一·参数
逻辑回归参数及多分类策略等完整解析
-
LogisticRegression 初始参数声明
LogisticRegression(penalty='l2', dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='liblinear', max_iter=100, multi_class='ovr', verbose=0, warm_start=False, n_jobs=1)
-
核心参数与概念详细说明
- Penalty:正则化方式,含 L1、L2 ;newton - cg、sag、lbfgs 仅支持 L2 ,L1 假设参数服从拉普拉斯分布,L2 假设服从高斯分布,加约束理论增强泛化能力防过拟合 。
- Dual:对偶方法,用于线性多核(liblinear)的 L2 惩罚项;样本数>特征数时,通常设 False 。
- Tol:迭代停止精度(容许停止标准 ),float 型,默认 1e - 4 。
- C:正则化强度,为正则化系数 λ 的倒数,数值越小正则化越强(类 SVM ),默认 1.0 (正浮点型数 )。
- fit_intercept:控制是否加截距项到决策函数,默认 True(加截距项 b )。
- intercept_scaling:仅正则化项为 "liblinear" 且 fit_intercept=True 时生效,float 型,默认 1 。
- class_weight:分类权重设置,支持字典、'balanced' ;默认 None(不考虑权重 ),样本失衡时可用,"balanced" 按样本量算权重(样本多则权重低 ),也可自定义(如 {0:0.9,1:0.1} ),解决误分类代价高、样本失衡问题 。
- random_state:伪随机数种子,用于数据洗牌,仅 sag、liblinear 正则化算法生效 。
- Solver :优化算法,可选 {'newton - cg', 'lbfgs', 'liblinear', 'sag', 'saga'} ,默认 liblinear :
- liblinear:坐标轴下降法,适小数据集;多分类用 OvR 策略,仅支持 L2 正则化(newton - cg、sag、lbfgs 同 ),saga 支持 L1/L2 ;
- newton - cg:牛顿法,二阶泰勒展开减迭代轮数,需算 Hessian 矩阵逆(复杂度高 );
- lbfgs:拟牛顿法,近似 Hessian 矩阵逆,解决牛顿法求逆难题;
- Sag:随机平均梯度下降,一阶优化,用部分样本算梯度,适大数据集(>10 万 ),不支持 L1 ;
- Saga:线性收敛随机优化算法变种,通吃 L1/L2 。
- max_iter:算法最大迭代次数,int 型,默认 100 ;仅 newton - cg、sag、lbfgs 正则化算法生效 。
- multi_class :分类策略,可选 ovr(one - vs - rest )、multinomial(many - vs - many ),默认 ovr :
- OvR:多元转二元处理,第 K 类样本为正例,其余为负例做二元回归,遍历类别构建模型;相对简单,分类效果略差(部分场景有优势 );选 ovr 时,liblinear、newton - cg、lbfgs、sag 4 种优化算法都可用 。
- MvM:以 OvO(one - vs - one )为例,T 类样本需选两类(T1、T2 ),T1 正例、T2 负例做二元回归,共需 T (T - 1)/2 次分类;分类精确但速度慢;选 multinomial 时,仅 newton - cg、lbfgs、sag 优化算法可用 。
- verbose:日志冗长度,int 型,默认 0(不输出训练过程 );1 偶尔输出结果,>1 则每个子模型都输出 。
- warm_start:热启动参数,bool 型,默认 False ;为 True 时,下次训练以追加树形式(用上一次调用初始化 )。
- n_jobs:并行数,int 型,默认 1(用 CPU 1 个内核 );2 则用 2 个内核,-1 用所有 CPU 内核 。
-
多分类策略与算法关联补充
OvR 相对简单但效果略差(部分样本分布场景有优势 ),MvM 分类精确但速度慢;选 ovr 时,4 种优化算法(liblinear、newton - cg、lbfgs、sag )均可搭配;选 multinomial 时,仅 newton - cg、lbfgs、sag 可用 。
二·代码
python
import numpy as np
