生产级中间件的Java网络通信技术深度优化
134_完成读取本地磁盘文件以及发送给客户端的代码逻辑
java
public class DataNodeNIOServer extends Thread {
private Map<String, String> waitReadingFiles = new ConcurrentHashMap<String, String>();
/**
* 将文件发送到客户端去
* @param channel
* @param key
* @throws Exception
*/
private void sendFileToClient(SocketChannel channel, SelectionKey key) throws Exception {
// 构建针对本地文件的输入流
if(!channel.isOpen()) {
channel.close();
return;
}
String remoteAddr = channel.getRemoteAddress().toString();
String filename = waitReadingFiles.get(remoteAddr);
File file = new File(filename);
Long fileLength = file.length();
FileInputStream imageIn = new FileInputStream(filename);
FileChannel imageChannel = imageIn.getChannel();
// 循环不断的从channel里读取数据,并写入磁盘文件
ByteBuffer buffer = ByteBuffer.allocate(
Integer.parseInt(String.valueOf(fileLength)) * 2);
long hasReadImageLength = 0L;
int len = -1;
while((len = imageChannel.read(buffer)) > 0) {
hasReadImageLength += len;
System.out.println("已经从本地磁盘文件读取了" + hasReadImageLength + "字节的数据");
buffer.flip();
channel.write(buffer);
buffer.clear();
}
imageChannel.close();
imageIn.close();
// 判断一下,如果已经读取完毕,就返回一个成功给客户端
if(hasReadImageLength == fileLength) {
System.out.println("文件发送完毕,给客户端: " + remoteAddr);
}
}
}按理说,上面数据写完以后,需要把waitReadingFiles中的数据删除
135_在NIO中处理完一次读写请求之后应该如何处理事件的监听?
上面的实现方式,是把Read事件和Write事件,分开作两个流程进行处理,实际上,也不用那么麻烦,直接在处理Read事件时,就从磁盘中读出文件并通过channel写回到客户端即可。
waitReadingFiles的逻辑,也都就不需要了
java
/**
* 数据节点的NIOServer
*/
public class DataNodeNIOServer extends Thread {
public static final Integer SEND_FILE = 1;
public static final Integer READ_FILE = 2;
// NIO的selector,负责多路复用监听多个连接的请求
private Selector selector;
// 内存队列,无界队列
private List<LinkedBlockingQueue<SelectionKey>> queues =
new ArrayList<LinkedBlockingQueue<SelectionKey>>();
// 缓存的没读取完的文件数据
private Map<String, CachedImage> cachedImages = new ConcurrentHashMap<String, CachedImage>();
// 与NameNode进行通信的客户端
private NameNodeRpcClient namenodeRpcClient;
/**
* NIOServer的初始化,监听端口、队列初始化、线程初始化
*/
public DataNodeNIOServer(NameNodeRpcClient namenodeRpcClient) {
ServerSocketChannel serverSocketChannel = null;
try {
this.namenodeRpcClient = namenodeRpcClient;
selector = Selector.open();
serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false);
serverSocketChannel.socket().bind(new InetSocketAddress(NIO_PORT), 100);
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
for (int i = 0; i < 3; i++) {
queues.add(new LinkedBlockingQueue<SelectionKey>());
}
for (int i = 0; i < 3; i++) {
new Worker(queues.get(i)).start();
}
System.out.println("NIOServer已经启动,开始监听端口:" + NIO_PORT);
} catch (IOException e) {
e.printStackTrace();
}
}
public void run() {
/**
* 无限循环,等待IO多路复用方式监听请求
*/
while (true) {
try {
selector.select();
Iterator<SelectionKey> keysIterator = selector.selectedKeys().iterator();
while (keysIterator.hasNext()) {
SelectionKey key = keysIterator.next();
keysIterator.remove();
handleEvents(key);
}
} catch (Throwable t) {
t.printStackTrace();
}
}
}
/**
* 处理请求分发
*
* @param key
* @throws IOException
* @throws ClosedChannelException
*/
private void handleEvents(SelectionKey key) throws IOException {
SocketChannel channel = null;
try {
if (key.isAcceptable()) {
ServerSocketChannel serverSocketChannel = (ServerSocketChannel) key.channel();
channel = serverSocketChannel.accept();
if (channel != null) {
channel.configureBlocking(false);
channel.register(selector, SelectionKey.OP_READ);
}
} else if (key.isReadable()) {
channel = (SocketChannel) key.channel();
String remoteAddr = channel.getRemoteAddress().toString();
int queueIndex = remoteAddr.hashCode() % queues.size();
queues.get(queueIndex).put(key);
}
} catch (Throwable t) {
t.printStackTrace();
if (channel != null) {
channel.close();
}
}
}
/**
* 处理请求的工作线程
*/
class Worker extends Thread {
