通过 Pulsar Functions ,可以使用 Python 函数发布与订阅消息,实现实时的机器学习推测。
各行各业在决策过程中都有运用 AI 和机器学习的需求。尽管已有强大的算力和实时事件数据支撑,考虑到实时重新训练及评估的难度,实时 AI 这个方向尚未取得长足进展。
Pulsar Functions 是基于 Apache Pulsar 的 Serverless 计算框架,它提供了一个方便而强大的解决方案,打破了传统机器学习工作流的局限性。
利用 Pulsar 固有的 pub/sub 特性,Pulsar Functions 可以为真正的实时 AI 提供一个框架。
Pulsar Functions 有广阔的使用场景,本文将重点关注其灵活性,并探索它如何为需要实时推测和结果的机器学习 pipeline 提供解决方案。
概述
我们的目标是构建一个通过 Pulsar Functions 实现的实时推理引擎,该引擎可以一次性或批量检索低延迟的推测信息。这一目标的实现过程可以拆解为以下两步:
-
安装、配置和启动 Pulsar。
-
定义构成推理引擎的 Python 函数。
下文将通过一个示例介绍实现过程,重点聚焦 Python 开发以及注册/触发 Pulsar Functions 的调用接口。
启动独立的 Apache Pulsar 实例
通常,Pulsar 会被部署在一个集群中,而非本地独立实例;但独立实例的形式更便于我们在实时 AI 的场景下进行实践。
启动实例步骤可参考 Pulsar 官方文档;输入以下命令:
bash
bin/pulsar standalone数据集配置
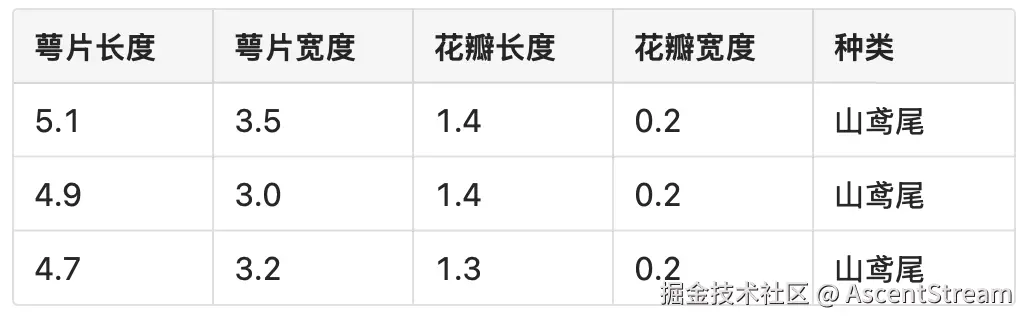
实例运行后,我们需要定义一个 Pulsar Function 来为机器学习提供示例。这里用到的是经典的 Iris Dataset 鸢尾花数据集。该数据集由 Edgar Anderson 收集创建,并由 Ronald Fisher 推广,包含 3 种共 50 朵花的数据,包括:
萼片长度(sepallength):萼片的测量长度
萼片宽度(sepalwidth):萼片的测量宽度
花瓣长度(petallength):花瓣的测量长度
花瓣宽度(petalwidth):花瓣的测量宽度
种类:花的种类(山鸢尾 Setosa、变色鸢尾 Versicolor或维吉尼亚鸢尾 Virginica)
下面附上相关数据的部分概览。
我们的目标是根据输入特性准确推测花的种类。模型 pipeline 的两个核心组成部分是训练和推测,后者正是本文 Pulsar 实践的落脚点。
构建 Pulsar Function
Pulsar Function 可以通过独立的 Python 脚本创建,其中包含将要部署的函数。如前所述,模型推测 routine 将是 Pulsar Function 的基础。在这个框架中,函数本身大部分都是标准的 Python 函数,只有极少为 Pulsar 专用;这一点极大地减少了代码的部署时间以及专业 Python 开发人员的时间。
让我们从拉取鸢尾花数据、训练模型并将其写入 Pulsar Topic 这一基础流程入手。
python
import os
import pickle
import pandas as pd
from pulsar import Function
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
def train_iris_model():
# If we already have an existing model file, we can load it right away
if os.path.exists("model.pkl"):
print("We are loading a pre-existing model")
return pickle.load(open("model.pkl", 'rb'))
# Read in the iris data, split into a 20% test component
iris = pd.read_csv("https://datahub.io/machine-learning/iris/r/iris.csv")
train, test = train_test_split(iris, test_size=0.2, stratify=iris['class'])