# numpy是专门用于处理矩阵数据
# 读取数据集
data = np.loadtxt('datingTestSet2.txt')
# 数据预处理(按需启用,若不需要筛选可注释)
# data_1 = data[data[:, -1] == 1] # 找出类别为1的数据
# data_2 = data[data[:, -1] == 2] # 找出类别为2的数据
# data_3 = data[data[:, -1] == 3] # 找出类别为3的数据
# data_new = np.concatenate((data_1, data_2), axis=0) # 拼接类别1和2的数据
# X = data_new[:, :-1] # 获取特征(不含最后一列标签)
# y = data_new[:, -1] # 获取标签(最后一列)
# 若无需筛选类别,直接用全部数据做特征和标签拆分
X = data[:, :-1] # 获取所有数据的特征(不含最后一列标签)
y = data[:, -1] # 获取所有数据的标签(最后一列)
"""建立模型"""
from sklearn.model_selection import train_test_split
# 专门用来对数据集进行切分的函数
# 拆分数据集为训练集和测试集
x_train_w, x_test_w, y_train_w, y_test_w = train_test_split(
X, y, test_size=0.3, random_state=1000
)
from sklearn.linear_model import LogisticRegression
# 逻辑回归的类,所有的算法都封装再这个类
# 创建逻辑回归模型实例
lr = LogisticRegression(C=0.01)
# 训练模型(用训练集特征和标签)
lr.fit(x_train_w, y_train_w)
# 测试集预测
test_predicted = lr.predict(x_test_w)
# 计算模型在测试集上的准确率
result = lr.score(x_test_w, y_test_w)
print("模型在测试集上的准确率:", result)
抽取30%测试集剩下的70%是训练集
python
x_train_w, x_test_w, y_train_w, y_test_w = train_test_split训练级的 x。测试机 x 训练机的 y,测试机的 y

lr中的coef
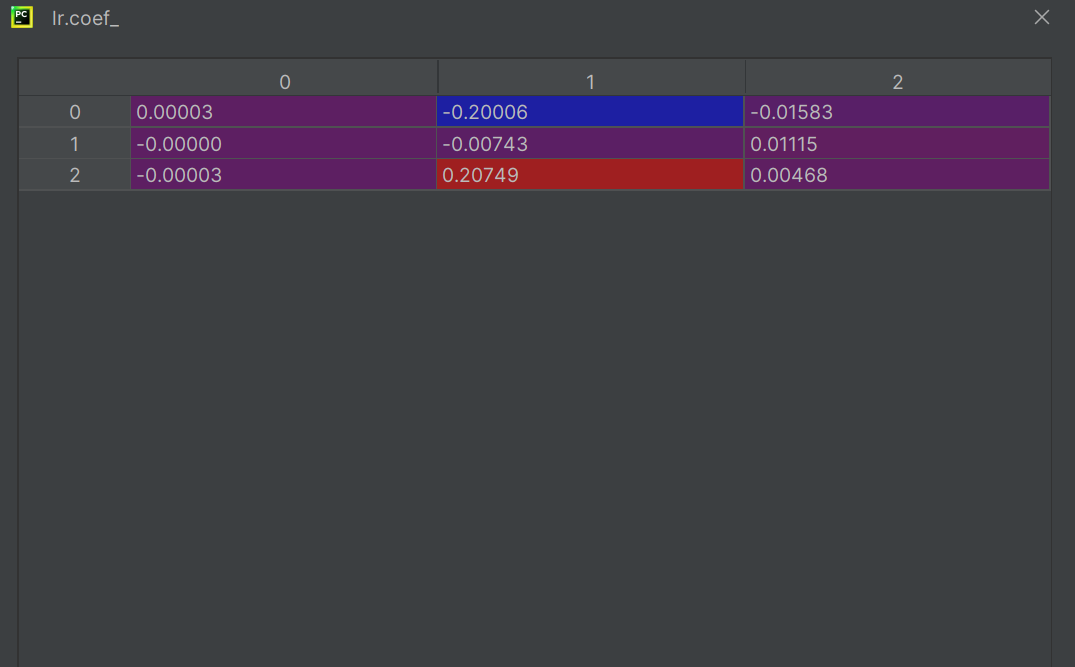
建立三条数据线,三条方程
三·关于银行的案例下篇文章会讲
python
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
from pylab import mpl
from sklearn import metrics
data = pd.read_csv(r"./creditcard.csv")
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']])
data = data.drop(['Time'], axis=1)
X_whole = data.drop('Class', axis=1)
y_whole = data['Class']
x_train_w, x_test_w, y_train_w, y_test_w = train_test_split(
X_whole, y_whole, test_size=0.3, random_state=1000
)
lr = LogisticRegression(C=0.01)
lr.fit(x_train_w, y_train_w)
test_predicted = lr.predict(x_test_w)
result = lr.score(x_test_w, y_test_w)
print(metrics.classification_report(y_test_w, test_predicted))
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei']
mpl.rcParams['axes.unicode_minus'] = False
labels_count = pd.value_counts(data['Class'])
labels_count.plot(kind='bar')
plt.title("正负例样本数")
plt.xlabel("类别")
plt.ylabel("频数")
plt.show()