0 前言
RNN(循环神经网络)本身存在各种各样的缺陷,比如梯度弥散、梯度爆炸和短时记忆的问题。为弥补RNN的这些问题,瑞士人工智能科学家于1997提出了Long Short-term Memory(长短时记忆网络),即现在常用的LSTM。
1 RNN的局限性
以下阐述流程
- 问题出现的原因
- 直观的解决问题的方法
循环神经网络会出现这三个问题的绝大多数原因取决于其参数梯度中的δhtδhi\frac{\delta h_t}{\delta h_i}δhiδht这一项。其展开如下所示,此处不做推导:
δhtδhi=Πj=it−1diag(σ′(Wxhxj+1+Whhhj+b))Whh\frac{\delta h_t}{\delta h_i}=\Pi^{t-1}{j=i}diag(\sigma'(W{xh}x_{j+1}+W_{hh}h_j+b))W_{hh}δhiδht=Πj=it−1diag(σ′(Wxhxj+1+Whhhj+b))Whh
观察上式我们发现实际上这个式子中存在WhhW_{hh}Whh的连乘运算,那么如果矩阵WhhW_{hh}Whh的最大特征值小于1,连乘会导致δhtδhi\frac{\delta h_t}{\delta h_i}δhiδht趋近于0,这就导致了梯度弥散。相对应的如果该值大于1,则会导致δhtδhi\frac{\delta h_t}{\delta h_i}δhiδht值爆炸式增长,即梯度爆炸。
1.1 梯度爆炸
很自然的,因为某个值过大而产生的问题,我们可以通过限制该值来解决。我们可以做梯度裁减,使WWW中的所有元素都在一定范围内就可以了。
- 假设张量为WWW,令所有元素wij∈min,maxw_{ij}\inmin,maxwij∈min,max
- 假设张量为WWW,限制张量的二范数∣∣W∣∣2∈0,max||W||_2\in0,max∣∣W∣∣2∈0,max,若∣∣W∣∣2>max||W||_2>max∣∣W∣∣2>max,则令W′=W∣∣W∣∣2⋅maxW'=\frac{W}{||W||_2}\cdot maxW′=∣∣W∣∣2W⋅max
- 假设张量为WWW,考虑全局范数裁减,令global_norm=∑i∣∣W(i)∣∣22global\_norm=\sqrt{\sum_i{||W^{(i)}||_2 }^2}global_norm=∑i∣∣W(i)∣∣22 ,则有W(i)=W(i)⋅max_normmax(global_norm,max_norm)W^{(i)}=\frac{W^{(i)}\cdot max\_norm}{max(global\_norm,max\_norm)}W(i)=max(global_norm,max_norm)W(i)⋅max_norm
上面的三种方法实际上只是从不同角度出发的裁减,目的都是一样的防止WWW过大导致梯度爆炸。
1.2 梯度弥散
对于梯度弥散现象,可以通过增加学习率、减少网络深度、添加SKip Connection(跳接,不了解可以看看unet)等一系列措施抑制。
1.3 短时记忆
上述两个问题必然会导致RNN的短时记忆,那么接下来就是来看LSTM是怎么解决这些问题的,我们先介绍门控制,再对门控制进行组合成为LSTM。
2 门控机制
实际上门这个概念很好理解,不管是电路、生物还是电脑的最底层理论里无外乎都是这些东西,那什么是门,通俗的理解就是有的东西能过去有的东西过不去,它对信号也好,化学物质也好做了筛选,实际上LSTM中的门控也是这样的。
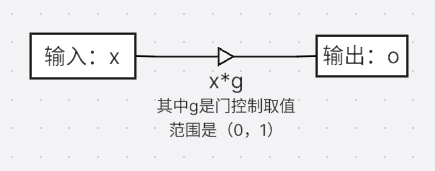
LSTM的门控机制如上图所示,这个图实际上就表明了输出o=输入x∗门控值g输出o=输入x*门控值g输出o=输入x∗门控值g,门控制g∈(0,1)g\in (0,1)g∈(0,1),显然g=0g=0g=0表示门关闭输入完全没有进来,g=1g=1g=1时刚好相反。
这个理念很好理解,但这里存在一个问题,我们的大脑对自动根据环境信息判断当前的信息要不要接收或者接受多少,这个东西就是所谓的门控值ggg,那么在LSTM中这个门控值ggg怎么计算呢?
