基于 Apache Flink CDC 的 PostgreSQL 到 OpenSearch 实时数据同步方案
项目代码:github.com/zzusp/flink...
项目概述
本项目实现了一个基于 Apache Flink CDC (Change Data Capture) 技术的实时数据同步解决方案,能够实时捕获 PostgreSQL 数据库的变更事件,并通过流处理引擎将数据同步到 OpenSearch 搜索引擎中。该方案适用于需要实时数据同步的场景,如实时报表、实时搜索、实时推荐等业务场景。
技术架构
整体架构设计
项目采用现代化的微服务架构,主要包含以下核心组件:
scss
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ PostgreSQL │ │ Apache Flink │ │ OpenSearch │
│ (数据源) │───▶│ (流处理引擎) │───▶│ (目标存储) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
│ │ │
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 逻辑复制 │ │ CDC 连接器 │ │ 搜索引擎 │
│ WAL 日志 │ │ 异步 I/O │ │ 可视化界面 │
└─────────────────┘ └─────────────────┘ └─────────────────┘技术栈选择
- Apache Flink 1.20.2 (Java 17): 选择 Flink 作为流处理引擎,主要考虑其强大的容错能力、Exactly-Once 语义支持以及丰富的连接器生态
- PostgreSQL 16.9: 利用 PostgreSQL 的逻辑复制功能,通过 Debezium 连接器实现变更数据捕获
- OpenSearch 2.19.3: 作为目标存储系统,提供分布式搜索和分析能力,支持实时数据写入
- OpenSearch Dashboards 2.19.3: 提供数据可视化和监控界面
核心功能特性
- ✅ 实时捕获 PostgreSQL 数据变更 (INSERT, UPDATE, DELETE)
- ✅ 数据转换和丰富化处理
- ✅ 异步查询关联数据
- ✅ 将处理后的数据写入 OpenSearch
- ✅ 支持 Exactly-Once 语义
- ✅ 容错机制和自动恢复
- ✅ 容器化部署和快速启动
项目结构
bash
flink-pg-cdc-opensearch/
├── docker-compose.yaml # Docker Compose 配置文件
├── flink-job/ # Flink 作业源码
│ ├── build.gradle.kts # Gradle 构建配置
│ └── src/main/java/
│ └── com.zzusp.flink/
│ ├── PgCdcJob.java # Flink CDC 主作业
│ └── CustomRestClientFactory.java # OpenSearch 客户端配置
│ └── org.apache.flink/ # flink-connector-opensearch2 源码
├── postgres/ # PostgreSQL 配置
│ └── conf/
│ └── postgresql.conf # PostgreSQL 配置文件
├── opensearch/ # OpenSearch 数据存储目录
├── table.sql # 数据库表结构和测试数据
└── README.md # 项目说明文档核心实现原理
1. PostgreSQL CDC 配置
PostgreSQL 的逻辑复制配置是实现 CDC 的基础。项目通过以下配置启用逻辑复制:
sql
-- 设置 WAL 级别为 logical
ALTER SYSTEM SET wal_level = logical;
-- 创建专用用户并授权
CREATE USER flink_user REPLICATION LOGIN PASSWORD 'FlinkPwd013!@';
GRANT CONNECT ON DATABASE flink TO flink_user;
GRANT USAGE ON SCHEMA public TO flink_user;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO flink_user;
-- 创建发布和复制槽
CREATE PUBLICATION flink_cdc_pub FOR TABLE "public"."users";
SELECT pg_create_logical_replication_slot('flink_users_slot', 'pgoutput');2. 数据库表结构设计
项目设计了两个核心表来演示数据关联查询:
sql
-- 用户表(主表)
CREATE TABLE "public"."users" (
"id" int4 NOT NULL PRIMARY KEY,
"name" varchar(255)
);
-- 地址表(关联表)
CREATE TABLE "public"."address" (
"id" int4 NOT NULL PRIMARY KEY,
"user_id" int4 NOT NULL,
"address" varchar(255)
);
-- 插入测试数据
INSERT INTO "public"."address" VALUES (1, 1, 'flink address');
INSERT INTO "public"."address" VALUES (2, 2, 'admin address');
INSERT INTO "public"."users" VALUES (1, 'flink');
INSERT INTO "public"."users" VALUES (2, 'admin');3. Flink CDC 连接器配置
Flink CDC 连接器通过以下配置连接到 PostgreSQL:
java
PostgresSourceBuilder.PostgresIncrementalSource<String> source = PostgresSourceBuilder
.PostgresIncrementalSource.<String>builder()
.hostname("postgres")
.port(5432)
.database("flink")
.schemaList("public")
.tableList("public.users")
.username("flink_user")
.password("FlinkPwd013!@")
.decodingPluginName("pgoutput")
.debeziumProperties(properties)
.slotName("flink_users_slot")
.deserializer(new JsonDebeziumDeserializationSchema())
.build();4. 异步数据丰富处理
项目采用 Flink 的异步 I/O 功能实现数据关联查询,避免阻塞主数据流:
