一、概念和优缺点
一些概念:
1、决策节点:通过条件判断而进行分支选择的节点。
2、叶子节点:没有子节点的节点,表示最终的决策结果。
3、决策树的深度:所有节点的最大层数。
决策树具有一定的层次结构,根节点的层次数定为0,从下面开始每一层子节点层次数增加
决策树的优缺点:
优点: 可视化 - 可解释能力-对算力要求低
缺点: 容易产生过拟合,所以不要把深度调整太大了。
二、基于信息增益决策树的建立
信息增益决策树倾向于选择取值较多的属性 ,在有些情况下这类属性可能不会提供太多有价值的信息,算法只能对描述属性为离散型属性的数据集构造决策树。
1、信息熵
信息熵描述的是不确定性。信息熵越大,不确定性越大。信息熵的值越小,则D的纯度越高。
假设样本集合D共有N类,第k类样本所占比例为Pk
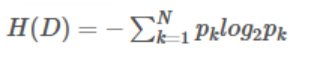
2、信息增益
信息增益是一个统计量,用来描述一个属性区分数据样本的能力。信息增益越大,那么决策树就会越简洁。这里信息增益的程度用信息熵的变化程度来衡量, 信息增益公式:
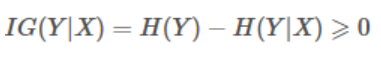
3、信息增益决策树建立
| 职业 | 年龄 | 收入 | 学历 | 是否贷款 | |
|---|---|---|---|---|---|
| 1 | 工人 | 36 | 5500 | 高中 | 否 |
| 2 | 工人 | 42 | 2800 | 初中 | 是 |
| 3 | 白领 | 45 | 3300 | 小学 | 是 |
| 4 | 白领 | 25 | 10000 | 本科 | 是 |
| 5 | 白领 | 32 | 8000 | 硕士 | 否 |
| 6 | 白领 | 28 | 13000 | 博士 | 是 |
(1)、计算根节点的信息熵
(2)、计算属性的信息增益

(3)、划分属性
python
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier,export_graphviz
from sklearn.model_selection import train_test_split
x,y=load_iris(return_X_y=True)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=0)
model=DecisionTreeClassifier(max_depth=5)
model.fit(x_train,y_train)
print(model.score(x_test,y_test))
y_pred=model.predict([[4.3,2.6,1.5,1.3]])
print(y_pred)
# 导出已经构建的决策树
export_graphviz(model,out_file='./src/tree.dot',feature_names=['花萼长度','花萼宽度','花瓣长度','花瓣宽度'])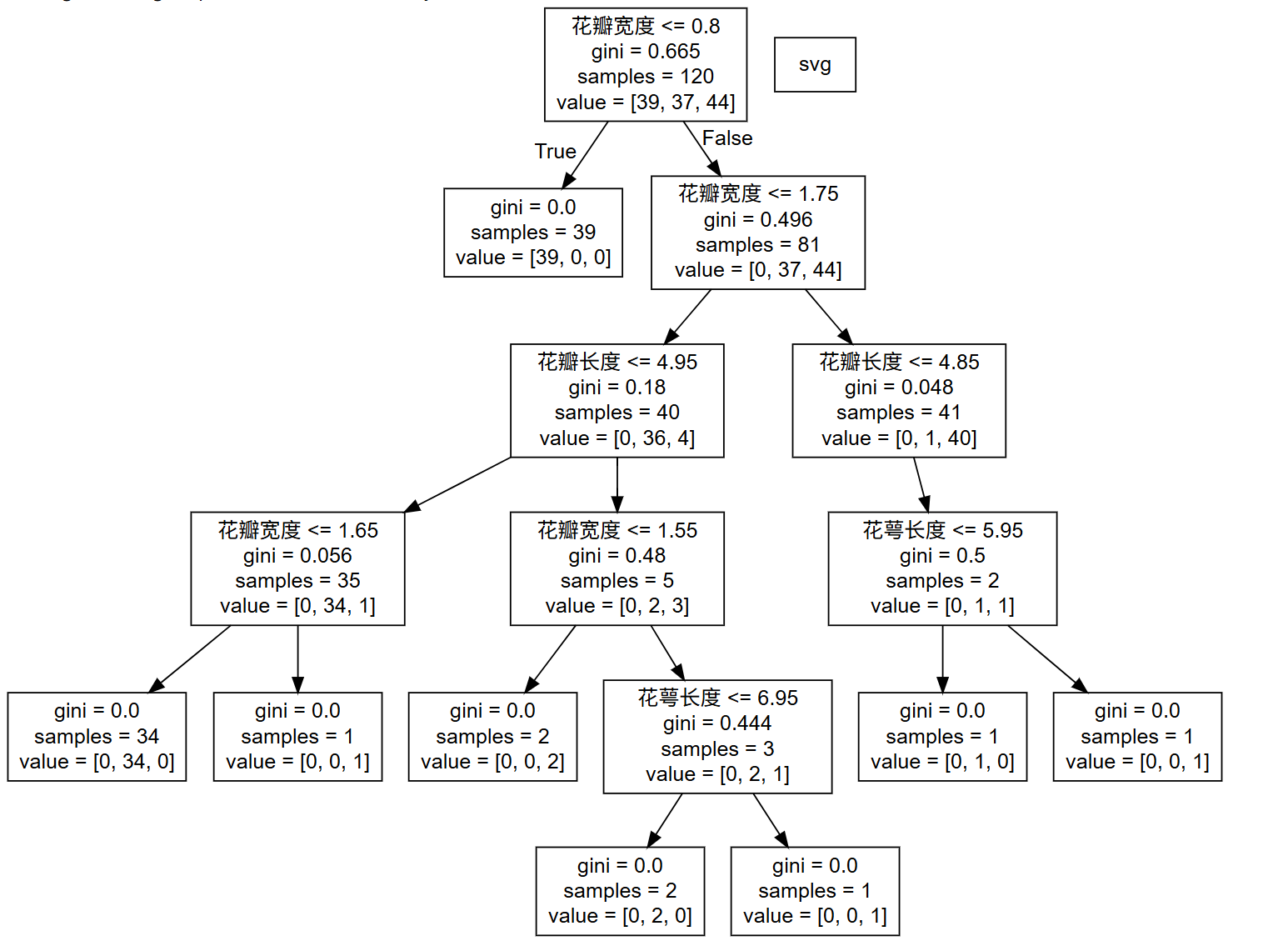
三、基于基尼指数决策树的建立
基尼指数(Gini Index)是决策树算法中用于评估数据集纯度的一种度量,基尼指数衡量的是数据集的不纯度,或者说分类的不确定性。在构建决策树时,基尼指数被用来决定如何对数据集进行最优划分,以减少不纯度。
二分类:
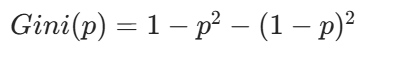
多分类问题:
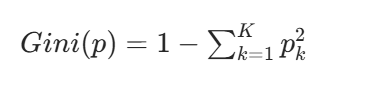
基尼指数的意义
-
当一个节点的所有样本都属于同一类别时,基尼指数为 0,表示纯度最高。
-
当一个节点的样本均匀分布在所有类别时,基尼指数最大,表示纯度最低。
API
class sklearn.tree.DecisionTreeClassifier(....)
参数:
criterion "gini" "entropy" 默认为="gini"
当criterion取值为"gini"时采用 基尼不纯度(Gini impurity)算法构造决策树,
当criterion取值为"entropy"时采用信息增益( information gain)算法构造决策树.
max_depth int, 默认为=None 树的最大深度
可视化决策树
function sklearn.tree.export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)
参数:
estimator决策树预估器
out_file生成的文档
feature_names节点特征属性名
功能:
把生成的文档打开,复制出内容粘贴到"http://webgraphviz.com/"中,点击"generate Graph"会生成一个树型的决策树图