传统静态应用安全测试(SAST)工具在检测SQL注入、XSS等模式化漏洞方面表现出色,但在识别与业务流程紧密相关的逻辑漏洞时则显得力不从心。本文探索了一种将 SAST 与大语言模型(LLM)相结合的混合方法。
一、前言
在现代复杂的应用中,逻辑漏洞(如支付绕过、越权访问、优惠券滥用等)造成的损失往往比传统漏洞更为严重。这些漏洞与特定的业务场景深度绑定,缺乏统一的、可被正则表达式或通用规则库捕获的"漏洞模式",传统SAST工具由于无法理解业务功能逻辑,所以几乎无法覆盖此类问题。
而大语言模型(LLM)的出现为代码安全扫描带来了新的思路。其强大的代码理解和逻辑推理能力,使其具备了像人类专家一样对代码进行审计的潜力。然而,直接将整个项目代码投喂给大模型进行"漫无目的"的审计,不仅成本高昂,效果也难以保证,并且企业代码作为重要的商业资产,上传到大模型平台会带来数据安全与隐私合规等方面的风险。
本文的实践探索,旨在构建一条由AI智能体(Agent)驱动的自动化审计流水线。该框架深度结合了静态分析技术与大语言模型(LLM)的推理能力,旨在模拟人类专家的审计智慧,系统性地发现复杂漏洞,为SAST在逻辑漏洞识别领域提供了全新的、可落地的思路。
二、传统SAST的困境
要理解LLM(大语言模型)融入代码安全分析的价值,首先需要明确传统静态应用安全测试(SAST,Static Application Security Testing)工具的能力边界和现实困境。
2.1 工作原理
传统SAST工具主要依赖预设的规则和模式来扫描代码中潜在的风险。其核心技术包括:
- 模式匹配: 寻找已知的危险函数调用(如
strcpy,eval)。 - 污点分析: 追踪从不可信的用户输入(Source)到危险操作(Sink)的数据流路径。
- 控制流与数据流分析: 构建程序的执行路径(Control Flow Graph)和数据依赖关系(Data Flow Graph),力图覆盖可能存在的漏洞路径和逻辑分支,实现更深层次的静态检测。
2.2 核心局限性
尽管SAST工具功能强大,但其"机械化"的本质导致了以下核心局限:
- 高误报率: 由于无法完全理解代码的上下文和开发者的意图,常常会将安全的代码误报为漏洞。
- 缺乏业务逻辑理解: SAST无法理解"订单金额不能为负数"、"普通用户不能访问管理员后台"这类业务规则,因此几乎无法发现业务逻辑漏洞。
