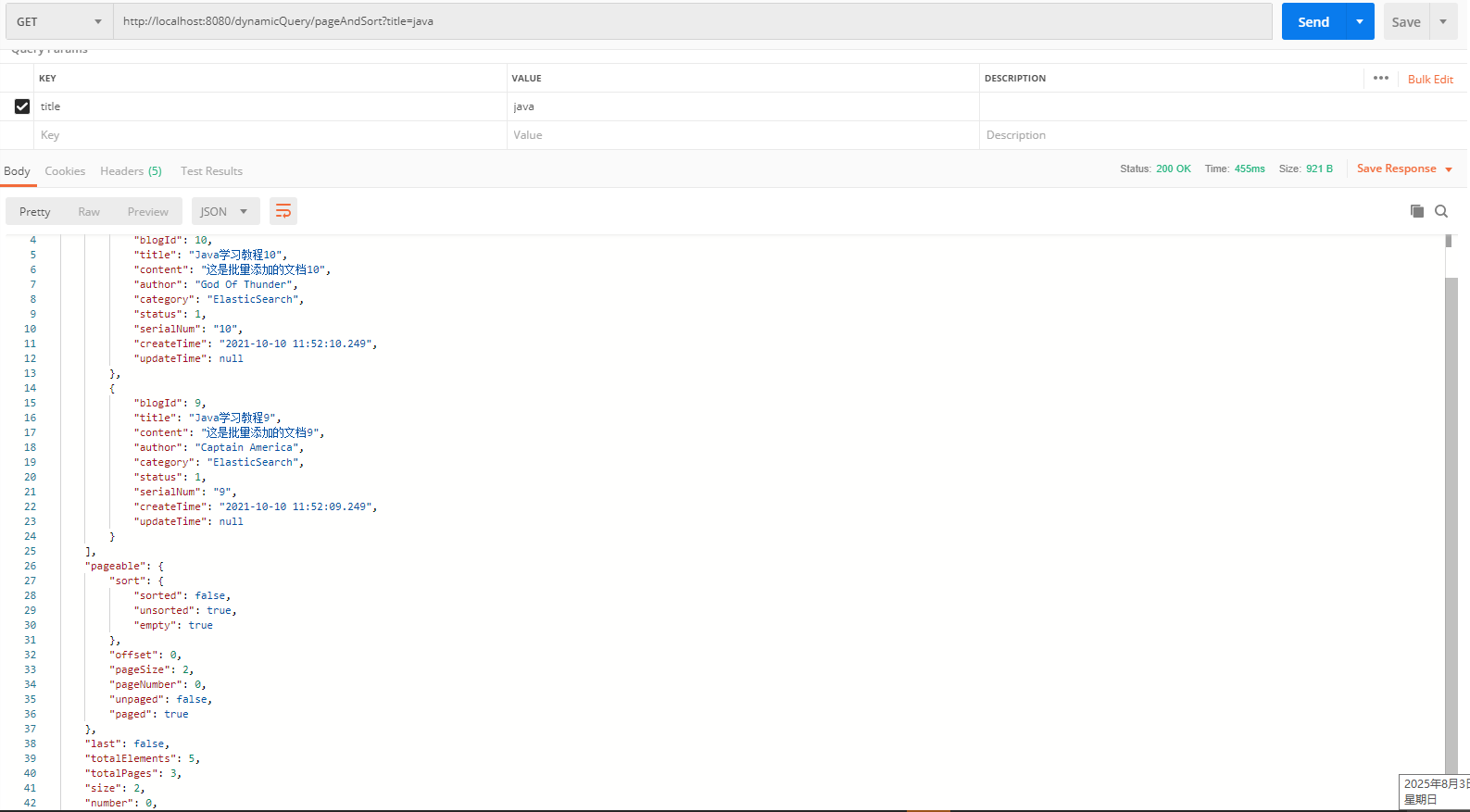
2.3.7 去重
通过标题和作者来查找博客,根据作者来去重。
java
// 去重
@GetMapping("collapse")
public List<Blog> collapse(String title, String author) {
PageRequest pageRequest = PageRequest.of(0, 2);
NativeSearchQueryBuilder query = new NativeSearchQueryBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
if (StringUtils.isNotBlank(title)) {
boolQueryBuilder.must(QueryBuilders.matchQuery("title", title));
}
if (StringUtils.isNotBlank(author)) {
boolQueryBuilder.must(QueryBuilders.matchQuery("author", author));
}
query.withQuery(boolQueryBuilder);
query.withPageable(pageRequest);
query.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC));
// 去重的字段不能是text类型。所以,author的mapping要有keyword,且通过author.keyword去重。
query.withCollapseField("author.keyword");
//query.withCollapseField("category");
SearchHits<Blog> searchHits = elasticsearchRestTemplate.search(query.build(), Blog.class);
List<Blog> blogs = new ArrayList<>();
for (SearchHit<Blog> searchHit : searchHits) {
blogs.add(searchHit.getContent());
}
return blogs;
}postman调用:
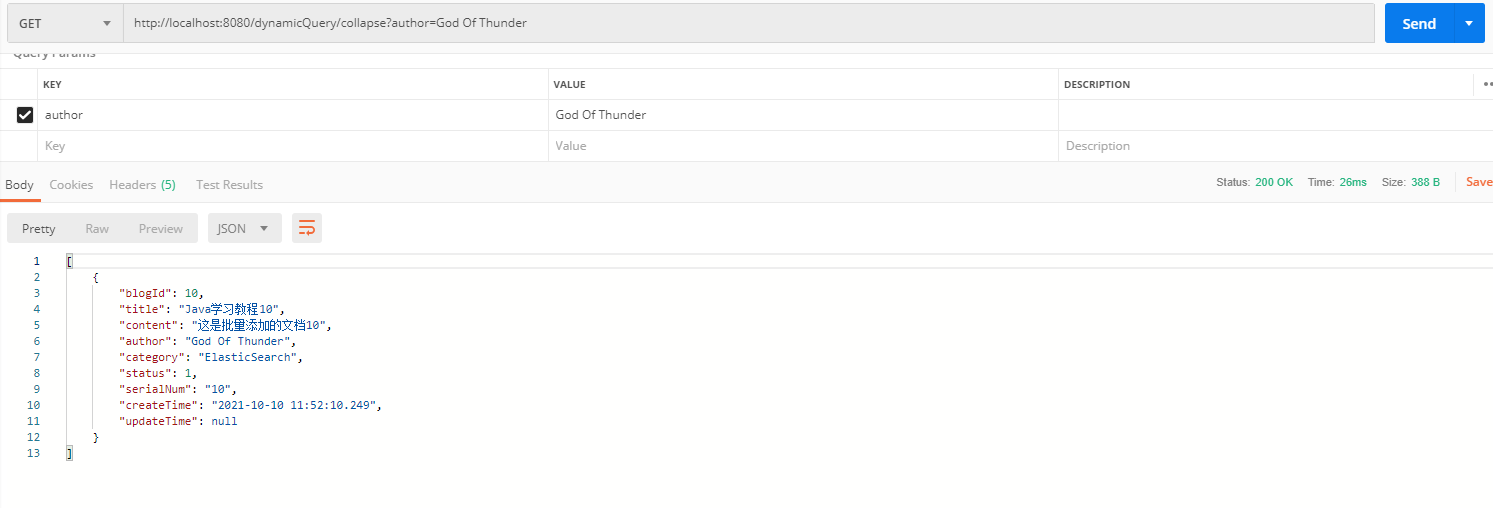
2.3.8 聚合
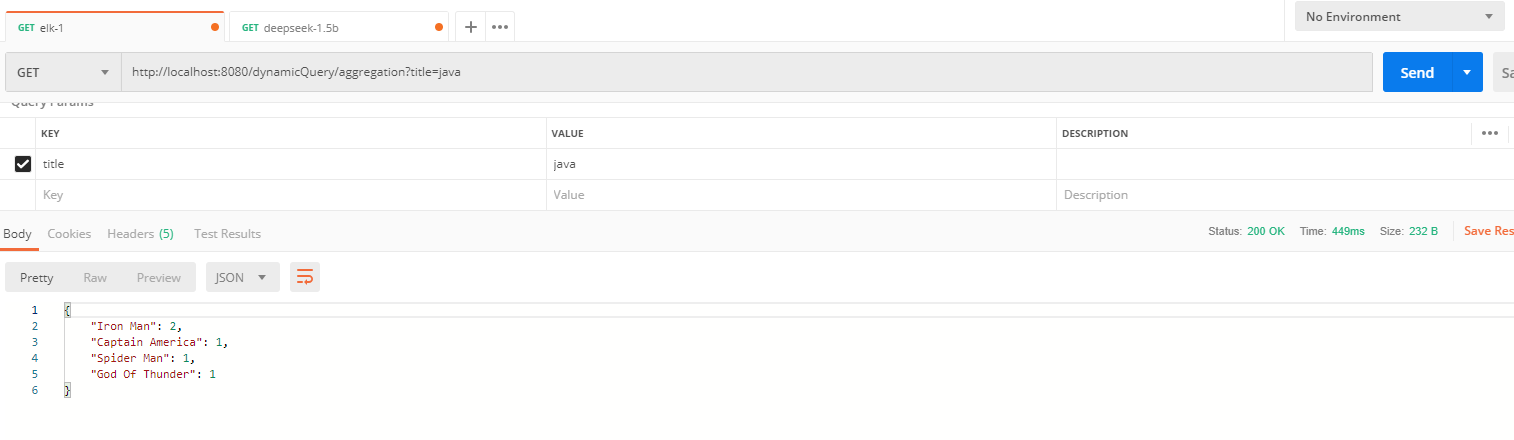
查询标题中带有"java"的每个作者的文章数量。
java
//聚合
@GetMapping("aggregation")
public Map<String, Long> aggregation() {
NativeSearchQueryBuilder query = new NativeSearchQueryBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.matchQuery("title", "java"));
query.withQuery(boolQueryBuilder);
// 作为聚合的字段不能是text类型。所以,author的mapping要有keyword,且通过author.keyword聚合。