private LinkedBlockingQueue<SelectionKey> queue;
public Worker(LinkedBlockingQueue<SelectionKey> queue) {
this.queue = queue;
}
@Override
public void run() {
while (true) {
SocketChannel channel = null;
try {
SelectionKey key = queue.take();
channel = (SocketChannel) key.channel();
handleRequest(channel, key);
} catch (Exception e) {
e.printStackTrace();
if (channel != null) {
try {
channel.close();
} catch (IOException e1) {
e1.printStackTrace();
}
}
}
}
}
}
/**
* 处理客户端发送过来的请求
*
* @param channel
* @param key
* @throws Exception
*/
private void handleRequest(SocketChannel channel, SelectionKey key) throws Exception {
// 假如说你这个一次读取的数据里包含了多个文件的话
// 这个时候我们会先读取文件名,然后根据文件的大小去读取这么多的数据
String remoteAddr = channel.getRemoteAddress().toString();
System.out.println("接收到客户端的请求:" + remoteAddr);
// 需要先提取出来这次请求是什么类型:1 发送文件;2 读取文件
if (cachedImages.containsKey(remoteAddr)) {
handleSendFileRequest(channel, key);
} else {
// 但是此时channel的position肯定也变为了4
Integer requestType = getRequestType(channel);
if (SEND_FILE.equals(requestType)) {
handleSendFileRequest(channel, key);
} else if (READ_FILE.equals(requestType)) {
handleReadFileRequest(channel, key);
}
}
}
/**
* 发送文件
*/
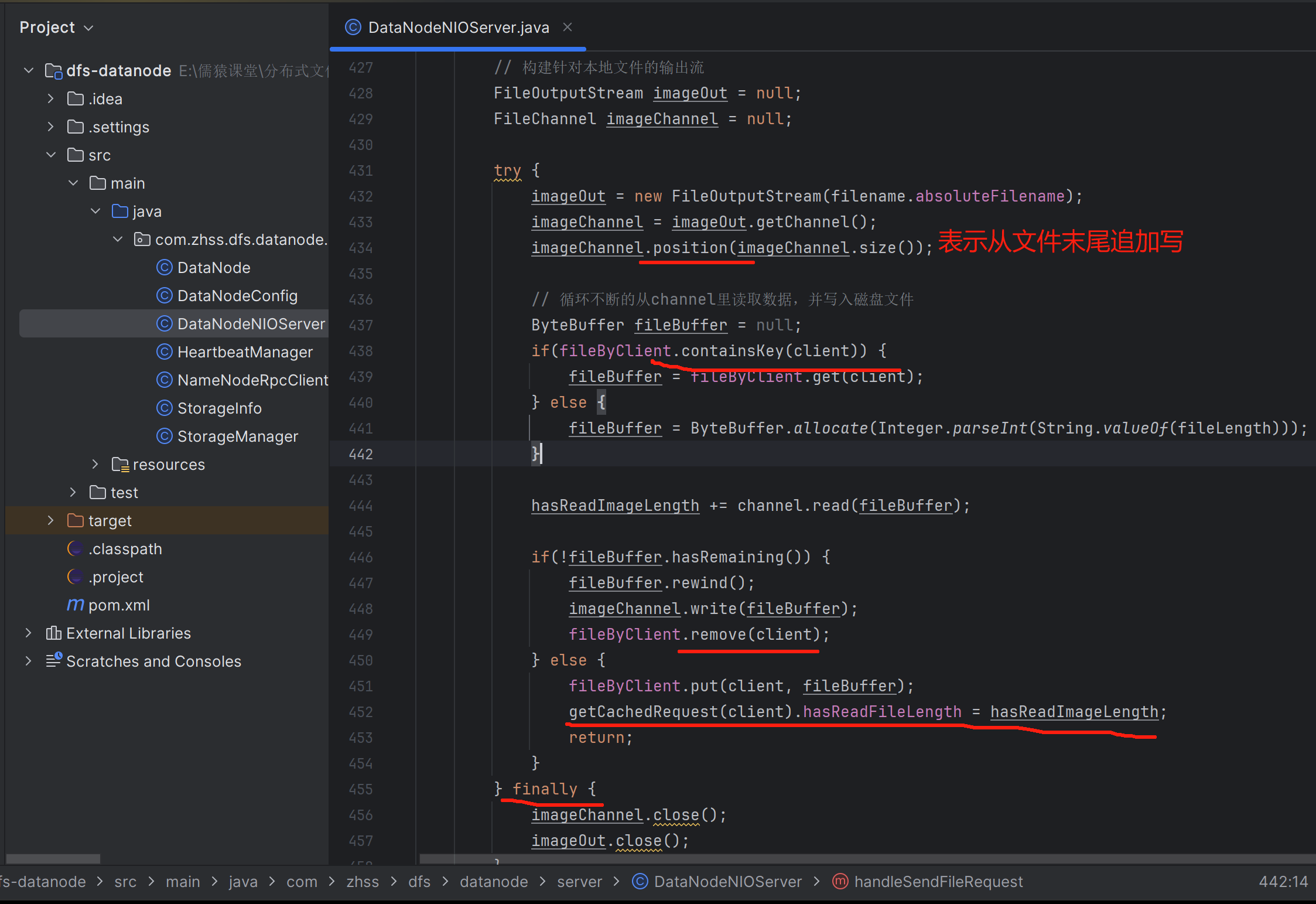
private void handleSendFileRequest(SocketChannel channel, SelectionKey key) throws Exception {
String remoteAddr = channel.getRemoteAddress().toString();
Filename filename = getFilename(channel);
System.out.println("从网络请求中解析出来文件名:" + filename);
if (filename == null) {
channel.close();
return;
}
// 从请求中解析文件大小
long imageLength = getImageLength(channel);
System.out.println("从网络请求中解析出来文件大小:" + imageLength);
// 定义已经读取的文件大小
long hasReadImageLength = getHasReadImageLength(channel);
System.out.println("初始化已经读取的文件大小:" + hasReadImageLength);
// 构建针对本地文件的输出流
FileOutputStream imageOut = new FileOutputStream(filename.absoluteFilename);
FileChannel imageChannel = imageOut.getChannel();
imageChannel.position(imageChannel.size());
// 循环不断的从channel里读取数据,并写入磁盘文件
ByteBuffer buffer = ByteBuffer.allocate(10 * 1024);
int len = -1;
while ((len = channel.read(buffer)) > 0) {
hasReadImageLength += len;
System.out.println("已经向本地磁盘文件写入了" + hasReadImageLength + "字节的数据");
buffer.flip();
imageChannel.write(buffer);
buffer.clear();
}
imageChannel.close();
imageOut.close();
// 判断一下,如果已经读取完毕,就返回一个成功给客户端
if (hasReadImageLength == imageLength) {
ByteBuffer outBuffer = ByteBuffer.wrap("SUCCESS".getBytes());
channel.write(outBuffer);
cachedImages.remove(remoteAddr);
System.out.println("文件读取完毕,返回响应给客户端: " + remoteAddr);
// 增量上报Master节点自己接收到了一个文件的副本
// /image/product/iphone.jpg
namenodeRpcClient.informReplicaReceived(filename.relativeFilename);
System.out.println("增量上报收到的文件副本给NameNode节点......");
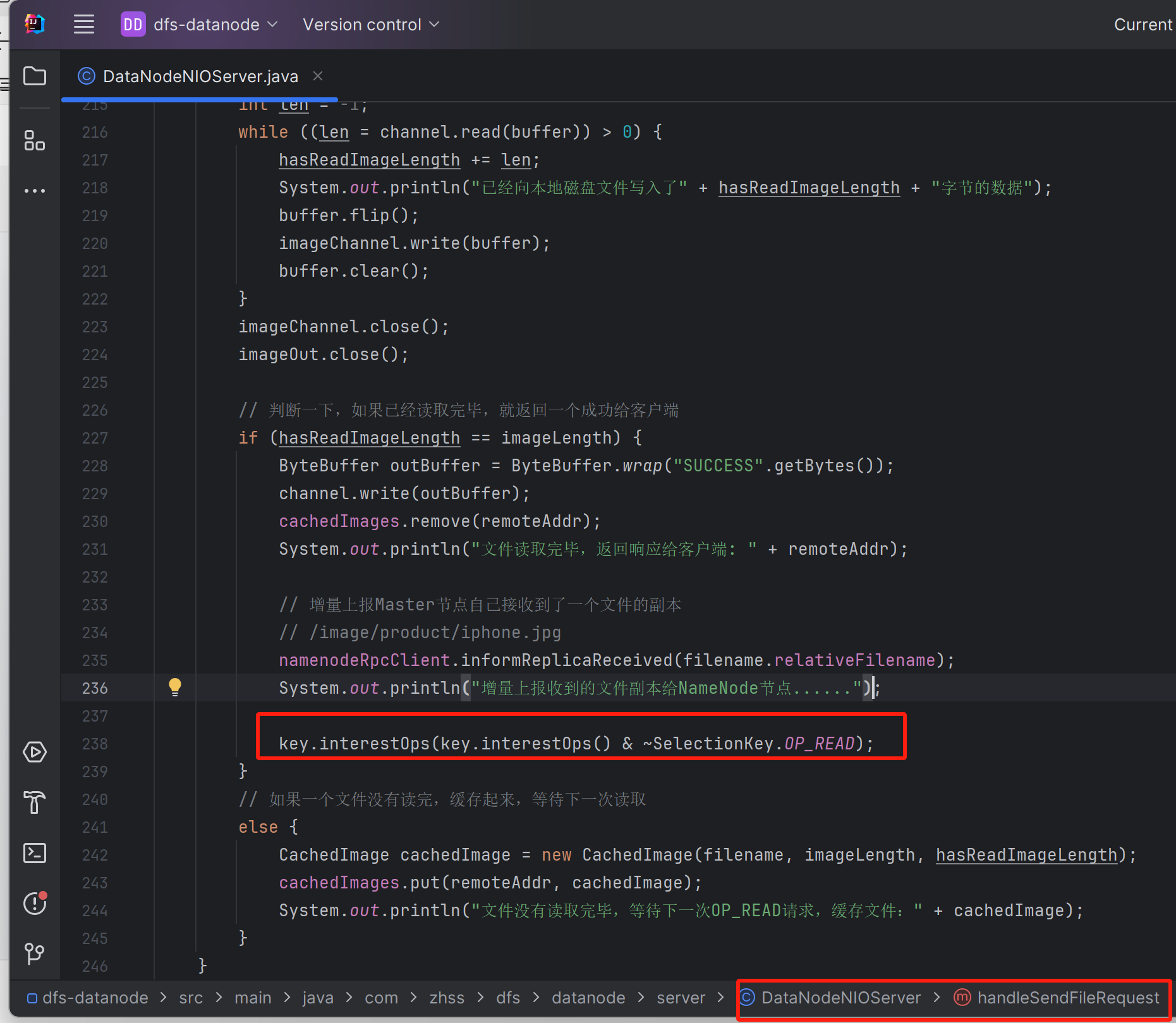
key.interestOps(key.interestOps() & ~SelectionKey.OP_READ);
}
// 如果一个文件没有读完,缓存起来,等待下一次读取
else {
CachedImage cachedImage = new CachedImage(filename, imageLength, hasReadImageLength);
cachedImages.put(remoteAddr, cachedImage);
System.out.println("文件没有读取完毕,等待下一次OP_READ请求,缓存文件:" + cachedImage);
}
}
/**
* 读取文件
*/
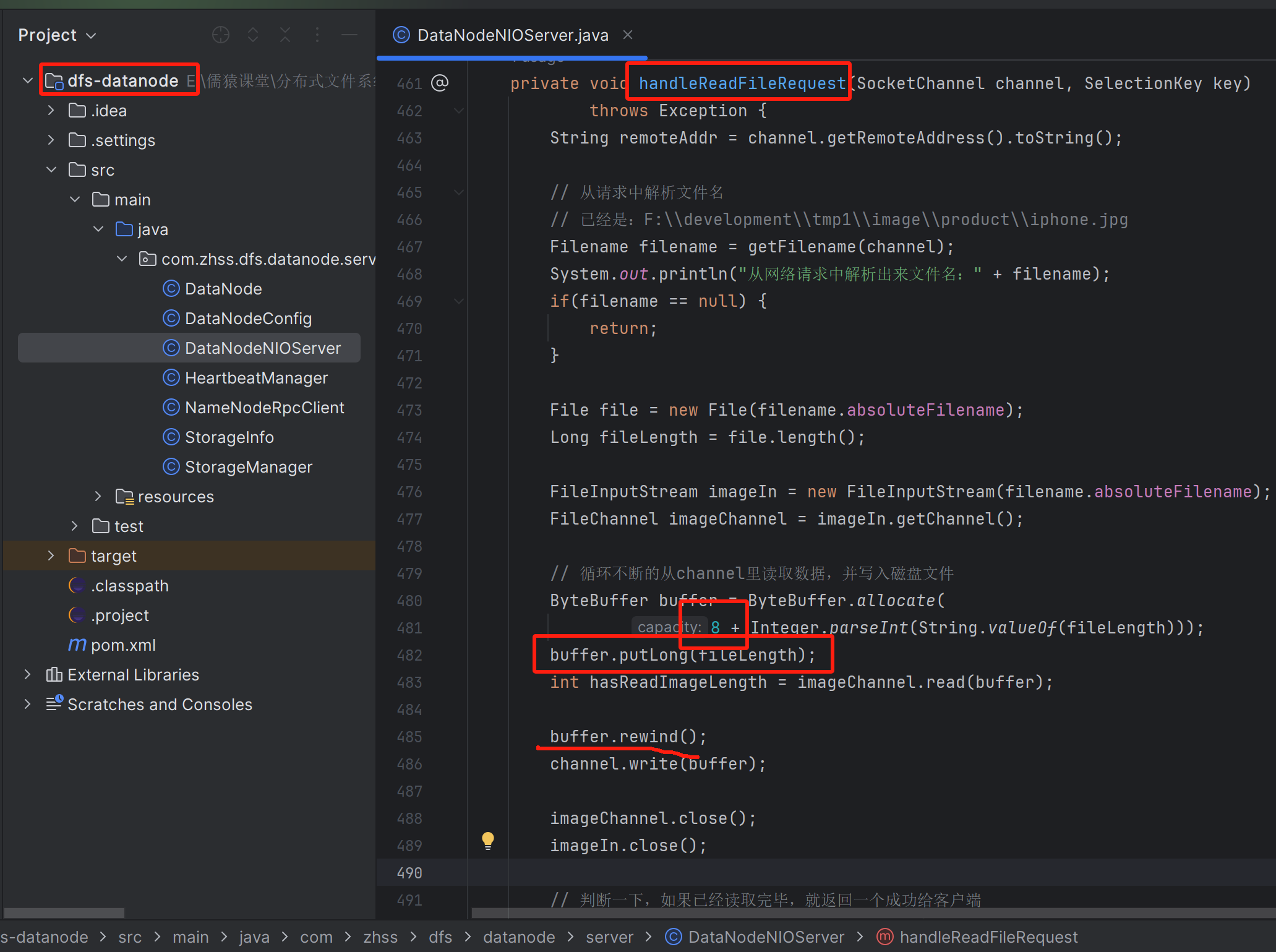
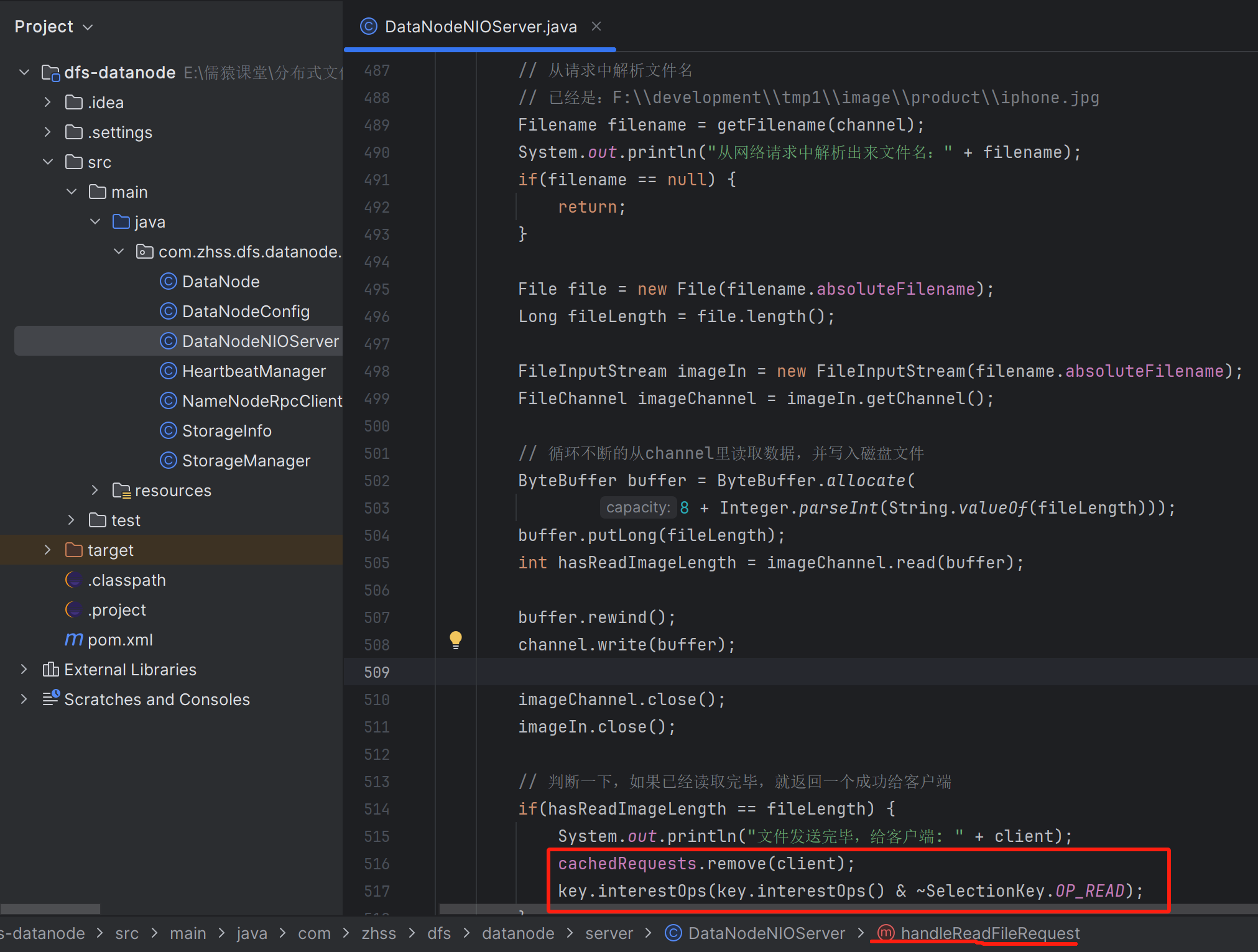
private void handleReadFileRequest(SocketChannel channel, SelectionKey key) throws Exception {
String remoteAddr = channel.getRemoteAddress().toString();
// 从请求中解析文件名
// 已经是:F:\\development\\tmp1\\image\\product\\iphone.jpg
Filename filename = getFilename(channel);
System.out.println("从网络请求中解析出来文件名:" + filename);
if (filename == null) {
channel.close();
return;
}
File file = new File(filename.absoluteFilename);
Long fileLength = file.length();
FileInputStream imageIn = new FileInputStream(filename.absoluteFilename);
FileChannel imageChannel = imageIn.getChannel();
// 循环不断的从channel里读取数据,并写入磁盘文件
ByteBuffer buffer = ByteBuffer.allocate(
Integer.parseInt(String.valueOf(fileLength)) * 2);
long hasReadImageLength = 0L;
int len = -1;
while ((len = imageChannel.read(buffer)) > 0) {
hasReadImageLength += len;
System.out.println("已经从本地磁盘文件读取了" + hasReadImageLength + "字节的数据");
buffer.flip();
channel.write(buffer);
buffer.clear();
}
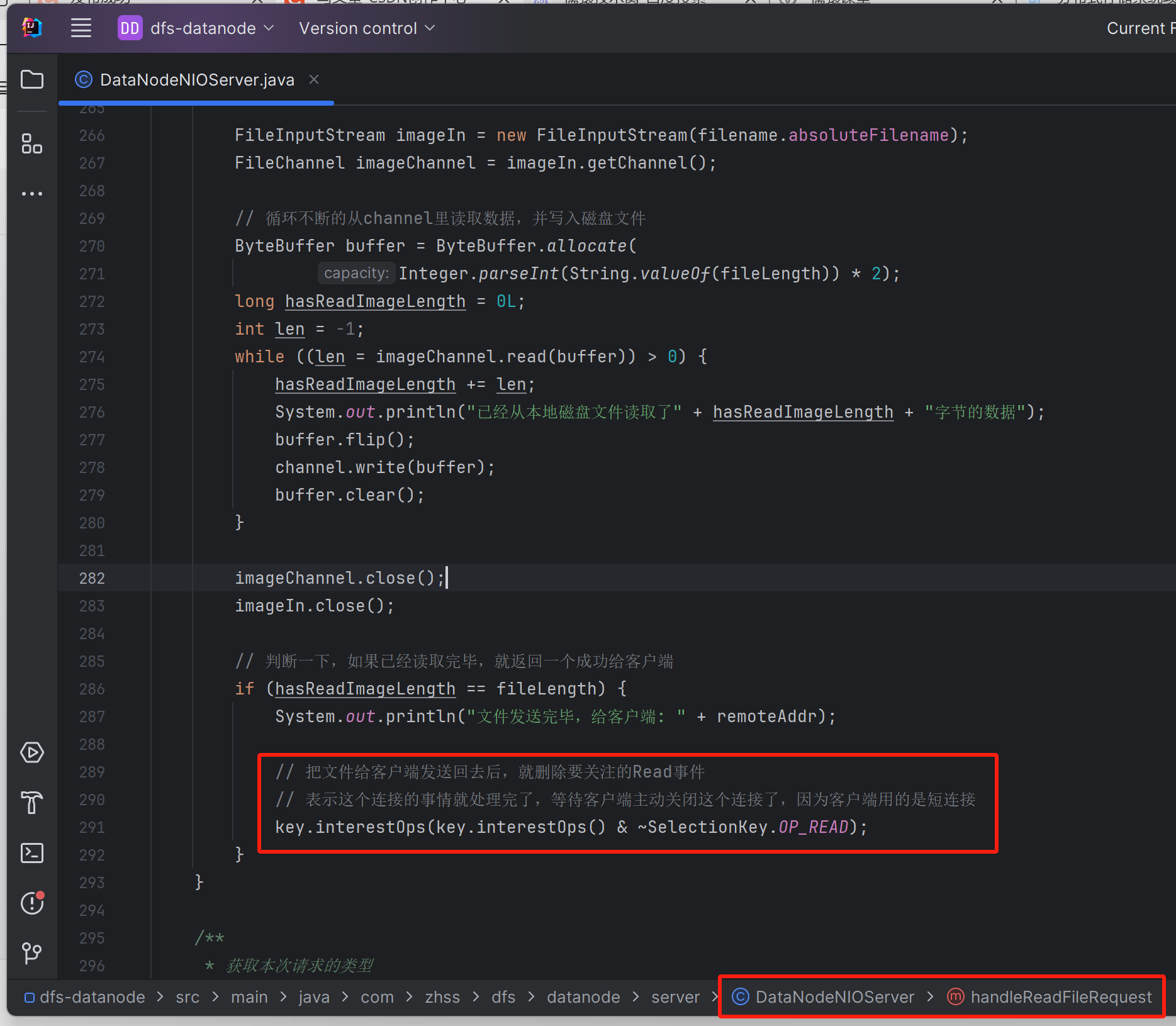
imageChannel.close();
imageIn.close();
// 判断一下,如果已经读取完毕,就返回一个成功给客户端
if (hasReadImageLength == fileLength) {
System.out.println("文件发送完毕,给客户端: " + remoteAddr);
// 把文件给客户端发送回去后,就删除要关注的Read事件
// 表示这个连接的事情就处理完了,等待客户端主动关闭这个连接了,因为客户端用的是短连接
key.interestOps(key.interestOps() & ~SelectionKey.OP_READ);
}
}
/**
* 获取本次请求的类型
*/
public Integer getRequestType(SocketChannel channel) throws Exception {
ByteBuffer requestType = ByteBuffer.allocate(4);
channel.read(requestType); // 此时requestType ByteBuffer,position跟limit都是4,remaining是0
if (!requestType.hasRemaining()) {
// 已经读取出来了4个字节,可以提取出来requestType了
requestType.rewind(); // 将position变为0,limit还是维持着4
return requestType.getInt();
}
return -1;
}
}主要就是加了,取消针对当前通道的Read事件的监听
136_在客户端实现从数据节点接收发送过来的图片数据
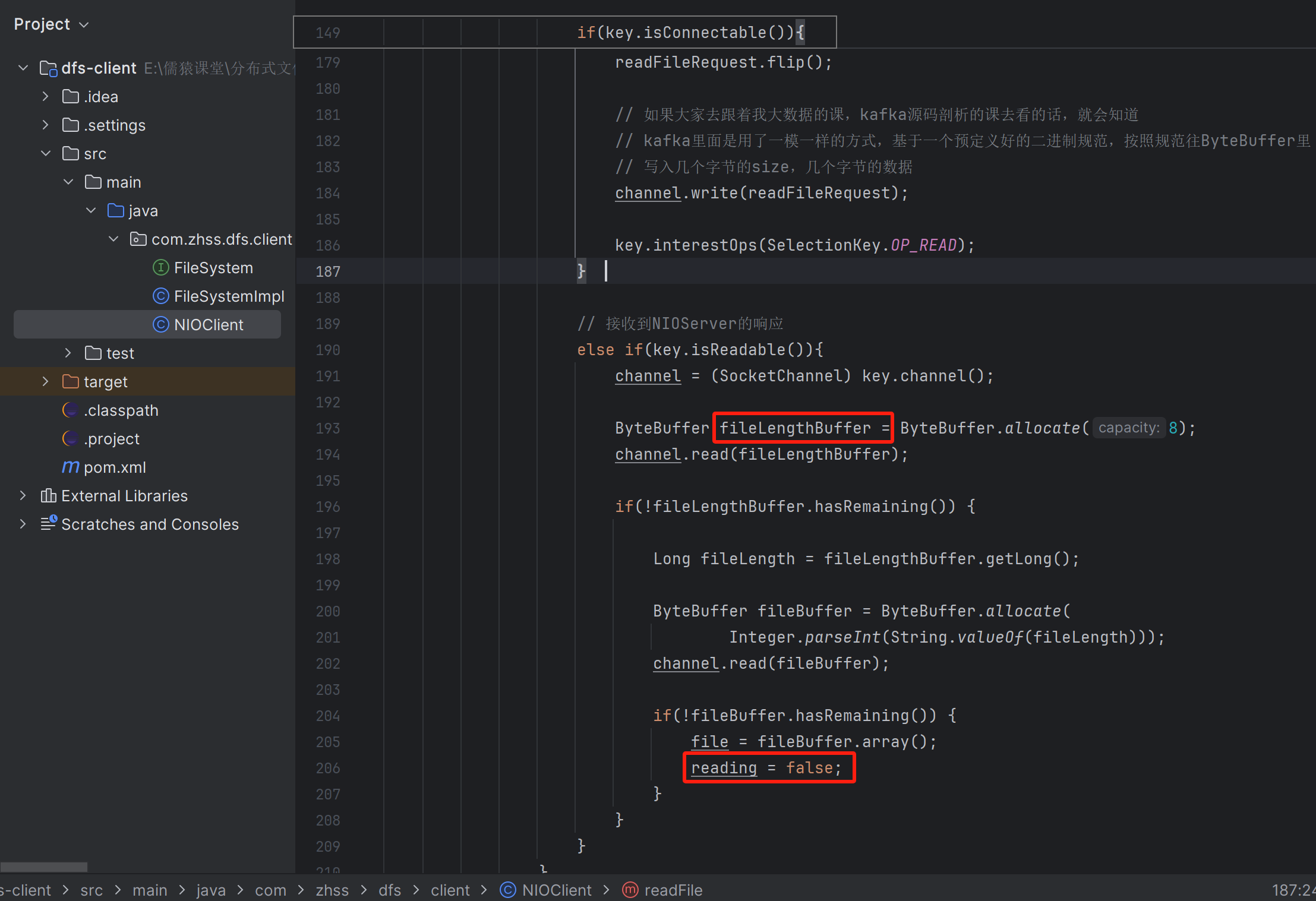
137_工业级NIO通信组件:请求头的拆包问题应该如何解决?
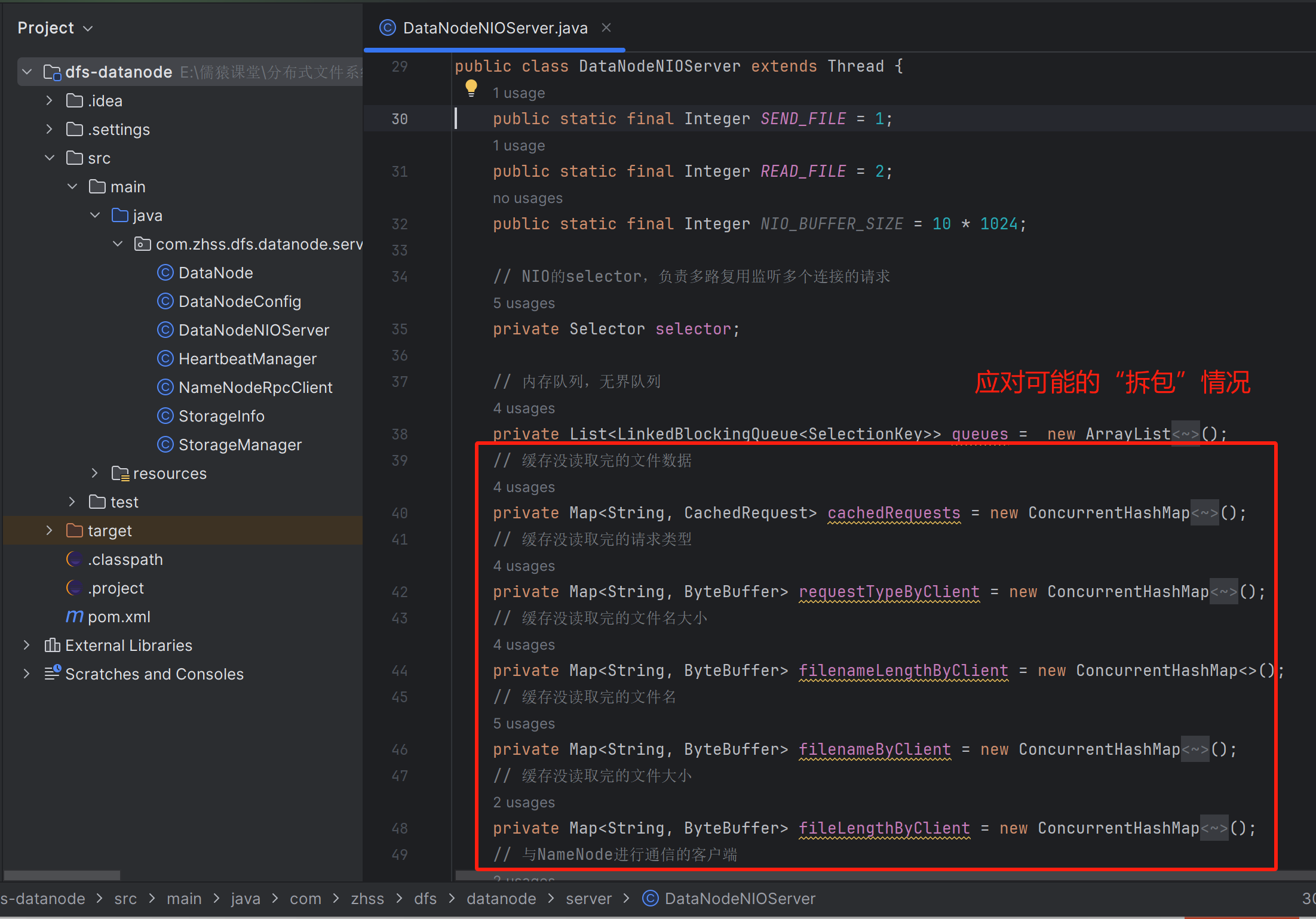
读取请求类型

第237行的remove动作不可少
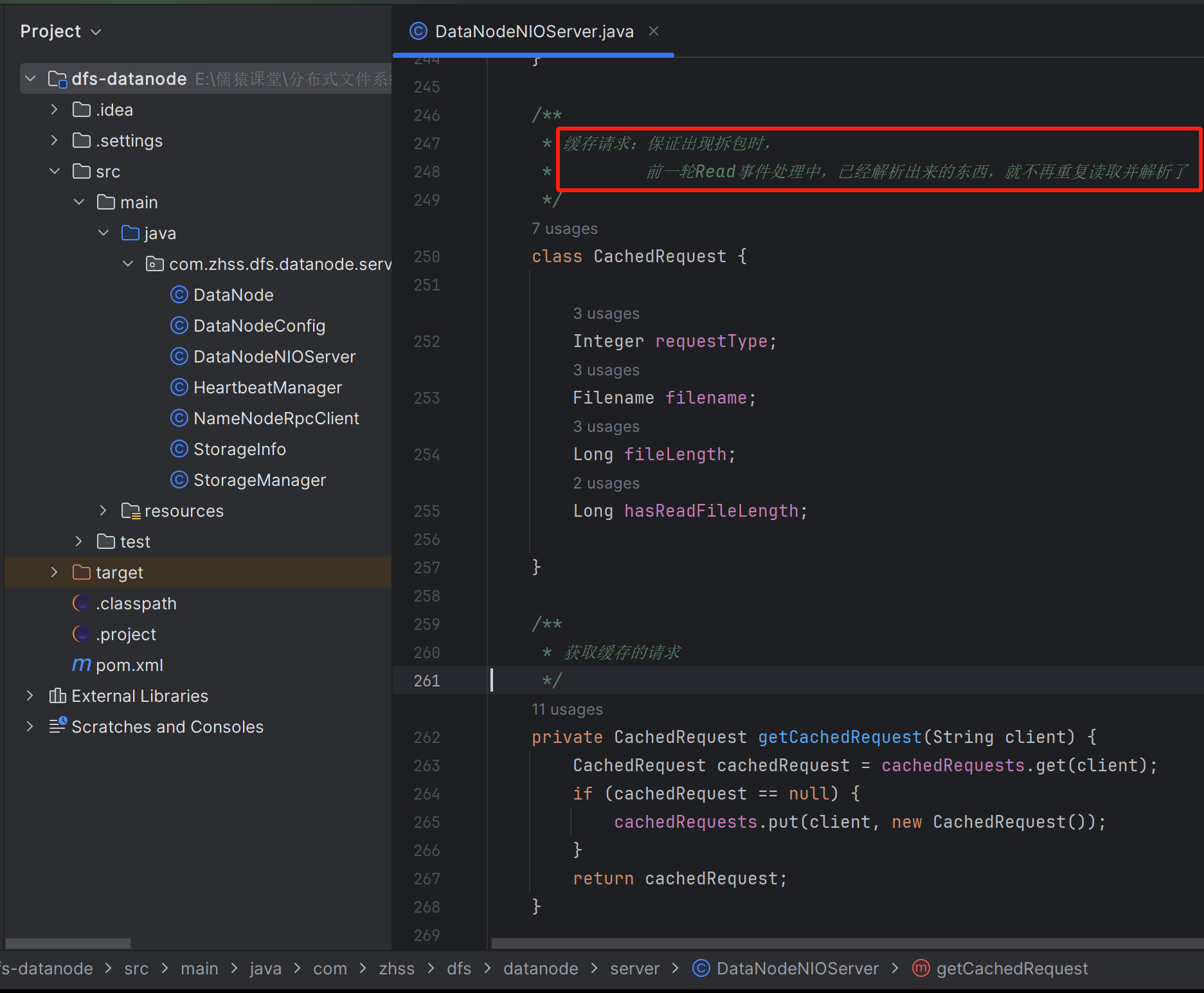
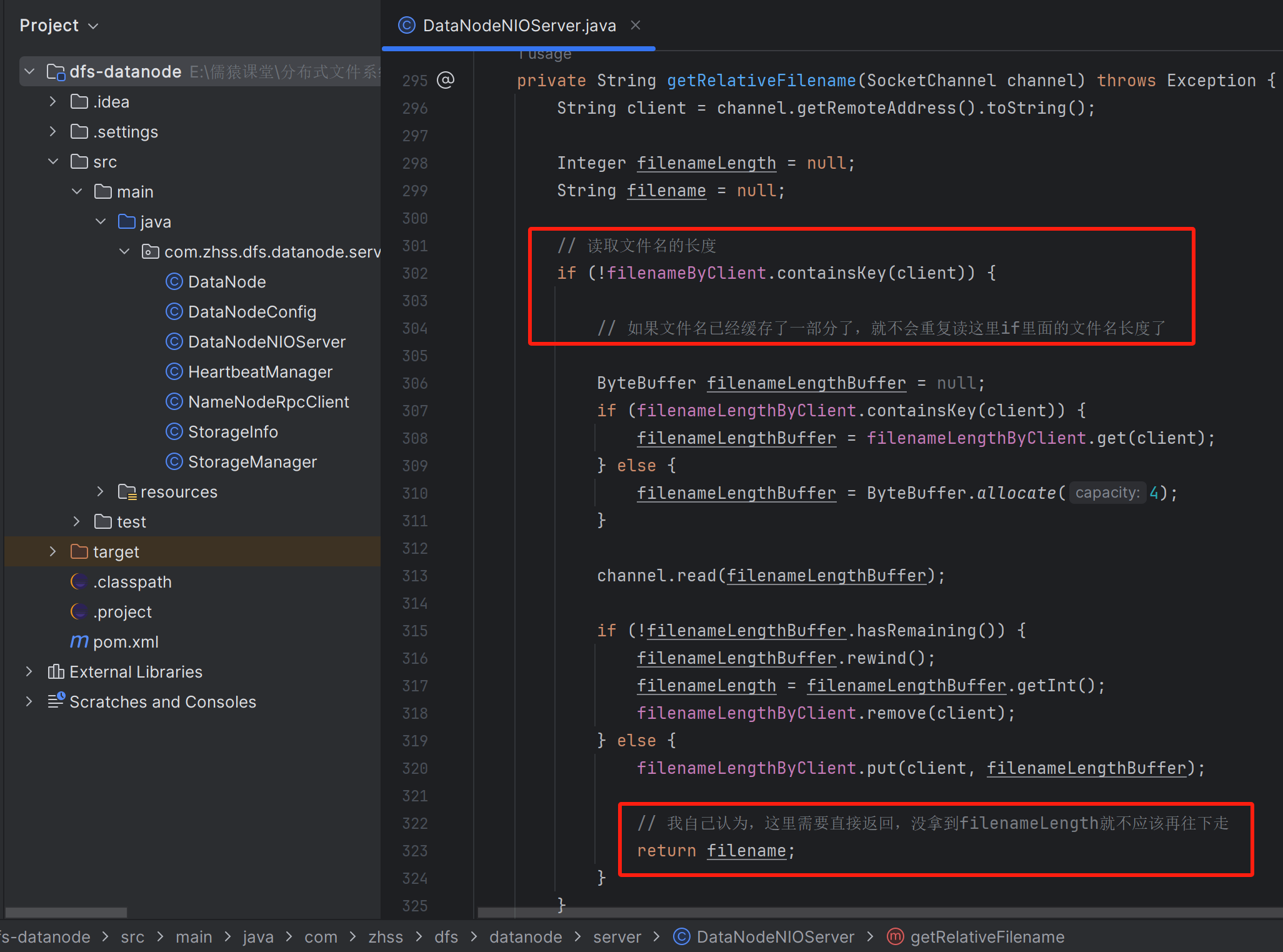
读取文件名
java
/**
* 获取相对路径的文件名
* @param channel
* @return
*/
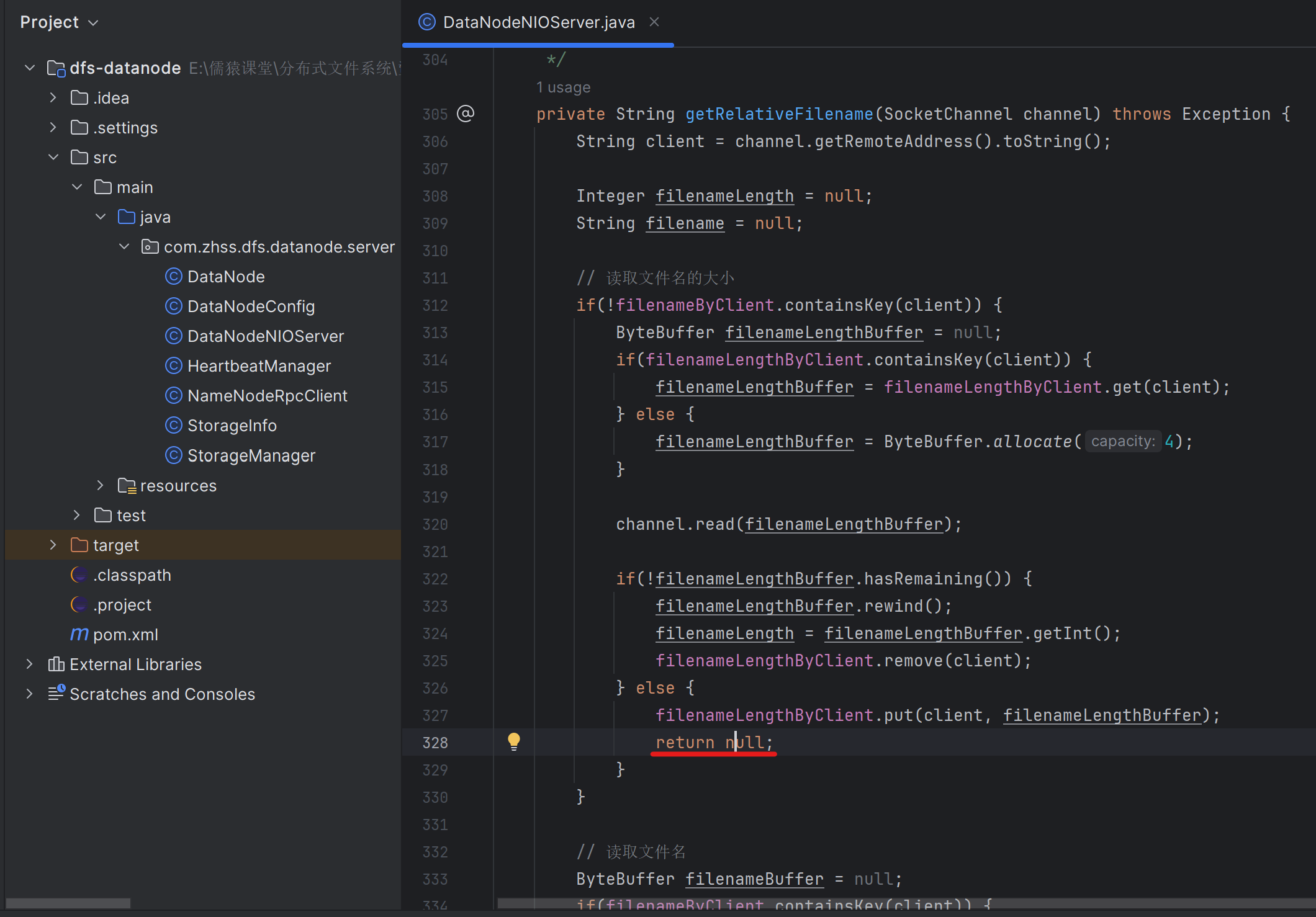
private String getRelativeFilename(SocketChannel channel) throws Exception {
String client = channel.getRemoteAddress().toString();
Integer filenameLength = null;
String filename = null;
// 读取文件名的大小
if(!filenameByClient.containsKey(client)) {
ByteBuffer filenameLengthBuffer = null;
if(filenameLengthByClient.containsKey(client)) {
filenameLengthBuffer = filenameLengthByClient.get(client);
} else {
filenameLengthBuffer = ByteBuffer.allocate(4);
}
channel.read(filenameLengthBuffer);
if(!filenameLengthBuffer.hasRemaining()) {
filenameLengthBuffer.rewind();
filenameLength = filenameLengthBuffer.getInt();
filenameLengthByClient.remove(client);
} else {
filenameLengthByClient.put(client, filenameLengthBuffer);
}
}
// 读取文件名
ByteBuffer filenameBuffer = null;
if(filenameByClient.containsKey(client)) {
filenameBuffer = filenameByClient.get(client);
} else {
filenameBuffer = ByteBuffer.allocate(filenameLength);
}
channel.read(filenameBuffer);
if(!filenameBuffer.hasRemaining()) {
filenameBuffer.rewind();
filename = new String(filenameBuffer.array());
filenameByClient.remove(client);
} else {
filenameByClient.put(client, filenameBuffer);
}
return filename;
}
读取文件长度
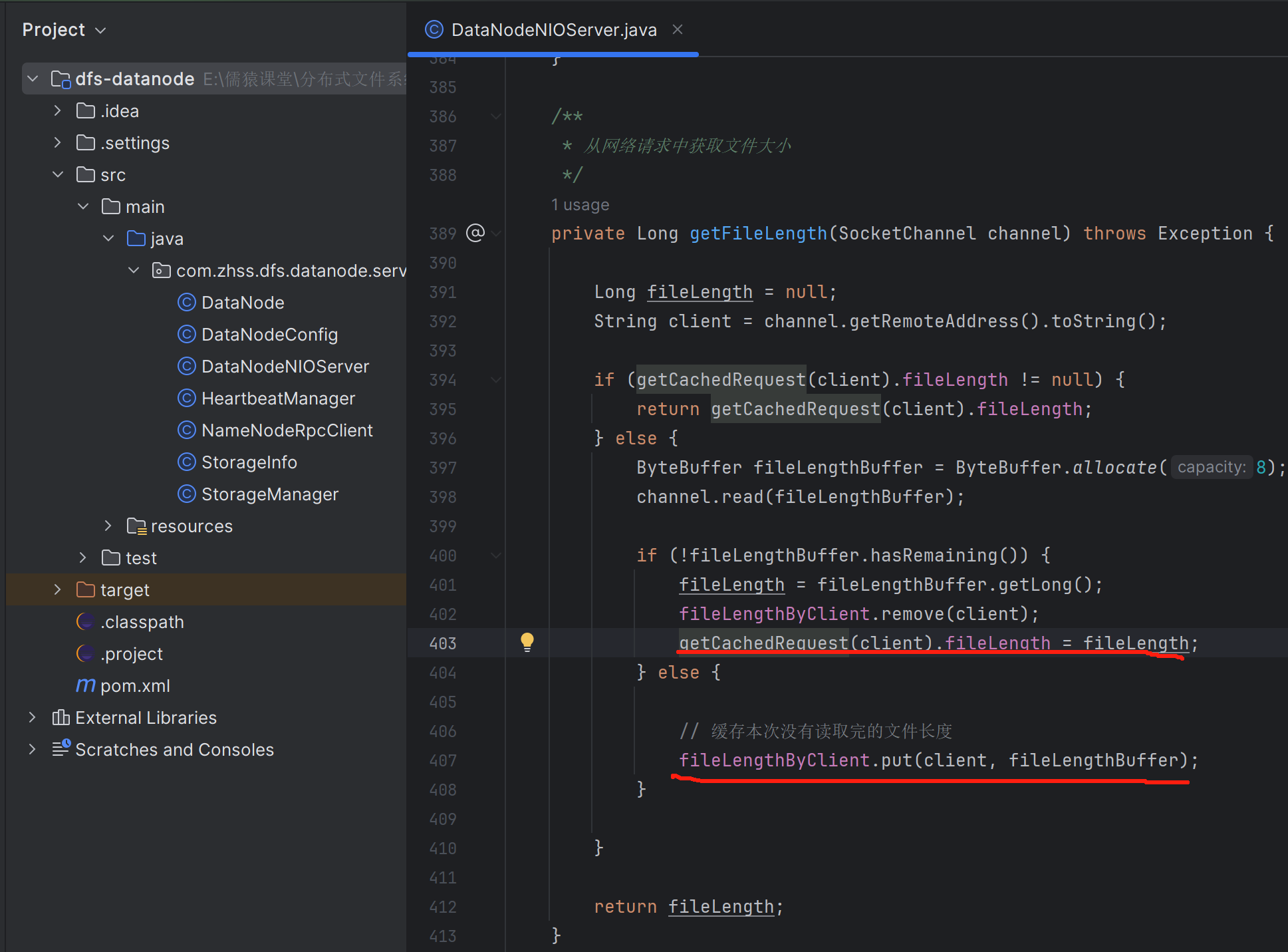
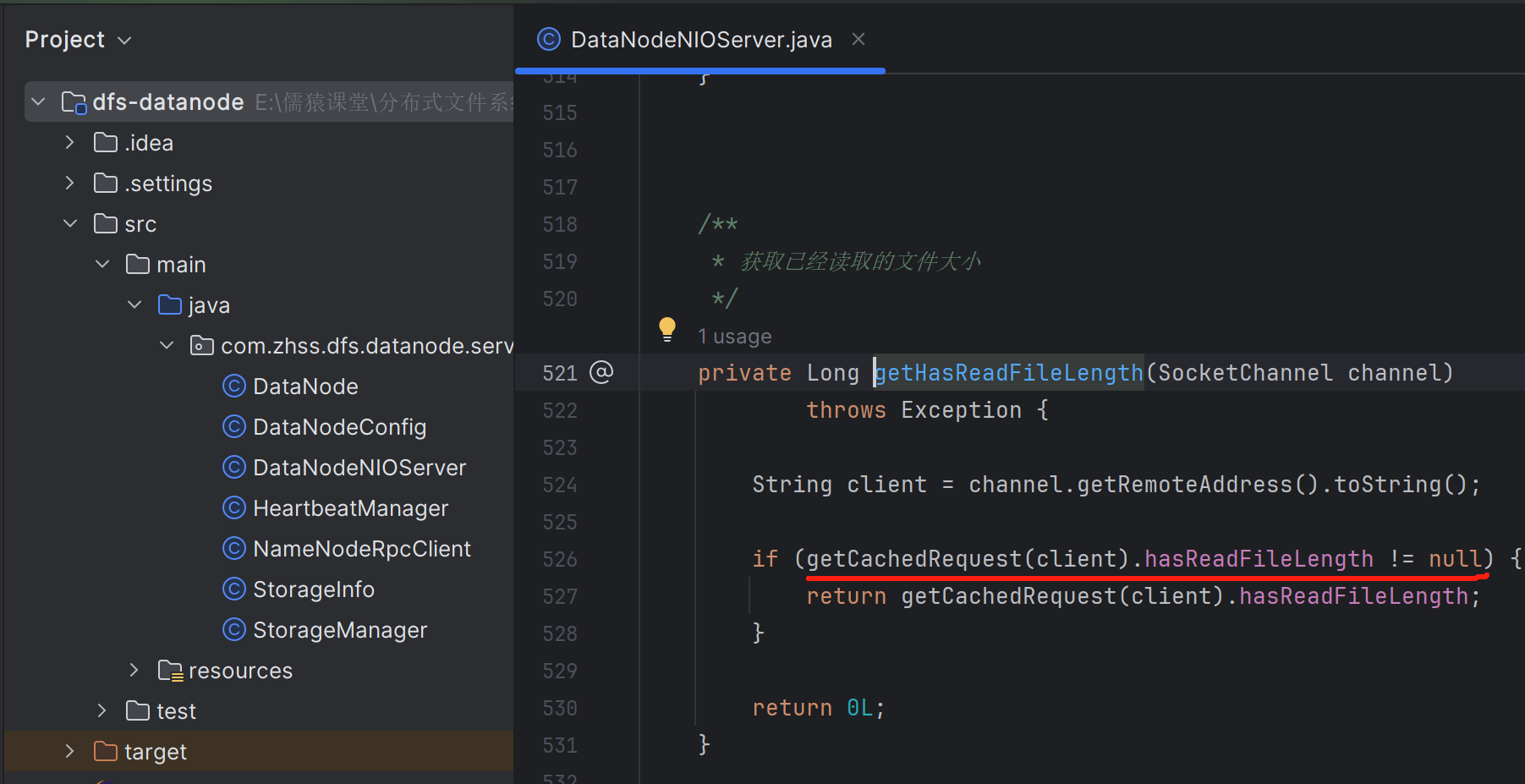
获取已经读取的文件大小
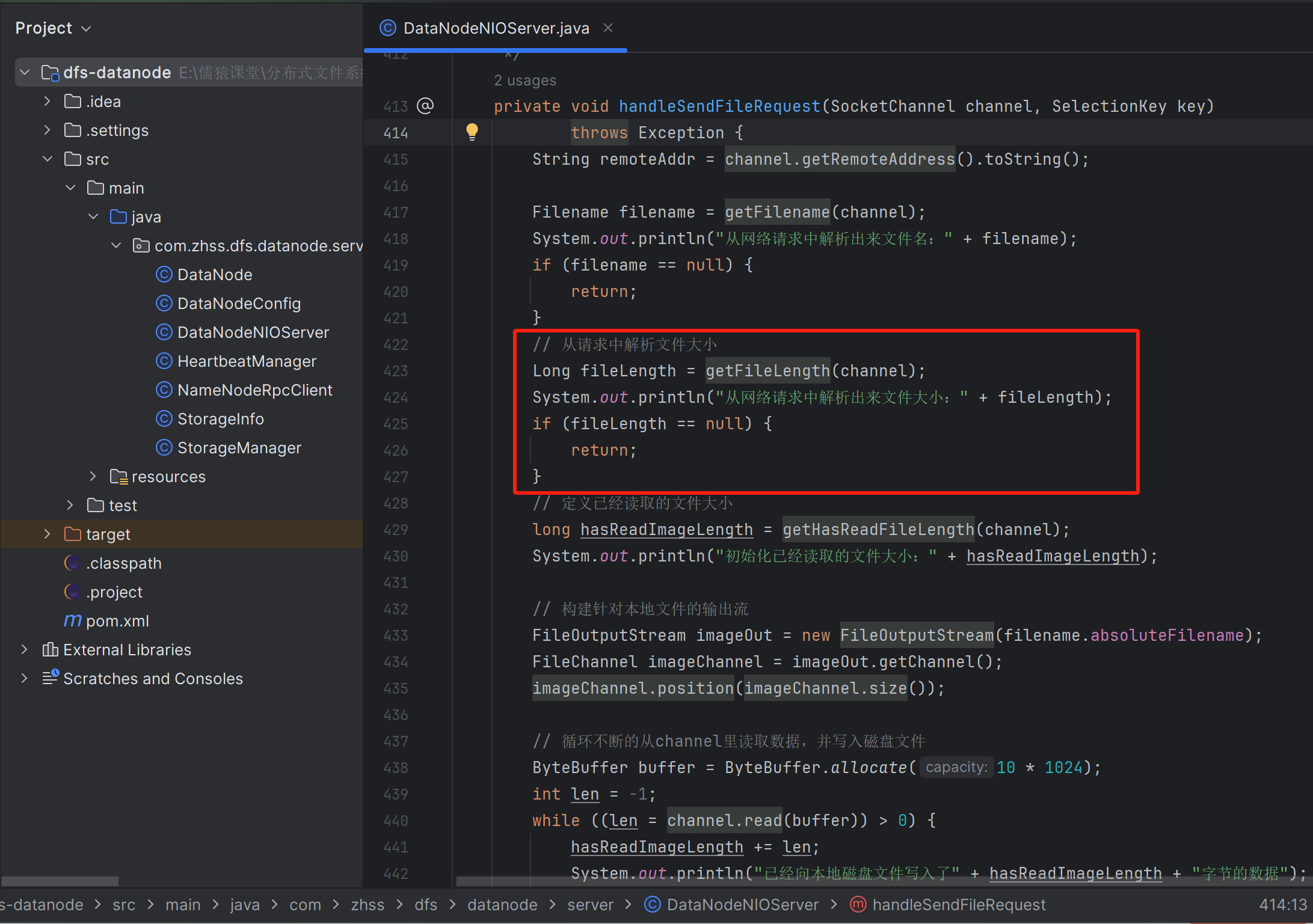
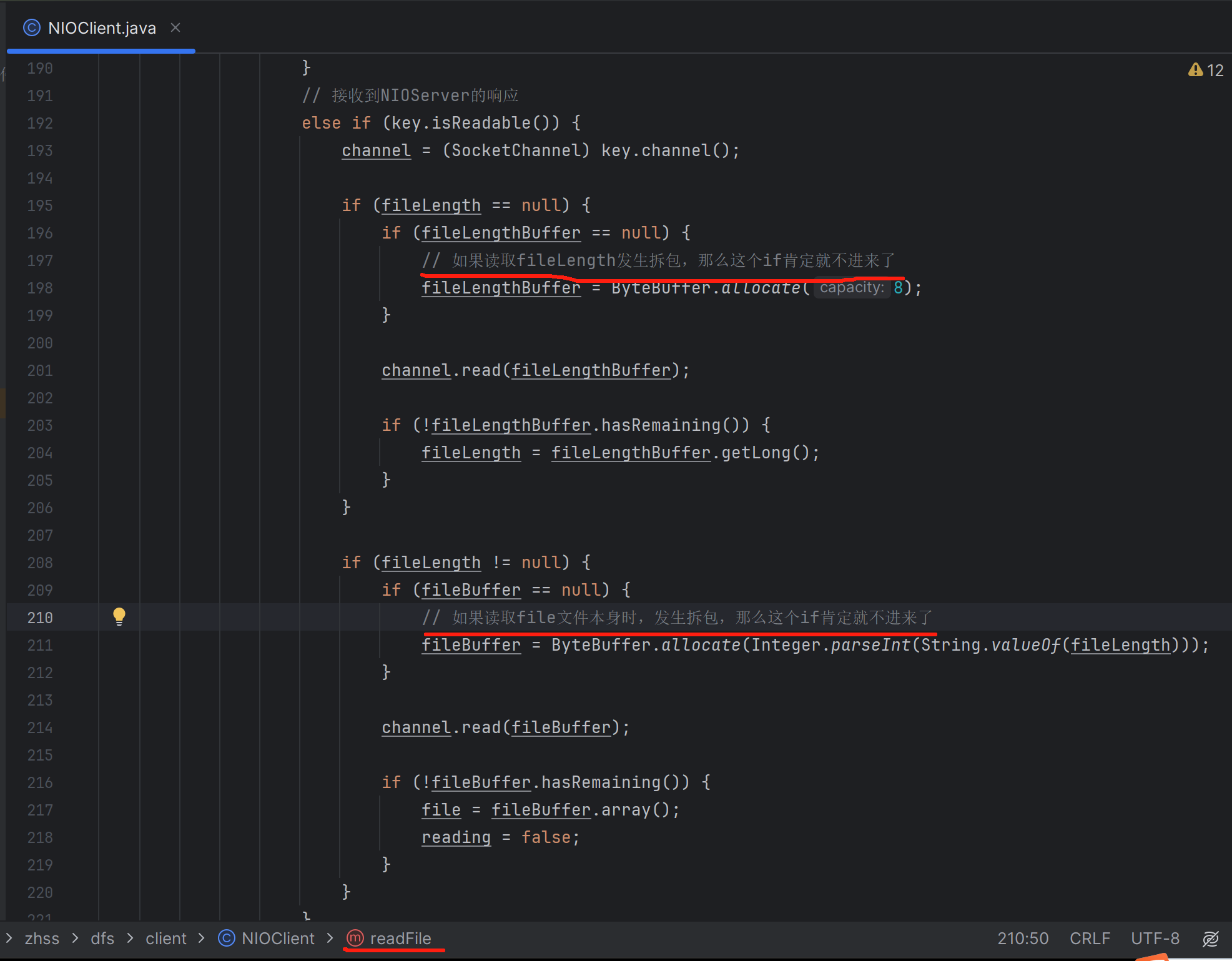
当客户端发送文件过来时,可能一个文件过大,不可避免的整个文件体就会被拆成多个包,表现在代码层面,就是会有一轮又一轮的Read事件达到,在最后一轮Read事件达到之前的每一轮,我们都需要记录已经读取了文件大小是多少。只有当已经读取的文件大小,等于请求头中的文件完整长度时,才表示这个文件全部接收完毕了
138_工业级NIO通信组件:多个数据文件的粘包问题应该如何解决?
某个客户端在一个连接中,连续上传了多个文件,才可能会出现粘包问题。虽然,我们这里使用的是短连接,一个请求一个连接,所以是不会出现粘包问题的
针对拆包问题,我们只要把已经读到的一部分包缓存起来,并保持对OP_READ事件的继续关注即可
针对粘包问题,我们就是一次只能读取一个文件的内容,如果一个文件读完了,channel中还有数据,那么就只能再走上面的拆包并缓存数据的逻辑,来重复处理第二个文件的数据包
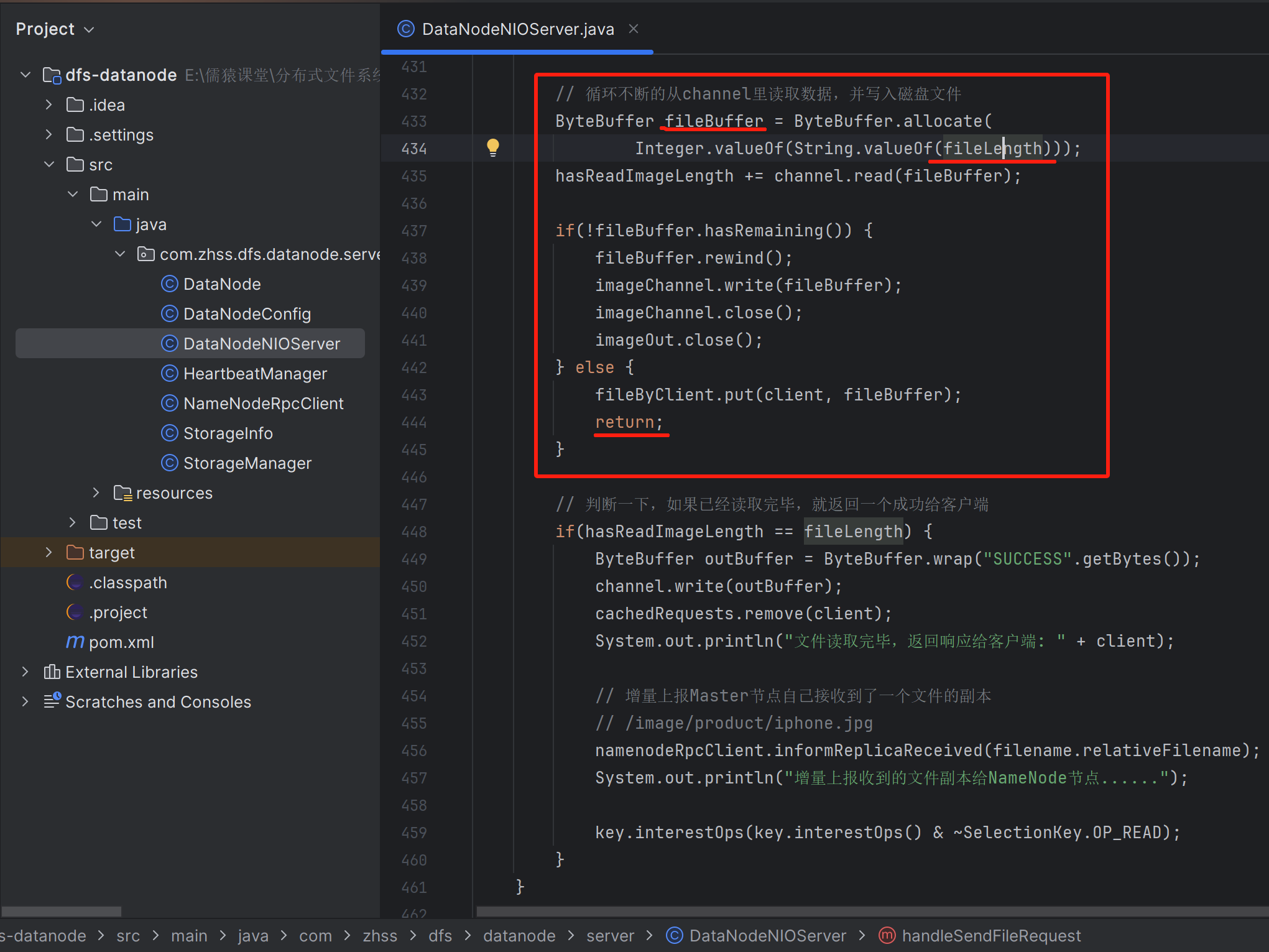
这里是一个文件内容,发生拆包时的处理逻辑。如果要处理粘包问题,那么也还是在这段代码中进行修改,但是定义的fileBuffer也还是fileLength的大小
当前一个文件数据包处理完之后,继续while循环,从channel中读取数据,如果没有读取到数据就结束本次OP_READ事件处理,如果从channel中读取到了数据,则缓存起来,进行下一个包的的处理,依然是先获取4个字节的文件名长度的请求头或者8个字节文件长度的请求头,后续的处理逻辑又是拆包的处理逻辑
139_工业级NIO通信组件:数据文件的拆包问题应该如何解决?
上传文件

下载文件
140_工业级NIO通信组件:客户端读取文件的拆包问题如何解决?
141_工业级NIO通信组件:客户端读取多文件的粘包问题如何解决?
如果客户端通过一个连接,发送了多个文件的下载请求,服务端可能同时把多个文件包发过来,从而产生了粘包问题。我们这里使用的是短连接,当然对应客户端下载文件来说,也不存在粘包问题
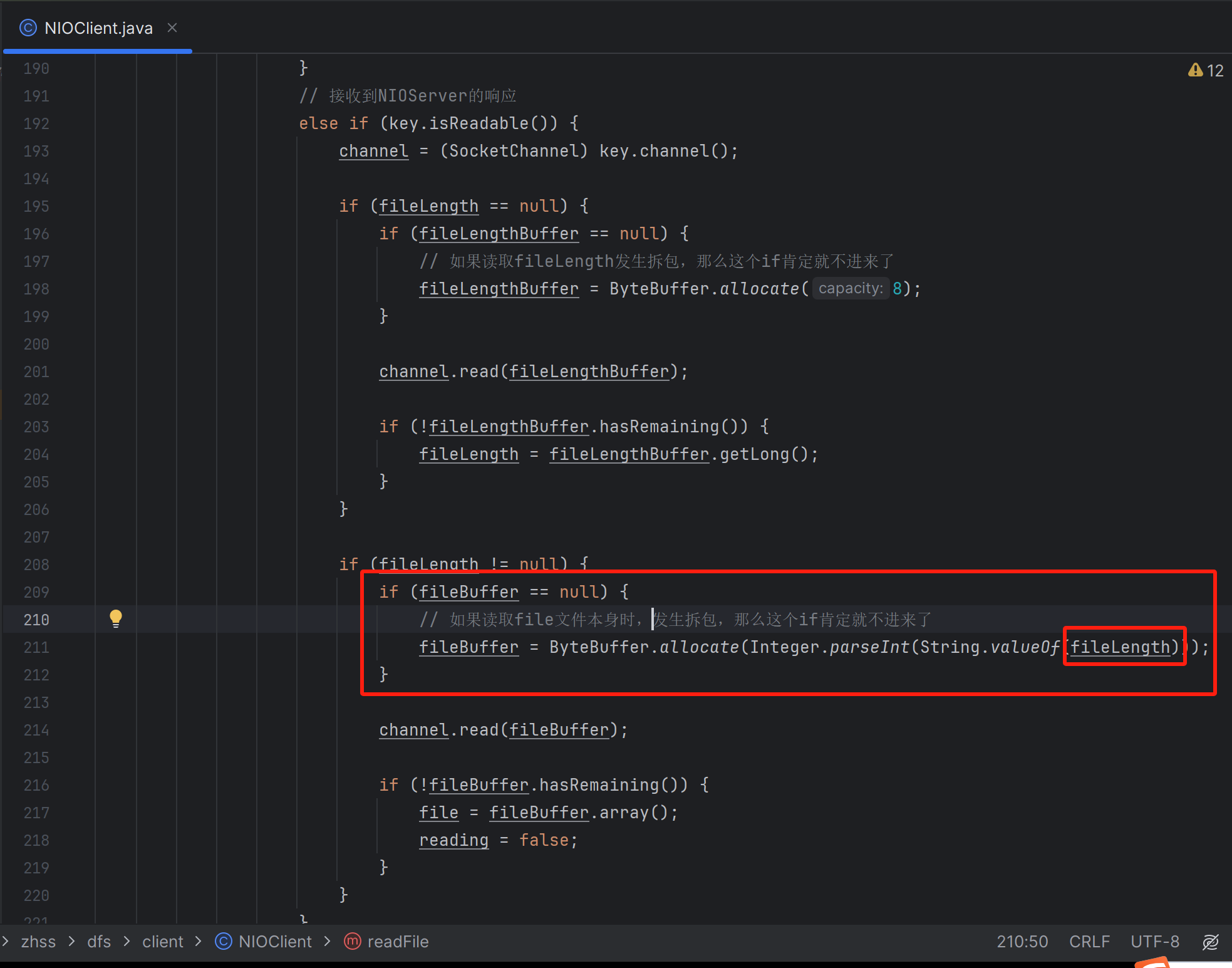
通过定义的这个buffer,保证了每次最多只读完一个文件,不会读到下一个文件去。所以,如果发生粘包问题,我们依然可以通过给增加一个while循环,继续从channel中读取下一个文件包的内容即可。当然了,读取下一个文件包时,又有可能发生拆包问题
142_结合代码再谈NIO设计思想:到底什么是同步非阻塞?
之前大量的重构了我们的文件上传和下载的细节上的通信的代码,原生NIO相关的,代码重构量实在是太大了,所以必须得在这里详细的把文件的上传和下载,分别梳理一下代码流程
基于原生的NIO来编程,其实主要要处理的,就是类拆包和类粘包的两种问题。一次OP_READ事件读取到了前后两个数据包的内容就是粘包。底层的网络通信的模式是一种数据流的方式,各种各样的数据在底层会转换为电路信号不停的发送给你,所以你要知道如何切分开来不同的数据包
拆包是很典型的一个问题,就是一个文件,11.2MB,结果一次OP_READ就读取到了5.6MB,另外一部分在下一次OP_READ才可以读取到,这个就是所谓的典型的类拆包的问题,一个完整的数据需要多次读到
其实在真正的工业级的网络通信的程序里,主要要处理的就是这块东西,其他的一些,比如调参优化,参数调优,很多参数都还好,在kafka的源码分析的课程里,就是重点讲解了kafka源码中是如何进行工业级的NIO编程的
阻塞和非阻塞
经历过了一连串的编程之后,大量的代码实战之后,在这里必须从头对里面的NIO这块的代码做一下梳理和总结,反复加深大家的印象,彻底打通网络通信这块的任督二脉
143_探探我对于JDK中的NIO API设计的一些缺陷的看法以及改进的思考
我们继续来梳理咱们的NIO代码,这个过程急不得,我一定要把这块东西给大家讲深讲透,理解,掌握,这块东西真的是一个Java程序员最最底层的核心技术
144_NIO编程时如何避免对同一个网络事件进行多次重复处理?
很多同学都问过我的一个问题
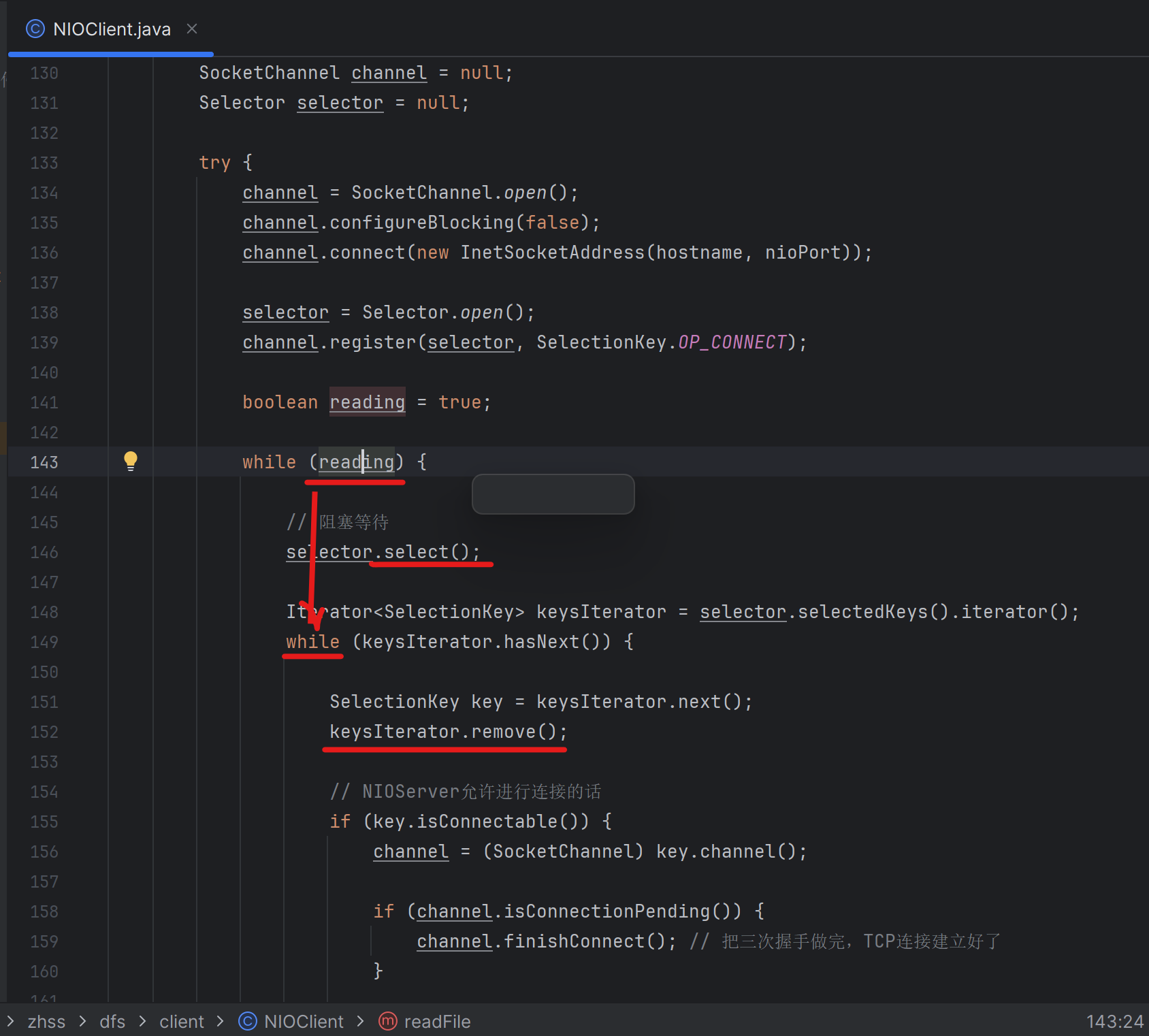
本质上也是人家NIO API设计的一个不足之处,如果你获取了一个SelectionKey出来,此时就应该自动把他给删除掉,不应该继续留在自己内部的selectedKeys集合里了。如果获取了一个SelectionKey出来并处理完后,就应该给它remove掉,否则当地143行的while循环在146行又会立马把这个SelectionKey给select出来,从而产生事件的重复处理(但是这个SelectionKey对应的事件,其实在上一轮已经被处理完成了)
145_基于JDK注释深入分析NIO客户端发起连接的过程以及原理
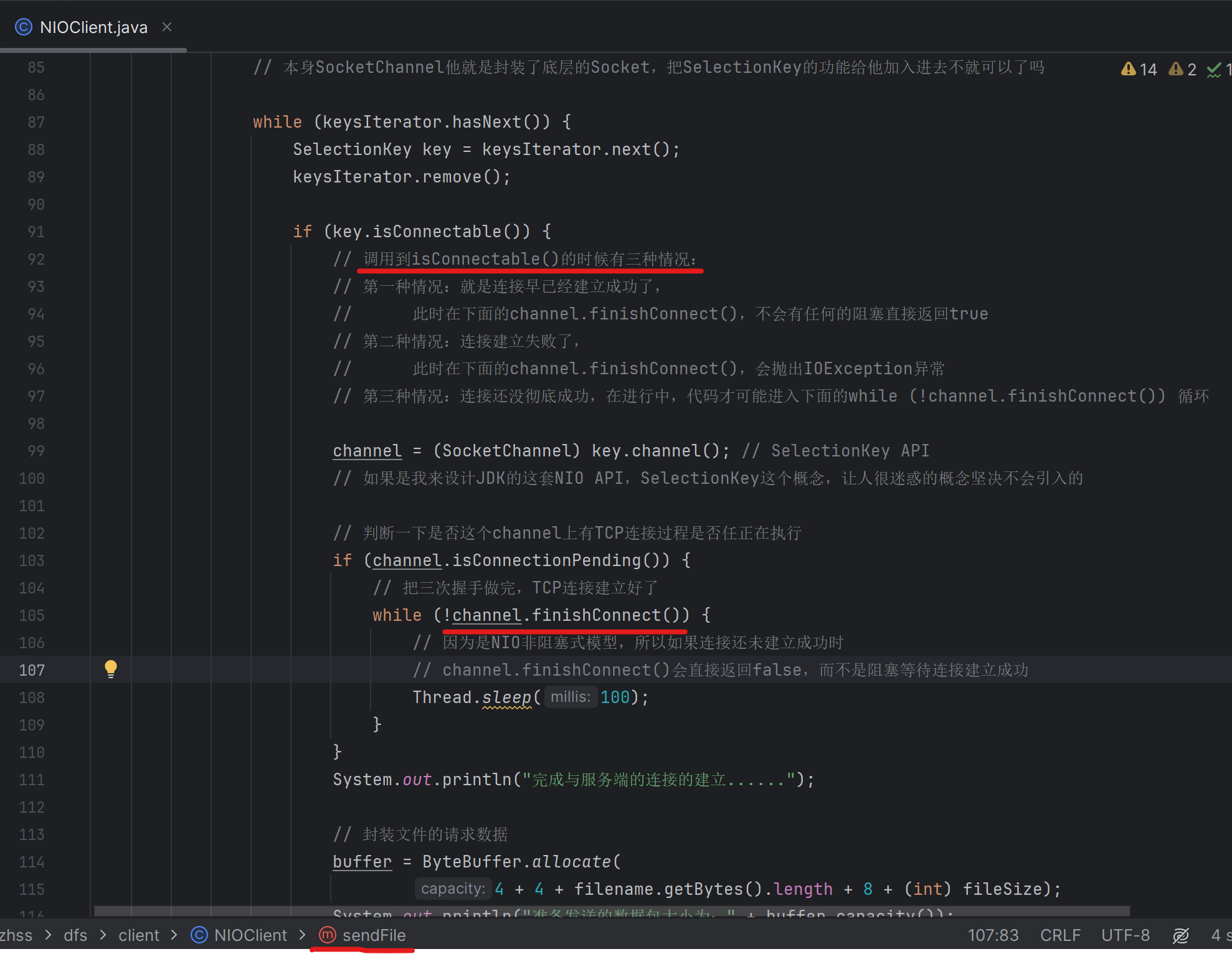
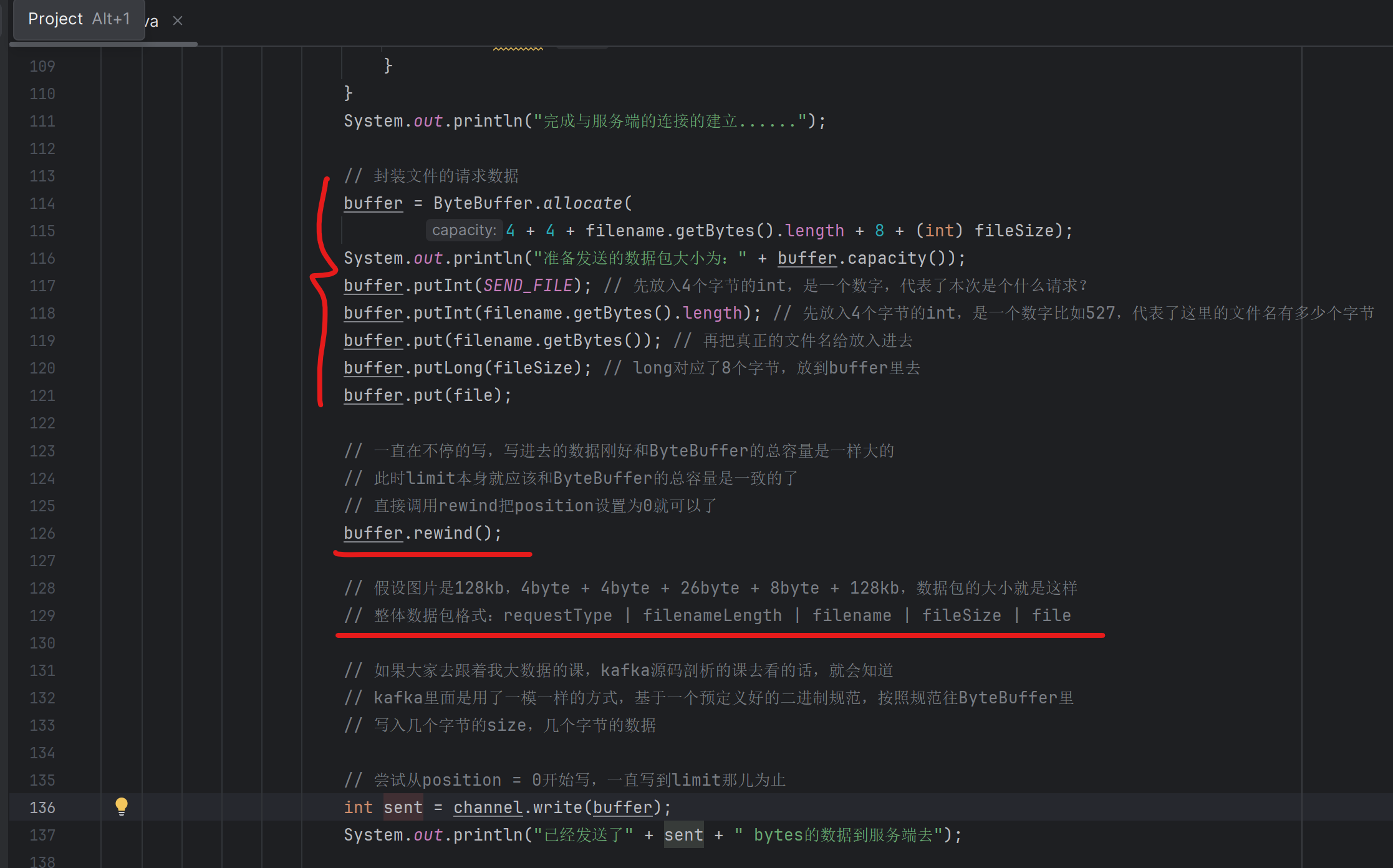
146_工业级的网络数据包封装:如何设计数据包的包头?
在直接基于原生NIO,进行网络编程的时候,必须是得自己设计数据包的格式。
也就是说,一次调用SocketChannel.write写出去的是你自己封装好的一个完整的数据包,你必须考虑好这个包里有哪些数据,而且包里的数据是按照什么样的格式和顺序来放置的
kafka的数据包的设计,也就是类似这样而已,其实也没什么特别的东西
147_客户端在传输大数据包时如果出现拆包问题应该如何处理?
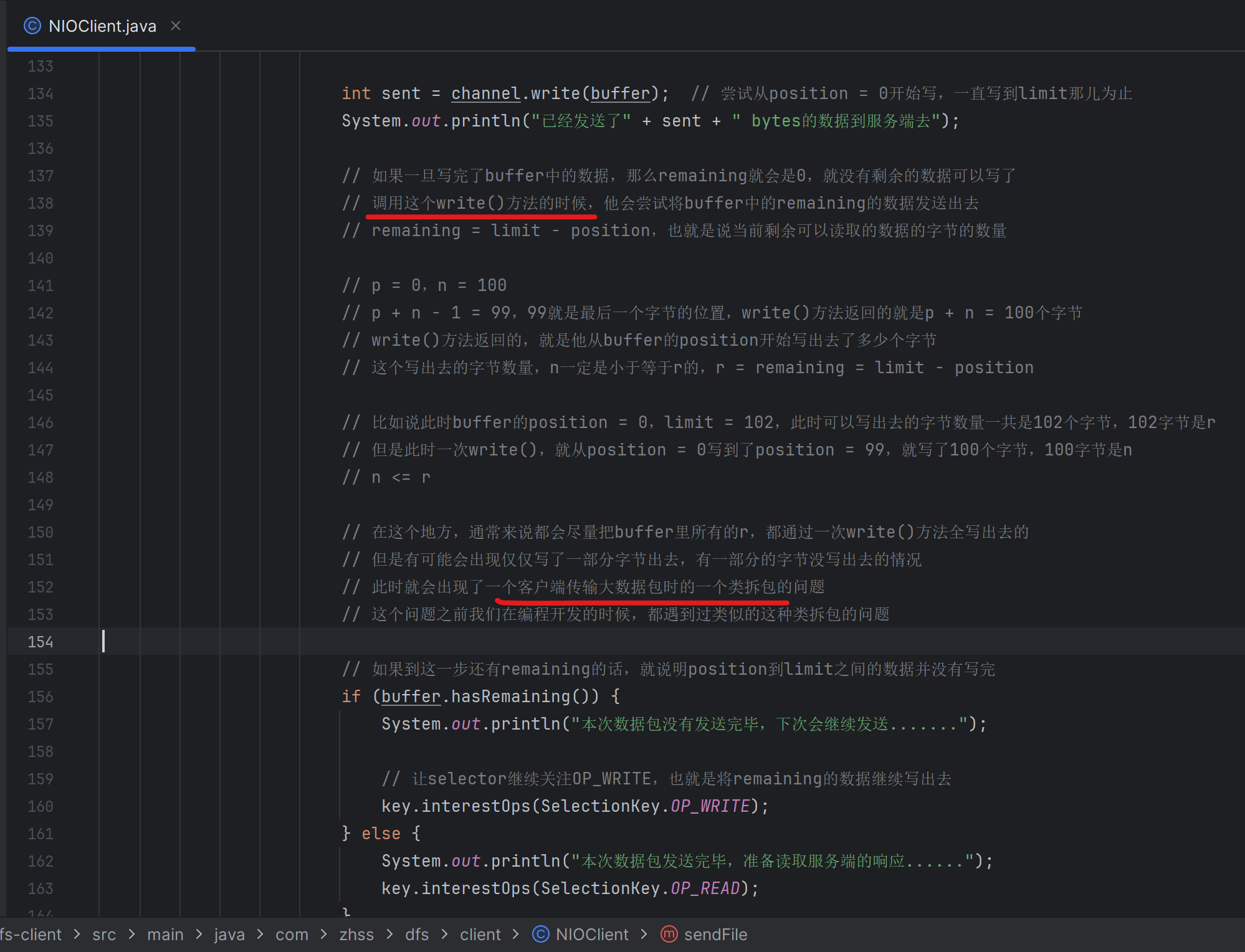
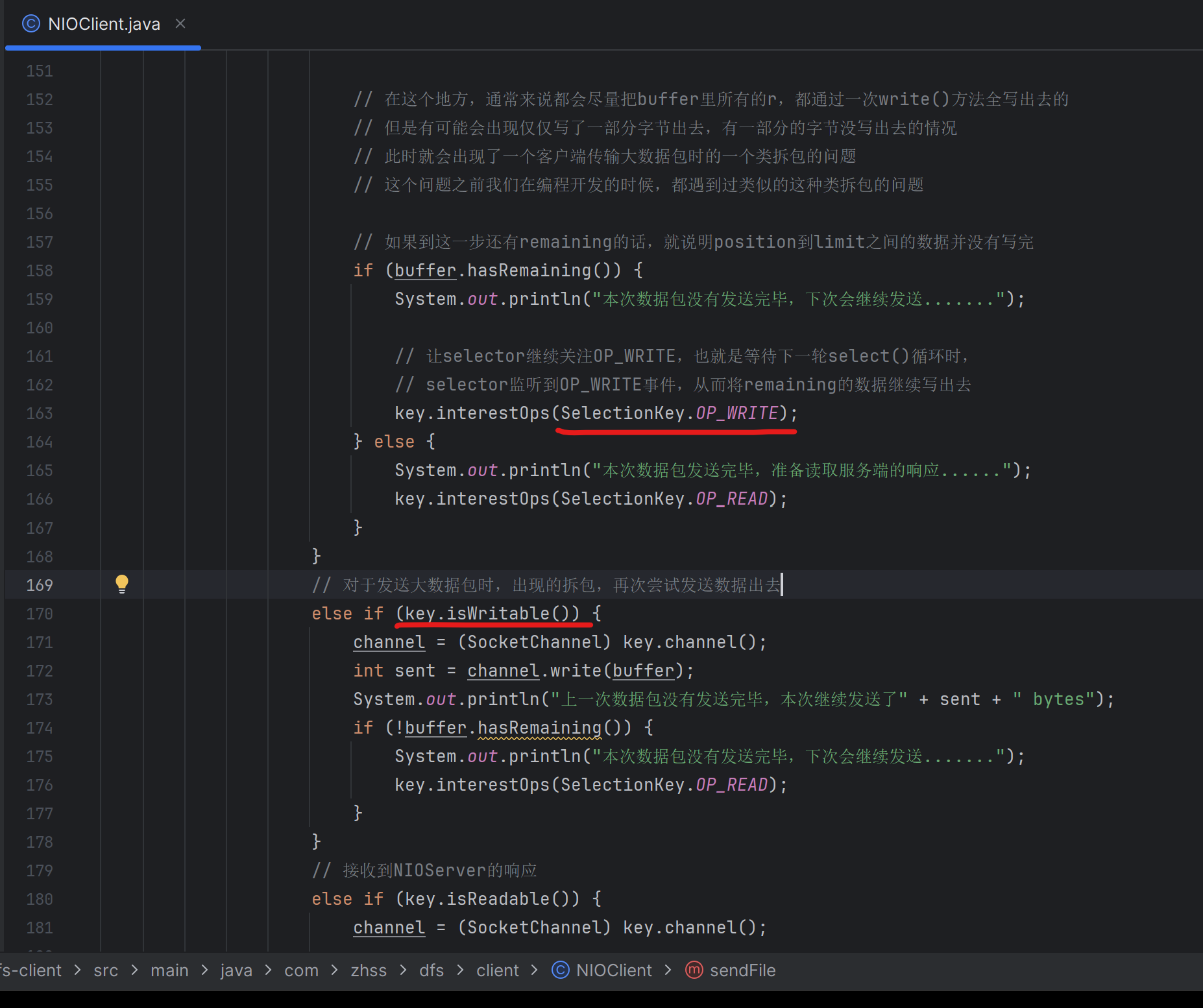
148_动手完成解决客户端大数据包类拆包问题的代码实现
149_再来仔细看看NIO到底是如何实现客户端连接请求的监听的?
我们已经讲完了客户端请求的发送,现在就是进行到NIO服务端,我们为什么要把这块代码仔仔细细的讲解一遍,再进行测试。是因为现在我们基于NIO写的代码已经完全实现了工业级了,代码是很复杂的,所以说我们需要把这块代码仔细的给讲解清楚才可以
150_当接收到客户端发送过来的请求时是如何基于多线程进行处理的?
核心就是,同一个channel过来的事件都会被hash到同一个worker线程,来进行处理。每个worker都有一个阻塞队列用来装channel过来的事件,worker线程从阻塞队列中取出一个个事件,然后处理即可
151_先分析一下服务端接收文件的正常情况下的核心流程
152_接着分析一下服务端接收文件的拆包粘包解决方案的代码
这里需要快速返回,
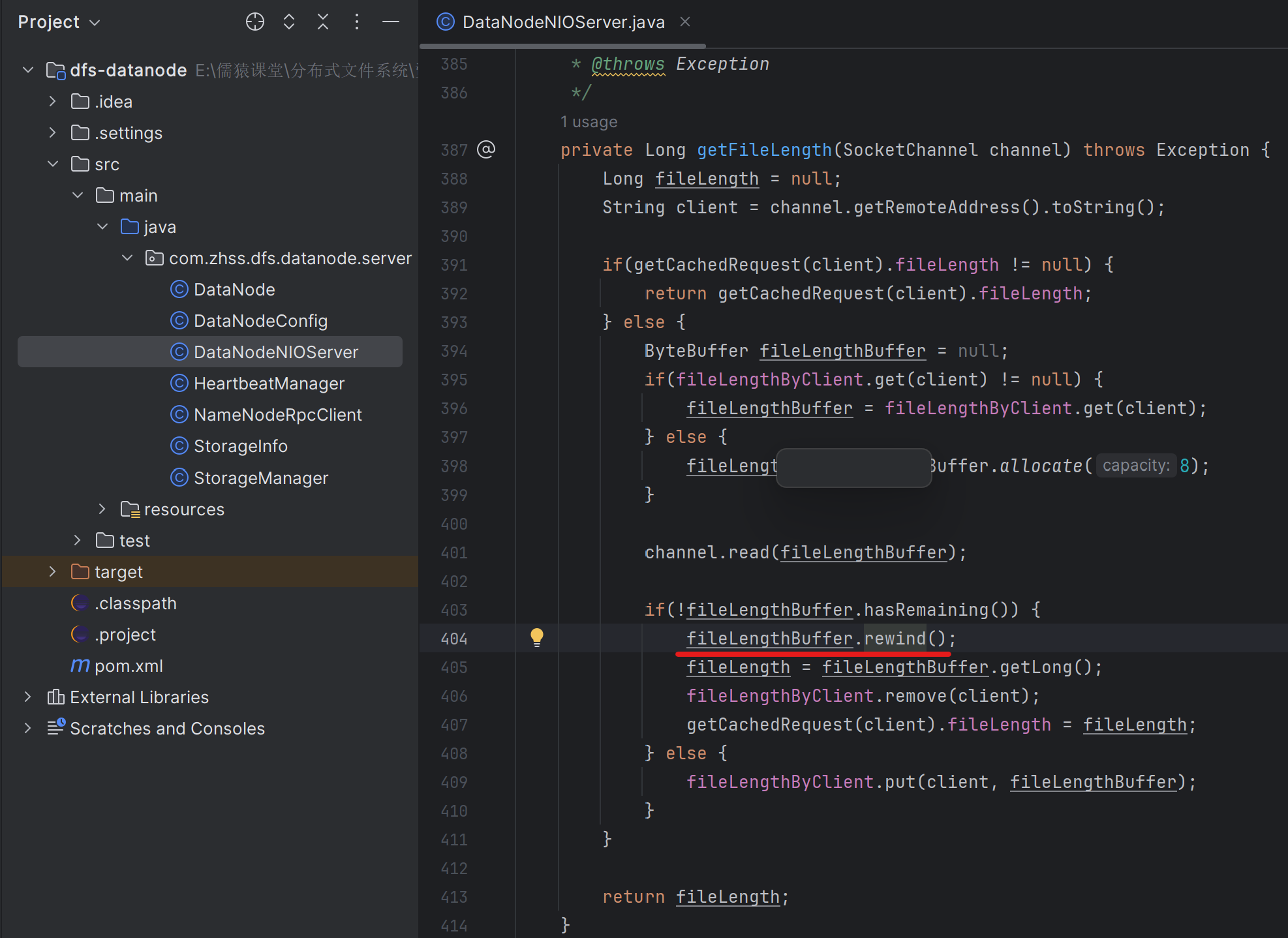
1,第395行到399行的代码,一开始遗漏了
2,读完以后一定要先rewind()
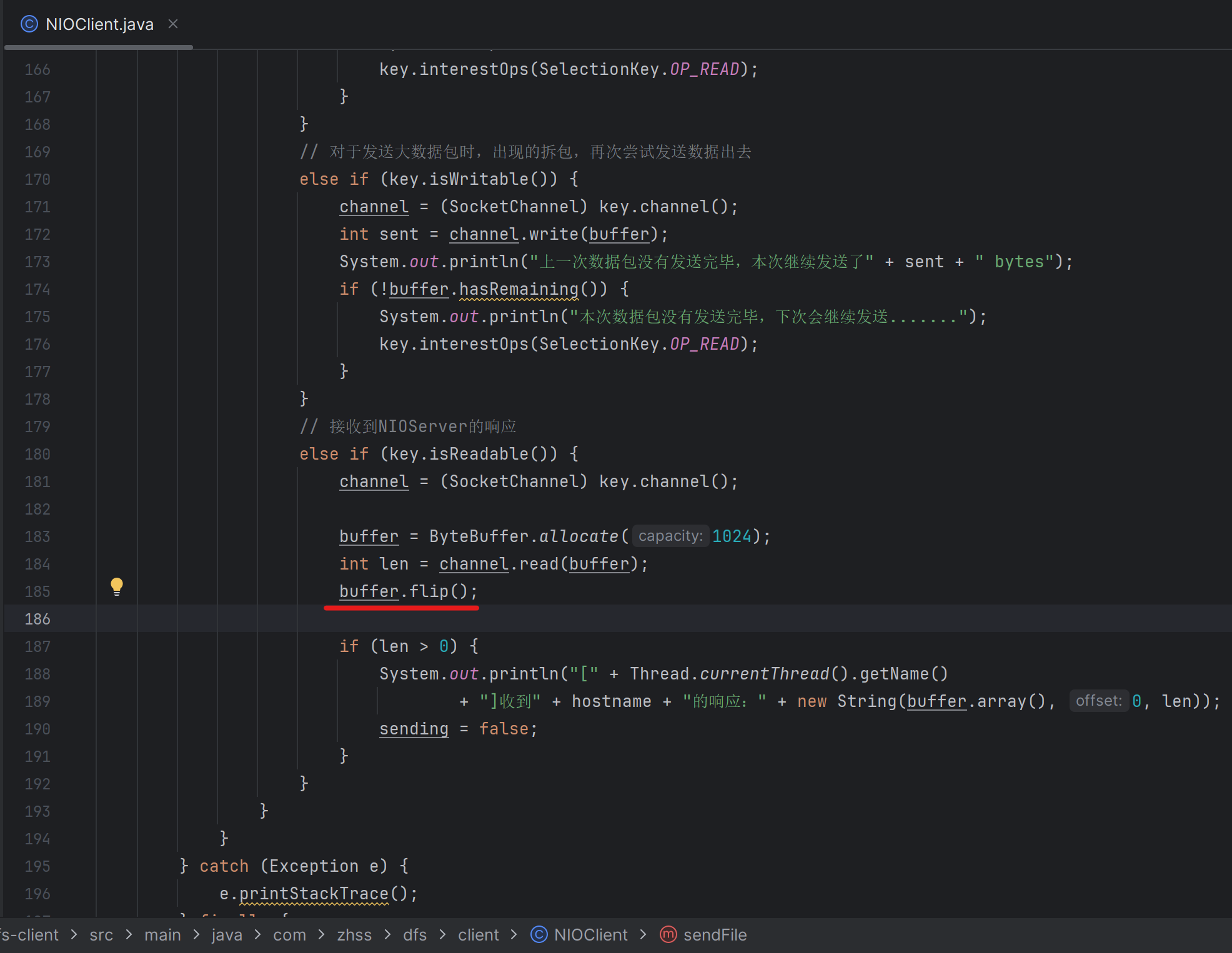
这里用于接收,服务端给客户端返回的SUCCESS,这里读完以后也要flip()
注意看,如果是buffer已经写满了,后续要读之前就可以rewind(),如果buffer没有写满,后续要读之前就需要flip()
flip()和rewind()区别

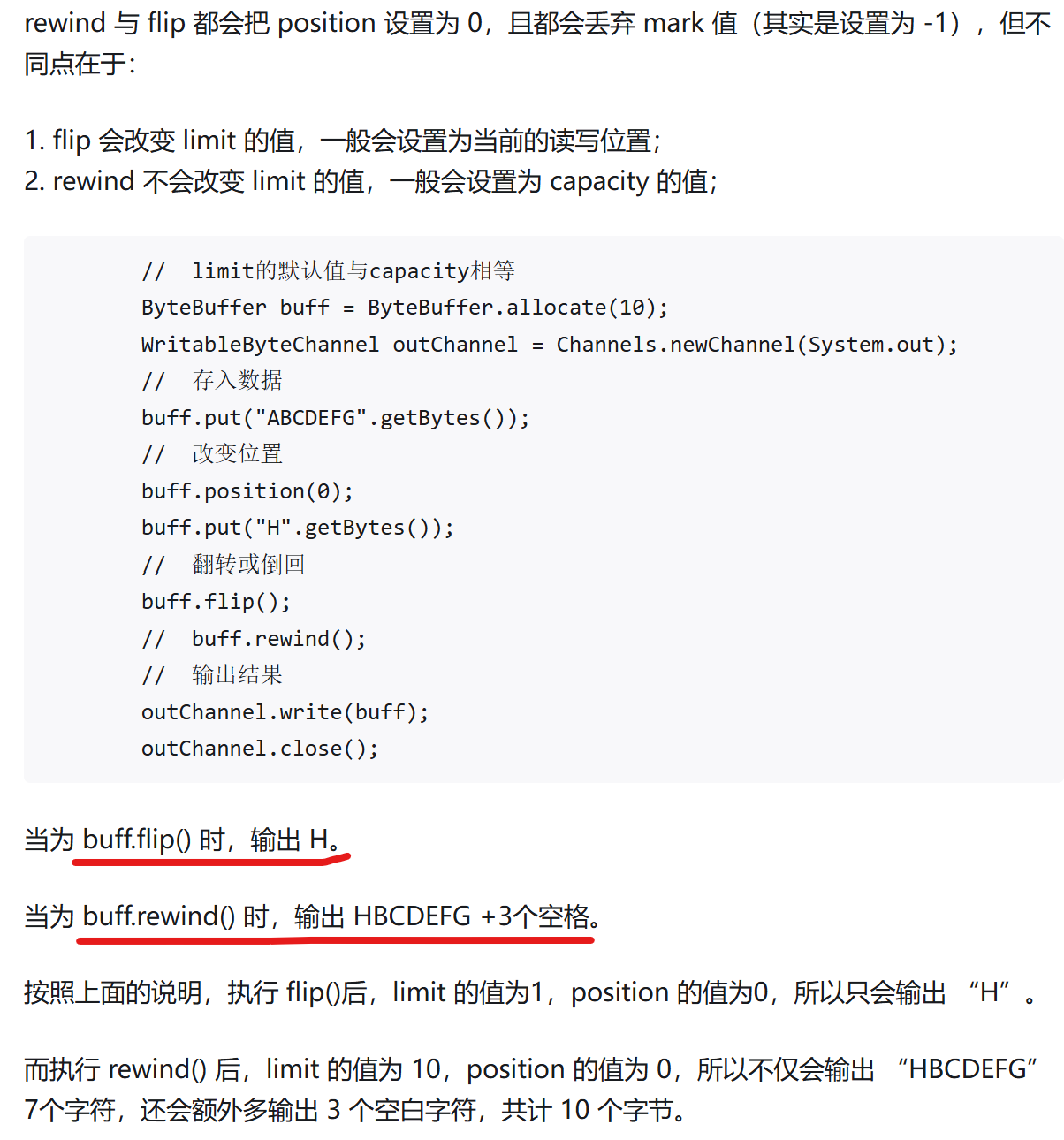
153_在客户端动手编写一个文件下载的测试用例代码
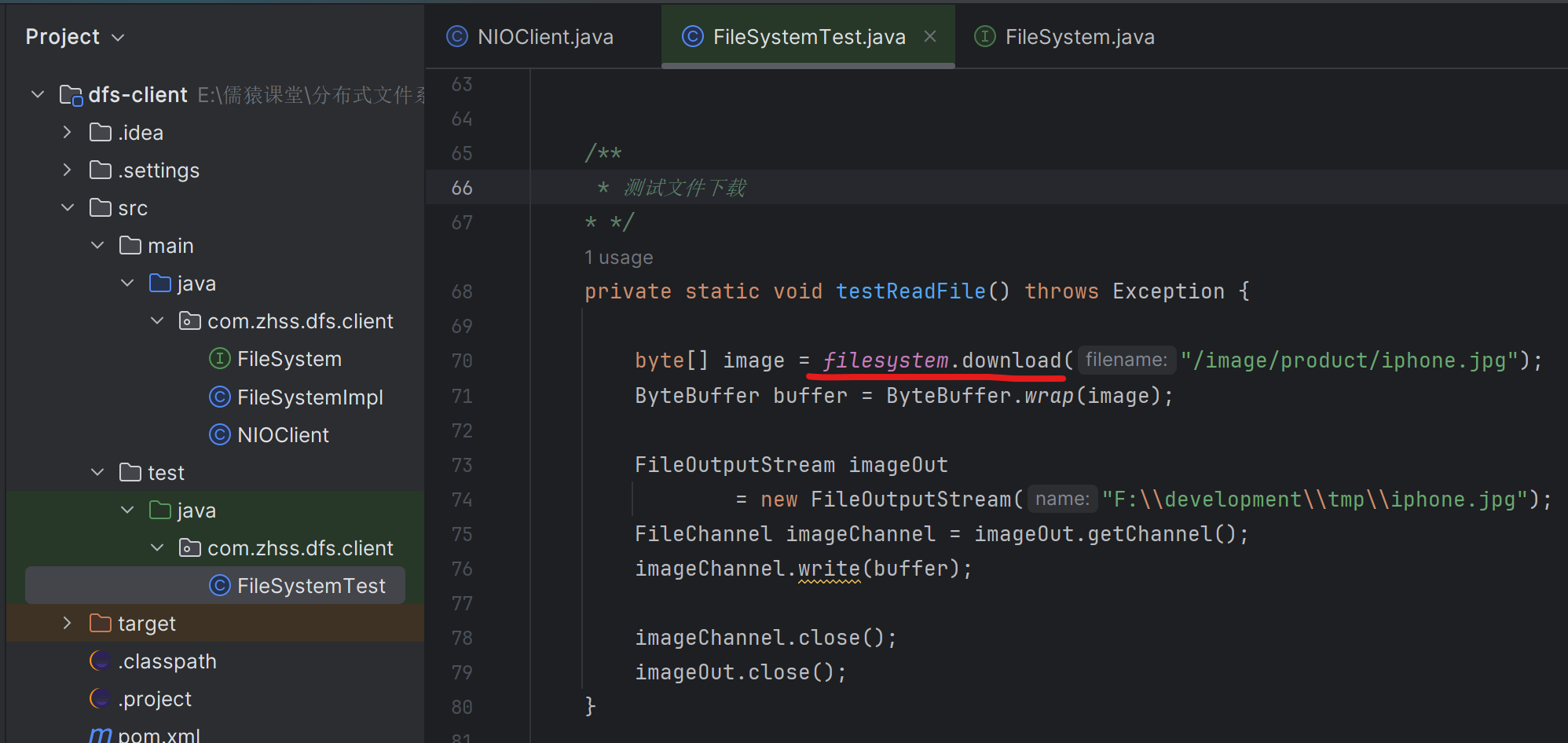
154_基于测试用例走读一下文件下载的正常流程中的代码
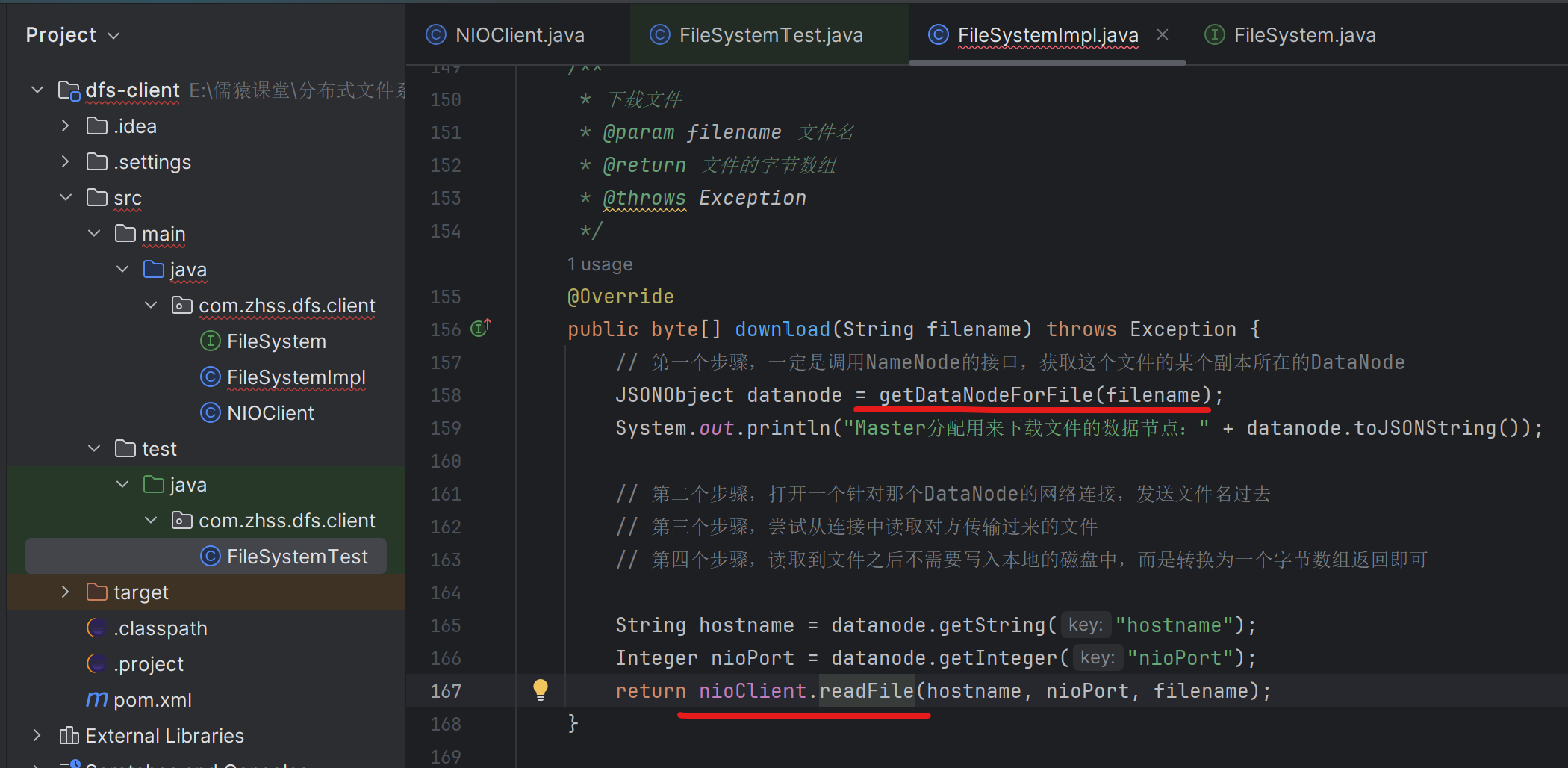
155_在文件上传的代码流程中加入测试需要观察的一些日志
java
public class DataNodeNIOServer extends Thread {
private void handleSendFileRequest(SocketChannel channel, SelectionKey key) throws Exception {
String client = channel.getRemoteAddress().toString();
// 从请求中解析文件名
Filename filename = getFilename(channel);
System.out.println("从网络请求中解析出来文件名:" + filename);
if (filename == null) {
return;
}
// 从请求中解析文件大小
Long fileLength = getFileLength(channel);
System.out.println("从网络请求中解析出来文件大小:" + fileLength);
if (fileLength == null) {
return;
}
// 获取已经读取的文件大小
long hasReadImageLength = getHasReadFileLength(channel);
System.out.println("初始化已经读取的文件大小:" + hasReadImageLength);
// 构建针对本地文件的输出流
FileOutputStream imageOut = null;
FileChannel imageChannel = null;
try {
imageOut = new FileOutputStream(filename.absoluteFilename);
imageChannel = imageOut.getChannel();
imageChannel.position(imageChannel.size());
System.out.println("对本地磁盘文件定位到position=" + imageChannel.size());
// 循环不断的从channel里读取数据,并写入磁盘文件
ByteBuffer fileBuffer = null;
if (fileByClient.containsKey(client)) {
fileBuffer = fileByClient.get(client);
} else {
fileBuffer = ByteBuffer.allocate(Integer.valueOf(String.valueOf(fileLength)));
}
hasReadImageLength += channel.read(fileBuffer);
if (!fileBuffer.hasRemaining()) {
// 1. 将从客户端接送到的文件字节数据,写入磁盘
fileBuffer.rewind();
int written = imageChannel.write(fileBuffer);
fileByClient.remove(client);
System.out.println("本次文件上传完毕,将" + written + " bytes的数据写入本地磁盘文件.......");
// 2. 接收文件完毕,写SUCCESS回客户端
ByteBuffer outBuffer = ByteBuffer.wrap("SUCCESS".getBytes());
channel.write(outBuffer);
cachedRequests.remove(client);
System.out.println("文件读取完毕,返回响应给客户端: " + client);