# Get the training data
X_train = train[['sepalwidth', 'sepallength', 'petalwidth', 'petallength']]
y_train = train['class']
# Get the test data
X_test = test[['sepalwidth', 'sepallength', 'petalwidth', 'petallength']]
y_test = test['class']
# Train the model
model = DecisionTreeClassifier(max_depth=3, random_state=1)
model.fit(X_train, y_train)
# Dump the model object to a file
pickle.dump(model, open("model.pkl", 'wb'))
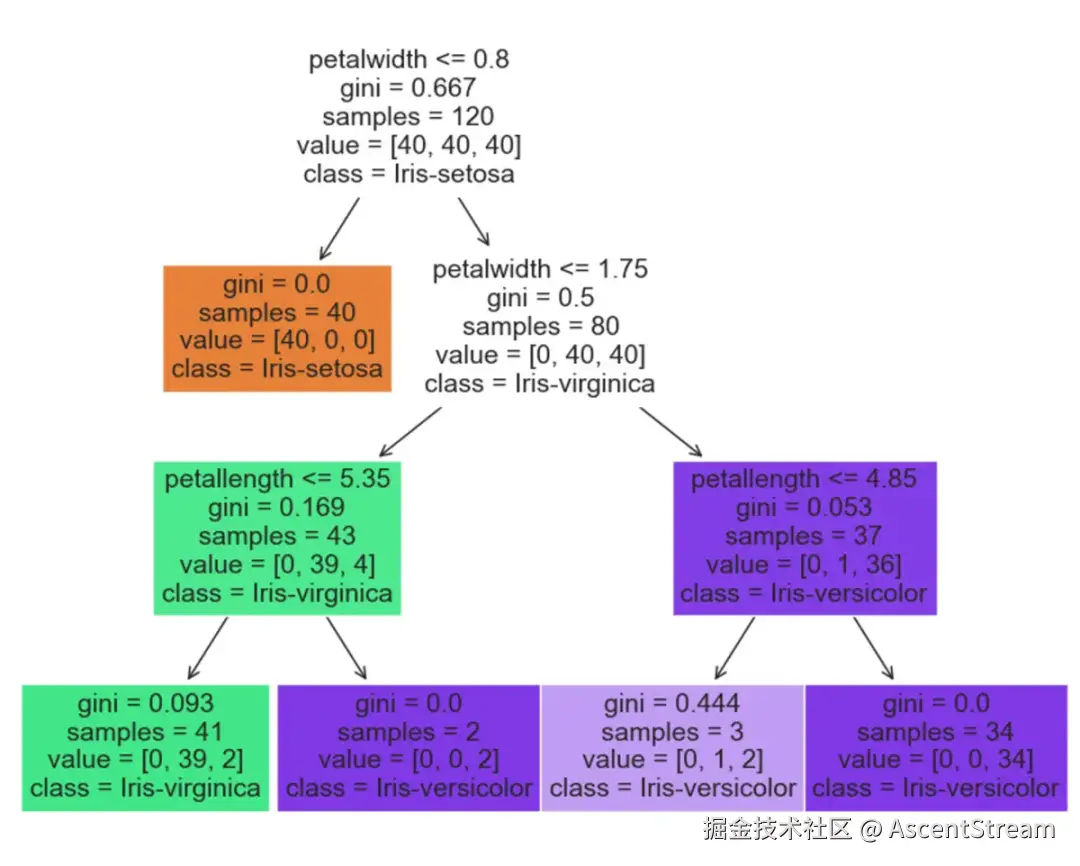
return model这组代码训练出一个决策树分类器(decision tree classifier),会根据萼片和花瓣的宽度和长度来推测花的种类。决策树分类器可以直观地表示为基于特征值的一系列决策,最终在到达树的叶节点(leaf node)时给出结论。下面是一个衍生出的示例决策树。
需要注意的一点是:我们在训练中使用 pickle 模块对模型进行序列化。这将把模型转储到工作目录中的文件中。如果序列化后的模型可用,后续对函数的调用将直接读取模型,而非经由重新训练。这一步对接下来的动作非常关键,因为它实现了一个单独的 routine,负责在收集新数据时对模型进行持续评估、增强和重新训练。
然而,在生产环境中,例如使用 Kubernetes 容器运行 Pulsar 时,工作目录可能是临时的,反而需要引入一些其他解决方案。几种可能性包括:
-
模型本身可以存储在 Pulsar Topic 中。序列化的格式可以写为 base64 编码的字符串并按需读取,而非从磁盘读取文件。
-
如果需要物理模型文件,序列化文件本身可以存储在云端;函数运行时,文件可以被下载并读取。
训练决策树分类器的代码完成后,就可以构建代表 Pulsar Function 的 routine 了。我们将在 Pulsar 中创建 Function 类的 IrisPredictionFunction 子类,并执行两种方法:一种是没有特定功能的 init () 方法,另一种是 process() 方法,负责在给定输入和用户上下文时,从模型中返回推测结果。
python
class IrisPredictionFunction(Function):
# No initialization code needed
def __init__(self):
pass
def process(self, input, context):
# Convert the input ratio to a float, if it isn't already
flower_parameters = [float(x) for x in input.split(",")]
# Get the prediction
model = train_iris_model()
return model.predict([flower_parameters])[0]Function 不依赖于用户上下文,而是依赖输入。由于模型训练是基于萼片长度、萼片宽度、花瓣长度和花瓣宽度四个特征数据实现的,我们需要按照顺序提供每个特征数据才能得到推测结果。方便起见,我们使用以逗号分隔的字符串输入信息。
1.8,2.1,4.0,1.4这代表一朵尺寸如下的花:
萼片长度:1.8
萼片宽度:2.1
花瓣长度:4.0
花瓣宽度:1.4
我们的 Pulsar Function 将使用此字符串,在逗号处拆分并将值转换为浮点,然后将它们传递给模型推测 routine。
部署 Pulsar Function
Pulsar独立客户端运行时,部署Function只需要创建和触发两步。创建:
lua
bin/pulsar-admin functions create
--tenant public
