在文本理解、图像识别、智能对话等领域大放异彩的 Transformer,如今正与实时视频流系统融合,为智能安防、工业巡检、远程医疗等行业构建出强大的"感知 + 理解"闭环。本文将从原理出发,剖析 Transformer 如何工作,并进一步探讨它与大牛直播SDK的结合方式及落地价值。
✳️ 类比引入:Transformer 是"全局感知"的语言理解者
设想一个多人会议场景,每位发言者依次表达观点:
-
有人提出问题
-
有人直接回答
-
有人补充说明
-
有人举例解释
作为会议纪要撰写者,你不只是逐字记录,还要理解:
-
谁说了什么?
-
哪些内容相互关联?
-
哪些是重点,哪些是背景?
传统模型(如 RNN)像"顺序打字员",一边听一边记,容易"忘前顾后";而 Transformer 则像拥有全局视野的专家记录员,能够:
-
✅ 同时关注所有词汇,不受顺序限制
-
✅ 动态判断词与词之间的关联权重
-
✅ 综合上下文理解,提炼关键信息
🧠 核心机制一:注意力机制(Attention)------「每个词该关注谁?」
Transformer 的核心创新在于 自注意力机制(Self-Attention):每个词在被编码时,会同时"查看"句中所有其他词,并根据语义关系打分,确定该关注谁、关注多少。
例如:
"他把它放在桌子上。"
模型会推理:"它"可能指的是"笔记本"、"文件"或"手机",根据上下文语义,判断与谁最相关。
这种机制让模型具备了超越传统 RNN 的"全局理解"能力,特别擅长处理长句子、指代关系、上下文依赖等复杂语言现象。
⚙️ 核心机制二:并行处理语义 ------「不再逐字阅读,而是整体感知」
传统模型只能串行处理,像打字一样慢慢读句子。而 Transformer 是并行架构:
-
所有词同时处理,不依赖前后顺序
-
每层都通过自注意力提炼语义
-
多层堆叠,实现语义抽象升级
结果是,Transformer 训练更快、理解更深、推理更强,为大模型如 GPT、BERT 等奠定了基础。
🧩 核心结构:Encoder-Decoder 框架
模块
类比角色
功能描述
Encoder
聪明听众
输入编码、上下文建模、提取语义特征
Decoder
表达专家
基于语义表示,逐步生成输出(翻译、回答等)
这一结构广泛应用于翻译、摘要、问答生成等任务。
🧪 示例演示:Transformer 如何翻译"我爱你"?
-
输入:"我 爱 你" → 向量嵌入 + 位置编码
