文章内容已同步到个人网站:zhangxuyang.com/
什么是缓存击穿?为什么会出现缓存击穿问题?
首先缓存击穿指的是当redis中的key过期后,同时有大量的请求想要从缓存中读取数据,由于数据不存在就只能去查询数据库中的数据,当大量的请求都来到数据库,这就造成了缓存击穿问题。所以说,缓存击穿就是指大量的请求由于拿不到缓存中的数据,于是越过缓存去查数据库。缓存击穿问题有可能会导致数据库压力过大。
怎么解决缓存击穿问题?
想要解决缓存击穿问题,首先需要从系统的侧重点出发,要考虑当前的系统是对数据的一致性要求更高,还是对可用性要求更高。
针对数据强一致性的解决方案:互斥锁
场景示例:查询订单列表,通过接口获取redis 缓存中的数据,使用JMeter 模拟1000 个请求,第一次演示缓存未过期的情况,第二次演示过期的情况,通过观察后台以及JMeter展示的吞吐量获取两次请求的区别。
代码示例:
controller
java
/**
* 查询商品订单列表
*/
@GetMapping("/list")
public TableDataInfo list(GoodsOrder goodsOrder)
{
startPage();
List<GoodsOrder> list = goodsOrderService.selectGoodsOrderList(goodsOrder);
return getDataTable(list);
}service
java
/**
* 查询商品订单列表
*
* @param goodsOrder 商品订单
* @return 商品订单
*/
@Override
@Cacheable(value = "orderCache",key = "'all'")
public List<GoodsOrder> selectGoodsOrderList(GoodsOrder goodsOrder)
{
return goodsOrderMapper.selectGoodsOrderList(goodsOrder);
}假设redis中已经缓存了订单列表数据,使用JMeter 测试请求,并发数1000:
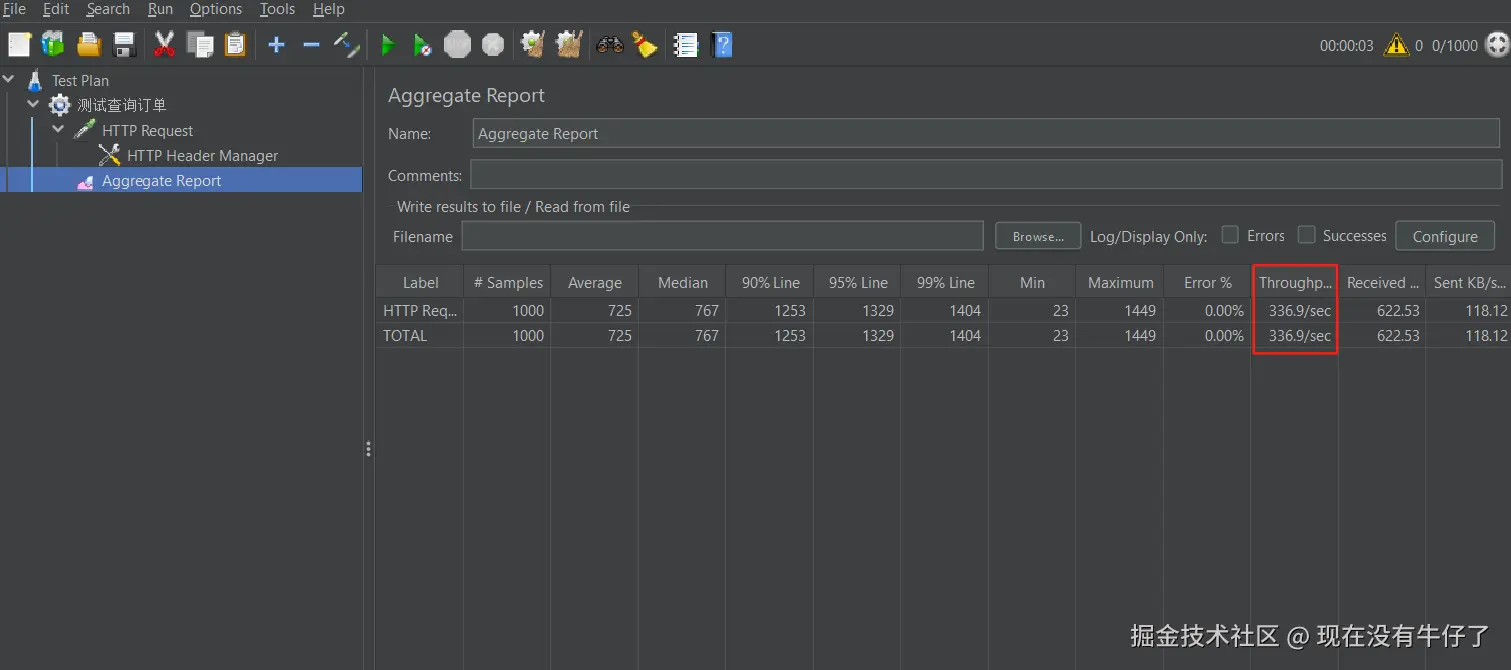
