编者按:
人工智能正以前所未有的渗透力重塑生产与生活图景。作为国内领先的数据智能科技企业,和鲸科技自 2015 年成立以来,深耕人工智能与数据科学,历经十年发展,已在气象、教育、医疗、航空航天、金融、通信、能源、零售等领域,与众多高校、科研机构、企业等单位展开了深度合作。
大模型技术正掀起新一轮产业变革浪潮。在此背景下,和鲸科技 AI Infra 架构总监朱天琦基于在大模型业务领域的丰富经验,解析大模型在实际应用中的实践案例与优化路径。
分享嘉宾
朱天琦 和鲸科技 AI Infra 架构总监
全面负责和鲸科技架构组相关工作,持续推动公司 AI Infra 基础设施的构建,特别在大模型平台与分布式系统领域取得了显著成果。
本篇为分享上篇,聚焦大模型微调与蒸馏技术的全景分析。
背景与需求
随着大型语言模型(LLM)的快速发展,企业和组织迫切需要将这些强大的通用模型适配到特定业务场景中。然而,直接部署基础模型往往面临知识局限、能力不足、资源消耗过大等挑战。模型优化技术如微调和蒸馏已成为连接通用大模型与特定业务需求的关键桥梁,能够显著提升模型在目标场景中的表现并优化部署效率。本章探讨大模型在实际应用中的主要瓶颈以及可行的优化路径,为后续技术选择奠定基础。
大模型能力边界与业务需求的差距
1 计算资源与部署成本挑战
-
尽管DeepSeek模型采用了混合专家(MoE)架构仅激活671B参数中的37B用于处理每个token,大幅提高效率,但完整模型的部署仍需要可观的计算资源比如最小的fp8部署规格为8卡H20,且只能支持3K左右的context。
-
蒸馏模型虽然降低了门槛,但小型模型(如1.5B-7B)在复杂任务上的能力有限,大型蒸馏模型(32B-70B)仍需较高硬件配置,32B为1卡H20,70B为2卡H20。
-
研究机构需要平衡模型性能与成本效益,特别是大规模模型服务场景。
2 推理一致性与可解释性不足
-
虽然DeepSeek-R1增强了推理能力,展示了与其他领先竞争对手相当的推理和数学技能,但在复杂业务场景中仍存在推理链断裂和逻辑跳跃。
-
模型对自身推理过程的解释有时不完整或存在后验合理化,影响关键业务决策的可信度。
-
业务应用通常需要可审计的决策链,尤其在医疗和法律等高风险领域。
3 领域知识深度与时效性限制
-
尽管基于开源代码和广泛数据训练,但在高度专业化的垂直领域知识深度仍然不足。
-
企业专有信息和内部知识无法自动获取,需要额外的检索增强机制。
4 系统集成与工具使用挑战
-
开源模型通常缺乏与企业现有系统的原生集成能力,确保与现有AI工具和工作流程的无缝兼容需要持续更新。
-
复杂工具链调用和多步骤操作执行能力有限,难以自动化完成端到端业务流程。
-
企业级应用需要稳定的API和完善的管理工具,而开源模型的支持体系有待完善。
5 隐私安全与合规风险
-
虽然开源带来透明度,但也引发安全漏洞、滥用风险和专业商业支持不足的担忧。
-
模型可能无意中泄露训练数据中的敏感信息,或生成不符合行业规范的内容。
-
企业部署需要满足数据保护法规,而现有模型的安全防护机制不够全面。
6 推理延迟与实时交互限制
-
链式思考推理虽然增强了问题解决能力,但也会降低响应时间,给实时应用带来挑战。
-
复杂分析任务的处理时间可能无法满足对即时决策的业务需求。