-
Encoder → 多层 Attention 处理
-
Decoder 预测输出:"I" → "love" → "you"
每一步都结合了当前上下文与输入语义,保持连贯性与正确性。
🔬 可解释性:Attention 可视化
在翻译过程中,我们可以清晰观察 Attention 的指向:
-
I关注 "我" -
love对应 "爱" -
you对应 "你"
可视化不仅提升模型可信度,也方便调试与优化。
🔗 Transformer × 大牛直播SDK:让实时视频也具备"理解"能力
随着 Transformer 向视觉、语音、多模态领域扩展,它可以与大牛直播SDK构建的视频通路系统深度融合,打造具备感知、理解、响应能力的智能平台。

✅ 功能划分:
模块角色
功能说明
🎥 大牛直播SDK
实时采集/推送 RTSP、RTMP、GB28181 视频流
🧠 Transformer 模型
对图像帧、音频文本进行语义理解和推理
⚙️ 联动方式
视频流 → AI 分析 → 结果反馈(控制、标注、决策)
🖼 多模态 AI 感知系统架构图
下图展示了大牛直播SDK与 Transformer 模型的结合路径:
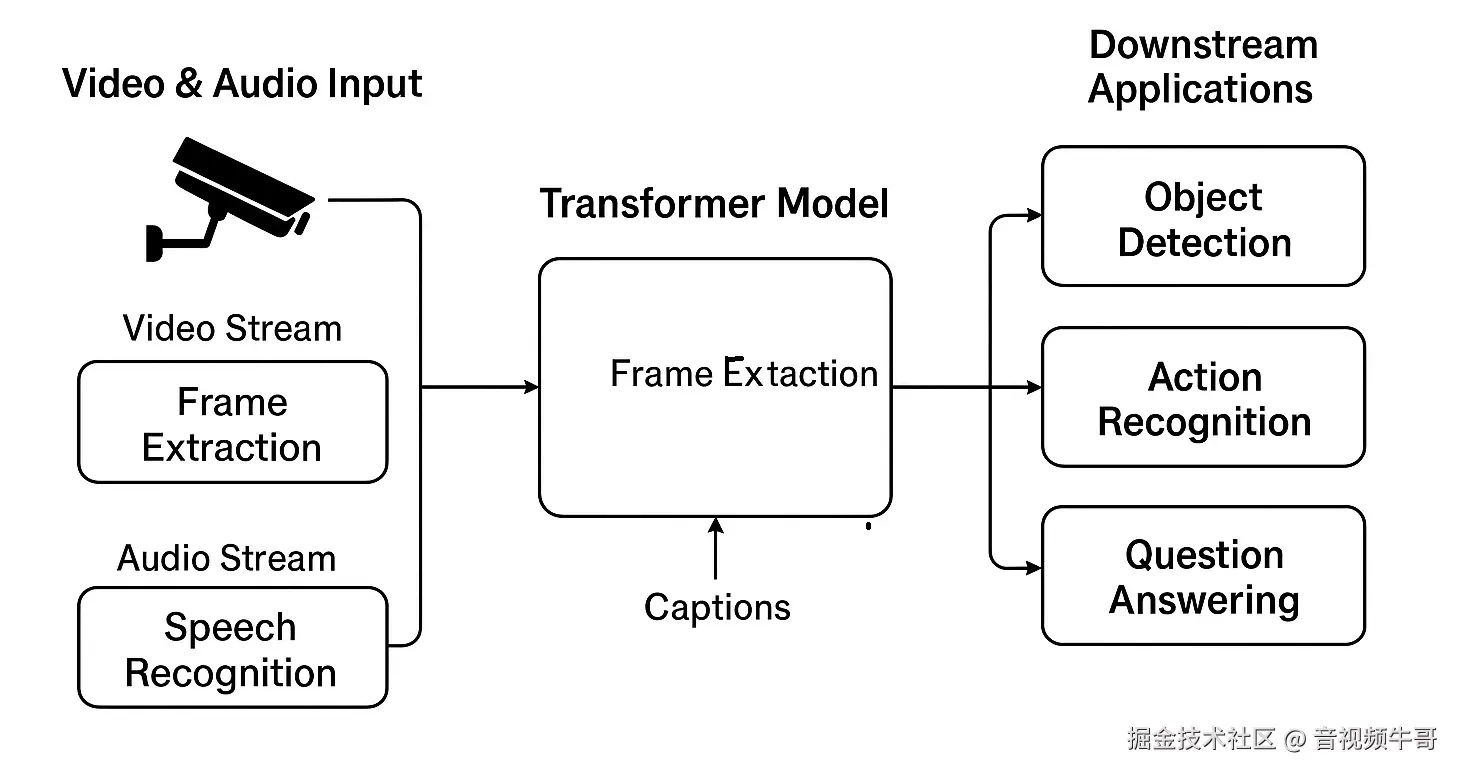
图示说明:
视频流 → 提取关键帧 → Transformer 识别目标或动作
音频流 → 语音识别为文本 → 输入文本Transformer处理,如问答、情感识别
输出结果用于行为预警、虚拟人响应、远程控制等下游系统
🌍 应用场景参考
应用领域
大牛直播SDK能力
接入 Transformer 后能力升级
安防监控
多路摄像头低延迟推流 + 录像
人群聚集检测、行为识别、入侵预警
工业巡检
高分辨率 RTSP 视频采集
缺陷检测、工人动作监控、故障定位
远程医疗
医患远程视频通话 + 音视频录制
情感识别、表情分析、语音理解
虚拟互动
实时采集主播音视频
语义识别 → 驱动数字人语音+动作
教育直播
高清屏幕推流 + 语音同步
内容提要生成、自动答疑、情绪识别
🔚 总结:视频的未来,是"看得懂"的视频
Transformer 的核心是理解,大牛直播SDK的优势在于连接。两者结合,构建出具备:
-
📡 实时采集(视频/音频)
-
🧠 多模态理解(图像+语音+文本)
-
🤖 智能响应(分析、生成、反馈)
新一代 AI 感知系统,不再只是"看得清",而是"看得懂、听得懂、说得出"。