大型音频语言模型(Large Audio Language Model, LALM)是一类基于深度学习的智能系统,专门针对音频信号(如语音、音乐、环境声等)进行理解、生成、转换和推理。它借鉴了大型语言模型(LLM)的"预训练-微调"范式,但核心处理对象从文本扩展到了音频,同时融合了音频与文本、图像等多模态信息的关联能力。
核心特征与定义
- 处理对象:覆盖全类型音频信号,包括语音(含多语言、方言、情感)、音乐(旋律、节奏、风格)、环境声(如汽车鸣笛、雨声、机械故障音)等。
- 核心能力:通过大规模音频数据预训练,学习音频的底层声学特征(如频谱、时序)和高层语义信息(如内容含义、情感、场景),具备"理解音频"和"生成符合规律的音频"的通用能力。
- 多模态融合:通常与文本、图像等模态深度结合(例如,语音转文字、文本生成语音、音频描述图像内容等),实现跨模态交互。
技术基础
-
音频预处理
音频是连续的时域信号,需先转换为模型可处理的特征。常用方法包括:
- 频谱分析:将时域信号通过傅里叶变换转换为频域的梅尔频谱图(Mel-Spectrogram)或梅尔倒谱系数(MFCC),保留人类听觉敏感的频率信息。
- 波形建模:直接对原始音频波形(如16kHz采样的音频序列)进行建模(如使用WaveNet、Transformer的变体),避免特征损失。
-
模型架构
主流架构以Transformer为核心(因其擅长处理序列数据),结合音频特性优化:
- 编码器:将音频特征序列转换为上下文相关的向量表示(如处理语音时学习音素、语义的关联)。
- 解码器:基于编码器输出或文本输入生成音频序列(如语音合成、音乐生成)。
- 自监督预训练:通过无标注数据学习音频规律,例如"掩码音频建模"(Masked Audio Modeling,类似BERT的掩码机制)、"音频片段预测"(预测下一段音频内容)等。
-
训练范式
- 预训练:使用海量无标注音频数据(如数百万小时的语音、音乐库)训练通用能力,学习音频的统计规律和潜在结构。
- 微调:针对特定任务(如语音识别、音乐生成),用小规模标注数据调整模型参数,提升任务性能。
关键能力
-
音频理解
- 内容解析:语音识别(ASR)、多语言转写、方言识别、音乐结构分析(如区分主歌/副歌)、环境声分类(如识别"婴儿哭声""火灾警报")。
- 语义推理:理解音频的深层含义,例如从语音中提取情感(愤怒、喜悦)、从会议录音中总结重点、从工厂噪音中判断设备故障类型。
-
音频生成
- 语音合成(TTS):根据文本生成自然语音,支持多音色、情感控制(如悲伤的语调)、方言模拟。
- 音乐创作:生成原创旋律、伴奏,甚至根据文本描述(如"轻快的爵士钢琴曲")生成符合风格的音乐。
- 音效生成:根据场景需求生成特定音效(如游戏中"暴雨中的雷声""机器人故障音")。
-
音频转换
- 语音转换:将A的语音转换为B的音色,同时保留内容和情感。
- 降噪与增强:去除音频中的背景噪音(如会议录音去杂音)、修复受损音频(如老唱片修复)。
- 跨语言转换:实时将一种语言的语音翻译为另一种语言的语音(如英语演讲实时转为中文语音)。
-
多模态交互
- 音频-文本:语音转文字、文字生成语音、用文本描述音频内容(如"这段音频是狗叫声,背景有雨声")。
- 音频-图像:为视频生成匹配的背景音乐,或根据图像内容生成环境音效(如"森林图像"生成鸟鸣、风声)。
典型应用场景
- 智能交互:更自然的语音助手(如理解模糊指令、带情感回应)、实时会议纪要(自动转写+总结)。
- 内容创作:辅助音乐人生成旋律、为视频自动匹配音效、AI主播生成新闻播报音频。
- 无障碍技术:为听障人士实时生成字幕、为视障人士描述环境声音(如"后方有汽车鸣笛")。
- 安防与监测:通过异常声音(如玻璃破碎、尖叫)触发警报、工业设备异响检测故障。
- 教育与娱乐:语言学习中的发音测评、互动游戏中的动态音效生成、有声书自动配音。
挑战与局限
- 数据瓶颈:高质量标注音频数据稀缺(尤其多语言、多场景),无标注数据的利用效率需提升。
- 计算成本:模型参数量常达数十亿至数千亿,训练和推理需大规模GPU/TPU资源,实时性优化难度大。
- 鲁棒性问题:在噪声环境(如地铁中)、低质量音频(如模糊录音)下性能下降明显。
- 生成质量:生成音频的自然度(如语音的韵律、音乐的连贯性)仍需提升,易出现"机械感"或逻辑断裂。
- 版权与伦理:训练数据可能包含受版权保护的音频(如流行歌曲),存在侵权风险;深度伪造音频(如模仿他人语音诈骗)的伦理问题需规范。
代表模型
Kimi-Audio模型
源自论文:Kimi-Audio Technical Report
一、整体架构设计
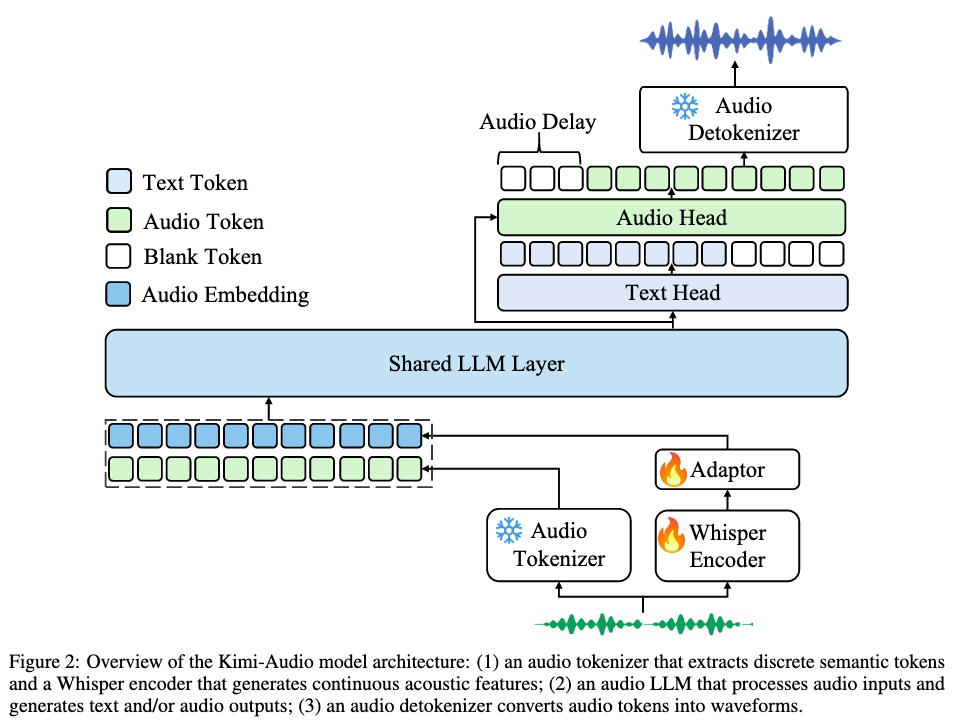
Kimi-Audio采用三组件一体化架构,实现音频理解、生成与对话的端到端处理,具体包括:
- 音频Tokenizer:负责将原始音频转换为模型可处理的表示
- 音频LLM:核心处理模块,支持多模态输入与多类型输出
- 音频Detokenizer:将模型生成的音频令牌转换为可听波形
二、核心组件设计
1. 音频Tokenizer(输入处理)
-
混合表示策略:
- 离散语义令牌:基于Whisper编码器的向量量化层,以12.5Hz帧率生成,捕捉语音语义信息
- 连续声学向量:从Whisper模型提取50Hz特征,通过适配器下采样至12.5Hz,保留细粒度声学特征
- 两种表示拼接后作为音频LLM的输入,兼顾语义理解与声学感知
-
关键优势:12.5Hz的统一压缩率缩小了音频与文本序列长度的差距,促进跨模态对齐
2. 音频LLM(核心处理)
-
架构设计:
- 共享Transformer层:采用预训练LLM(Qwen2.5 7B)的底层Transformer,处理多模态输入并学习跨模态表示
- 并行输出头 :
- 文本头: autoregressively预测文本令牌,负责语音识别、问答等任务
- 音频头:生成离散音频语义令牌,支持语音生成任务
- 初始化策略:共享层与文本头沿用LLM权重,音频头随机初始化,保留语言能力的同时学习音频处理
-
创新点:通过单一模型架构同时支持理解与生成任务,无需任务切换机制
3. 音频Detokenizer(输出生成)
-
两阶段转换:
- 流匹配模块:将12.5Hz语义令牌转换为50Hz梅尔频谱图
- BigVGAN声码器:将梅尔频谱图转换为音频波形
-
流式生成优化:
- 分块自回归框架:将音频分为1秒 chunks,通过因果掩码确保生成顺序性
- 前瞻机制:每个chunk拼接下一chunk的72个令牌(约4秒),解决边界间断问题
- 训练-free设计:仅延迟首个chunk生成,不增加计算负担
三、数据处理流程
1. 预训练数据构建
-
数据集规模:1300万小时多模态音频,涵盖:
- 语音类:有声书、播客、访谈
- 环境声:自然场景、城市声音
- 音乐:多种风格音乐片段
-
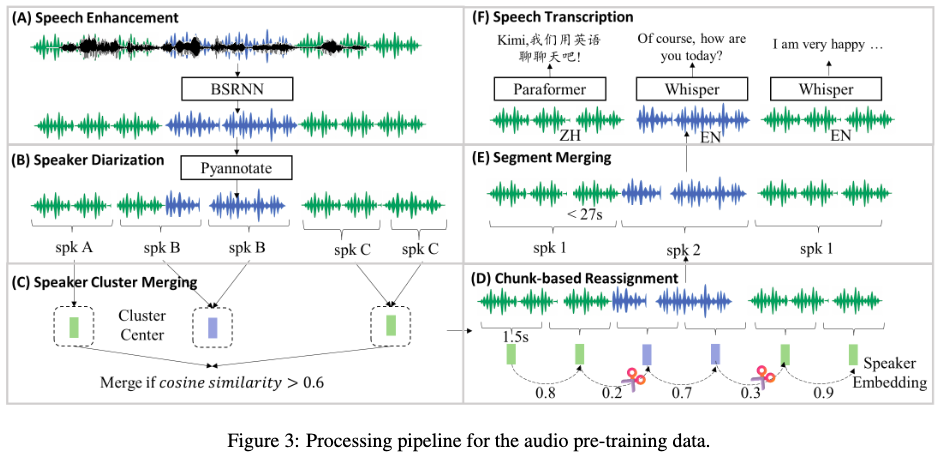
预处理 pipeline:
- 语音增强:基于BSRNN模型处理48kHz音频,随机混合原始/增强音频(1:1)保留环境信息
- 说话人分轨:使用PyAnnote工具+聚类优化(余弦相似度>0.6合并),解决标签碎片化
- 转录处理:Whisper-large-v3处理英文,Paraformer-Zh处理中文并自动添加标点
- 处理能力:30台云实例集群(240张L20 GPU)日处理20万小时音频
2. 微调数据(SFT)
- 三大任务类型 :
- 音频理解:涵盖ASR(10+数据集)、AQA、情感识别等6类任务,共约280K小时数据
- 语音对话:通过Kimi-TTS生成多样查询语音,Kimi-VC转换音色,构建多轮对话数据
- 音频-文本聊天:将700万+文本对话数据转换为语音查询-文本响应形式
四、训练策略
1. 预训练阶段
-
任务设计(三类七项任务):
任务类别 具体任务 目标 单模态预训练 文本仅预测、音频仅预测 分别学习文本/音频领域知识 跨模态映射 音频→文本(ASR)、文本→音频(TTS) 建立模态转换能力 交织任务 音频→语义令牌、音频→文本、音频→语义+文本 强化模态交互 -
训练配置:
- 初始化:基于Qwen2.5 7B模型扩展词汇表
- 数据量:5850亿音频令牌+5850亿文本令牌,训练1轮
- 优化器:AdamW,学习率2e-5→2e-6(余弦衰减)
2. 微调阶段
- 训练策略 :
- 采用自然语言指令引导任务,随机选择音频/文本指令形式
- 每任务构建多样化指令(ASR 200条,其他任务30条)
- 配置:2-4轮训练,学习率1e-5→1e-6,10%令牌用于热身
3. Detokenizer训练
- 三阶段训练:
- 100万小时音频预训练流匹配模块与声码器
- 分块微调(动态chunk大小0.5-3秒)
- 高质量单 speaker 数据微调提升自然度
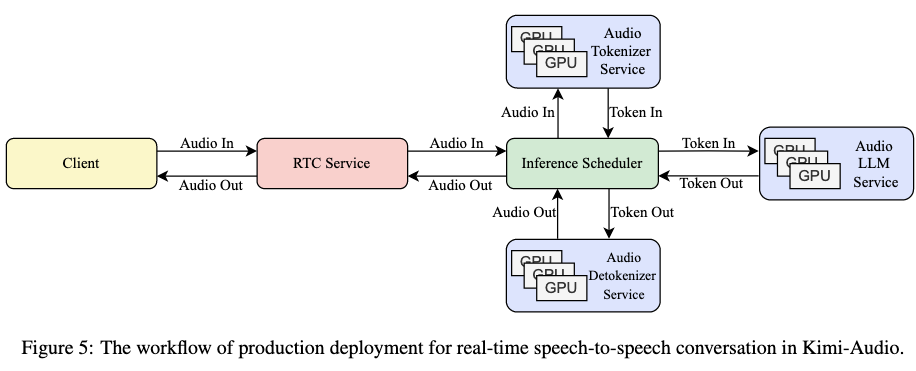
五、推理部署
-
实时语音对话流程:
- 客户端通过WebRTC流式传输音频
- 服务端VAD检测说话结束,触发模型推理
- 音频LLM生成响应令牌,Detokenizer实时转换为音频流
- 客户端边接收边播放,实现低延迟交互
-
部署架构:
- 模块化服务:Tokenizer/LLM/Detokenizer独立部署,负载均衡
- 推理调度器管理对话历史,确保上下文连贯性
该方法通过架构创新、数据规模突破与精细化训练,实现了音频领域的通用建模能力,在多项基准测试中达到SOTA水平。"
Qwen2-Audio
源自论文:Qwen2-Audio Technical Report
"该论文提出的Qwen2-Audio模型是一款大型音频语言模型(LALM),其核心方法围绕三阶段训练框架展开,结合特定的模型架构设计和数据处理策略,实现了对音频的深度理解与灵活交互。以下是具体方法的详细描述:
一、模型架构设计
Qwen2-Audio的架构由音频编码器 和大型语言模型(LLM) 两部分组成,整体采用"音频编码-文本生成"的端到端框架:
-
音频编码器
- 基于Whisper large-v3模型初始化,保留其对音频信号的基础建模能力。
- 音频预处理流程:
- 将原始音频重采样至16kHz,统一输入格式。
- 转换为128通道的梅尔频谱图(窗口大小25ms, hop大小10ms),捕捉音频的时频特征。
- 加入步长为2的池化层,缩短音频表示长度,使编码器输出的每个帧对应原始音频约40ms的片段,提升处理效率。
-
大型语言模型(LLM)
- 采用Qwen-7B作为基础组件,负责文本生成和指令理解。
- 模型总参数为8.2B,其中音频编码器与LLM的参数联合训练,实现音频特征与文本语义的深度融合。
-
训练目标
对于输入音频序列aaa和文本序列xxx,模型通过最大化下一个文本 token 的概率进行训练:
Pθ(xt∣x<t,Encoderϕ(a)) \mathcal{P}{\theta}\left(x{t} | x_{<t}, \text{Encoder}_{\phi}(a)\right) Pθ(xt∣x<t,Encoderϕ(a))其中,θ\thetaθ和ϕ\phiϕ分别为LLM和音频编码器的可训练参数,Encoderϕ(a)\text{Encoder}_{\phi}(a)Encoderϕ(a)为音频编码器输出的特征表示。
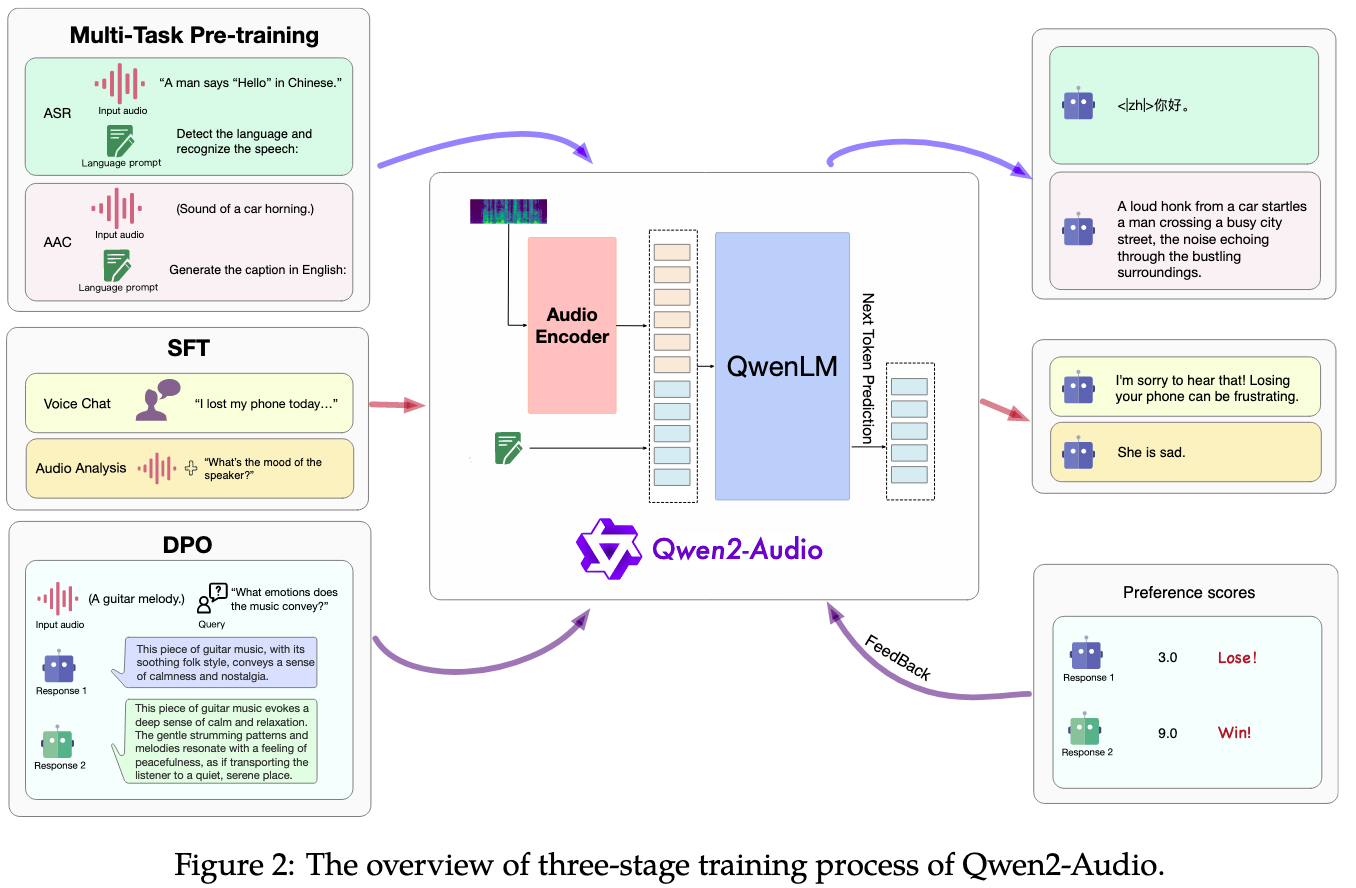
二、三阶段训练流程
Qwen2-Audio的训练分为预训练 、监督微调(SFT) 和直接偏好优化(DPO) 三个阶段,逐步提升模型的音频理解能力、指令遵循能力和人类偏好对齐度:
1. 多任务预训练:统一音频-文本关联学习
- 核心创新 :用自然语言提示 替代传统的层级标签(如"ASR""Sound"),统一不同数据和任务的预训练形式。
- 示例:
- 语音识别(ASR)任务:用提示"A man says 'Hello' in Chinese."对应文本"你好"。
- 声音分类任务:用提示"A loud honk from a car..."对应音频中的汽车鸣笛声。
- 示例:
- 数据规模:显著扩大训练数据量,涵盖Speech(370k小时)、Sound(140k小时)、Music(10k小时),包含多语言语音、环境音、音乐等多样化音频类型。
- 目标:让模型通过自然语言理解音频内容与文本的关联,提升跨任务泛化能力,缩小预训练与微调的差距。
2. 监督微调(SFT):强化人机交互对齐
- 核心目标:通过高质量指令数据,提升模型对人类意图的理解和响应能力,支持两种交互模式。
- SFT数据设计 :
- 精选高复杂度、高相关性的交互数据,涵盖语音聊天和音频分析场景。
- 数据需满足"指令-响应"对齐,例如用户问"这段音乐表达什么情感?",模型需输出符合人类认知的情感描述。
- 双模式联合训练 :
- 语音聊天模式:训练模型进行自由对话(如回答问题、提供建议),支持语音与文本交互的无缝切换。
- 音频分析模式:训练模型分析音频细节(如识别声音类型、音乐 tempo、混合音频中的语音内容)。
- 两种模式无需系统提示区分,模型通过输入内容自动判断(如含指令的音频触发分析模式,纯对话触发聊天模式)。
3. 直接偏好优化(DPO):提升输出质量与人类偏好对齐
- 核心思想:通过人类标注的"好/坏响应"对比数据,优化模型输出,使其更符合人类预期。
- 数据形式 :采用三元组数据(x,yw,yl)(x, y_w, y_l)(x,yw,yl),其中xxx为输入(含音频),ywy_wyw为人类偏好的"好响应",yly_lyl为"差响应"。
- 示例:对音乐情感分析的输入,"好响应"需详细描述情感(如"平静与怀旧"),"差响应"则过于简略(如"放松")。
- 优化目标 :通过以下损失函数最大化"好响应"的概率,最小化"差响应"的概率:
LDPO(Pθ;Pref)=−E(x,yw,yl)∼Dlogσ(β(logPθ(yw∣x)Pref(yw∣x)−logPθ(yl∣x)Pref(yl∣x))) \mathcal{L}{\text{DPO}}\left(\mathcal{P}{\theta} ; \mathcal{P}{\text{ref}}\right) = -\mathbb{E}{\left(x, y_w, y_l\right) \sim \mathcal{D}}\left \\log \\sigma\\left( \\beta \\left( \\log \\frac{\\mathcal{P}_{\\theta}(y_w \| x)}{\\mathcal{P}_{\\text{ref}}(y_w \| x)} - \\log \\frac{\\mathcal{P}_{\\theta}(y_l \| x)}{\\mathcal{P}_{\\text{ref}}(y_l \| x)} \\right) \\right) \\right LDPO(Pθ;Pref)=−E(x,yw,yl)∼Dlogσ(β(logPref(yw∣x)Pθ(yw∣x)−logPref(yl∣x)Pθ(yl∣x)))
其中,Pref\mathcal{P}_{\text{ref}}Pref为参考模型(初始化自微调后的模型),σ\sigmaσ为sigmoid函数,β\betaβ为控制优化强度的超参数。
三、关键技术特点
- 无需模式切换:通过联合训练和自然语言理解,模型自动区分语音聊天与音频分析模式,用户无需手动切换。
- 鲁棒性设计:能处理混合音频(如同时含对话、环境音、指令),精准提取关键信息(如从噪音中识别歌词或语音命令)。
- 零任务特定微调:模型在预训练和微调阶段已学习通用能力,在ASR、翻译、情感识别等任务上无需额外微调即可达到SOTA性能。
总结
Qwen2-Audio通过"自然语言提示预训练+双模式SFT+DPO偏好优化"的三阶方法,结合高效的音频-文本融合架构,实现了对多样化音频的深度理解和灵活交互,其核心创新在于简化预训练流程、强化人机对齐,并通过统一框架支持多场景应用。"
Pengi
源自论文:Pengi: An Audio Language Model for Audio Tasks
Pengi 是一种新型音频语言模型(Audio Language Model, ALM),其核心思想是将所有音频任务统一为"音频+文本提示→文本生成"的任务,通过迁移学习实现对开放式和封闭式任务的支持,无需额外微调或任务特定扩展。以下是其模型方法的详细描述:
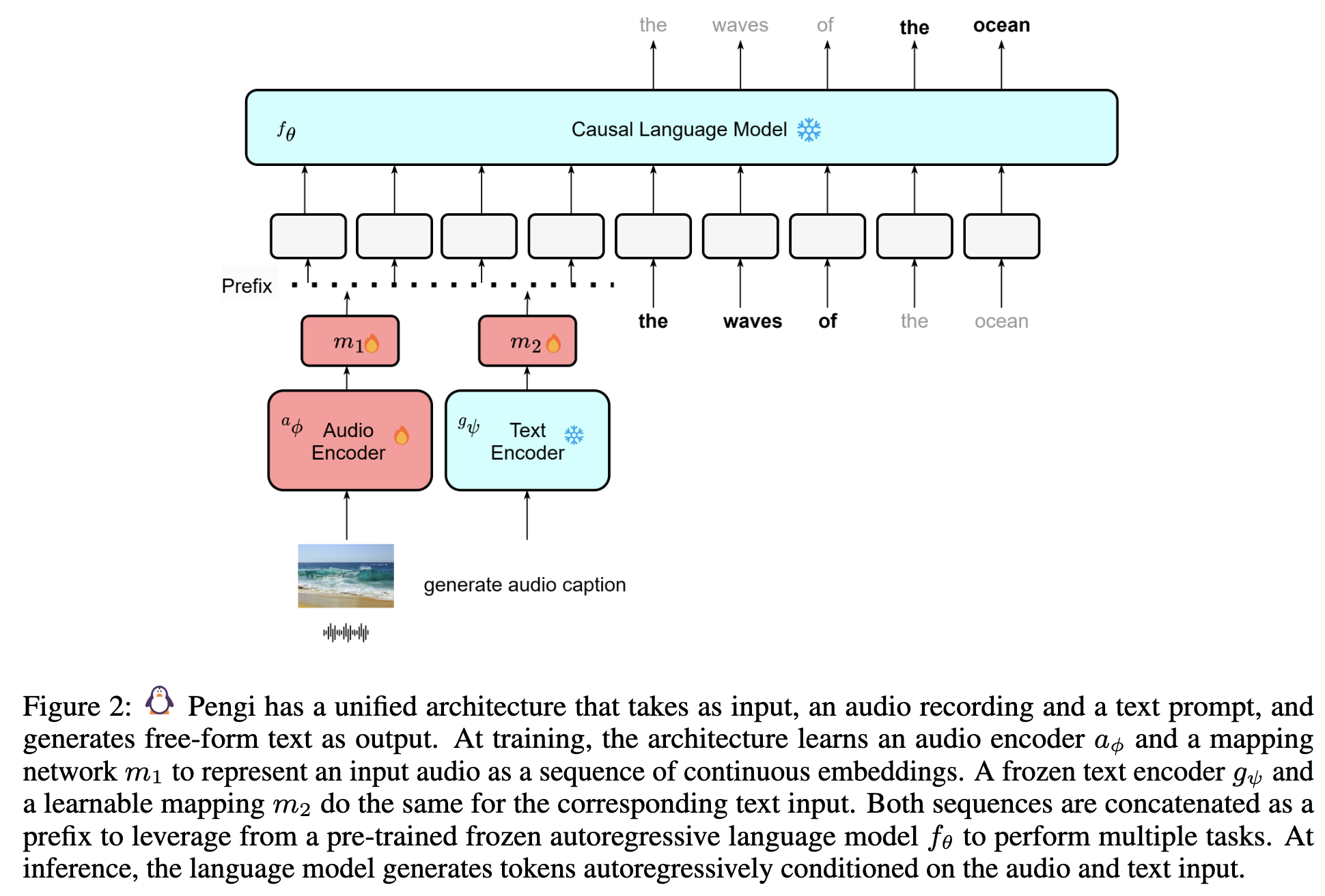

一、核心架构设计
Pengi 的架构由四个关键组件构成,通过"前缀融合"机制连接音频、文本输入与语言模型,实现跨模态生成。架构如图 2 所示:
-
音频编码器(Audio Encoder, aϕa_{\phi}aϕ)
- 功能:将原始音频信号转换为连续的音频嵌入(embedding)。
- 实现:采用 CLAP 15 中的音频 transformer 骨干网络 HTSAT 6,该模型在多模态音频任务中表现优异。
- 特点:与视觉语言模型(VLM)中冻结图像编码器不同,Pengi 的音频编码器在训练时解冻权重,以适应音频-文本对齐需求(因音频-文本配对数据规模远小于图像-文本数据)。
- 预处理:音频采样率 44.1 kHz,转换为 64 维 log Mel spectrogram,随机截断为 7 秒以统一输入长度。
-
文本编码器(Text Encoder, gψg_{\psi}gψ)
- 功能:将输入的文本提示(如任务指令"this emotion is")转换为文本嵌入。
- 实现:采用 CLIP 47 的文本编码器,训练时保持冻结,确保文本表示的通用性。
- 特点:支持任意自然语言提示(如问题、指令),最大输入长度设为 40 以提升计算效率。
-
映射网络(Mapping Networks, m1m_1m1 和 m2m_2m2)
- 功能:将音频编码器和文本编码器的输出转换为固定长度的序列,作为语言模型的"前缀"(prefix)。
- 实现:每个映射网络为 8 层 transformer,将单一声学/文本嵌入转换为长度为 40 的嵌入序列。
- 特点:可训练,负责将音频和文本嵌入映射到与语言模型兼容的 latent 空间,最终拼接为长度 80 的前缀(40 音频 + 40 文本)。
-
因果语言模型(Causal Language Model, fθf_{\theta}fθ)
- 功能:基于前缀生成自由文本输出,采用自回归方式预测下一个 token。
- 实现:使用预训练的 GPT2-base(124M 参数),训练和推理时均保持冻结,仅通过前缀引导生成。
- 特点:借助预训练语言模型的知识增强生成能力,同时避免过拟合特定任务。
二、训练框架:统一文本生成目标
Pengi 采用单一训练流程 和字幕生成目标函数,将所有音频任务转化为"音频-文本输入→文本输出"的格式。
-
训练数据与模板设计
- 数据规模:340 万音频-文本对,来自 16 个数据集(如 AudioSet、Clotho、NSynth 等),涵盖声音事件、情感、音乐等多领域。
- 任务模板:设计 8 种指令模板(见表 1),将任务标准化为"输入提示-输出格式"对,例如:
- 音频字幕生成:提示"generate audio caption"→输出描述性文本(如"海浪拍打海岸后退去");
- 声音事件分类:提示"this is a sound of"→输出事件标签(如"train, railway");
- 辅助任务:提示"generate metadata"→输出非任务特定的音频描述(如"background: quiet")。
-
训练目标与损失函数
- 目标:学习根据音频和文本前缀,自回归生成目标文本(如分类标签、字幕)。
- 前缀构建:
pi=concat{m1(aϕ(xi)),m2(gψ(ti))} p^i = \text{concat}\{m_1(a_{\phi}(x^i)), m_2(g_{\psi}(t^i))\} pi=concat{m1(aϕ(xi)),m2(gψ(ti))}
其中 xix^ixi 为音频,tit^iti 为文本提示,pip^ipi 为拼接后的前缀。 - 输入序列:将前缀与目标文本拼接为 zi=pi;ciz^i = p\^i; c\^izi=pi;ci(cic^ici 为目标输出),输入语言模型。
- 损失函数:交叉熵损失,优化目标文本的预测概率:
L=−∑i=1N∑j=1llogpγ(cji∣pi,c1i,...,cj−1i) \mathcal{L} = -\sum_{i=1}^{N} \sum_{j=1}^{l} \log p_{\gamma}\left(c_j^i \mid p^i, c_1^i, ..., c_{j-1}^i\right) L=−i=1∑Nj=1∑llogpγ(cji∣pi,c1i,...,cj−1i)
其中 γ\gammaγ 为可训练参数(音频编码器和映射网络的权重),文本编码器和语言模型权重冻结。
-
训练细节
- 优化器:Adam 32,训练 60 个 epoch,批大小 384,在 20 个 V100 GPU 上运行。
- 学习率:基础学习率 1e-4,线性调度+2000 步预热。
三、推理流程:基于前缀的文本生成
- 前缀构建 :对测试音频 xxx 和文本提示 ttt,通过音频编码器、文本编码器和映射网络生成前缀 ppp。
- 文本生成 :冻结的语言模型基于前缀 ppp 自回归生成文本,采用束搜索(beam size=5) 解码以提升输出质量。
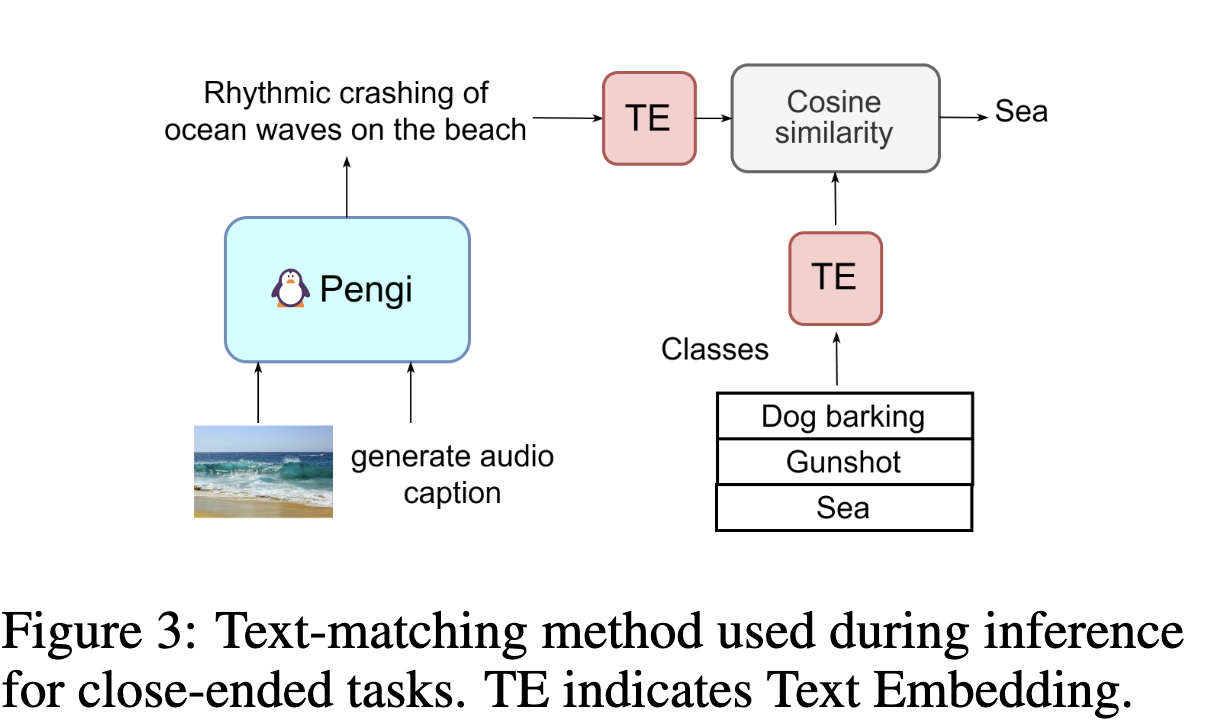
- 封闭式任务适配 :对于分类等任务,通过两种方式将生成文本与预定义类别匹配:
- 文本匹配:计算生成文本与类别标签的文本嵌入余弦相似度,取最高得分类别;
- 对数似然:计算每个类别作为输出时的概率,取最高值(适用于小类别集)。
四、关键创新点
- 统一架构:首次实现单一模型支持开放式(字幕、问答)和封闭式(分类、检索)任务,无需任务特定模块。
- 指令模板:借鉴 NLP 中的指令微调(如 FLAN 8),通过模板将任务标准化,增强跨任务迁移能力。
- 冻结语言模型复用:借助预训练语言模型的知识提升生成质量,同时避免重新训练大模型的成本。
通过上述设计,Pengi 在 21 个下游任务中多项指标达到 SOTA,证明了"音频-语言融合"框架在通用音频理解中的有效性。"
GLM-4-Voice
源自论文:GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
该论文提出的GLM-4-Voice模型是一款端到端的智能语音聊天机器人,其核心方法围绕语音-文本跨模态建模 和高效训练流程展开,具体可分为以下几个关键部分:
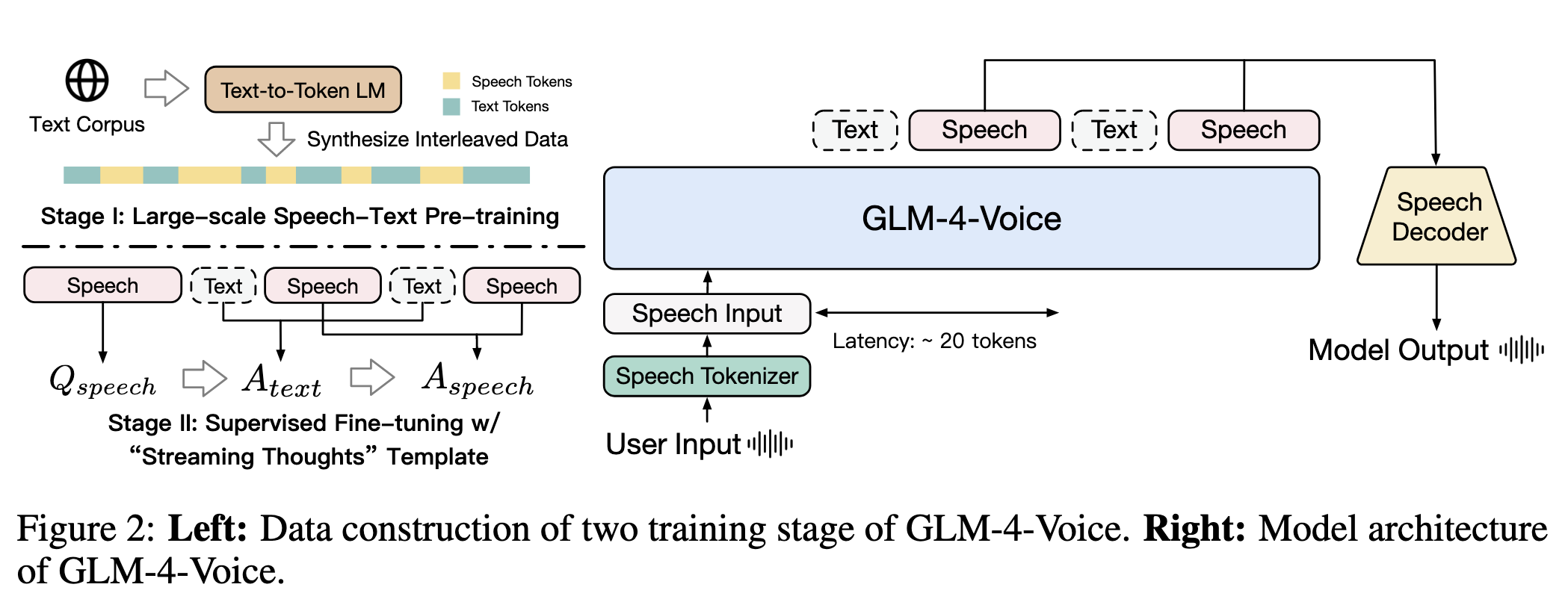
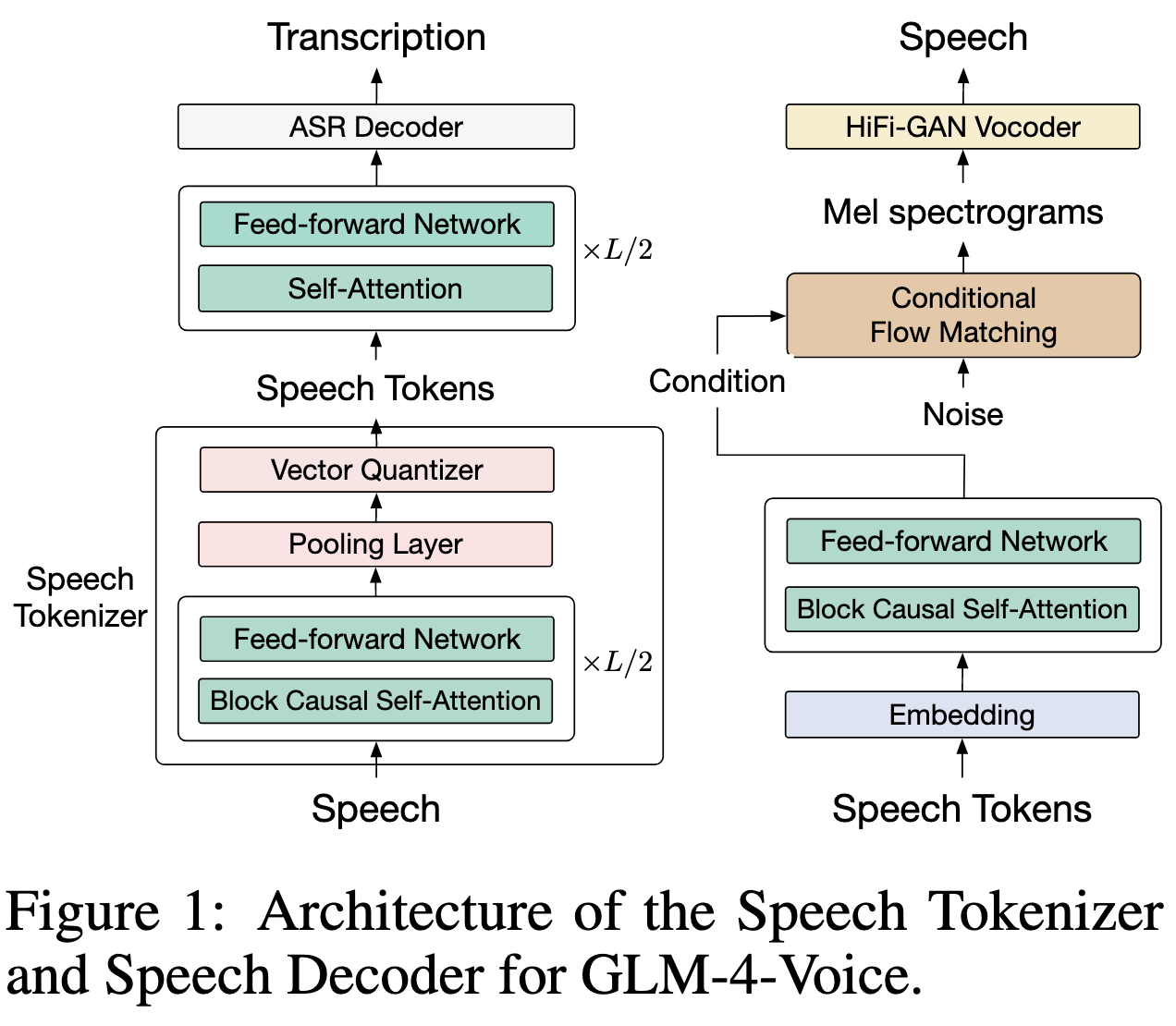
一、核心架构设计
GLM-4-Voice采用最小化修改的自回归Transformer架构,通过统一的语音表示实现输入输出的端到端处理,核心组件包括:
1. 语音Tokenizer(语音编码)
- 设计目标:将连续语音波形转换为离散令牌(tokens),同时保留语义信息和部分声学细节,支持低比特率传输和自回归生成。
- 技术细节 :
- 基于预训练的ASR模型(Whisper-large-v3)改造,在编码器中间加入池化层 和向量量化层(Vector Quantization),通过指数移动平均(EMA)学习码本向量,避免码本坍塌(Codebook Collapse)。
- 关键参数:采用12.5Hz帧率 (每秒生成12.5个令牌)、175bps超低比特率,单码本设计(无需多层残差量化),平衡效率与语音质量。
- 流式适配:将Whisper编码器的卷积层替换为因果卷积 ,双向注意力改为块因果注意力,支持实时流式语音编码。
- 优势:相比传统声学令牌(如SpeechTokenizer)的高比特率和语义令牌(如HuBERT)的低重建质量,该Tokenizer在保留语义(ASR准确率高)的同时,可生成高质量语音(MOSNet评分3.39)。
2. 语音解码器(语音合成)
- 功能:将离散语音令牌转换为自然语音波形,支持流式推理以降低交互延迟。
- 架构 :
- 由语音令牌编码器 、条件流匹配模型 (Conditional Flow Matching)和HiFi-GAN声码器组成。
- 训练分为两阶段:预训练使用海量多 speaker 语音数据,微调使用高质量单 speaker 数据,提升语音自然度。
- 流式推理优化 :
- 微调阶段引入截断音频样本(仅保留前n-b秒),使模型适应流式场景。
- 推理时,以历史语音为提示,逐块生成新语音(块大小b=0.8秒),最小延迟仅需10个语音令牌。
3. 推理机制
- 任务拆分 :将语音-语音交互拆解为两个子任务:
- 语音到文本(Speech-to-Text):根据用户语音输入生成文本响应。
- 语音+文本到语音(Speech-and-Text-to-Speech):结合用户语音和文本响应,生成带语调、情感的语音输出。
- 流式思维模板(Streaming Thoughts) :
- 交替生成文本令牌和语音令牌(比例1:2,即13个文本令牌+26个语音令牌),避免等待完整文本生成后再合成语音,降低延迟。
- 保证文本生成速度快于语音,确保语音合成时有足够上下文。
二、训练流程
GLM-4-Voice采用"预训练+微调"范式,通过大规模数据融合实现跨模态知识迁移:
1. 阶段一:联合语音-文本预训练
- 目标:将文本LLM的知识迁移到语音模态,提升语音建模能力。
- 初始化:基于GLM-4-9B文本模型扩展词汇表,加入语音令牌。
- 训练数据(总量1万亿 tokens) :
- 交织语音-文本数据:从文本语料合成,通过文本到令牌模型生成对应语音令牌,构建跨模态对齐数据(455B语音令牌+279B文本令牌)。
- 无监督语音数据:700k小时未标注语音,通过自回归预测学习语音规律(31B语音令牌)。
- 有监督语音-文本数据:ASR和TTS数据,强化语音与文本的对应关系(11B语音令牌+3.5B文本令牌)。
- 纯文本数据:保留10T文本令牌,维持文本处理能力。
- 训练配置 :
- 优化器:AdamW(β₁=0.9,β₂=0.95)。
- 学习率:从6×10⁻⁵线性衰减至6×10⁻⁶,序列长度8192。
2. 阶段二:监督微调
- 目标:提升对话能力和语音质量,适配真实交互场景。
- 训练数据 :
- 多轮对话语音数据:从高质量文本对话转换而来,过滤代码、数学内容,缩短长文本,合成对应语音。
- 风格控制数据:包含语速、情感、方言等风格指令的多轮对话,增强语音细节控制能力。
- 训练策略 :
- 拆分样本为两部分:一部分仅训练"语音到文本"(屏蔽语音输出损失),另一部分仅训练"语音+文本到语音"(屏蔽文本输出损失),解决两个子任务学习速度差异。
- 训练参数:语音输出训练20轮,文本输出训练4轮;学习率从1×10⁻⁵降至1×10⁻⁶;采用权重衰减(0.1)、dropout(0.5)和梯度裁剪(max=1.0)抑制过拟合。
三、核心创新点
- 高效语音令牌化:175bps超低比特率+12.5Hz帧率的单码本设计,兼顾语义保留、低延迟和语音质量。
- 跨模态知识迁移:通过合成交织语音-文本数据,将文本LLM的海量知识高效迁移到语音模态。
- 流式交互优化:语音编码器和解码器均支持流式处理,结合"流式思维"模板,实现低延迟实时对话。
- 细粒度语音控制:通过风格控制数据微调,支持情感、语调、方言等细节调整,接近人类语音表达能力。
通过上述方法,GLM-4-Voice在语音语言建模、口语问答、ASR/TTS等任务中均达到SOTA性能,且对话自然度和语音质量显著优于现有基线模型。
AudioPaLM
源自论文:AudioPaLM: A Large Language Model That Can Speak and Listen
"该论文提出的AudioPaLM模型是一种融合语音与文本的多模态大型语言模型,其核心方法围绕"统一模态表示""预训练权重迁移""跨任务训练"和"高质量语音生成"四个维度展开。以下是具体方法的详细描述:
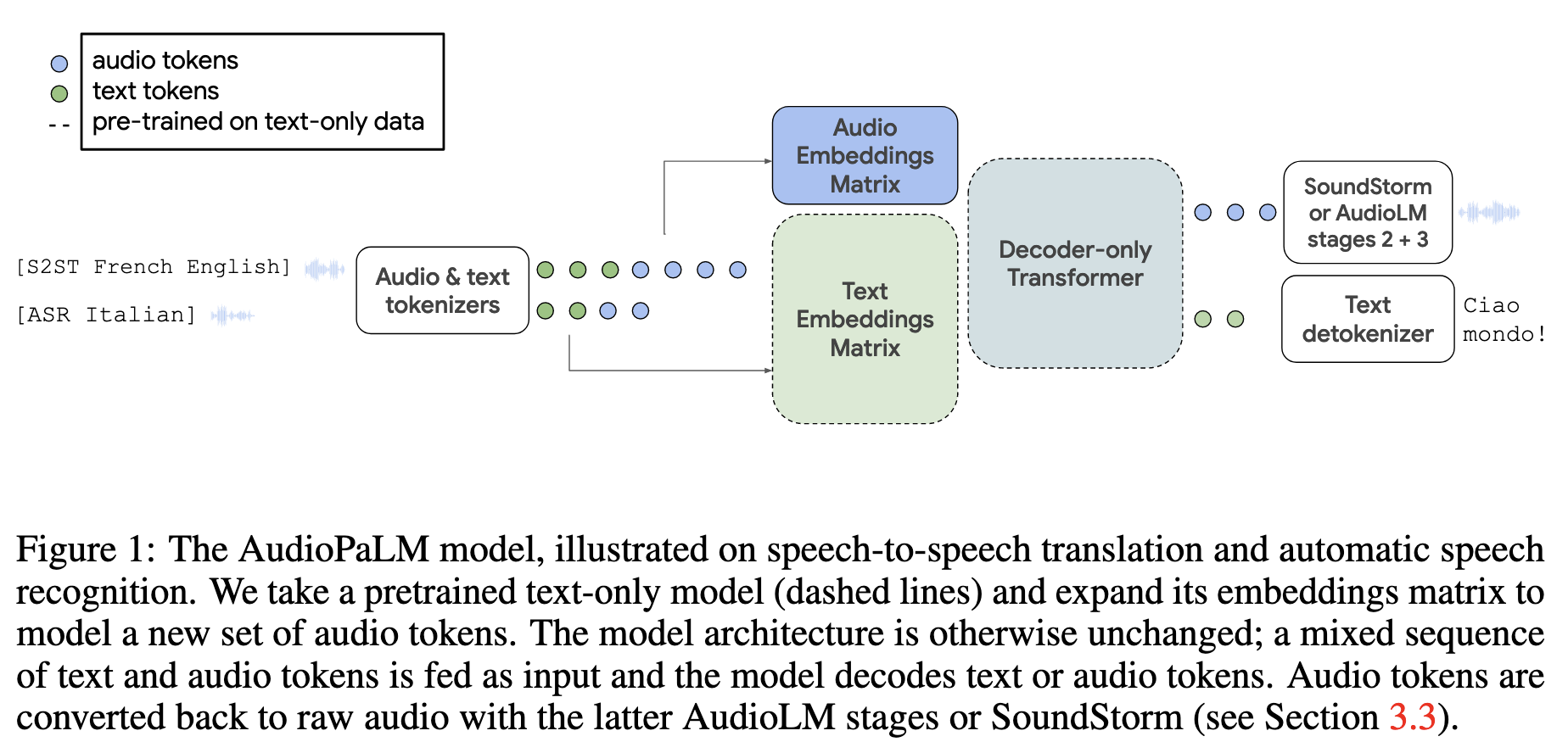
一、核心架构:统一多模态解码器
AudioPaLM采用单一解码器-Transformer架构,通过"联合词汇表"将语音和文本统一为离散令牌(tokens),实现对所有模态和任务的端到端处理。
- 输入/输出设计:模型的输入和输出均可为语音令牌、文本令牌或两者的混合序列(如"语音令牌+任务标签+文本令牌")。
- 任务灵活性 :通过前缀任务标签(如
[ASR 法语]表示法语语音识别,[S2ST 英语 法语]表示英语到法语的语音-语音翻译)指定任务类型,无需修改模型结构即可切换任务。
二、语音与文本的令牌化(Tokenization)
为实现模态统一,需将原始语音和文本转换为模型可处理的离散令牌:
1. 文本令牌化
- 采用SentencePiece工具将文本转换为子词令牌(subword tokens),与PaLM-2的文本词汇表兼容,确保模型能复用文本预训练的语言知识。
2. 语音令牌化
- 通过量化器 将原始音频波形转换为离散音频令牌,具体采用三种方案:
- w2v-BERT:基于多语言预训练的w2v-BERT模型提取语音嵌入,经k-means聚类量化为1024种令牌(采样率25Hz),保留多语言语音特征。
- USM-v1:使用更大规模的多语言语音编码器(Universal Speech Model,2B参数)提取嵌入并量化,提升语音表示的鲁棒性。
