魔塔链接:omnivision-968M
https://github.com/NexaAI/nexa-sdk?tab=readme-ov-file#install-option-1-executable-installer
介绍:
OmniVLM 是一个紧凑的、亚十亿(968M)参数的多模态模型,用于处理视觉和文本输入,并针对边缘设备进行了优化。在 LLaVA 架构的基础上进行了改进,它具有以下特点:
- 9倍令牌减少 :将图像令牌从 729 减少到 81,大幅降低了延迟和计算成本。请注意,视觉编码器和投影部分的计算保持不变,但由于图像令牌跨度缩短了9倍,语言模型骨干的计算量减少了。
- 可靠的结果 :使用来自可信数据的 DPO 训练来减少幻觉。
模型架构:
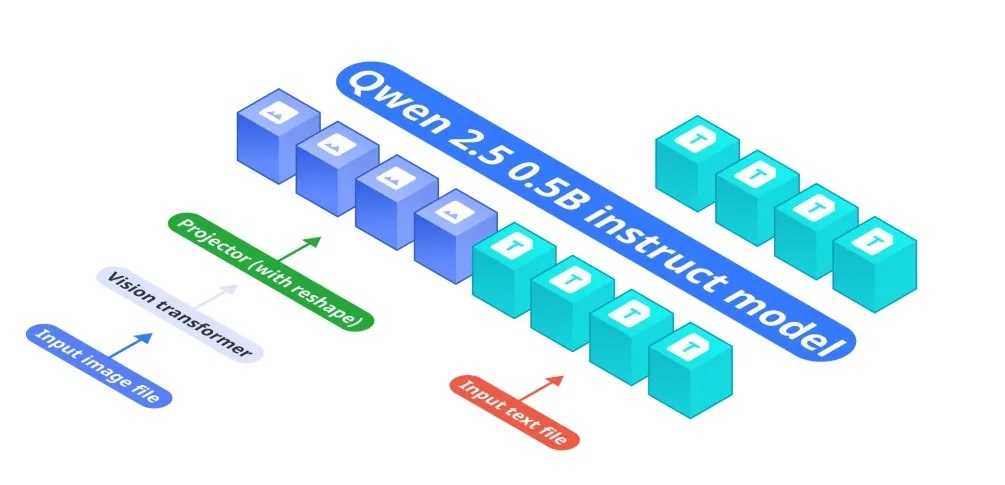
OmniVLM的架构由三个关键组件组成:
- 基础语言模型:Qwen2.5-0.5B-Instruct作为处理文本输入的基础模型
- 视觉编码器:SigLIP-400M以384分辨率和14×14的补丁大小工作,生成图像嵌入
- 投影层:多层感知机(MLP)将视觉编码器的嵌入与语言模型的令牌空间对齐。与原始Llava架构相比,我们设计了一个减少9倍图像令牌的投影器。
视觉编码器首先将输入图像转换为嵌入,然后通过投影层处理以匹配Qwen2.5-0.5B-Instruct的令牌空间,从而实现端到端的视觉-语言理解。
模型训练:
我们通过三阶段训练管道开发了OmniVLM:
预训练:
初始阶段侧重于使用图像-标题对建立基本的视觉-语言对齐关系,在此期间仅解冻投影层参数来学习这些基本关系。
监督微调(SFT):
我们使用基于图像的问题回答数据集增强模型的上下文理解能力。这一阶段涉及在包含图像的结构化聊天历史记录上进行训练,使模型能够生成更加符合上下文的回答。
直接偏好优化(DPO):
最后阶段通过首先使用基础模型生成对图像的响应来实现DPO。然后,一个教师模型在保持与原始响应高度语义相似的同时,产生最小编辑的修正,特别关注准确性关键元素。这些原始输出和修正后的输出形成选择-拒绝配对。微调针对的是对模型输出进行必要的改进,而不改变模型的核心响应特性。
模型安装:
步骤1:安装所需的依赖项
pip install torch torchvision torchaudio einops timm pillow
pip install git+https://github.com/huggingface/transformers
pip install git+https://github.com/huggingface/accelerate
pip install git+https://github.com/huggingface/diffusers
pip install huggingface_hubpip install sentencepiece bitsandbytes protobuf record步骤2:安装Nexa-SDK(本地设备推理框架)
