摘要
随着大语言模型(LLMs)和大推理模型(LRMs)的能力不断提升,构建具备长期任务规划与复杂信息检索能力的智能体Agent成为关键研究方向。阿里通义实验室提出WebDancer------一套从数据构建到训练策略的端到端信息检索智能体构建范式,支持多轮、多工具交互与长程推理。该系统在 GAIA与 WebWalkerQA 等复杂多跳信息检索任务中表现优异,验证其方法有效性与可扩展性。
- 论文标题:WebDancer: Towards Autonomous Information Seeking Agency
- 论文链接:arxiv.org/abs/2505.22...
- 发表单位:阿里-通义实验室
要点总结
WebDancer 提供了构建自主信息检索智能体的系统路径,技术要点如下:
- 端到端智能体构建范式:提出四阶段流程,1)数据构造、2)轨迹采样、3)冷启动微调与 4)强化学习泛化;
- 高质量 QA 数据集自动合成:设计 CRAWLQA 与 E2HQA 两种合成策略,分别针对结构化网页与逐步复杂化问题;
- 推理轨迹采样与建模策略:结合 LLM 与 LRM,采集 Short-CoT 与 Long-CoT 轨迹,覆盖短链与长链推理路径;
- 动态采样强化学习算法 DAPO:优化采样与奖励机制,提升策略鲁棒性与数据效率,支持多轮多工具智能行为。
1 引言
WebDancer 的核心目标是构建能够在真实 Web 环境中实现自主搜索、点击与读取,并完成复杂推理任务的智能体系统。其具备以下三项能力:
- 在动态 Web 环境中自主获取与处理信息;
- 将复杂问题逐步拆解为子任务,并依赖外部工具交错执行;
- 在面对未知任务与长程推理时具备良好的泛化能力。
构建这样的智能体面临多重挑战,包括:1)数据稀缺:真实世界多跳推理与信息操作任务的数据集极为有限;2)训练困难:多轮交互 + 多工具调用会造成 RL 训练不稳定;3)泛化困难:代理模型在真实动态 Web 环境中难以应对变化和长程目标。
2 方法
WebDancer 的构建流程分为四个阶段:
Step 1:构建高质量 QA 数据对
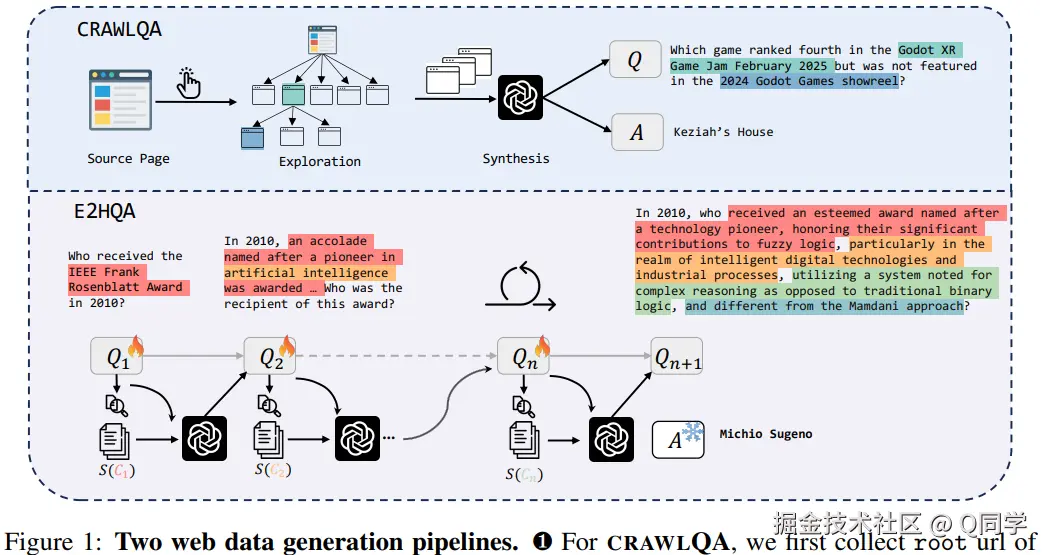
如图1所示,使用两种方式构建数据集:
- CRAWLQA:模拟人类浏览行为,爬取 Arxiv、GitHub、Wiki 等专业网站的结构化页面,系统点击子链接,采集子页面内容,调用 GPT-4o 基于 COUNT、MULTI-HOP 等设定类型合成问答;
- E2HQA:从 SimpleQA 风格出发,通过迭代搜索与问题改写,逐步提高问题复杂度,每轮引入新的子问题构建步骤,使原问题转化为需要长链推理的新问题。
Step 2:采样高质量推理轨迹
- 基于 ReAct 框架,采集 Thought-Action-Observation 的完整交互轨迹;
- 使用 GPT-4o 生成 Short-CoT,QwQ-Plus 生成 Long-CoT;
- 对所有轨迹执行 rejection sampling,并通过合法性、正确性与质量三重过滤确保样本可用。
