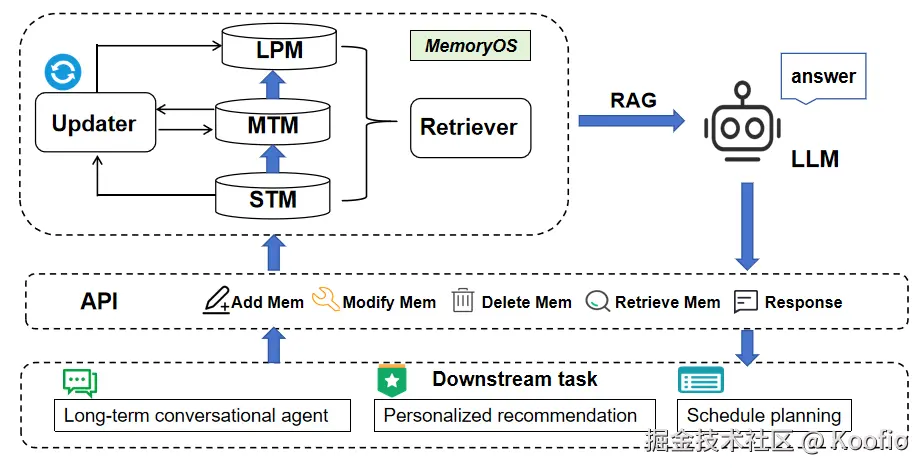
MemoryOS 是北邮百家团队开发的 Agent Memory 管理开源系统,他们将记忆分为三类:
- 短期 STM,一个明文存储的问答对
- 中期 MTM,中期记忆由一组会话构成,每个 Session 包含多个问答对和一些权重和摘要信息
- 长期 LPM,重新组织生成的一个高纬度摘要信息
各种记忆的数据格式
短期记忆
python
[
{
"user_input": "用户输入内容",
"agent_response": "AI助手的回复",
"timestamp": "时间戳"
},
// 更多问答对...
]中期记忆
由 LLM 生成的会话摘要 (summary)、摘要的向量 (summary_embedding)、关键词 (summary_keywords)
python
{
"sessions": {
"session_id": {
"id": "会话ID",
"summary": "会话摘要",
"summary_keywords": ["关键词1", "关键词2", ...],
"summary_embedding": [向量数据],
"details": [
{
"page_id": "页面ID",
"user_input": "用户输入",
"agent_response": "助手回复",
"timestamp": "时间戳",
"preloaded": false,
"analyzed": false,
"pre_page": "前一个页面ID",
"next_page": "后一个页面ID",
"meta_info": "页面元信息",
"page_embedding": [页面向量],
"page_keywords": ["页面关键词"]
}
],
"L_interaction": 交互数量,
"R_recency": 近期访问度量,
"N_visit": 访问次数,
"H_segment": 会话热度,
"timestamp": "创建时间戳",
"last_visit_time": "最后访问时间",
"access_count_lfu": LFU访问计数
}
},
"access_frequency": {
"session_id": 访问频率计数
}
}长期记忆
python
{
"user_profiles": {
"user_id": {
"data": "用户画像数据",
"last_updated": "最后更新时间"
}
},
"knowledge_base": [
{
"knowledge": "知识条目内容",
"timestamp": "时间戳",
"knowledge_embedding": [知识向量]
}
],
"assistant_knowledge": [
{
"knowledge": "助手知识条目",
"timestamp": "时间戳",
"knowledge_embedding": [知识向量]
}
]
}📎sample_long_term_assistant.json
各阶段记忆处理
各个阶段的记忆转换由 updater.py 实现,retriever.py 负责检索和回复
Updater:
-
- process_short_term_to_mid_term: 负责 STM -> MTM 的流程。它会取出 STM 中的所有对话,调用 LLM 进行多主题摘要(gpt_generate_multi_summary),然后根据摘要结果将这些对话智能地插入或合并到 MTM 的不同 Session 中。
Retriever:
-
- retrieve_context: 负责为生成回复提供上下文。它会并行地(使用 ThreadPoolExecutor)向 MTM 和 LTM 发起检索请求,高效地收集所有相关信息。
短期记忆
短期记忆处理比较简单,初始化时会根据输入参数创建一个指定长度的 deque 队列。
python
def add_memory(self, user_input: str, agent_response: str, timestamp: str = None, meta_data: dict = None):
if self.short_term_memory.is_full():
print("Memoryos: Short-term memory full. Processing to mid-term.")