主要观察Throughput(每秒吞吐量),在正常的情况下每秒的吞吐量能达到336.9,还是不错的。
现在清空redis缓存模拟数据过期,再次发起并发请求:
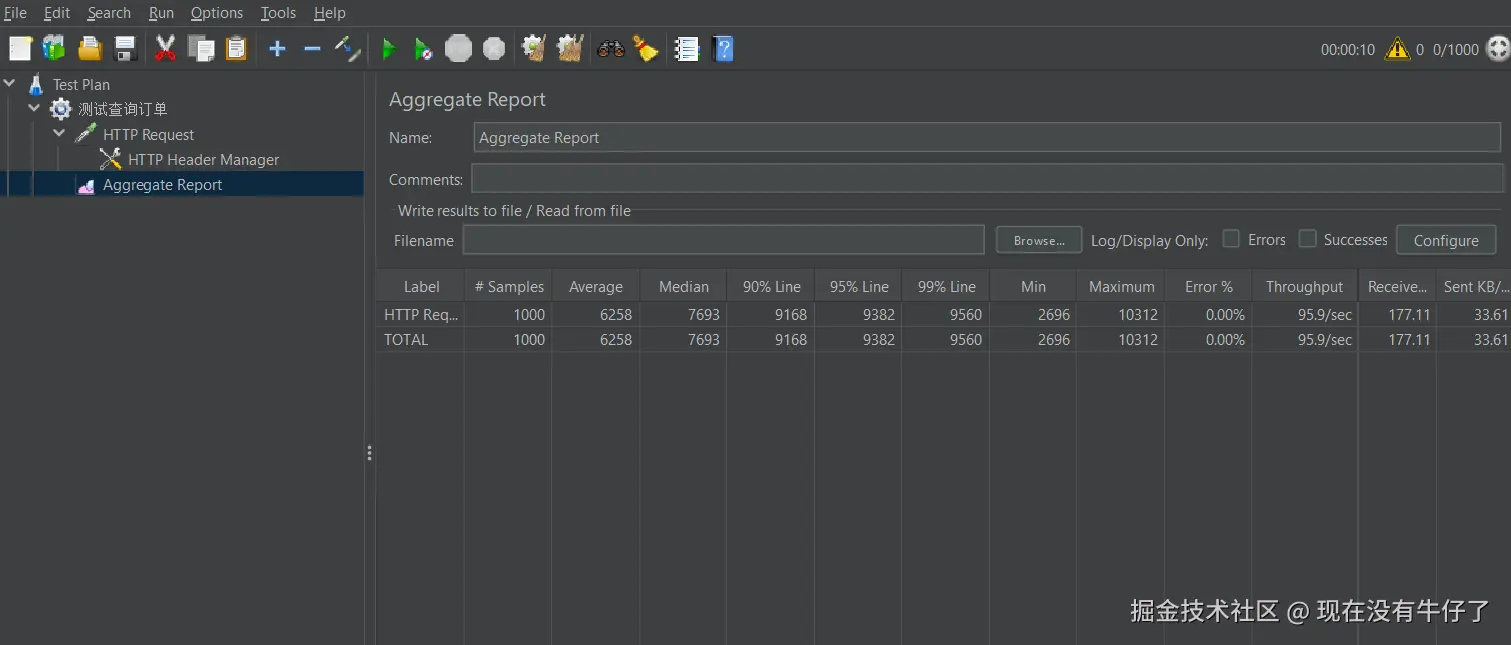
可以看到,吞吐量下降了很多,现在只有不到100每秒,并且通过观察后台日志,发现有大量的数据库查询,这种情况就说明存在缓存击穿问题
接下来,清空删除这个key的缓存并为这个查询操作加一个互斥锁,修改后的代码如下(sync = true):
java
/**
* 查询商品订单列表
*
* @param goodsOrder 商品订单
* @return 商品订单
*/
@Override
@Cacheable(value = "orderCache",key = "'all'",sync = true)
public List<GoodsOrder> selectGoodsOrderList(GoodsOrder goodsOrder)
{
return goodsOrderMapper.selectGoodsOrderList(goodsOrder);
}再次使用JMeter工具进行测试:
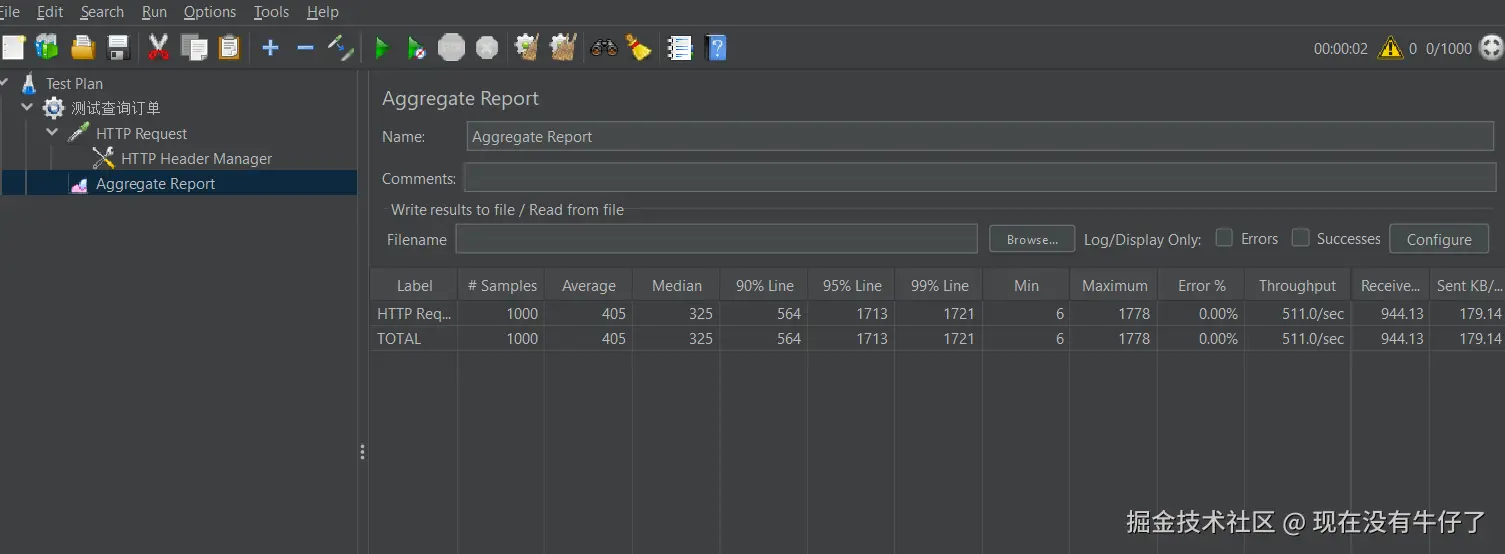
可以看到,吞吐量已经恢复正常了,并且后台也只有一条查询数据库的记录,这是因为添加互斥锁之后,只有当前获取了锁的线程成功的将数据库中的数据存储到缓存中之后,才能继续进行读的操作 。并且这个锁是读写互斥,读读不互斥的,所以当有了数据之后,其他的线程都可以同时查询数据。
以上就是通过互斥锁解决缓存击穿问题的方案,它可以保证数据的强一致,但是会有线程阻塞的情况,所以并不是效率最高的方案。
针对高可用性的解决方案:逻辑过期
场景示例:查询订单,如果缓存信息不存在或过期了先返回旧值,并开启一个新的线程更新数据并将过期时间字段一起存储到缓存中。
代码示例:
新建一个CacheWrapper类,用来存储订单数据和过期时间
java
public class CacheWrapper<T> implements Serializable {
private static final long serialVersionUID = 1L;
private T data; // 缓存数据
