随着工业信息化和物联网(IoT)的快速发展,工厂每天都会产生海量的实时时间序列数据(如设备状态、传感器读数)。此时,传统的关系型数据库 在应对高并发写入、快速查询和长期存储这些数据时,已经显现出性能瓶颈。时序数据库正是为解决这一难题而设计的专业系统。

InfluxDB专注于时间序列数据的优化处理,通过高效的数据模型和压缩算法,为用户提供了高效、可靠的数据存储和查询服务。
关系型数据库和时序数据库的区别?
▼数据库性能对比▼
| 特性维度 | 关系型数据库 | 时序数据库 |
|---|---|---|
| 设计目标 | 保障数据的一致性和完整性,支持复杂的关联操作的事务 | 高效处理时间顺序写入的海量数据,专注于时序数据的快速写入、压缩和聚合查询 |
| 数据模型 | 以实体和关系为核心 | 以时间线和度量为核心 |
| 数据写入/读取 | 随机写入、灵活查询 | 高吞吐、仅追加的顺序写入,写入性能极高,基于时间范围的高性能查询 |
| 存储优化 | 针对随机读写优化 | 针对时间序列优化 |
| 扩展性 | 纵向扩展为主,扩展性低 | 横向扩展设计,扩展性高 |
那如何实现安全、快速地将OPC数据写入InfluxDB时序数据库呢?
1、使用Kepware软件 IoT Gateway插件实现,订阅授权方式
2、使用上海泗博自动化OPLink软件InfluxDB插件实现,永久授权方式
接下来给大家介绍如何实现把数据存储到InfluxDB时序数据库
Kepware IoT Gateway插件篇
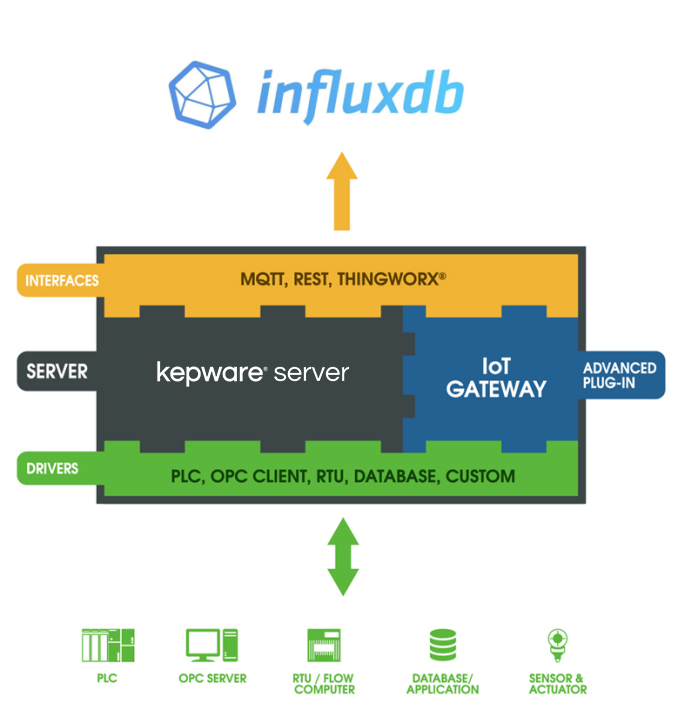
Kepware Server操作设置说明:
1.新建一个IoT Gateway的Agent,选择REST Client
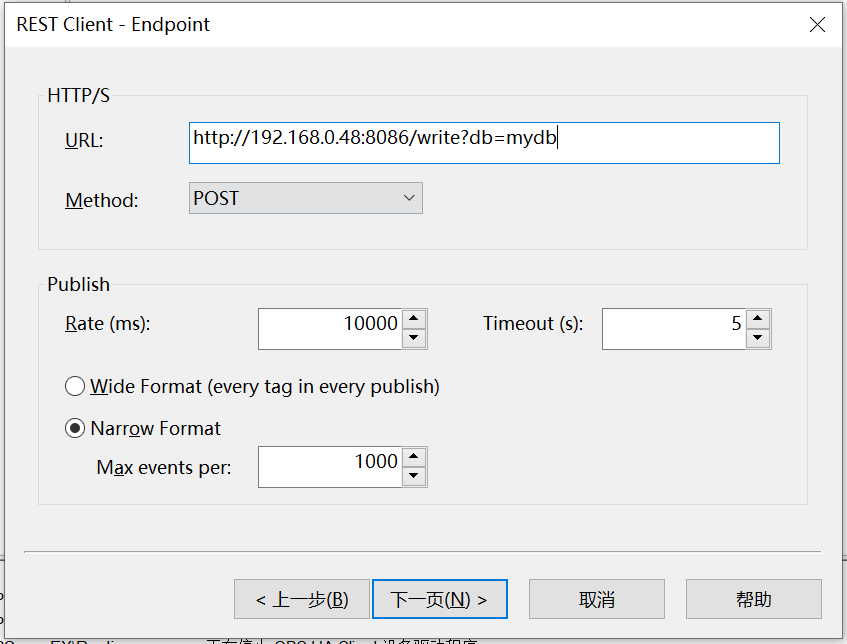
2.填写要连接的InfluxDB数据库的Host地址,例如:
http://192.168.0.48:8086/write?db=mydb
其中mydb是数据库的名字
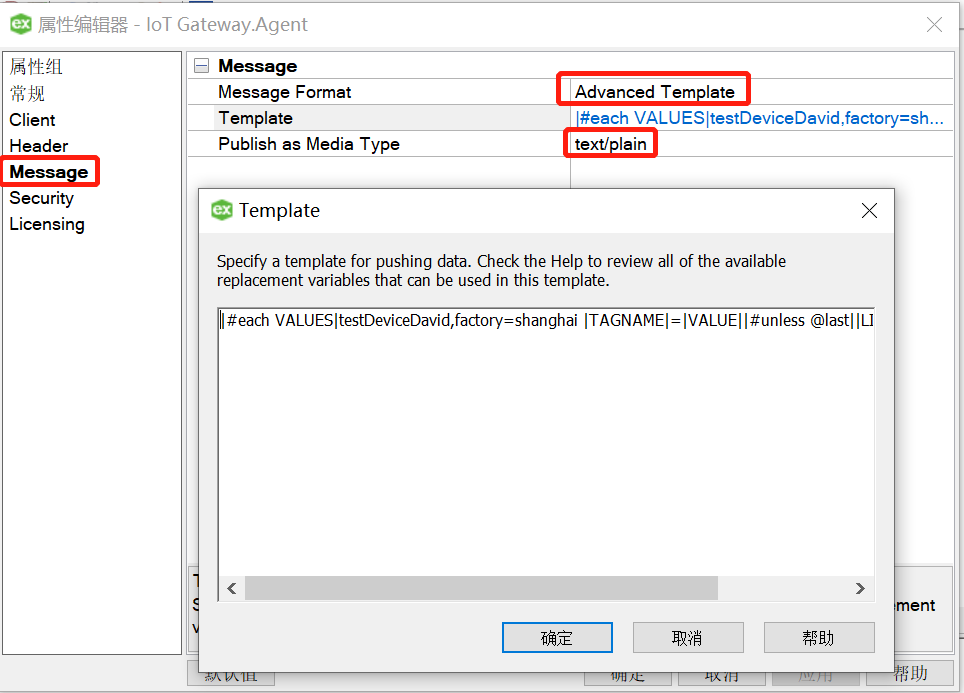
3.修改发布数据模板为"Advanced Template",Message格式如下所示
|#each VALUES|testDeviceDavid,factory=shanghai |TAGNAME|=|VALUE||#unless @last||LINEFEED||/unless||/each|
testDeviceDavid为数据库中的表名