java
DataStream<String> enrichedStream = AsyncDataStream.unorderedWait(
cdcStream,
new EnrichmentAsyncFunction(),
15000, // 超时时间 (ms)
TimeUnit.MILLISECONDS,
20 // 最大并发请求数
);异步函数通过连接池查询关联的地址信息:
java
static class EnrichmentAsyncFunction extends RichAsyncFunction<String, String> {
@Override
public void asyncInvoke(String input, ResultFuture<String> resultFuture) {
JSONObject obj = JSONObject.parseObject(input);
String docId = obj.getJSONObject("after").getString("id");
Integer userId = Integer.parseInt(docId);
// 异步查询关联数据
CompletableFuture<String> future = Mono.from(connectionPool.create())
.flatMap(conn ->
Mono.from(conn.createStatement("SELECT * FROM address WHERE user_id = $1")
.bind(0, userId)
.execute())
.flatMap(result ->
Mono.from(result.map((row, meta) -> (String) row.get("address")))
)
).toFuture();
// 组装结果并返回
future.thenAccept(externalData -> {
obj.put("address", externalData);
resultFuture.complete(Collections.singleton(obj.toJSONString()));
});
}
}5. 数据转换处理
原始 CDC 数据经过以下转换处理:
java
DataStream<Map<String, Object>> esDataStream = enrichedStream.map(json -> {
JSONObject root = JSONObject.parseObject(json);
Map<String, Object> result = new HashMap<>();
// 提取操作类型
String op = root.getString("op");
result.put("op", op);
// 提取主键
String docId = root.getJSONObject("after").getString("id");
if (docId == null || docId.isEmpty()) {
docId = root.getJSONObject("before").getString("id");
}
result.put("id", docId);
// 构建文档内容
JSONObject payload = "c".equals(op) || "u".equals(op) ?
root.getJSONObject("after") : root.getJSONObject("before");
Map<String, Object> sourceMap = payload == null ? new HashMap<>(8) : payload.toJavaObject(Map.class);
result.put("sourceMap", root.getString("address"));
result.put("source", sourceMap);
// 添加时间戳
result.put("@timestamp", root.getLong("ts_ms"));
return result;
}).returns(Types.MAP(Types.STRING, Types.GENERIC(Object.class)));6. OpenSearch 连接器优化
为了解决 OpenSearch 连接器的 SSL 配置问题,项目自定义了 CustomRestClientFactory:
java
public class CustomRestClientFactory implements RestClientFactory {
@Override
protected void configureHttpClientBuilder(
HttpAsyncClientBuilder httpClientBuilder,
RestClientConfig networkClientConfig) {
if (networkClientConfig.isAllowInsecure().orElse(false)) {
try {
httpClientBuilder.setSSLContext(
SSLContexts.custom().loadTrustMaterial(new TrustAllStrategy()).build());
httpClientBuilder.setSSLHostnameVerifier(NoopHostnameVerifier.INSTANCE);
} catch (Exception ex) {
throw new IllegalStateException("Unable to create custom SSL context", ex);
}
}
}
}这个自定义工厂类解决了官方 flink-connector-opensearch-base 包中 DefaultRestClientFactory 在连接不安全的 OpenSearch 的 https 地址时报错的问题。
数据流处理流程
1. 数据捕获阶段
PostgreSQL 通过逻辑复制将数据变更写入 WAL (Write-Ahead Log),Flink CDC 连接器读取这些变更事件,包括 INSERT、UPDATE、DELETE 操作。
2. 数据转换阶段
原始 CDC 数据经过以下转换处理:
- 解析 Debezium JSON 格式
- 提取操作类型和主键信息
- 通过异步 I/O 查询关联数据
- 构建适合 OpenSearch 存储的数据结构
3. 数据写入阶段
处理后的数据通过 OpenSearch Sink 写入目标索引:
java
esDataStream.sinkTo(
new Opensearch2SinkBuilder<Map<String, Object>>()
.setBulkFlushMaxActions(1)
.setHosts(new HttpHost("opensearch", 9200, "https"))
.setConnectionUsername("admin")
.setConnectionPassword("HiQsquare013:!")