self.updater.process_short_term_to_mid_term()
self._trigger_profile_and_knowledge_update_if_needed()- 超过 short term memory 队列长度会通过
process_short_term_to_mid_term触发记忆迁移 - 同时每次添加记忆都会触发更新长期记忆
在将短期记忆转移到中期记忆时,系统还会检查对话的连续性:
python
is_continuous = check_conversation_continuity(temp_last_page_in_batch, current_page_obj, self.client, model=self.llm_model)通过 LLM 判断两个对话页面是否连续,使用专门的提示模板:
python
CONTINUITY_CHECK_SYSTEM_PROMPT = "You are a conversation continuity detector. Return ONLY 'true' or 'false'."
CONTINUITY_CHECK_USER_PROMPT = ("Determine if these two conversation pages are continuous (true continuation without topic shift).\n"
"Return ONLY "true" or "false".\n\n"
"Previous Page:\nUser: {prev_user}\nAssistant: {prev_agent}\n\n"
"Current Page:\nUser: {curr_user}\nAssistant: {curr_agent}\n\n"
"Continuous?")中期记忆处理
在 MemoryOS 的中期记忆模块中,会话合并是通过 insert_pages_into_session方法实现的。当需要添加新的对话页面时,系统会判断是否应该将这些页面合并到现有会话中,而不是创建新的会话。下面就是合并的具体流程:
- 相似性判断:结合语义嵌入和关键词的相似性计算,准确判断会话相关性
- 重要性评估:通过热度算法综合考虑访问频率、交互长度和时间因素
- 智能合并 :根据相似性阈值决定是合并 到现有会话还是创建新会话
- 连续性维护:通过 LLM 检查确保对话的连贯性
这种设计使得系统能够有效地组织和管理对话记忆,既能保持话题的连贯性,又能识别和分离不同的话题,为后续的记忆检索和响应生成提供了良好的基础。
相似性判断机制
相似性判断采用两种方式的组合:
1. 语义相似性(Semantic Similarity)
系统使用嵌入向量计算语义相似性:
python
new_summary_vec = get_embedding(
summary_for_new_pages,
model_name=self.embedding_model_name,
**self.embedding_model_kwargs
)
new_summary_vec = normalize_vector(new_summary_vec)
for sid, existing_session in self.sessions.items():
existing_summary_vec = np.array(existing_session["summary_embedding"], dtype=np.float32)
semantic_sim = float(np.dot(existing_summary_vec, new_summary_vec))通过计算两个会话摘要嵌入向量的点积来衡量语义相似性。
2. 关键词相似性(Keyword Similarity)
系统还使用 Jaccard 相似度计算关键词相似性:
python
# Keyword similarity (Jaccard index based)
existing_keywords = set(existing_session.get("summary_keywords", []))
new_keywords_set = set(keywords_for_new_pages)
s_topic_keywords = 0
if existing_keywords and new_keywords_set:
intersection = len(existing_keywords.intersection(new_keywords_set))
union = len(existing_keywords.union(new_keywords_set))
if union > 0:
s_topic_keywords = intersection / union
overall_score = semantic_sim + keyword_similarity_alpha * s_topic_keywords最终相似度得分是语义相似度和关键词相似度的加权组合。
重要性评估机制
系统使用热度(Heat)算法来评估会话的重要性,热度值越高表示会话越重要:
python
def compute_segment_heat(session, alpha=HEAT_ALPHA, beta=HEAT_BETA, gamma=HEAT_GAMMA, tau_hours=RECENCY_TAU_HOURS):
N_visit = session.get("N_visit", 0) # 访问次数
L_interaction = session.get("L_interaction", 0) # 交互长度
# 基于上次访问时间计算时间衰减因子
R_recency = 1.0 # Default if no last_visit_time
if session.get("last_visit_time"):
R_recency = compute_time_decay(session["last_visit_time"], get_timestamp(), tau_hours)
session["R_recency"] = R_recency # Update session's recency factor
return alpha * N_visit + beta * L_interaction + gamma * R_recency热度计算包含三个因素:
- 访问频率(N_visit) :访问次数。一个会话被检索的次数越多,越热。
