一、项目背景
《红楼梦》是中国古典文学的巅峰之作,其丰富的语言和复杂的人物关系为文本分析提供了绝佳的素材。在本次项目中,我们将通过 Python 实现以下目标:
分词与停用词处理:对《红楼梦》文本进行分词,并去除无意义的停用词。
TF-IDF 关键词提取:计算每个章节的 TF-IDF 值,并提取关键词。
通过这些步骤,我们可以更好地理解《红楼梦》的文本结构,挖掘其主题和核心内容。
二、项目实现步骤
(一)分词与停用词处理
- 文本数据的准备
我们将《红楼梦》的文本按卷分割,存储在文件夹中,每个卷的内容保存为一个单独的文本文件。这样可以方便我们后续对每个卷分别进行处理。
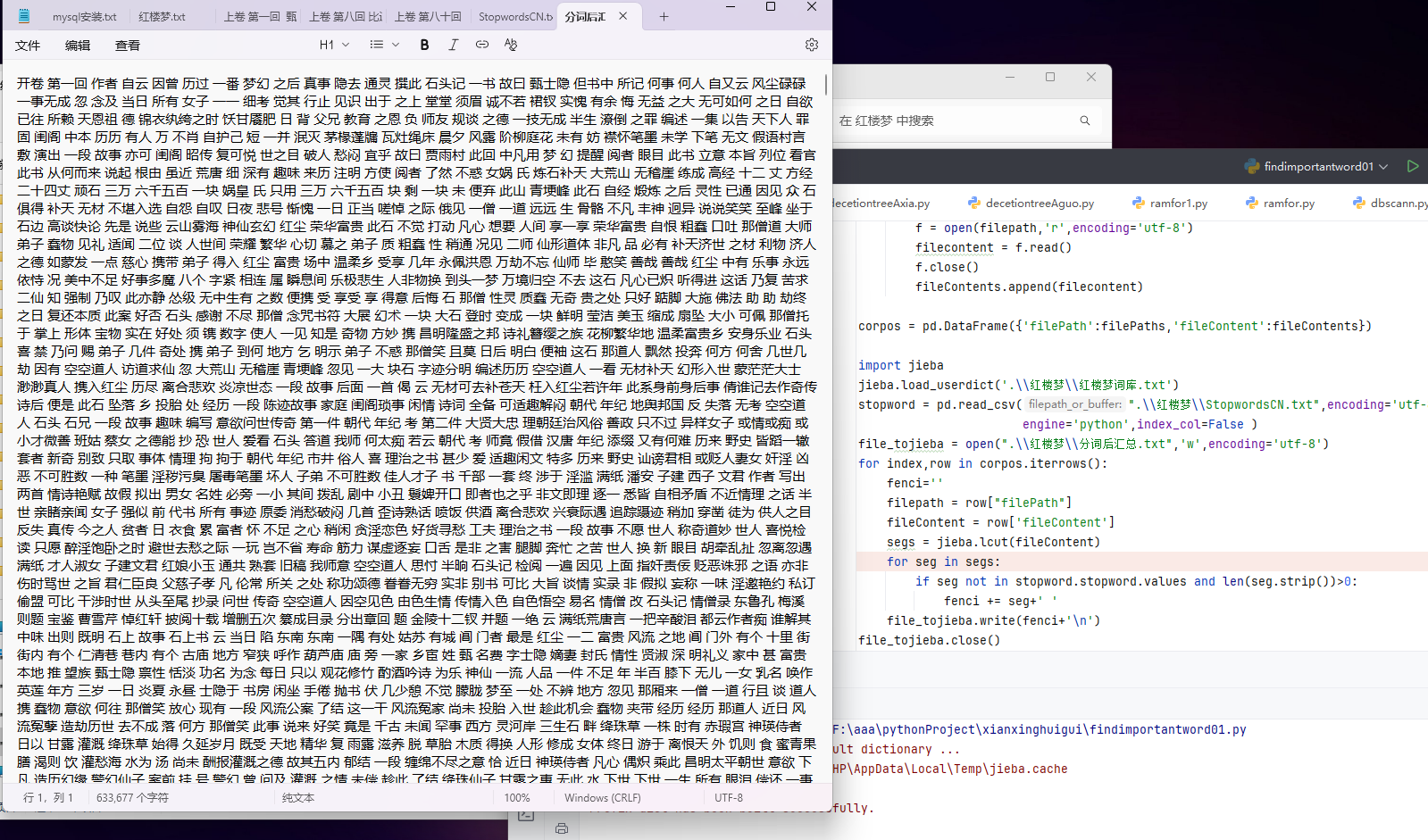
- 遍历文件夹并读取文本内容
我们使用 os.walk 方法遍历存储《红楼梦》文本的文件夹,获取每个卷的文件路径,并读取其内容。以下是实现代码的关键部分:
filePaths = [] # 保存文件的路径
fileContents = [] # 保存文件路径对应的内容
# 遍历文件夹中的所有文件
for root, dirs, files in os.walk(r"D:\Users\妄生\PycharmProjects\机器学习pythonProject\.idea\红楼梦\分卷"):
for name in files:
filePath = os.path.join(root, name) # 获取每个文件的路径
print(filePath)
filePaths.append(filePath) # 卷文件路径添加到列表中
with open(filePath, 'r', encoding='utf-8') as f:
fileContent = f.read() # 读取文件内容
fileContents.append(fileContent) # 文件内容添加到列表中通过上述代码,我们将所有卷的文件路径和内容分别存储在 `filePaths` 和 `fileContents` 列表中,以便后续处理。
- 加载自定义词库
由于《红楼梦》中存在一些特定的词汇,这些词汇可能不在 jieba 的默认词库中。为了提高分词的准确性,我们需要加载自定义词库。我们使用 jieba.load_userdict 方法加载自定义词库:
jieba.load_userdict(r"D:\Users\妄生\PycharmProjects\机器学习pythonProject\.idea\红楼梦\红楼梦词库.txt")
这一步确保了 `jieba` 在分词时能够正确识别《红楼梦》中的专有名词、成语等词汇。
- 读取停用词
停用词是指在文本中频繁出现但对文本意义贡献较小的词汇,如"的""是""和"等。在文本分析中,去除停用词可以减少噪声,提高分析效果。我们从文件中读取停用词列表,并将其存储为一个集合,以便后续快速查找:
stopwords = pd.read_csv(r"D:\Users\妄生\PycharmProjects\机器学习pythonProject\.idea\红楼梦\StopwordsCN.txt",
encoding='utf8', engine='python', index_col=False)
stopwords = set(stopwords['stopword'].values)5. 分词与停用词过滤
file_to_jieba = open(r'D:\Users\妄生\PycharmProjects\机器学习pythonProject\.idea\红楼梦\分词后汇总.txt', 'w', encoding='utf-8')
for index, row in corpos.iterrows():
juan_ci = '' # 空的字符串
fileContent = row['fileContent']
segs = jieba.cut(fileContent) # 对文本内容进行分词
for seg in segs: # 遍历每一个词