// 3. 增量上报Master节点自己接收到了一个文件的副本
// /image/product/iphone.jpg
namenodeRpcClient.informReplicaReceived(filename.relativeFilename);
System.out.println("增量上报收到的文件副本给NameNode节点......");
// 4. 取消监听当前通道的OP_READ事件
key.interestOps(key.interestOps() & ~SelectionKey.OP_READ);
} else {
fileByClient.put(client, fileBuffer);
getCachedRequest(client).hasReadFileLength = hasReadImageLength;
System.out.println("本次文件上传出现拆包问题,缓存起来,下次继续读取.......");
}
} finally {
imageChannel.close();
imageOut.close();
}
}
}将步骤2,3,4,统统挪入 if (!fileBuffer.hasRemaining())中
156_在文件下载的代码流程中加入测试需要观察的一些日志
157_清理一下本地磁盘中的文件准备一个干净的环境用来测试
实现数据节点可以部署多台机器,Master节点会负责整个集群的管控,客户端上传文件的时候走的是一个分布式存储,就是这个文件仅仅会在某个机器上存储一份,但是同时为了高可用,会做一个双副本的冗余,也就是说,每个文件在其他机器上都会有一个副本存在
Master可以收集和管理所有的集群里的元数据,文件目录树,各个机器上的存储的情况
文件下载,会从一个文件的多副本中随机选择某台机器出来,从这台机器上下载一个文件副本到本地
我们已经实现了一套工业级的分布式系统的元数据管理机制、分布式存储架构、多副本冗余的机制、分布式集群中的数据读取的机制、工业级的网络通信/磁盘读写/内存管理/并发控制,但是目前为止可能有一些少数的小bug
在公司里做项目,如此复杂的系统,有一些小bug是很正常的,实际上这些bug需要依靠大量的测试,在测试环境真实部署一套集群出来,然后模拟生产环境的各种情况来进行测试,才能知道具体是怎么回事
158_先测试文件上传后的分布式存储以及多副本冗余等机制是否正常
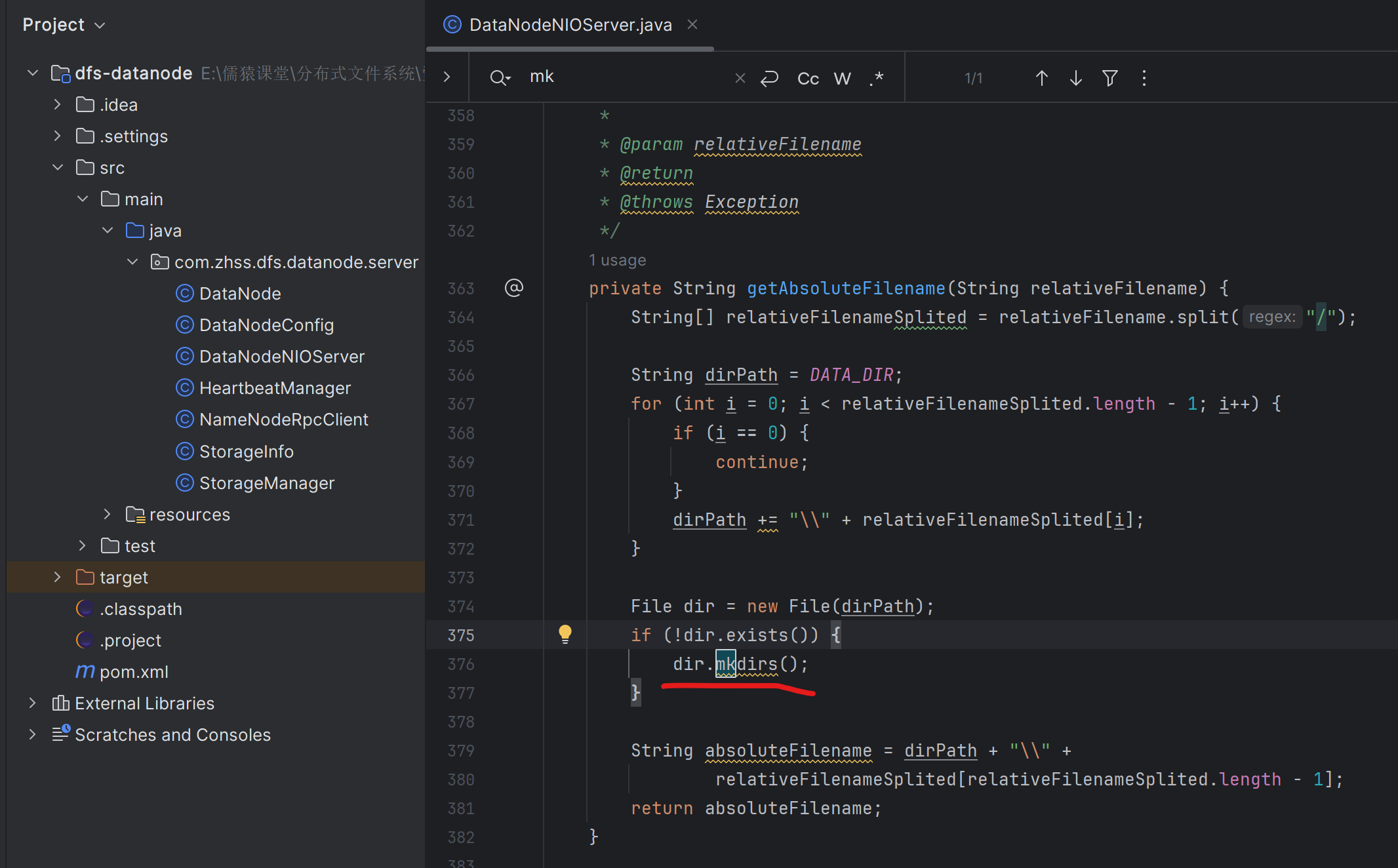
获取本地绝对路径时,目录在本地磁盘不存在,则直接创建目录
159_再测试基于已经分布式多副本存储的文件是否可以读取
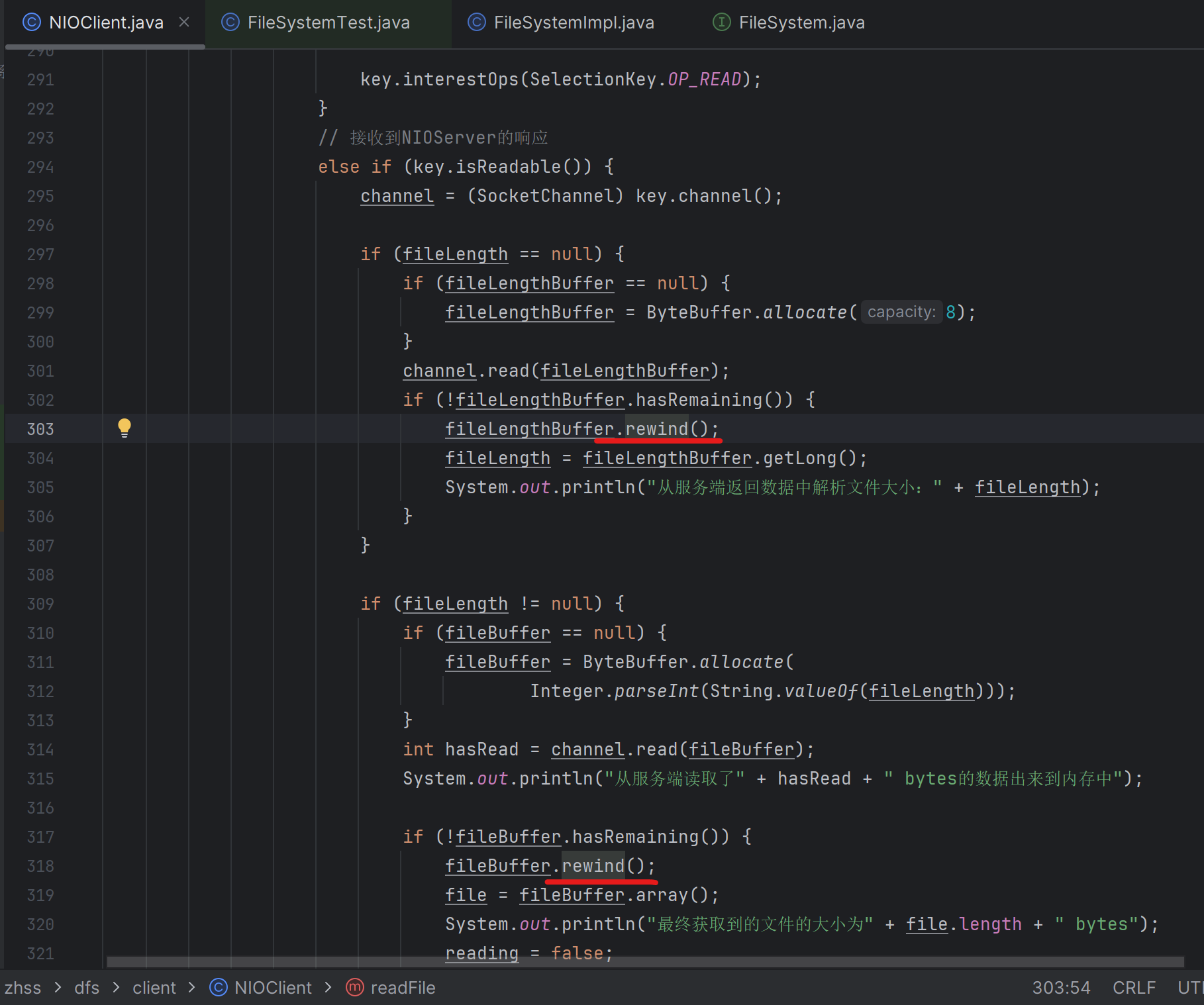
rewind()不能漏,NIO的编程就这点比较恶心,这些buffer的操作
160_对分布式文件系统的架构总结:元数据管理、分布式存储、多副本冗余
目前为止整体的架构
(1)元数据管理机制:纯内存来进行管理、editslog机制、backup备份机制、fsimage合并机制,实现了元数据的初步的高可用的架构(冷备份实现的)
(2)分布式存储架构:海量文件分布式的存储在很多机器上,每台机器存储一部分的文件,后续就可以实现可伸缩性,可以进行集群扩容,就可以无限的扩容让更多的文件可以存储在集群里
(3)多副本冗余架构:因为文件上传的时候多副本冗余存储,如果说某台机器宕机不要紧,这些文件有其他的副本在别的机器上,这样的话就可以保证了数据容错性,高可用性
(4)内存管理机制、并发控制机制、磁盘读写、网络通信(重点)
(5)FastDFS(分布式文件系统,c语言写的,不太适合Java技术栈来使用,看不懂它源码,但是可以分析一下他的架构上的优点),TFS(淘宝内部的分布式文件系统,架构设计),吸取人家架构中的精华和优秀的架构设计思想
(6)高可用、高并发、高性能、可伸缩的架构
这个项目是非常非常具有工业级的价值和意义的,完全可以说你在自己公司里在基础架构的团队,负责带了几个小弟从0开始研发了这么一套分布式存储系统,支撑了公司上亿图片的存储,里面的架构设计的思想,都是极为有价值的
做这个项目的原因是,FastDFS用的时候会有各种各样的问题,而且是很难说是真的可以去读它的源码,分析它的架构,如果出了问题,你很难说去维护和改动它的源码
161_迄今为止已有架构通过一张图来整体梳理一下
why?
本项目的架构,完全是参考的HDFS的架构:文件目录树的更新。
文件目录树的维护是纯内存的操作,如果我们又将文件目录树的维护依赖第三方的zk作为NameNode,第一影响性能,第二又多了个依赖,如果zk挂了则NameNode就不可用了
避免磁盘随机写,通过editslog文件的磁盘顺序写,来避免直接操作磁盘产生磁盘随机写
对于我们的这套架构,里面有一些高可用的问题的,我们后面给大家来分析
对于NameNode我们引入了BackupNode,让BackupNode充当NameNode的冷备份角色,每搁一段时间让BackupNode做一次checkpoint,产生一份fsimage文件,且BackupNode内存中也有一套完整的文件目录树。引入BackupNode就是为了高可用,作为NameNode的备份
162_再来通过一张图梳理一下分布式存储的整体架构思想
不同的分布式系统,分布式NoSQL数据库(HBase),分布式文件系统DFS,分布式缓存系统Redis,分布式消息系统MQ,分布式数据库,分布式微服务注册中心,不同的分布式系统,其实他的元数据都是不一样的,在管理不同的元数据的时候,所采取的策略也是不一样的
HDFS,已经全世界规模最大、最成熟、最优秀的一种分布式文件系统了,他的元数据管理机制的设计都是经过大量的实践和考量的,我就给大家详细分析了为什么要那样设计一套架构
对技术的理解和掌握,大致分为以下几个level:
- 学习过我们的亿级流量,ES,面试突击,加上你平时自己会自学一些技术,比如说MQ等等,各种技术都知道,初步的能用各种技术做系统
- 还学过springcloud、分布式事务、分布式锁、并发,如果你学习过这样的一些技术,相当于就是读过了一些开源项目的源码
- 你能够自研分布式系统、中间件系统,能够基于最底层的数据结构、并发编程、网络通信、磁盘读写,去研发出来适用于特定场景的分布式系统,里面的架构设计的、机制的设计,你都能够玩儿的转
- 精读MQ、数据库中间件、ES、ZooKeeper、Dubbo,一些流行的分布式系统的源码,这些技术的落地使用(进行第4步的前提是要有第3步的功底)
- 结合业务,微服务架构,性能优化,高可用方案,高并发方案,把常见的技术在业务系统中的架构设计的方案,都能搞一遍
以上5个阶段都走过了,七八十万年薪的架构师,或者是技术专家的职位,妥妥的
再往后的高大上的架构,那个时候朝着的就是年薪百万以上的架构师,首席架构师,或者高级技术专家 的职位去走了
163_先来看看分布式文件系统存在哪些高可用的问题?
如果你在设计一个系统的架构的时候,考虑高可用的话,考虑的就是,你的系统如果有任何一个部分挂掉了,此时你的系统如何继续保持对外是可用的
这个分布式文件系统讲完了以后,就讲Netty,然后就会把分布式微服务注册中心给搞定,做架构升级,用Netty做网络通信,因为当时网络通信的环节都没加入进去,他的架构参考比如阿里的Nacos等等给他做一个架构升级,这是后面课程的规划
我们会讲解ZooKeeper,就是放在分布式文件系统里,做双NameNode热备热切换的高可用的架构设计,然后就是用ZooKeeper再看看在微服务注册中心里有没有使用的场景
Dubbo,把最新的版本,源码,以及底层的Netty、ZooKeeper的使用都一起讲了,因为之前的电商项目是用的SpringCloud,所以Dubbo的使用,会结合别的业务讲一个小的项目出来
三个问题:
(1)副本数量的缺失:正常每个图片都是双副本,如果一个DataNode挂掉了,势必会导致一批图片只有单副本,如果此时再挂一台机器,就可能会导致部分图片就彻底丢失掉了
(2)如果某个客户端正在向DataNode上传图片,此时DataNode突然挂了,客户端发现图片上传失败了,此时如何处理?
(3)如果某个客户端正在从DataNode读取图片,此时DataNode突然挂了,客户端发现图片读取失败了,此时如何处理?
164_如果Master节点宕机之后如何手动完成主备切换?
搞一台新的机器,然后在上面放上去一个最新的fsimage(从BackupNode上来),接着部署一个新的NameNode,然后启动一个新的NameNode,对外来提供服务。比较挫的一个办法,就是得重新部署所有的系统,包括客户端,包括DataNode,包括BackupNode
正常来说,还是在原来的机器上,尝试重启NameNode,这样所有人,都可以基于原先配置的hostname之类的东西可以瞬间感知到NameNode重新起来了
如果原来的NameNode机器上,所有的editslog文件,还有fsimage都损坏了,那么就只能是用BackupNode他的fsimage,在新的一个机器上来部署NameNode
此时如果你要是实现NameNode高可用,必须得是引入ZooKeeper概念,NameNode的地址应该是写到ZooKeeper里去的,然后其他的BackupNode、DataNode、客户端感知NameNode他的地址的变化,都是通过zk来的。当个切换了NameNode后,zk上保存的NameNode地址就会变化,其他的BackupNode,DataNode,客户端就能感知NameNode他的地址的变化
这个时候,就会丢失一些文件或者目录,因为从BackupNode他的fsimage一定是比NameNode滞后一点点的
ZooKeeper主要作用
Hadoop 集群中确实使用了 ZooKeeper 。ZooKeeper主要为Hadoop提供分布式协调服务,确保集群的高可用性和稳定性。
ZooKeeper在Hadoop集群中主要负责NameNode的高可用管理。当主NameNode发生故障时,ZooKeeper会触发备NameNode的切换,保障HDFS文件系统的数据访问不中断
165_如果一个数据节点突然宕机了,Master节点如何感知到?
我们来看一下这一块,如果DataNode一旦宕机了,此时NameNode如何可以感知到?
166_感知到副本数量缺失之后触发副本复制的任务
一旦感知到了一个DataNode宕机,此时就应该触发这个DataNode上的所有的副本都需要新增一个异步复制的任务,交给其他的DataNode来进行副本复制,保证说每个图片都有2个副本
这个宕机的DataNode上有多个张图片,就需要有多少个副本异步复制的任务,这些副本复制任务又需要分发到别的未宕机的各个DataNode上去,让未宕机的各个DataNode去完成副本的复制
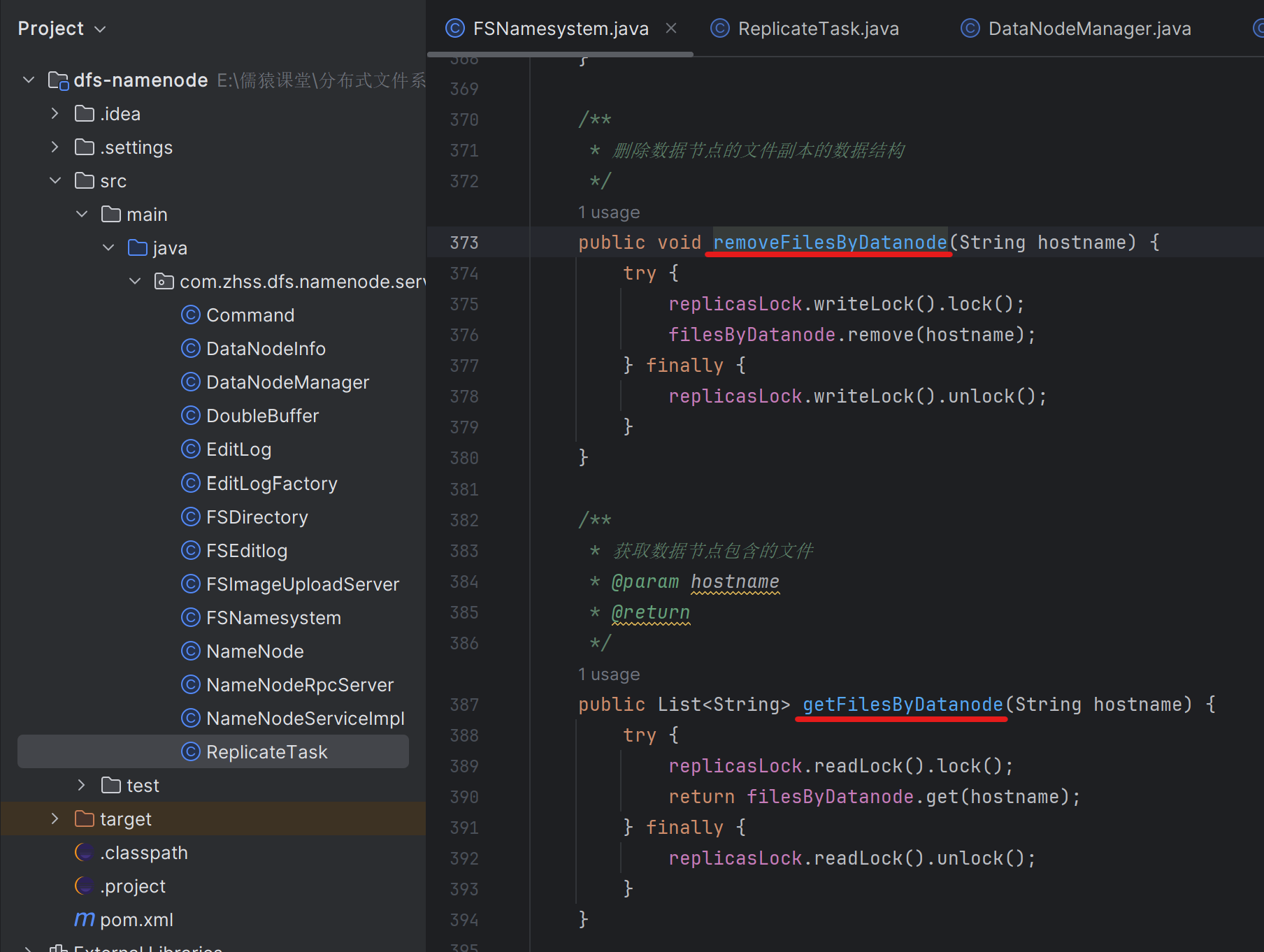
167_完善副本数据结构,需要知道每个数据节点有哪些文件副本
因为NameNode需要知道每个datanode上是有哪些文件副本的,从而在某个datanode宕机时,NameNode才能生成针对这个宕机的datanode上的所有文件副本的异步复制任务
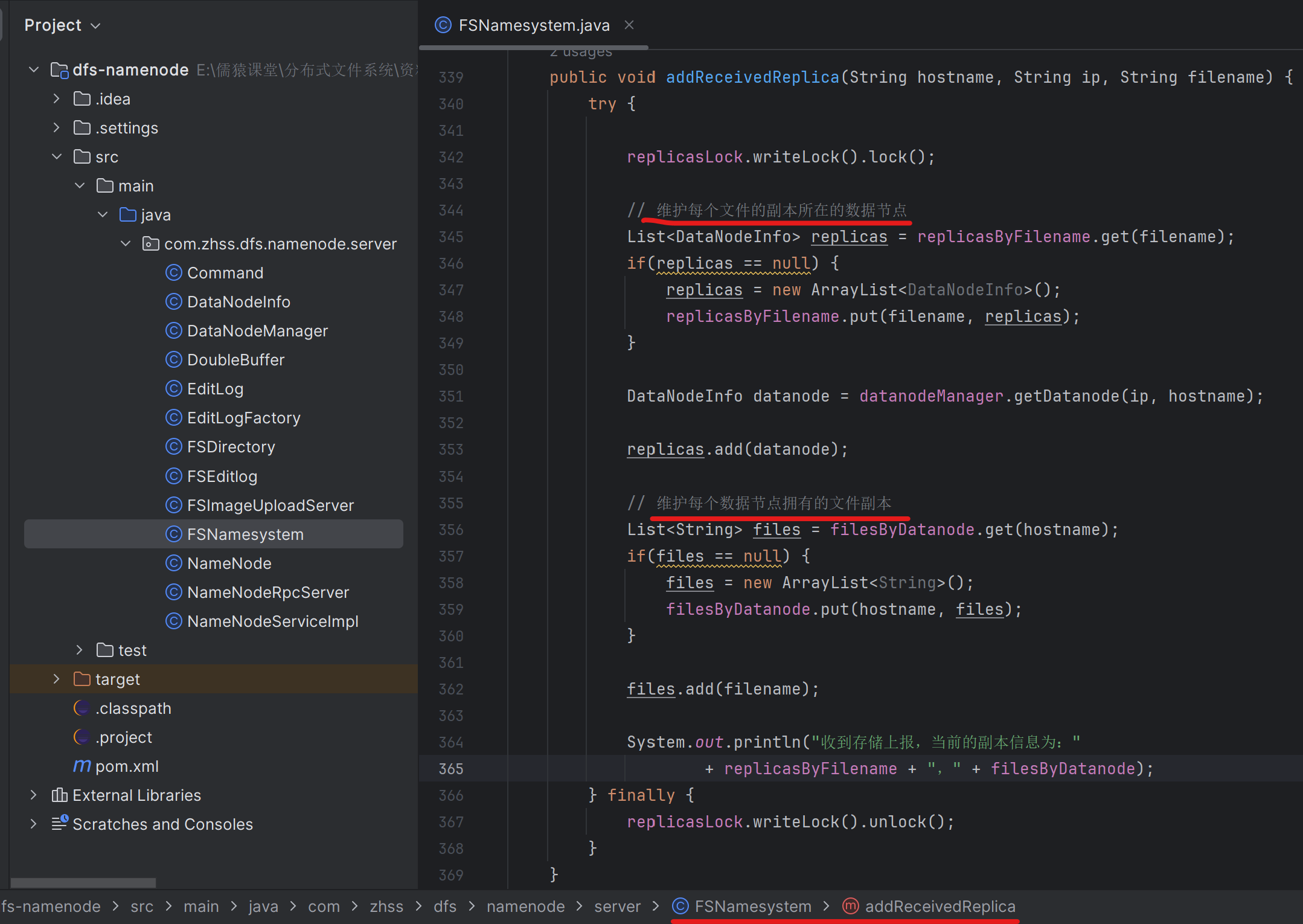
168_为宕机的数据节点上的每个副本都生成一个复制任务
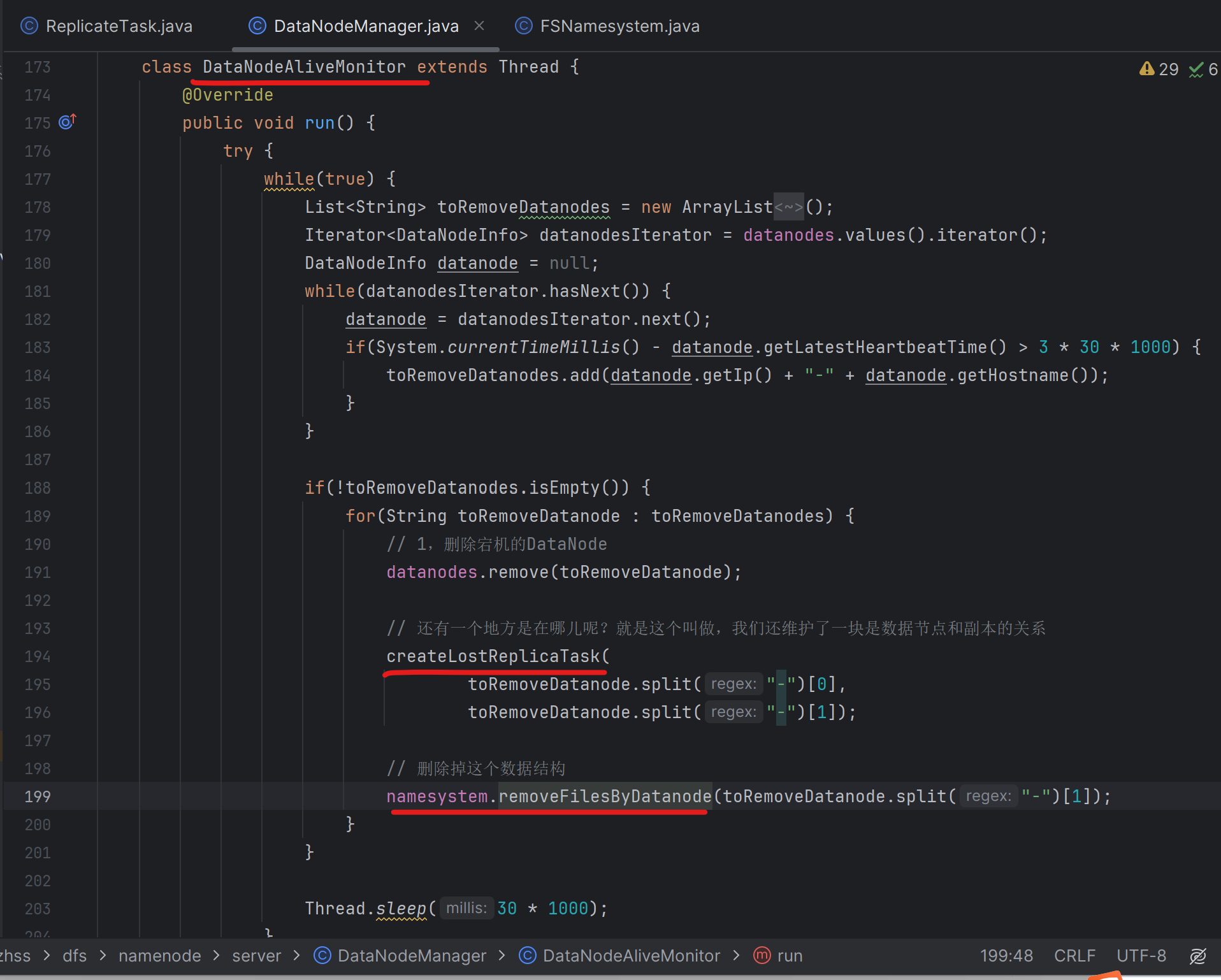
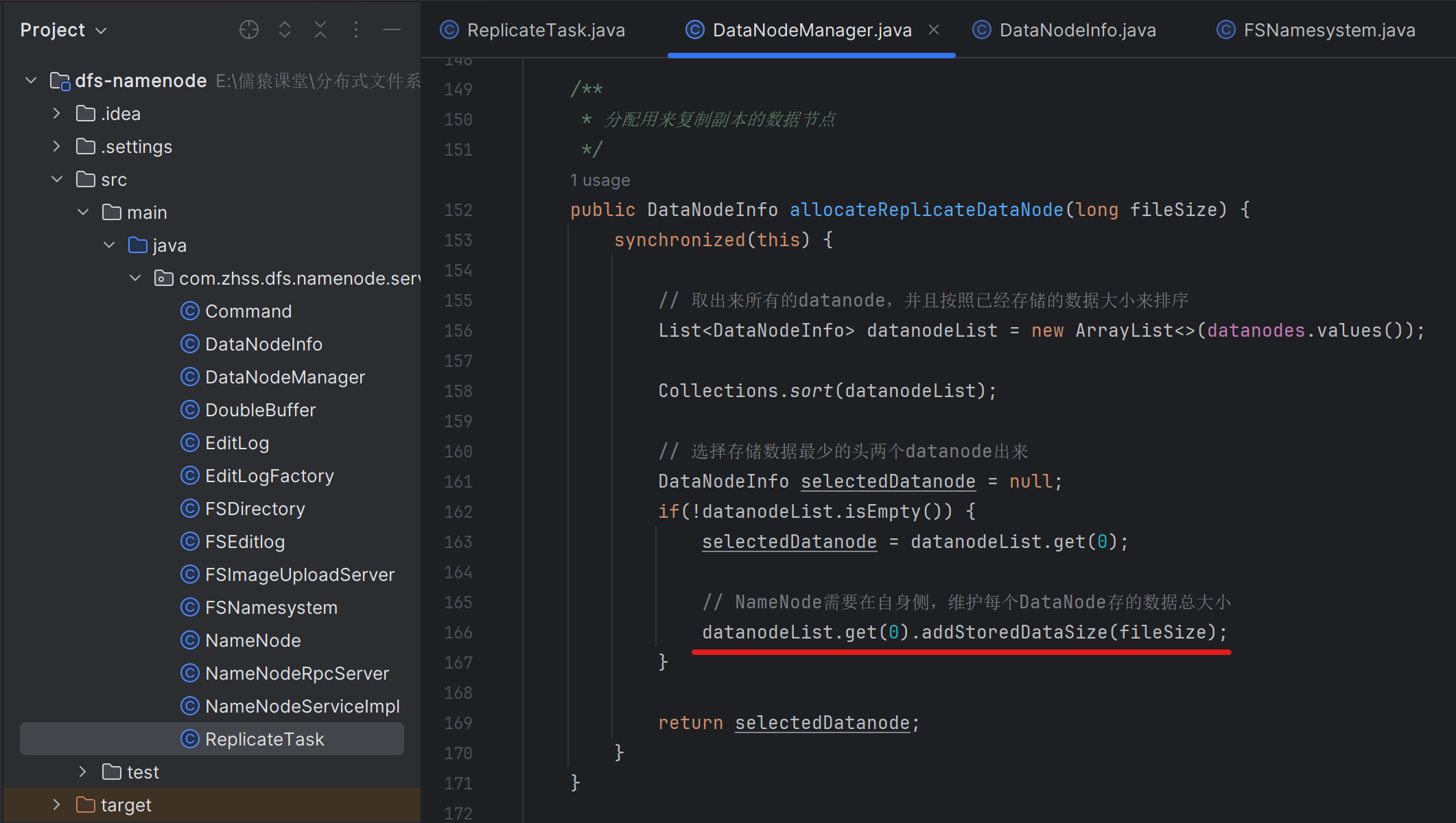
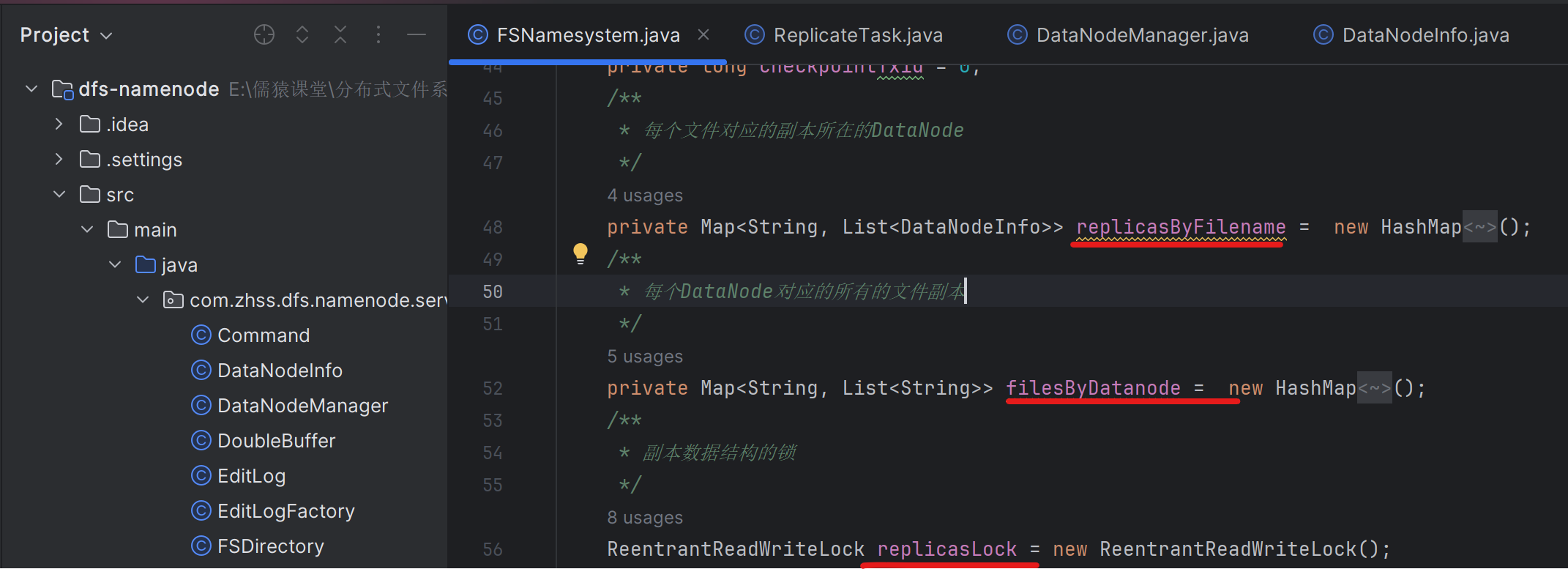
169_为副本复制任务去获取可用的源头数据节点
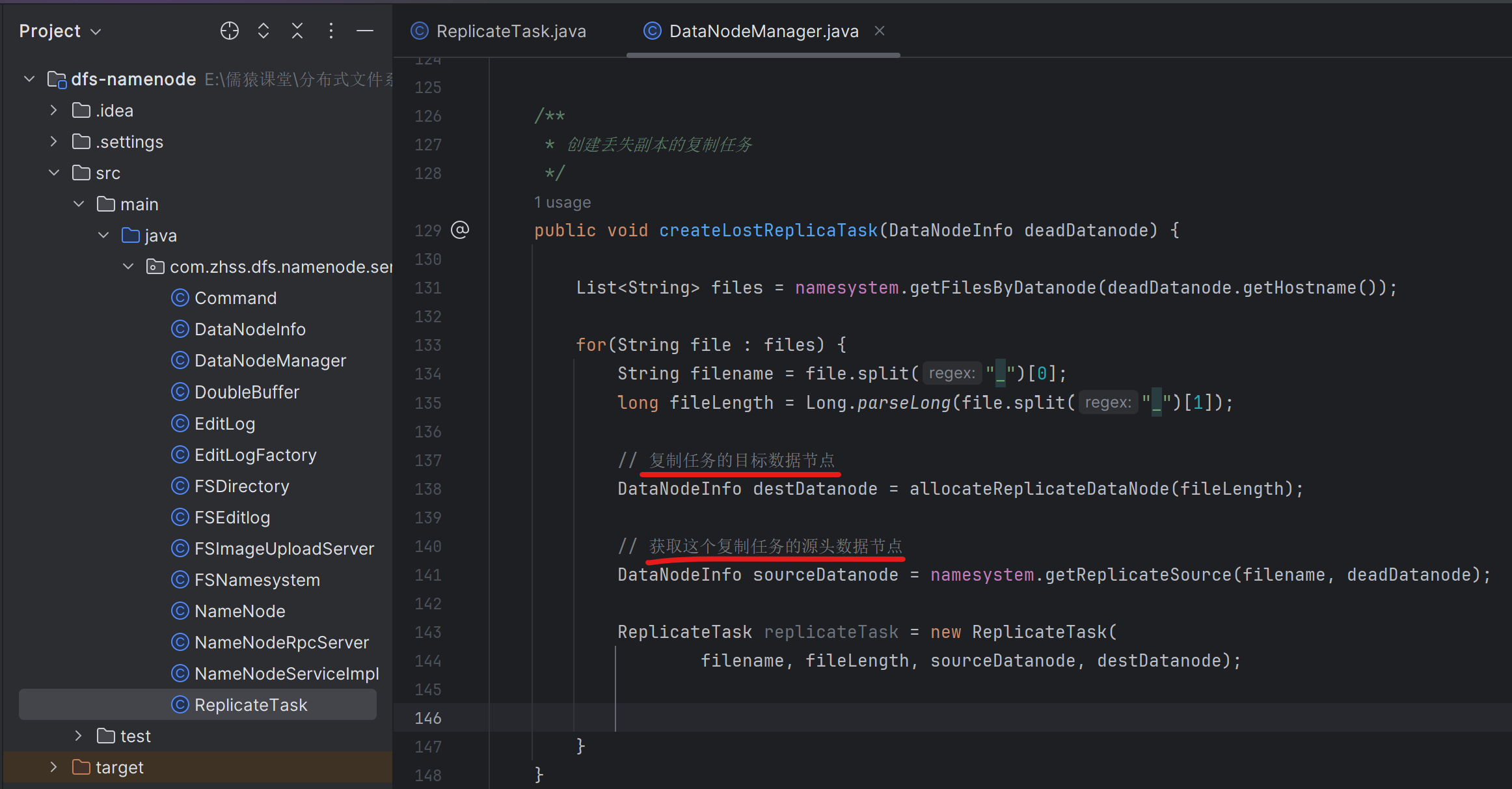
复制任务的源头节点,就是一个文件有两个副本,分别在两台dataNode只上,当前NameNode通过心跳探测机制,发现死了一个dataNode,那么另外一个dataNode就是本次文件副本的的复制源头节点
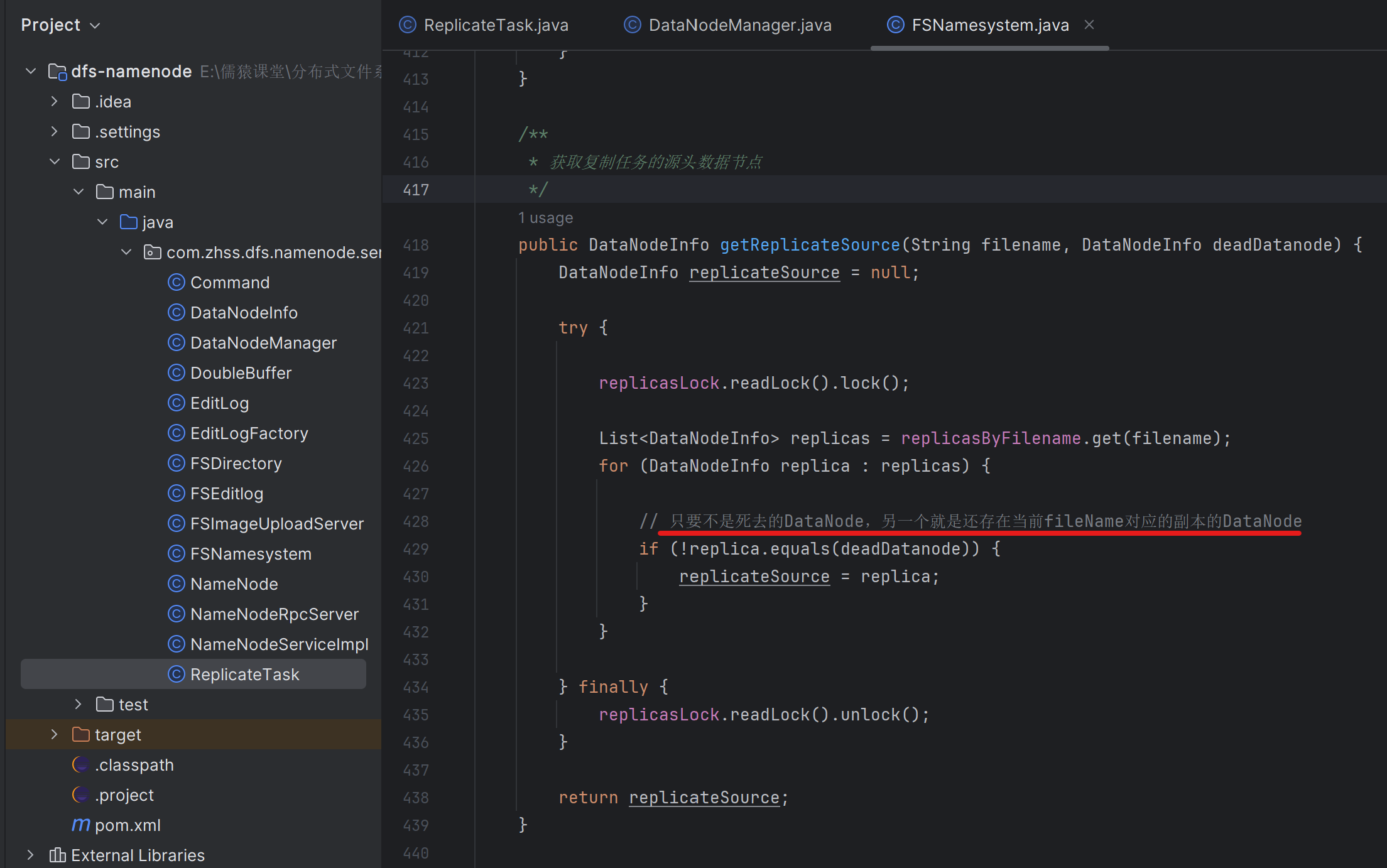

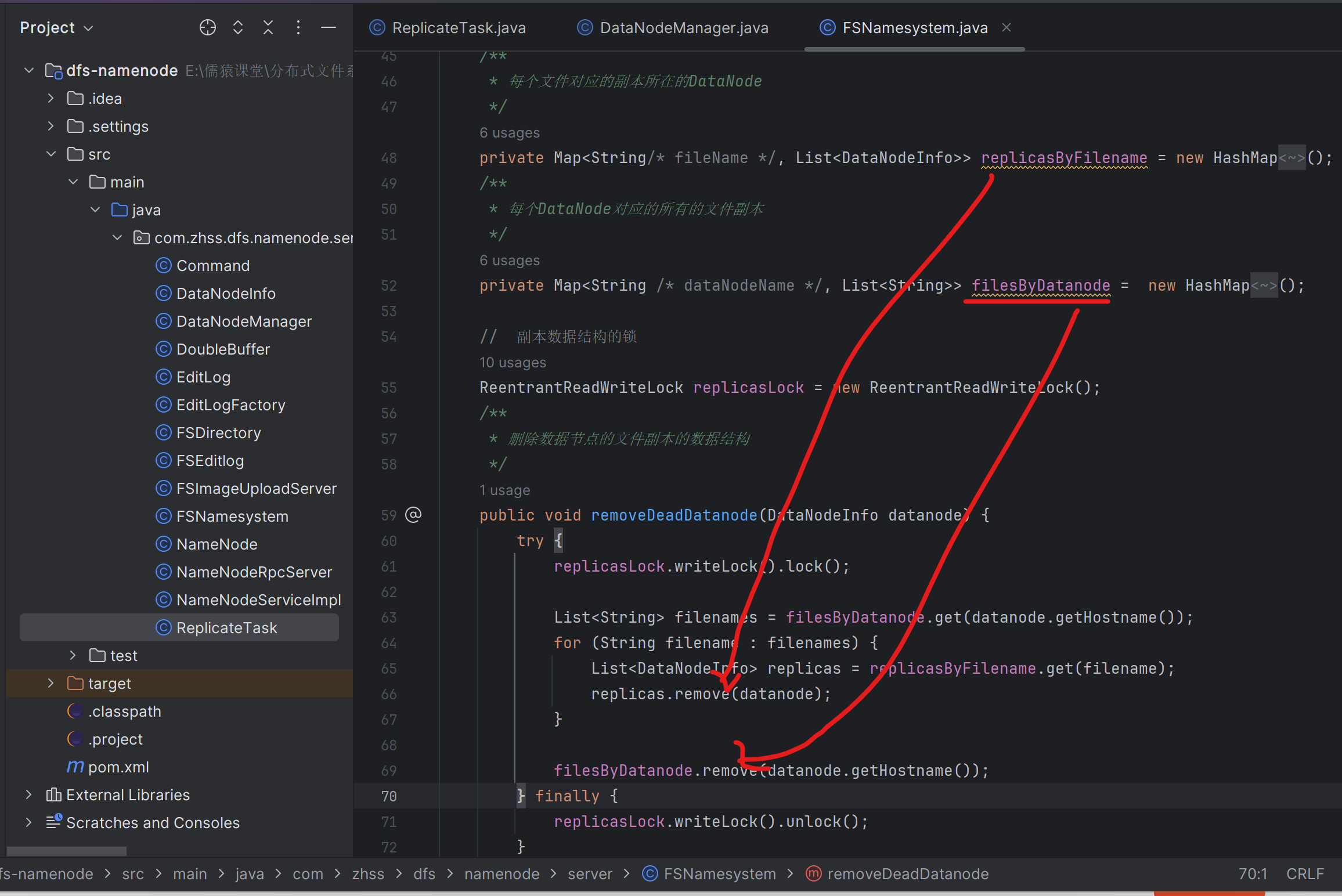
170_将创建好的副本复制任务放入目标数据节点的任务队列
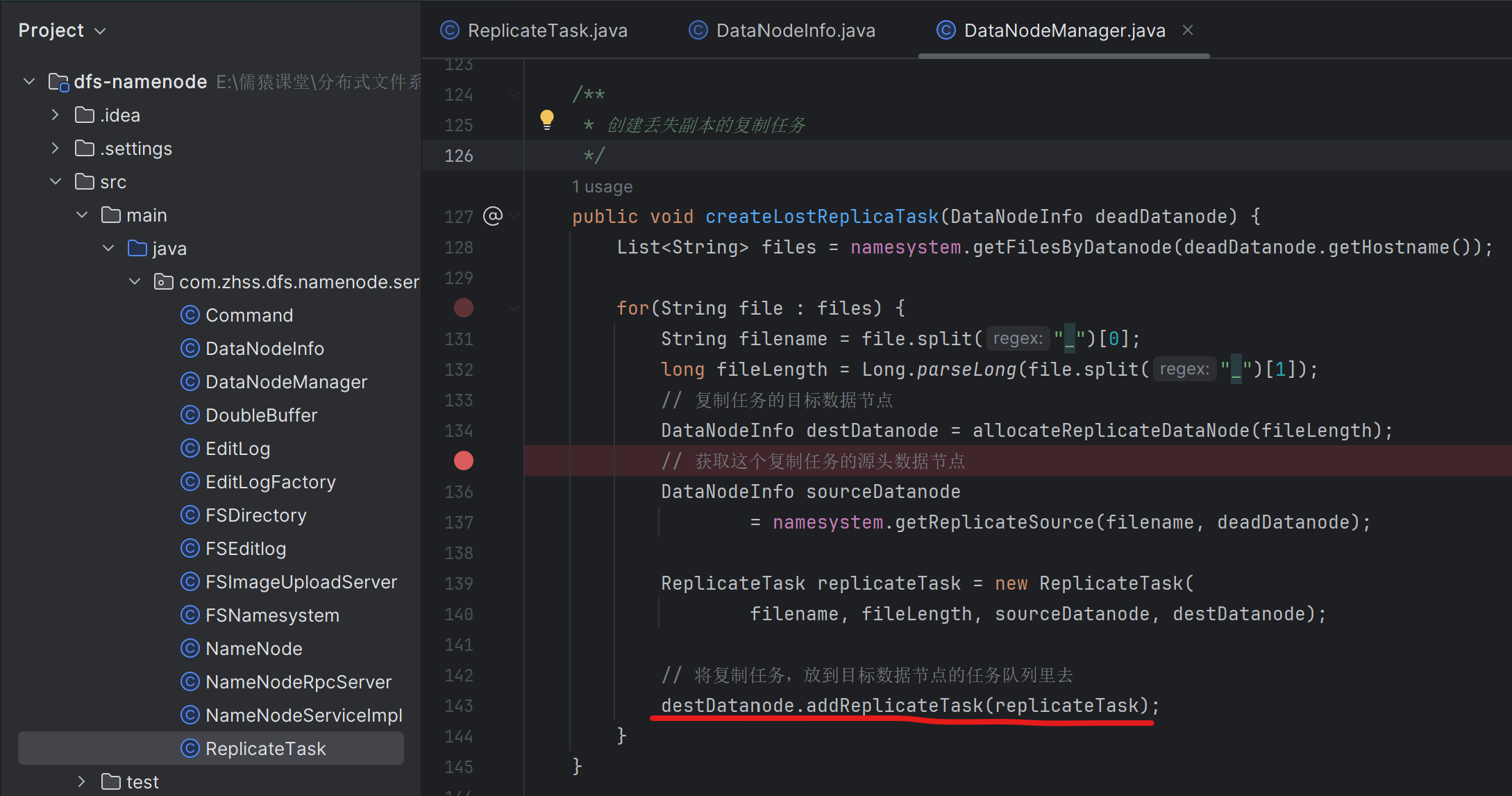
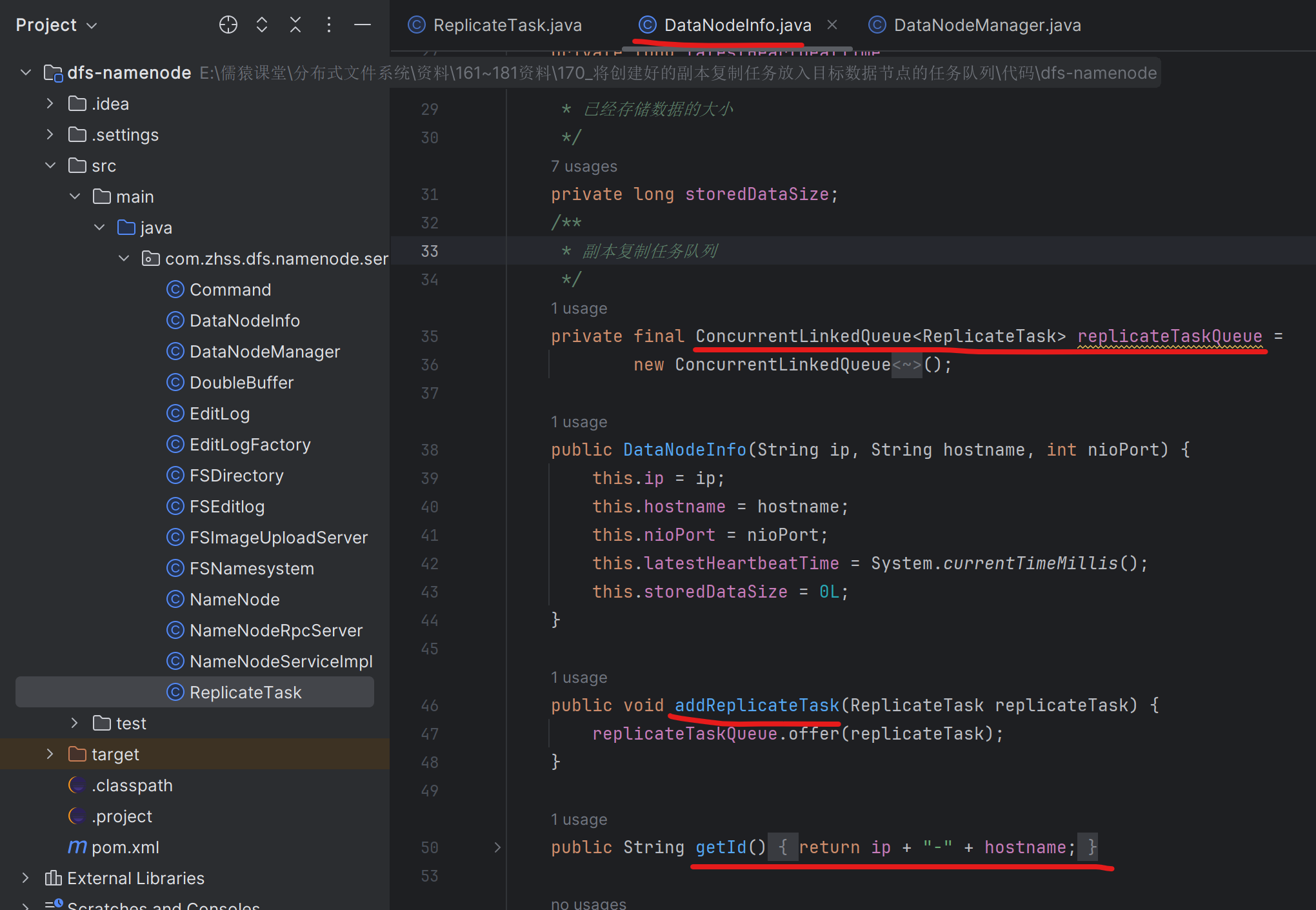
171_目标数据节点发送心跳时将复制任务下发给该节点
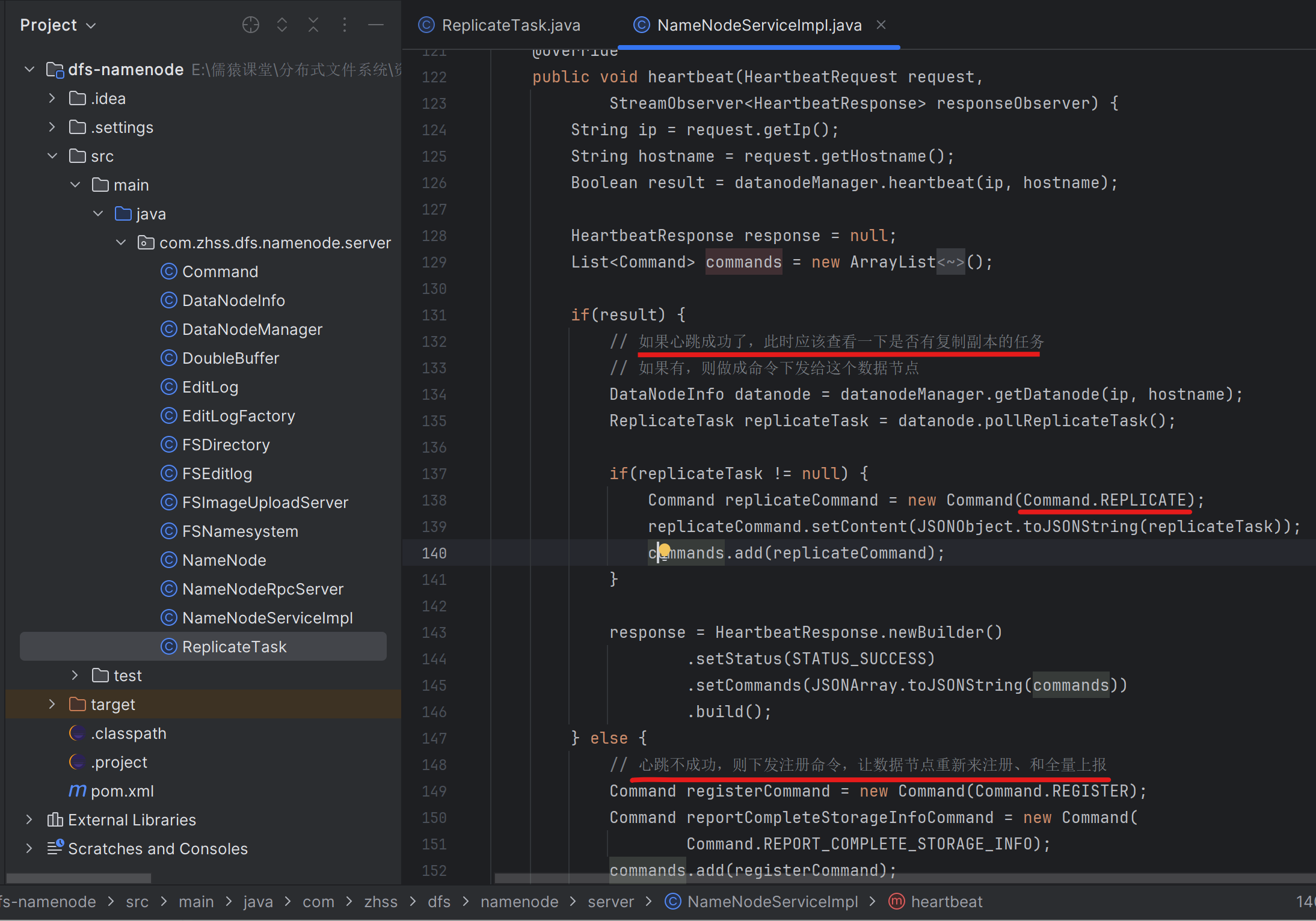
172_通过心跳响应让目标数据节点接收一个复制任务
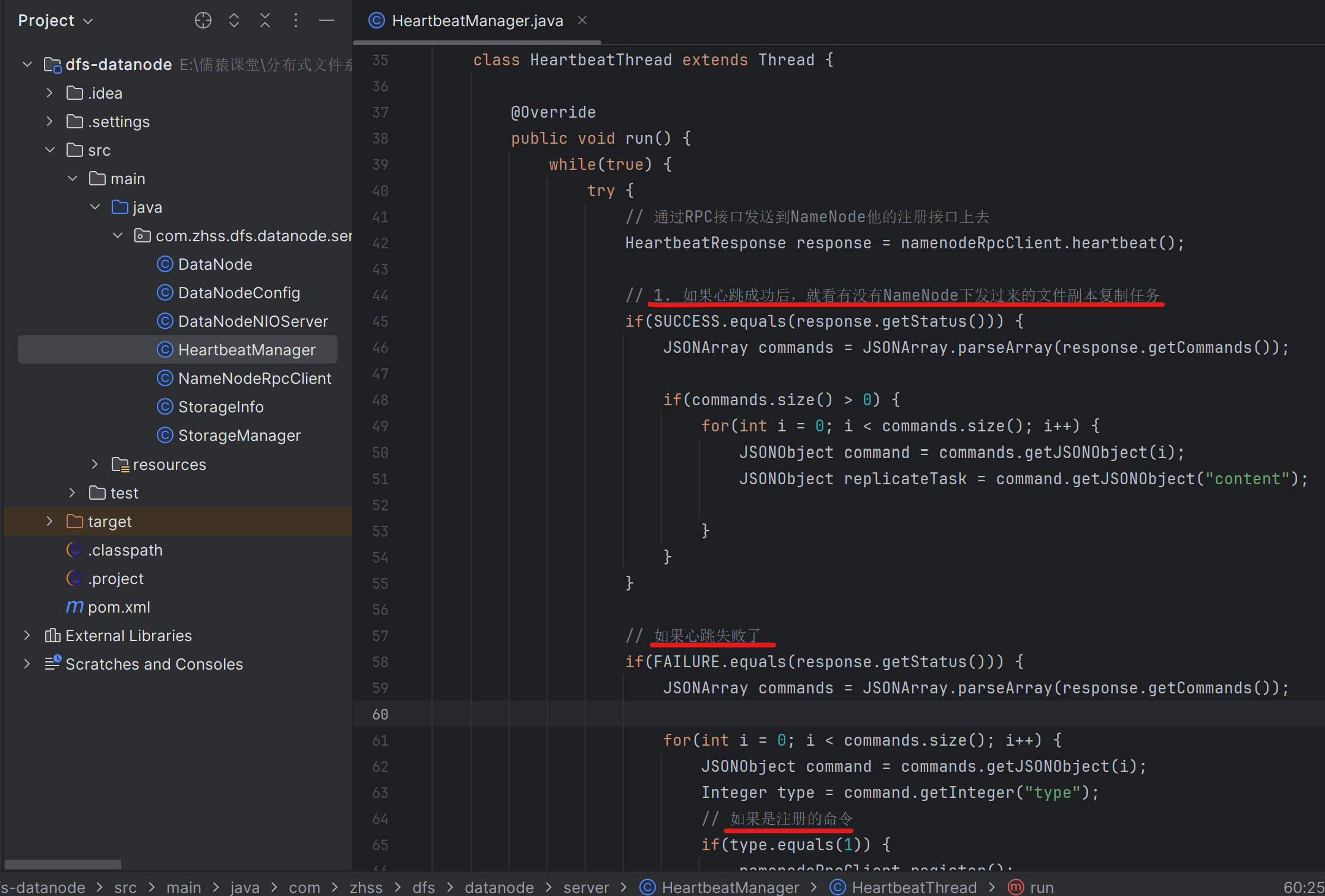
173_目标数据节点将接收到的复制任务放入本地任务队列中
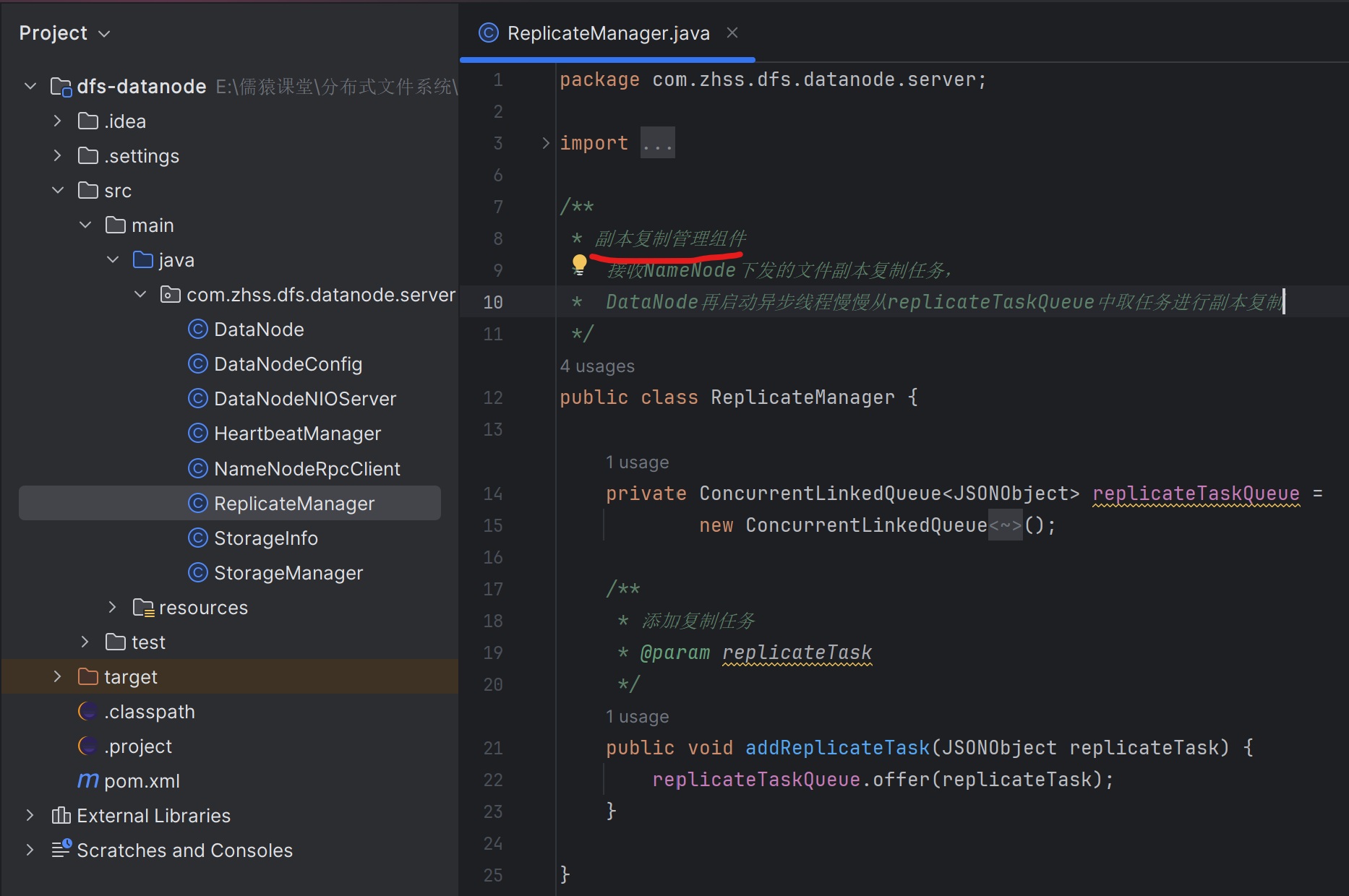
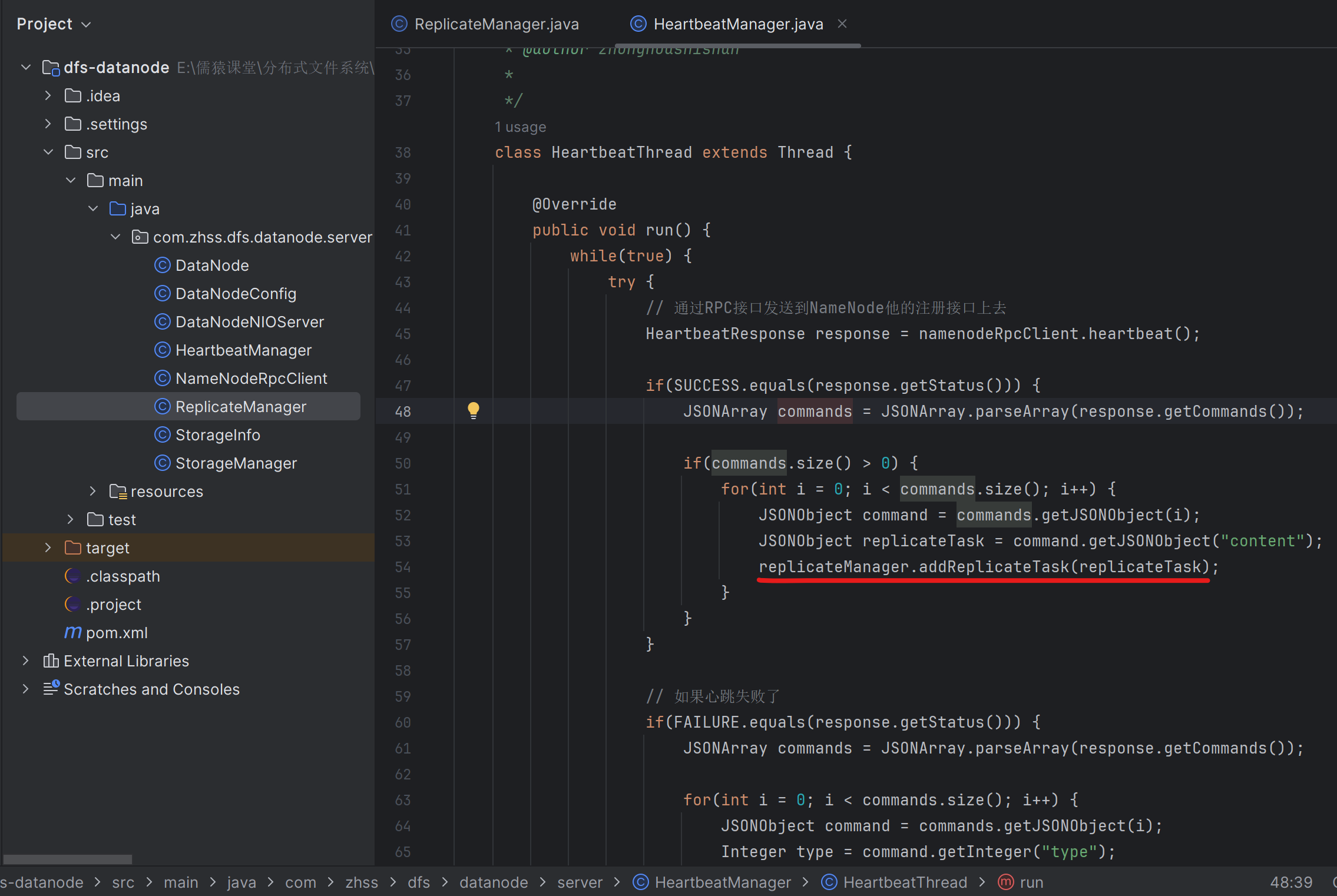
因为NameNode管理着21台DataNode集群,NameNode在探测到DataNode-A宕机后,比如DataNode-A上一共有500万文件,NameNode会把这500万文件,平均分25w到另外存活的每台DataNode上去,也就是每台DataNode的上面图第54行,会被执行25w次
174_设计与实现一个用于异步副本复制的线程
java
/**
* 副本复制管理组件
*/
public class ReplicateManager {
public static final Integer REPLICATE_THREAD_NUM = 3;
/**
* 副本复制任务队列
*/
private final ConcurrentLinkedQueue<JSONObject> replicateTaskQueue =
new ConcurrentLinkedQueue<JSONObject>();
public ReplicateManager() {
for(int i = 0; i < REPLICATE_THREAD_NUM; i++) {
new ReplicateWorker().start();
}
}
/**
* 添加复制任务
* @param replicateTask
*/
public void addReplicateTask(JSONObject replicateTask) {
replicateTaskQueue.offer(replicateTask);
}
/**
* 副本复制线程
* @author zhonghuashishan
*
*/
class ReplicateWorker extends Thread {
@Override
public void run() {
while(true) {
try {
JSONObject replicateTask = replicateTaskQueue.poll();
if(replicateTask == null) {
Thread.sleep(1000);
continue;
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}175_基于NIO实现两个数据节点之间进行副本的复制
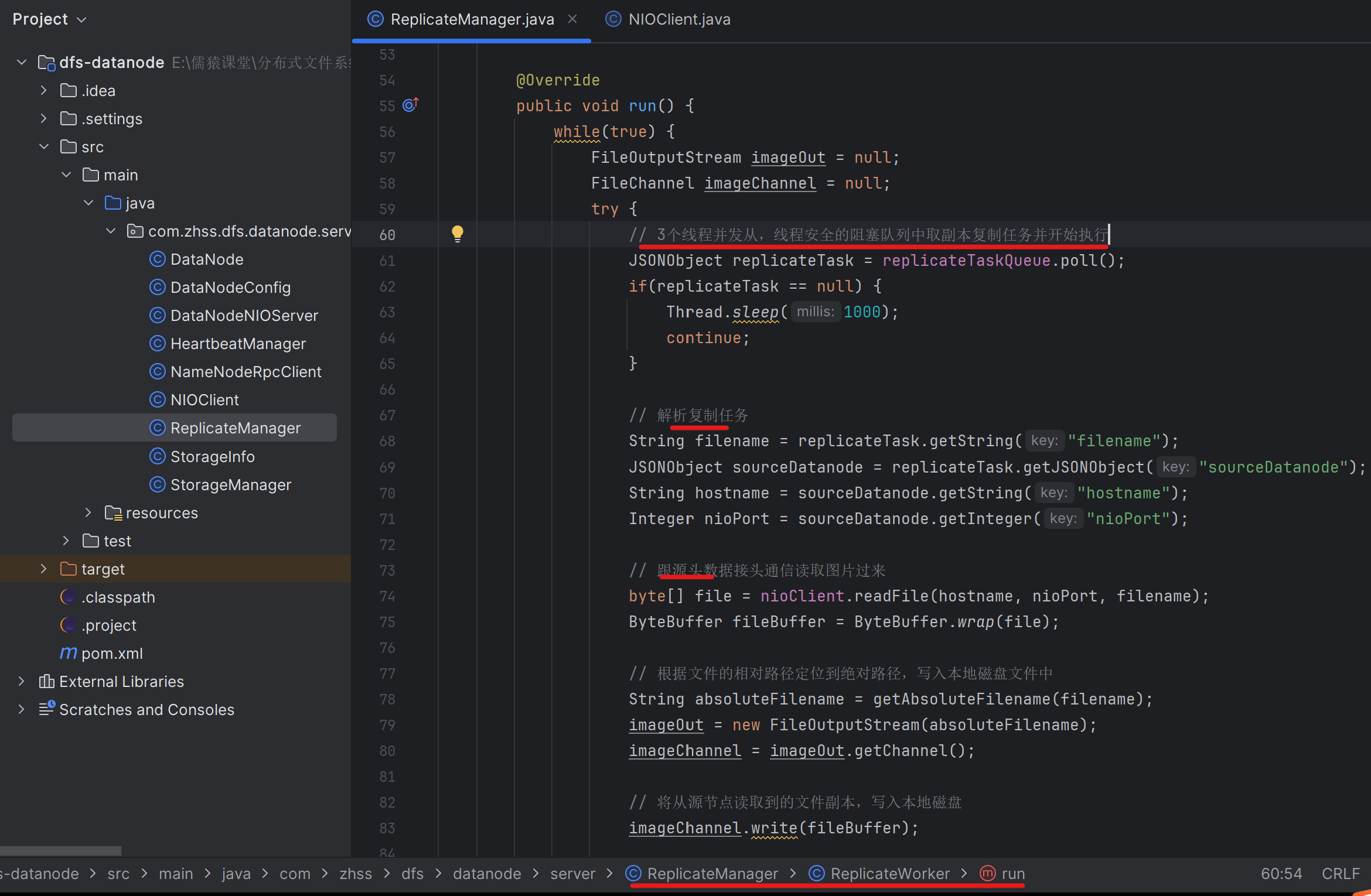
这里将文件副本写到本地后,还忘了一件事,就是要往NameNode进行增量上报