- 交互长度(L_interaction) :交互长度。一个会话包含的对话越多,越热。
- 时间衰减因子(R_recency) :新近度。最近访问的会话,热度更高(随时间衰减)。
公式为:Heat = α × N_visit + β × L_interaction + γ × R_recency
其中 α、β、γ 是权重参数,R_recency 使用指数衰减函数计算:
python
def compute_time_decay(event_timestamp_str, current_timestamp_str, tau_hours=24):
from datetime import datetime
fmt = "%Y-%m-%d %H:%M:%S"
try:
t_event = datetime.strptime(event_timestamp_str, fmt)
t_current = datetime.strptime(current_timestamp_str, fmt)
delta_hours = (t_current - t_event).total_seconds() / 3600.0
return np.exp(-delta_hours / tau_hours)
except ValueError: # Handle cases where timestamp might be invalid
return 0.1 # Default low recency会话合并
- 会话创建:通过 add_session 方法创建新会话,初始化热度值
- 会话合并决策:
-
- 计算新会话与所有现有会话的相似度得分
- 找到最高相似度得分的会话
- 如果最高得分超过阈值,则合并;否则创建新会话
- 合并操作:
-
- 将新页面添加到目标会话的 details 列表中
- 更新会话的交互长度(L_interaction)
- 更新最后访问时间
- 重新计算会话热度
- 重建热度堆
删除记忆会话
会话长度超过了预设长度(2000)时,根据 lfu 算法丢弃旧的会话记录
python
def add_session(self, summary, details, summary_keywords=None):
if len(self.sessions) > self.max_capacity:
self.evict_lfu()
def evict_lfu(self):
session_to_delete = self.sessions.pop(lfu_sid) # Remove from sessions
del self.access_frequency[lfu_sid] # Remove from LFU tracking长期记忆处理
每次调用 add_memory 时,都会检测是否需要更新长期记忆的内容。包含用户画像、用户私有知识、助手知识,如果需要更新就会调用使用指定的 Prompt 调用 LLM 生成记忆,并调用长期记忆(LTM)的相应方法(update_user_profile, add_user_knowledge 等)将这些高度浓缩的信息存入 LTM。
python
def add_memory(self, user_input: str, agent_response: str, timestamp: str = None, meta_data: dict = None):
# After any memory addition that might impact mid-term, check for profile updates
self._trigger_profile_and_knowledge_update_if_needed()
def _trigger_profile_and_knowledge_update_if_needed(self):
# 获取现有的 profile,然后和 unanalyzed_pages 内容一起调用 LLM 处理
existing_profile = self.user_long_term_memory.get_raw_user_profile(self.user_id
gpt_user_profile_analysis(unanalyzed_pages, self.client, model=self.llm_model, existing_user_profile=existing_profile)
gpt_knowledge_extraction(unanalyzed_pages, self.client, model=self.llm_model)
# 使用并行任务执行
with ThreadPoolExecutor(max_workers=2) as executor:
# 提交两个主要任务
future_profile = executor.submit(task_user_profile_analysis)
future_knowledge = executor.submit(task_knowledge_extraction)
# 等待结果
try:
updated_user_profile = future_profile.result() # 直接是更新后的完整画像
knowledge_result = future_knowledge.result()
self.user_long_term_memory.update_user_profile(self.user_id, updated_user_profile, merge=False) # 直接替换为新的完整画像
self.user_long_term_memory.add_user_knowledge(line.strip())
self.assistant_long_term_memory.add_assistant_knowledge(line.strip()) # Save to dedicated assistant LTM
python
def gpt_user_profile_analysis(conversation_str: str, client: OpenAIClient, model="gpt-4o-mini", existing_user_profile="None"):
"""
Analyze and update user personality profile from a conversation string.
"""
messages = [
{"role": "system", "content": prompts.PERSONALITY_ANALYSIS_SYSTEM_PROMPT},
{"role": "user", "content": prompts.PERSONALITY_ANALYSIS_USER_PROMPT.format(
conversation=conversation_str,
existing_user_profile=existing_user_profile
)}
]
print("Calling LLM for user profile analysis and update...")
result_text = client.chat_completion(model=model, messages=messages)
try:
return json.loads(result_text)
def gpt_knowledge_extraction(conversation_str: str, client: OpenAIClient, model="gpt-4o-mini"):
"""Extract user private data and assistant knowledge from a conversation string"""
messages = [
{"role": "system", "content": prompts.KNOWLEDGE_EXTRACTION_SYSTEM_PROMPT},
{"role": "user", "content": prompts.KNOWLEDGE_EXTRACTION_USER_PROMPT.format(
conversation=conversation_str
)}
]
print("Calling LLM for knowledge extraction...")
result_text = client.chat_completion(model=model, messages=messages)
return {
"private": private_data if private_data else "None",
"assistant_knowledge": assistant_knowledge if assistant_knowledge else "None"
}总结
核心原理
系统通过模拟人类记忆机制,将信息在三个层级中进行处理、沉淀和检索:
- 短期记忆 (STM):一个高速、小容量的 FIFO(先进先出)队列,用于暂存最近的对话。
- 中期记忆 (MTM):系统的核心。它将从 STM 传来的对话通过 LLM 进行语义聚类,组织成按主题划分的"会话(Session)"。每个会话都有一个动态计算的 "热度(Heat)" 值(基于访问频率、新近度和交互长度),并采用 LFU(最不常用)策略进行淘汰,确保记忆库的有效性。
- 长期记忆 (LTM):当 MTM 中的某个会话"热度"达到阈值时,系统会调用 LLM 对其进行深度分析,提炼出高度浓缩的 用户画像(User Profile) 和 关键知识点(Knowledge),并存入 LTM。LTM 的知识库采用 滚动更新(Rolling Update) 机制,自动淘汰最旧的知识。
整个信息流由 Updater(更新器) 负责从低级向高级"提炼"和写入,由 Retriever(检索器) 负责在生成回复时从所有层级"并行"拉取上下文。
优点
- 上下文深度:能够跨越非常长的时间周期,关联和检索相关记忆,实现真正意义上的长期个性化对话。
- 结构化记忆:通过智能聚类和分层,记忆内容不再是杂乱的流水账,而是高度组织化的,显著提升了检索的准确性。
- 高效的运行机制:检索过程并行化,核心搜索依赖高效的 faiss 向量索引,同时各层级的自动淘汰机制保证了系统不会无限膨胀,性能稳定。
- 另外 user profile 的 90 种定义也很有意思。
缺点
- 高昂的 LLM 调用开销:系统在记忆的组织、提炼和检索过程中大量依赖 LLM 进行分析(如连续性判断、摘要生成、知识提取),这将导致显著的 API 调用成本和一定的处理延迟。
- 行为的不可预测性:由于记忆的组织在很大程度上依赖 LLM 的"判断",其效果与 LLM 的能力强相关,有时可能出现难以精确控制的"黑盒"行为。
适合的使用场景
该项目非常适合需要与用户建立 长期、深度、个性化关系 的 AI 应用,典型场景包括:
- AI 伴侣或虚拟朋友:需要记住用户的点滴、性格和长期经历。
- 个人专属助理:例如个人研究助理、学习伙伴或工作秘书,需要长期跟进特定项目和用户偏好。
- 高端定制化客服:例如私人银行顾问、VIP 客户经理等,需要记住高价值用户的历史记录和特定需求。
- 个性化教育导师:能够跟踪学生长期的学习进度、知识薄弱点和学习习惯。