--namespace default
--name iris_prediction_1
--py iris_prediction.py
--timeout-ms 10000
--classname iris_prediction.IrisPredictionFunction
--inputs persistent://public/default/in
--output persistent://public/default/out注意一些参数:
--name 定义了 Fucntion 任务的名(唯一即可)以便查询和管理。
--py 是上文编写的 Python 代码脚本文件的名称。
--classname 是 Python 脚本中的类名称。
触发 Function 并传递前文示例参数:
scss
bin/pulsar-admin functions trigger
--tenant public
--namespace default
--name iris_prediction_1
--trigger-value 1.8,2.1,4.0,1.4批量推测
简单修改上述 Function 即可实现批量推测。添加下述类,用于创建一个新的 Pulsar Function:
python
class IrisPredictionFunctionBulk(Function):
# No initialization code needed
def __init__(self):
pass
def process(self, input, context):
# Convert the input parameters to floats, if they aren't already
flower_parameters_str = input.split(":")
flower_parameters_split = [x.split(",") for x in flower_parameters_str]
flower_parameters_float = [[float(x) for x in y] for y in flower_parameters_split]
# Get the prediction
model = train_iris_model()
return ", ".join(model.predict(flower_parameters_float))用于批量推测的 Function 有以下特点:
-
定义了一个新的类名,以便在注册函数时区分。
-
涵盖可能有不止一组花的测量值的场景,使用 : 字符分割。
-
将推测结果输出为以逗号分隔的字符串。
和之前一样,我们注册 Function、定义一个新名称,并引用刚创建的正确类名称:
lua
bin/pulsar-admin functions create
--tenant public
--namespace default
--name iris_prediction_bulk_1
--py iris_prediction.py
--timeout-ms 10000
--classname iris_prediction.IrisPredictionFunctionBulk
--inputs persistent://public/default/in
--output persistent://public/default/out触发 Function 并一次性传递三组花的测量值:
scss
bin/pulsar-admin functions trigger
--tenant public
--namespace default
--name iris_prediction_bulk_1
--trigger-value 1.8,2.1,4.0,1.4:0.1,0.1,0.1,0.1:1.8,2.5,0.5,5.0以上是一个简单的案例,在 Python 中使用 Pulsar Functions 并基于测量值对鸢尾花种类进行实时推测。
这个案例仅触及到 Pulsar Functions 的浅层应用,可以当作对基于 Pulsar 实现实时AI Pipeline 的投石问路。
通过 Pulsar 核心框架赋能,具有大量实时数据 的复杂发布/订阅系统 可以实现无缝处理; 推理模型的输出结果可以直接被消费,甚至用于下游任务。