if seg not in stopwords and len(seg.strip()) > 0: # 剔除停用词和空字符
juan_ci += seg + ' '
file_to_jieba.write(juan_ci + '\n')
file_to_jieba.close()通过上述代码,我们将每个卷的内容分词后,去除停用词,并将结果写入到一个汇总文件中。
1.读取和显示图像
cv.imread(firepath, flags=1)
读取图像
firepath 图像的路径
flags 图像的打开方式
返回值 返回一个图像对象,实际上是一个三维矩阵
cv.imwrite(firepath, img)
firepath 图像的保存路径
img 要保存的图像对象
flags参数 属性 含义
1 cv.IMREAD_COLOR 以彩色模式加载图像,任何图像的透明度都将被忽略,这是默认参数
0 cv.IMREAD_GRAYSCALE 以灰度模式加载图像
-1 cv.IMREAD_UNCHANGED 包括alpha通道的加载图像模式
flags可以是上述数字参数,也可以是上述属性
cv.imshow(winname, mat)
显示图像
winname 图像显示窗口的名称,字符串的形式
mat 要显示的图像对象
cv.waitKey(time)
图像的停留时间
time=0 时表示图像一直停留
cv.destroyAllWindows()
按任意键可以停止 waitKey(time) 的等待,并关闭所有图像
例:
img = cv.imread("HappyFish.jpg", 1)
cv.imshow("HappyFish", img)
cv.waitKey(0)2.图像的读取方式
在 OpenCV 中,读取和表达图像的方式是B-G-R通道,(Blue-Green-Red)
在 OpenCV 中,图像对象实际上是一个 M×N×3 的三维矩阵,数据类型一般为 uint8 0, 255,如图所示:
例:分别显示出一张彩色图像的 B-G-R 灰度 0, 255
img = cv.imread("HappyFish.jpg", 1)
# B
img_b = img[:, :, 0]
# G
img_g = img[:, :, 1]
# R
img_r = img[:, :, 2]
cv.imshow("B", img_b)
cv.imshow("G", img_g)
cv.imshow("R", img_r)
# 原图
cv.imshow("img", img)此外,在 Matplotlib 中,读取和表达图像的方式是R-G-B通道,显然,如果想要使 OpenCV 打开的图像通过 Matplotlib 来表达,就需要通道的转换,很显然,B-G-R通道 ⇨ R-G-B通道 的转换,只需要将一维矩阵中的元素反转即可
img:, :, ::-1
对图像对象进行通道转换,即一维矩阵的反转
img:, ::-1, :
对图像进行列翻转,即对图像进行水平翻转
img::-1, :, :
对图像进行行翻转,即对图像进行竖直翻转
注:还可以多处进行 ::-1 处理
plt.imshow(img, cmap=)
使用 Matplotlib 来显示图像,通道:R-G-B
img 要显示的图像
cmap= 图像显示的颜色图谱
plt.show()
显示图像
cmap参数 含义
plt.cm.autumn 红-橙-黄
plt.cm.bone 黑-白,x线
plt.cm.cool 青-洋红
plt.cm.copper 黑-铜
plt.cm.flag 红-白-蓝-黑
plt.cm.gray 黑-白
plt.cm.hot 黑-红-黄-白
plt.cm.hsv hsv颜色空间, 红-黄-绿-青-蓝-洋红-红
plt.cm.inferno 黑-红-黄
plt.cm.jet 蓝-青-黄-红
plt.cm.magma 黑-红-白
plt.cm.pink 黑-粉-白
plt.cm.plasma 绿-红-黄