实际上也很简单,我们也根据现在输入的环境信息获取一个取值范围在0到1之间的值就可以了。
LSTM有两个很重要的变量一个是输出hth_tht,一个是状态ctc_tct。
2.1 遗忘门
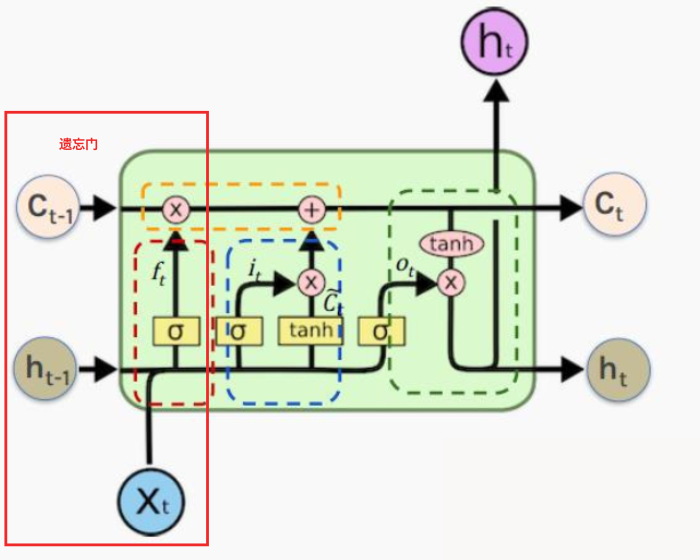
如上图所示实际上遗忘门就是对过去的状态ct−1c_{t-1}ct−1做筛选,而该门的门控值是通过ht−1、xth_{t-1}、x_tht−1、xt得到的,而门控值的取值范围是(0,1)(0,1)(0,1),因此最合理的方式是采取sigmoidsigmoidsigmoid函数,即ft=sigmoid(Wfht−1,xt+bf)f_t=sigmoid(W_fh_{t-1},x_t+b_f)ft=sigmoid(Wfht−1,xt+bf),经过该遗忘门后状态向量ct−1c_{t-1}ct−1变为ft∗ct−1f_t*c_{t-1}ft∗ct−1。
2.2 输入门
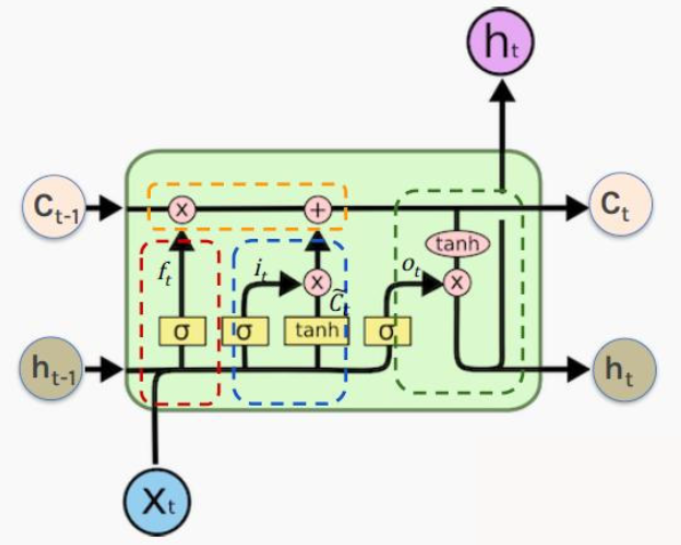
上图中的蓝色虚线部分就是输入门的部分,输入门的门控值依然是通过ht−1、xth_{t-1}、x_tht−1、xt得到的,即it=sigmoid(Wiht−1,xt+bi)i_t=sigmoid(W_ih_{t-1},x_t+b_i)it=sigmoid(Wiht−1,xt+bi),而输入门要过滤的值同样与输入相关,ct~=tanh(Wcht−1,xt+bc)\tilde{c_t}=tanh(W_ch_{t-1},x_t+b_c)ct~=tanh(Wcht−1,xt+bc),该值经过输入门后变为it∗ct~i_t*\tilde{c_t}it∗ct~。
将输入门的结果与遗忘门的结果相加得到的就是新的状态向量ct=ft∗ct−1+it∗ct~c_t=f_t*c_{t-1}+i_t*\tilde{c_t}ct=ft∗ct−1+it∗ct~
2.3 输出门
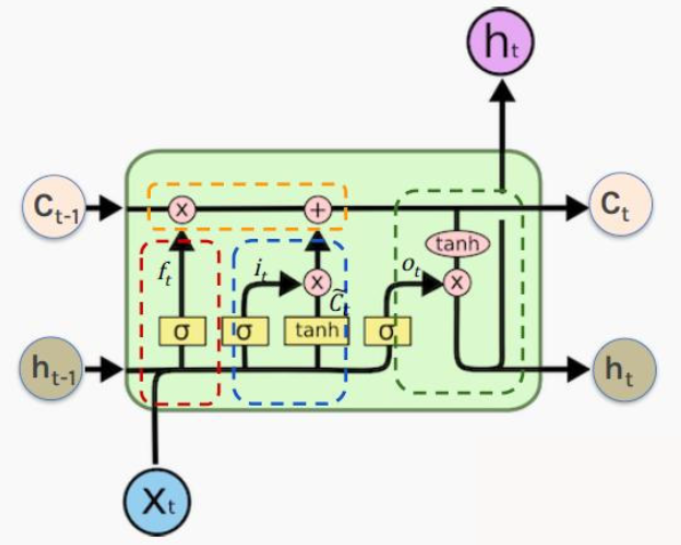
输出门的门控值依然是通过ht−1、xth_{t-1}、x_tht−1、xt得到的,即ot=sigmoid(Woht−1,xt+bo)o_t=sigmoid(W_oh_{t-1},x_t+b_o)ot=sigmoid(Woht−1,xt+bo),而输出门要过滤的值是tanh(ct)tanh(c_t)tanh(ct),所以输出ht=ot∗tanh(ct)h_t=o_t*tanh(c_t)ht=ot∗tanh(ct)