private long expireTime; // 逻辑过期时间
public CacheWrapper(T data,long expireTime){
this.data = data;
this.expireTime = expireTime;
}
/**
* 创建缓存对象
* @param data
* @param duration
* @return
* @param <T>
*/
public static <T> CacheWrapper<T> wrap(T data, long duration) {
return new CacheWrapper<>(data, System.currentTimeMillis() + duration);
}
/**
* 判断缓存是否已过期
*/
public boolean isExpired() {
return System.currentTimeMillis() > expireTime;
}
public T getData() {
return data;
}
public long getExpireTime() {
return expireTime;
}
}isExpired() => 判断缓存数据是否过期
wrap() => 创建CacheWrapper对象,第一个参数是订单数据,第二个参数是数据缓存的时间,单位毫秒
新的service代码
java
//创建线程池,只能提交一个任务
private static final ExecutorService executor = new ThreadPoolExecutor(
1, // 核心线程数
1, // 最大线程数
0L, TimeUnit.MILLISECONDS,
new SynchronousQueue<>(), // 不存储任务的队列
new ThreadPoolExecutor.AbortPolicy() // 直接抛出RejectedExecutionException
);
/**
* 查询商品订单列表
*
* @param goodsOrder 商品订单
* @return 商品订单
*/
@Override