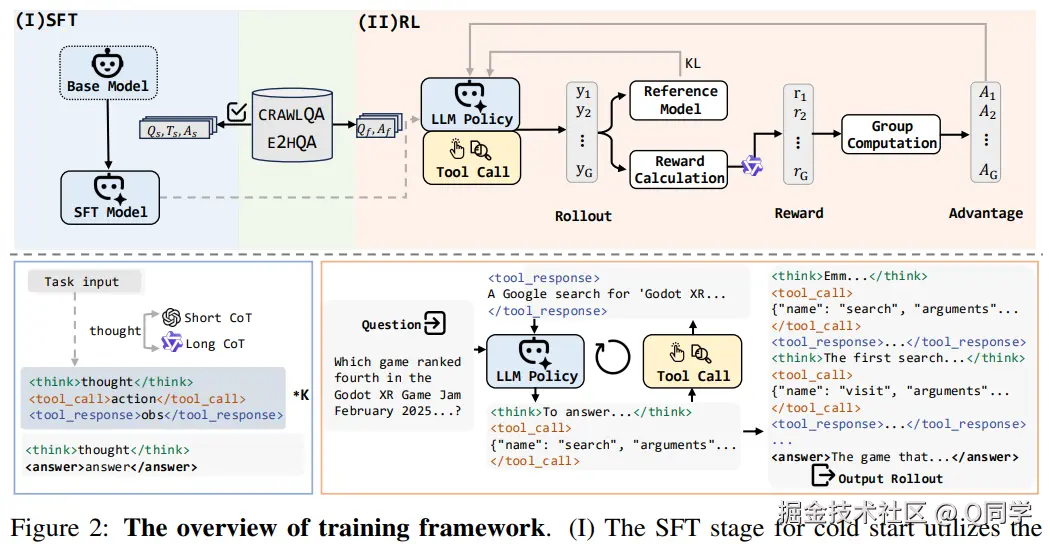
Step 3:监督微调实现冷启动
采用结构化格式(、<tool_call>、<tool_response>、)标注训练数据; 训练策略模型,将工具调用输出部分(Observation)进行MASK,防止模型在学习早期被外部信息干扰。
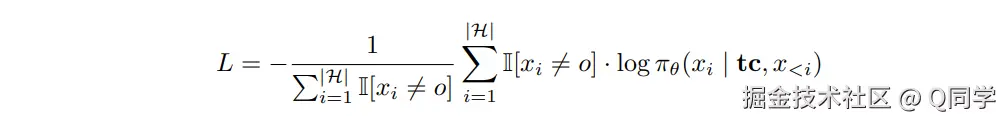
Step 4:强化学习实现泛化
使用 DAPO算法优化策略(最大化公式(3)); 奖励设计为 0/1 二元打分,考虑格式合法性(score_format)与答案准确性(score_answer),其中正确性分数使用裁判模型(Qwen2.5-72B-Instruct)判定。
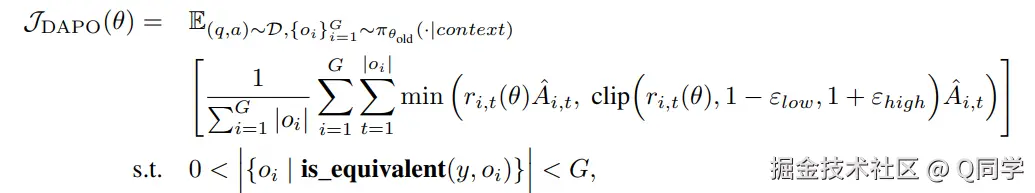
3 实验
实验结果
在 GAIA 与 WebWalkerQA 上,WebDancer 显著优于无代理能力的方法; 在开源模型中,WebDancer 在 ReAct 框架下性能远超 vanilla ReAct,甚至在某些设置下超越 GPT-4o。
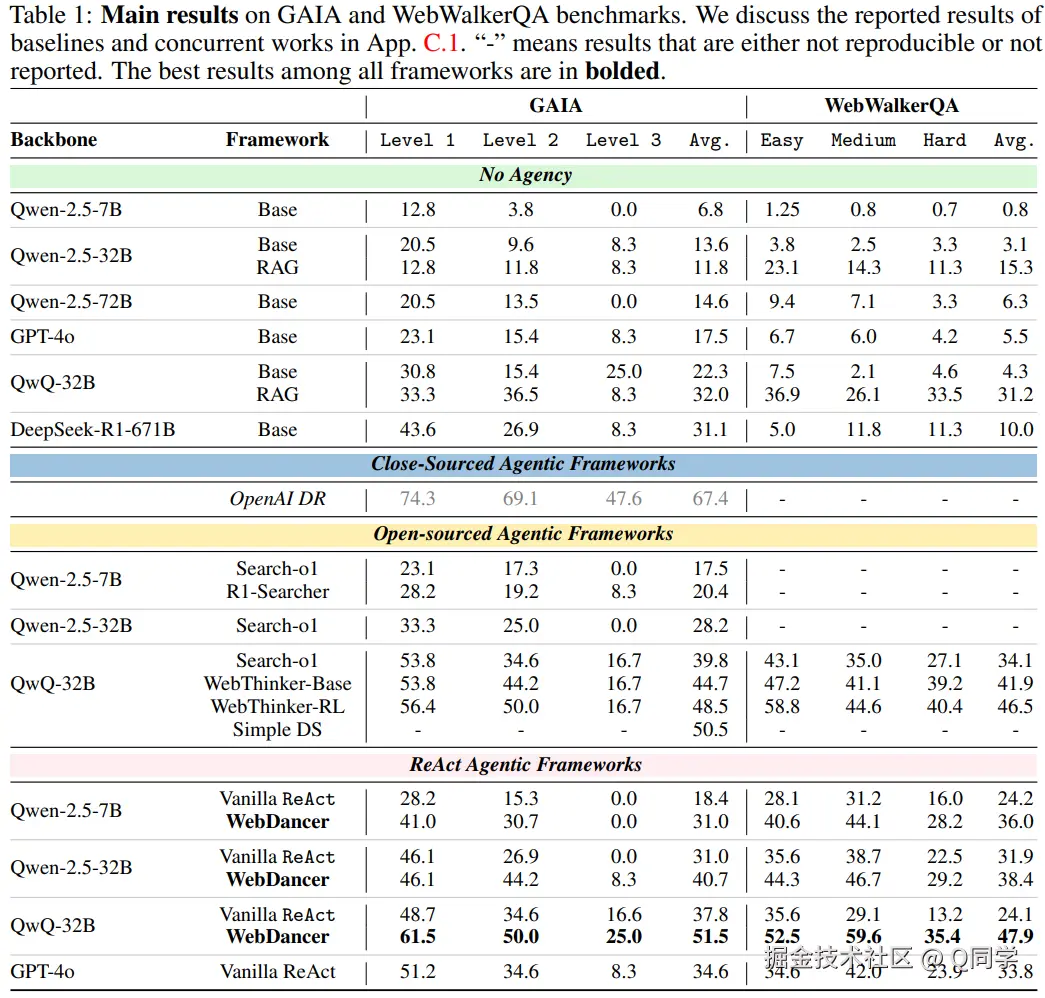
高难度任务测试
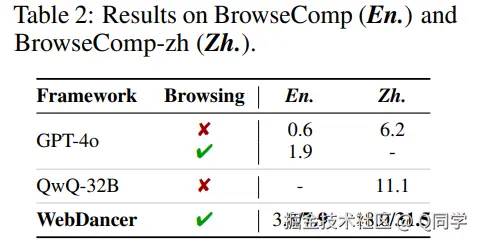
在 BrowseComp(英文) 和 BrowseComp-zh(中文) 数据集上表现稳定,凸显 WebDancer 在跨语言与复杂搜索场景中的适应能力。