-
用户体验要求毫秒级响应,而深度推理过程难以实现这一目标。
现有模型能力优化路径概述:基础模型迭代、提示词工程与模型定制
基础模型迭代路径:
开源模型选择与组合:
-
优势:可从多样化的开源模型库中选择最适合的基础模型;能够灵活组合不同模型的优势。
-
劣势:需要评估和比较模型性能;模型之间的接口和特性差异需要适配。
-
适用场景:对模型透明度有要求的团队;预算有限但需要高性能的组织。
社区驱动的改进:
-
优势:可利用全球开发者社区的持续优化;不依赖单一提供商的更新周期。
-
劣势:社区支持质量参差不齐;可能需要自行解决兼容性和稳定性问题。
-
适用场景:有技术团队支持的长期项目;注重开放创新的研究机构。
提示词工程(Prompt Engineering):
开源模型特化提示技术:
-
优势:可针对不同开源模型特点开发优化的提示模板;低成本实现能力提升。
-
劣势:开源模型对提示格式敏感度各异;需要针对特定模型定制提示策略。
-
适用场景:需要快速适配多种开源模型的应用;资源有限但需要良好性能的场景。
模型能力探索:
-
优势:通过提示工程发现模型隐藏能力;低风险测试模型极限。
-
劣势:提升空间受限于模型内在能力;难以突破架构限制。
-
适用场景:模型能力与任务需求相近;探索性应用开发。
模型定制技术:
开源基础上的微调:
-
优势:可直接基于开源权重进行二次开发;降低预训练成本,聚焦领域适配。
-
劣势:硬件要求仍然可观;需要专业知识和高质量数据。
-
适用场景:有特定领域需求的企业;需要差异化竞争优势的应用。
轻量级适配技术:
-
优势:参数高效微调方法(PEFT)显著降低资源需求;适合中小规模部署。
-
劣势:性能提升可能不如全参数微调;需要专业调优知识。
-
适用场景:算力资源有限但需要定制化的团队;快速原型验证。
知识蒸馏链条:
-
优势:可构建"大模型->中型模型->小模型"的蒸馏链;逐级优化性能与资源平衡。
-
劣势:蒸馏过程中能力损失;多级蒸馏复杂度高。
-
适用场景:需要部署到多种硬件环境;追求极致推理效率。
混合优化策略:
预构建模型+RAG+微调:
-
优势:组合利用开源模型优势;降低定制成本同时提高性能。
-
劣势:系统复杂度增加;集成挑战大。
-
适用场景:企业级应用;需要兼顾通用能力和专业能力的场景。
开源协作开发:
-
优势:可贡献改进回馈社区;共享优化成本和收益。
-
劣势:需要遵循开源许可限制;知识产权保护挑战
-
适用场景:学术研究;开放创新组织。
AWS的解决方案架构师对模型业务适配解决方案的分布估算如下:
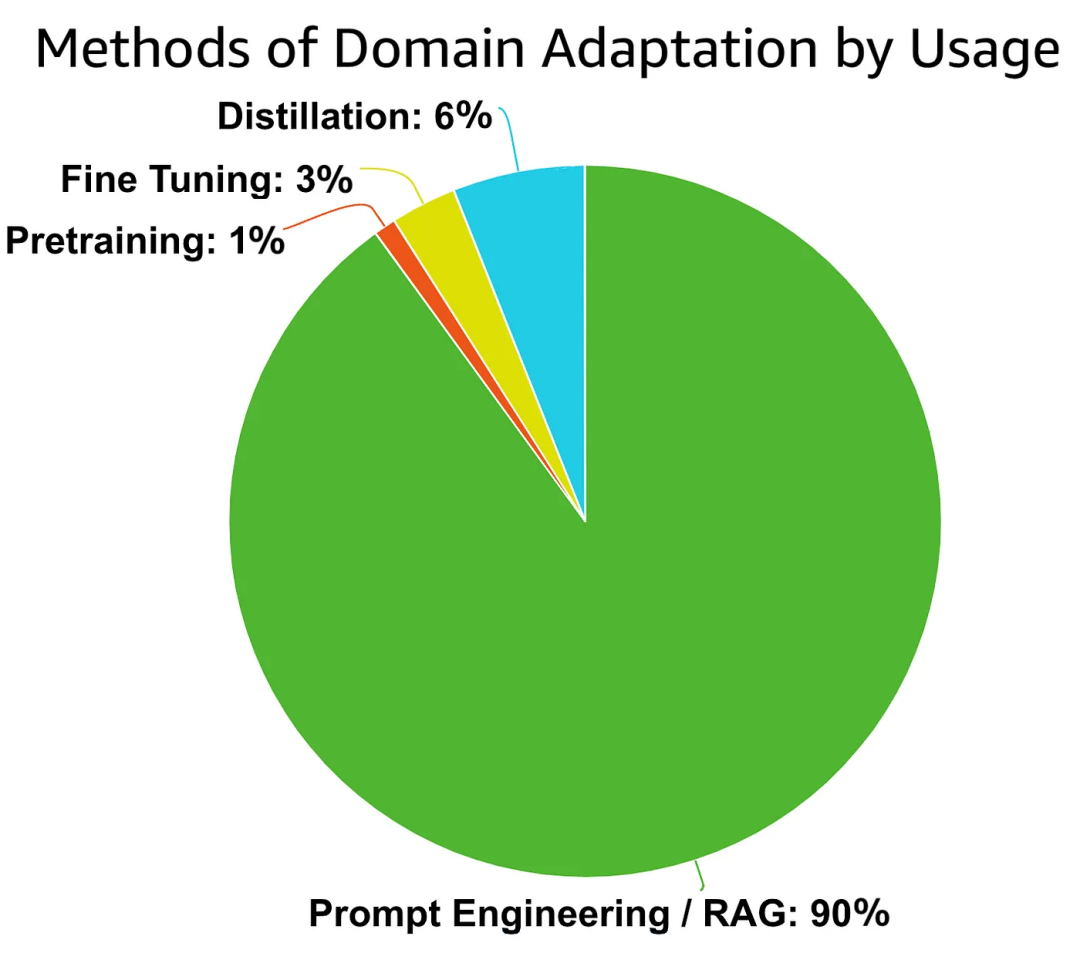
能力边界评估
提示词工程的极限判断框架
知识覆盖度评估
-
关键概念测试:设计覆盖核心业务概念的测试集,评估模型对关键专业术语的理解准确率。
-
知识更新需求:评估业务所需知识更新频率与模型知识更新周期的匹配度。
-
专有信息依赖:量化任务对企业专有信息的依赖程度。
任务复杂性评估
-
多步推理能力:评估模型在多步骤逻辑推理中的成功率。
-
上下文依赖度:测量模型在长对话历史下保持连贯性的能力衰减率。
-
指令遵循精度:测量模型严格执行复杂多条件指令的准确率。
一致性与鲁棒性评估
-
问题变体测试:同一问题不同表述下的答案一致性。
-
对抗性测试:在包含干扰信息的提示下维持正确答案的能力。
-
边界情况处理:在极端或罕见场景下的表现稳定性。
系统集成评估
-
工具使用能力:模型调用外部工具与API的准确率与效率。
-
流程适配性:模型输出与现有业务流程的匹配度与兼容性。
-
错误处理机制:识别并适当处理超出能力范围请求的有效性。
决定模型微调/蒸馏技术的量化指标(一些拍脑袋的想法)
性能差距指标
-
准确率门槛:特定任务准确率低于目标阈值20%以上。
-
召回率不足:关键信息检索召回率低于75%。
-
一致性指标:相同语义问题的答案一致性低于80%。
-
域内表现差距:与人类专家在特定领域的表现差距超过25%。
资源效率指标
-
延迟不可接受:推理响应时间超出业务容忍度50%以上。
-
成本效益比:API调用成本超过预期预算的30%以上。
-
依赖风险:外部API依赖导致的服务中断风险超过可接受水平。
业务价值指标
-
ROI预期:技术投资回报期预计小于9个月。
-
规模化潜力:优化后可覆盖的业务场景增幅预期超过200%。
-
战略重要性:应用对企业核心竞争力的贡献度评分高于7分(10分制)。
技术可行性指标
-
数据可得性:高质量领域数据集规模达到最低要求(通常10K-100K样本)。
-
专业资源可用度:具备必要的计算资源和专业AI人才。
-
验证机制完备性:是否具备有效评估优化效果的测试框架。
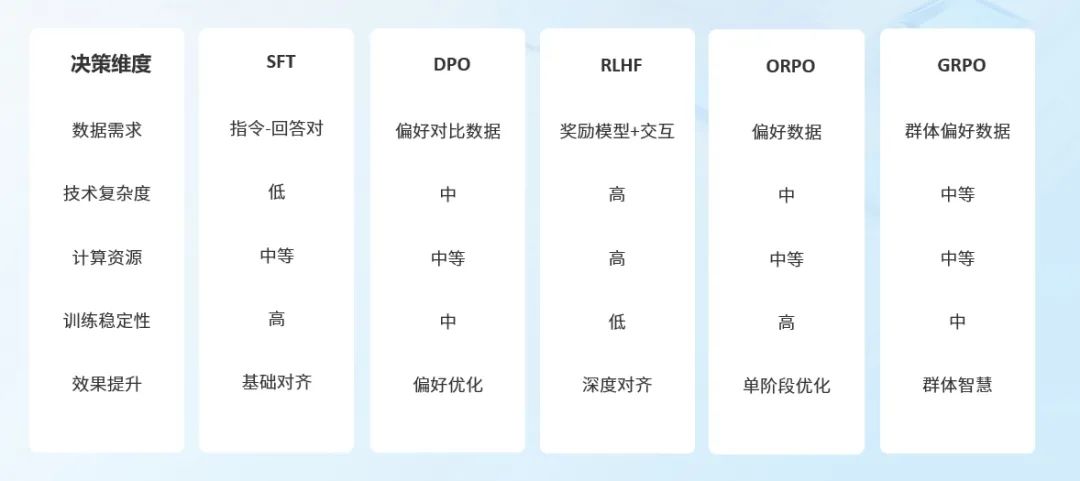
模型微调与蒸馏技术选择
理解微调与蒸馏这两种主要模型定制技术的原理、优劣势及适用场景,对于制定有效的大模型优化策略至关重要。本章深入分析两种技术的核心特点,并提供科学的决策框架。
两种技术的原理与关键区别
微调(Fine-tuning)技术体系
-
基本概念:在预训练模型基础上,使用特定领域或任务数据进行二次训练
-
核心机制:通过梯度下降调整模型参数权重,使模型更适合目标任务
-
参数效率微调变体:
-
全参数微调(Full Fine-tuning):调整模型所有参数,效果最佳但资源需求最高
-
LoRA (Low-Rank Adaptation):仅调整低秩适配矩阵,大幅降低计算需求
-
P-tuning/Prompt-tuning:只调整连续提示向量,最轻量级的微调方式
-
QLoRA:结合量化技术的低秩适配,进一步降低资源门槛
-
Adapter-tuning:插入小型可训练模块,保持大部分原始参数冻结
- LLM特有微调方法:
-
SFT(Supervised Fine-Tuning):使用高质量人工编写的指令-回复对进行有监督微调
-
DTO(Direct Training Optimization):直接优化模型对目标指标的表现,如DPO、PRO等
-
Online DTO:在交互环境中实时收集反馈并优化模型
-
RTO(Reinforcement Training from Optimization):从优化目标出发的强化学习训练,如RLHF
-
强化学习范式:基于人类反馈的强化学习(RLHF)和基于AI反馈的强化学习(RLAIF)
蒸馏(Distillation)技术体系
-
基本概念:将大型"教师模型"的知识压缩传递到小型"学生模型"
-
