bash
flink是一个分布式的处理引擎,因为它要做大数据处理,数据处理肯定是并行的
flink 主要处理的是数据流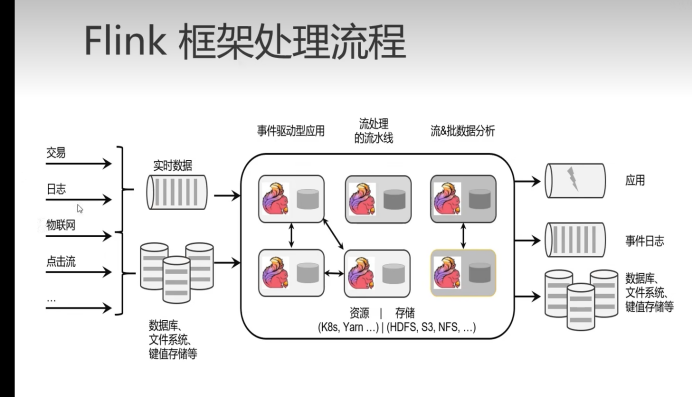
bash
它的处理框架就是有很多实时数据 比如说我们的网站有交易数据,有日志数据 还有点击流
这些数据都是在不停的源源不断的收集 所以我们叫做实时数据,这种情况下,这个数据我们就要不停的读取,随时拉取新的数据过来
flink要做的就是从外部把数据读取进来,实时数据读取进来,然后做各种类型的处理
比如说事件驱动类型(来一个事件我就给他一个响应)
或者我可以做流水线操作 我昨晚一个操作 我接下来再做下一个操作
后续还可以做流数据的分析.或者批处理的分析。一批数据攒齐了之后 我来去分析 到底有什么特征 有什么特点 统计有什么指标
这就是大数据流式处理 这个过程是实时的
bash
每来一个新的数据.理论上我们都可以得到对应响应。因为他是事件驱动。
你来一个新的事件.我这里去做一个响应 最终我可以返回一个结果---->
应用程序 做一个响应
也可以重新写入到事件日志中
另外也可以吧处理的结果写入到 数据库文件系统中
这就是Flink处理的整体流程
bash
flink在什么场景下使用 只要你的数据是实时的 比如说我们的交易数据 我们很多网站不就是要处理这些交易数据么
或者日志数据进行分析,我们要做实时分析
所以 能够应用的行业和应用的场景是很多的
Flink主要就是实时 来了之后 它就可以马上处理 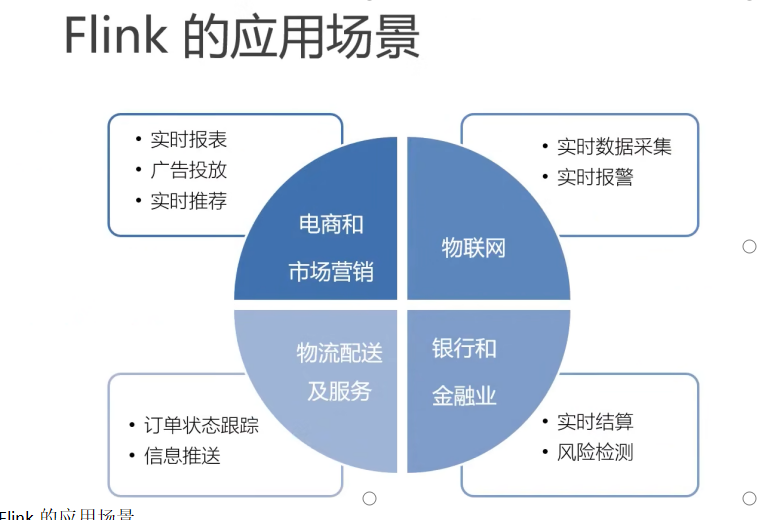
bash
flink的应用场景
为什么要使用Flink
数据都是一个一个的来的 来一个处理一个 流处理
等待一批次 再去处理---------> 这个叫做批处理
flink 处理流处理
真实场景下 数据是一批一批来的多 还是一个一个像数据流一样来的多
我们仔细想一下 更多的还是流式数据
就想vx一样, 我说一句话 发过去 再说一句话 发送这个叫做一条条发送
我也可以吧这一段时间要说的话 所有都换行 全编辑好 一次性发过去
bash
我发一条信息 应该是针对于这条信息做一个反馈 --------------->>>>流式数据
发消息>>>>>>>>>>>>.处理数据
我们真实的数据是流式数据 我处理的时候未必是流处理
对于真实的流式数据来讲 到底是批处理好还是流处理好
从实时性角度来说,聊天必然是实时的聊天
批处理尽管实时性不是很好,但是它从系统设计角度来讲 比较方便 毕竟流式处理对系统压力大 我批处理攒一批再处理
但是批处理的问题就是 尽管它简单 但是它慢
bash
##################>>
我们现在有很多场景就是要快 就是要数据来了 及时处理 及时响应
所以我们的目标是低延迟
所以我们要低延迟 也就是说实时效果要好
###>>> 高吞吐量
很快的处理非常海量的数据 要保证高吞吐
除此之外还要保证结果的正确
分布式处理的有一个问题就是 当前处理的顺序有没有办法保证
我此时很多个服务器同时处理,数据在网络传输和处理过程中会有差异的 就没有办法保证最初的原始数据
bash
这有可能保证我最初的结果不正确
我们怎么能够保证数据是正确的结果是准确的
良好的容错性 如果发生故障 还可以恢复到故障之前的某个状态 然后继续正确的处理