factory=shanghai为数据库加一个索引
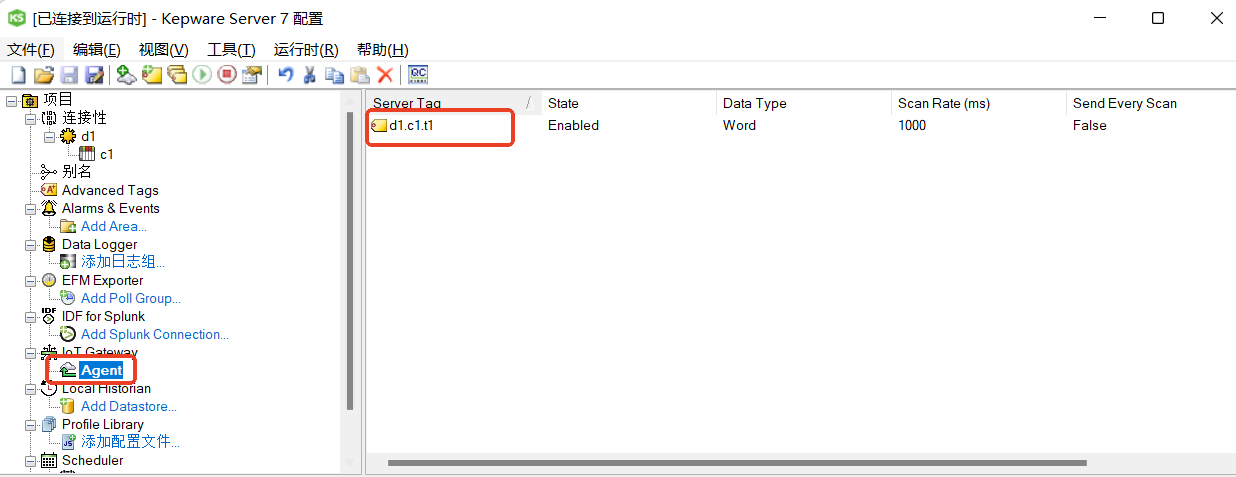
4.添加需要上传存储的数据点位
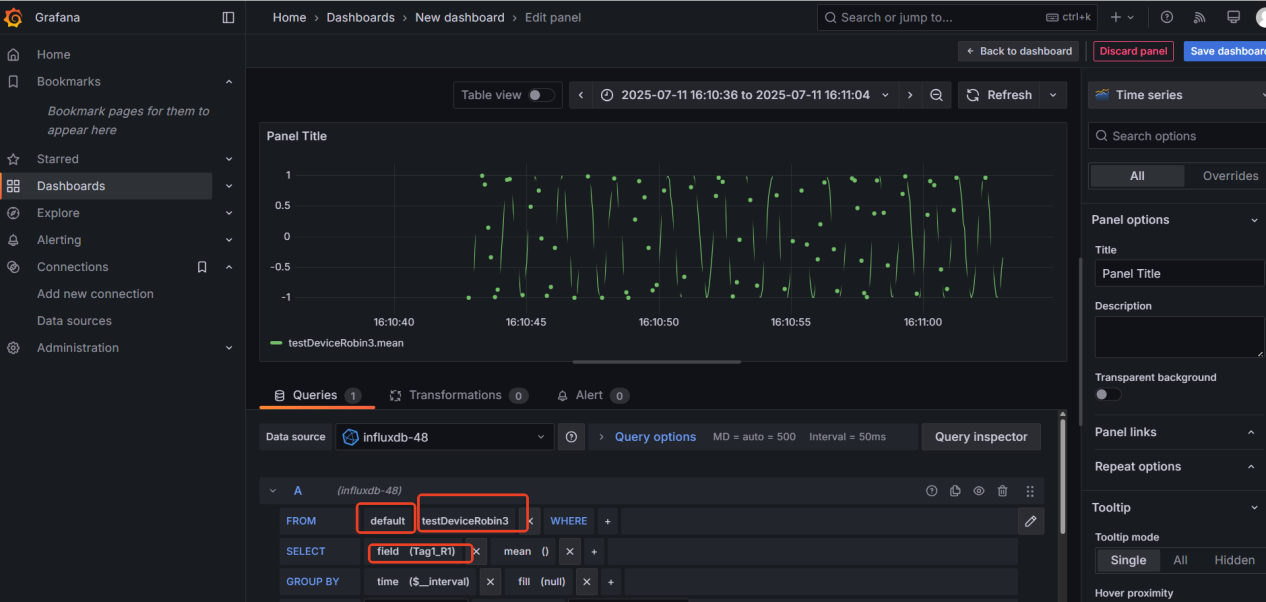
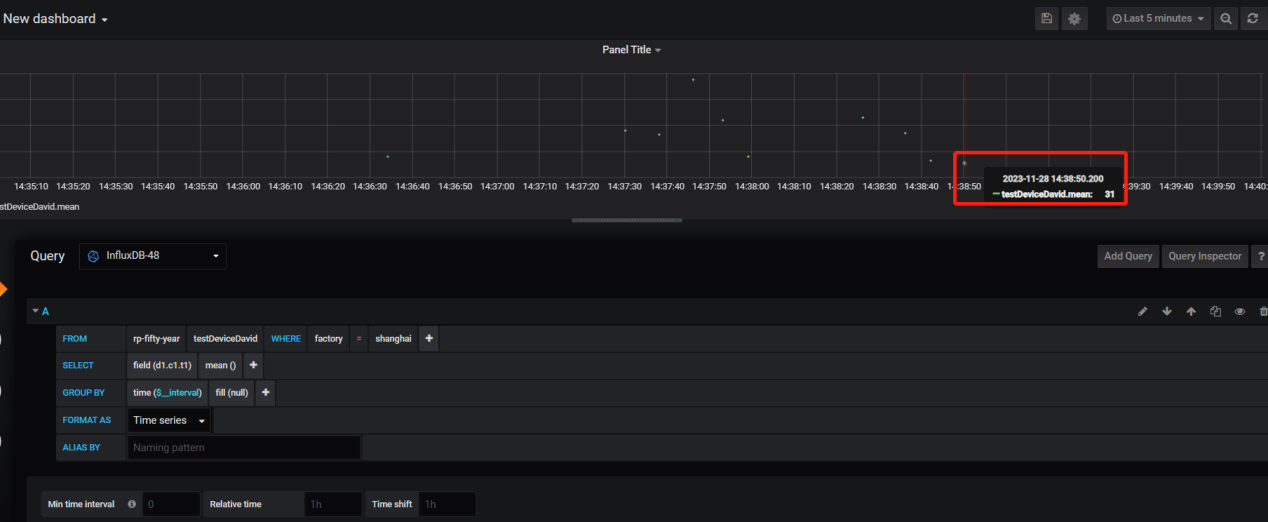
使用Grafana工具查看数据
OPLink软件篇
以下演示如何使用OPLink软件将本地OPC Server(Kepware Server)的数据存储到InfluxDB数据库。
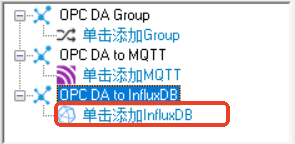
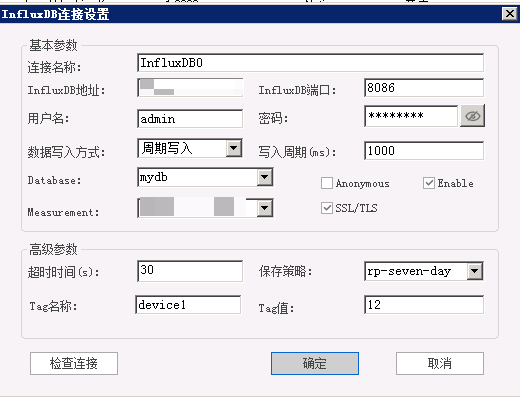