核心机制:学生模型不仅学习正确标签,更学习教师模型的概率分布和中间表示
-
参数效率微调变体:
-
响应蒸馏(Response Distillation):学生模型学习匹配教师模型的最终输出
-
特征蒸馏(Feature Distillation):学习中间层特征表示,传递更丰富的知识
-
关系蒸馏(Relation Distillation):学习样本间的关系知识
- LLM特有微调方法:
-
标准知识蒸馏(KD):基于软标签(soft labels)学习教师模型的输出分布
-
自蒸馏(Self-distillation):模型作为自己的教师,通过多阶段优化提升效果
-
在线蒸馏(Online Distillation):教师和学生模型同时训练优化
-
协作蒸馏(Collaborative Distillation):多个教师协作引导单个或多个学生模型
-
课程蒸馏(Curriculum Distillation):按难度递增的顺序进行知识传递

大模型蒸馏的特殊案例(如DeepSeek-R1)
DeepSeek-R1的蒸馏方法分析
DeepSeek-R1采用的是一种数据蒸馏(Data Distillation)方法,而不是传统的知识蒸馏(Knowledge Distillation)。关键区别在于:
DeepSeek-R1的蒸馏流程
1、数据生成阶段:
-
使用DeepSeek-R1(基于DeepSeek-V3-Base开发的671B参数MoE模型)生成高质量训练样本
-
生成了约80万个样本(60万个推理相关,20万个非推理相关)
-
样本包含详细的推理过程(链式思考CoT)和最终答案
2、监督微调阶段:
-
使用这些生成的样本对较小的开源模型进行标准监督微调
-
微调目标包括Qwen和Llama系列的六种不同规模模型(1.5B、7B、8B、14B、32B和70B)
与传统知识蒸馏的区别
传统知识蒸馏通常使用教师模型的软标签(概率分布)来训练学生模型,而DeepSeek-R1的方法主要使用大模型生成的显式文本样本进行监督微调。
这种数据蒸馏方法的优势是可以将一个强大模型的知识转移到架构完全不同的模型中,而且比直接应用强化学习于小模型效果更好。
实验证明
研究团队通过对比实验证明了这种蒸馏方法的有效性:他们直接在Qwen-32B上应用大规模强化学习,结果远不如使用DeepSeek-R1生成的数据进行蒸馏的效果好。这表明大模型发现的推理模式可以有效地转移到小模型中。
场景适配性与选择决策框架
微调技术选择矩阵
蒸馏技术选择框架
标准知识蒸馏适用场景:
-
部署效率要求:推理延迟需降低50%以上
-
硬件限制严格:目标设备显存/算力有明确上限
-
性能容忍度:可接受5-15%的性能损失换取资源效率
数据蒸馏适用场景:
-
架构差异大:教师与学生模型架构完全不同
-
知识迁移重点:重视推理过程而非参数分布
-
数据生成能力强:拥有强大的教师模型生成高质量样本
ModelWhale 大模型应用平台 现已全新升级!围绕**"知识、模型、流程、应用"**四大数字资产视角,掌握与大模型/智能体的协作方法。以更强大的功能和更灵活的适应性,紧跟时代步伐,引领数据科学行业迈向新的发展阶段。
-
以文件知识库为基底,拓展面向大模型的 RAG 知识库,让大模型吃透专业;
-