- 上下文感知能力差: 无法判断一个变量虽然被标记为"污点",但实际上已经在上游被一个安全的业务逻辑函数(如
isValidOrderIdForUser())所净化。
2.3 面临的挑战
- 高度依赖业务上下文:漏洞的产生往往与特定的业务场景强相关。脱离了"支付"、"下单"、"优惠券核销"等场景,一段代码本身可能毫无破绽。
- 缺乏通用漏洞模式:与SQL注入拥有固定的语法指纹不同,"越权访问"或"支付金额篡改"等逻辑漏洞在代码层面的表现形式千变万化,难以用统一的规则去匹配。
- 对状态与顺序的敏感性:业务流程的正确性严重依赖操作的顺序和状态的变更。例如,"先检查库存再扣款"与"先扣款再检查库存"在并发场景下安全性天差地别,这是传统静态分析难以理解的。
三、人工代码审计
审计方式与思路
(1)信息收集:
-
先对项目进行整体把控,阅读项目的文档(如README、设计说明、架构文档、注释)等内容,快速了解项目的业务目标和技术选型
-
查看项目的目录结构和配置文件,识别用到的主流技术栈(如Web框架、中间件、数据库类型等)、项目依赖及运行环境,评估系统可能涉及的安全边界。
-
了解各子模块的职责拆分及其间的调用关系,初步识别暴露在外的接口和核心数据流走向定位核心功能:
(2)定位核心功能:
- 结合文档、目录结构和业务流程,梳理出系统中的核心功能模块(如用户认证、权限管理、交易流程、资金操作、个人信息处理等)
- 分析相关功能在代码中的实现位置,例如确定每个接口对应的控制器/路由、Service层业务代码和数据访问层代码等
(3)关联代码与功能映射:
-
明确功能需求后,把业务功能点精准映射到具体的代码实现。例如,从API文档、路由配置或前端调用逻辑入手,追踪与业务相关的控制器、服务和数据库操作等代码。
-
搞清楚数据的流向,比如输入参数如何进入后端系统、在各层之间如何传递和处理、最终如何输出(对外返回或写入数据库等)。
(4)提出利用假设 :
-
结合经验和安全知识,针对每个功能点提出可能的攻击或滥用场景。比如:
markdown- 权限越权:用户是否可以访问/修改本不属于自己的资源? - 参数篡改:用户传入非法、特定格式的数据是否被正确处理? - 拒绝服务:是否存在可以被用来消耗服务器资源,导致服务不可用的入口? - SQL注入/XSS等安全问题点是否有风险点存在? -
针对不同类型的功能(如支付、用户信息修改、接口上传等)制定不同的审计关注点和假设攻击路径。
(4)利用场景验证:
-
顺着提出的利用假设,从入口点出发,深入分析代码实现,尤其是用户输入、权限校验、数据操作、异常处理等关键点。
-
跟踪请求参数和数据的流转过程,关注如下方面:
markdown- 输入参数的校验(如长度、格式、权限、白名单控制等) - 业务流程中的状态变更和依赖关系 - 关键操作是否有完善的权限认证与认证隔离 - 边界条件处理、异常分支、错误处理逻辑 -
必要时可结合调试或静态分析工具辅助定位问题
四、 如何让LLM像人一样进行逻辑漏洞分析
为了让AI Agent能够模拟人类安全专家的审计智慧,我们将其核心工作流解构为四个关键阶段:建立认知、构想攻击路径、验证追踪以及报告总结与修复。每个阶段都由特定的技术框架驱动,以系统化的方式完成其目标。
4.1 第一阶段 :建立认知 (Cognition)
(1)代码深度解析与知识库构建
- 目标:
将整个项目的源代码,转化为机器可以理解和检索的结构化知识,为后续的分析提供全面且精准的上下文。
- 实现路径:
ⅰ. 代码图谱生成:通过使用传统SAST工具,将项目源码编译成一个包含了控制流图(CFG)、数据流图(DFG)和函数调用关系图(Call Graph)的、高度结构化的代码属性图(CPG),这是所有后续分析的数据基石。
ⅱ. 架构信息提取: 随后对代码属性图执行一系列图查询算法。这些算法能精确地梳理出项目中所有的API端点、核心数据模型以及关键的架构组件信息,并且通过脚本工具,提取项目中的环境信息(README.MD、目录结构、配置文件等)。
ⅲ. 构建向量知识库: 将提取到的信息整合并进行向量化处理,构建一个支持语义检索的向量知识库,最终,我们得到了一个可以充分描述项目信息的知识库,它通过调用工具供大模型进行查询。
- 核心技术
此阶段的核心是RAG (Retrieval-Augmented Generation) 技术。RAG是一种将LLM的强大生成能力与外部知识库的精准检索能力相结合的技术框架。它允许LLM在回答问题前,先从我们构建的可信知识库中检索相关信息,并将这些信息作为上下文一同提供给模型。这使得LLM的回答不再仅仅依赖其静态的、预训练好的内部知识,而是基于了即时的、与问题高度相关的事实依据,从而完成了对项目的"认知建立"。
4.2 第二阶段:构想攻击路径
模拟威胁建模与攻击构想
-
目标: 在已建立的认知基础上,模仿人类专家的经验和发散性思维,系统性地提出针对应用核心业务逻辑的、高价值的攻击假设。
-
实现路径:
ⅰ. 核心功能识别: Agent首先通过调用知识库检索工具,向LLM提供项目的整体信息,让其识别出如"订单创建"、"用户认证"等高风险的核心业务功能。
ⅱ. 生成攻击假设: Agent向LLM下达一个基于业务背景的指令,例如:"针对'订单创建'流程,请提出几种最有可能的逻辑漏洞攻击假设。"
ⅲ. 思维分支探索: 在指令下,LLM会生成一个"攻击假设树",每个分支都是一个独立的攻击思路,如"分支A:价格篡改"、"分支B:越权操作"、"分支C:重复提交"等。
ⅳ. 初步评估与剪枝: Agent会引导LLM根据知识库中的信息(如API是否存在防重放机制),对每个分支的可行性进行快速的初步评估,从而优先探索最有希望的攻击路径。
- 核心技术:
此阶段由ToT(Tree-of-Thoughts) 框架驱动。ToT是一种让LLM模仿人类进行复杂问题解决的思维模式。当人类专家面对一个需要战略规划或探索的任务时,通常不会沿着一条路走到黑,而是会同时思考多种可能性,评估优劣,然后选择最有希望的路径深入探索。ToT框架就是将这种"思维树"的探索过程赋予了LLM,使其能够进行有效的头脑风暴和威胁建模。
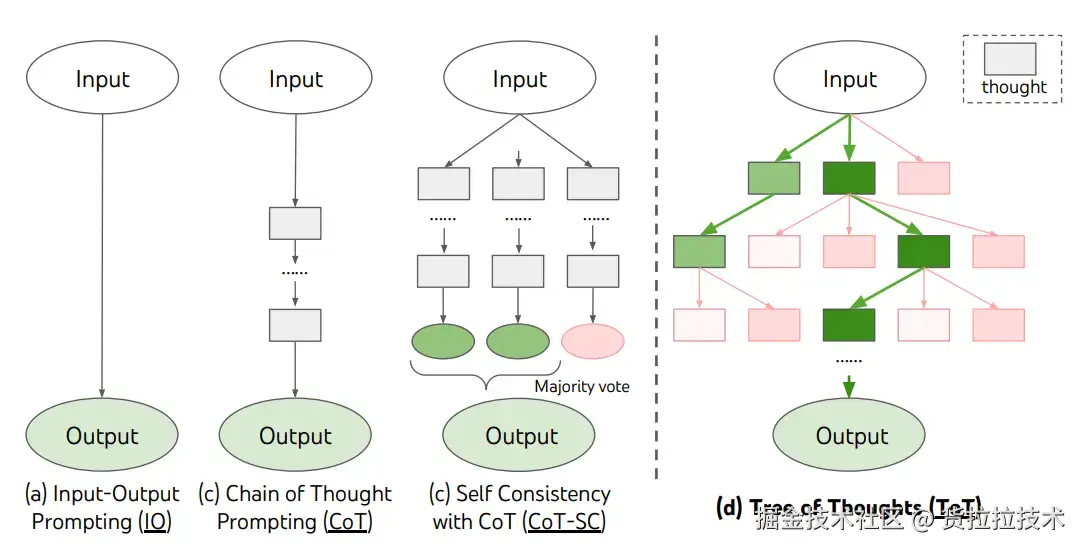
图1 ToT演示图
4.3 第三阶段:验证追踪
实现利用场景验证
-
目标: 针对上一阶段生成的高优先级攻击假设,通过一系列严谨的、工具驱动的验证步骤,形成完整的证据链,最终确认或排除漏洞的存在。
-
实现路径(以"价格篡改"假设为例):
ⅰ. 制定验证计划: Agent接收到任务后,LLM会首先制定一个验证计划:"首先,我需要确认用户传入的价格是否直接流向了支付计算;其次,我需要确认系统是否从数据库获取了真实价格进行校验。"
ⅱ. 执行数据流分析: Agent根据计划,发起一次污点分析,通过图查询追踪从HTTP输入到数据库写入的数据流路径。分析引擎返回"数据流存在"的结果。
ⅲ. 执行调用图分析: 接着,Agent查询代码属性图,分析关键方法的函数调用关系,以确认是否存在对价格校验逻辑的调用。分析引擎返回"未发现相关调用"。
ⅳ. 审查代码证据: 最后,Agent请求提取指定范围的代码片段,交由LLM进行最终审查。
ⅴ. 形成结论: LLM结合所有工具返回的证据(数据流存在、校验调用缺失、代码逻辑印证),最终得出"漏洞确认存在"的结论。
- 核心技术:
此阶段的核心是ReAct(Reasoning + Acting) 框架。ReAct是一个将LLM的"推理"(Reasoning)能力和"行动"(Acting)能力相结合的框架。它的灵感来自于"行为"与"推理"之间的协同作用,其核心是一个不断循环的过程:思考 -> 行动 -> 观察。在我们的场景中,"行动"即调用代码图谱分析、代码片段提取等工具。这有效地克服了传统LLM因缺乏与外部世界接触而导致的事实幻觉和错误传播问题,使得漏洞验证过程既智能又严谨。
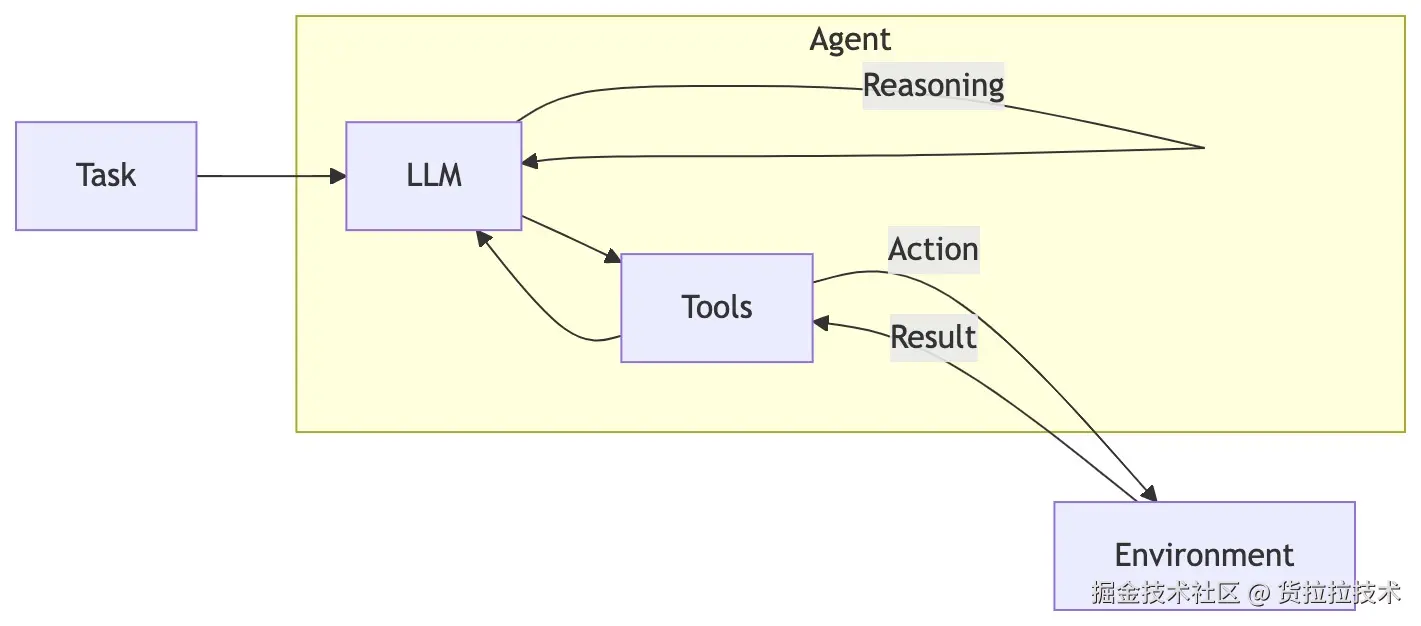
图2 ReAct演示图
4.4 第四阶段:报告总结与修复
- 目标:
在确认漏洞后,完成从"发现者"到"修复顾问"的角色转变,产出包含完整分析、评估和修复建议的最终报告,形成DevSecOps闭环。
- 实现路径:
ⅰ. 评估漏洞严重性: Agent将完整的证据链和漏洞上下文提交给LLM,指令其根据CWE、CVSS等行业标准,对漏洞的潜在影响和严重性进行评估。
ⅱ. 生成修复代码(补丁): 紧接着,Agent会向LLM提供存在漏洞的代码片段以及漏洞的根本原因分析,并要求其直接生成修复后的代码。LLM会理解漏洞(例如,缺少价格校验),并产出一个安全的、可供开发者参考甚至直接使用的代码补丁。
ⅲ. 整合最终报告: 最后,Agent将所有信息--包括漏洞描述、严重性评估、完整的证据链、以及AI生成的修复代码--自动汇编成一份结构化、内容详实的最终审计报告。
五、效果展示
图3 Agent运行流程图
5.1 漏洞检测报告
以下内容以AI生成的逻辑漏洞靶场为例,展示Agent在各个阶段的核心产出。
(1)应用识别与知识图谱构建
ⅰ. Agent首先采集项目元数据,通过深度代码分析构建出可供查询的知识库。
ⅱ. 流程图
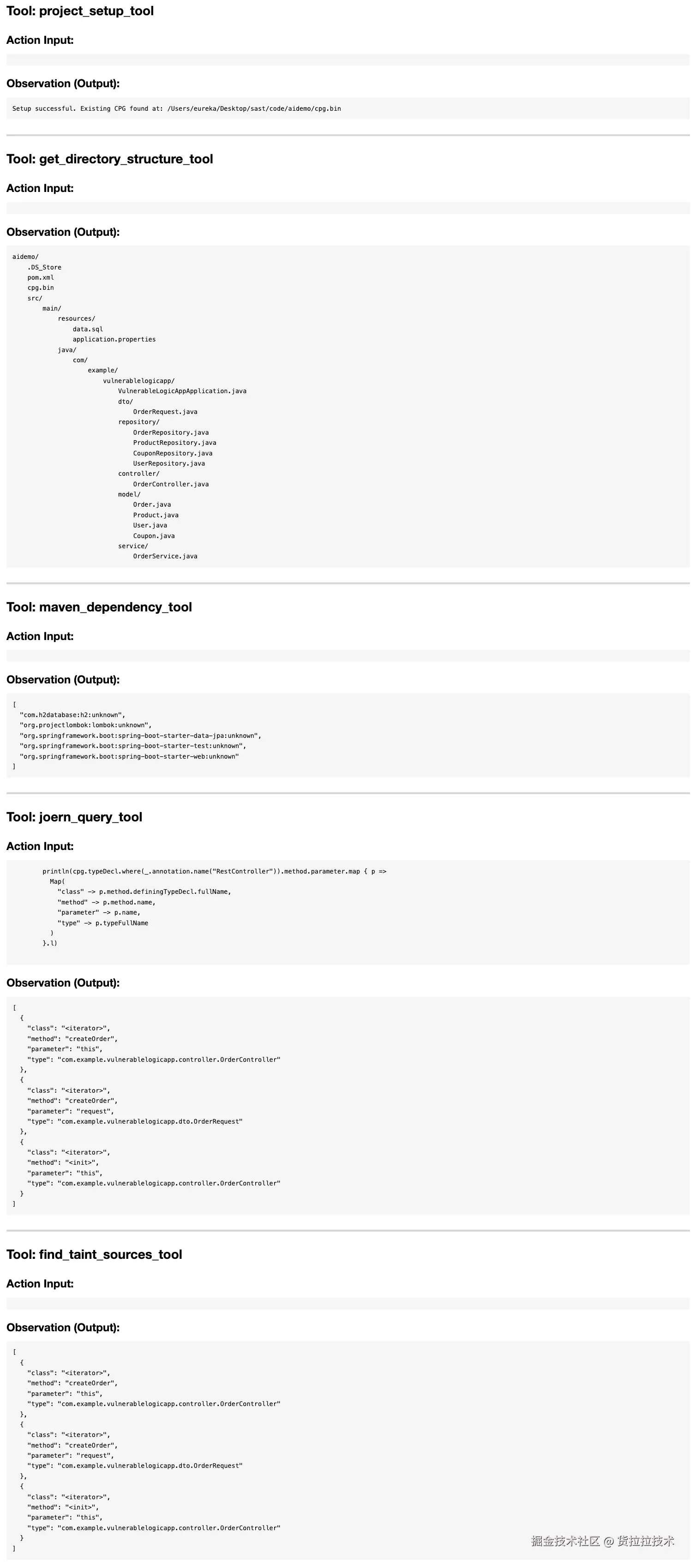
ⅲ. 部分元数据知识库效果图