注意:该项目只展示部分功能,如需了解,文末咨询即可。
1.开发环境
发语言:python 采用技术:Spark、Hadoop、Django、Vue、Echarts等技术框架 数据库:MySQL 开发环境:PyCharm
2 系统设计
随着北京市医疗保障体系的不断完善,医保药品目录的规模和复杂性日益增加。为了更好地管理医保基金,优化药品资源配置,同时提升医疗服务质量和患者满意度,需要对医保药品数据进行全面、深入的分析。然而,传统的数据分析方法难以满足复杂多变的医保药品管理需求。因此,开发一个基于机器学习的医保药品目录分析与可视化系统显得尤为迫切,该系统能够整合海量的医保药品数据,通过多维度的分析模型,为医保政策制定、药品采购、临床使用等提供科学依据和技术支持。
本系统的开发旨在填补北京市医保药品数据分析领域的技术空白,通过构建一个高效、智能的数据分析平台,实现对医保药品数据的深度挖掘和可视化展示。系统能够帮助医保管理部门精准制定政策,优化医保基金的使用效率;为医疗机构提供科学的药品采购和使用建议,提升医疗服务水平;同时,为患者提供透明的药品信息和报销政策解读,降低就医成本。系统的开发还将推动医保药品管理的信息化和智能化进程,为全国医保药品数据分析提供可借鉴的经验和模式。