public List<GoodsOrder> selectGoodsOrderList(GoodsOrder goodsOrder)
{
String key = "orderCache::all";
CacheWrapper<List<GoodsOrder>> wrapper = redisCache.getCacheObject(key);
if(wrapper==null||wrapper.isExpired()){
try {
executor.execute(() -> {
CacheWrapper<List<GoodsOrder>> current = redisCache.getCacheObject(key);
if (current==null||current.isExpired()) {
List<GoodsOrder> goodsOrders = goodsOrderMapper.selectGoodsOrderList(goodsOrder);
CacheWrapper<List<GoodsOrder>> newData = CacheWrapper.wrap(goodsOrders, 30000);
redisCache.setCacheObject(key, newData);
}
});
}catch (RejectedExecutionException e){
System.out.println("任务已被处理");
}
}
return wrapper==null?null:wrapper.getData();
}如果缓存中的数据已经过期,开启一个新的线程去更新缓存,当前线程则返回旧的数据,这里设置的缓存过期时间为30秒。
现在缓存的数据是过期的,使用JMeter 测试请求,并发数1000:
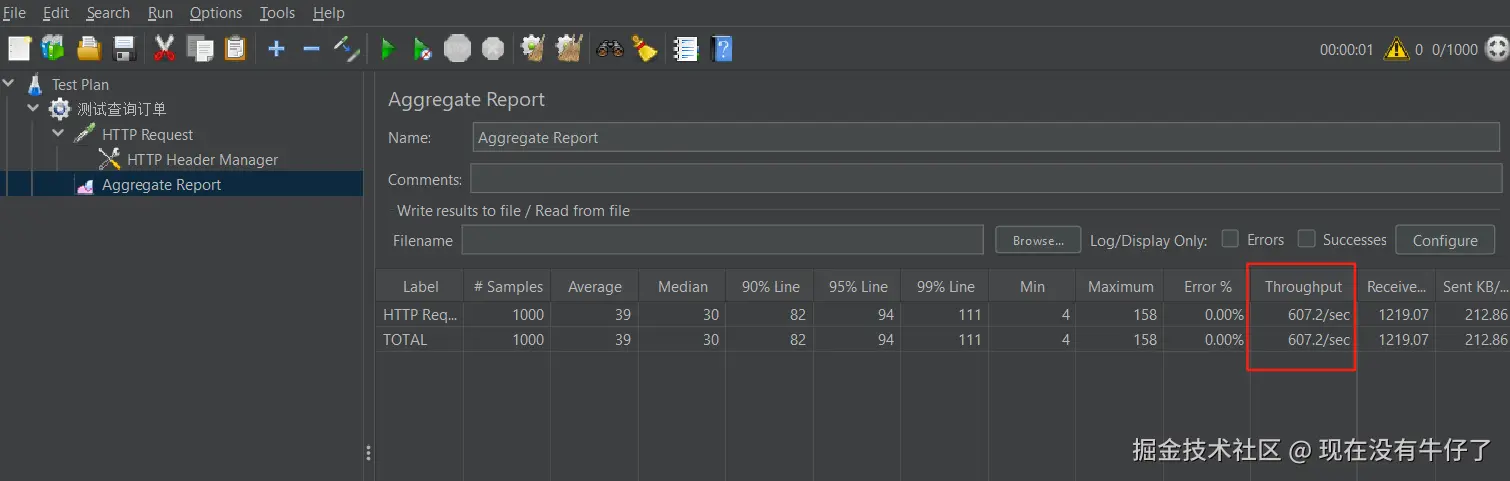
吞吐量为600左右每秒,效率非常高
为什么逻辑过期的方式可用性更高?
首先,逻辑过期避免了锁竞争,避免了线程间的阻塞。只需要一个线程去更新数据,其他线程只需要进行读的操作即可。用户可以很快的获取请求的数据。同时这种方式也有缺点,线程不会等待更新完再去读取数据而是返回旧数据,所以会降低数据的一致性。
这两种解决缓存击穿问题的方式各有利弊,要根据具体的业务场景做取舍。