plt.cm.prism 红-黄-绿-蓝-紫-...-绿模式
plt.cm.spring 洋红-黄
plt.cm.summer 绿-黄
plt.cm.viridis 蓝-绿-黄
plt.cm.winter 蓝-绿
img_cv = cv.imread("HappyFish.jpg", 1)
img_plt = img_cv[:, :, ::-1]
# 原图在OpenCV中的显示
cv.imshow("img_cv", img_cv)
# 反转图在OpenCV中的显示
cv.imshow("img_plt_in_cv", img_plt)
# 反转图在Matplotlib中显示
plt.imshow(img_plt)
plt.show()
cv.waitKey(0)
cv.destroyAllWindows()二、绘制几何图形
cv.line(img, start, end, color, thickness, lineType)
绘制直线
img 要绘制直线的图像
start, end 直线的起点和终点
color 直线的颜色,用(B, G, R)表示
thickness 线条宽度
lineType 线条类型
cv.circle(img, centerpoint, radius, color, thickness, lineType)
绘制圆形
img 要绘制圆形的图像
centerpoint, radius 圆形的圆心和半径
color 线条的颜色,用(B, G, R)表示
thickness 线条宽度,为-1时生成闭合的图案并填充线条颜色
lineType 线条类型
cv.rectangle(img, leftupper, rihtdown, color, thickness, lineType)
绘制矩形
img 要绘制矩形的图像
leftupper, rightdown 矩形的左上角和右下角坐标
color 线条的颜色,用(B, G, R)表示
thickness 线条宽度,为-1时生成闭合的图案并填充线条颜色
lineType 线条类型
cv.putText(img, text, station, font, fontsize, color, thickness, cv.LINE_AA)
向图像中添加文字
img 要添加文字的图像
text 要写入的文本内容
station 文本的放置位置
font 字体
fontsize 字体大小
color 线条的颜色,用(B, G, R)表示
thickness 线条宽度
cv.LINE_AA 一种线条类型
# 创建一个全黑的三维矩阵作为图像对象
img = np.zeros((512, 512, 3), np.uint8)
# 绘制图形
cv.line(img, (0, 0), (511, 511), color=(255, 0, 0), thickness=5)
cv.rectangle(img, (384, 0), (510, 128), color=(0, 255, 0), thickness=3)
cv.circle(img, (447, 63), radius=63, color=(0, 0, 255), thickness=-1)
# 添加字体
font = cv.FONT_HERSHEY_SIMPLEX
cv.putText(img, "OpenCV", (10, 500), font, 4, (255, 255, 255), thickness=2, lineType=cv.LINE_AA)
# 显示图像
plt.imshow(img[:, :, ::-1])
plt.title("result"), plt.xticks([]), plt.yticks([])
plt.show()三、其他图像操作
前面已经提到,图像对象实际上是一个三维矩阵,因此我们可以通过对三维矩阵的操作来实现对图像的操作
1.获取并修改图像中的像素点
当我们只指定图像对象的行、列下标时,我们就可以获得图像的B-G-R的1×3一维数组