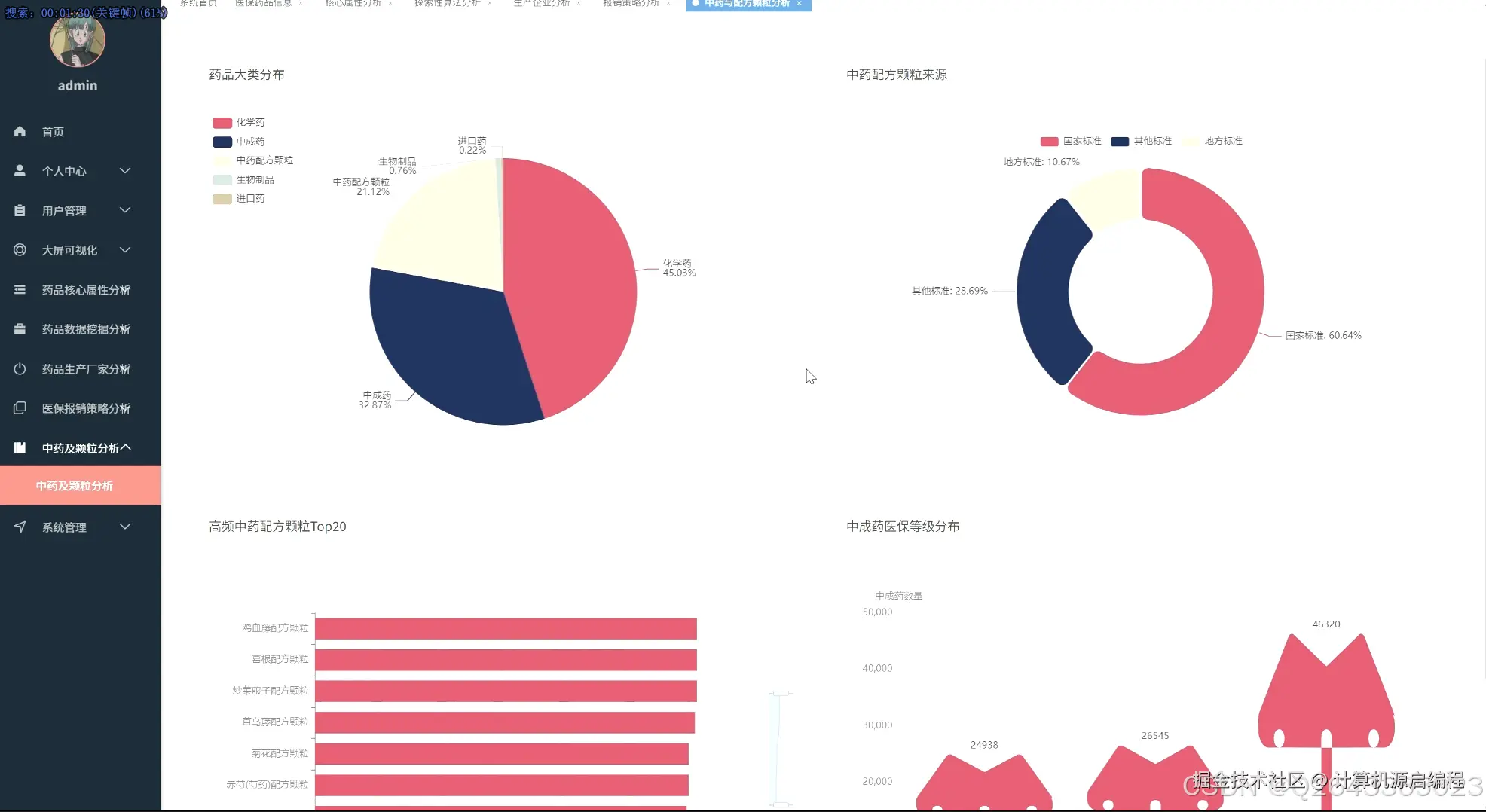
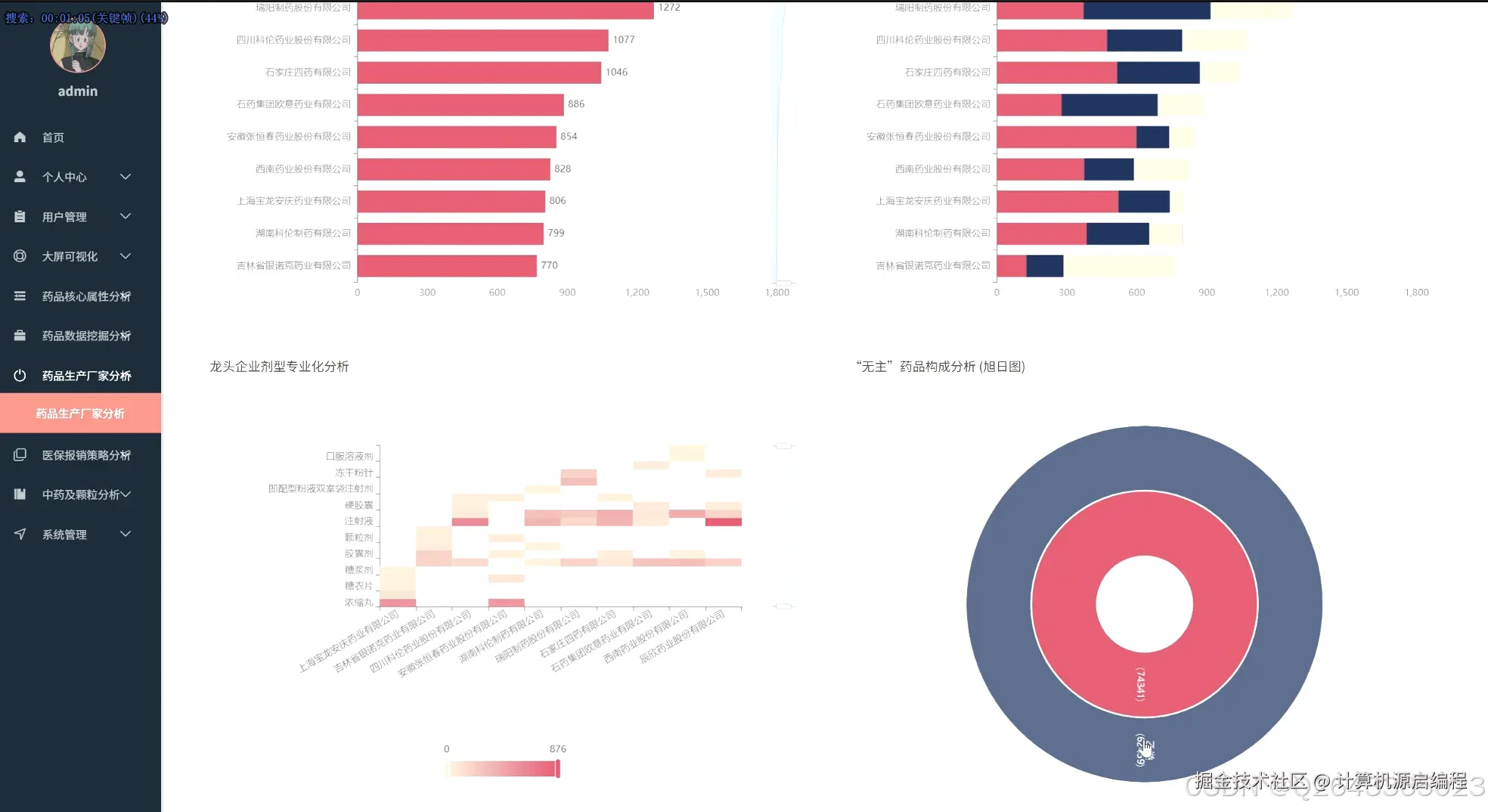
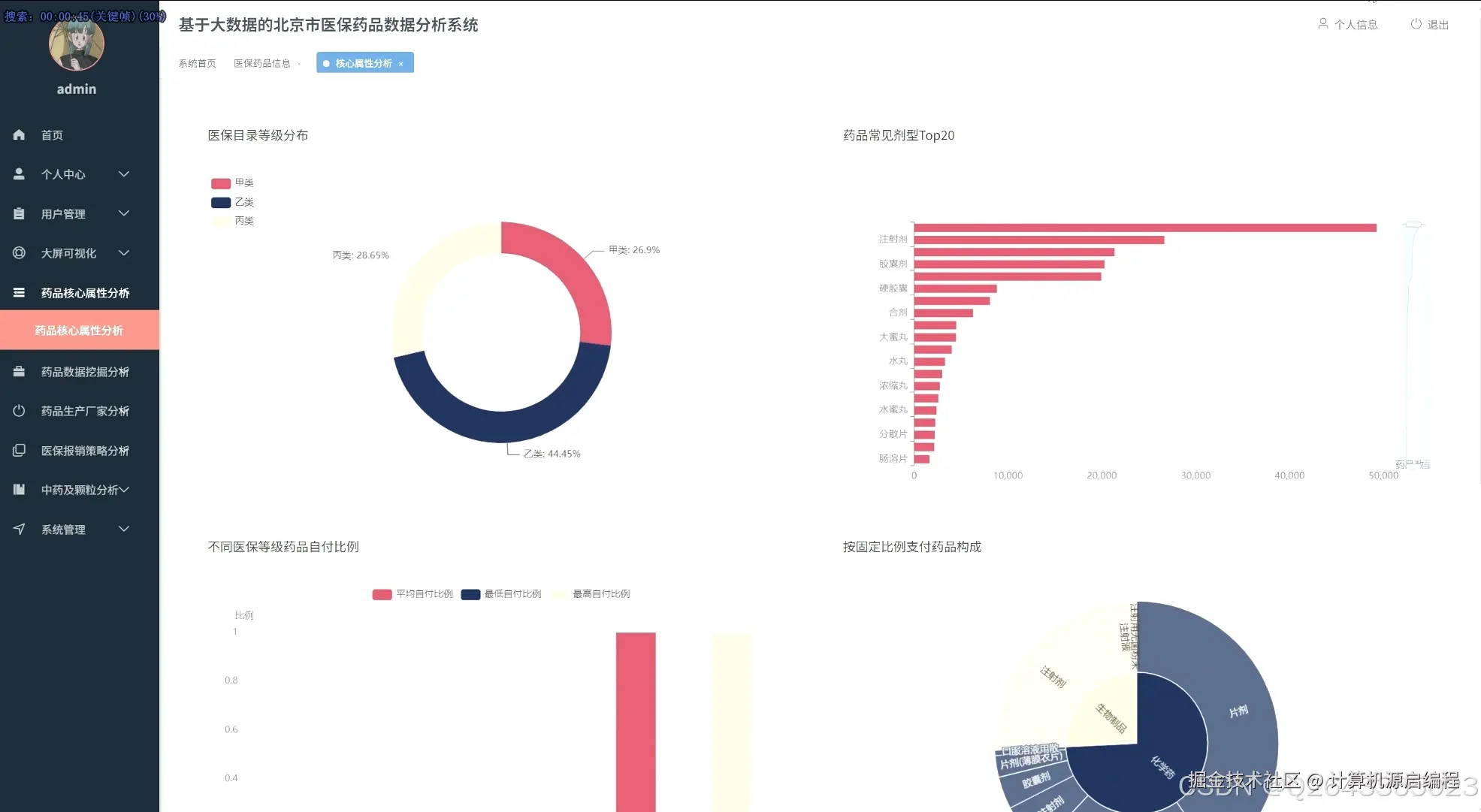
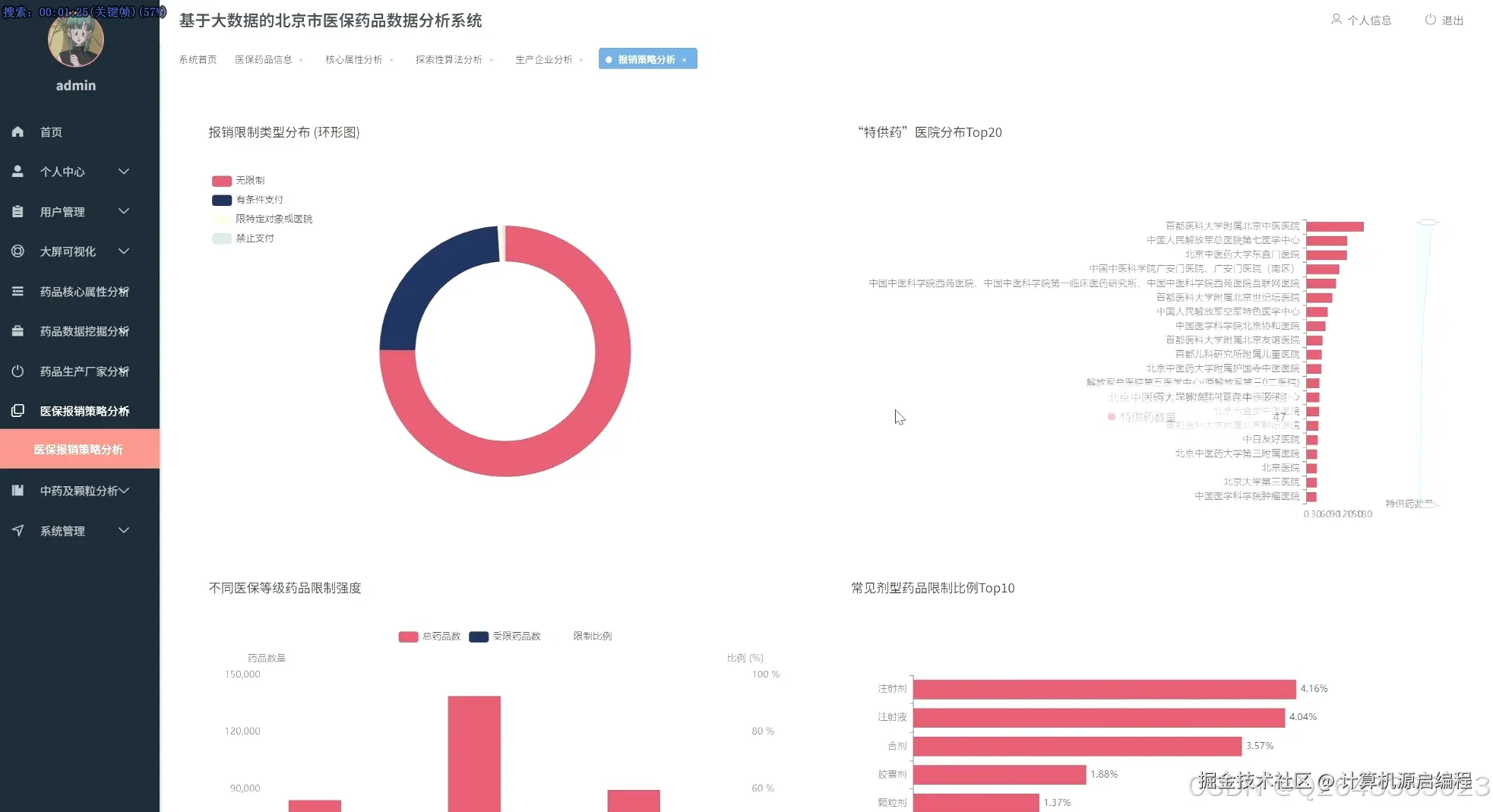
基于机器学习的医保药品目录分析与可视化系统的研究内容涵盖了北京市医保药品的多个关键维度,首先从药品的核心属性入手,分析医保目录等级分布、常见剂型、自付比例以及高频核心药品,宏观把握医保目录的整体构成和基本特征。其次,聚焦药品生产企业,研究其在医保市场中的份额、产品组合策略、剂型专业化水平以及"无主"药品的数据质量问题。进一步,深入医保报销限制策略,分析限制类型分布、"特供药"医院分布以及不同医保等级和剂型药品的限制强度。针对中药及中药配方颗粒开展专题分析,评估中西药数量对比、中药配方颗粒的种类及来源、生产企业竞争格局以及中成药的医保等级分布。最后,利用Apriori算法和K-Means算法,探索药品属性之间的潜在关联和聚类模式,为医保药品管理提供更深层次的决策支持。基于机器学习的医保药品目录分析与可视化系统包含以下主要功能模块: 药品核心属性分析模块:从医保目录等级、药品剂型、自付比例等基础属性出发,宏观分析北京市医保目录的整体构成和特征,识别核心药品及常见剂型。 药品生产企业分析模块:聚焦药品生产者,分析各药企在医保市场中的地位、产品策略和剂型专业化程度,识别龙头药企及其市场布局。 医保报销限制策略分析模块:深入研究药品报销限制条款,揭示医保基金的管理和控制手段,分析不同医保等级和剂型药品的限制强度。 特定药品专题分析模块:针对中药及中药配方颗粒进行专项分析,评估中医药在医保体系中的地位和政策支持力度。 药品关联与聚类分析模块:利用机器学习算法,挖掘药品属性之间的潜在关联和模式,实现药品的智能分类和报销限制条款的自动归纳。 数据可视化与报告生成模块:通过直观的图表和报表,展示分析结果,支持用户自定义报告生成,方便数据共享和决策支持。
3 系统展示
3.1 大屏页面
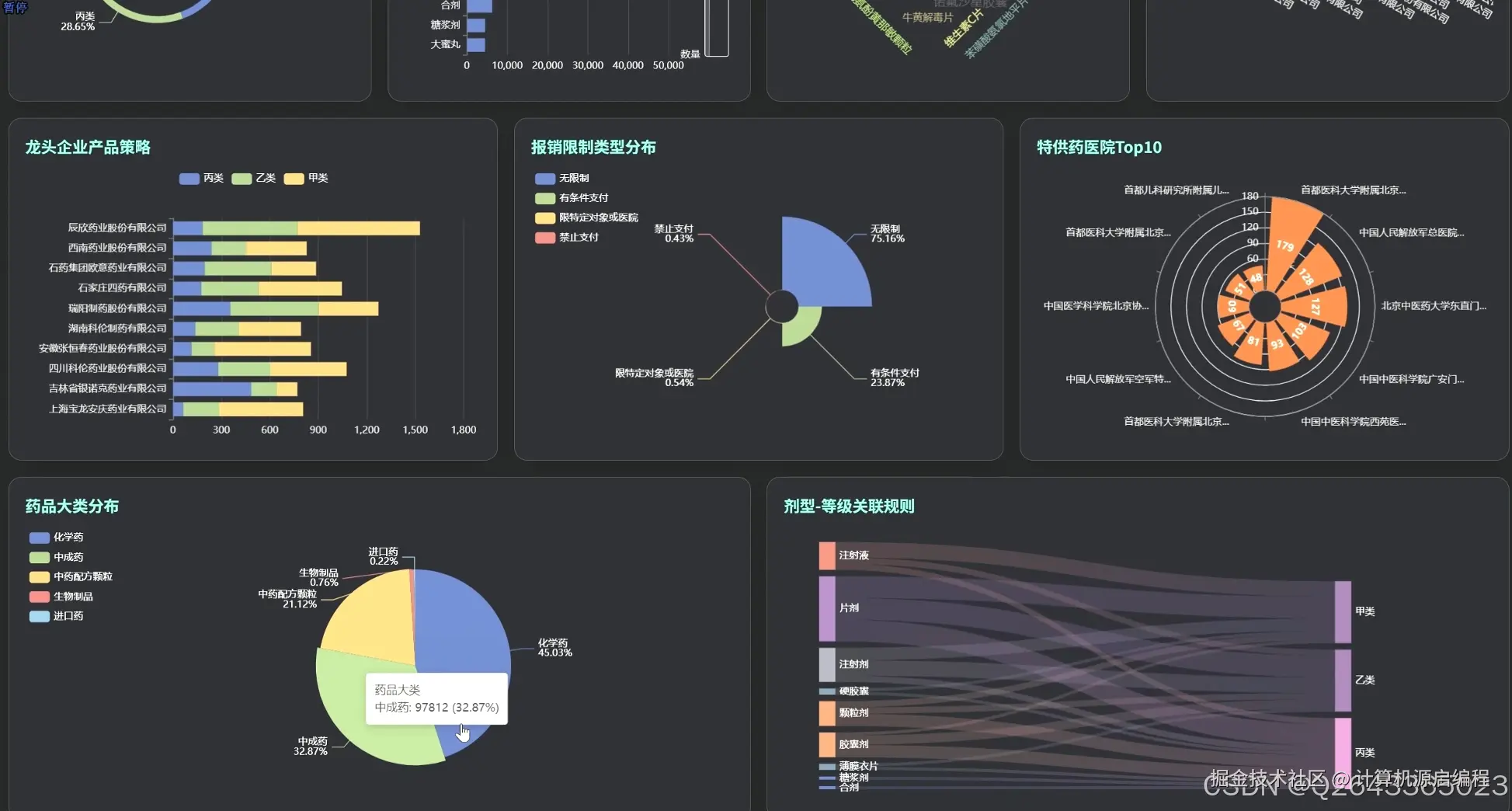
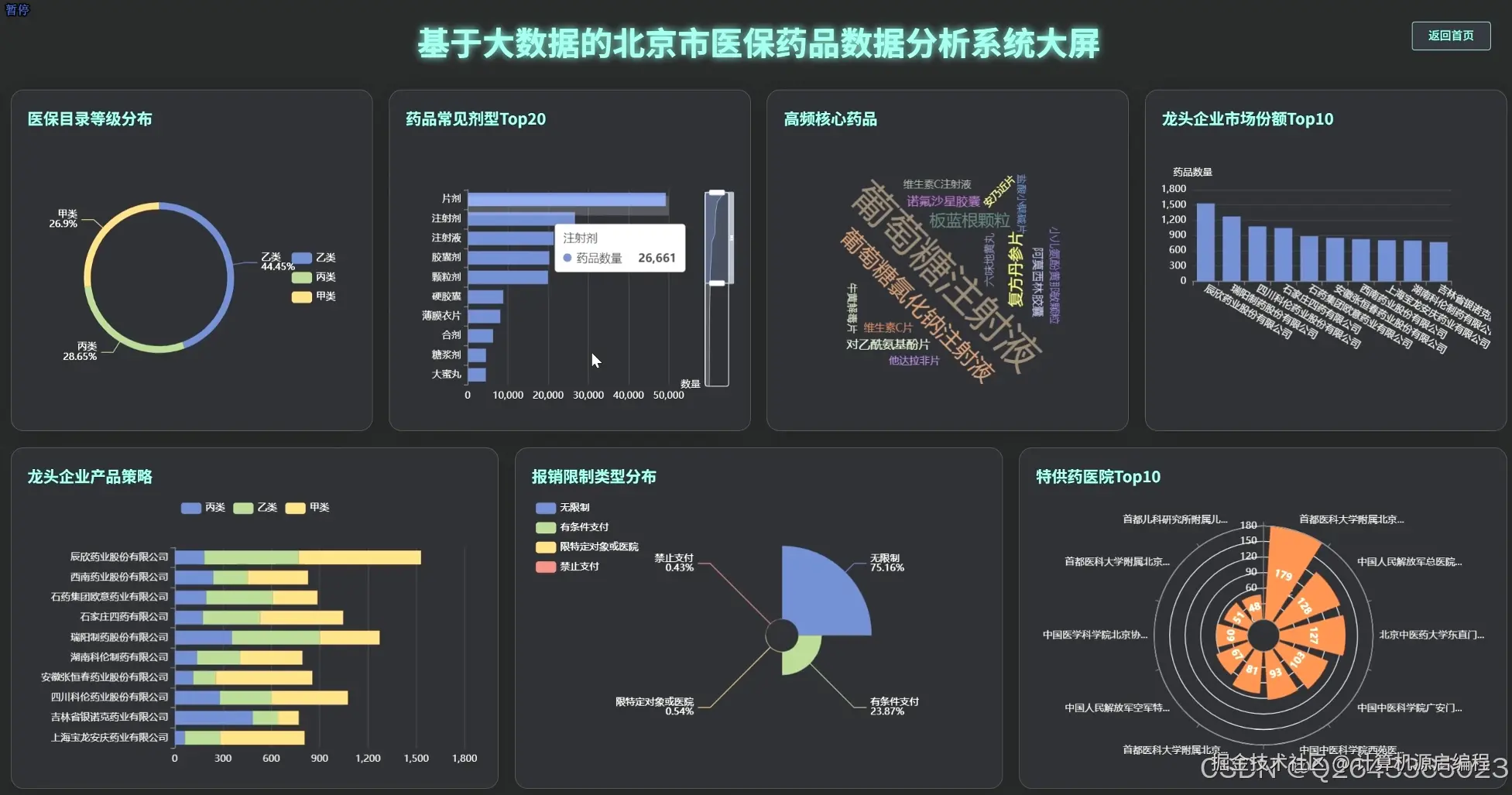
3.2 分析页面
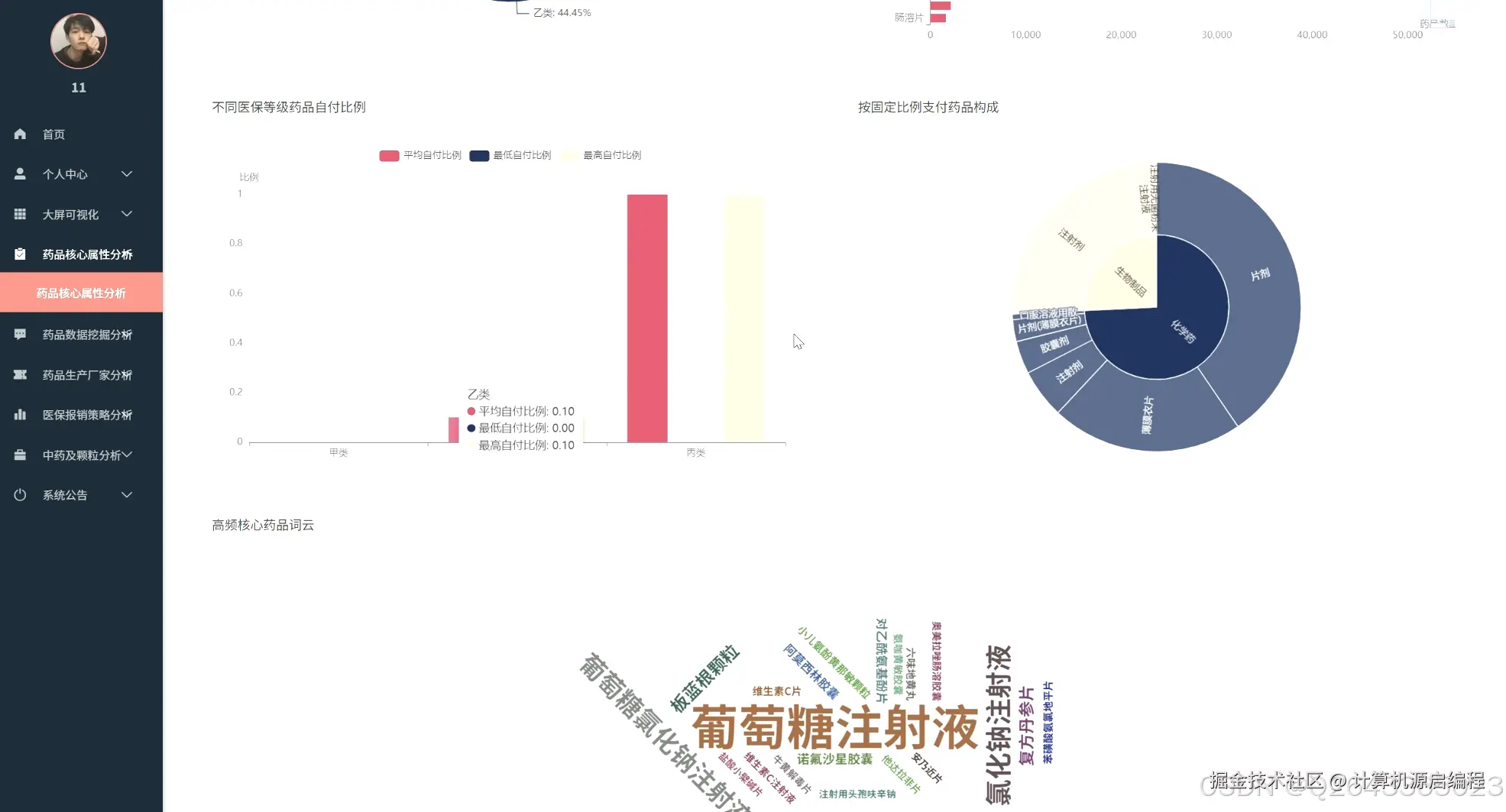
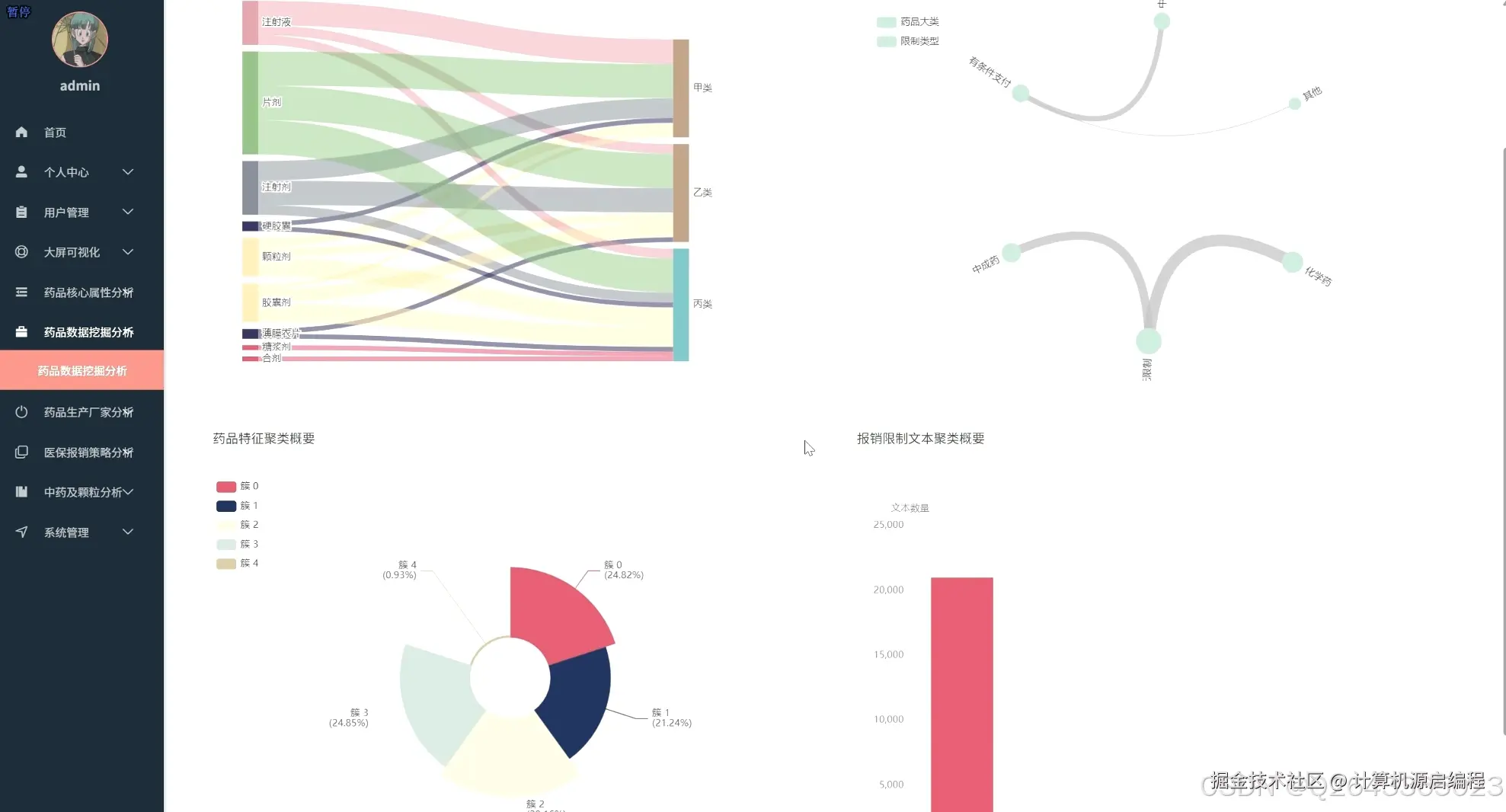
4 更多推荐
计算机专业毕业设计新风向,2026年大数据 + AI前沿60个毕设选题全解析,涵盖Hadoop、Spark、机器学习、AI等类型 【2026大数据毕业设计选题宝典】大数据专业毕业设计热门选题推荐,从数据挖掘到机器学习,全方位解析助力毕业设计轻松过 2025年最全的计算机软件毕业设计选题大全 基于 Python 和大数据框架的气象站数据深度分析与可视化系统设计与实现 基于Spark的酒店客户行为分析与个性化推荐系统 基于大数据的B站热门评论情感分析与可视化
5 部分功能代码
python
# 核心功能1:医保目录等级分布分析
def analyze_medical_insurance_level_distribution(medical_data):
"""
分析医保目录等级分布
:param medical_data: 医保药品数据列表,每个元素是一个字典,包含药品信息
:return: 医保目录等级分布的统计结果
"""
level_distribution = {'甲类': 0, '乙类': 0, '丙类': 0}
for item in medical_data:
level = item.get('医保目录等级')
if level in level_distribution:
level_distribution[level] += 1
else:
level_distribution[level] = 1
return level_distribution
# 核心功能2:药品生产企业市场份额分析
def analyze_market_share_of_manufacturers(medical_data):
"""
分析药品生产企业市场份额
:param medical_data: 医保药品数据列表,每个元素是一个字典,包含药品信息
:return: 药品生产企业市场份额的统计结果
"""
manufacturer_share = {}
for item in medical_data:
manufacturer = item.get('生产企业名称')
if manufacturer:
if manufacturer in manufacturer_share:
manufacturer_share[manufacturer] += 1
else:
manufacturer_share[manufacturer] = 1
# 按药品数量排序,获取市场份额排名
sorted_manufacturers = sorted(manufacturer_share.items(), key=lambda x: x[1], reverse=True)
return sorted_manufacturers
# 核心功能3:报销限制类型分布分析
def analyze_reimbursement_restrictions(medical_data):
"""
分析报销限制类型分布
:param medical_data: 医保药品数据列表,每个元素是一个字典,包含药品信息
:return: 报销限制类型分布的统计结果
"""
restriction_types = {'无限制': 0, '指定医院使用': 0, '工伤保险支付': 0, '其他限制': 0}
for item in medical_data:
restriction = item.get('报销限制说明')
if '无限制' in restriction:
restriction_types['无限制'] += 1
elif '指定医院使用' in restriction:
restriction_types['指定医院使用'] += 1
elif '工伤保险支付' in restriction:
restriction_types['工伤保险支付'] += 1
else:
restriction_types['其他限制'] += 1
return restriction_types
# 示例数据
medical_data = [
{'医保目录等级': '甲类', '生产企业名称': '企业A', '报销限制说明': '无限制'},
{'医保目录等级': '乙类', '生产企业名称': '企业B', '报销限制说明': '指定医院使用'},
{'医保目录等级': '丙类', '生产企业名称': '企业C', '报销限制说明': '工伤保险支付'},
# 更多数据...
]
# 调用核心功能
level_distribution = analyze_medical_insurance_level_distribution(medical_data)
print("医保目录等级分布:", level_distribution)
manufacturer_share = analyze_market_share_of_manufacturers(medical_data)
print("药品生产企业市场份额:", manufacturer_share)
restriction_types = analyze_reimbursement_restrictions(medical_data)
print("报销限制类型分布:", restriction_types)源码项目、定制开发、文档报告、PPT、代码答疑 希望和大家多多交流 ↓↓↓↓↓