1.在OPC DA to InfluxDB下方,点击**单击添加InfluxDB**可创建一个新InfluxDB。
- 打开InfluxDB属性界面:
在此界面设置InfluxDB的连接名、InfluxDB地址、端口、用户名、密码、数据写入方式、写入周期、Database、是否启用SSL/TMS等参数。
在创建Link之前,需确保本地OPC Server已安装,已创建作为发布和订阅使用的Tag。 本文档举例所用OPC Server为Kepware Server软件,已在本地安装,使用Simulator驱动创建有两个Tag:Tag1_R和Tag1_R1。
运行之后可以看到日志记录显示正在存储:

使用Grafana工具查看数据
Tag1_R 点位存储效果
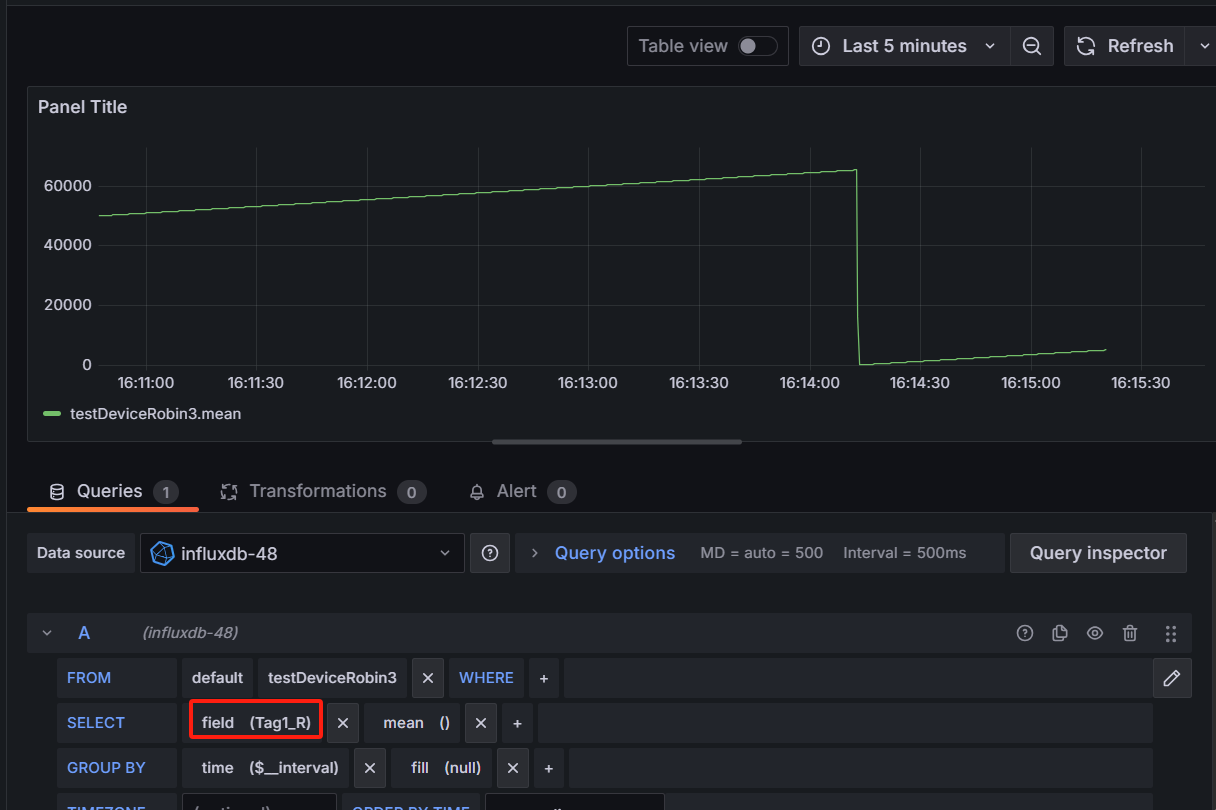
Tag1_R1 点位存储效果: