转载请注明出处:
一、订阅功能的核心作用
InfluxDB 的订阅是一种 数据自动推送机制,当指定数据库的写入操作发生时,InfluxDB 会 实时复制数据 并推送到预先配置的端点(如 Kapacitor)。
类比说明:
-
类似于 MySQL 的 Binlog 复制
-
或 Kafka 的 Producer-Consumer 模型
二、订阅的工作原理
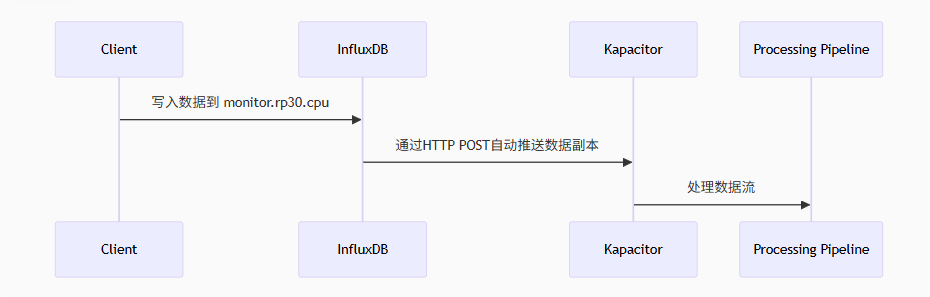
-
数据路径
写入请求 → InfluxDB存储引擎 → 订阅分发器 → HTTP推送 → 接收端 -
协议支持
-
默认使用 HTTP 协议(可配置 HTTPS)
-
数据格式与 InfluxDB 行协议(Line Protocol)一致
-
三、订阅的配置方法
1. 创建订阅
-- 基本语法
CREATE SUBSCRIPTION "<订阅名称>"
ON "<数据库>"."<保留策略>"
DESTINATIONS <ALL|ANY> "<协议>://<主机>:<端口>/<路径>"
-- 实际示例(推送到Kapacitor)
CREATE SUBSCRIPTION "kapacitor-sub"
ON "monitor"."rp30"
DESTINATIONS ALL 'http://kapacitor:9092'2. 参数说明
| 参数 | 说明 | 示例值 |
|---|---|---|
ALL |
发送到所有目标 | ALL 或 ANY |
ANY |
发送到任意一个可用目标 | |
| 协议 | 支持 http/https/udp |
http |
| 路径 | Kapacitor 需使用 /write |
/kapacitor/v1/write |
四、订阅的管理与查看
1. 查看所有订阅
-- 查看特定数据库的订阅
SHOW SUBSCRIPTIONS ON "monitor"
-- 输出示例:
name: monitor
retention_policy name mode destinations
--------------- ---- ---- ------------
rp30 kapacitor-sub ALL [http://kapacitor:9092]2. 删除订阅
DROP SUBSCRIPTION "kapacitor-sub" ON "monitor"."rp30"3. 查看订阅状态(需监控端点)
kapacitor stats ingress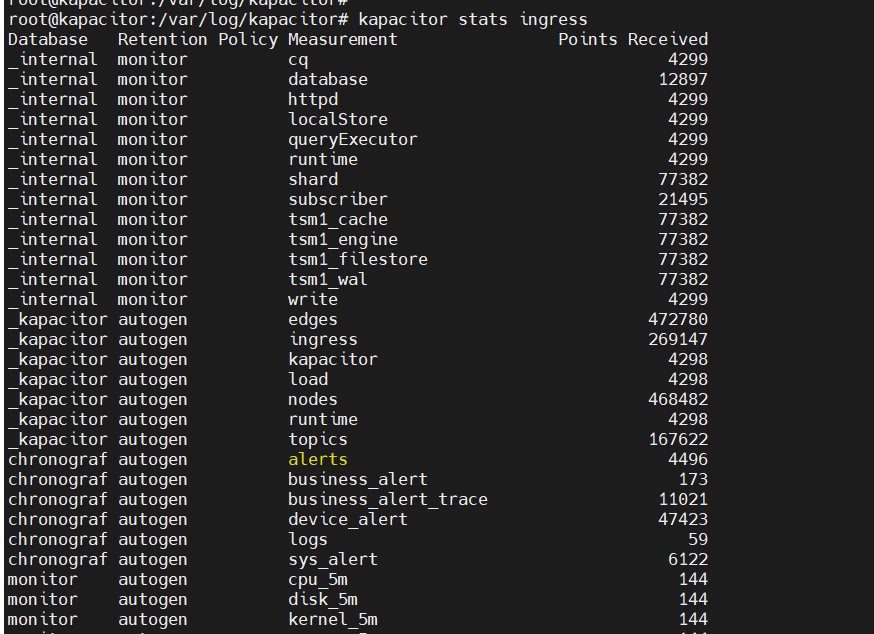
五、订阅的核心特点
1. 实时性
-
数据写入 InfluxDB 后 毫秒级 推送到订阅端
-
对比查询拉取模式,延迟降低 90% 以上
2. 可靠性
| 保障机制 | 说明 |
|---|---|
| 重试机制 | 默认重试 3 次(可配置) |
| 离线缓存 | 网络中断时缓存 1000 条数据(默认) |
| 数据去重 | 通过 UUID 避免重复推送 |
六、Kapacitor日志分析数据写入
查看kapacitor得日志:
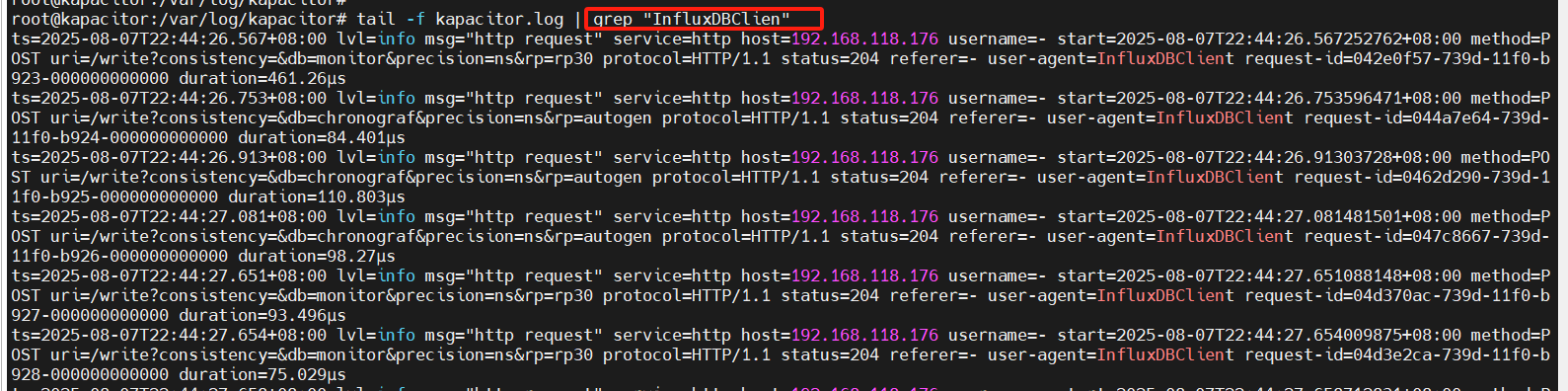
(1)数据来源
-
InfluxDB 订阅推送:
-
InfluxDB 的
monitor.rp30数据通过 HTTP POST 推送到 Kapacitor 的/write端点。 -
触发条件:InfluxDB 的
CREATE SUBSCRIPTION配置生效。
-
(2)数据内容
-
数据库:
monitor -
保留策略:
rp30 -
时间精度:
ns(纳秒级时间戳) -
一致性级别:未指定(默认
all)
(3)Kapacitor 处理
-
成功接收(
status=204):- Kapacitor 正确接收数据,未返回内容(
204 No Content)。
- Kapacitor 正确接收数据,未返回内容(
七、Kapacitor命令分析
| 命令 | 作用 | 与 ingress 的关联性 |
|---|---|---|
kapacitor stats general |
查看任务处理状态 | 若 ingress 有数据但任务无处理,需检查任务逻辑 |
kapacitor stats egress |
查看数据输出(如HTTP告警发送) | 确认数据是否被正确处理并转发 |
influx -execute "SHOW STATS" |
查看InfluxDB推送统计 | 对比InfluxDB发送量与Kapacitor接收量 |
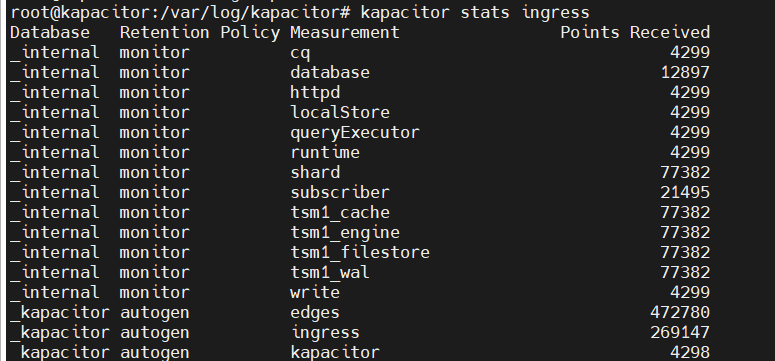
(1)kapacitor stats egress
典型输出示例:
Database Retention Policy Measurement Points Received
--------- --------------- ----------- ---------------
monitor rp30 cpu 1500
_kapacitor autogen edges 39451| 字段 | 说明 |
|---|---|
| Database | 数据来源的数据库名(如 monitor) |
| Retention Policy | 数据所属的保留策略(如 rp30) |
| Measurement | 指标名称(如 cpu) |
| Points Received | 累计接收的数据点数(持续增长表示数据正常流动) |
(2)kapacitor stats general
root@kapacitor:/var/log/kapacitor# kapacitor stats general
ClusterID: 183a5dd5-458f-4923-8c7c-d1951e1da259
ServerID: 675c36aa-e959-4a46-8713-cbe86346b01c
Host: kapacitor
Tasks:16
Enabled Tasks: 16
Subscriptions: 4
Platform: OSS
Version: 1.5.9
root@kapacitor:/var/log/kapacitor#可以查看订阅任务得数量