2.4 LSTM解决梯度爆炸及梯度弥散的方法
实际上我们通过简单的推理就能知道:ctc0≈Πj=1tfi\frac{c_t}{c_0}\approx \Pi^t_{j=1}f_ic0ct≈Πj=1tfi,其中fif_ifi是门控制,它的取值范围在(0,1)(0,1)(0,1)之间,实际上来说这也是一种裁减方式。fk<1f_k<1fk<1的约束避免了梯度爆炸。
深究RNN 我们会发现实际上导致梯度弥散的本质是激活函数求导造成的。
正向传播:
ht=σ(W⋅ht−1,xt+b)h_t=σ(W⋅h_{t−1},x_t+b)ht=σ(W⋅ht−1,xt+b)
σσσ 是激活函数(如 tanhtanhtanh 或 sigmoidsigmoidsigmoid)
反向传播(关键路径):
损失函数 LLL 对 ht−kh_{t−k}ht−k 的梯度依赖于链式法则:
∂L∂ht−k=∂L∂ht⋅(Πj=t−k+1t∂hj∂hj−1)\frac{\partial L}{\partial h_{t-k}}=\frac{\partial L}{\partial h_t}\cdot (\Pi^t_{j=t-k+1}\frac{\partial h_j}{\partial h_{j-1}})∂ht−k∂L=∂ht∂L⋅(Πj=t−k+1t∂hj−1∂hj)
而Πj=t−k+1t∂hj∂hj−1\Pi^t_{j=t-k+1}\frac{\partial h_j}{\partial h_{j-1}}Πj=t−k+1t∂hj−1∂hj部分的连乘是导致梯度弥散的关键。
其中∂hj∂hj−1=diag(σ′(zj))⋅Whh\frac{\partial h_j}{\partial h_{j-1}}=diag(\sigma'(z_j))\cdot W_{hh}∂hj−1∂hj=diag(σ′(zj))⋅Whh
其中σ′(zj)\sigma'(z_j)σ′(zj)是激活函数的导数,其值远小于1,所以就算WhhW_hhWhh特征值接近于1,连乘还是会导致梯度弥散。
但是LSTM中实际上梯度ctc0≈Πj=1tfi\frac{c_t}{c_0}\approx \Pi^t_{j=1}f_ic0ct≈Πj=1tfi只与门控值相关,没有激活函数的导数,从而及大程度的避免了梯度弥散的出现。