query.addAggregation(AggregationBuilders.terms("per_count").field("author.keyword"));
// 不需要获取source结果集,在aggregation里可以获取结果
query.withSourceFilter(new FetchSourceFilterBuilder().build());
SearchHits<Blog> searchHits = elasticsearchRestTemplate.search(query.build(), Blog.class);
Aggregations aggregations = searchHits.getAggregations();
assert aggregations != null;
//因为结果为字符串类型 所以用ParsedStringTerms。其他还有ParsedLongTerms、ParsedDoubleTerms等
ParsedStringTerms per_count = aggregations.get("per_count");
Map<String, Long> map = new HashMap<>();
for (Terms.Bucket bucket : per_count.getBuckets()) {
map.put(bucket.getKeyAsString(), bucket.getDocCount());
}
return map;
}postman调用:
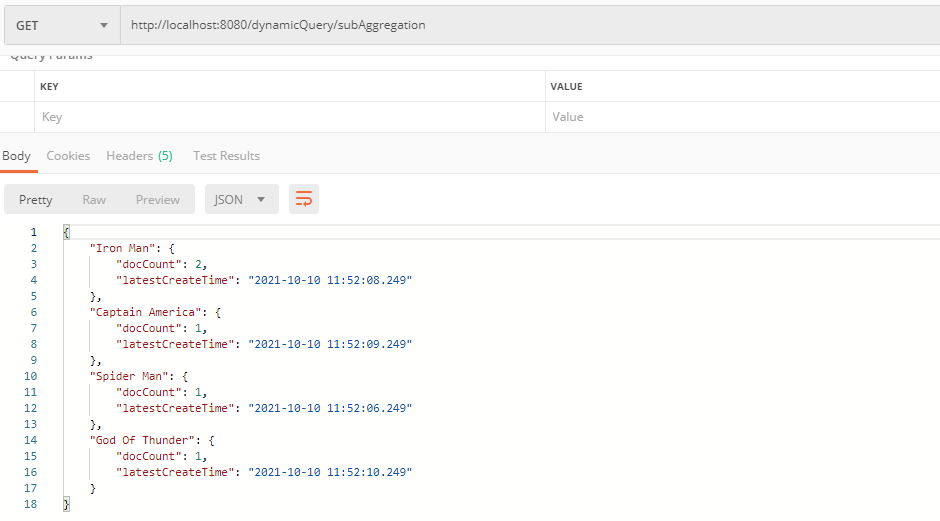
2.3.9 嵌套聚合
查询标题中带有"java"的每个作者的文章数量,再查出各个作者的最新的发文时间。
java
// 嵌套聚合
@GetMapping("subAggregation")
public Map<String, Map<String, Object>> subAggregation() {
NativeSearchQueryBuilder query = new NativeSearchQueryBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.must(QueryBuilders.matchQuery("title", "java"));
query.withQuery(boolQueryBuilder);
query.addAggregation(AggregationBuilders.terms("per_count").field("author.keyword")
.subAggregation(AggregationBuilders.max("latest_create_time").field("createTime"))
);
// 不需要获取source结果集,在aggregation里可以获取结果
query.withSourceFilter(new FetchSourceFilterBuilder().build());
SearchHits<Blog> searchHits = elasticsearchRestTemplate.search(query.build(), Blog.class);
Aggregations aggregations = searchHits.getAggregations();
assert aggregations != null;