一体化的 MaaS 大模型应用平台,为科研机构及企业提供从模型托管到智能应用落地的全链路支持;
-
灵活的 Agent + Workflow 编排工具,一键连通平台所有知识和模型资产,丝滑对接外部 LLM 与 MCP 服务;
-
将编排工具中设计的智能体直接发布至应用中心,实现团队内共享,也可通过链接添加第三方的优质应用,整合领域内常用工具。
ModelWhale 大模型应用平台现已正式启动开放体验,为企业与团队级 AI 应用落地打造全流程底座。
参考文献
-
how-to-choose-between-pre-training-fine-tuning-and-model-distillation
-
a-guide-to-amazon-bedrock-model-distillation-preview
-
Alignment Guidebook - Shangmin Guo, Wei Xiong (2024)
-
Training language models to follow instructions with human feedback - Long Ouyang et al. (2022)
-
Proximal Policy Optimization Algorithms - John Schulman et al. (2017)
-
Llama 2: Open Foundation and Fine-Tuned Chat Models - Meta (2023)
-
Direct Preference Optimization: Your Language Model is Secretly a Reward Model - Rafailov et al. (2023)
-
Direct Language Model Alignment from Online AI Feedback - Shangmin Guo et al. (2024)
-
DPO Meets PPO: Reinforced Token Optimization for RLHF - Han Zhong et al. (2024)
-
Baichuan 2: Open large-scale lanuage models - Baichuan AI (2023)
-
Exploring the LLM Journey from Cognition to Expression with Linear Representations - Yuzi Yan et al. (2024)
-
WEAK-TO-STRONG GENERALIZATION: ELICITING STRONG CAPABILITIES WITH WEAK SUPERVISION - OpenAI (2024)
-
The Generative AI Paradox: "What It Can Create, It May Not Understand" - Peter West et al. (2023)
-
The Platonic Representation Hypothesis - Minyoung Huh et al.(2024)
-
AWS Bedrock:面向 AI 应用的端到端解决方案