.setConnectionRequestTimeout(5000)
.setConnectionTimeout(5000)
.setSocketTimeout(5000)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.setAllowInsecure(true)
.setEmitter((element, context, indexer) ->
indexer.add(createIndexRequest(element)))
.build()
);部署和运维
环境要求
- Docker 和 Docker Compose
- 至少 4GB 可用内存
- 支持 Docker 的操作系统
快速部署步骤
-
克隆项目到本地
bashgit clone <repository-url> cd flink-pg-cdc-opensearch -
创建 Docker 网络
bashdocker network create flink-net -
启动所有服务
bashdocker-compose up -d -
初始化数据库
bash# 连接到 PostgreSQL 容器并执行初始化脚本 docker cp ./table.sql postgres:/table.sql docker exec -it postgres psql -U postgres -d postgres -f /table.sql
服务配置说明
PostgreSQL 配置
- 数据库:
flink - 用户名:
flink_user - 密码:
FlinkPwd013!@ - 复制槽:
flink_users_slot - 发布:
flink_cdc_pub - WAL 级别:
logical
OpenSearch 配置
- 用户名:
admin - 密码:
HiQsquare013:! - 地址:
https://localhost:9200 - 单节点模式
Flink 配置
- JobManager 端口: 8081
- 并行度: 2
- Checkpoint 间隔: 5000ms
容器化部署架构
项目采用 Docker Compose 进行容器化部署:
yaml
version: '3'
services:
jobmanager:
image: flink:1.20.2-java17
ports:
- "8081:8081"
command: jobmanager
environment:
- FLINK_PROPERTIES=jobmanager.rpc.address: jobmanager,parallelism.default: 2
taskmanager:
image: flink:1.20.2-java17
depends_on:
- jobmanager
command: taskmanager
environment:
- FLINK_PROPERTIES=jobmanager.rpc.address: jobmanager,taskmanager.numberOfTaskSlots: 2
postgres:
image: postgres:16.9
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=ThePgpass013@!
- POSTGRES_DB=postgres
- WAL_LEVEL=logical
opensearch:
image: opensearchproject/opensearch:2.19.3
environment:
- discovery.type=single-node
- OPENSEARCH_INITIAL_ADMIN_PASSWORD=HiQsquare013:!
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:2.19.3
environment:
OPENSEARCH_HOSTS: '["https://opensearch:9200"]'使用方法
1. 启动服务后访问管理界面
- Flink Web UI : http://localhost:8081
- OpenSearch Dashboards : http://localhost:5601
2. 编译和部署 Flink 作业
bash
cd flink-job
# 注意:打包需要使用 shadowJar,确保不会缺少第三方依赖包
gradle clean shadowJar生成的 JAR 文件将位于 build/libs/ 目录中。
3. 提交 Flink 作业
通过 Flink Web UI 上传 JAR 包并点击Submit按钮提交作业。
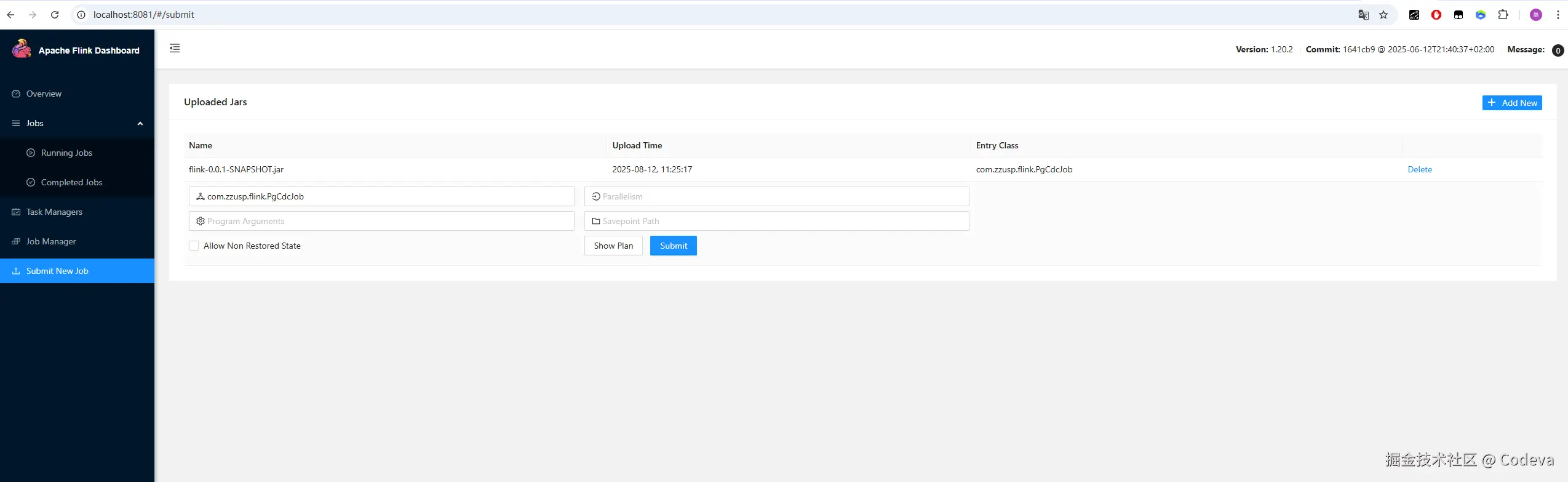
4. 测试数据同步
在 PostgreSQL 中执行 DML 操作观察数据同步:
sql
-- 插入新用户地址
INSERT INTO address VALUES (3, 3, 'newuser address');
-- 插入新用户
INSERT INTO users VALUES (3, 'newuser');
-- 更新用户信息
UPDATE users SET name = 'updateduser' WHERE id = 1;
-- 删除用户
DELETE FROM users WHERE id = 2;5. 查看同步结果
在 OpenSearch Dashboards 中配置 Index 和 Discover,查看同步的数据。
Discover配置Index 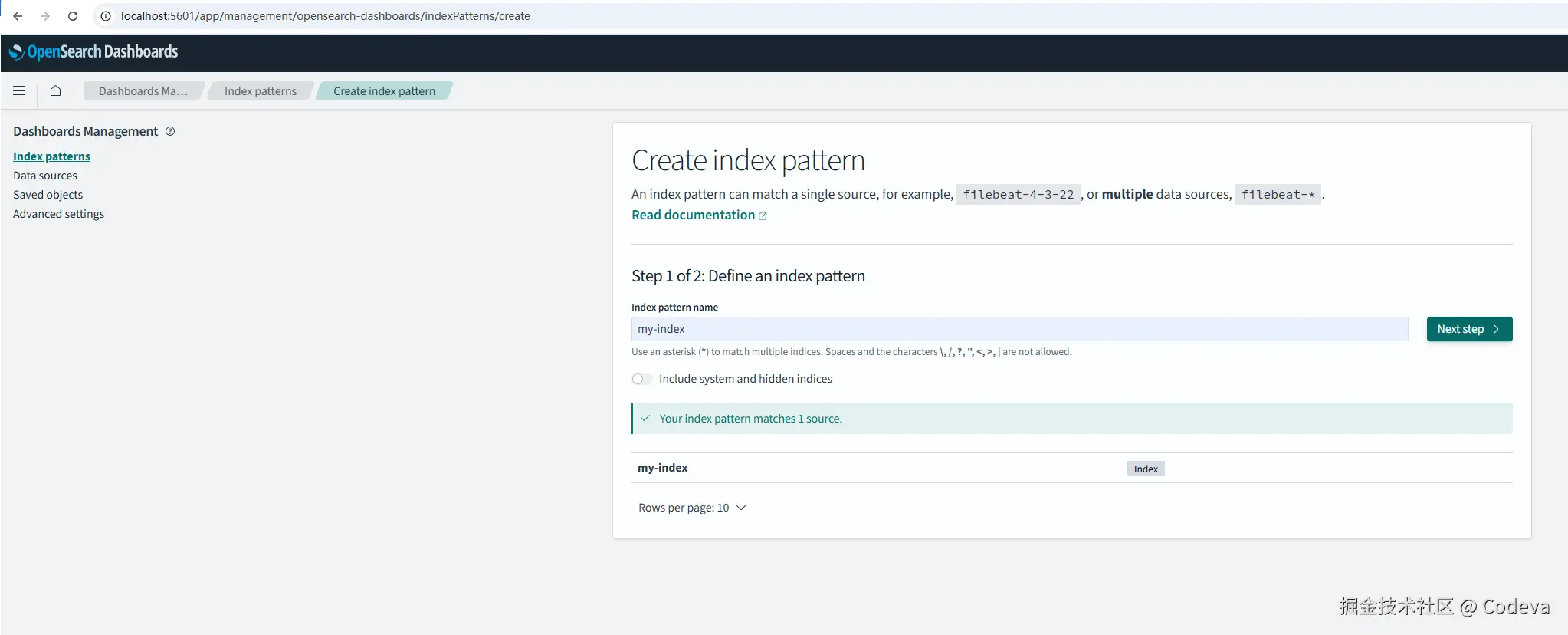 查看Discover
查看Discover 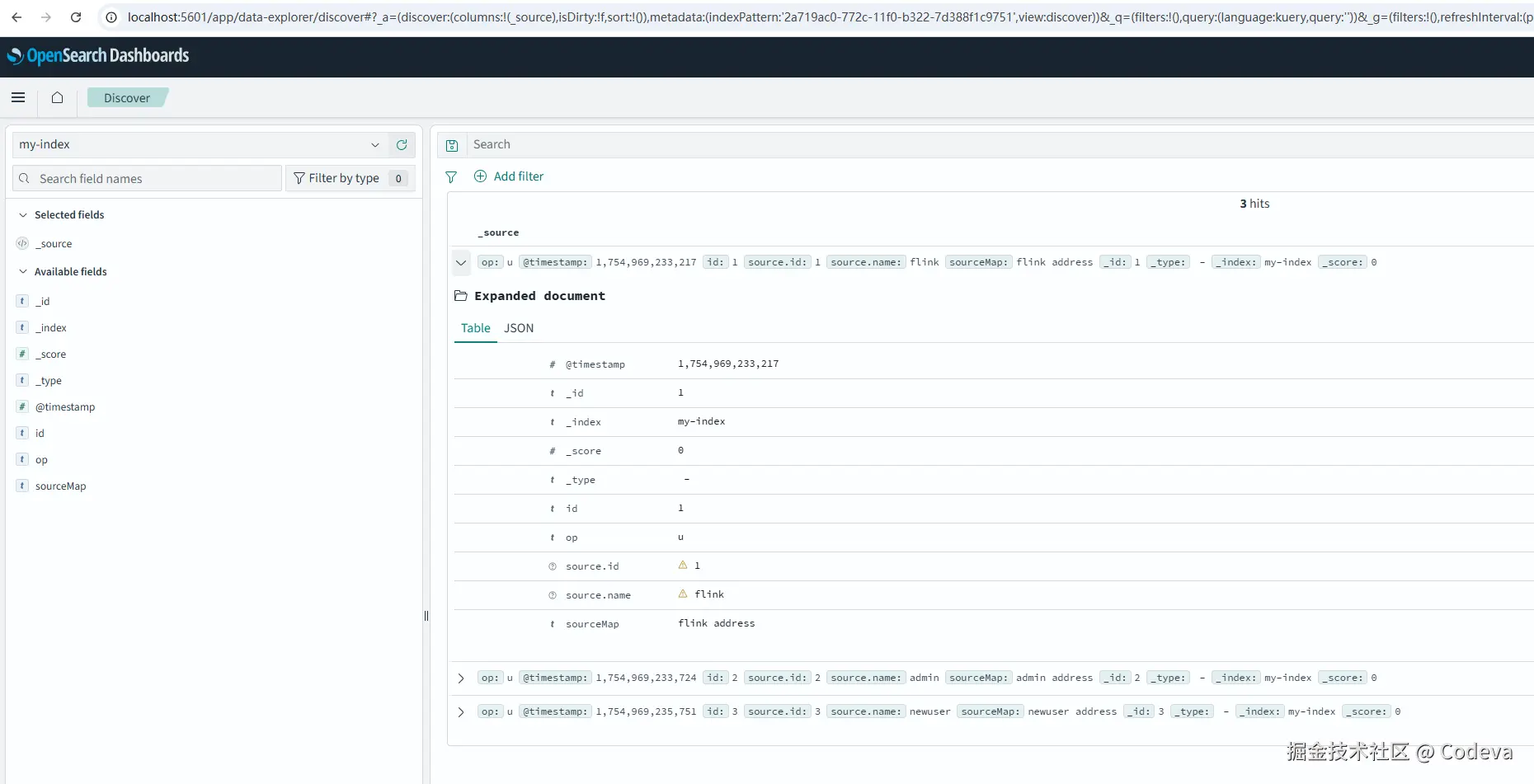
性能优化策略
1. 连接池管理
使用 R2DBC 连接池管理数据库连接,提高查询性能:
java
static ConnectionPoolConfiguration poolConfig = ConnectionPoolConfiguration.builder(connectionFactory)
.maxIdleTime(Duration.ofMinutes(30))
.maxSize(20)
.initialSize(5)
.maxCreateConnectionTime(Duration.ofSeconds(10))
.build();2. 异步处理优化
- 设置合理的超时时间(15秒)
- 控制最大并发请求数(20个)
- 使用无序等待模式提高吞吐量
3. 批量写入优化
java
.setBulkFlushMaxActions(1) // 每条数据立即写入
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE) // 至少一次语义监控和日志
查看服务日志
bash
# 查看 Flink JobManager 日志
docker logs flink-pg-cdc-opensearch-jobmanager-1
# 查看 Flink TaskManager 日志
docker logs flink-pg-cdc-opensearch-taskmanager-1
# 查看 PostgreSQL 日志
docker logs postgres
# 查看 OpenSearch 日志
docker logs opensearch监控指标
- Flink 指标: 通过 Web UI 查看作业执行状态、吞吐量、延迟等
- OpenSearch 指标: 通过 Dashboards 查看索引状态、查询性能等
- 系统资源: 监控 CPU、内存、磁盘 I/O 等系统资源使用情况
故障排除和最佳实践
常见问题解决
1. Flink 作业无法连接 PostgreSQL
检查 PostgreSQL 是否正确配置了逻辑复制:
- 确认
postgresql.conf中wal_level = logical - 确认
