Weaviate深度解析+保姆级实战教程!从Docker一键启动,到Python代码实战,手把手教你用Weaviate的模块化和混合搜索功能,搭建属于你自己的RAG应用。告别空谈,即刻上手!
Github: github.com/weaviate/we...

各位AI领域的探索者们,大家好!
今天,我们要把聚光灯打在一颗冉冉升起的新星身上------Weaviate。它不仅仅是一个存储和检索向量的"仓库",更像一个懂数据、懂模型、也懂你的"智能数据管家"。
如果你觉得普通的向量数据库还不够"聪明",那么Weaviate的几大"杀手锏"功能,绝对会让你眼前一亮!
Weaviate是谁?一个开源的向量搜索引擎
Weaviate (发音 "we-vee-ate") 是一个使用Go语言从头构建的开源向量数据库。它允许你用类属性(Class Properties)的方式存储JSON文档,并无缝地将机器学习模型产生的向量附加到这些文档上,从而在向量空间中精准地表达它们的语义。
除了基础的向量存储和毫秒级相似性搜索能力,Weaviate真正的魅力在于它独特的设计哲学和强大功能。
杀手锏一:模块化设计,让"向量化"开箱即用
传统的向量数据库工作流通常是:数据准备 -> 调用外部模型进行向量化 -> 将向量存入数据库。这个过程不仅繁琐,而且需要开发者维护额外的模型服务。
Weaviate通过其创新的模块化系统彻底改变了这一点。它允许你将各种功能(如向量化、问答等)作为"模块"即插即用。
这意味着什么?
你可以在创建数据集合(Collection)时,直接指定一个向量化模块,比如 text2vec-openai、text2vec-cohere 或各种开源的HuggingFace模型。之后,当你插入一条文本数据时,Weaviate会自动调用你指定的模型,将文本转换成向量并存储起来。
杀手锏二:混合搜索,兼顾"语义"与"关键词"
纯粹的向量搜索虽然能理解语义,但有时也会忽略一些关键的"字面量"信息。
为了解决这个问题,Weaviate提供了强大的**混合搜索(Hybrid Search)**功能。它巧妙地结合了向量搜索(理解语义)和传统的关键词搜索(BM25,匹配字面),将两者的结果进行智能融合,返回给你最相关、最准确的结果。
杀手锏三:强大的GraphQL API,像"对话"一样查询数据
Weaviate提供了一套非常优雅和强大的 GraphQL API 用于数据查询。GraphQL允许客户端精确地指定需要哪些数据,不多也不少。你可以用非常直观的方式发起复杂的查询,比如在一次请求中同时进行向量搜索和结构化过滤。
快速上手:三步搭建你的第一个Weaviate应用
理论说再多,不如亲手敲一遍代码!下面,我们将通过一个完整的实例,手把手带你从零开始,用Weaviate搭建一个简单的文章检索引擎。
第一步:使用Docker一键启动Weaviate
本地体验Weaviate最简单的方式就是使用Docker。我们创建一个docker-compose.yml文件,内容如下。这个配置会同时启动Weaviate服务以及一个开源的Transformer模型作为我们前面提到的"向量化模块"。
yml
version: '3.4'
services:
weaviate:
image: semitechnologies/weaviate:1.32.1
ports:
- "8080:8080"
- "50051:50051"
restart: on-failure:0
environment:
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
DEFAULT_VECTORIZER_MODULE: 'text2vec-transformers'
ENABLE_MODULES: 'text2vec-transformers'
TRANSFORMERS_INFERENCE_API: 'http://t2v-transformers:8080'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
volumes:
- './weaviate_data:/var/lib/weaviate'
t2v-transformers:
image: semitechnologies/transformers-inference:sentence-transformers-multi-qa-MiniLM-L6-cos-v1
environment:
ENABLE_CUDA: '0' # 如果你有NVIDIA GPU,可以设置为 '1'在保存好文件后,在终端中运行以下命令启动服务:
bash
docker compose up -d第二步:连接并定义数据结构 (Schema)
现在,我们用Python来和Weaviate交互。首先,确保你安装了Weaviate的Python客户端:
bash
pip install -U weaviate-client 接着,编写Python脚本来连接Weaviate,并定义我们要存储的数据格式。
python
import weaviate
import weaviate.classes.config as wvc
import json
# 连接到本地Weaviate实例
client = weaviate.connect_to_local()
# 定义一个名为 "Article" 的集合(Collection)
# 如果已存在,先删除,确保我们从一个干净的状态开始
if client.collections.exists("Article"):
client.collections.delete("Article")
articles = client.collections.create(
name="Article",
# 在这里指定向量化模块,以及要对哪些字段进行向量化
vectorizer_config=wvc.Configure.Vectorizer.text2vec_transformers(),
properties=[
wvc.Property(name="title", data_type=wvc.DataType.TEXT),
wvc.Property(name="content", data_type=wvc.DataType.TEXT),
]
)
print("集合 'Article' 创建成功!")在这段代码里,我们通过vectorizer_config参数告诉Weaviate,使用我们刚才在Docker里启动的text2vec-transformers模块来自动处理向量化。
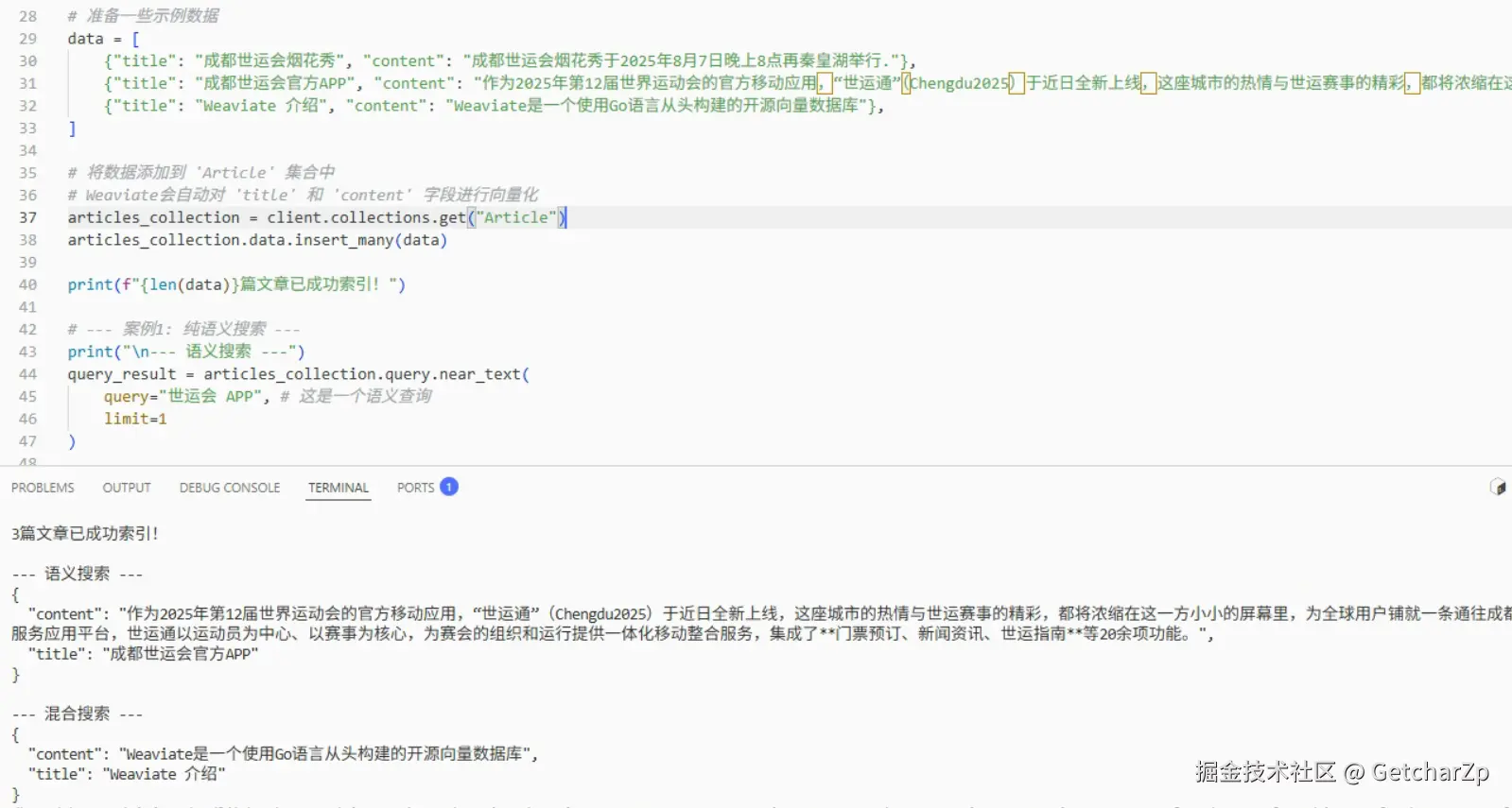
第三步:索引数据并开始搜索!
python
# --- 继续上面的Python脚本 ---
# 准备一些示例数据
data = [
{"title": "成都世运会烟花秀", "content": "成都世运会烟花秀于2025年8月7日晚上8点再秦皇湖举行."},
{"title": "成都世运会官方APP", "content": "作为2025年第12届世界运动会的官方移动应用,"世运通"(Chengdu2025)于近日全新上线,这座城市的热情与世运赛事的精彩,都将浓缩在这一方小小的屏幕里,为全球用户铺就一条通往成都世运会的便捷之路。 作为赛会官方移动服务应用平台,世运通以运动员为中心、以赛事为核心,为赛会的组织和运行提供一体化移动整合服务,集成了**门票预订、新闻资讯、世运指南**等20余项功能。"},
{"title": "Weaviate 介绍", "content": "Weaviate是一个使用Go语言从头构建的开源向量数据库"},
]
# 将数据添加到 'Article' 集合中
# Weaviate会自动对 'title' 和 'content' 字段进行向量化
articles_collection = client.collections.get("Article")
articles_collection.data.insert_many(data)
print(f"{len(data)}篇文章已成功索引!")
# --- 案例1: 纯语义搜索 ---
print("\n--- 语义搜索 ---")
query_result = articles_collection.query.near_text(
query="世运会 APP", # 这是一个语义查询
limit=1
)
for item in query_result.objects:
print(json.dumps(item.properties, indent=2, ensure_ascii=False))
# --- 案例2: 混合搜索 (语义 + 关键词过滤) ---
print("\n--- 混合搜索 ---")
hybrid_result = articles_collection.query.hybrid(
query="向量数据库", # 语义部分
alpha=0.5, # 0.5表示向量搜索和关键词搜索权重各占一半
limit=1
)
for item in hybrid_result.objects:
print(json.dumps(item.properties, indent=2, ensure_ascii=False))运行这段代码,你会看到,Weaviate 能够根据我们标题或正文中的内容进行相似性的查找:
结语
Weaviate不仅仅是一个存储向量的容器,它通过模块化的向量生成、强大的混合搜索能力和灵活的API,将自己打造成了一个云原生的、智能的、对开发者极其友好的向量搜索引擎。
这个简单的例子仅仅揭开了Weaviate强大功能的冰山一角。它在保证高性能和可扩展性的同时,极大地降低了AI应用,特别是RAG应用的开发门槛。
快去试试Weaviate,感受下一代AI数据管家带来的开发乐趣吧!