Nexa-SDK是一个开源的、支持文本生成、图像生成、视觉-语言模型(VLM)、音频-语言模型、语音转文字(ASR)和文字转语音(TTS)功能的本地设备推理框架。可以通过Python包或可执行安装程序进行安装。
# 安装支持GPU的Nexa SDK
CMAKE_ARGS="-DGGML_CUDA=ON -DSD_CUBLAS=ON" pip install nexaai --prefer-binary --index-url https://nexaai.github.io/nexa-sdk/whl/cu124 --extra-index-url https://pypi.org/simple --no-cache-dir步骤3:运行OmniVision-968M模型
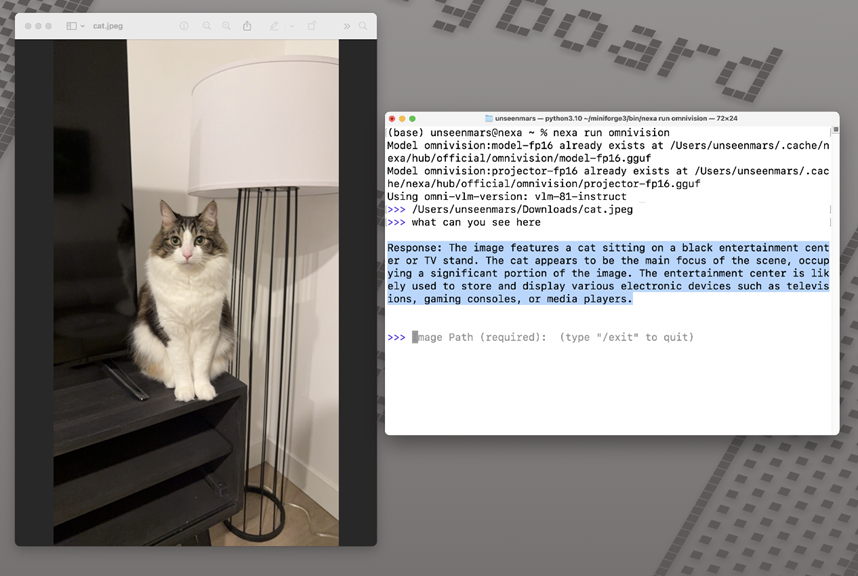
nexa run omnivision步骤4:使用OmniVision分析图像
假设有一张位于/home/user/images/horses.png的图像,我们可以运行OmniVision-968M来生成对内容的描述。将图像放置在指定路径并运行以下命令:
>> /home/user/images/horses.png
>> Describe the image
模型回复:"图像展示了三匹马站在草地上,靠近水体。它们似乎正在从位于背景中的池塘中饮水。马匹彼此靠近,一匹马位于图像的左侧,另一匹在中心,第三匹马在右侧。场景传达出一种平和宁静的氛围,马匹享受着靠近水源的时光。"
预期使用场景:
OmniVLM 适用于 视觉问答 (回答关于图像的问题)和 图像字幕生成(描述照片中的场景),使其非常适合于设备端应用。
示例演示: 在 M4 Pro Macbook 上为一张 1046×1568 的图片生成字幕仅需 < 2 秒处理时间,并且只需要 988 MB RAM 和 948 MB 存储空间。
基准测试:
下面我们将展示一个图表,以说明 OmniVLM 与 nanollava 的性能对比。在所有任务中,OmniVLM 的表现都超过了之前世界上最小的视觉-语言模型。
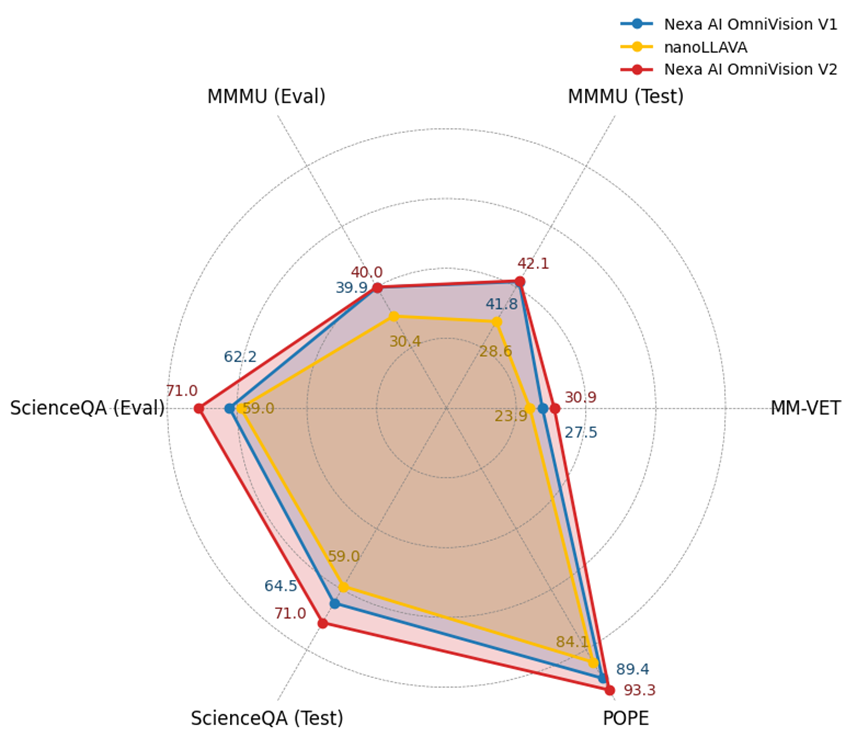
我们在基准数据集上进行了一系列实验,包括 MM-VET、ChartQA、MMMU、ScienceQA、POPE 来评估 OmniVLM 的性能。
| 基准测试 | Nexa AI OmniVLM v2 | Nexa AI OmniVLM v1 | nanoLLAVA |
|---|---|---|---|
| ScienceQA (评估) | 71.0 | 62.2 | 59.0 |
| ScienceQA (测试) | 71.0 | 64.5 | 59.0 |
| POPE | 93.3 | 89.4 | 84.1 |
| MM-VET | 30.9 | 27.5 | 23.9 |
| ChartQA (测试) | 61.9 | 59.2 | NA |
| MMMU (测试) | 42.1 | 41.8 | 28.6 |
| MMMU (评估) | 40.0 | 39.9 | 30.4 |