flink_user用户已授权 replication 权限 - 检查复制槽是否已创建
2. 数据未同步到 OpenSearch
- 检查 Flink 作业是否正常运行
- 查看日志确认是否有错误信息
- 验证 OpenSearch 连接配置是否正确
3. 性能问题
- 调整 Flink 并行度以匹配硬件资源
- 根据数据量调整 checkpoint 间隔
- 优化 OpenSearch 索引配置
生产环境建议
-
安全性
- 修改默认密码
- 配置适当的网络访问控制
- 启用 SSL/TLS 加密
-
监控
- 集成 Prometheus 和 Grafana 进行系统监控
- 设置告警机制
- 定期检查日志和指标
-
备份
- 定期备份 PostgreSQL 数据
- 备份 OpenSearch 索引配置
- 测试恢复流程
-
扩展性
- 根据数据量调整 Flink 集群规模
- 考虑使用 OpenSearch 集群模式
- 评估是否需要读写分离
注意事项
1. 自定义 OpenSearch 连接器
项目解决了官方 flink-connector-opensearch-base 包中 DefaultRestClientFactory 在连接不安全的 OpenSearch 的 https 地址时报错的问题。通过自定义 CustomRestClientFactory 并修改 flink-connector-opensearch2 源码,实现了对不安全 HTTPS 连接的支持。
2. 异步数据关联查询
采用 Flink 的异步 I/O 功能实现数据关联查询,避免了同步查询可能导致的性能瓶颈,提高了整体数据处理的吞吐量。
总结
本项目实现了一个基于 Apache Flink CDC 的实时数据同步解决方案,该方案具有以下优势:
- 实时性: 毫秒级的数据同步延迟,满足实时业务需求
- 可靠性: 支持 Exactly-Once 语义和容错机制,确保数据一致性
- 扩展性: 支持水平扩展和负载均衡,适应不同规模的数据量
- 易维护: 容器化部署和完整的监控体系,降低运维成本
- 高性能: 异步处理和连接池优化,提高数据处理效率
该方案适用于需要实时数据同步的场景,如实时报表、实时搜索、实时推荐、实时风控等业务场景。通过合理的技术选型和架构设计,能够为企业提供稳定、高效的实时数据处理能力。
未来规划
- 功能扩展: 支持更多数据源和目标存储系统
- 性能优化: 引入更多性能优化策略和监控指标
- 生态集成: 与更多大数据生态组件集成
- 云原生: 支持 Kubernetes 部署和云原生架构
参考资料
本文档基于项目实际代码和配置生成,如有疑问或建议,请提交 Issue 或 Pull Request。