//因为结果为字符串类型 所以用ParsedStringTerms。其他还有ParsedLongTerms、ParsedDoubleTerms等
ParsedStringTerms per_count = aggregations.get("per_count");
Map<String, Map<String, Object>> map = new HashMap<>();
for (Terms.Bucket bucket : per_count.getBuckets()) {
Map<String, Object> objectMap = new HashMap<>();
objectMap.put("docCount", bucket.getDocCount());
ParsedMax parsedMax = bucket.getAggregations().get("latest_create_time");
objectMap.put("latestCreateTime", parsedMax.getValueAsString());
map.put(bucket.getKeyAsString(), objectMap);
}
return map;
}postman调用:
2.3.10 application.yml
yaml
server:
port: 8080
spring:
elasticsearch:
rest:
# 如果是集群,用逗号隔开
uris: http://10.86.97.210:9200
username: elastic
password: test@123456
connection-timeout: 1
read-timeout: 30
# 上边是客户端High Level REST Client的配置,推荐使用。
# 下边是reactive客户端的配置,非官方,不推荐。
# data:
# elasticsearch:
# client:
# reactive:
# endpoints: 127.0.0.1:9200
# username: xxx
# password: yyy
# connection-timeout: 1
# socket-timeout: 30
# use-ssl: false2.3.11 pom.xml
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.elk</groupId>
<artifactId>spring-boot-elk</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>spring-boot-elk</name>
<description>Demo project for Spring Boot</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.12.RELEASE</version>
<relativePath /> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version> <!-- 推荐稳定版本 -->
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>3.相关资源
百度网盘:https://pan.baidu.com/s/1qlabJ7m8BDm77GbDuHmbNQ?pwd=41ac