- USM-v2:在USM-v1基础上加入辅助语音识别(ASR)损失训练,优化多语言语音的语义编码,最终成为论文中性能最优的令牌化方案。
三、模型初始化与权重迁移
为融合文本大语言模型的语言知识,AudioPaLM通过以下方式初始化:
- 基于文本预训练模型扩展 :以PaLM-2(文本大语言模型)的权重为初始值,扩展其嵌入矩阵(token embedding matrix)以容纳新增的音频令牌。
- 文本令牌的嵌入直接复用PaLM-2的预训练权重,音频令牌的嵌入随机初始化并在训练中学习。
- 模型的所有参数(包括预训练的文本权重)均参与微调,确保语音与文本知识的深度融合。
- 优势:直接继承PaLM-2的跨语言翻译、语法理解等能力,解决语音模型语言知识不足的问题。
四、语音生成:从令牌到原始音频
模型输出的音频令牌需转换为可听的原始音频,论文采用两种解码方案:
1. AudioLM的自回归解码
- 分两阶段生成:
- Stage 2:以AudioPaLM输出的音频令牌和语音提示(如3秒原始语音片段)为输入,生成低比特率的SoundStream令牌(神经编解码器的中间表示)。
- Stage 3:重建SoundStream的高分辨率残差向量,提升音频质量至自然语音水平。
2. SoundStorm的非自回归解码
- 采用并行迭代方法一次性生成所有SoundStream令牌,速度比AudioLM快两个数量级,且语音质量和声音一致性(如说话人特征)更优,最终成为论文中首选方案。
五、多任务训练策略
为提升模型对复杂任务的适应性,AudioPaLM在混合任务数据上训练,具体包括:
1. 任务类型
- 基础任务:语音识别(ASR)、语音到文本翻译(AST)、文本到语音(TTS)、文本翻译(MT)、语音到语音翻译(S2ST)。
- 联合任务:将复杂任务拆解为多步子任务(如"S2ST"拆解为"ASR→AST→TTS"),强制模型生成中间结果(如先输出文本翻译再生成语音),类似"思维链"(Chain-of-Thought)提示,提升任务准确性。
2. 训练数据混合
- 采用多源数据集,包括:
- 语音-文本对齐数据(如CoVoST2、VoxPopuli)、纯语音数据(如CommonVoice)、文本翻译数据(如WMT/TED)。
- 合成数据:通过PaLM-2翻译文本并生成语音(如将YouTube语音的转录文本翻译为英语,再合成英语语音),扩充低资源语言的S2ST数据。
- 数据权重根据任务重要性调整,例如对大型数据集(如YouTube ASR)进行降权,避免模型过度拟合。
六、训练细节
- 优化器:使用Adafactor优化器,学习率为5×10⁻⁵,dropout率0.1。
- 损失函数:采用交叉熵损失,对输入部分进行掩码(loss masking),仅计算输出部分的损失。
- 模型规模:实验中主要使用8B参数模型(基于PaLM-2 8B初始化),并验证了模型规模对性能的影响(128M→1B→8B参数,性能随规模提升)。
方法核心优势
- 模态统一:通过联合词汇表消除语音与文本的壁垒,实现跨模态任务的端到端处理。
- 知识迁移:复用文本大语言模型的预训练权重,将丰富的语言知识迁移到语音任务。
- 灵活性:支持零样本任务(如未见过的语言组合翻译)和语音特征迁移(如跨语言保留说话人声音)。
- 高效性:单一模型替代多模型级联系统,减少部署成本且避免误差累积。"
MiDashengLM
源自论文:MiDashengLM: Efficient Audio Understanding with General Audio Captions
MiDashengLM 是一款开源大型音频语言模型(LALM),旨在通过通用音频字幕(General Audio Captions) 实现高效、全面的音频理解。其核心方法涵盖模型架构设计、训练流程、数据集构建及效率优化,具体如下:
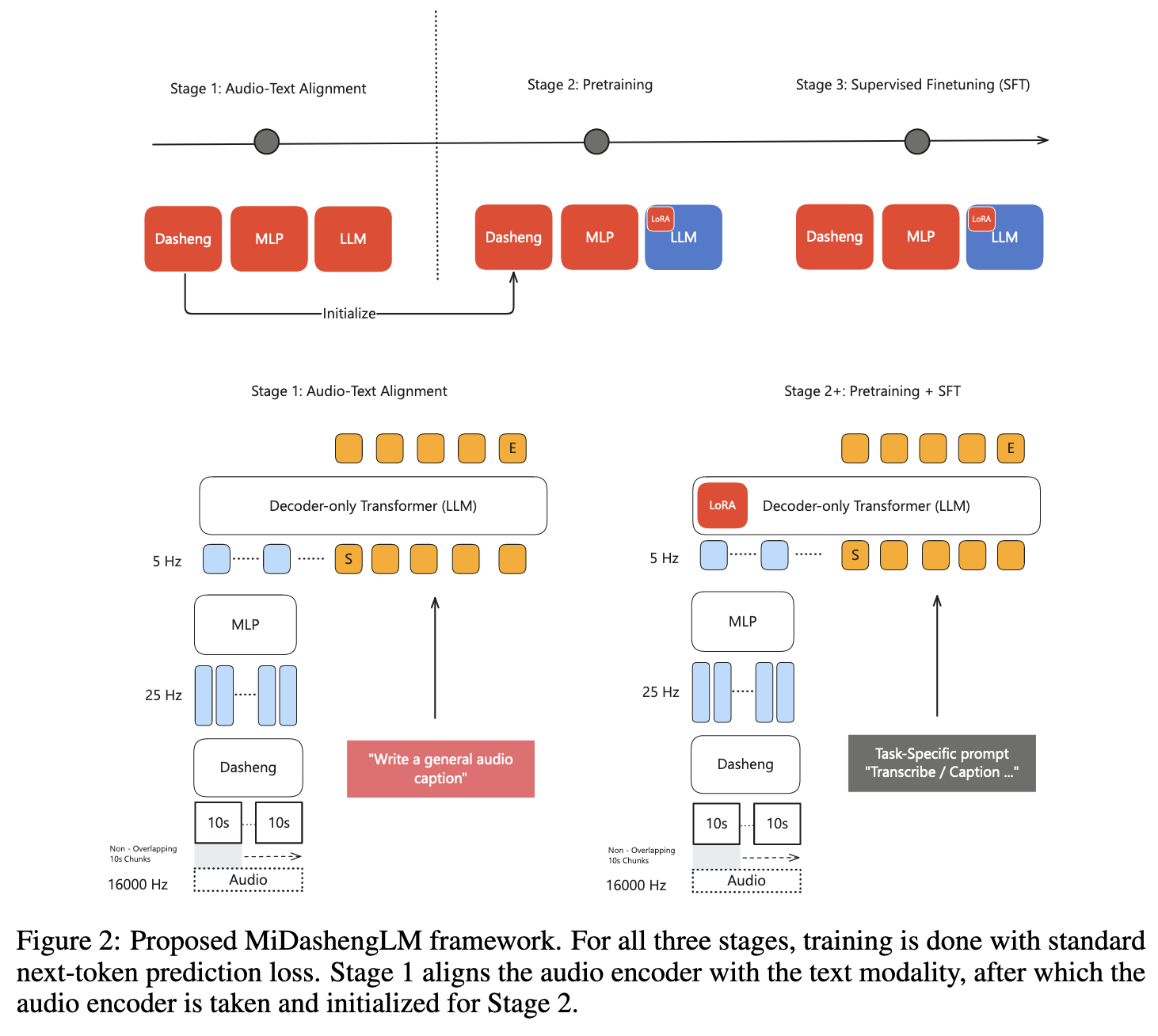
1. 整体架构设计
模型采用音频编码器-文本解码器的Transformer架构,核心是将音频特征映射至文本语义空间,实现跨模态理解。
| 组件 | 细节描述 |
|---|---|
| 音频编码器(Dasheng) | - 基于开源模型 Dasheng-0.6B,采用 Masked Autoencoder(MAE)预训练,参数约630.3M。 - 输入:16kHz 音频波形,转换为64维梅尔频谱图,以32ms帧长、10ms步长提取特征。 - 输出:支持可变长度输入(最长10.08秒),通过4倍下采样生成5Hz帧率的高层特征(每40ms一个特征帧),减少冗余计算。 - 优势:无需固定30秒填充(区别于Whisper),适配多数短音频样本(1-10秒),提升训练效率。 |
| 文本解码器 | - 基于 Qwen2.5-Omni-7B(70亿参数)初始化,采用 Decoder-only Transformer 结构。 - 优化:通过 LoRA(低秩适应)技术微调,仅更新部分参数(如注意力层的 query/value 矩阵),平衡性能与效率。 |
| 跨模态映射 | 音频编码器输出通过多层感知机(MLP) 映射至文本解码器的嵌入空间,实现音频-文本特征对齐。 |
2. 训练流程
采用三阶段训练策略,逐步优化模型的音频-文本对齐能力和任务适应性:
-
阶段1:音频-文本对齐
- 目标:将 Dasheng 编码器的音频特征与文本语义空间对齐。
- 数据集:使用 ACAVCaps(38,662小时通用音频字幕),强制模型学习"音频特征→通用字幕"的映射。
- 训练:端到端微调编码器和 MLP 层,采用 next-token 预测损失,训练3个 epoch,有效 batch size 为256。
-
阶段2:预训练
- 目标:扩展模型对多样化音频数据的理解能力。
- 数据集:总计约110万小时公开数据,包括 ASR 转录(90%)、声音/音乐字幕(10%),覆盖多语言、多场景。
- 训练:固定已对齐的音频编码器,仅微调解码器(LoRA 优化),训练1.4个 epoch,学习率1e-4,采用余弦衰减调度。
-
阶段3:监督微调(SFT)
- 目标:优化模型在具体任务(如字幕生成、分类、问答)上的性能。
- 数据集:精选35.2万小时高质量数据,包括 ACAVCaps 子集、标注精细的分类/问答数据。
- 训练:扩展 LoRA 作用范围(更新所有线性层),学习率降至1e-5,训练1个 epoch,增强任务适应性。
3. 核心创新:通用音频字幕与数据集构建
为解决传统音频字幕的局限性,论文提出通用音频字幕范式,并构建配套数据集:
-
通用音频字幕定义:融合三类信息------
- 语音:转录文本、语言、说话人特征(性别、情绪)、声学特性(混响、噪声);
- 环境声音:事件描述(如"风吹""鸟叫")、场景(如"户外");
- 音乐:风格(如"电子流行")、乐器、节奏、情绪。
示例:"俄语解说员以沙哑声线介绍合成器功能,背景伴随实验电子乐,带轻微混响"。
-
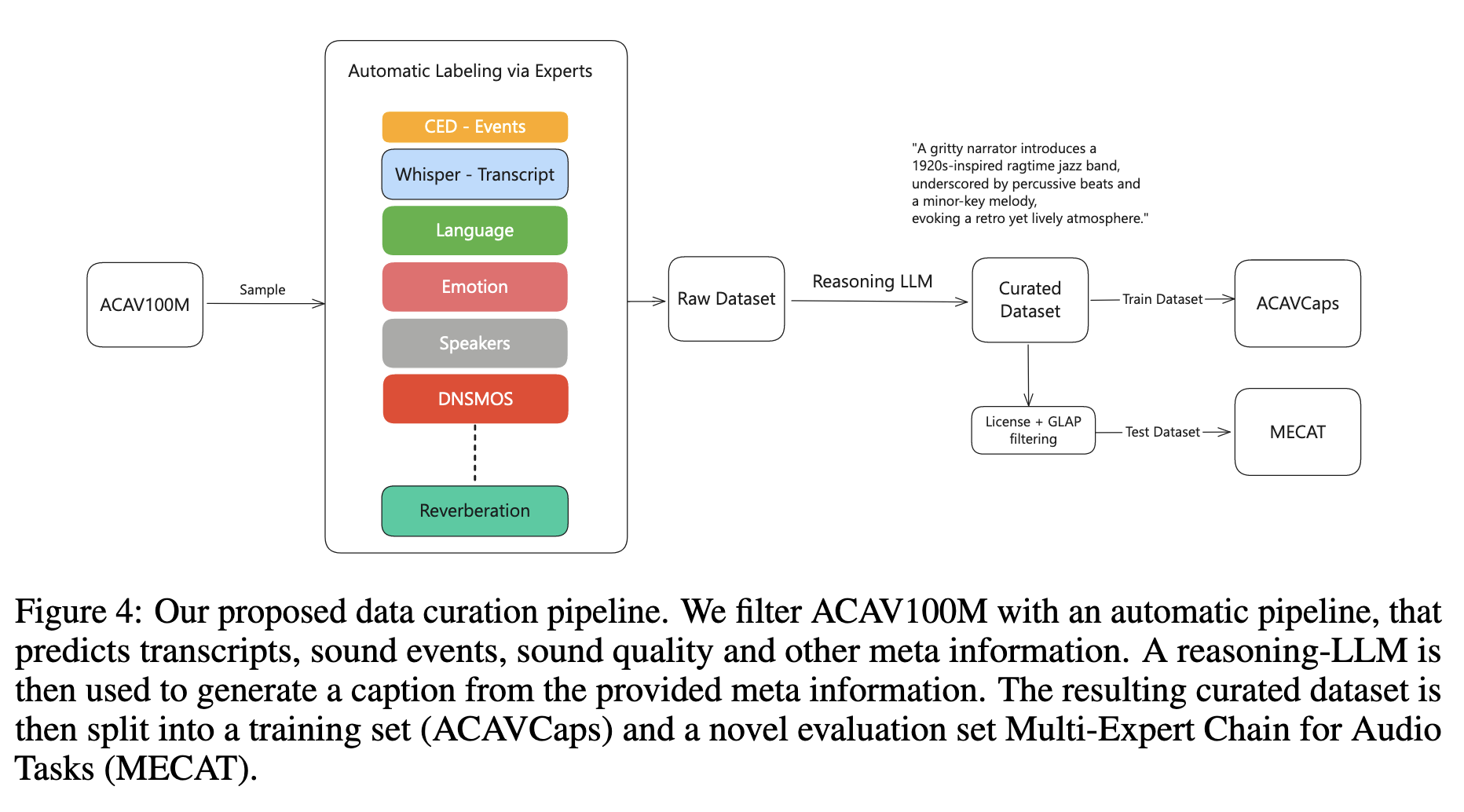
ACAVCaps 数据集构建流程(图4):
- 数据源:采用 ACAV100M(与传统数据集重叠少,含多语言、多场景音频)。
- 多专家标注:通过 CED-Base 预测声音事件,结合 Whisper 转录语音、情感分类器、音乐流派识别等模型提取细粒度特征。
- 字幕生成:使用推理 LLM(DeepSeek-R1)将多维度特征融合为自然语言字幕。
- 过滤:通过 GLAP(音频-文本一致性评分)和许可证筛选,确保质量。
-
MECAT 评估基准:
- 从 ACAVCaps 中拆分出的测试集,含9类任务(纯语音/声音/音乐、混合类型等),采用 FENSE 指标评估字幕质量。
- 配套 MECAT-QA:10万+问答对,覆盖感知(如"识别乐器")、分析(如"评估音质")、推理(如"推断场景")三级认知能力。
4. 效率优化策略
- 可变长度输入:Dasheng 支持动态处理不同长度音频(最长10.08秒),避免固定30秒填充(如 Whisper),减少50%以上冗余计算。
- 低帧率特征:音频特征输出帧率为5Hz(每200ms一个特征),大幅缩短序列长度,降低 decoder 计算负担。
- LoRA 参数高效微调:仅更新解码器的部分参数(预训练阶段更新注意力层,SFT 阶段扩展至所有线性层),训练成本降低60%+。
总结
MiDashengLM 通过通用音频字幕突破传统 ASR 依赖,结合开源编码器 Dasheng、三阶段训练流程及创新数据集,实现了对语音、声音、音乐的统一理解。其核心优势在于:(1)全面捕捉音频语义与声学特征;(2)高效利用数据,支持多语言和低资源场景;(3)推理速度与吞吐量远超同类模型,为开源音频语言模型提供了新范式。"
Step-Audio 2
源自论文:Step-Audio 2 Technical Report
Step-Audio 2是一款端到端多模态大型音频语言模型(LALM),旨在实现行业级音频理解与智能语音交互。其核心方法涵盖架构设计 、训练流程 、推理机制 及工具集成四大模块,具体如下:
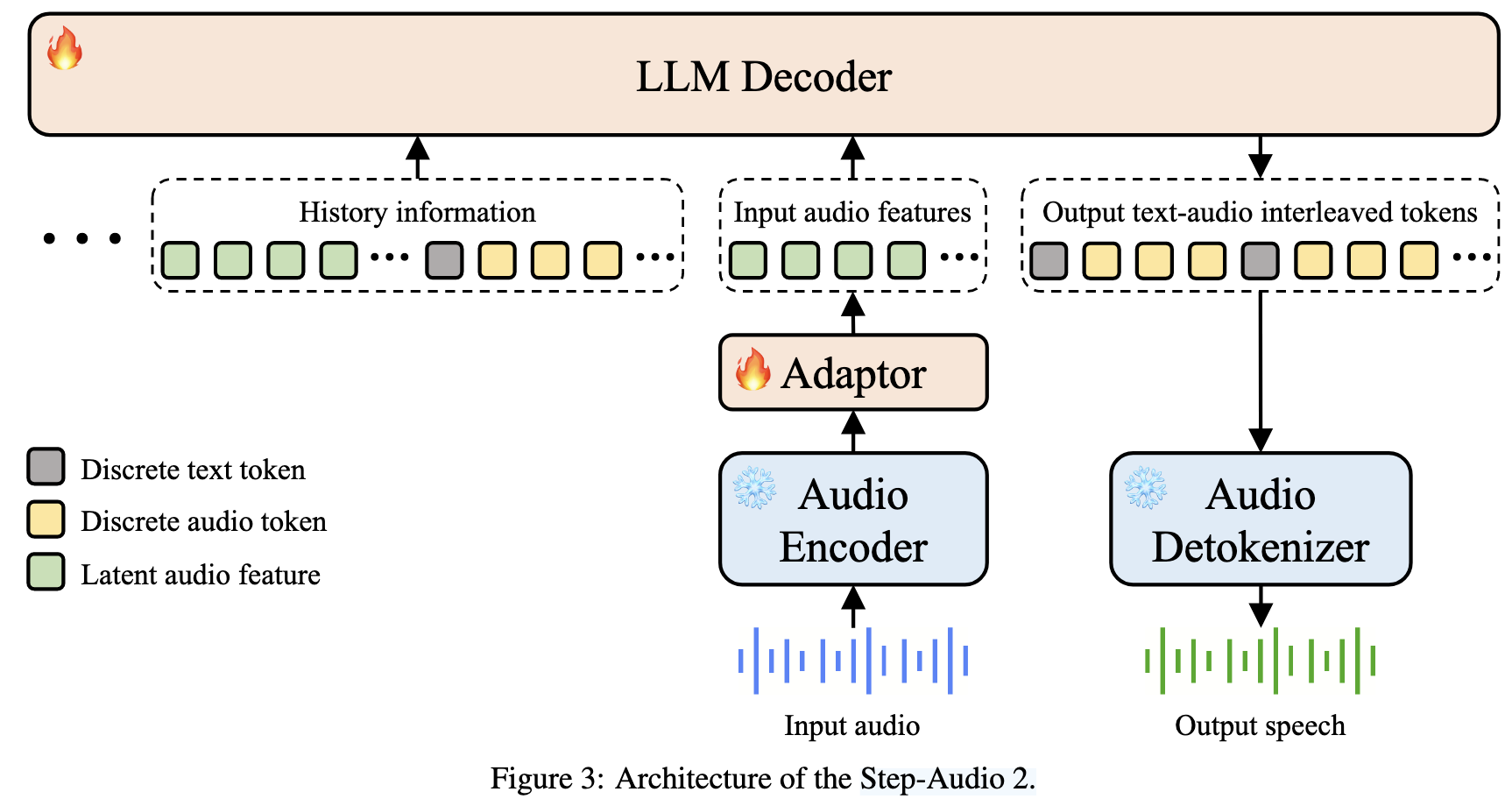
一、模型架构设计
Step-Audio 2的架构实现了从原始音频输入到语音输出的端到端处理,主要包含四个核心组件(如图3所示):
-
音频编码器(Audio Encoder)
- 功能:预处理原始音频,提取潜在音频特征。
- 细节:预训练于ASR、说话人年龄/性别预测、音频事件检测等任务,输出帧率为25 Hz,训练过程中参数冻结以保留预训练知识。
-
音频适配器(Audio Adaptor)
- 功能:连接音频编码器与LLM解码器,降低特征维度以适配语言模型。
- 细节:采用下采样率为2的设计,将音频编码器的输出帧率从25 Hz降至12.5 Hz,减少计算量的同时保留关键声学信息。
-
LLM解码器(LLM Decoder)
- 功能:接收潜在音频特征与历史对话信息,生成文本与音频令牌的交错序列。
- 细节:
- 采用CosyVoice 2的音频令牌器,将语音信号离散化为6.6K音频令牌,与文本令牌按固定比例交织。
- 输出序列包含文本令牌(用于语义交互)和音频令牌(用于语音生成),并将输入特征与输出序列作为历史信息缓存,支持多轮对话。
-
音频解令牌器(Audio Detokenizer)
- 功能:将离散音频令牌转换为可听语音波形。
- 细节:
- 包含Flow Matching模块(生成梅尔频谱图)和HiFi-GAN声码器(将频谱图转换为波形)。
- Flow Matching模块中加入CNN编码器层,提升梅尔频谱图重建精度,优化发音准确性和音色相似度。
二、训练流程
模型采用多阶段训练策略,涵盖预训练、监督微调(SFT)和强化学习(RL),具体如下:
-
预训练(Pre-training)
- 目标:对齐语音与文本特征空间,初步习得音频理解与生成能力。
- 阶段划分:
- 阶段1(对齐适应):使用1000亿ASR数据训练适配器,冻结音频编码器和LLM,学习率从1e-4降至2e-5,序列长度8192。
- 阶段2(扩展令牌):扩展LLM令牌器至6.6K音频令牌,使用1280亿文本+音频数据(含TTS、语音对话等)训练,序列长度增至16384,分层设置学习率(LLM:2e-5,适配器:5e-5)。
- 阶段3(大规模训练):在8000亿文本+音频数据(含ASR、翻译、对话等)上统一训练,学习率2e-5,强化多任务能力。
- 阶段4(任务冷却):使用2000亿高质量数据(含多语言ASR、副语言理解)微调,学习率从2e-5降至5e-6,引入5万独特说话人数据增强语音多样性。
-
监督微调(SFT)
- 目标:让模型遵循人类意图,掌握核心任务(如副语言理解、工具调用)。
- 细节:
- 在400亿文本+音频数据上训练1轮,学习率从1e-5降至1e-6。
- 数据集涵盖:多语言ASR(GigaSpeech、WenetSpeech)、音频理解(AudioSet重构为问答对)、副语言描述(11维度标注数据集)、语音翻译(CoVoST 2)、工具调用脚本(1K/工具类型)等。
-
强化学习(RL)
- 目标:提升复杂场景下的推理效率与响应质量。
- 阶段划分:
- 阶段1(长度控制):采用二进制奖励函数(简洁推理得1分,过长/过短得0分),PPO训练60轮,限制思考序列长度。
- 阶段2(质量优化):使用训练好的奖励模型评分,PPO训练120轮,优化响应相关性与自然度。
- 阶段3(感知增强):采用GRPO(Group Relative Policy Optimization)训练400轮,提升音频细节感知能力。
三、推理与交互机制
-
实时对话支持
- 集成语音活动检测(VAD)模块,过滤无效音频输入,实现低延迟实时交互。
-
副语言信息处理
- 通过CoT推理解析语音中的情感、语速、风格等信息(如"用户用悲伤语气提问"),生成匹配的响应(如降低语调、放缓语速)。
-
工具调用与检索增强
- 外部工具:支持调用网络搜索(如查询股票指数)、日期时间、天气等,通过语音指令触发。
- 音频搜索工具(创新点) :
- 内置含数十万语音样本的库,支持通过语音指令检索(如"模仿四川方言的老人")。
- 检索结果附加到输入特征中,用于动态切换音色和说话风格。
四、创新设计亮点
- 端到端令牌交织:将音频令牌生成融入语言建模,避免传统"ASR+LLM+TTS"级联架构的延迟与误差累积。
- 副语言理解增强:通过专项数据集(11维度标注)和RL优化,提升对情感、音色等信息的捕捉与应用能力。
- 多模态检索增强:结合RAG与音频搜索工具,利用真实世界知识减少幻觉,扩展语音风格多样性。
通过上述方法,Step-Audio 2在语音识别、音频理解、跨语言对话等任务中实现了state-of-the-art性能,支持自然、智能的多场景语音交互。"
AudioChatLlama
源自论文:AudioChatLlama: Towards General-Purpose Speech Abilities for LLMs
"该论文提出的AudioChatLlama 模型旨在为大型语言模型(LLMs)赋予通用语音处理与推理能力,其核心方法围绕端到端架构设计 和模态对齐策略展开,具体如下:
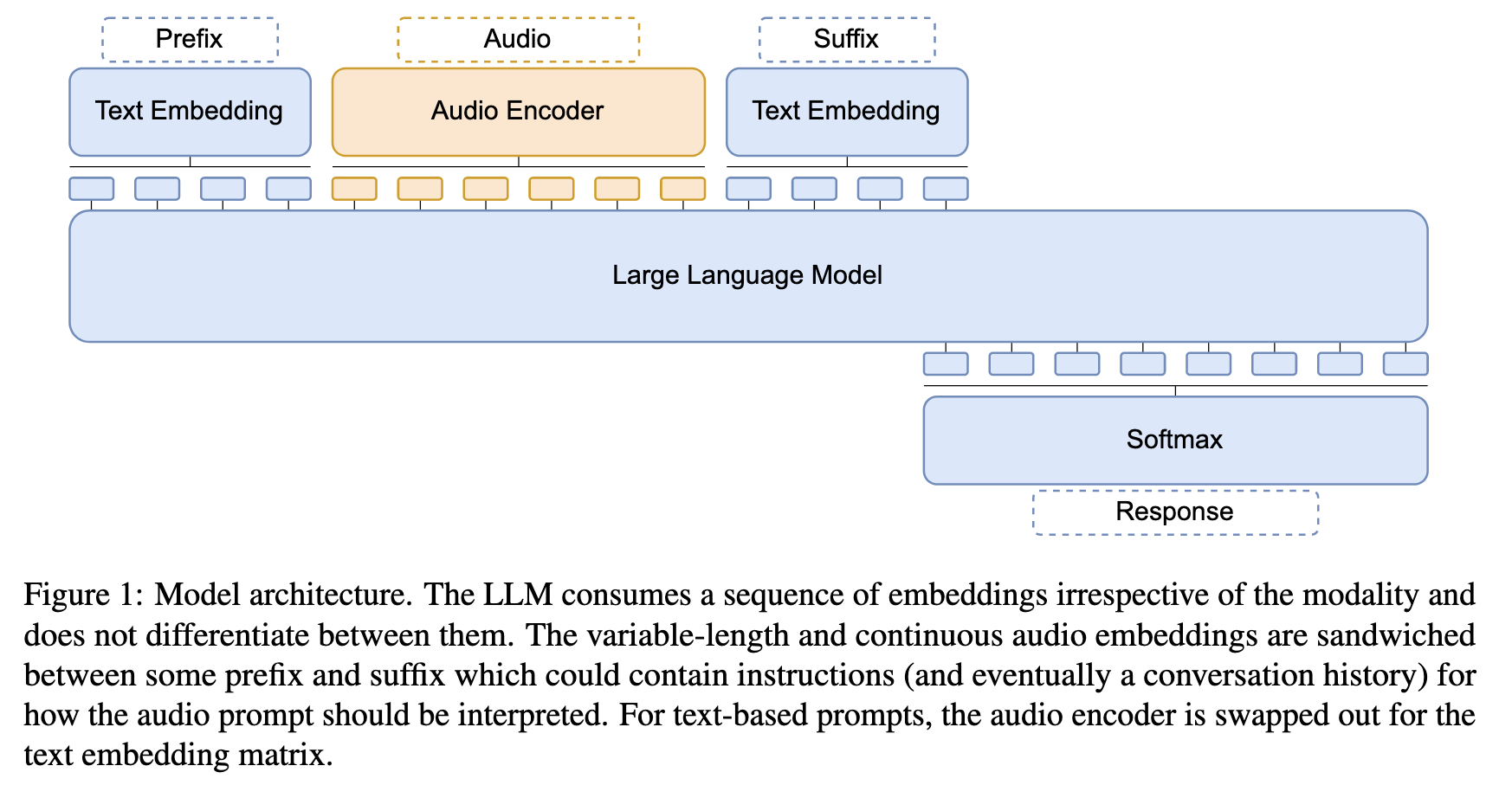
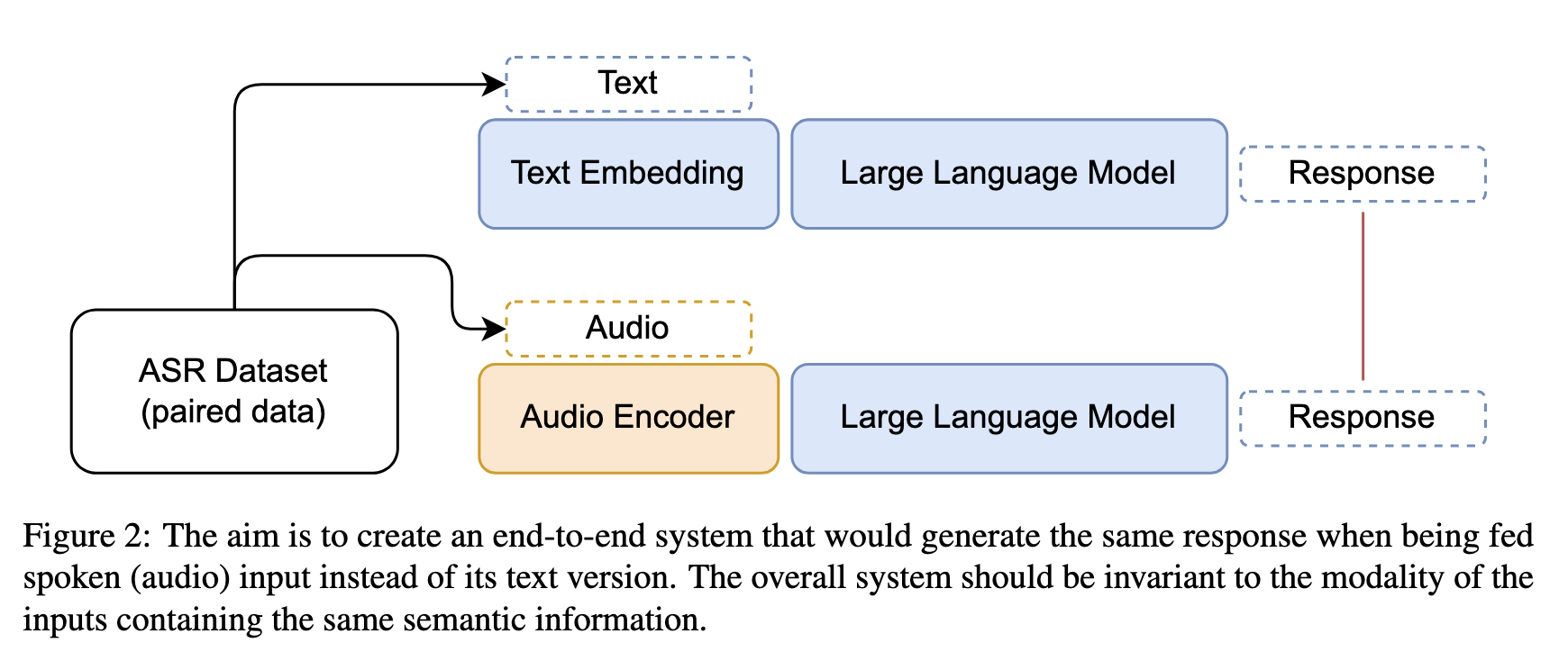
一、模型核心目标
实现指令调优的LLM(Llama-2-chat)在语音领域的通用扩展,使其能够:
- 直接以音频作为输入(替代文本),生成符合语义的响应;
- 支持文本与音频模态的无缝互换,维持多轮对话;
- 具备跨模态任务能力(如语音问答、翻译、总结等);
- 无需依赖精心标注的语音-文本配对数据。
二、模型架构设计
采用解码器-only架构(如图1所示),整体由三部分组成:
-
音频编码器(Audio Encoder)
- 作用:将原始音频信号转换为与LLM输入维度匹配的嵌入向量。
- 结构:
- 基础组件:基于预训练的Conformer模型(采用CTC损失预训练),包含卷积特征提取器和多个Conformer层(18层或36层)。
- 投影层:将Conformer输出的512维特征投影至4096维,以匹配Llama-2-chat(7B)的输入维度。
- 处理细节:音频输入为80维滤波器组特征(帧率10ms),经Conformer处理后帧率降至80ms,再通过帧堆叠进一步压缩序列长度,最终生成可变长度的音频嵌入。
-
大型语言模型(LLM)
- 选用Llama-2-chat(7B):指令调优版本,具备对话能力和通用文本任务处理能力(如问答、总结、翻译)。
- 训练策略:LLM参数完全冻结,仅通过音频编码器的训练实现与语音模态的对齐,确保其原有文本能力不受影响。
-
模态嵌入融合
- 音频嵌入与文本嵌入共享同一输入空间:音频嵌入被夹在特定前缀(
<s>[INST] <<SYS>>\n\n<</SYS>>\n\n)和后缀([/INST])之间,模拟Llama-2-chat的标准对话格式,使LLM无需区分输入模态即可统一处理。
- 音频嵌入与文本嵌入共享同一输入空间:音频嵌入被夹在特定前缀(
三、关键训练方法:模态不变性对齐(Modal Invariance Alignment)
为避免依赖稀缺的语音-文本配对数据,论文提出利用非配对ASR数据 实现音频与文本的语义对齐,核心思路是:相同语义的文本和音频输入,应诱导LLM生成相同的响应。
-
数据来源
- 采用Multilingual LibriSpeech(MLS) 英语子集:包含50k小时音频及其转录文本(非配对任务数据,仅语音-文字对应)。
-
训练数据构建
- 步骤1:用ASR数据中的转录文本作为输入,通过Llama-2-chat生成响应(遵循其对话格式,系统提示为空,用户提示为转录文本)。
- 步骤2:构建"音频-响应"对:将音频输入通过音频编码器转换为嵌入,以LLM生成的响应为目标,训练音频编码器使LLM输出与文本输入时一致。
-
训练细节
- 优化目标:最小化LLM对音频嵌入生成响应的预测损失(自回归语言建模损失)。
- 训练参数:
- 音频编码器预训练:使用Adam优化器(β₁=0.9,β₂=0.98),学习率经20k步预热至1e-3,随后指数衰减。
- 联合训练:学习率经5k步预热至5e-4,250k步内衰减至5e-6,训练通常在100k步内终止。
- 硬件:使用64块NVIDIA A100 40GB GPU,通过梯度累积实现大批次训练。
四、模型能力扩展与验证
通过上述架构和训练方法,AudioChatLlama具备以下核心能力:
-
跨模态输入处理
- 支持音频直接作为输入,替代文本完成各类任务(如语音问答、翻译),无需先经ASR转换为文本。
-
模态互换与对话连续性
- 在多轮对话中,用户可交替使用音频和文本输入(如先语音提问,再文字追问),模型能利用上下文历史辅助理解(如图4、5示例)。
-
鲁棒性与上下文利用
- 相比级联系统(ASR+LLM),在ASR错误率较高时(如WER=37.5%),仍能生成更优响应(成功率52% vs 40%),因无需依赖精确转录,可直接处理语音嵌入中的语义信息。
总结
AudioChatLlama的核心方法是通过冻结LLM并训练音频编码器 ,利用非配对ASR数据和模态不变性原理,实现语音与文本在语义空间的对齐。这一方法突破了传统级联系统的局限性,首次使LLM在无需精心配对数据的情况下,具备通用语音处理和跨模态交互能力。"
HDMoLE
源自论文:HDMoLE: Mixture of LoRA Experts with Hierarchical Routing and Dynamic Thresholds for Fine-Tuning LLM-based ASR Models
"该论文提出的HDMoLE(Hierarchical routing and Dynamic thresholds-based Mixture of LoRA Experts) 是一种基于混合LoRA专家(MoLE)的参数高效微调方法,旨在解决预训练LLM-based ASR模型在多口音域的适配问题,同时避免灾难性遗忘。其核心是通过分层路由 和动态阈值策略,优化LoRA专家的协作与激活机制,具体方法如下:
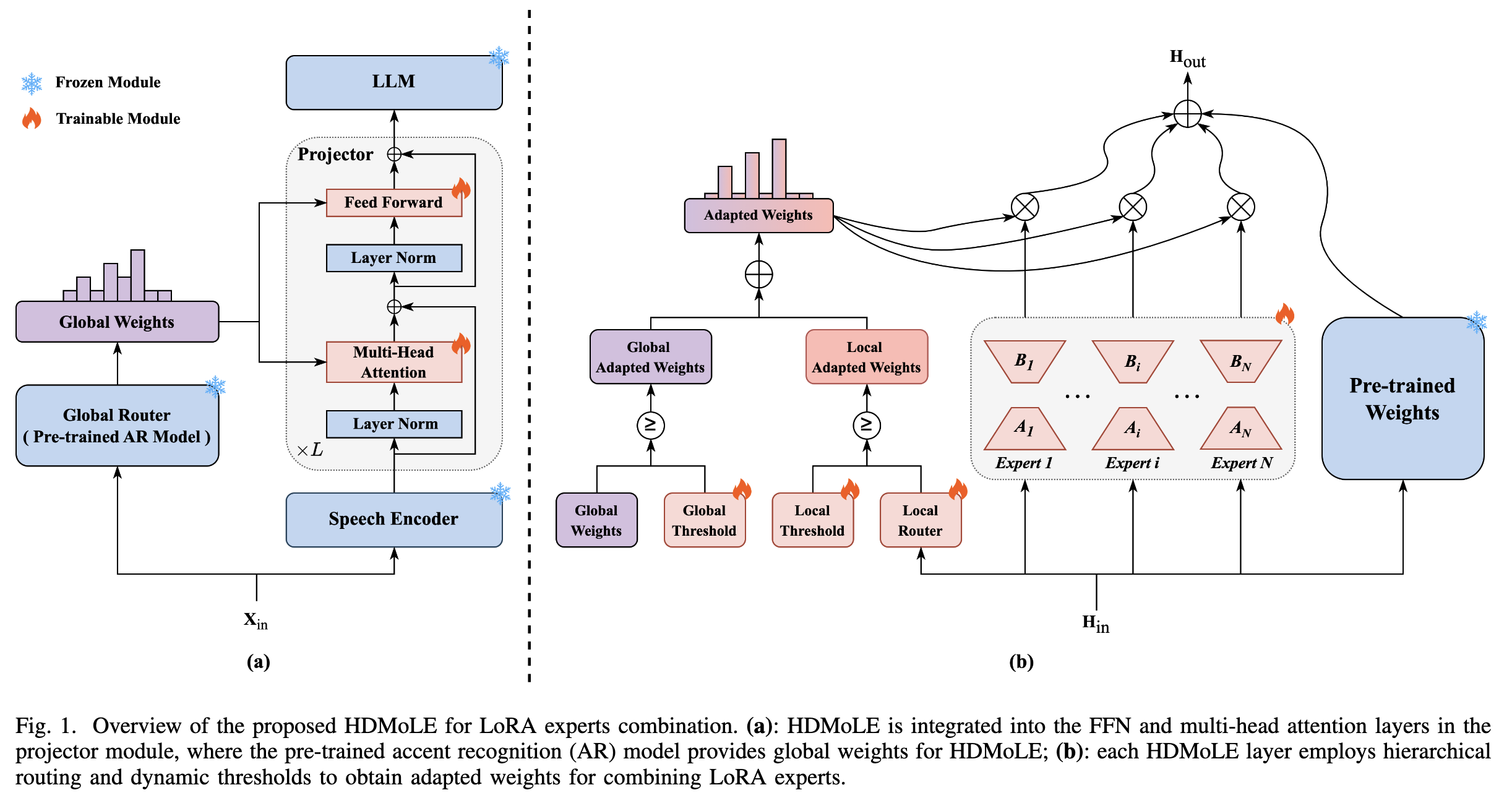
一、模型核心框架
HDMoLE以低秩适应(LoRA) 作为域专家,结合混合专家(MoE) 框架,通过分层路由和动态阈值实现对LLM-based ASR模型的高效微调。该方法可应用于模型的任何线性层,论文中重点在LLM-based ASR模型的projector模块(连接语音编码器与LLM的桥梁)中实现,具体涉及前馈网络(FFN)和多头自注意力(MHSA)的线性层。
二、核心组件与机制
1. 基础:LoRA与MoE的融合(MoLE)
- LoRA专家 :将每个LoRA视为一个域专家,通过低秩矩阵对(AiA_iAi和BiB_iBi)实现对原始权重的高效更新,公式为:
ΔWi=αrBiAi \Delta W_i = \frac{\alpha}{r} B_i A_i ΔWi=rαBiAi
其中rrr为低秩维度(r≪min(din,dout)r \ll \min(d_{in}, d_{out})r≪min(din,dout)),α\alphaα为缩放因子,原始权重W0W_0W0保持冻结。 - 混合专家(MoLE) :将多个LoRA专家组合为MoE层,最终输出为原始模型输出与LoRA专家加权输出的总和:
Hout=W0Hin+∑i=1NPai⋅ΔWiHin+b H_{out} = W_0 H_{in} + \sum_{i=1}^N P_a^i \cdot \Delta W_i H_{in} + b Hout=W0Hin+i=1∑NPai⋅ΔWiHin+b
其中PaiP_a^iPai为第iii个LoRA专家的最终适配权重,NNN为专家总数。
2. 分层路由(Hierarchical Routing)
为解决传统MoE中专家与域对应关系模糊的问题,HDMoLE设计了全局路由 与局部路由的双层机制:
-
全局路由:
- 作用:明确LoRA专家与特定口音域的对应关系,引导专家"各司其职"。
- 实现:采用预训练的口音识别(AR)模型 作为全局路由器,输入原始语音特征XinX_{in}Xin,输出全局权重PgP_gPg:
Pg=Softmax(RouterGlobal(Xin)) P_g = \text{Softmax}(\text{Router}{\text{Global}}(X{in})) Pg=Softmax(RouterGlobal(Xin)) - 特点:全局路由器在训练和推理中冻结,确保专家-域对应关系的稳定性。
-
局部路由:
- 作用:促进不同口音域间的专家协作,提升模型对复杂场景的适应性。
- 实现:每个MoE层配备可训练的线性层作为局部路由器,输入隐藏语音特征HinH_{in}Hin,输出局部权重PlP_lPl:
Pl=Softmax(RouterLocal(Hin)) P_l = \text{Softmax}(\text{Router}{\text{Local}}(H{in})) Pl=Softmax(RouterLocal(Hin)) - 特点:局部路由器通过学习动态调整权重,实现跨域专家的灵活协作。
3. 动态阈值(Dynamic Thresholds)
为替代传统MoE中僵化的静态Top-K策略,HDMoLE设计了动态阈值机制,自适应选择激活的专家:
- 阈值设计 :为全局权重PgP_gPg和局部权重PlP_lPl分别设置可学习的阈值τg\tau_gτg和τl\tau_lτl,初始化为1/N1/N1/N(确保至少激活1个专家)。
- 适配权重计算 :
- 全局适配权重PgaP_{ga}Pga:仅保留超过τg\tau_gτg的全局权重,归一化后缩放:
Pga=E(Pg≥τg)⋅Pg∑i=1NE(Pgi≥τg)⋅Pgi⋅τg P_{ga} = \frac{\mathbb{E}(P_g \geq \tau_g) \cdot P_g}{\sum_{i=1}^N \mathbb{E}(P_g^i \geq \tau_g) \cdot P_g^i} \cdot \tau_g Pga=∑i=1NE(Pgi≥τg)⋅PgiE(Pg≥τg)⋅Pg⋅τg - 局部适配权重PlaP_{la}Pla:同理基于τl\tau_lτl计算:
Pla=E(Pl≥τl)⋅Pl∑i=1NE(Pli≥τl)⋅Pli⋅τl P_{la} = \frac{\mathbb{E}(P_l \geq \tau_l) \cdot P_l}{\sum_{i=1}^N \mathbb{E}(P_l^i \geq \tau_l) \cdot P_l^i} \cdot \tau_l Pla=∑i=1NE(Pli≥τl)⋅PliE(Pl≥τl)⋅Pl⋅τl - 最终权重PaP_aPa:全局与局部适配权重的总和:
Pa=Pga+Pla P_a = P_{ga} + P_{la} Pa=Pga+Pla
- 全局适配权重PgaP_{ga}Pga:仅保留超过τg\tau_gτg的全局权重,归一化后缩放:
- 动态性:不同MoE层可激活不同数量的专家(如低层处理通用特征时激活更多专家,高层处理特定域特征时激活更少专家)。
4. 完整前向过程
HDMoLE层的输出为原始模型输出与LoRA专家加权输出的结合:
Hout=W0Hin+αr∑i=1NPai⋅BiAiHin+b H_{out} = W_0 H_{in} + \frac{\alpha}{r} \sum_{i=1}^N P_a^i \cdot B_i A_i H_{in} + b Hout=W0Hin+rαi=1∑NPai⋅BiAiHin+b
其中,若某LoRA专家的全局和局部权重均低于阈值,则其Pai=0P_a^i = 0Pai=0,不参与输出计算。
三、模型优势
- 参数高效:仅微调LoRA专家、局部路由器和阈值,可训练参数仅为全微调的9.6%。
- 避免灾难性遗忘:原始模型权重冻结,源通用域性能退化极小。
- 多域适应性:分层路由明确专家分工与协作,动态阈值灵活应对不同域复杂度。
通过上述机制,HDMoLE在多口音ASR任务中实现了与全微调接近的性能,同时保持了参数效率和源域稳定性。"
JELLY
源自论文:JELLY: Joint Emotion Recognition and Context Reasoning with LLMs for Conversational Speech Synthesis
"该论文提出的JELLY框架 (Joint Emotion Recognition and Context Reasoning with LLMs for Conversational Speech Synthesis)是一种用于对话语音合成(CSS)的新型模型,核心是通过整合情感识别与语境推理,生成符合对话情感语境的自然语音。其模型方法可分为核心组件设计 和三阶段学习流程两部分,具体如下:
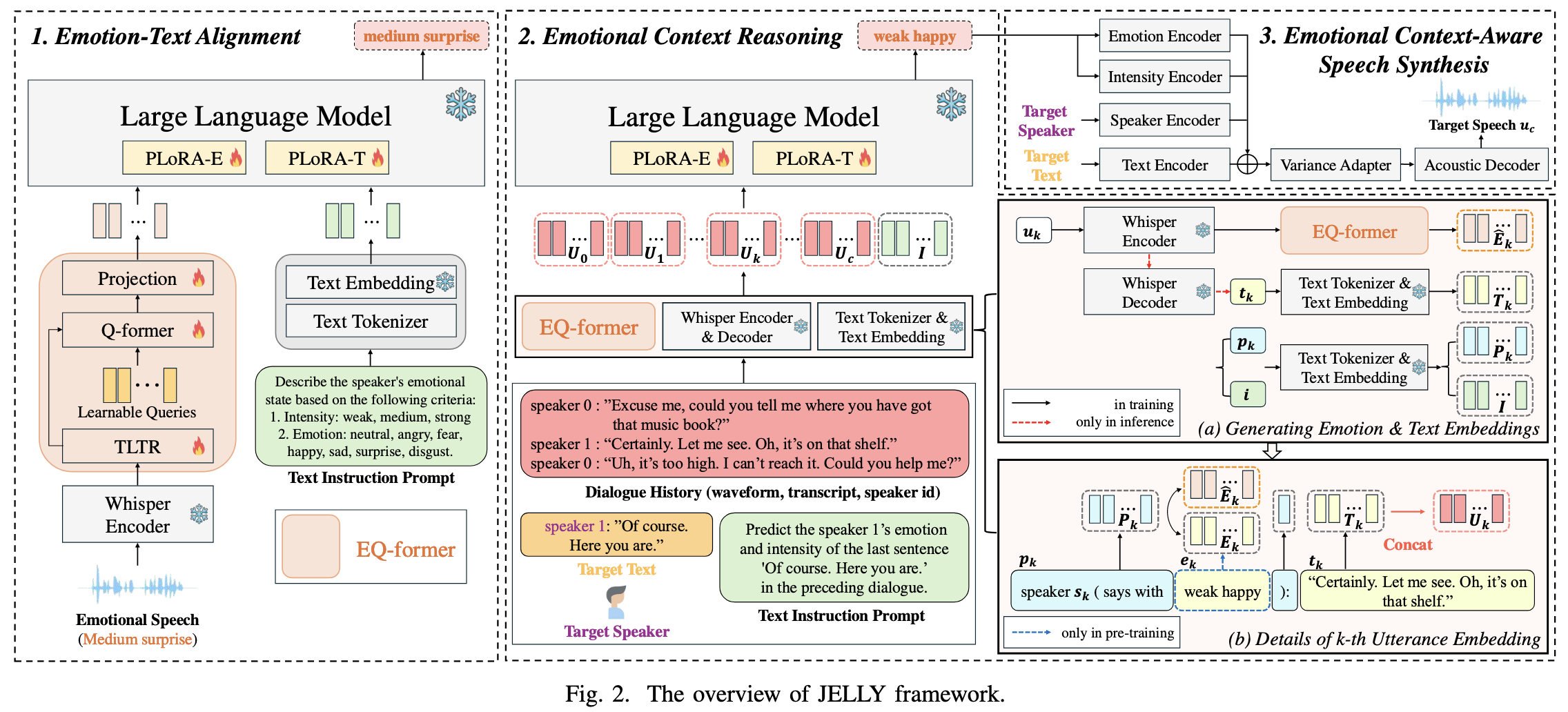
一、核心组件设计
JELLY的核心架构围绕"情感感知-语境推理-语音生成"的逻辑链展开,关键组件包括Emotion-aware Q-former Encoder(EQ-former) 、带多部分LoRA(PLoRA)的大型语言模型(LLM) ,以及情感语境感知的语音合成模块。
1. Emotion-aware Q-former Encoder(EQ-former)
EQ-former是连接语音情感与文本语义的桥梁,负责从语音中提取情感特征并与文本表征对齐,使LLM能够"理解"语音中的情感。其结构包含三个子模块:
-
TLTR(Time and Layer-Wise Transformer)
- 输入:Whisper编码器(预训练语音模型)的32层中间输出(包含语音的韵律、语调等副语言信息)。
- 功能:通过注意力机制聚焦于情感信息更丰富的层(如特定频率或时间窗口的特征),精准提取语音中的情感特征(如"中等悲伤""弱惊喜")。
- 作用:解决传统模型仅依赖单一层输出导致的情感特征提取不充分问题。
-
Q-former(Querying Transformer)
- 输入:TLTR提取的情感特征、可学习的查询嵌入(learnable queries)。
- 功能:通过交叉注意力机制,让查询嵌入与情感特征交互,将情感信息"编码"到查询输出中,实现情感特征与文本表征的跨模态对齐。
- 作用:消除情感(语音模态)与文本(语言模态)的语义鸿沟,使LLM能同时处理两种信息。
-
投影层(Projection Layer)
- 功能:将Q-former输出的情感对齐特征投影到与LLM嵌入维度一致的空间,确保情感信息能被LLM直接利用。
- 特性:参数可训练,动态适配LLM的输入要求。
2. 带多部分LoRA(PLoRA)的LLM
为让LLM同时处理情感嵌入和文本嵌入,且避免全量微调的高成本,JELLY采用部分LoRA(PLoRA) 策略,对LLM的不同输入模态分别适配:
- PLoRA-E(针对情感嵌入):仅微调LLM中与EQ-former输出的情感嵌入相关的参数(注意力层的查询和值投影),使LLM能"解读"情感信息。
- PLoRA-T(针对文本嵌入):仅微调与文本嵌入(来自对话文本)相关的参数,保留LLM原有的文本理解和生成能力。
- 优势:在保持LLM完整性的同时,缩小情感与文本模态的差距,提升情感语境推理效率。
3. 情感语境感知的语音合成模块
基于推断的情感状态生成语音,以FastSpeech 2为骨干模型,新增两个子模块:
- 情感编码器:将LLM预测的情感类别(如"开心""悲伤")转换为韵律特征(如基频、语速)。
- 强度编码器:将情感强度(如"弱""中""强")映射到韵律的强弱变化(如音量、语调起伏)。
- 功能:确保生成的语音在情感表达和韵律上与推断的语境一致。
二、三阶段学习流程
为缓解情感对话数据集稀缺的问题,JELLY设计了分阶段训练策略,逐步提升模型对情感语境的建模能力:
阶段1:情感-文本对齐(Emotion-Text Alignment)
- 目标:训练EQ-former从单句语音中提取情感特征,并与文本语义对齐,使LLM能"看懂"语音中的情感。
- 数据:单句情感语音数据集(如IEMOCAP、CREMA-D,共80.6小时),包含语音、文本及情感标签(7类情感+3级强度)。
- 训练方式 :
- 冻结Whisper编码器和LLM的参数,仅训练EQ-former(TLTR+Q-former+投影层)和PLoRA模块。
- 任务:通过LLM的"下一个token预测",让模型学习用文本描述语音中的情感(如输入语音"我赢了!",输出"强开心")。
- 输出:能将语音情感转换为LLM可理解的嵌入的EQ-former。
阶段2:情感语境推理(Emotional Context Reasoning)
- 目标:让模型结合对话历史(语音+文本),推断当前utterance应有的情感状态(如前句是"我失业了",当前句应带"悲伤"情感)。
- 数据 :
- 预训练:大规模文本对话数据集(如DailyDialog,13,118个对话),仅用文本和情感标签训练PLoRA-T。
- 微调:小规模情感对话语音数据集(如DailyTalk,20小时语音),包含对话历史、语音、文本及情感标签。
- 训练方式 :
- 输入:对话历史的语音(经EQ-former生成情感嵌入)、文本(经LLM分词器生成文本嵌入)、指令提示(如"预测当前句的情感")。
- 任务:LLM通过PLoRA-E和PLoRA-T处理嵌入,预测当前utterance的情感类别和强度。
- 关键设计:通过文本数据预训练PLoRA-T,减少对稀缺情感对话语音数据的依赖。
阶段3:情感语境感知语音合成(Emotional Context-Aware Speech Synthesis)
- 目标:基于阶段2推断的情感状态,生成韵律和情感匹配的语音。
- 数据:DailyTalk数据集的语音,转换为梅尔频谱图(用于训练声学模型)。
- 模型 :以FastSpeech 2为骨干,新增:
- 情感编码器:将情感类别(如"开心")转换为韵律特征。
- 强度编码器:将强度(如"中")映射到语速、音量等细节。
- 训练方式:独立训练,输入为文本和阶段2预测的情感/强度,输出为梅尔频谱图,再通过HiFi-GAN声码器转换为语音。
三、推理流程
在实际应用中,JELLY仅需输入对话历史的语音(无需文本或情感标签),即可生成当前句的语音:
- 对话历史的语音经Whisper编码器和EQ-former处理,生成情感嵌入。
- Whisper解码器将语音转换为文本,生成文本嵌入。
- LLM通过PLoRA-E和PLoRA-T处理两种嵌入,推断当前句的情感和强度。
- 语音合成模块基于文本和推断的情感/强度,生成最终语音。
该方法的核心优势在于:通过跨模态对齐和分阶段训练,在数据稀缺的情况下,仍能实现情感语境的精准建模,生成自然且符合对话逻辑的语音。"
LTU
源自论文:LISTEN, THINK, AND UNDERSTAND
"该论文提出的LTU(Listen, Think, and Understand)模型,是一种融合音频感知与语言推理能力的多模态基础模型,其核心方法涵盖模型架构设计 、训练数据集构建 、训练策略三个关键部分,具体如下:

一、模型架构设计
LTU的架构旨在将音频感知能力与大型语言模型(LLM)的推理能力深度整合,整体结构如图1所示,包含三个核心模块:
1. 音频编码器(Audio Encoder)
- 核心组件 :采用预训练的Audio Spectrogram Transformer(AST)(Gong et al., 2021b),该模型经CAV-MAE自监督目标预训练(Gong et al., 2022a)和AudioSet-2M微调,具备强大的音频特征提取能力。
- 处理流程 :
- 将10秒音频波形转换为1024(时间)×128(频率)的log Mel频谱图(采用25ms汉宁窗,10ms步长)。
- 将频谱图分割为512个16×16的方形补丁,输入AST模型,输出512个768维的音频嵌入。
- 对嵌入进行频率平均池化 和2×时间下采样,得到32个按时间顺序排列的音频嵌入(采样率3.2Hz)。
- 通过投影层将768维嵌入映射至4096维,以匹配LLaMA模型的嵌入维度,最终与文本嵌入拼接作为LLM的输入。
2. 大型语言模型(LLM)
- 基础模型 :采用LLaMA-7B(Touvron et al., 2023),并基于Vicuna(Chiang et al., 2023)进行指令微调,增强其遵循指令和生成文本的能力。
- 作用:负责将音频嵌入与文本输入结合,进行语义理解、推理和答案生成。
3. 低秩适配器(LoRA)
- 设计目的 :为避免全量微调LLaMA导致的"灾难性遗忘"(Goodfellow et al., 2013)和过拟合,采用低秩适应(LoRA) 技术(Hu et al., 2021)。
- 具体实现:在LLaMA所有自注意力层的键(Key)和查询(Query)投影层中注入LoRA适配器(秩=8,α=16),仅引入4.2M可学习参数,大幅提升训练效率。
二、训练目标与生成设置
1. 训练目标
采用自回归语言建模目标 ,即基于历史文本token和输入音频,最大化下一个token的预测概率:
P(xt∣x1:t−1,A) P\left(x_{t} | x_{1: t-1}, A\right) P(xt∣x1:t−1,A)
其中,x1:Tx_{1:T}x1:T为文本序列,AAA为参考音频,通过交叉熵损失优化所有1<t≤T1 < t \leq T1<t≤T的token预测。
2. 生成设置
为平衡生成质量与实用性,采用固定参数:
- 温度(Temperature)=0.1(控制输出随机性)
- Top-K=500,Top-P=0.95(控制候选词范围)
- 重复惩罚=1.1(减少重复生成)
三、OpenAQA-5M数据集构建
为训练LTU的感知与推理能力,论文构建了包含568万条(音频、问题、答案)三元组的数据集,分为两个子集:
1. 封闭式问答数据(190万条)
- 任务类型 :涵盖四类结构化任务,统一为问答形式:
- 分类:如"音频中包含哪些声音事件?"(答案为预定义类别)。
- 声学特征:如"基于声学特征分类声音事件"(答案为"高频、短促→狗叫"等特征-类别对)。
- Captioning:如"描述音频内容"(答案为音频字幕)。
- 时间分析:如"每个声音事件的时间戳?"(答案含事件及起止时间)。
- 数据来源:整合AudioSet-Strong、VGGSound、FSD50K等8个公开数据集,确保覆盖多样音频场景。
2. 开放式问答数据(370万条)
- 生成方法 :通过音频指令生成(AIG) 技术,利用GPT-3.5-Turbo基于音频元信息(如事件、特征、时间戳)生成复杂问答对。
- 问题类型:包括细节询问(如"引擎加速的音调如何?")、推理(如"从交通噪音减弱能推断什么?")、场景理解(如"音频传达什么氛围?")等,覆盖从低级感知到高级理解的全维度。
- 特色:包含6.5%"不可回答"样本(如"仅凭音频无法确定钟声类型"),训练模型"知其不知",减少幻觉。
四、"感知到理解"的课程训练策略
为避免模型依赖语言知识而非音频输入(幻觉),设计四阶段渐进式训练课程(表3),逐步提升任务复杂度:
| 阶段 | 训练参数 | 训练任务 | 样本量 | 学习率 | 轮次 |
|---|---|---|---|---|---|
| 1 | 仅音频投影层 | 分类+声学特征描述 | 120万 | 1e-3 | 2 |
| 2 | 音频编码器+投影层+LoRA | 分类+声学特征描述 | 120万 | 1e-4 | 2 |
| 3 | 同上 | 所有封闭式任务 | 190万 | 1e-4 | 1 |
| 4 | 同上 | 所有封闭式+开放式任务 | 560万 | 1e-4 | 1 |
- 设计逻辑:先通过封闭式任务强制模型学习音频与语义的关联(感知阶段),再引入开放式任务培养推理能力(理解阶段)。
- 有效性:消融实验显示,无课程训练时平均分类性能从50.3降至23.0,证明课程对平衡感知与推理至关重要。
总结
LTU通过AST+LLaMA+LoRA的架构 实现音频-文本融合,OpenAQA-5M数据集 提供多样化训练信号,感知到理解的课程确保学习有序性,最终实现了传统音频模型不具备的推理与理解能力,同时在分类、captioning等传统任务上超越SOTA模型(如CLAP)。"
基于自监督语音编码器与大型语言模型(LLM)融合的汉语方言语音识别方法
源自论文:Leveraging LLM and Self-Supervised Training Models for Speech Recognition in Chinese Dialects: A Comparative Analysis
"该论文提出了一种基于自监督语音编码器与大型语言模型(LLM)融合的汉语方言语音识别方法,核心是通过多阶段训练策略优化模型组件的协同性,以应对方言数据稀缺和识别精度低的问题。以下是模型方法的详细描述:
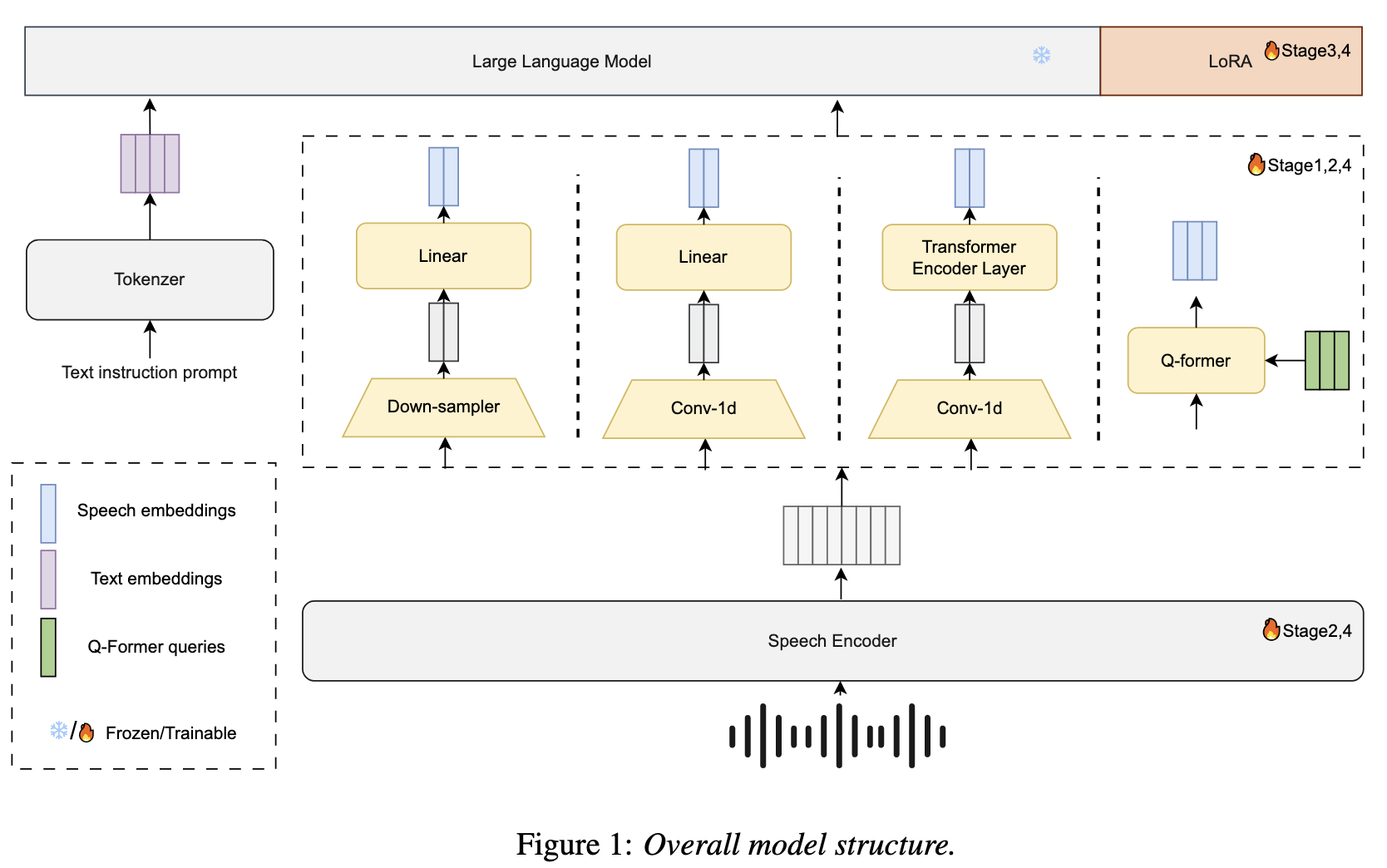
一、模型整体架构
模型由语音编码器 、投射器(Projector) 和LLM解码器三部分组成,整体结构如图1所示,核心是将语音信号转化为与文本语义对齐的特征,并通过LLM生成最终转录结果。具体流程如下:
-
输入处理
- 对于每个样本,定义文本提示(如"Transcribe the following speech")、语音 utterance(语音片段)和对应转录文本,分别记为 PPP、SSS、TTT。
- 文本提示和转录文本通过LLM的分词器(Tokenizer)转化为 tokens,再经嵌入层生成特征向量 EpE_pEp 和 EtE_tEt:
Ep=Embedding(Tokenizer(P)),Et=Embedding(Tokenizer(T)) E_p = \text{Embedding}(\text{Tokenizer}(P)), \quad E_t = \text{Embedding}(\text{Tokenizer}(T)) Ep=Embedding(Tokenizer(P)),Et=Embedding(Tokenizer(T))
-
语音特征提取与投射
- 语音信号 SSS 首先通过语音编码器 生成声学特征 HsH_sHs:
Hs=Encoder(S) H_s = \text{Encoder}(S) Hs=Encoder(S) - 特征 HsH_sHs 经投射器 和线性层处理,生成与LLM嵌入空间维度一致的语音特征序列 EsE_sEs:
Es=Linear(Projector(Hs)) E_s = \text{Linear}(\text{Projector}(H_s)) Es=Linear(Projector(Hs))
其中,投射器负责保留语音编码器输出的维度,线性层则将其映射到LLM的语义空间。
- 语音信号 SSS 首先通过语音编码器 生成声学特征 HsH_sHs:
-
LLM解码
- 将文本提示嵌入 EpE_pEp、语音特征 EsE_sEs 和转录文本嵌入 EtE_tEt 拼接后输入LLM,生成最终转录结果 YYY:
Y=LLM(Regulation(Ep,Es,Et)) Y = \text{LLM}(\text{Regulation}(E_p, E_s, E_t)) Y=LLM(Regulation(Ep,Es,Et))
- 将文本提示嵌入 EpE_pEp、语音特征 EsE_sEs 和转录文本嵌入 EtE_tEt 拼接后输入LLM,生成最终转录结果 YYY:
二、核心组件设计
1. 语音编码器(Speech Encoder)
- 选用Data2vec2(TeleSpeechPT变体),模型含24层、3.01亿参数,预训练于30万小时无标注方言及带口音语音数据。
- 采样率设为25Hz(低于Whisper的50Hz),通过低帧率设计降低计算开销,同时保证方言特征的捕捉能力。
2. 投射器(Projector)
- 作用:实现语音特征与LLM文本嵌入的跨模态对齐,并通过下采样平衡精度与效率。
- 对比四种投射器类型:
- 全连接层(Linear):训练初期性能最优,适合快速收敛。
- 1D卷积层(Conv1d):通过卷积操作提取局部特征,适配语音的时序特性。
- Transformer:建模长距离依赖,但计算成本较高。
- Q-Former:生成固定长度嵌入(64维),但无法灵活调整下采样率。
- 下采样策略:测试1、2、4、8倍下采样率,最终选择4倍下采样(结合编码器25Hz采样率,LLM输入帧率为6.25Hz),在精度(CER较低)和效率(计算量小)间取得平衡。
3. LLM解码器
- 选用Qwen 2系列(0.5B、1.5B、7B)和Qwen 2.5 3B,基于中文任务性能(CLiB排行榜)选择,支持方言口语化表达的理解与生成。
- 微调方式:采用LoRA(低秩适应)技术,仅更新低秩矩阵参数,降低大规模模型的训练成本。
三、四阶段训练策略
为解决LLM与语音编码器的协同优化问题,在传统三阶段训练基础上新增第四阶段,具体步骤如下:
| 阶段 | 训练对象 | 核心操作 | 目的 |
|---|---|---|---|
| 1 | 仅投射器 | 冻结语音编码器和LLM,仅训练投射器参数 | 初步对齐语音特征与LLM嵌入空间 |
| 2 | 仅语音编码器 | 冻结投射器和LLM,微调语音编码器 | 优化编码器对 dialect 声学特征的捕捉能力 |
| 3 | LLM(LoRA微调) | 冻结编码器和投射器,通过LoRA更新LLM的低秩矩阵 | 使LLM适应方言语音与文本的映射关系,避免全量微调的高成本 |
| 4 | 全模型(编码器+投射器) | 解冻编码器和投射器,与LLM联合优化 | 打破局部最优,实现跨组件全局收敛,进一步提升性能 |
四、关键实现细节
- 数据集:30万小时无标注方言/带口音语音(预训练)+4万小时有监督方言数据(微调),覆盖安徽、广东、上海等20余种方言及普通话。
- 训练配置:使用8张40G A100 GPU,7B模型四阶段训练约30天;优化器为AdamW(学习率1e-5,权重衰减0.01),采用梯度裁剪(阈值5)和梯度累积(20步)稳定训练。
- 评估指标:字符错误率(CER),用于衡量转录文本与标注的差异。
总结
该方法通过自监督预训练+LLM融合+四阶段训练的协同设计,在低资源方言场景下实现了高精度识别。核心创新在于:以Data2vec2捕捉方言声学特征,通过投射器优化跨模态对齐,并通过多阶段训练释放模型全局优化能力,最终在Kespeech等数据集上取得SOTA性能(如Kespeech的CER降至6.48%)。"
"该论文提出的模型方法旨在通过融合双听觉编码器与大语言模型(LLM),实现自动语音识别(ASR)和自动音频字幕生成(AAC)的联合处理,核心包括双听觉编码器结构 、窗口级Q-Former时序对齐机制 和轻量级LLM适配策略三部分。以下是详细描述:
EXTENDING LARGE LANGUAGE MODELS FOR SPEECH AND AUDIO CAPTIONING
源自论文:EXTENDING LARGE LANGUAGE MODELS FOR SPEECH AND AUDIO CAPTIONING
1. 整体架构概览
模型以Vicuna 13B 为基础LLM,通过双听觉编码器 提取语音和音频事件特征,再经窗口级Q-Former将特征转换为LLM可理解的文本类令牌,最终由LLM生成目标输出(语音转写或音频描述)。整体结构实现了"听觉信号→特征编码→跨模态对齐→语言生成"的端到端流程,支持ASR、AAC及混合场景的联合字幕生成。
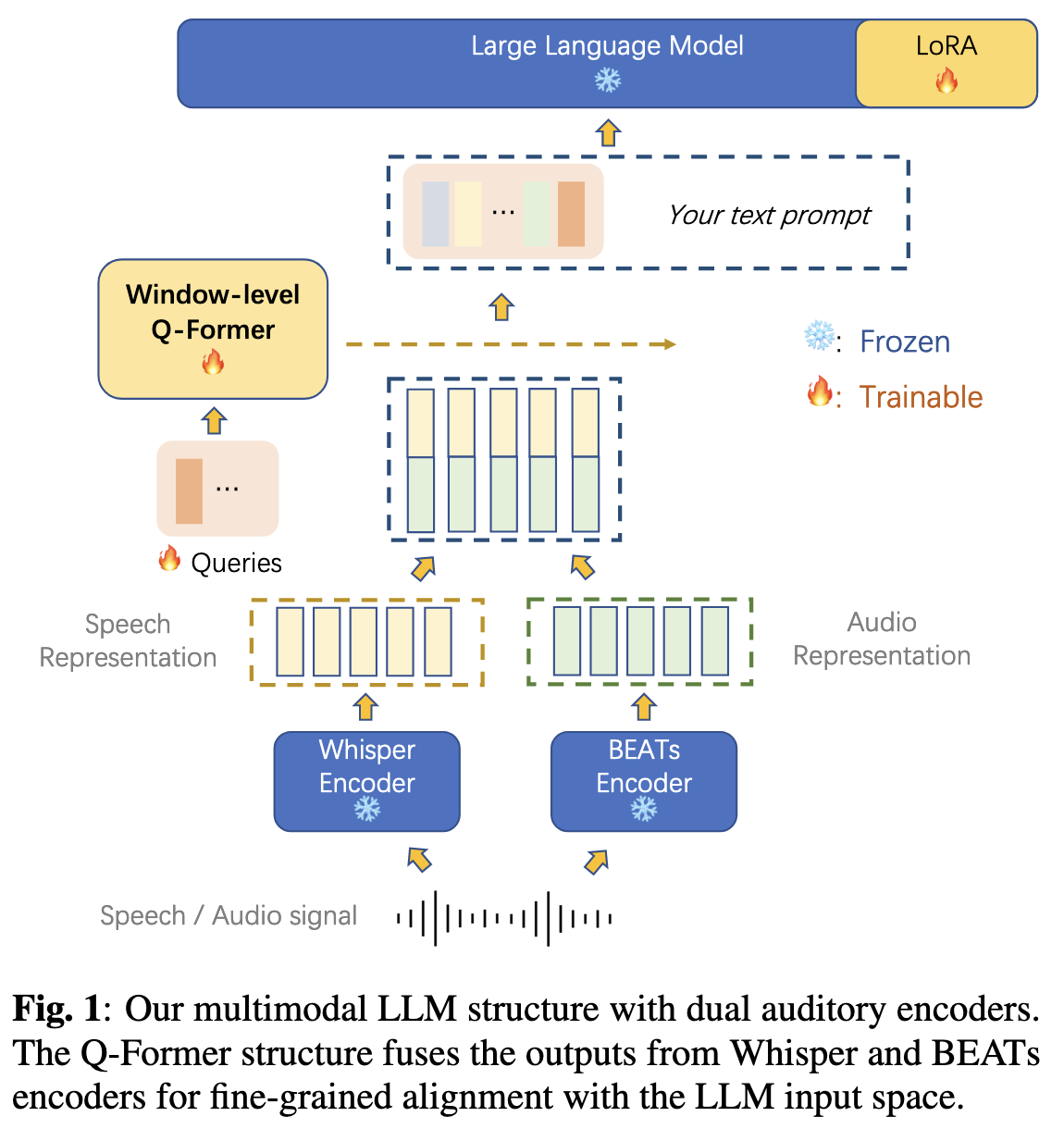
2. 核心组件设计
2.1 双听觉编码器:互补特征提取
为同时处理语音和音频事件,模型采用两种专用编码器提取互补特征:
-
Whisper编码器(语音专用)
选用Whisper-Large-v2的编码器部分,基于Transformer架构,在大规模多语言语音数据上预训练,输出1280维特征向量。其优势在于:
- 对语音语义信息(如发音、语法)捕捉能力强,适合ASR任务;
- 具备一定抗噪声能力,能从混合音频中聚焦语音信号20,27。
-
BEATs编码器(音频事件专用)
选用经微调的BEATs模型(iter3+),通过自监督学习(声学tokenizer+知识蒸馏)预训练,输出768维特征向量。其优势在于:
- 擅长提取非语音音频事件的高层语义(如"狗叫""雨声"),适合AAC任务;
- 能捕捉音频的环境上下文信息21。
-
特征融合
两种编码器输出的特征序列(均为50Hz帧率)通过帧级拼接融合为2048维向量序列,确保语音与音频事件特征在时间上同步对齐。
2.2 窗口级Q-Former:高分辨率时序对齐
为解决听觉信号的高时间分辨率与LLM固定输入格式的适配问题,提出窗口级Q-Former,将连续特征序列转换为文本类令牌:
-
核心原理
与传统序列级Q-Former(直接将整段特征编码为固定长度令牌)不同,窗口级Q-Former通过"分段处理+独立编码"保留细粒度时序信息:
- 将融合后的特征序列ZZZ分割为TTT个固定长度窗口Z1,Z2,...,ZTZ_1, Z_2, ..., Z_TZ1,Z2,...,ZT(如窗口长度0.33秒对应17帧);
- 每个窗口通过Q-Former生成loutl_{out}lout个文本类令牌(如1个令牌/窗口);
- 所有窗口的令牌拼接为最终序列HHH,作为LLM的输入。
-
数学定义
设Q-Former含bbb个Transformer块,第ttt个窗口的输出为:
Hb,t=Q-Formerb(lout,Zt) H_{b,t} = Q\text{-Former}b(l{out}, Z_t) Hb,t=Q-Formerb(lout,Zt)最终输入LLM的序列为:
H=Hb,1,Hb,2,...,Hb,T H = H_{b,1}, H_{b,2}, ..., H_{b,T} H=Hb,1,Hb,2,...,Hb,T -
优势
- 高时间分辨率:令牌与输入窗口严格单调对齐,保留局部时序细节(如语音停顿、短时音频事件);
- 减少信息丢失:避免长跨度注意力导致的关键信息稀释(实验显示,窗口长度0.33秒时ASR的WER比序列级Q-Former低3.9个百分点)。
2.3 LLM适配与训练策略
为将听觉特征与LLM的语言生成能力结合,采用轻量级适配策略:
- 基础LLM:选用Vicuna 13B(LLaMA的指令微调变体),具备强指令遵循能力4。
- 低秩适应(LoRA):仅对LLM的注意力层插入低秩矩阵(秩=8,缩放=4.0),冻结LLM和编码器参数,仅训练Q-Former和LoRA参数(约33M,占总参数的0.24%),大幅降低计算成本28。
- 训练目标 :通过交叉熵损失优化,同时学习ASR和AAC任务:
- ASR任务:输入语音特征,生成转录文本(如"天气很好");
- AAC任务:输入音频特征,生成描述文本(如"雨声伴随着雷声");
- 联合任务:输入混合语音-音频特征,生成融合描述(如"有人说'你好',背景有汽车鸣笛")。
3. 关键参数与设置
- Q-Former配置 :2个Transformer块,窗口长度lin=17l_{in}=17lin=17(对应0.33秒),每个窗口输出lout=1l_{out}=1lout=1个令牌;
- 输入投影:Q-Former输出的768维令牌通过全连接层投影至5120维(匹配Vicuna输入维度);
- 数据增强:混合语音与背景音频时采用3dB信噪比,模拟真实场景;
- 提示工程:针对不同任务设计专用提示(如ASR用"写下语音内容",AAC用"描述音频")。
4. 方法创新总结
- 双编码器互补设计:结合Whisper(语音)和BEATs(音频事件)的优势,首次实现ASR与AAC的联合建模;
- 窗口级时序对齐:通过分段处理提升时间分辨率,解决传统跨模态对齐中时序信息丢失的问题;
- 轻量级适配:基于LoRA的参数高效微调,在保留LLM能力的同时降低训练成本。
该方法不仅在单一任务上刷新SOTA(如GigaSpeech的ASR、AudioCaps的AAC),更支持混合场景的联合字幕生成,推动机器听觉感知向更贴近人类的"综合理解"迈进。"