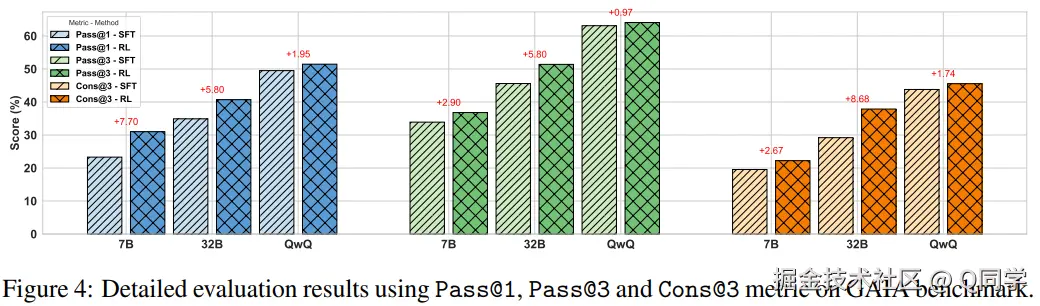
长短思维链分析
对于非推理模型,强化学习显著提升回答一致性与 Pass@3 表现; 对于推理模型(如 QwQ-Plus),RL 虽提升幅度有限,但明显提升 Cons@3(思维路径一致性)。
4 总结与未来工作
WebDancer提出了一种系统化、端到端的多步信息检索代理构建范式,覆盖从数据构建、轨迹采样、思维建模到策略优化全过程,未来工作可以在以下几个方面开展:
- 引入更复杂工具(如浏览器模拟器、Python sandbox)以支持开放式环境交互;
- 拓展至文档级生成与多模态任务,例如网页摘要生成、图文混合搜索等;
- 优化 RL 稳定性与样本效率,如引入记忆机制、压缩 rollout 成本;
- 开发混合推理模型(hybrid reasoning agent),支持动态控制推理长度与策略分支。
案例展示
作者在最后附了一个较长的案例展示,案例展示的问题来自于GAIA
-
问题:我正在研究那些在人们将其作为宠物饲养后被释放,并最终成为入侵物种的生物。有一种鱼类因为成为电影《海底总动员》的主角而在宠物市场上广受欢迎。根据 USGS 的数据,该鱼在 2020 年之前在哪些地方作为非原生物种被发现?我需要答案以五位数邮政编码(ZIP code)的形式呈现,若有多个地点,用逗号分隔。
-
模型回答:模型进行多次搜索和访问,这里进行了多工具调用,包括search进行搜索引擎查询,visit访问特定网页链接,获取文本。


